

注:感谢特工宇宙战略顾问 @庄明浩 老师推荐。
原文:https://substack.com/inbox/post/
在这篇文章里,我想介绍编码智能体(Coding agents)以及 Agent harnesses 的整体设计:它们是什么、怎么运作,以及各个零件在实践中怎么拼到一起。
更广泛地说,Agent 之所以成了一个重要话题,是因为最近很多可落地 LLM 系统的进步,并不只是模型变强了,还在于我们怎么用模型。
在很多真实应用里,工程化的系统(比如工具使用、上下文管理、记忆)和模型本身一样关键。这也解释了:为什么像 Claude Code 或 Codex 这样的系统,用起来会明显比把同一个模型塞进普通聊天框更能干。
在这篇文章中,我把编码 Agent 的六个主要构件拆开讲清楚。
文章首发于观猹:https://watcha.cn/discuss/5900?ts=1775478026185&,欢迎来观猹(watcha.cn)上查看更多 AI 资讯/教程等内容。
你大概已经熟悉 Claude Code 或 Codex CLI。铺垫一下:它们本质上是具备 Agent 特性(agentic)的编码工具——在一个 LLM 外面包了一层应用层(也叫 agentic harness),让它在做编码任务时更顺手、表现更稳定。
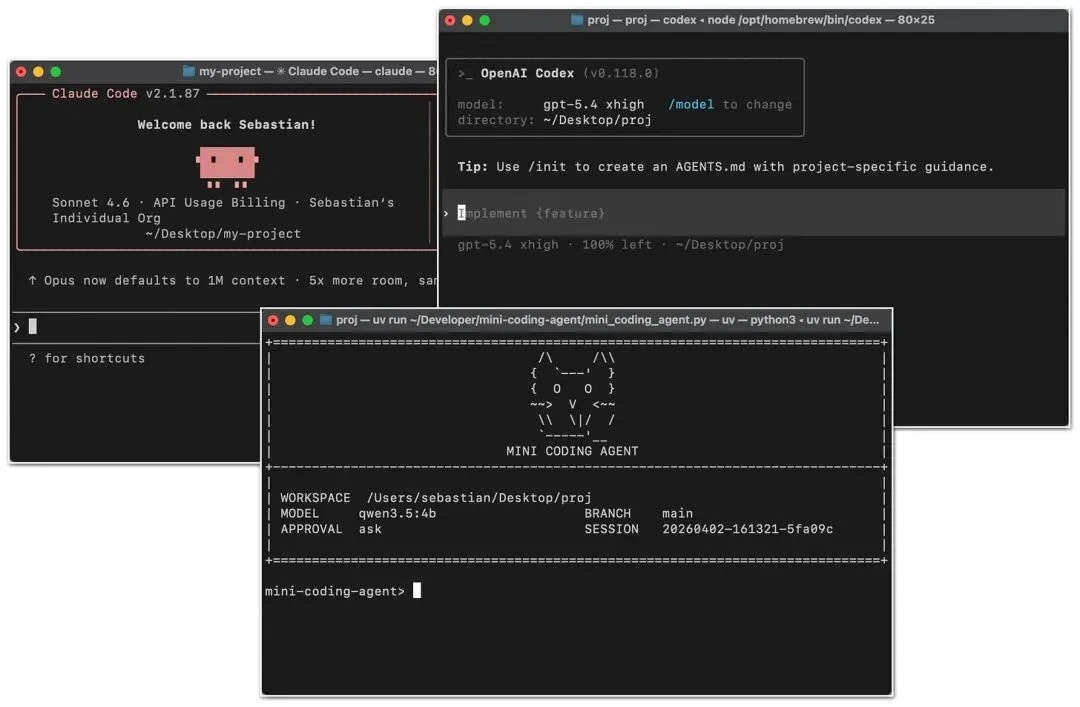
编码 Agent 是为软件工程场景专门设计的:关键不只是选了哪个模型,还有周边系统怎么做——包括仓库上下文(repo context)、工具设计、提示词缓存(prompt-cache)的稳定性、记忆,以及长会话的连续性。
这个区分很重要,因为大家聊 LLM 的编码能力时,经常把模型本身、推理行为、以及具体 Agent 产品混成一回事。但在进入编码 Agent 的细节之前,我先简单补一点背景:LLM、推理模型(reasoning models)与 Agent 之间到底是什么关系。
LLM 是核心的下一个 token 预测模型。推理模型本质上还是 LLM,但通常会通过训练和/或提示词,让它在推理时投入更多推理计算,用于中间推理、校验、或者在多个候选答案之间做搜索。
