
微信
ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo

语音转文本转换,也称为自动语音识别(ASR)或音频转录,是将口语音频转换为书面文本的过程,生成的文本称为转录稿。虽然基于 Transformer 的模型现已广泛应用于语音转文本转换,但对于较小或资源匮乏的语言,它们的性能仍然较差。
一个转录错误就可能完全改变句子的意思。对于某些语言,如芬兰语,拆分复合词或扭曲专有名词有时就足以使转录稿令人困惑、误导甚至无法使用。
在我们的项目中,我们处理一些少数民族语言(如芬兰语)的语音转文本转换。虽然最先进的模型,如 OpenAI 的 gpt-4o-transcribe 或开源的 Whisper 模型(如 WhisperX 系列)提供了令人印象深刻的语音转文本性能,但它们对少数民族语言的准确性仍然不如英语等主要语言。
最常见的语音转文本错误通常分为三类:
- 插入错误:模型添加了未被说出的额外词汇
- 删除错误:模型删除了被说出的词汇
- 替换错误:模型用错误的词汇替换正确的词汇
- 拼写错误:拼写错误、形态变化或由发音引起的扭曲
这些错误会降低可读性,有时甚至完全改变转录稿的含义。
微调是提高转录质量的一种方法。但它需要大量标记的音频和文本数据来训练更强的模型,而对于许多语言或领域来说,这些数据的可用性是一个挑战。
在本文中,我们将讨论如何评估语音转文本质量,识别模型产生的最常见的转录错误,开发基于大语言模型(LLM)的后转录音频转录增强方法,并评估该增强方法。
这种方法专注于提高芬兰语数据的语音转文本质量;然而,它可以很容易地定制为任何其他语言。
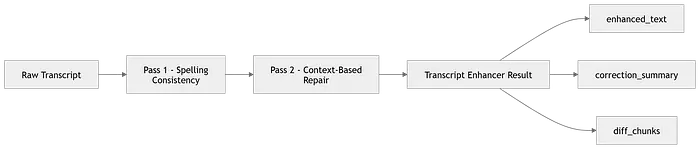
双通道基于大语言模型的增强方法的整体思路如下:
- 使用任何语音转文本模型生成转录稿
- 将转录稿发送到大语言模型进行拼写聚焦修复通道(通道1)
- 将结果发送到大语言模型进行第二个上下文感知修复通道(通道2)
这种方法显著提高了转录稿质量。虽然它最初是为芬兰语设计的,但可以通过更新双通道提示词来匹配特定语言的模式,从而适配其他语言。
转录增强流程使用双通道大语言模型方法(作者提供的图片)
这种方法是我们 GAIK 项目工具包的独立软件组件(参见此链接),可以通过以下方式安装:
pip install "gaik[enhance-transcript]"

GAIK 工具包 提供了一整套组件和指导,用于构建以知识为中心的生成式 AI 解决方案,从战略方向到可部署的实现(在此链接阅读更多内容)。
本文讨论的完整代码可在 GitHub 上找到。
让我们开始吧。
有两种方法可以评估语音转文本质量。第一种方法是主观的,需要手动比较转录文本(称为假设)与语音对应的正确文本(称为参考)。
另一种方法是客观的,使用质量指标比较假设和参考转录稿。我们将在本文中使用这种方法,因为它提供了一种一致且可测量的方式来比较转录稿质量。
语音转文本质量最常见的客观指标是词错误率(WER),它衡量假设转录稿中与参考转录稿不同的词汇数量。
WER 基于替换、删除和插入错误,计算方法如下:
WER = (S + D + I) / N * 100% 其中:
S= 替换数D= 删除数I= 插入数N= 参考转录稿中的总词数
WER 越低越好。
除了上述指标外,我还使用了拼写错误率,因为许多语音转文本错误并非完全错误的词汇;它们是接近正确的拼写。例如,“hammas” 与 “hamas”,以及 “Vastuuhenkilö” 与 “Vastuu henkilö”。这些基本上是替换错误,但它们比不相关的替换更接近预期的词汇。换句话说,每个拼写错误都是替换错误,但并非每个替换错误都是拼写错误。
