
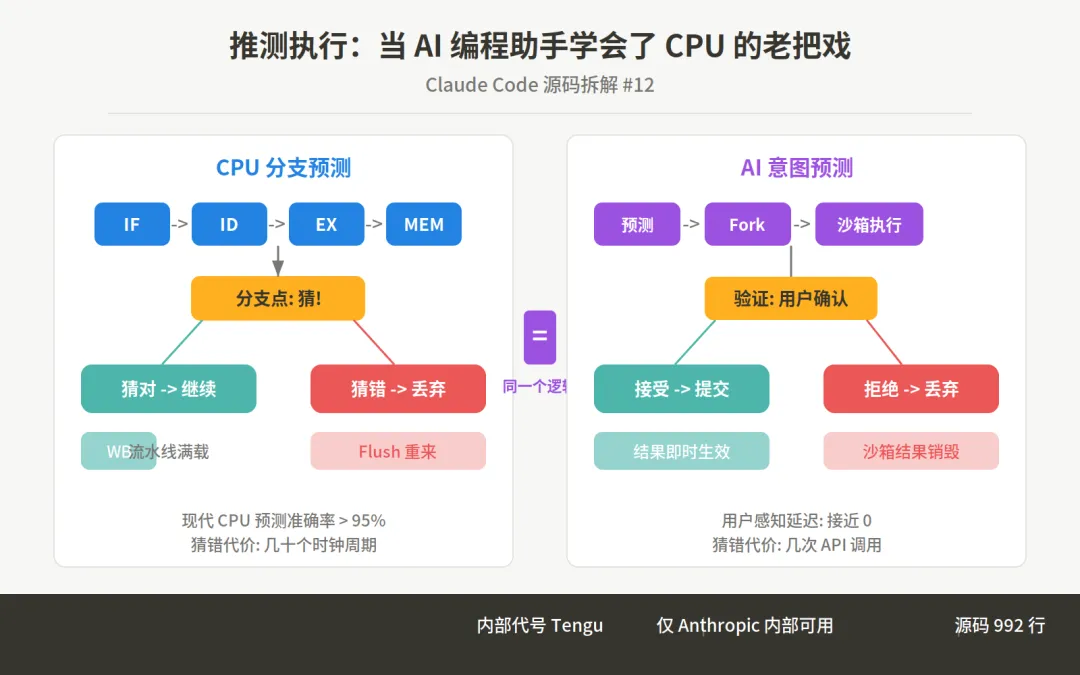
1969 年,IBM System/360 Model 91 第一次在硬件里实现了分支预测——CPU 不再傻等条件判断的结果,而是赌一把:猜你接下来要走哪条路,提前把那条路上的指令算好。猜对了,省掉几十个时钟周期;猜错了,把算好的结果扔掉,假装什么都没发生。
57 年后,Claude Code 的源码里出现了同样的逻辑。只不过这次预测的对象不是机器指令的跳转方向,而是人类开发者的下一步操作。
泄露的 992 行 speculation.ts 揭示了一套完整的意图流水线(Intent Pipeline):预测你要输什么 → 在沙箱里替你先做了 → 你按回车确认就直接用结果,改主意就全丢。这套系统内部代号 Tengu(天狗),目前仅限 Anthropic 内部员工使用,但所有基础设施已经完全就位。
这篇拆解不是讲”Claude Code 有个酷炫功能”。它讲的是一种正在浮现的设计范式:AI 工具的下一个竞争维度不是更聪明,而是更快——不是模型推理更快,而是让人感觉更快。
推测执行核心循环
整套意图流水线的起点,是一个看起来不起眼的功能:输入建议。
每轮对话结束后,Claude Code 会在后台 fork 一个子 agent(forked agent),用当前对话上下文去预测用户下一步会输入什么。源码里的 prompt 写得很直白:
“Your job is to predict what THEY would type – not what you think they should do. THE TEST: Would they think ‘I was just about to type that’?”
