
文生图大模型能根据文字描述生成精美图片,本文将带你了解文生图大模型的基本概念,并详细讲解LoRA、DreamBooth、ControlNet等后训练技术,助你以最小成本创建属于自己的专属文生图模型,开启AI绘画创作之旅。
文生图(Text-to-Image)大模型是人工智能领域近年来最令人瞩目的突破之一。这类模型能够理解人类的自然语言描述,并据此生成高质量、富有创意的图像。从2022年Stable Diffusion开源以来,文生图技术经历了爆发式的发展,如今已经广泛应用于艺术创作、广告设计、游戏开发、影视制作等众多领域。
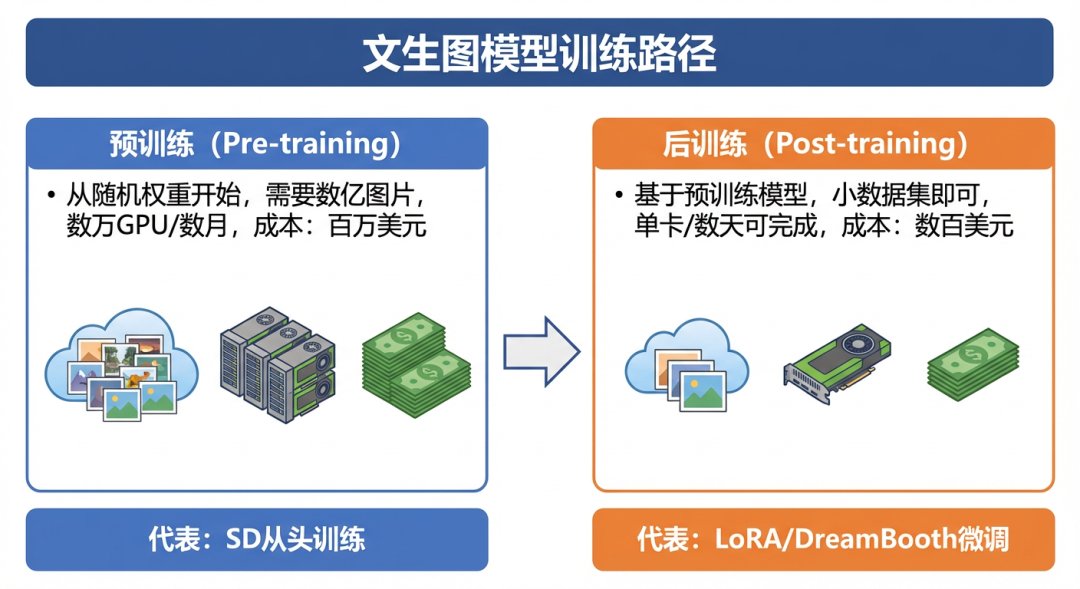
当我们谈论"训练自己的文生图模型"时,实际上存在两条截然不同的路径:预训练(Pre-training)和后训练(Post-training)。预训练是指从随机初始化的模型权重开始,使用海量数据(通常需要数亿张图片)从零开始训练整个模型。这种方式需要巨大的计算资源,例如Stable Diffusion的预训练使用了256块A100 GPU训练了数周时间,成本高达数百万美元,这对于个人开发者或小团队来说几乎是不可能完成的任务。
相比之下,后训练(Post-training)是一种更加务实和高效的方法。它基于已经预训练好的模型,通过微调(Fine-tuning)技术,让模型学习新的风格、概念或能力。这种方法只需要少量数据(几十到几千张图片),使用消费级显卡(如RTX 3090或RTX 4090)就能在数小时到数天内完成训练。本指南将专注于后训练技术,帮助你以最小的成本创建属于自己的专属文生图模型。
2.1 预训练与后训练的本质区别
要理解后训练的价值,我们首先需要了解预训练模型的本质。一个预训练好的文生图模型(如Stable Diffusion XL)已经从海量的图文数据中学习到了丰富的视觉知识:它理解什么是"猫"、什么是"日落"、什么是"油画风格"。这些通用知识被编码在模型的数十亿个参数中。
后训练的核心思想是:我们不需要重新教会模型所有的视觉知识,只需要在已有知识的基础上,教会它一些新的、特定的内容。这就像一个已经学会绘画基础的艺术家,只需要短期学习就能掌握一种新的绘画风格,而不需要从握笔开始重新学起。
2.2 扩散模型的工作原理
在深入后训练技术之前,有必要简要理解扩散模型(Diffusion Model)的工作原理,因为这直接关系到我们如何设计训练策略。
扩散模型的训练过程可以概括为两个阶段:
前向过程(Forward Process):逐步向一张清晰的图片添加高斯噪声,直到它变成完全的随机噪声。这个过程是确定性的,不需要学习。
反向过程(Reverse Process):训练一个神经网络(在Stable Diffusion中是UNet或DiT架构),学习如何从噪声中逐步恢复出原始图片。模型的任务是预测每一步应该去除的噪声。
训练的核心就是让模型学会"去噪"。在后训练中,我们利用特定风格或主题的图片,让模型学习这些特定内容的"去噪模式",从而使其能够生成类似风格或主题的新图片。