为了测量这一点,我使用了莱文斯坦距离(Levenshtein distance),它是衡量两个字符串之间相似性的指标。较小的莱文斯坦距离意味着两个词更相似。如果转录稿词元和参考词元之间的归一化距离小于或等于 0.4,我将其视为类似拼写的替换。
莱文斯坦距离和归一化距离的计算方法如下:
莱文斯坦距离 = min(插入数 + 删除数 + 替换数) 归一化距离 = 莱文斯坦距离 / 参考词元长度 我使用 Python 库 jiwer 来计算 WER、替换率、删除率和插入率。基于莱文斯坦距离的拼写相似性使用 Python 库 rapidfuzz 计算。
side_by_side_compare.py 脚本(参见 GitHub 仓库)对参考和假设文本进行归一化,使用 jiwer 逐词对齐,并计算 WER、替换率、删除率、插入率以及单独的拼写错误率等指标。
下图展示了如何检测和突出显示上述错误。请注意,某些错误可能既是替换错误又是拼写错误。

真实文本(REF)和转录文本(HYP)并排对比的片段(作者提供的图片)
在开发基于大语言模型的转录错误修复方法之前,我分析了最常见的语音转文本错误。
请注意,此分析侧重于芬兰语音频记录;然而,相同的方法可以应用于任何其他语言。
为此,我分析了多个芬兰语音频记录的参考转录稿和语音转文本假设(通过 side_by_side_compare.py 生成)的并排比较。我还使用大语言模型审查这些参考-假设对,并识别最常见的错误模式。
我在芬兰语转录中发现了以下问题:
- 错误的品牌名称和专有名词
- 接近正确的人名变体
- 错误拆分的复合词
- 破损或不一致的连字符
- 扭曲的外来词
- 芬兰语形态错误
- 拼写错误
- 相同术语使用不一致
- 缺失的词汇
- 额外插入的词汇
- 错误的词汇替换
其中一些错误不会影响可读性和/或准确性。例如,缺失短功能词或添加填充词通常不会非常大地改变句子的整体含义。
其他错误可能会影响可读性和准确性。拆分的复合词、扭曲的名称和错误的替换可能使句子令人困惑或完全改变其含义。
大多数频繁的语音转文本问题可以通过基于大语言模型的后转录修复方法解决。大语言模型可以利用其对芬兰语拼写、词汇、形态和上下文的了解进行有针对性的更正。
我使用此分析设计了一种基于大语言模型的双通道转录稿增强方法。
这种方法在不添加任何额外信息、不删除重要信息和不重新生成完整转录稿的情况下对转录稿进行有针对性的修复。有针对性的修复对于保持转录稿的正确部分完整(减少重新生成产生的幻觉可能性),同时只关注需要更正的部分非常重要。
TranscriptEnhancer 软件组件 将这种方法实现为双通道(提示词)管道。它以原始转录稿(由语音转文本模型生成)作为输入,并生成增强版本以及包含所有更改详细信息的可选结构化输出。
在这些实验中,我使用 OpenAI 的 gpt-5.4 模型进行转录稿增强。然而,该方法是模型无关的,其他模型也应该以相同的方式工作。
在 TranscriptEnhancer 中,通道1(enhance_transcript.py 中的 PASS1_SYSTEM_PROMPT)专注于更正拼写并在整个转录稿中保持一致性。它不考虑句子结构或语法。它查看单个词元并对它们进行归一化。
通道1的主要目标是:
- 更正拼写错误
- 归一化重复术语(使它们一致)
- 修复专有名词的大小写
- 修复明显的复合词分词问题
- 完全按原样保留数字
通道1保持严格的字数,不添加或删除词汇,因为激进的改写可能会引入幻觉。我发现保持编辑最小化使输出更加安全。
通道1中最重要的规则是:
- 绝不删除词汇
- 保持标点和词序不变
- 只进行局部更正
- 除非预期拼写明显,否则保留专有名称
- 不重新解释数字
- 如果不确定,保持原样不变
完整的通道1提示词(PASS1_SYSTEM_PROMPT)请参阅 GAIK 工具包的 enhance_transcript.py 软件组件。
