
作者:互联网搜索团队-Wang Wenqian
本文通过对OpenClaw,Claude Code等主流Agent产品的设计进行分析,给出Agent架构设计的关键决策,分析各方案的利弊。
1分钟看图掌握核心观点
图 1 VS 图 2,您更倾向于哪张图来辅助理解全文呢?
构建一个 Agent 需要做一系列架构决策:上下文怎么管理?工具怎么加载?工具怎么查找?Agent 的主循环围绕什么来设计?
这些决策没有标准答案,但每个选择都有明确的代价。本文从 OpenClaw、Claude Code 等主流 Agent 产品的实现出发,拆解四个关键的设计决策,分析各种方案的利弊。
OpenClaw 和 Claude Code 采用了同一种模式:追加式上下文(Append-only Context)。Agent 维护一个持续增长的对话历史,每次调用 LLM 时将完整历史作为 prompt 发送,每轮交互的结果追加到同一个数组中。
第1轮 LLM 调用: ┌──────────────────────────────────────────────┐ │ System Prompt │ User: "帮我重构登录模块" │ → LLM → 回复 + 工具调用 └──────────────────────────────────────────────┘ ~2K tokens 第2轮 LLM 调用(工具结果返回后): ┌──────────────────────────────────────────────────────────────────┐ │ System Prompt │ User │ Assistant │ Tool Call │ Tool Result │ ... │ → LLM └──────────────────────────────────────────────────────────────────┘ ~8K tokens ... 经过 20 轮工具调用 ... 第N轮 LLM 调用: ┌─────────────────────────────────────────────────────────────────────────────┐ │ System │ U │ A │ T │ R │ A │ T │ R │ A │ T │ R │ ... │ User: "你好" │ └─────────────────────────────────────────────────────────────────────────────┘ │◄──────────────── 80K tokens 历史 ──────────────────────►│◄─ 2 tokens ──►│ 全部重新发送 实际新内容这种模式运行在一个典型的 Agent Loop 中:
用户输入 │ ▼ ┌─────────────────────────────────────────────────────────┐ │ Agent Loop │ │ │ │ ┌───────────────────────────────────────────────┐ │ │ │ messages = [system, ...history, user_input] │ │ │ └───────────────────┬───────────────────────────┘ │ │ │ │ │ ▼ │ │ ┌─────────────────┐ │ │ │ 调用 LLM API │◄────────────┐ │ │ │ (全量上下文) │ │ │ │ └────────┬────────┘ │ │ │ │ │ │ │ ▼ │ │ │ 有工具调用? │ │ │ ╱ ╲ │ │ │ 是 否 │ │ │ │ │ │ │ │ ▼ ▼ │ │ │ ┌────────────┐ ┌──────────┐ │ │ │ │ 执行工具 │ │ 输出回复 │ │ │ │ │ 追加结果 │ │ (结束) │ │ │ │ │ 到 messages │ └──────────┘ │ │ │ └─────┬──────┘ │ │ │ │ 追加到 messages │ │ │ └──────────────────────────────────┘ │ │ │ │ messages 只增不减,直到会话结束或达到上下文窗口上限 │ └─────────────────────────────────────────────────────────┘优势:
- 缓存利用率高——每次请求的前缀高度重叠,prompt cache 命中率极高
- 实现简单——一个数组,只追加不修改,不需要复杂的上下文选择或裁剪逻辑