注意这个设计抉择。建议系统的目标不是”给出最好的下一步”,而是”猜中用户自己想做的下一步”。两个目标听起来像,实际差距巨大。前者是顾问思维——我比你懂,听我的;后者是助手思维——我知道你想干嘛,让我帮你省点力气。
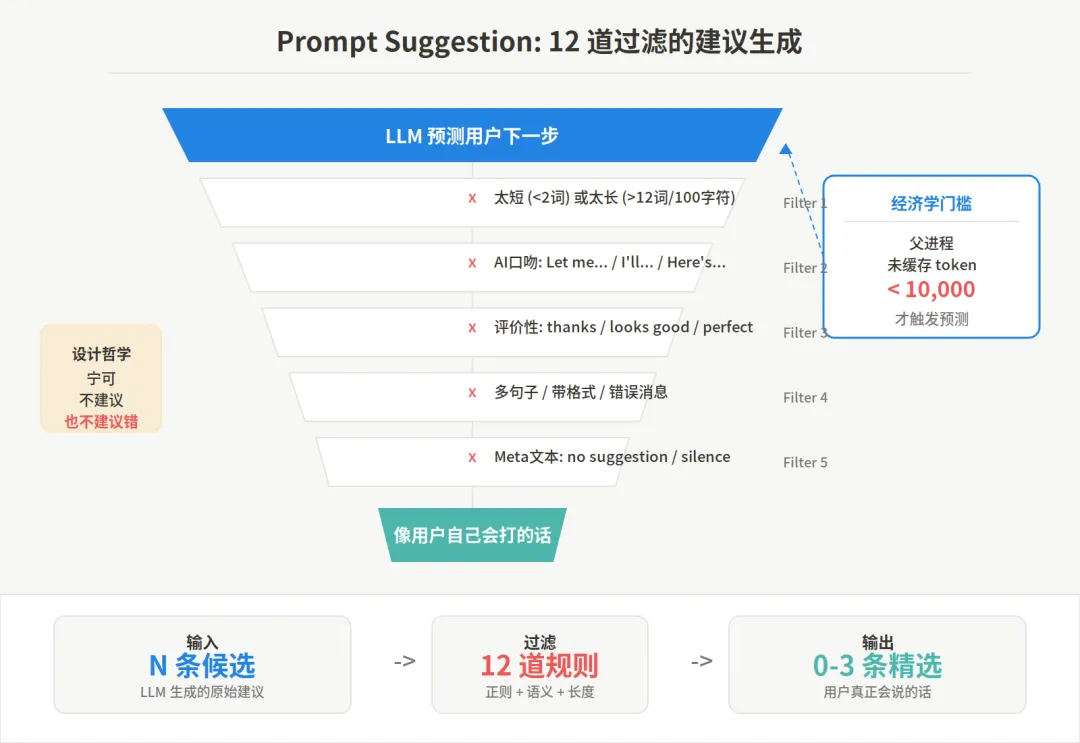
为了确保建议”像用户自己会打的话”,源码里堆了 12 条过滤规则。太短的丢(单个词,除了 yes/no/push/commit 这类常见指令)。太长的丢(超过 12 个词或 100 字符)。听起来像 AI 在说话的丢——”Let me…”、”I’ll…”、”Here’s…” 这类句式全部拦截。评价性的丢——”looks good”、”thanks”、”perfect”。多句子的丢。带格式的丢。
这不是简单的文本过滤,这是一套严格的角色校准系统。建议必须是”用户语气”,不能是”AI 语气”。一旦用户感觉”这不像我会说的话”,信任就崩了。
Prompt Suggestion 过滤漏斗
还有一层更精妙的经济学考量。建议生成本身是一次 LLM 调用,要花钱。源码里有一个 getParentCacheSuppressReason 函数:如果上一轮对话的未缓存 token 数超过 10,000,就不生成建议。原因是 fork 出来的子 agent 必须复用父进程的 prompt cache 才划算——如果父进程的缓存还没写入,子进程就要重新处理全部上下文,成本翻倍。
这个细节说明一件事:建议系统不是”有总比没有好”。只有在缓存命中率足够高的时候,它才有正的 ROI。 做不到就宁可不做。