通道2(enhance_transcript.py 中的 PASS2_SYSTEM_PROMPT)接收通道1的输出并修复需要句子级上下文的部分。与按词元工作的通道1不同,通道2跨周围的从句阅读以决定是否需要修复。
通道2的主要目标是:
- 合并拆分的复合词
- 拆分错误合并的词
- 修复连字符
- 插入缺失的短功能词
- 提高整个转录稿的一致性
我也在通道2中保持严格的规则。我不想让模型将转录稿改写成精美的书面芬兰语。我希望它忠实于口语芬兰语,因为如果转录稿变得过于精美,它就不再像口语了。
我在通道2中包含了一个插入预算。模型每100个词的转录稿最多可以插入2个词。这有助于降低产生幻觉或不必要的添加的风险。
通道2中最重要的规则是:
- 保留口语芬兰语
- 保持编辑小而局部
- 绝不改写整个句子
- 只在语法强烈需要时才插入短功能词
- 绝不编造名称、品牌或事实
- 不确定的情况保持原样不变
完整的通道2提示词(PASS2_SYSTEM_PROMPT)请参阅 GAIK 工具包的 enhance_transcript.py 软件组件。
为了使双通道工作流可重用,我将其打包成一个名为 TranscriptEnhancer 的类,它将双通道大语言模型增强管道封装到一个可重用的对象中。
enhancer = TranscriptEnhancer( api_config=config, use_azure=False, # 使用标准 OpenAI API 密钥
)
enhance_text() 方法从字符串中读取转录稿,enhance_file() 方法从文本文件中读取转录稿。
当调用 TranscriptEnhancer 类的 enhance_text() 或 enhance_file() 方法时,转录稿会经过通道1和通道2。两个通道完成后,类返回一个包含原始转录稿和增强版本的 TranscriptEnhancerResult 对象。
该类还接受一些可选参数,使分析更容易。如果 generate_summary=True,组件会计算增强过程中进行了多少次插入、删除和替换。如果 diff_chunks=True,它会返回转录稿中哪些部分发生更改的列表。两种方法都使用 SequenceMatcher 并在两个通道完成后的最终结果上操作。
可以通过 additional_instructions 传递额外指令,这些指令会附加到第二通道提示词中。此选项可用于需要额外规则的特定领域转录稿,例如保留公司名称或产品术语。
最终结果存储在 Pydantic 模型中,可以使用 model_dump() 或 model_dump_json() 导出为 Python 字典或 JSON 对象。
有关
TranscriptEnhancerResult 类的完整实现,请参阅 GAIK 工具包的 enhance_transcript.py 脚本。
以下是导入、初始化和使用 TranscriptEnhancer 对象的示例。此示例存在于 GitHub 仓库 的 enhanced_transcript_example.py 中。TranscriptEnhancer 类作为 GAIK 工具包的软件组件导入。从 GAIK 工具包的 config.py 导入的 get_openai_config 方法配置并创建 OpenAI 和 Azure 客户端。相同的配置脚本还设置了大语言模型名称(在本例中为 gpt-5.4)。当我们使用 OpenAI 的 API 密钥时,我们设置 use_azure = False。
from gaik.software_components.enhance_transcript import ( TranscriptEnhancer, get_openai_config,
)
config = get_openai_config(use_azure=False) enhancer = TranscriptEnhancer(api_config=config)