Agent 则是在模型之上的一层,你可以把它理解成围绕模型的一个控制循环(control loop)。通常给定一个目标,Agent 层(或 harness)会决定:下一步该看什么、调用什么工具、如何更新自身状态、何时停止等。
粗略类比一下:LLM 是发动机;推理模型是“加大马力的发动机”(更强,但更贵);而 Agent harness 是帮我们把这个发动机用得更好的整套车架/传动系统。
这个比喻当然不完美,因为我们也能把普通 LLM 或推理 LLM 单独拿来用(比如在聊天界面或 Python 里),但希望能传达核心意思。

换句话说:Agent 是一个在环境中反复调用模型的系统。
所以,简单总结如下:
- LLM:原始模型
- 推理模型:经过优化的 LLM,更倾向输出中间推理轨迹,并更会自我校验
- Agent:一个循环系统:模型 + 工具 + 记忆 + 环境反馈
- Agent harness:围绕 Agent 的软件脚手架,负责上下文、工具、提示词、状态与控制流管理
- Coding harness:Agent harness 的特例;针对软件工程的任务型 harness,管理代码上下文、工具执行与迭代反馈
如上所列,在 Agent 与编码工具的语境里,经常会出现 Agent harness 和 Coding harness 这两个术语。Coding harness 是围绕模型的软件脚手架,帮助它高效地写/改代码;而 Agent harness 概念更宽,不一定只做编码(比如 OpenClaw)。Codex 和 Claude Code 可以看作 Coding harness。
总之:更好的 LLM 是推理模型的更好地基(推理模型往往需要额外训练),而 harness 能把推理模型的能力榨出来更多。
当然,LLM 和推理模型即使不加 harness,也能单独解决编码任务。但编码工作不只是「下一个 token 生成」。很大一部分其实是:在仓库里导航、搜索、查函数定义、应用 diff、跑测试、看报错、以及把所有相关信息都维持在可用上下文里。(写代码的人都知道这很费脑子,所以我们编码时不喜欢被打断 :)))
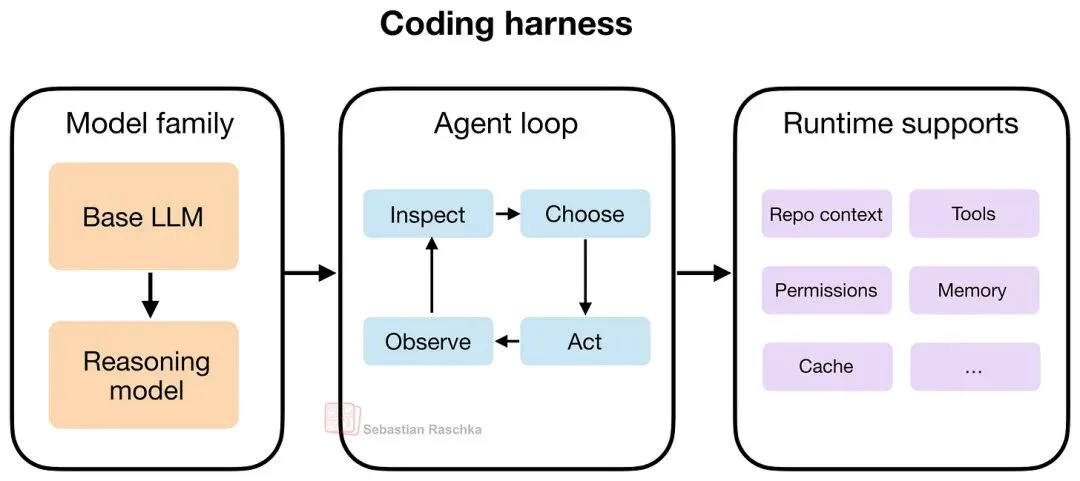
这里的要点是:好的 Coding harness 能让推理模型和非推理模型在普通聊天框里看起来“没那么强”的能力,在实际体验上显著变强——因为它更擅长上下文管理等周边工作。