- 上下文连贯——模型始终能看到完整的交互历史,对单一任务的长期推理非常理想
问题:
当用户在同一个会话中切换话题时,所有历史被无差别地塞入同一个上下文窗口。用户上午讨论了一个复杂的代码重构(消耗 80K token),下午回来说了句"你好"——这句"你好"需要携带 80K token 的完整历史一起发送给模型。即便命中缓存,以 Opus 定价计算也要 $0.30。
上下文只增不减,无关信息干扰模型推理,成本与当前请求的复杂度完全脱钩。
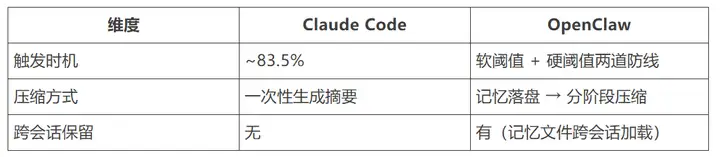
追加式模式终究会撞上上下文窗口的天花板。Claude Code 和 OpenClaw 各自设计了压缩机制。
Claude Code 在上下文使用率达到约 83.5% 时自动触发压缩——优先裁剪工具输出,LLM 生成结构化摘要前置到新会话开头,最近几轮对话原样保留。
压缩前: ┌─────────────────────────────────────────────────────────────────┐ │ System │ U │ A │ T │ R │ ... │ U │ A │ T │ R │ U │ A │ U │ A │ └─────────────────────────────────────────────────────────────────┘ │◄──────────────────── ~167K tokens ─────────────────────────────►│ 压缩后: ┌─────────────────────────────────────────────────────────────────┐ │ System │ [压缩摘要: 已完成X, 正在做Y, │ 最近几轮 │ 新输入 │ │ │ 修改了哪些文件, 关键决策...] │ 原样保留 │ │ └─────────────────────────────────────────────────────────────────┘ │◄─ 固定 ─►│◄──── ~10-20K ──────────────►│◄─ 近期 ─►│OpenClaw 采用更复杂的多层策略:在压缩之前先进行记忆落盘(让模型把重要信息写入磁盘上的 .md 文件),然后分阶段渐进压缩。落盘的记忆文件跨会话存活,下次可加载。
压缩机制是必要的安全网,但它是对上下文膨胀的缓解而非解决:压缩本身需要额外的 LLM 调用,摘要是有损的,而且压缩后的摘要仍然混合了所有话题。
这引出了另一个思路:与其在上下文膨胀之后想办法缩小,能否从源头避免不相关的内容进入同一个上下文?
除了压缩,还有一种更直接的应对方式:以任务为单位隔离上下文。这并不是什么新概念——传统的任务队列、工单系统早就是这么做的,只是在 Agent 领域,对话驱动模式的流行让这种思路被忽略了。
对话驱动(当前主流模式): ┌──────────────────────────────────────────────────────────────┐ │ 重构登录模块(80K) │ "你好"(2) │ 查询用户数据(30K) │ ... │ │ 所有内容挤在同一个上下文中 │ └──────────────────────────────────────────────────────────────┘ 每次调用都携带全部历史,无论是否相关 任务隔离: ┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ │ 任务1: 重构登录 │ │ 任务2: 查询数据 │ │ 任务3: 部署服务 │ │ 上下文: 80K │ │ 上下文: 30K │ │ 上下文: 15K │ │ (只含相关内容) │ │ (只含相关内容) │ │ (只含相关内容) │ └──────────────────┘ └──────────────────┘ └──────────────────┘ 每个任务只为自己的上下文付费以任务为单位隔离上下文,每个任务拥有独立的上下文窗口。任务内部仍然使用追加式上下文——这完全合理,一个任务内的所有交互记录天然相关。但任务之间的上下文是隔离的,互不干扰。
这种方式要求用户建立一个简单的意识:不同的问题,在不同的任务中解决。 就像程序员知道不同的功能应该在不同的分支上开发一样。好的设计应该让这种隔离自然发生——新问题自动创建新任务,上下文跟着任务走,用户不需要手动管理 prompt。
任务隔离的优势是彻底消除了话题混杂问题,每个任务的上下文成本与其自身的复杂度成正比。代价是放弃了跨任务的上下文连贯性——如果两个任务之间有关联,需要额外的机制(如任务间共享摘要、会话关联)来传递信息。