建议只是开胃菜。Claude Code 真正激进的设计在下一步:推测执行(Speculation)。
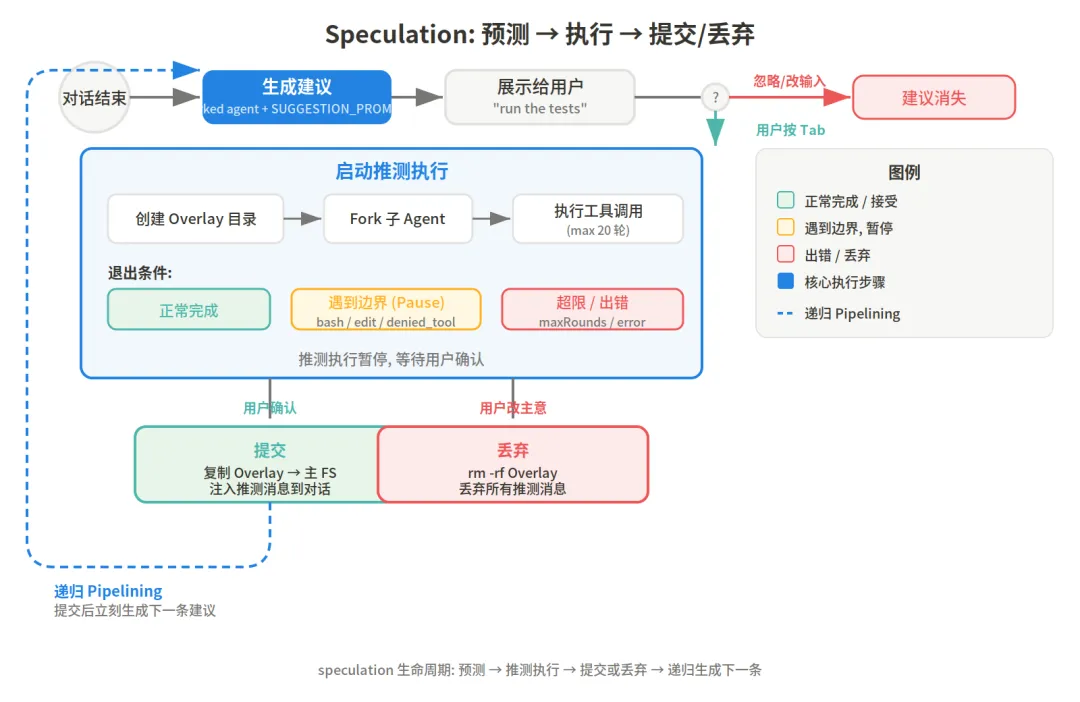
当 Prompt Suggestion 生成一条建议(比如 “run the tests”)之后,系统不是干等着用户按 Tab 接受。它立刻启动一个隔离的 forked agent,拿这条建议当作用户的真实输入,在后台执行。
源码中 startSpeculation 函数的流程:
1. 生成一个唯一 speculation ID(UUID 前 8 位)
2. 在临时目录创建 overlay 文件系统:~/.claude/speculation/
3. fork 一个子 agent,把建议文本作为用户消息传入
4. 子 agent 开始执行工具调用——读文件、搜索代码、甚至编辑文件(写入 overlay)
5. 每个工具调用都经过严格的权限检查
6. 执行最多 20 轮,或 100 条消息
等用户决定的时候,两种结局:
按 Tab 接受建议 → overlay 里修改过的文件复制回主文件系统,推测过程中的所有消息注入对话历史,就好像用户亲自执行了一样。省下的时间被精确记录:speculationSessionTimeSavedMs。
用户自己打了别的话 → overlay 整个删除,推测过程中的消息全部丢弃。几秒到几十秒的计算资源,说扔就扔。
这就是分支预测的精髓:赌赢了,你省了等待时间;赌输了,你什么都没感觉到。
Speculation 核心循环
推测执行最大的工程挑战不是预测——预测错了大不了丢掉。真正危险的是:如果推测过程中修改了文件,然后预测错了,怎么回滚?