上一节提到,当我们说 harness,通常指的是模型周边的软件层:它负责拼装提示词、暴露工具、跟踪文件状态、应用编辑、运行命令、管理权限、缓存稳定前缀、存储记忆……等等。
如今在用 LLM 时,相比直接提示模型或用网页聊天 UI(更像“带文件上传的聊天”),这一层软件几乎决定了大部分用户体验。
在我看来,现阶段各家 LLM 的原始模型能力其实差不多(比如 GPT-5.4、Opus 4.6、GLM-5 之类),因此 harness 往往是让某个 LLM 在特定任务里更好用的关键差异点。
这是我的推测:如果把最新、最强的一批开源模型(例如 GLM-5)塞进类似的 harness 里,它很可能能在 Codex 里做到接近 GPT-5.4 的水平,或在 Claude Code 里做到接近 Claude Opus 4.6 的水平。当然,针对 harness 的后训练(post-training)通常也会有帮助。比如 OpenAI 过去就长期维护 GPT-5.3 和 GPT-5.3-Codex 这类不同变体。
下面我会更具体地讨论 Coding harness 的核心组件。我会以我的 Mini Coding Agent 为例:https://github.com/rasbt/mini-coding-agent。
备注:本文为了简化表述,会把 Coding agent 和 Coding harness 有点混着用。(严格说:Agent 是模型驱动的决策循环;harness 是提供上下文、工具与执行支持的周边软件脚手架。)
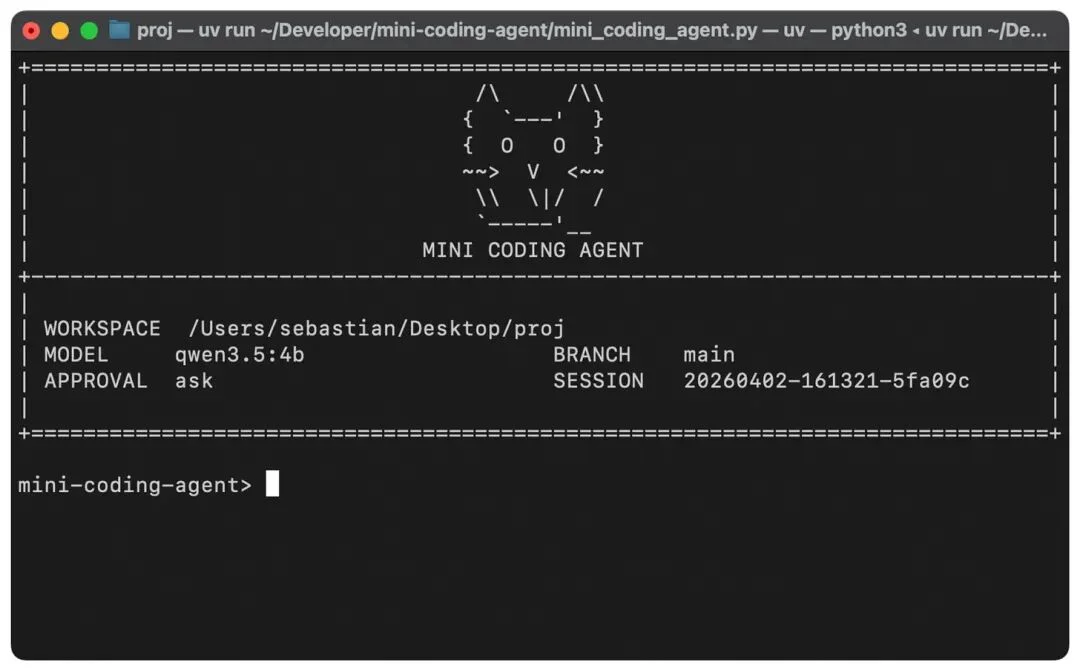
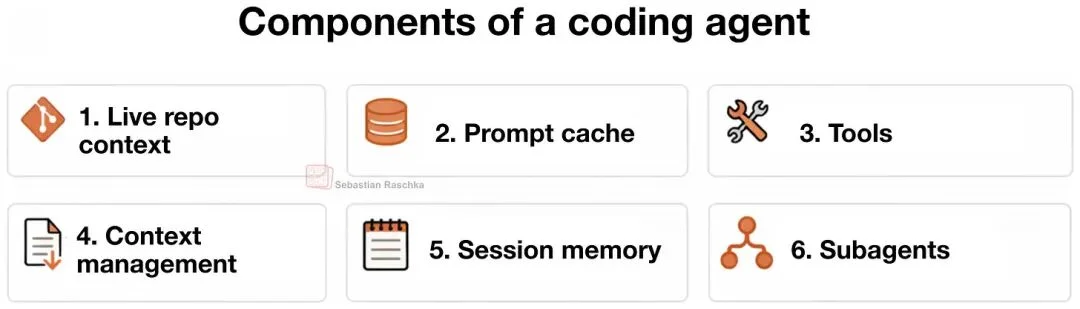
下面是编码 Agent 的六个主要组件。你也可以直接看我这个“最小但完整可用”的 Mini Coding Agent 源码(纯 Python 实现),里面用注释标了这六块:
# Six Agent Components #
# 1) Live Repo Context -> WorkspaceContext
# 2) Prompt Shape And Cache Reuse -> build_prefix, memory_text, prompt
# 3) Structured Tools, Validation, And Permissions -> build_tools, run_tool, validatetool, approve, parse, path, tool*
# 4) Context Reduction And Output Management -> clip, history_text
# 5) Transcripts, Memory, And Resumption -> SessionStore, record, note_tool, ask, reset
# 6) Delegation And Bounded Subagents -> tool_delegate
1. 实时仓库上下文(Live Repo Context)
这可能是最显而易见的组件,但也往往是最重要的之一。
当用户说“修一下测试”或“实现 xyz”时,模型应该知道:自己是否在一个 Git 仓库里、当前在哪个分支、有哪些项目文档可能包含指令等。
因为这些信息经常会影响正确行动。比如“修一下测试”并不是一个自洽的指令;如果 Agent 看到了 AGENTS.md 或项目 README,它可能会知道该跑哪条测试命令;如果它知道仓库根目录和目录结构,就能去正确的位置找信息,而不是瞎猜。
另外,Git 分支、状态、提交记录也能提供更多上下文:现在有哪些改动正在进行、注意力应该放在哪一块等。
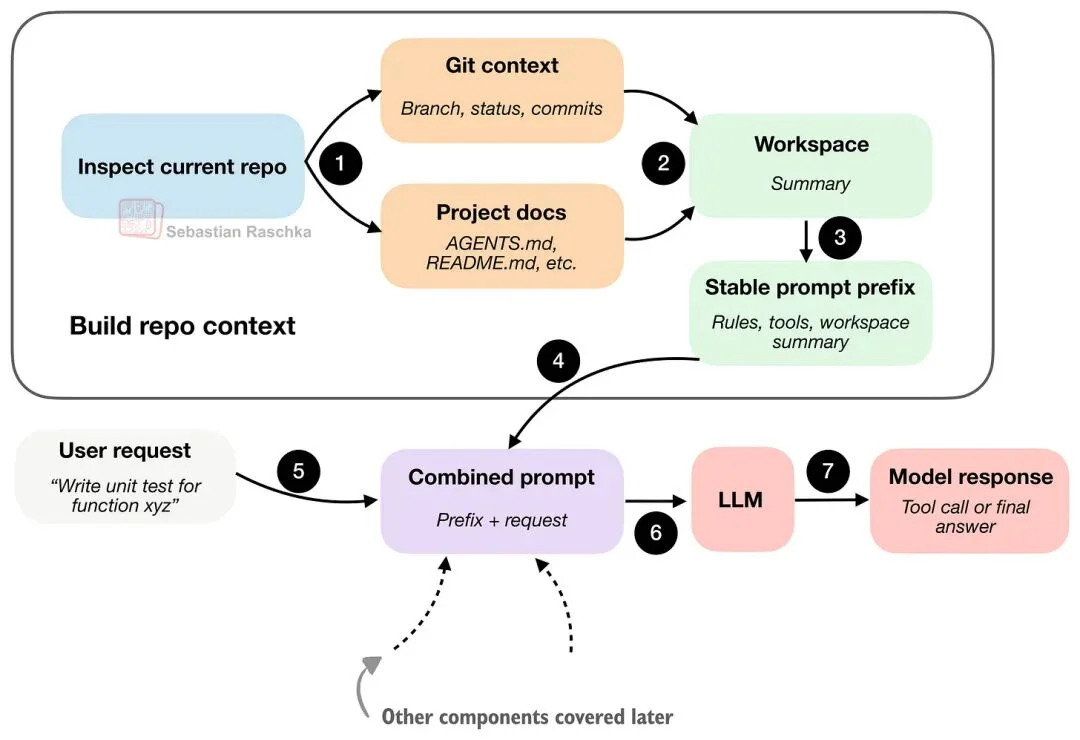
这里的要点是:编码 Agent 会在真正开始干活前,先收集信息。这样它不会每次接到新提示时都从零开始、毫无上下文。
2. 提示词形状与缓存复用(Prompt Shape And Cache Reuse)
当 Agent 有了仓库视图之后,下一个问题是:如何把这些信息喂给模型。上一张图展示了一个简化版本(“合并提示词:prefix + request”),但在实践中,如果每次用户提问都把 workspace 摘要重新拼一次、重新处理一次,其实挺浪费的。