从那里,我们可以增强原始字符串(enhancer.enhance_text)
或文本文件(enhancer.enhance_file)。
result = enhancer.enhance_file(
transcript_file, generate_summary=True, diff_chunks=True, additional_instructions=( "完全按原样保留所有公司名称。" ),
)
当 generate_summary=True 时,结果包含更改了多少词以及以何种方式更改的详细信息。
CorrectionSummary(total_changes=3, insertions=0, deletions=0, substitutions=3) 当 diff_chunks=True 时,结果包含原始和增强转录稿之间所有修改部分的列表。
result = enhancer.enhance_text( transcript_text="Hei, 23.8.2025 Vetämän Kaltenbach-sahalla viereinen turva-aita toimii yleisenä liinatelineenä. Vastuu henkilö otti havainnon käsittelyyn.", diff_chunks=True,
) for chunk in result.diff_chunks:
print(chunk) # DiffChunk(kind='substitute', original='Vetämän', corrected='Vetämön') # DiffChunk(kind='substitute', original='Vastuu henkilö', corrected='Vastuuhenkilö')
每个 DiffChunk 都有一个 kind 属性,值为 substitute、insert 或 delete。这可用于准确检查更改了什么、将更正输入审查 UI,或分析大批量转录稿的增强行为。
TranscriptEnhancer 返回一个 TranscriptEnhancerResult。完整结构使用 model_dump_json() 序列化:
{ "original_text": "Hei, 23.8.2025 Vetämän Kaltenbach-sahalla viereinen turva-aita toimii yleisenä liinatelineenä. Vastuu henkilö otti havainnon käsittelyyn.", "enhanced_text": "Hei, 23.8.2025 Vetämön Kaltenbach-sahalla viereinen turva-aita toimii yleisenä liinatelineenä. Vastuuhenkilö otti havainnon käsittelyyn.", "source_file": "Sample.txt", "correction_summary": { "total_changes": 3, "insertions": 0, "deletions": 1, "substitutions": 2 }, "diff_chunks": [ {"kind": "substitute", "original": "Vetämän", "corrected": "Vetämön"}, {"kind": "substitute", "original": "Vastuu henkilö", "corrected": "Vastuuhenkilö"} ]
}
为了评估转录稿增强方法的有效性,我使用了前面讨论的相同指标:WER、拼写错误率以及插入率、删除率和替换率。
