
October 27, 2025
YugabyteDB 提供了 PostgreSQL 的熟悉感和可扩展性,同时还能提供卓越的规模和弹性。得益于 pgvector PostgreSQL 扩展,它还可以作为一个高性能的向量数据库 (vector database)。其可扩展性使其能够存储和搜索数十亿个向量。
这个系列文章的第一部分解释了为什么向量数据库对 Agentic AI 至关重要,以及 YugabyteDB 如何满足全球组织的关键需求,包括数据主权 (data sovereignty) 和零停机时间。
在本系列的第二部分,我们将演示如何轻松利用这项技术,通过 n8n(一个零代码编排工具)为 AI 提供您组织的信息。
AI Agent 是具备工具访问能力的推理型大语言模型 (Large Language Models, LLMs),例如 OpenAI 的 ChatGPT 5 或 Google 的 Gemini 2.5 Pro。
推理模型是第一代 LLM 的继任者,它们可以迭代或"更深入地思考"问题,以提供更高质量的响应。它们的工具使它们不仅能够"说话",还能够行动,以完成复杂的任务。例如,它们可以检索额外信息、进行购买或发送电子邮件。
AI Agent 与自动化的不同之处在于,它们不需要预先编程精确的、重复性的步骤。想象一下,一位 AI 员工只需简短的指示就能创建演示文稿、管理您的日历或审查产品设计。
允许 AI Agent 使用工具(如数据库、电子邮件账户或您的日历)的标准机制称为模型上下文协议 (Model Context Protocol, MCP)。我们将在未来的博客文章中探讨 MCP。
所以,这听起来很棒——AI 员工可以执行通常与知识型员工相关的任务。与新员工相比,他们可能更快,并且能创建更精致的输出。然而,人类员工仍然有自己的优势……他们可以查阅手册、订单、会议纪要以及每个企业都拥有的大量历史文档。虽然 AI Agent 的 LLM 是在公共领域的此类材料上进行训练的,但它对组织的私有信息没有任何了解。
人类员工的另一个好处是他们能够随着时间学习以更好地完成工作。AI 的长期记忆是学术研究的主题,鉴于发展的速度,这可能已经不远了。
为了帮助 AI Agent 在竞争中取得平衡,我们可以使用检索增强生成 (Retrieval Augmented Generation, RAG)。这允许 Agent 在形成响应时以非结构化数据的形式访问私有的组织信息。想象一下,您的 AI Agent 在第一天上班时就能随时获取组织的参考材料。
RAG 的工作方式是:
- 通过以下方式预处理非公开数据
-
- 从文档中提取文本
-
- 将文本分割成块 (chunks)
-
- 使用嵌入模型 (embedding model) 将每个块转换为向量(数字)
-
- 将向量存储在数据库中