Claude Code 的解法借鉴了容器技术中的 overlay filesystem 思想,但做了大幅简化。
核心机制是 Copy-on-Write(写时复制)。推测执行过程中,所有写操作(Edit、Write、NotebookEdit)都被重定向到 overlay 目录。具体来说:
第一次写某个文件时:先把原文件复制到 overlay 目录(保留原始状态),然后在 overlay 副本上修改。
后续读同一个文件时:如果这个文件之前被写过,就从 overlay 读(读到自己的修改);如果没被写过,从主文件系统读(读到真实状态)。
写工作目录之外的文件:直接拒绝,无条件。
这套机制的精妙之处在于成本极低。不需要真正的文件系统快照,不需要 git stash,不需要 Docker 容器。就是一个临时目录 + 路径重定向。接受时 copyOverlayToMain 把文件复制回去,拒绝时 rm -rf 整个目录。
主文件系统(真实世界) Overlay(平行宇宙) ├── src/ ├── src/ │ ├── app.ts ────读───→ │ ├── app.ts(副本,被修改过) │ ├── test.ts ──读───→ │ │ │ └── utils.ts │ └──(不存在,从主FS读) │ │ 用户按 Tab ──→ 复制回来 用户打字 ──→ rm -rf 整个目录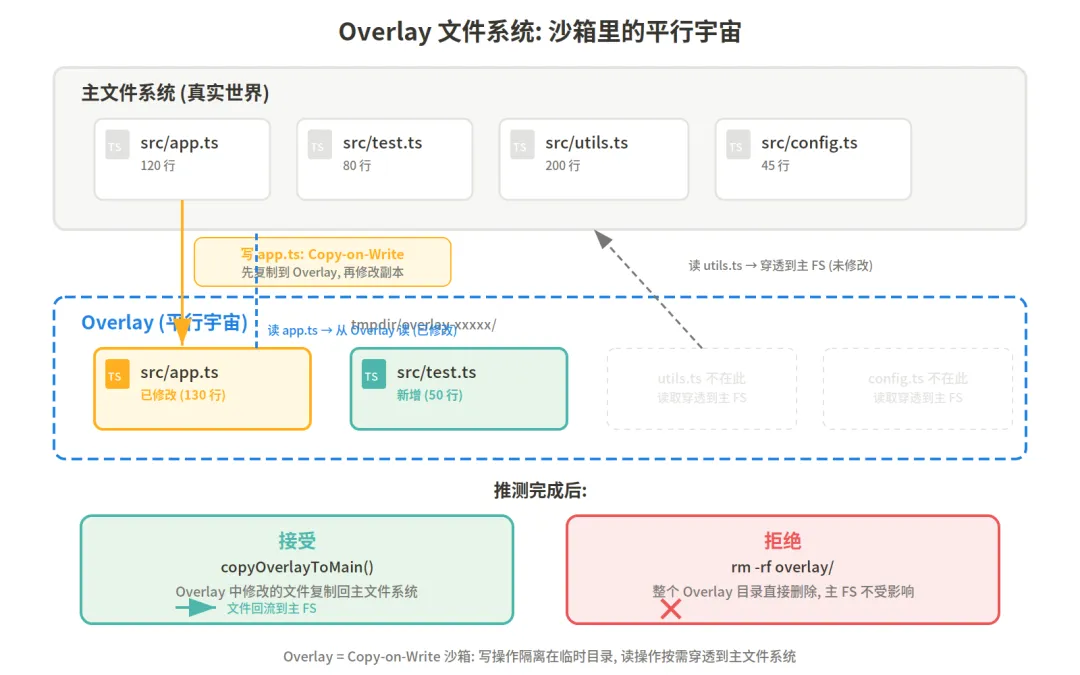
Overlay 文件系统
但 overlay 只解决了文件操作的可逆性。对于不可逆的操作——比如运行一个会修改数据库的脚本,或者发送 HTTP 请求——推测执行选择了更简单粗暴的策略:不做。碰到这类操作就停下来,记录一个”边界”(boundary),等用户确认后再继续。
拆到这里,一个更大的图景浮现了。推测执行不是 Claude Code 里唯一在”抢跑”的机制。从微观到宏观,至少有三层流水线在同时工作:
当模型还在流式输出 Bash 命令的参数时——注意,参数还没输出完——系统就已经开始并行运行安全分类器了。startSpeculativeClassifierCheck 在 toolExecution.ts 里被调用的位置非常靠前:工具参数刚通过 schema 校验,分类器就启动了。
模型流式输出中... ├─ 时间点 T1: 参数校验通过 → 启动 speculative classifier ├─ 时间点 T2: 模型继续输出,分类器并行运行 ├─ 时间点 T3: 模型输出完成 └─ 时间点 T4: 分类器结果已就绪,直接使用(无需等待)如果没有这个预取,流程是:模型输出完 → 启动分类器 → 等分类器返回 → 执行。串行变并行,用户无感但省了一个完整的分类器调用延迟。
query.ts 里有两个预取机制:
Memory Prefetch:每个用户 turn 开始时,系统用 startRelevantMemoryPrefetch 启动一个异步查询,去找和当前对话相关的记忆文件。这个查询不阻塞主循环——每次迭代用 zero-wait 方式检查结果是否已经返回。如果还没返回就跳过,下次迭代再检查。源码注释说得很清楚:the prefetch gets as many chances as there are loop iterations before the turn ends。