我使用不同的语音转文本模型生成了15个转录稿。每个语音转文本模型为同一组15个音频文件生成转录稿。对于每个音频文件,我还通过让芬兰语母语者听录音并转录来手动创建参考转录稿。
用于从不同语音转文本模型生成转录稿的代码可在 GitHub 仓库的 transcribers 文件夹中找到。
每个转录稿然后通过 GAIK 工具包的转录稿增强组件进行增强。
增强版本与原始语音转文本输出和手动创建的参考转录稿进行比较。比较使用 eval_enhanced.py 脚本(参见 GitHub 仓库)进行。此脚本读取参考转录稿、原始假设及其增强版本。然后使用 jiwer 进行词对齐和使用 rapidfuzz 进行基于莱文斯坦距离的拼写错误检测,计算 WER、拼写错误率以及插入率、删除率和替换率。
结果汇总每个语音转文本模型的所有转录稿。
下图显示了增强前后的整体 WER。
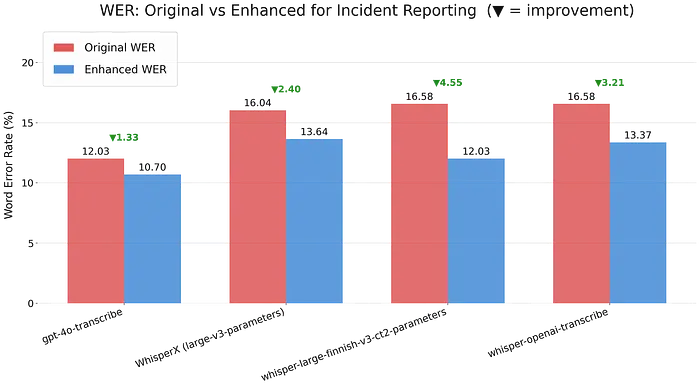
结果显示所有测试模型的 WER 都有所降低。最大的改进出现在芬兰语微调的 WhisperX 模型 whisper-large-finnish-v3-ct2-parameters 中。OpenAI 的 gpt-4o-transcribe,其 WER 已经最低,仍然从增强方法中受益,平均 WER 降低了 1.33个百分点。
下表细分了 WER 的各个组成部分,包括替换率、删除率、插入率和拼写错误率。
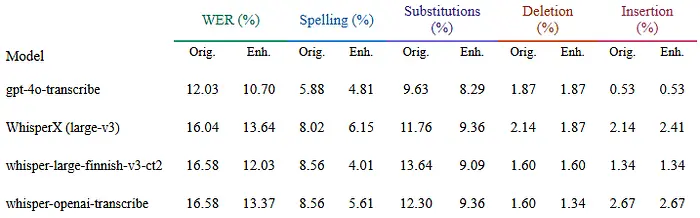
由于增强提示词中的严格约束,删除率和插入率要么保持不变,要么仅略有降低(除了 WhisperX large-v3 的略微增加)。通道1禁止任何词的添加或删除,通道2强制执行严格的插入预算,每100个词最多插入两个词。假设中已经存在的删除(语音转文本模型在转录过程中完全遗漏的词)无法通过后处理单独恢复,因为在该阶段没有可用的音频信息来重建所说的内容。
最显著的改进是在拼写和替换错误方面。由于通道1的直接作用,所有模型的拼写错误率都大幅下降,通道1针对接近正确的词元、不一致的术语拼写和大小写错误。替换率也遵循类似的模式,各模型降低了2-4个百分点。这与通道2修复复合词合并、连字符修复和外来词归一化的性质一致。
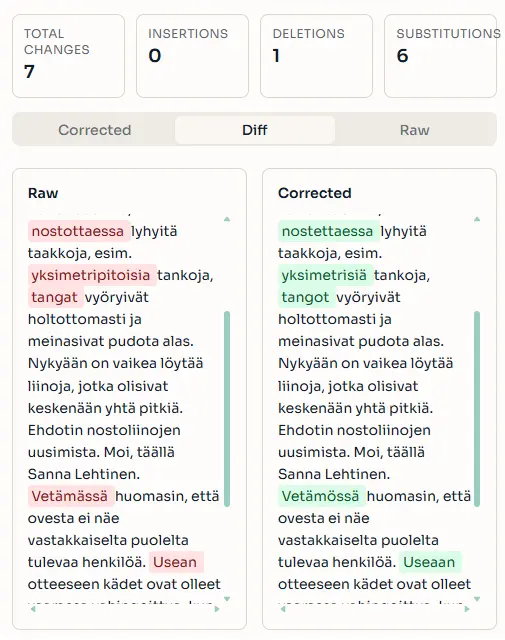
下图显示了原始和增强转录稿的并排差异视图。修改的词元在原始转录稿中以红色突出显示,在更正版本中以绿色突出显示。在此示例中,更正是拼写和形态修复,而周围的文本完全保持不变。
带有文档的完整源代码可在 GitHub 上找到。
TranscriptEnhancer 软件组件目前专为芬兰语音设计,其中 PASS1_SYSTEM_PROMPT 和 PASS2_SYSTEM_PROMPT 编码了芬兰语特定的行为。然而,拼写规则、词修复逻辑、口语形式保留列表、功能词插入白名单和语法安全规则都可以修改为任何其他语言。
要将组件适配为不同语言,唯一需要更改的部分是提示词。以下是可以完成的方法:
- 通道1: 将芬兰语正字法规则和一致性归一化指南替换为目标语言的等效规则。应用相同的方法来识别目标语言中反复出现的性能问题(错误)。更新任何特定于语言的示例。
- 通道2: 将功能词白名单替换为目标语言的等效集合。更新复合词处理规则、口语形式保留指令和语法安全规则。
PASS1_SYSTEM_PROMPT 和 PASS2_SYSTEM_PROMPT 从包中导出,因此可以在不分叉完整实现的情况下读取、修改并传递回作为新语言变体的基础。
原文链接:How I Improved Speech-to-Text Accuracy
汇智网翻译整理,转载请标明出处
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/255579.html