也就是说:编码会话是重复的;Agent 规则通常不变;工具描述通常也不变;甚至 workspace 摘要通常也大体不变。每一轮主要变化往往是:最新的用户请求、最近的对话记录(transcript),以及可能的短期记忆。
“聪明”的运行时(runtime)不会每回合都把所有东西当成一大坨提示词从头构建,如下图所示。
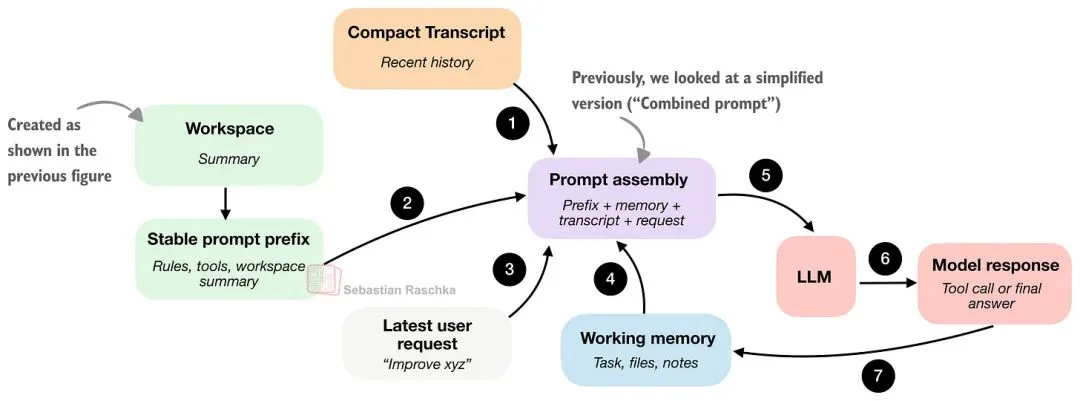
与第 1 节的区别在于:第 1 节关心的是收集仓库事实;这里关心的是如何把这些事实打包并高效缓存,以便反复调用模型。
图里的“稳定(Stable)提示词前缀”意味着那部分信息变化不大:通常包含通用指令、工具描述、workspace 摘要等。如果没有重要变化,我们不想每次交互都浪费算力去重建它。
而其他部分更新更频繁(通常每回合都会变):包括短期记忆、最近的对话记录,以及最新的用户请求。
简而言之:所谓缓存“稳定提示词前缀”,就是一个聪明的 runtime 会尽量复用那部分内容。
3. 工具访问与使用(Tool Access and Use)
工具访问/工具使用,是“这不再只是聊天,而开始像一个 Agent” 的分水岭。
普通模型可以用文字建议你去跑什么命令;但把 LLM 放进 Coding harness 后,它应该做得更“窄”但更有用:能直接执行命令并把结果取回来(而不是我们手动执行再把结果贴回聊天框)。
不过,harness 通常不会让模型随意编造任意语法;它会提供一个预先定义好的、允许调用的“命名工具列表”,这些工具的输入清晰、边界明确。(当然,也可以把 Python 的 subprocess.call 作为其中一个工具,让 Agent 能跑广泛的 shell 命令。)
工具使用的流程大致如下图:
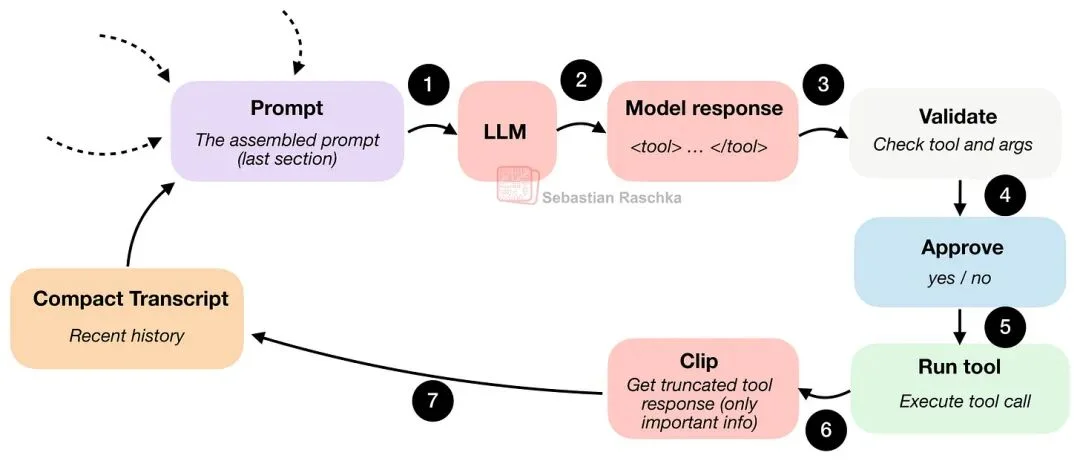
为了更直观,下面是使用我的 Mini Coding Agent 时,用户通常能看到的交互样子。(它没 Claude Code 或 Codex 那么漂亮,因为它非常极简:纯 Python、无外部依赖。)
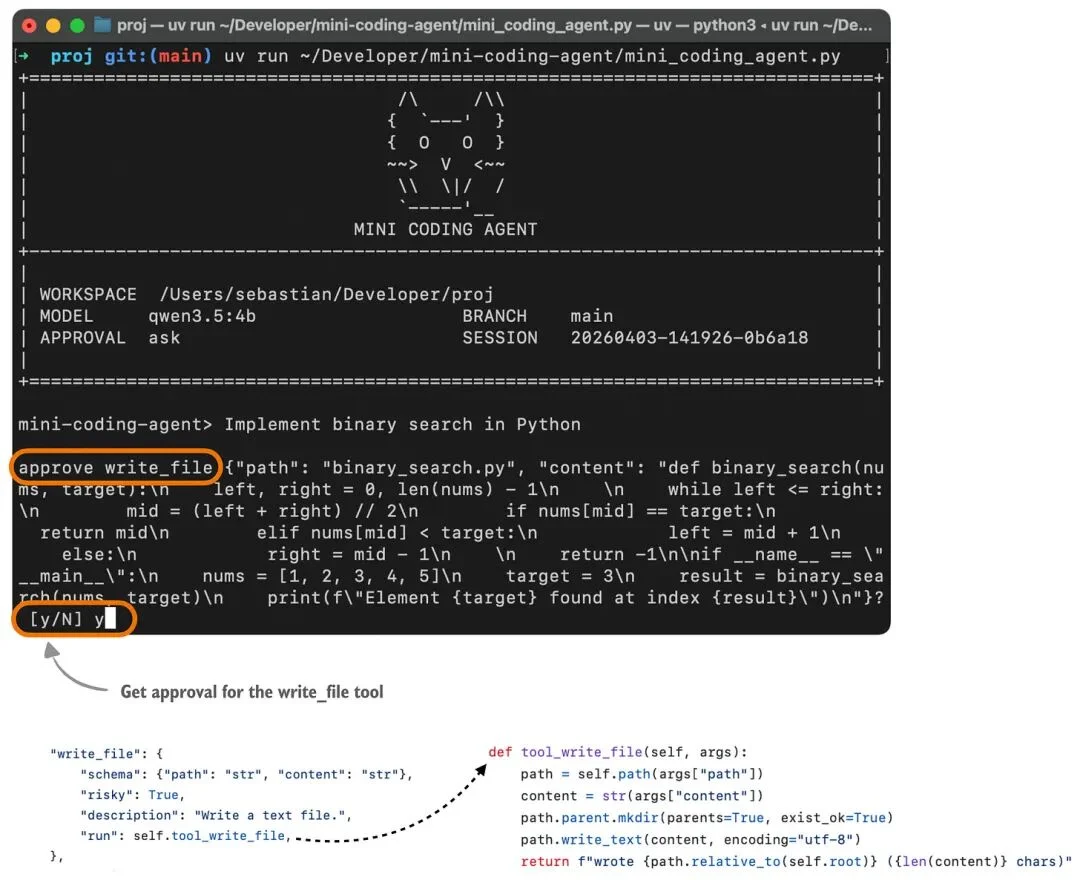
在这里,模型必须选择一个 harness 能识别的动作,比如:列目录、读文件、搜索、跑 shell 命令、写文件等;同时还要把参数按 harness 可校验的格式给出来。