对话驱动模式屏蔽了任务概念,换来的是入门门槛低;任务隔离模式引入了任务边界,换来的是更高的效率和更低的成本。两者的取舍取决于目标用户和使用场景。
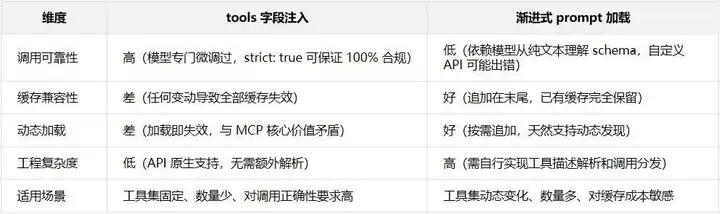
LLM API 的请求中,tools 是独立于 messages 的顶层字段。模型针对这种结构化格式专门微调过,保证了工具调用的高正确率和解析确定性。
但 Anthropic 的 Prompt Cache 按严格顺序构建缓存前缀: system → tools → messages。 tools位于前端,缓存从第一个 token 开始逐一比对,任何位置出现差异,该位置及之后的所有内容全部失效。
请求 A(5 个工具): ┌──────────────────────────────────────────────────────────┐ │ system prompt │ tools(5个) │ msg1 │ msg2 │ ... │ msg100 │ └──────────────────────────────────────────────────────────┘ ✅ 全部命中 请求 B(加了1个新工具,变成6个): ┌───────────────────────────────────────────────────────────┐ │ system prompt │ tools(6个) │ msg1 │ msg2 │ ... │ msg100 │ └───────────────────────────────────────────────────────────┘ ↑ tools 变了,整条链全部失效 ❌ 100K token 的 messages 缓存失效(即使内容完全没变)MCP 的核心价值在于动态工具发现和加载,但每切换一次工具集,就要为整个对话历史全额付费。Claude Code 报告的 92% 缓存命中率,很大程度上靠的就是永远不改变 tools 列表。
当前架构的矛盾: 动态工具(MCP 的核心价值) ↕ 不可调和 缓存稳定性(成本控制的关键)一种替代方案是将工具描述嵌入 messages 而非 tools 字段:
当前方式(tools 字段注入): ┌──────────────────────────────────────────────────┐ │ system │ tools [A,B,C] │ messages... │ └──────────────────────────────────────────────────┘ ↑ 改这里 → 后面全部失效 替代方式(工具描述嵌入 prompt): ┌──────────────────────────────────────────────────┐ │ system │ messages... │ [工具 A 描述] [工具 B 描述] │ └──────────────────────────────────────────────────┘ ↑ 追加新工具 → 前面的缓存全部保留 ✅优势是增加工具不破坏缓存,按需加载,与追加式上下文兼容。代价是离开了 tools 字段的结构化保证,需要自行实现工具结构的解析和调用逻辑,模型从纯文本描述中理解自定义 API schema 的可靠性可能下降。
工具描述移入 prompt 后,格式可靠性取决于工具类型。
如果工具是终端—— execute: 执行 shell 命令,返回 stdout/stderr ——几乎不需要"教"模型任何东西。curl、grep、psql、docker 这些是模型在预训练中已经掌握的世界知识,不是需要通过 JSON Schema 定义的陌生 API。
MCP 方式:需要 N 个工具定义 ┌─────────────────────────────────────────────────────────┐ │ tools: [get_weather, query_db, send_email, read_file, │ │ write_file, search_web, translate, ...] │ └─────────────────────────────────────────────────────────┘ 每增加一个 → 缓存全部失效 控制台方式:始终只需要 1 个工具定义 ┌───────────────────────────┐ │ tools: [execute] │ ← 永远不变,永远命中缓存 └───────────────────────────┘ 需要查天气? → execute: curl wttr.in/Beijing 需要查数据库?→ execute: psql -c "SELECT ..." 需要发邮件? → execute: sendmail ...控制台的优势:零学习成本、格式解析问题消失、工具数量无限、与缓存完全兼容。
