
在当今AI驱动的开**潮中,将强大的大语言模型(LLM)与智能助手框架集成到本地环境,已成为提升开发效率、保护数据隐私和构建个性化AI应用的关键一步。对于使用Mac(尤其是Apple Silicon芯片)的开发者而言,如何高效地部署一套完整的本地AI解决方案?本文将手把手带你使用OpenClaw和Ollama,在Mac上搭建一个功能齐全、可扩展的本地大模型服务端,并深入探讨其背后的微服务架构与**实践。
在开始部署之前,明确硬件与软件栈是成功的第一步。本次部署基于Apple M3 Pro芯片,其强大的神经网络引擎(ANE)能显著加速本地模型的推理性能。软件栈的核心是Ollama和OpenClaw:Ollama作为轻量化的模型管理与服务中间件,负责模型的拉取、加载和提供标准的API接口;而OpenClaw则是一个构建在Ollama之上的AI助手框架,提供了对话、工具调用等更高级的功能。我们选择Qwen3.5:9B作为基础模型,它在参数量、性能与资源消耗之间取得了良好平衡,非常适合在个人电脑上运行。这套组合本质上构建了一个微型的微服务架构,其中Ollama是模型服务端,OpenClaw是应用层,两者通过API进行通信。
Ollama的安装过程极其简单,它封装了复杂的模型环境配置。打开终端,执行以下命令即可完成安装:
curl -fsSL https://ollama.com/install.sh | sh安装完成后,Ollama会作为一个后台服务运行。你可以通过一个简单的命令来测试它是否工作正常,例如运行一个视觉语言模型进行聊天:
ollama run llava这行命令会拉取(如果尚未缓存)并启动llava模型,进入一个交互式对话界面。更重要的是,Ollama在本地11434端口启动了一个HTTP API服务。这意味着任何本地应用程序,包括我们即将部署的OpenClaw,都可以通过向http://localhost:11434发送请求来与模型交互。这种设计使得Ollama成为了一个标准的模型服务端,为上层应用提供了统一的访问接口。
有了稳定的模型服务,接下来部署功能更丰富的OpenClaw。OpenClaw可以理解为一个“AI助手操作系统”,它不仅能进行对话,还能规划任务、调用工具。使用Ollama提供的便捷命令,我们可以一键部署OpenClaw并指定其使用的模型:
ollama launch openclaw –model qwen3.5:9b执行此命令后,程序会自动处理所有依赖,将OpenClaw框架与我们之前准备好的Qwen3.5:9b模型进行绑定。在安装过程中,可能会遇到安全提示,选择yes即可。
安装成功后,终端会直接进入OpenClaw的命令行交互界面,如下图所示。此时,你已经可以通过自然语言与你的本地AI助手进行对话了。
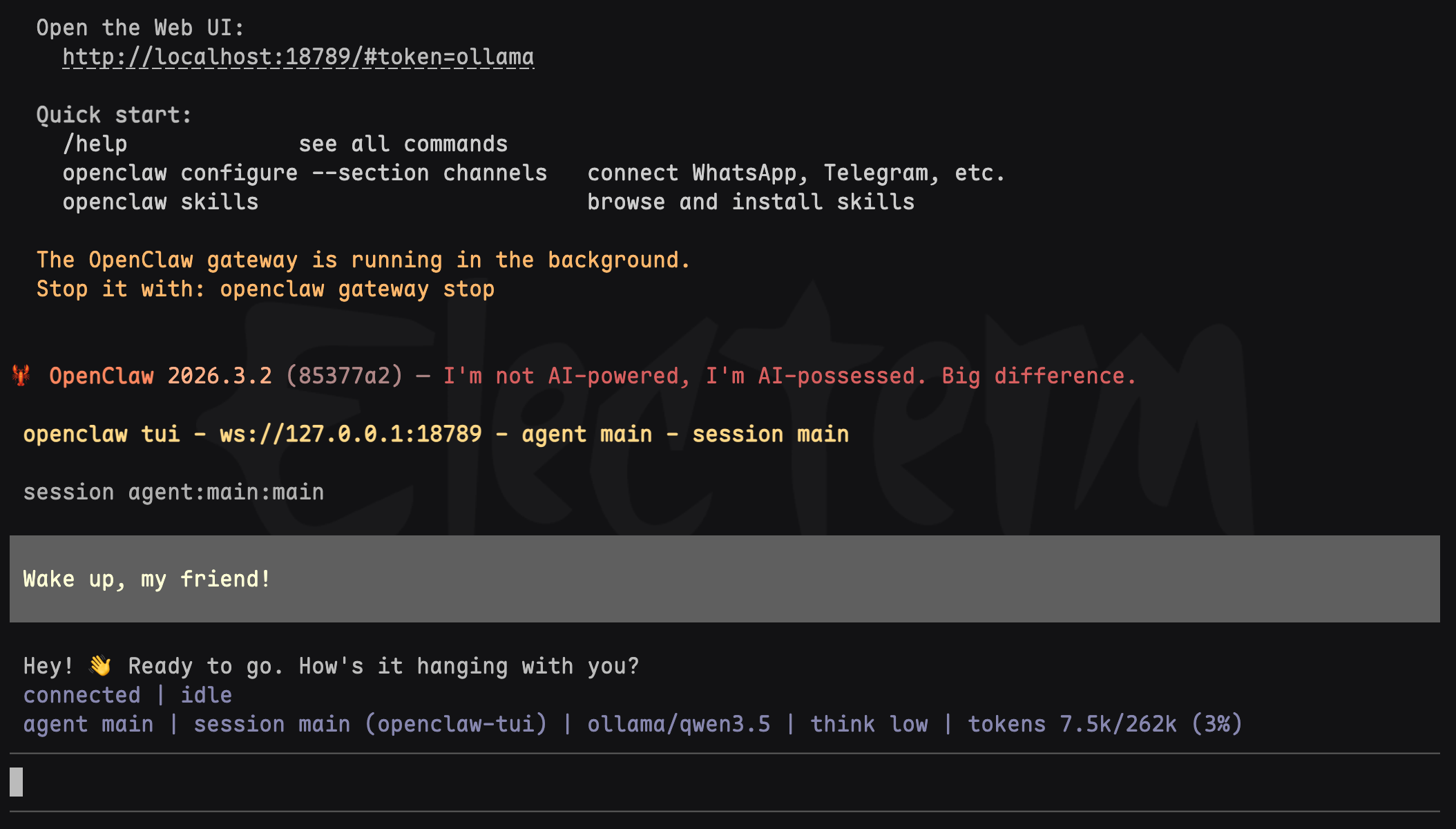