Skill Discovery Prefetch:同样的模式,startSkillDiscoveryPrefetch 在模型流式输出和工具执行期间运行。源码提到一个关键数据:之前的阻塞式 skill 发现在生产环境中 97% 的调用什么都没找到。把它改成预取后,那 97% 的空等待就被藏到了模型推理的时间里。
这是最激进的一层。推测执行完成后,系统不是停下来等用户——它立刻生成下一条建议,然后开始推测执行那条建议。源码中叫 generatePipelinedSuggestion:
用户输入 → Claude 回复 → 生成建议 A → 推测执行 A ↓ (A 执行完毕) 生成建议 B → 推测执行 B ↓ (B 执行完毕) 生成建议 C → ...如果用户接受了建议 A,系统检查是否已经有 pipelined 建议 B。如果有,直接展示 B 并开始推测执行 B。理论上,对于高度可预测的工作流(比如”改 bug → 跑测试 → 提交 → 推送”),整条链路可以在用户第一次按 Tab 之前就全部预执行完毕。
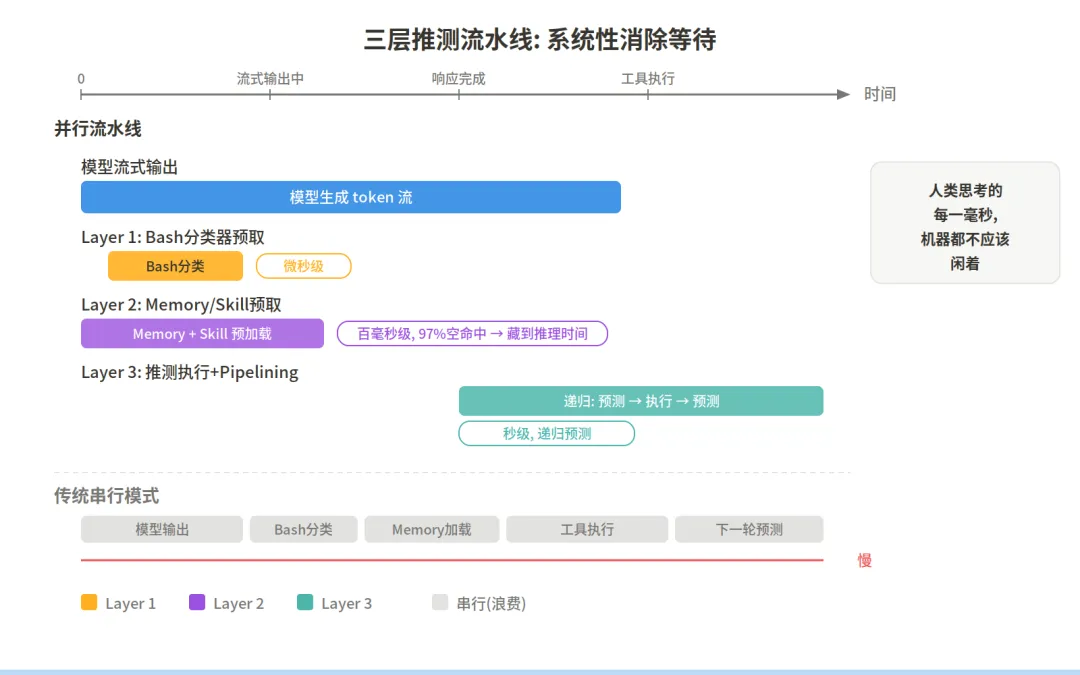
三层推测流水线
这让人想起 CPU 流水线的深度——Intel 的 Pentium 4 曾经把流水线做到 31 级深,为的就是在每个时钟周期里尽可能多地并行执行指令。Claude Code 的三层流水线是同一个思路:人类思考的每一毫秒,机器都不应该闲着。
推测执行听起来很酷,但有一个关键的问题:它划算吗?
每次推测执行都是一次完整的 forked agent 调用——要过模型,要用 token。如果预测准确率只有 30%,那 70% 的推测调用都是浪费。成本问题不解决,这个功能就只能给内部员工用。
Claude Code 的答案是 prompt cache 复用。
forkedAgent.ts 里定义了一个叫 CacheSafeParams 的类型,它包含五个字段:系统提示词、用户上下文、系统上下文、工具使用上下文、父进程对话历史。这五个字段必须和父进程完全一致,才能命中 Anthropic API 的 prompt cache。
源码注释里记录了一个血泪教训:
“PR #18143 tried effort:’low’ and caused a 45x spike in cache writes (92.7% → 61% hit rate).”
有人尝试在 fork 里设置 effort: 'low' 来省 token,结果 cache hit rate 从 92.7% 暴跌到 61%。因为 effort 参数影响了 API 的 cache key 计算——哪怕 fork 的对话上下文和父进程完全一样,只要有一个参数不同,缓存就失效了。45 倍的 cache write spike,意味着每个 fork 都要重新处理整个对话上下文。
这个事故揭示了推测执行的经济学本质:fork 的边际成本取决于 cache hit rate。在 92.7% 的 cache hit rate 下,fork 只需要为自己新增的内容(建议文本 + 推测过程中的消息)付费,成本极低。一旦 cache 失效,fork 的成本就等于一次完整的对话请求——这时推测执行就变成了赔本买卖。

Cache 复用机制
所以源码里到处都是对 cache 的小心翼翼:
●fork 不设置 maxOutputTokens——因为这会影响 budget_tokens,进而破坏 cache key
●fork 不覆盖 effortValue——同上
●建议生成使用 skipCacheWrite: true——因为建议的 fork 是”用完即弃”的,不需要写入缓存供后续请求使用