-
- 当用户的提示到达时,LLM 可以为向量数据库生成查询,该查询
-
- 被转换为向量
-
- 用于对数据库进行相似性搜索
-
- 将相似的文本块返回给 LLM
-
- LLM 现在处理增强后的、更丰富的提示
向量数据库支持语义搜索 (semantic search),它允许您找到具有相似含义的内容,即使它不包含相同的文本。它还避免了找到文本相同但含义不同的信息。
AI Agent 可以将向量数据库作为工具来帮助它检索与任务相关的上下文。它可以快速访问相关文档、会议纪要、电子邮件等。这使它能够确定民事诉讼中的一方是否提到了特定购买,或回忆多年前签署的合同细节。
YugabyteDB 是一个具有企业级规模和弹性的向量数据库。它支持关键的 RAG 工作负载,为 AI Agent 提供对您非结构化数据的了解。
YugabyteDB 熟悉的 PostgreSQL 接口加速了开发,并能够访问广泛的生态系统。它在统一平台上管理结构化的关系数据和非结构化的向量化数据。
为了帮助演示使用 YugabyteDB 大规模搜索向量的好处,我们将使用 n8n(一个流行的可视化工作流工具)来创建数据摄入管道 (ingestion pipeline)。我们的工作流将包含一个按需触发器来向量化非结构化数据,以及一个聊天触发器来与可以访问该数据的 AI Agent 进行交互。
Yuga Readers 是一个位于美国的读书小组,旨在分享对优秀文学的热爱。然而,阅读需要时间,所以我们决定创建一个 AI Agent 来帮助回答读者的问题。为了让 Agent 有更深入的了解,我们将使用 RAG 让它能够访问书籍文本。这也允许 Agent 在回答问题时提供对文本的具体引用。
我们将使用 Project Gutenberg 获取公共领域的阅读材料。我们从 Arthur Conan Doyle 的经典 Sherlock Holmes 小说开始。
随着时间的推移,Yuga Readers 取得了成功,我们在欧洲开设了第二个分会(双关语)。然而,欧洲的读者落后于我们的阅读清单。为了避免剧透,我们需要确保 Yuga Readers AI Agent 只能访问每个地点小组已阅读的故事。
作为分布式数据库,YugabyteDB 可以托管单个逻辑数据库,同时将数据放置在特定的地理位置。这可以帮助满足数据主权要求,或为某些 AI Agent 提供位置特定的上下文,同时允许其他 Agent 访问所有上下文。
为此,YugabyteDB 利用了标准的 PostgreSQL 构造。向量表被分区为两个子表,每个位置一个,这些子表被分配到表空间 (tablespaces),而表空间又被分配到这些位置的节点。您可以在此处阅读更多相关信息。
使用子表(也称为分区 (partitions))之一的 AI Agent 只能访问该位置允许的向量;使用父表的 Agent 可以访问两个位置的所有向量。