但控制台不能覆盖所有场景——需要 OAuth 认证的第三方 API、需要维持长连接的服务等,终端命令并非**选择,这类远程服务仍然需要 MCP 提供标准化的接口结构和鉴权机制。
实际的工具策略是:本地能力用控制台,远程能力用 MCP,二者组合覆盖绝大部分场景。 少数需要持久连接或复杂状态管理的场景(如 WebSocket 订阅、连接池维护)仍然是开放问题。
结合控制台和 MCP,理想的工具加载方式是渐进式的:
任务开始(轻量上下文): ┌────────────────────────────────────────────┐ │ system │ 任务目标 │ 基础工具(execute) │ └────────────────────────────────────────────┘ ~3K tokens Agent 判断需要远程搜索工具: ┌────────────────────────────────────────────────────────────┐ │ system │ 任务目标 │ 基础工具 │ 对话... │ + mcp_search 描述 │ └────────────────────────────────────────────────────────────┘ │◄────────── 缓存命中 ──────────────►│◄─ 新增 ─►│ Agent 发现并加载数据库工具: ┌──────────────────────────────────────────────────────────────────────┐ │ system │ 任务目标 │ 基础工具 │ 对话... │ mcp_search │ + query_db 描述 │ └──────────────────────────────────────────────────────────────────────┘ │◄─────────────── 缓存命中 ──────────────────────►│◄── 新增 ──►│每次只追加新工具的描述,已有的上下文缓存完全保留——工具跟着对话流走,而不是钉死在缓存前缀的头部。
两种方式可以混合使用:高频、核心的工具(如 execute)放在 tools 字段保证可靠性和缓存稳定;低频、动态发现的远程工具通过 prompt 渐进式加载,避免破坏缓存前缀。
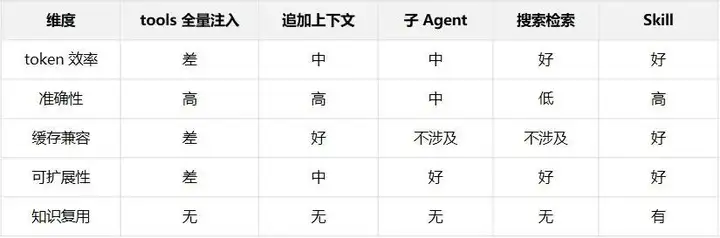
当可用工具达到数百甚至上千个时,Agent 如何高效地找到解决当前问题所需的工具?
- 全量注入 tools 字段。 最简单,模型路由准确率高。但工具列表变动导致缓存失效,工具数量多时固定 token 开销巨大。
- 追加上下文加载。 不破坏缓存,但工具描述一旦追加就永远留在上下文中,几轮搜索下来上下文堆满已用完的工具描述。
- 子 Agent 查找。 不污染主上下文,但子 Agent 缺乏主对话的上下文理解,可能选择不够精准的工具。
- 向量搜索 / 关键词检索。 零 LLM token 消耗,但语义模糊时不够准确,工具库大时噪声严重。
这四种方式面临一个共同的矛盾:我们在接口维度上查找工具(一个 API 一个工具),但实际需求是在功能维度上查找能力。
Skill 的本质是:将多个工具的调用方法内聚在一起,按功能维度组织,而非按接口维度罗列。
接口维度(传统工具列表): ┌────────────────────────────────────────────────────────────┐ │ pg_connect │ pg_query │ pg_insert │ pg_update │ │ pg_delete │ pg_schema │ pg_export │ pg_import │ │ redis_get │ redis_set │ redis_del │ redis_scan │ │ s3_upload │ s3_download│ s3_list │ s3_delete │ └────────────────────────────────────────────────────────────┘ 20 个工具定义,搜索空间:20 个选项 功能维度(Skill): ┌──────────────────────────────────────────────┐ │ 数据库管理 │ 缓存操作 │ 文件存储 │ │ (内含 8 个 │ (内含 4 个 │ (内含 4 个 │ │ pg_* 工具的 │ redis_* │ s3_* 工具的 │ │ 组合用法) │ 工具用法) │ 组合用法) │ └──────────────────────────────────────────────┘ 3 个技能,搜索空间:3 个选项一个 Skill 不是一个工具,而是一份"如何组合使用多个工具完成某类任务"的说明书:
# 数据库管理技能 能力描述 管理 PostgreSQL 数据库:查询、写入、schema 管理、数据导入导出。 可用工具 - psql:命令行客户端,支持 SQL 查询和管理 - pg_dump / pg_restore:备份与恢复 常见用法 查询数据 > psql -h $HOST -d $DB -c "SELECT * FROM users WHERE active = true" 导出为 CSV > psql -h $HOST -d $DB -c "COPY (SELECT ...) TO STDOUT CSV HEADER" > output.csv 查看表结构 > psql -h $HOST -d $DB -c "d+ tablename" 注意事项 - 写操作前先确认,避免误修改 - 大查询加 LIMIT就像 CPU 缓存把频繁访问的内存数据放在更快的存储中一样,Skill 把频繁使用的工具调用知识预先组织好,避免每次都从头搜索和学习。
没有 Skill(每次从头探索): 任务: "导出用户数据为 CSV" Agent 第1次做:搜索工具 → 阅读文档 → 尝试执行 → 调试 → 成功 Agent 第2次做:同样的探索过程再来一遍 每次都消耗大量 token 在"重新发现"已知的方法 有 Skill(知识已缓存): 任务: "导出用户数据为 CSV" Agent 任意次做:匹配技能 → 加载 → 直接执行 1 次搜索 + 加载技能文本 ≈ 几百 token技能不一定需要人工编写。Agent 可以在首次完成新类型任务后,将探索过程中学到的工具组合自动整理成 Skill,下次遇到同类任务直接加载。这形成了一个自我优化的循环:Agent 使用工具越多,积累的 Skill 越丰富,未来的效率越高。
Skill 不是替代其他方式,而是在它们之上提供了一个缓存层。 底层仍然可以用搜索检索来匹配 Skill,用追加上下文来加载 Skill 内容,但搜索空间和加载量都被功能聚合大幅压缩了。
前三章讨论了 Agent 的上下文、工具加载和工具查找机制,其中第一章已经提到了任务隔离作为上下文管理的一种思路。本章从更上层的视角展开这个话题:Agent 的主循环围绕什么来设计?
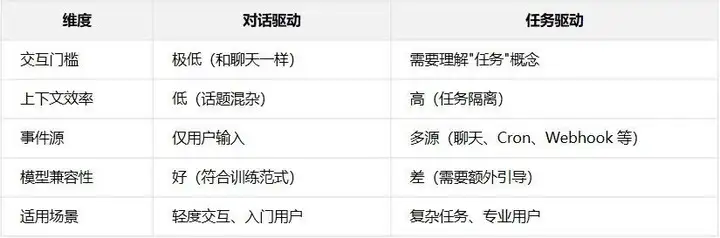
当前几乎所有 Agent 产品——OpenClaw、ChatGPT、Claude——都围绕对话框设计:用户在对话框里输入,Agent 在对话框里回复,对话框既是输入源、输出目标,也是维系上下文的容器。
这种模式的优势是交互门槛极低——和聊天没有区别,不需要理解任何抽象概念。但它也意味着 Agent 的一切行为都被包裹在对话交互中,上下文管理、工具调用、结果输出全部绑定在对话框这个载体上。
另一种思路是围绕任务来设计主循环:
对话驱动: ┌─────────────────────────────────────────────┐ │ 对话框 = Agent 的世界 │ │ │ │ 用户输入 → Agent 思考 → Agent 回复 │ │ 用户输入 → Agent 思考 → 调用工具 → 回复 │ │ │ │ 对话框既是输入源,也是输出目标, │ │ 更是维系上下文的容器 │ └─────────────────────────────────────────────┘ 任务驱动: ┌─────────────────────────────────────────────┐ │ Agent 主循环:感知→思考→行动 │ │ │ │ 感知: │ │ ├─ 聊天框(工具)→ 读取用户消息 │ │ ├─ Cron 定时器 → 触发定期检查 │ │ ├─ Webhook → 接收外部事件 │ │ └─ 自身推理 → fork 新子任务 │ │ │ │ 思考:(Agent 的核心输出) │ │ 分析任务 → 制定方案 → 选择工具 │ │ │ │ 行动: │ │ ├─ 控制台(工具)→ 执行本地操作 │ │ ├─ MCP(工具)→ 调用远程服务 │ │ ├─ 聊天框(工具)→ 回复用户 │ │ └─ 任务队列 → 创建后续任务 │ └─────────────────────────────────────────────┘在任务驱动设计中,聊天框被降格为一个工具——Agent 通过它读取用户消息,也通过它回复用户,和 execute(控制台)、MCP 远程调用没有本质区别。聊天框的特殊之处在于它同时充当输入源和输出工具,但它是 Agent 众多可调用能力中的一个,不是 Agent 运行的容器。