●如果父进程的未缓存 token 超过 10,000,直接放弃生成建议——cache 还没热,fork 太贵
这些细节加在一起,画出了一条清晰的设计红线:能复用缓存才做推测,不能复用就不做。经济学先于功能。
知道什么不能推测,比知道能推测什么更重要。
speculation.ts 里定义了两组工具白名单:
安全只读工具(推测中自由使用):Read、Glob、Grep、ToolSearch、LSP、TaskGet、TaskList
写工具(重定向到 overlay):Edit、Write、NotebookEdit——但前提是用户当前的权限模式允许自动接受编辑(acceptEdits 或 bypassPermissions)。如果权限不够,碰到写操作就停下,记录一个 edit 边界。
Bash 命令:只允许只读命令。checkReadOnlyConstraints 会检查命令是否在安全白名单里——比如 git diff、rg、find 这些。任何可能产生副作用的命令都被拒绝。
所有其他工具:无条件拒绝。WebFetch、Agent、MCP 工具——碰到就停,记录 denied_tool 边界。
每种停止都被分类为一个边界类型(CompletionBoundary):bash(危险命令)、edit(权限不足的文件修改)、denied_tool(不允许的工具)、complete(正常完成)。这些边界数据全部通过 tengu_speculation 事件上报分析——Anthropic 显然在用这些数据来判断哪些边界可以放宽、哪些必须收紧。

权限边界矩阵
一个细节值得注意:推测执行中的 Bash 命令不仅要通过只读检查,还要通过 commandHasAnyCd 检测——如果命令里有 cd,也会被拦截。因为改变工作目录会影响后续所有文件操作的路径解析,在沙箱环境里这是不可控的副作用。
这套边界设计的哲学是“安全默认拒绝”(deny by default)——不在白名单里的一律不做。宁可少推测几步,也不冒产生不可逆副作用的风险。
这套系统并非没有疑问。
准确率是多少? 源码中有完整的遥测埋点——接受率、命中率、节省时间——但没有任何硬编码的阈值或注释透露实际数据。tengu_chomp_inflection 这个 feature flag 曾经短暂对外部用户开放过 Prompt Suggestion 功能,然后又关闭了。一位独立研究者 Pete 通过环境变量 CLAUDE_CODE_ENABLE_PROMPT_SUGGESTION=1 手动激活了它,证实系统完全可用。关闭的原因不明——可能是准确率不够,也可能是成本没算过来。
成本到底多少? 每次推测是一次完整的 forked agent 调用。即使 cache hit rate 达到 92.7%,剩下 7.3% 的 cache miss 在长对话中仍然意味着可观的额外成本。如果加上递归 pipelining(建议 A 完成后立刻预执行建议 B),成本还要翻倍。Anthropic 目前只对内部员工开放这个功能,可能正是因为外部用户的 API 定价模型还没准备好吸收这个成本。
overlay 只管文件,不管状态。 如果推测执行中运行的 Bash 命令产生了文件之外的副作用——比如修改了环境变量、启动了一个后台进程、向 API 发送了请求——overlay 机制管不了。当前的解决方案是直接禁止,但这也限制了推测执行的适用范围。真正的通用推测执行需要进程级别的沙箱,而不只是文件级别的。