n8n 工作流将提前创建所需的表空间、表和分区。
以下步骤在我们的视频此处中有详细说明和现场演示。
n8n 和两节点 YugabyteDB 宇宙 (universe/cluster) 可以使用 Compose 在 Docker/podman 中安装。您可以从我们的 GitHub 仓库此处获取所需的文件。将它们克隆或下载到您的本地机器。
此演示有一些先决条件:
- 一个与 OpenAI API 标准/n8n 兼容的 LLM。我们将使用 Anthropic,它需要 API 密钥。还有许多其他提供商,或者您可以使用 Ollama 在本地机器上运行开源 AI 模型。
-
- Ollama 用于运行嵌入模型,将文本块转换为向量。您可以在此处获取。可以在 Docker 中运行 Ollama,但如果您有 AI 加速硬件,您应该在本地(容器外)运行以获得**性能。也可以使用在线商业 AI 提供商进行嵌入,例如 OpenAI 或 Anthropic。
-
- Podman 或 Docker(以及
podman-compose或docker-compose)
值得记住的是,这仅作为演示。在这里,YugabyteDB 部署时没有弹性以减少所需资源。复制因子为 1 (RF1) 的宇宙不适合生产环境。
- Podman 或 Docker(以及
要部署 n8n 和 YugabyteDB 容器,请运行以下命令:
# Retrieve the embedding model with Ollama, which is installed locally ollama pull mxbai-embed-large:latest # Deploy the containers (may need to use docker in place of podman) podman-compose up --detach 然后,在浏览器中访问 http://localhost:5678 的 n8n 并创建您的用户账户。您不需要请求许可证密钥。
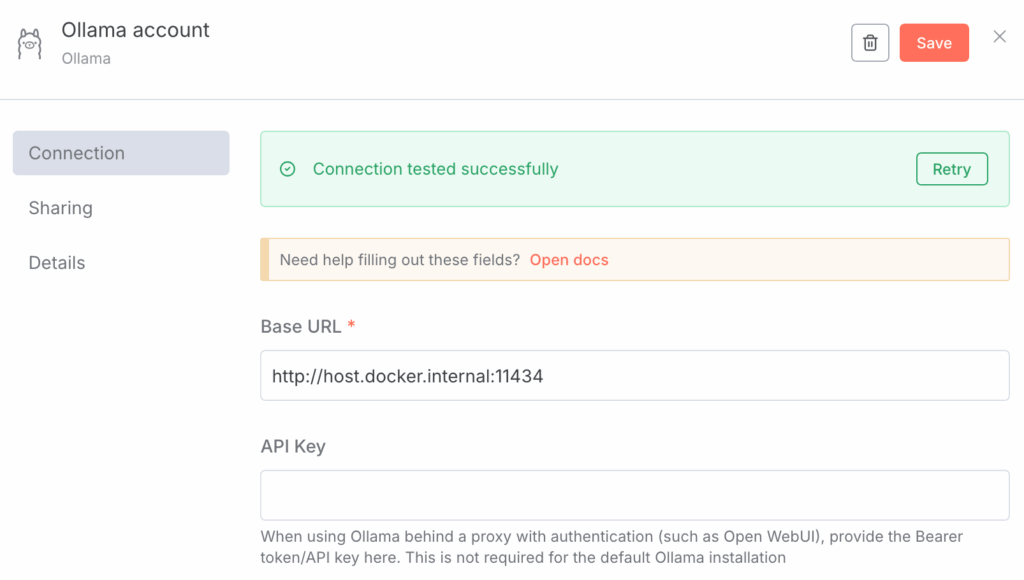
在 n8n 主页上,选择 Create Workflow 旁边的下拉菜单,然后点击 Create Credential。

选择 Ollama 作为 Credential Type,并输入 http://host.docker.internal:11434 作为 URL,以将 n8n(在容器中)指向主机上的 Ollama。
保存时,您应该看到连接成功:
为 Postgres(实际上是 YugabyteDB,兼容)创建另一个凭证:
- Host:
rag-yugabytedb-1 -
- Database:
yugabyte