所以当模型请求做某件事时,runtime 就可以停下来做一系列程序化检查,例如:
- “这是已知工具吗?”
- “参数合法吗?”
- “这需要用户审批吗?”
- “请求访问的路径是否在 workspace 内?”
只有这些检查通过,工具调用才会真正执行。
运行编码 Agent 当然有风险,但这些 harness 检查也会提高可靠性:避免模型执行完全任意的命令。
此外,除了拒绝格式错误的动作、做审批门禁(approval gating),还可以通过检查文件路径,把文件访问限制在仓库内部。
某种意义上,harness 给了模型更少的自由,但同时也让它更可用、更可靠。
4. 尽量减少上下文膨胀(Minimizing Context Bloat)
“上下文膨胀(context bloat)”不是编码 Agent 独有的问题,是所有 LLM 系统都会遇到的。确实,现在 LLM 支持的上下文越来越长,但长上下文仍然昂贵,也会带来额外噪声(如果塞了很多不相关信息)。
在多轮对话里,编码 Agent 比普通 LLM 更容易遭遇上下文膨胀:反复读文件、工具输出很长、日志很多等等。
如果 runtime 把这些都原封不动保留,它很快就会把可用的上下文 token 用光。所以,一个好的 Coding harness 通常在处理上下文膨胀方面会更讲究,不只是像普通聊天 UI 那样简单截断或总结。
概念上,编码 Agent 的上下文压缩(compaction)可以像下图这样工作。
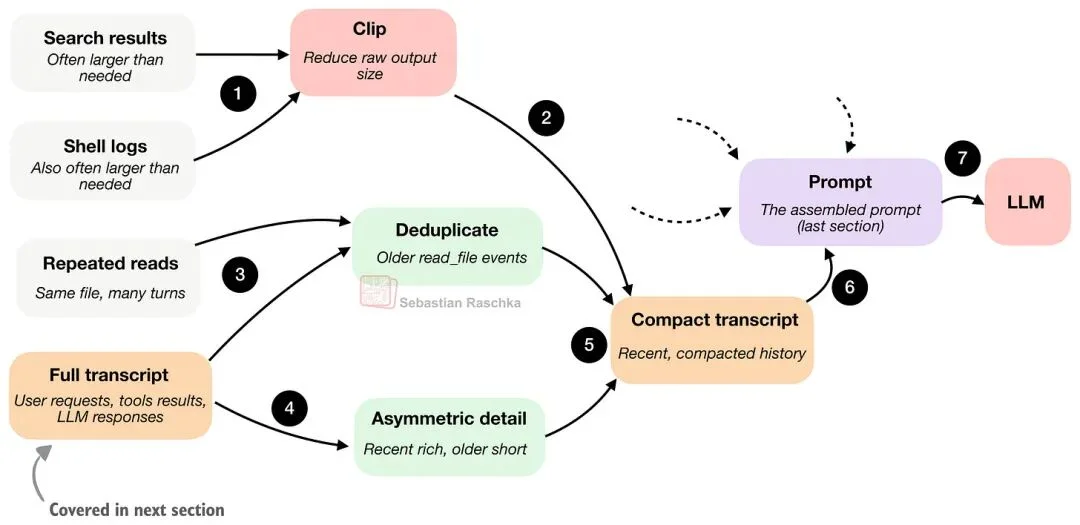
一个最小的 harness 至少会用两种压缩策略来管理这个问题:
- Clipping(裁剪):缩短长文档片段、大工具输出、记忆笔记、对话条目。也就是:避免某一段文本因为太啰嗦就霸占了整个提示词预算。
- Transcript reduction / summarization(对话记录压缩/总结):把完整会话历史(下一节会讲更多)变成更小、可塞进 Prompt 的摘要。
这里一个关键技巧是:让最近发生的事保留更丰富的细节,因为它们更可能影响当前步骤;而更早的事件则更激进地压缩,因为它们往往更不相关。
此外,还会对早期的文件读取做去重,避免模型因为之前多次读过同一个文件,就在后续每次都重复看到一模一样的内容。