然而,命令行界面(CLI)并非唯一选择。OpenClaw还提供了一个更直观的Web TUI(文本用户界面)。要启用它,需要先配置Gateway(网关)。在命令行中输入:
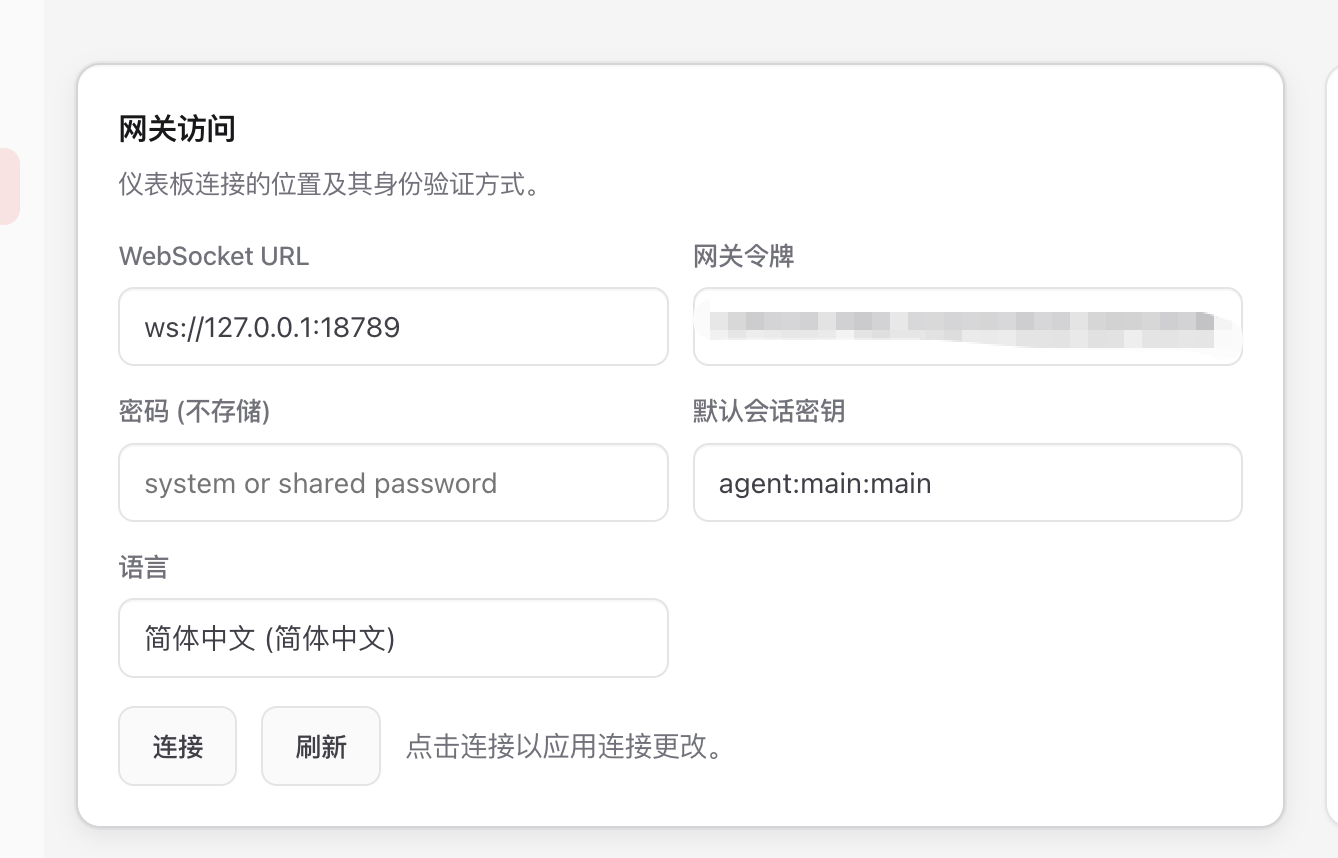
openclaw config在配置菜单中选择Gateway,然后进行端口、绑定模式(建议选择Loopback仅本地访问)和认证方式的配置。这里选择Token认证,系统会自动生成一个令牌(Token),请务必复制保存。
配置完成后,在浏览器中访问http://127.0.0.1:18789/overview(端口以你配置的为准),在网关令牌配置页面粘贴刚才生成的Token。
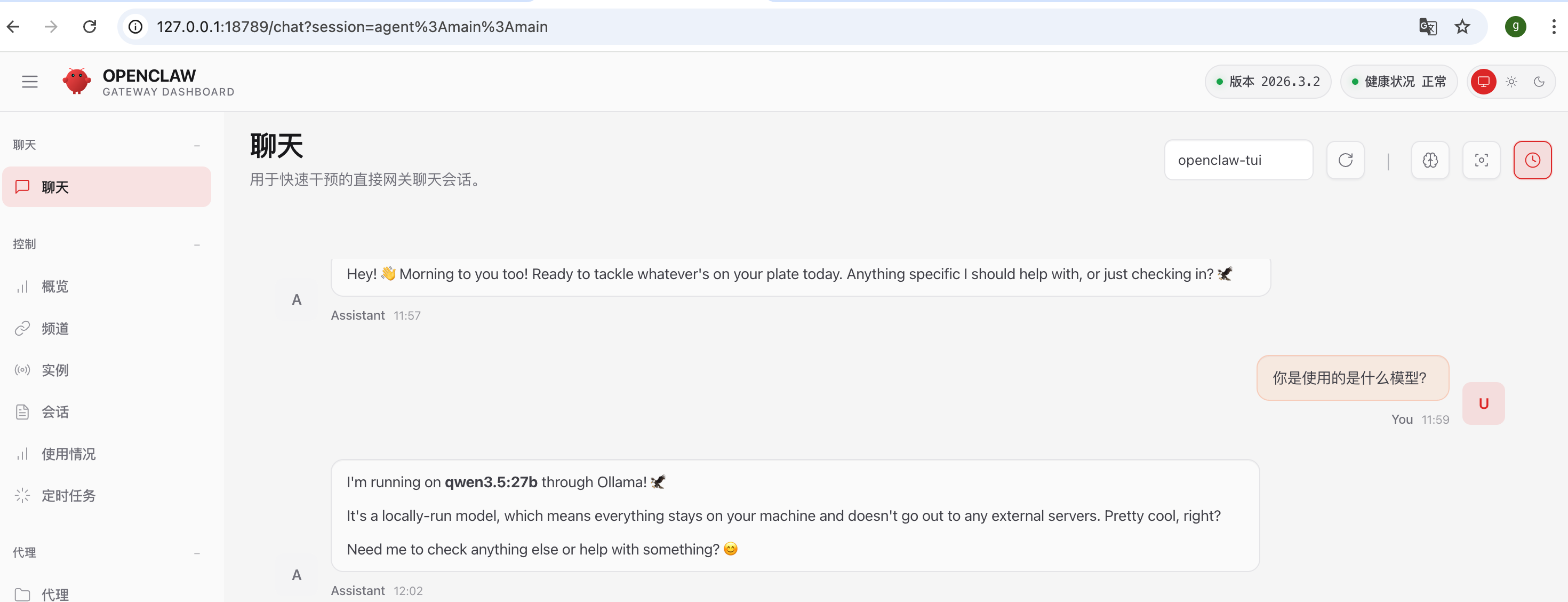
完成上述配置后,你就可以通过精美的Web TUI界面与OpenClaw交互了,体验大幅提升。
 [AFFILIATE_SLOT_1]
[AFFILIATE_SLOT_1] 本地AI部署的魅力在于其高度的可定制性。Ollama和OpenClaw的组合提供了灵活的模型切换能力。如果你觉得9B参数的模型能力不足,或者想尝试其他模型(如CodeLlama、Mixtral等),可以轻松更换。Ollama提供了封装好的命令,直接替换模型名称即可:
ollama launch openclaw –model
<新模型名称>例如,如果你想升级到能力更强的Qwen3.5:27B模型(确保你的硬件内存足够),只需执行:
ollama launch openclaw –model qwen3.5:27b这个过程会重新部署OpenClaw并连接至新的模型服务端。此外,还有一些**实践值得关注:
- 资源监控:使用
活动监视器关注内存和GPU负载,大型模型是资源消耗大户。 - 模型缓存:Ollama会将拉取的模型缓存在本地,通常位于
~/.ollama/models目录,管理该目录可以释放磁盘空间。 - API集成:你可以将本地运行的Ollama API集成到你自己的微服务或应用中,作为其中一个智能服务模块。
- 持久化与上下文:研究OpenClaw的配置,看是否支持将对话历史保存到本地数据库(如SQLite),以实现跨会话的记忆。
通过本文的步骤,我们成功在Mac M3 Pro上搭建了一套由OpenClaw和Ollama驱动的本地大模型应用栈。这套方案的核心优势在于:数据隐私(所有计算在本地完成)、离线可用、低成本(无需API调用费用)以及高度可定制。它不仅仅是一个聊天机器人,更是一个可以接入你本地工具链、数据库和业务系统的智能服务端助手原型。随着本地模型效能的不断提升和此类框架的日益成熟,在个人设备上运行功能强大的专属AI助手,正迅速从概念变为开发者的日常生产力工具。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/254467.html