这套系统背后有一个清晰的产品洞察:开发者在编程工作流中的”操作类”动作是高度可预测的。
写完代码之后,下一步大概率是”跑测试”。测试通过之后,大概率是”提交”。提交之后,大概率是”推送”。这些操作不需要创造力,不需要判断力,只需要有人(或有 AI)按照惯性去做。
Prompt Suggestion 的建议 prompt 里有一个暗示性极强的例子列表:
After code written → "try it out" Task complete, obvious follow-up → "commit this" or "push it" Claude asks to continue → "yes" or "go ahead" After error or misunderstanding → silence (let them assess/correct)前三条是可预测的操作流——可以推测执行。最后一条是需要人类判断的场景——保持沉默。这条边界的位置,恰恰定义了 AI 编程助手的下一个进化方向:接管操作流,释放判断力。
Google 在 2022 年发表的 Speculative Decoding 论文,把 CPU 推测执行的思想用在了 LLM 推理加速上——用小模型预测大模型的输出,命中就省推理时间,不命中就丢弃。Claude Code 做了第二次跨域迁移:从模型推理层到人机交互层——用 LLM 预测人类的意图,命中就省等待时间,不命中就丢弃。
两次迁移的共同逻辑是:在任何存在等待的地方,都可以用预测+回滚来换取速度。 代价是偶尔浪费算力,收益是大部分时间感觉更快。
对于 AI 产品的从业者来说,这意味着”人机交互延迟”正在成为和”模型能力”同等重要的竞争维度。模型的能力差距在缩小——Claude、GPT、Gemini 在大多数 benchmark 上已经难分伯仲。但用户体验的差距可以通过工程手段拉开:谁能让用户”感觉”更快,谁就赢了交互体验这一仗。
Claude Code 的意图流水线给出了一个方向:不要让人等机器,让机器抢跑人。
Speculation(推测执行) — Claude Code 中的一套系统,在用户还没确认操作之前就在沙箱中预先执行预测的操作。猜对了直接用结果,猜错了丢弃。源自 CPU 分支预测的同名概念。值得知道是因为它代表了 AI 工具从”响应式”到”预判式”的范式转移。
Tengu(天狗) — Claude Code 推测执行系统的内部代号。遥测事件命名为 tengu_speculation、tengu_prompt_suggestion。天狗在日本神话中是能预知未来的存在——取名很贴切。
Overlay Filesystem(覆盖文件系统) — 推测执行中用于隔离文件修改的机制。Copy-on-Write 策略:第一次写文件时复制原文件到临时目录,所有修改在副本上进行。接受则复制回主目录,拒绝则删除整个临时目录。
CacheSafeParams(缓存安全参数) — forked agent 必须与父进程共享的五组参数(系统提示词、用户上下文、系统上下文、工具上下文、对话历史),用于确保 prompt cache 命中。任何一个参数的差异都会导致缓存失效,推测执行的经济可行性依赖于此。
Pipelining(流水线化) — 推测执行完成后立即生成下一条建议并开始新的推测执行,形成递归预测链。类似 CPU 的指令流水线——上一条指令还在执行阶段,下一条已经在取指阶段了。