总体上我觉得这是一块“被低估但很重要、而且很无聊”的编码 Agent 设计:很多你以为的“模型质量”,其实是“上下文质量”。
5. 结构化会话记忆(Structured Session Memory)
这一节“结构化会话记忆”,关注的是历史在存储层面的结构:Agent 会把什么长期保留下来,当作永久记录?
所以这里强调的是:runtime 会保留更完整的 transcript 作为耐久状态,同时还有一层更轻量的“记忆层(memory layer)”——它更小,而且会被修改/压实,而不是只追加不整理。
总结一下:编码 Agent 至少会把状态分成两层:
- 工作记忆(working memory):Agent 明确维护的一小段“蒸馏态”信息
- 完整 transcript(全量对话记录):包含所有用户请求、工具输出、LLM 回复
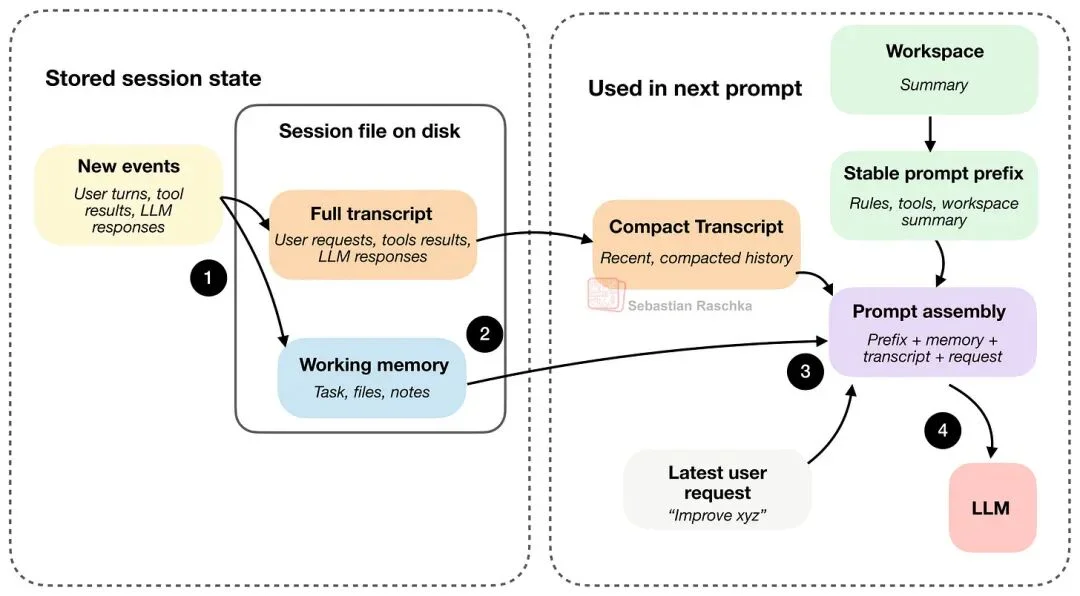
上图展示了通常会存成磁盘 JSON 文件的两份会话文件:完整 transcript 与工作记忆。如前所述:完整 transcript 保存全历史,并且关闭 Agent 后能恢复继续;工作记忆是当前最重要信息的蒸馏版,和紧凑 transcript 有点关系。
但紧凑 transcript 和工作记忆的职责略有不同:
- 紧凑 transcript:用于重建 prompt。它的工作是给模型一份“压缩过的最近历史视图”,这样模型能接着聊下去,而不必每回合都看全量 transcript。
- 工作记忆:更偏向任务连续性。它的工作是保持一段小而明确维护的摘要,记录跨回合真正重要的东西,比如当前任务、关键文件、近期笔记等。
按照上图的第 4 步,最新的用户请求、LLM 回复与工具输出,会在下一轮里被记录成一个“新事件”,同时写入全量 transcript 和工作记忆中(图里为了不太乱没画出来)。
6. 通过(有边界的)子 Agent 做任务委派(Delegation With (Bounded) Subagents)
当一个 Agent 具备工具与状态后,下一个很有用的能力就是:委派(delegation)。