- Database:
-
- User:
yugabyte
- User:
-
- Password:
yugabyte
- Password:
-
- Port: 5433
最后,为 Anthropic 或您想用于 LLM 的任何 AI 提供商添加凭证。
- Port: 5433
点击 Create Workflow 生成新工作流。选择 My workflow 以重命名并保存新工作流。
接下来,点击右上角的三个点,然后点击 Import from File…
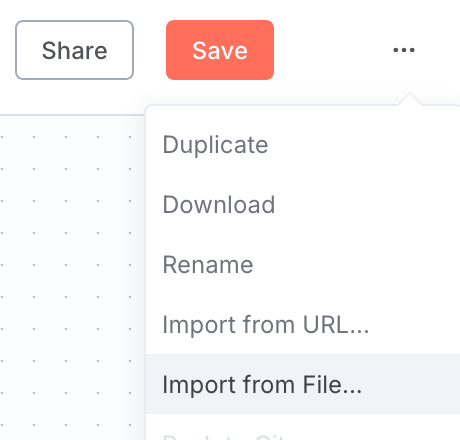
从 GitHub 仓库导入 rag_demo.json 文件。
工作流中的许多节点(步骤)将显示红叉以指示问题。这些是缺失的账户/凭证。只需双击每个节点,然后每次返回工作流即可修复此问题。
默认情况下,运行工作流将从 When clicking Execute workflow 触发器开始。
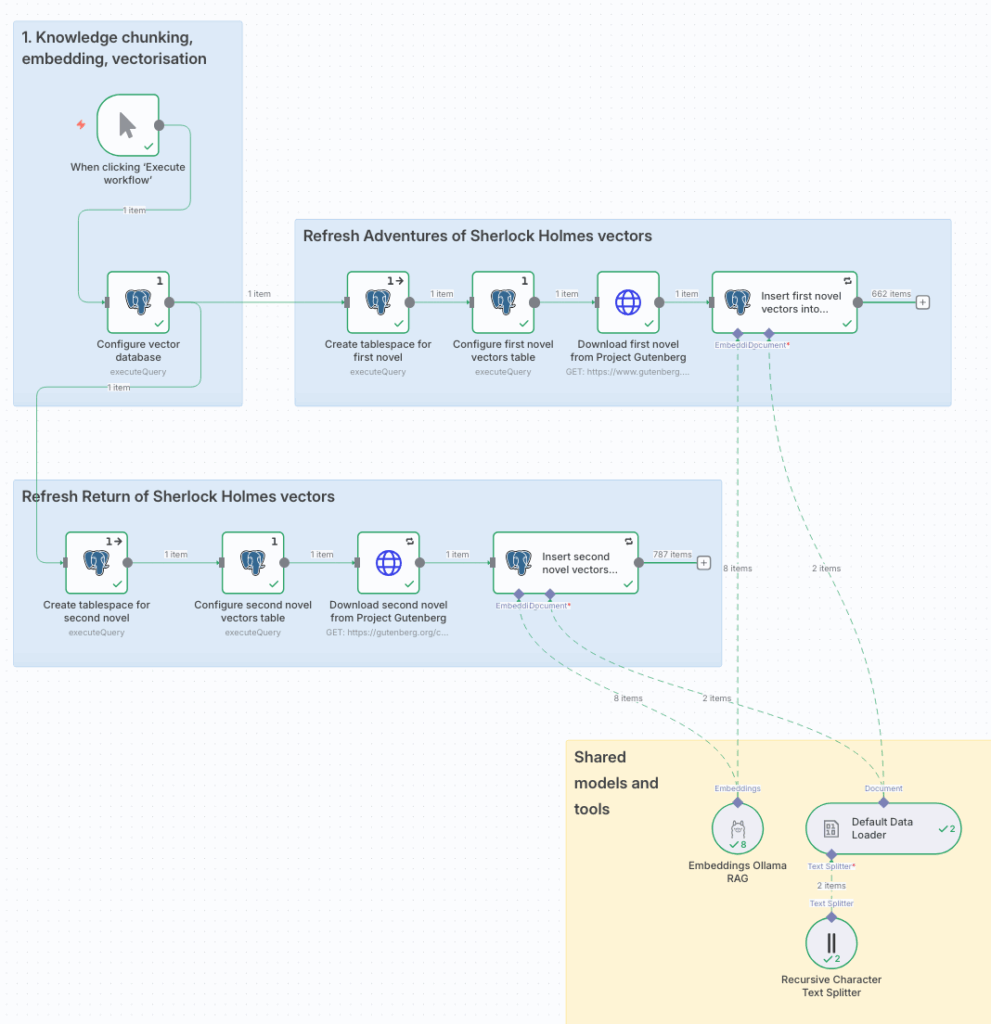
工作流从 Project Gutenberg 下载两部小说,将它们分割成块,使用 Ollama 托管的嵌入模型将它们转换为向量,并将向量存储在 YugabyteDB 中。
YugabyteDB 透明地将每部小说的向量分配给其自己的表空间,以帮助确保 Yuga Readers 的不同分会只能访问他们已阅读的书籍。Yuga Readers 的美国分会已阅读《The Adventures of Sherlock Holmes》,欧洲分会已阅读《The Return of Sherlock Holmes》。
工作流每次运行时都会删除并重新创建 YugabyteDB 中的 public schema,使其可以安全地重新运行。然后它创建一个 vectors 表,n8n 可以在其中存储向量。每个向量由 n8n 分配到一个集合 (collection),这只是一个表示向量所属位置的标签。
工作流还为每个位置预配置了表空间和 vectors 表的分区。它指示 YugabyteDB 根据其集合透明地将新向量放置到正确的分区中。
您可以在 master UI 中查看表到节点(因此也是集合/位置)的分配。
工作流有三个 AI Agent,每个都连接到同一个 YugabyteDB 数据库,但使用不同的地理限制表。When chat message received 触发器可以连接到任何 AI Agent 进行测试。
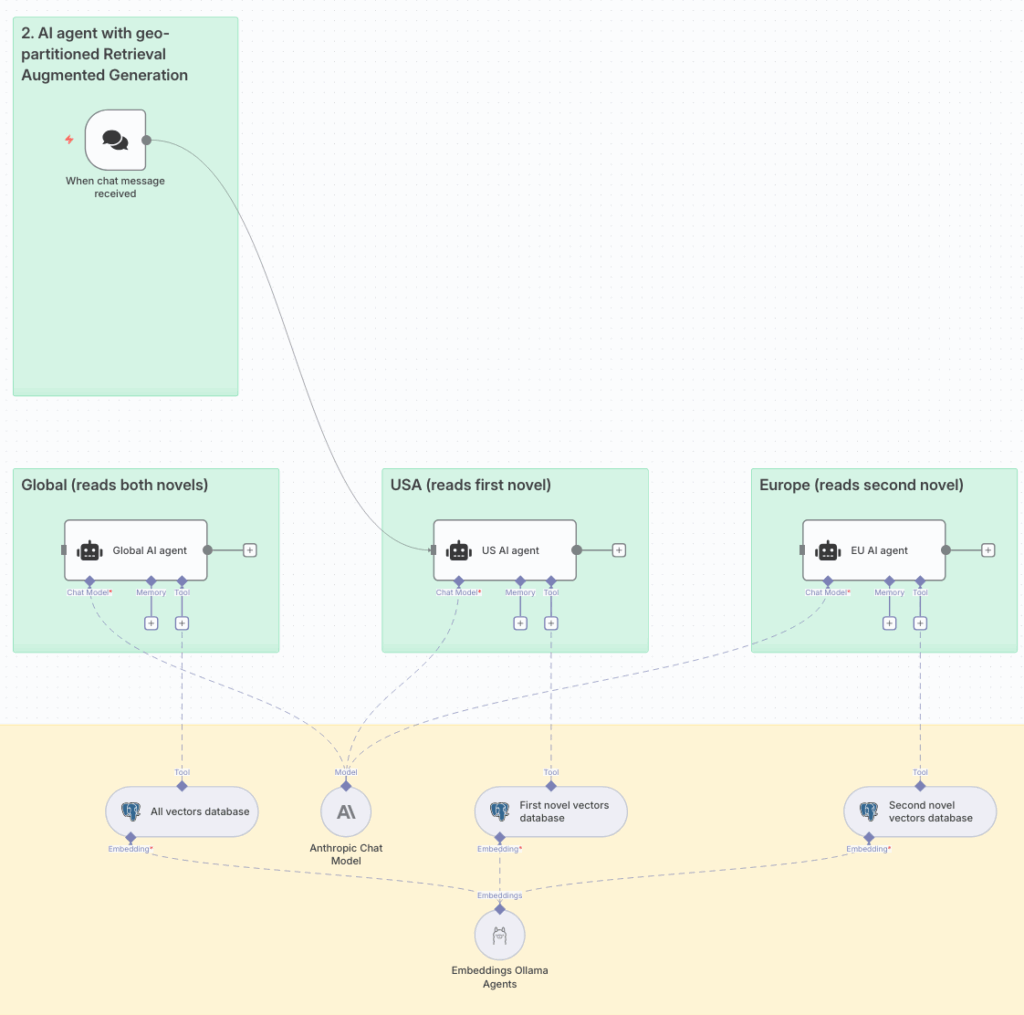
美国分会
当聊天触发器连接到美国 AI Agent 时,询问与第一部小说《The Adventures of Sherlock Holmes》相关的问题:
Mr St Clair 住在哪里?