CompletionBoundary(完成边界) — 推测执行遇到无法处理的操作时的停止点。四种类型:bash(危险命令)、edit(权限不足)、denied_tool(不允许的工具)、complete(正常完成)。边界数据是 Anthropic 调优推测范围的关键遥测信号。
Intent Pipeline(意图流水线) — 本文命名的概念。指 Claude Code 中从”预测用户意图”到”预执行+预取”的多层流水线架构:Bash 分类器预取(微秒级)→ Memory/Skill 预取(百毫秒级)→ 推测执行+递归 Pipelining(秒级)。CPU 流水线的跨域迁移。
“Your job is to predict what THEY would type – not what you think they should do. THE TEST: Would they think ‘I was just about to type that’?”(你的任务是预测用户会打什么——不是你觉得他们应该做什么。检验标准:他们会不会觉得”我刚想打这个”?)– Prompt Suggestion 系统提示词
“PR #18143 tried effort:’low’ and caused a 45x spike in cache writes (92.7% → 61% hit rate).”(PR #18143 尝试设置 effort:’low’,导致 cache write 飙升 45 倍,命中率从 92.7% 暴跌到 61%。)– forkedAgent.ts 源码注释
“the prefetch gets as many chances as there are loop iterations before the turn ends”(预取在 turn 结束前有和循环迭代次数一样多的机会。)– query.ts 源码注释
“97% of those calls found nothing in prod”(生产环境中 97% 的调用什么都没找到。)– query.ts 关于 skill discovery 的注释
1. Claude Code 泄露源码 — 本期拆解原文(speculation.ts, promptSuggestion.ts, forkedAgent.ts, bashPermissions.ts, query.ts, StreamingToolExecutor.ts)
2. I Found a Hidden Feature in Claude Code Called Speculation — Pete 的独立发现,通过环境变量激活 Prompt Suggestion 并分析 Speculation 系统
3. Fast Inference from Transformers via Speculative Decoding — Google Research 2022,CPU 推测执行思想在 LLM 推理中的第一次跨域迁移
4. Claude Code 源码深度解读 — 投机性分类器检查(startSpeculativeClassifierCheck)的分析
5. 从 Claude Code 源码看 Anthropic 的产品野心 — Prompt Suggestion + 推测性执行 + 进化链分析
6. The Great Claude Code Leak of 2026 — 泄露事件始末
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/253721.html