原因是:它允许我们把某些工作并行化,拆成子任务交给子 Agent(subagents),从而加速主任务。比如主 Agent 正在做一件事,但还需要一个旁支答案:某个符号在哪个文件定义、某个配置写了什么、为什么某个测试失败等。把这类工作拆出去给一个有边界的子任务,会比让一个循环同时扛所有工作线更好。
子 Agent 只有在继承了足够上下文时才真的有用。但如果不做约束,就可能出现多个 Agent 重复劳动、同时改同一批文件、或不断递归再起子 Agent ……等问题。
所以真正棘手的设计点不只是“怎么起一个子 Agent”,还包括“怎么给它上边界(bind one)” :).
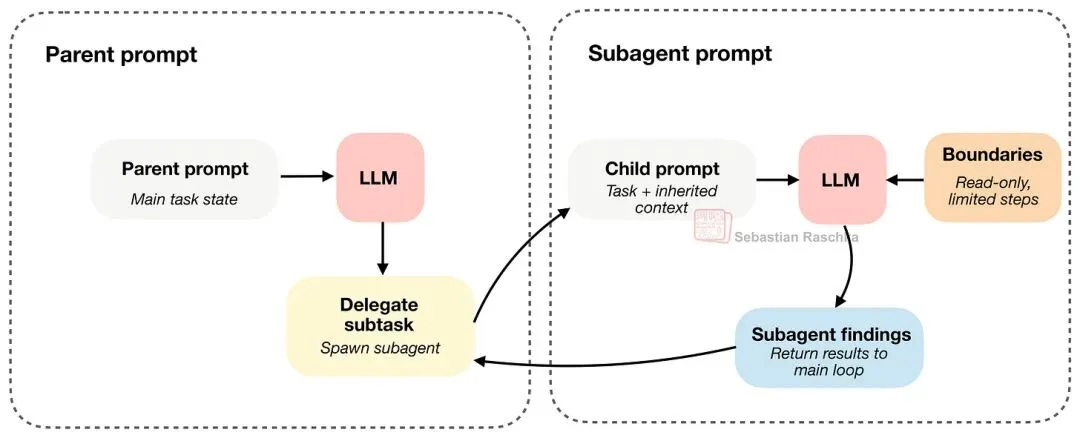
这里的诀窍是:子 Agent 继承足够上下文以便有效工作,同时又受到约束(比如只读、以及限制递归深度)。
Claude Code 很早就支持 subagents,Codex 是后来才加的。Codex 通常不会强制 subagent 只读;相反,它们一般会继承主 Agent 的沙箱与审批设置。所以边界更多是任务范围、上下文与深度控制。
上面的章节试图覆盖编码 Agent 的主要组件。它们在实现上彼此深度交织。
这和 OpenClaw 相比如何?
OpenClaw 可能是个有趣的对比,但它并不完全是同一种系统。
OpenClaw 更像是一个本地的、通用的 Agent 平台(也能写代码),而不是一个专门的(终端)编码助手。
不过它与 Coding harness 仍有不少重叠点:
- 它会使用 workspace 里的提示词/指令文件,例如 AGENTS.md、SOUL.md、TOOLS.md
- 它会保存 JSONL 会话文件,并包含 transcript 压缩与会话管理
- 它可以启动辅助会话与子 Agent
- 等等
但如上所述,侧重点不同。编码 Agent 是为“人在仓库里工作、让编码助手高效检查文件/改代码/跑本地工具”而优化的;而 OpenClaw 更偏向在多个聊天、频道与 workspace 上运行许多长期存活的本地 Agent——编码只是其中一个重要工作负载。
文章来自于”特工宇宙”,作者 “宇宙编辑部”。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/255150.html