AI Agent 使用其分配的工具(访问 YugabyteDB 向量数据库)来帮助添加上下文。它编写查询 St Clair residence address 并要求 YugabyteDB 执行语义搜索。
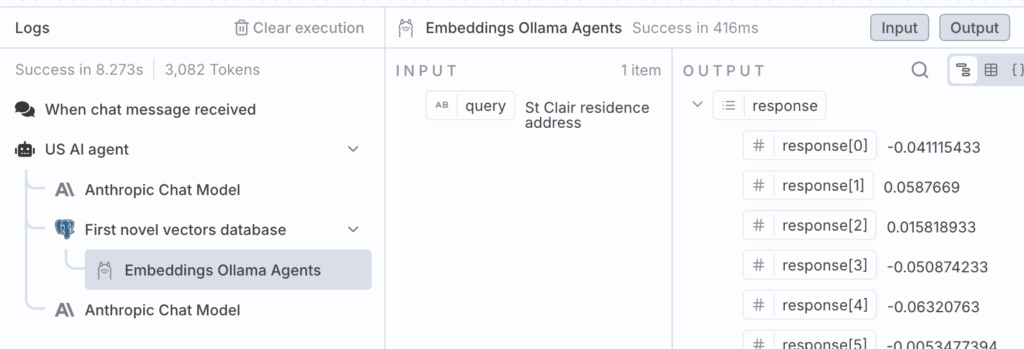
Agent 使用增强上下文的响应非常准确。值得注意的是,它已从小说中识别出文本,尽管文本不包含查询中的 address 或 residence 一词。
根据搜索结果,我发现 Mr. Neville St. Clair 住在 Lee。具体来说,文本提到"几年前——确切地说,在 1884 年 5 月——一位名叫 Neville St. Clair 的绅士来到 Lee,他似乎很有钱。他买了一栋大别墅,把庭院布置得非常漂亮,并且总体上过着优渥的生活。"
细节表明他:
- 于 1884 年 5 月搬到 Lee
-
- 购买了一栋大别墅
-
- 到 1887 年与当地酿酒厂老板的女儿结婚
-
- 有两个孩子
-
- 每天通勤到城里,乘坐 5:14 从 Cannon Street 出发的火车返回
因此他的主要住所是 Lee 地区的一栋大别墅,Lee 是伦敦东南部的一个区域。
- 每天通勤到城里,乘坐 5:14 从 Cannon Street 出发的火车返回
欧洲分会
当聊天触发器连接到欧洲 AI Agent 时,它只能访问第二部小说《The Return of Sherlock Holmes》的向量,而不能访问第一部。
AI Agent 的 LLM 可能在其广泛的训练语料库中可以访问更广泛的小说信息,但没有完整的文本可供查询:
我深表歉意,但经过多次搜索,我无法在小说中找到 Mr. St. Clair 住所的具体地址。故事《The Man with the Twisted Lip》提到了 Neville St. Clair,但搜索结果中未提供其家庭住址的详细信息。我从故事中可以回忆起的是,他和妻子孩子住在一个体面的郊区,但这些向量数据库结果中未指定确切位置。如果您需要更具体的信息,您可能需要直接参考故事的完整文本。
检索增强生成 (RAG) 使 AI Agent 能够访问您组织的私有知识,提供更快、更准确且内容丰富的输出。
YugabyteDB 提供企业级的可扩展性、弹性和数据主权,同时在单个 PostgreSQL 兼容平台上管理结构化数据和向量数据。
结果如何?AI 可以即时生成关键洞察、改善决策并提升整个业务的生产力。
想了解如何在 PostgreSQL 兼容数据库上构建 GenAI 应用? 下载我们的解决方案简报,了解基本 AI 概念、架构考虑因素,以及访问实践教程,演示如何在各种平台上构建您的第一个 GenAI 应用程序。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/254824.html