如果聊天框只是工具之一,Agent 的核心输出就不是对话回复,而是思考过程:
对话驱动:Agent 的输出 = 对话回复 ┌────────────────────────────────────────────┐ │ User: 帮我查一下线上报错 │ │ │ │ Assistant: 我来查一下。 │ ← 主要输出:对话文本 │ [调用工具: grep error.log] │ ← 附带动作 │ Assistant: 找到了,是数据库连接超时... │ ← 主要输出:对话文本 └────────────────────────────────────────────┘ 任务驱动:Agent 的输出 = 思考链 ┌────────────────────────────────────────────┐ │ 任务: 排查线上报错 │ │ │ │ 思考: 需要先查看错误日志 │ │ 行动: execute("grep -n ERROR app.log") │ │ 思考: 发现数据库连接超时,需要检查连接池配置 │ │ 行动: execute("cat config/db.yaml") │ │ 思考: 连接池 max_idle 设置过低, │ │ 需要告知用户结果 │ │ 行动: chat.send("问题定位到了:...") │ ← 回复用户只是其中一个动作 │ 任务完成 │ └────────────────────────────────────────────┘当思考过程成为核心输出时,Agent 的行为变得可观测——用户可以看到 Agent 在想什么、为什么选择某个工具、为什么放弃某个方案。当 Agent 犯错时,可以追溯到具体哪一步思考出了问题,这种可追溯性是 Agent 持续改进的基础。
Claude Code 在这个方向上做了有意义的尝试——它展示了思考过程、工具调用和执行结果。虽然目前的形式更像是 Agent 在自问自答,但核心理念值得借鉴:让思考过程成为一等公民。
任务驱动设计面临一个现实障碍:当前的大语言模型是以对话模式训练的。
- RLHF 优化的是"回复满意度" ——直接给出答案几乎总是比"我先调用工具"获得更高的评分,模型的本能是直接回答
- 工具调用是后天习得的 ——function calling 能力通过后期微调加入,没有明确触发信号时模型会 fallback 到对话模式
- 回复和工具调用是竞争关系 ——训练数据中"说话"的样本远多于"调用工具"的样本
要让 Agent 真正以"思考→工具调用"为主循环,不仅需要 system prompt 层面的引导,更需要模型厂商在训练阶段针对 agent 模式专门优化。从 GPT-4 到 Claude 到 Gemini,每一代模型的工具调用能力都在提升,但距离"模型天然就是任务执行器"的状态还有距离。
两种模式并非非此即彼。对话驱动可以作为任务驱动的前端——用户通过对话提交需求,系统自动将其转化为任务,在后台以任务驱动模式执行。关键是在架构层面保留任务隔离的能力,而不是将所有东西绑定在一个对话框上。
构建 Agent 的四个关键设计决策:
①上下文管理。
追加式上下文简单高效但成本与请求复杂度脱钩,压缩机制可以缓解膨胀但无法消除话题混杂。任务隔离从源头避免了这个问题,代价是需要额外机制处理跨任务的上下文关联。
②工具加载。
tools 字段保证了调用可靠性但与动态加载存在缓存冲突,工具描述移入 prompt 兼容了缓存但牺牲了格式保证,两者可以混合使用。本地能力用控制台、远程能力用 MCP 的组合是当前的务实选择。
③工具查找。
接口维度的查找在工具规模增长时效率下降,Skill 通过功能维度的聚合压缩了搜索空间,并形成了可复用的经验沉淀,但需要前期投入来构建和维护技能库。
④主循环设计。
对话驱动门槛低、模型兼容性好,任务驱动灵活、可观测性强,但受制于模型的对话训练倾向。两者可以结合——对话作为前端,任务作为后端。
这些决策之间并非独立。任务隔离影响上下文管理策略,工具加载方式决定了 Skill 的组织形式,主循环设计决定了 Agent 能从哪些来源获取任务。理解这些决策的关联和取舍,是设计一个高效 Agent 的前提。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/255658.html