后训练方法 ├── 1. 全参数微调 (Full Fine-tuning) │ └── 更新所有参数,需要较多显存和数据 │ ├── 2. 参数高效微调 (PEFT) │ ├── LoRA (Low-Rank Adaptation) │ ├── LoHa / LoCon │ └── Adapter │ ├── 3. 个性化定制 │ ├── DreamBooth (学习新概念/人物) │ ├── Textual Inversion(学习新词嵌入) │ └── Custom Diffusion │ ├── 4. 条件控制训练 │ ├── ControlNet (姿态/边缘/深度控制) │ ├── T2I-Adapter │ └── IP-Adapter (图像提示) │ └── 5. 对齐优化 ├── RLHF (人类反馈强化学习) ├── DPO (直接偏好优化) └── ReFL (奖励反馈学习) 3.1 全参数微调(Full Fine-tuning)
全参数微调是最直接的后训练方法:加载预训练模型的所有权重,然后在新数据集上继续训练,更新所有参数。这种方法的优点是理论上能够实现最大程度的定制化,模型可以完全适应新的数据分布。
然而,全参数微调也存在显著的缺点。首先,它需要大量的显存,因为需要存储所有参数的梯度和优化器状态。对于SDXL这样拥有26亿参数的模型,全参数微调通常需要至少40GB显存。其次,全参数微调容易导致"灾难性遗忘"(Catastrophic Forgetting),即模型在学习新知识的同时忘记了原有的通用能力。最后,全参数微调产生的模型文件很大,不便于分享和部署。
3.2 LoRA:参数高效微调的明星技术
LoRA(Low-Rank Adaptation)是目前最流行的后训练技术,它巧妙地解决了全参数微调的诸多问题。LoRA的核心思想基于一个关键观察:在微调过程中,模型权重的变化往往是低秩的,即可以用两个小矩阵的乘积来近似。
具体来说,对于原始模型中的一个权重矩阵W(维度为d × k),LoRA不直接修改W,而是添加一个旁路:ΔW = A × B,其中A的维度是d × r,B的维度是r × k,r(称为秩)远小于d和k。这样,需要训练的参数数量从d × k大幅降低到 (d + k) × r。
LoRA的优势包括:
- 显存效率高
:只需要存储和更新少量参数,8GB显存即可训练SDXL
- 训练速度快
:参数量少意味着计算量小,训练更快
- 模型文件小
:典型的LoRA文件只有几十MB,便于分享
- 可组合性强
:多个LoRA可以叠加使用,实现风格混合
- 保留原始能力
:原始权重不变,不会灾难性遗忘
3.3 DreamBooth:个性化定制的利器
DreamBooth是Google在2022年提出的技术,专门用于教会模型识别和生成特定的人物、物体或概念。与LoRA侧重于学习整体风格不同,DreamBooth更适合学习具体的实例。
DreamBooth的工作原理是将新概念与一个稀有的"触发词"(如"sks")绑定。通过在少量包含该概念的图片上训练,模型学会将这个触发词与特定的视觉特征关联起来。之后,只要在提示词中包含这个触发词,模型就能生成包含该概念的图片。
DreamBooth特别适合以下场景:
- 创建个人或名人的AI肖像
- 学习特定产品的外观
- 定制宠物或角色形象
3.4 ControlNet:精确控制生成过程
ControlNet是一种条件控制技术,它不改变模型的基础生成能力,而是增加了额外的控制信号输入。通过ControlNet,用户可以使用边缘图、深度图、姿态骨架等作为生成的引导条件,实现对生成结果的精确控制。
ControlNet的架构设计非常巧妙:它复制了原始UNet的编码器部分,用于处理控制信号,然后将处理后的特征通过"零卷积"层注入到原始UNet中。这种设计既保留了原始模型的能力,又能有效融入控制信息。
4.1 硬件需求分析
选择合适的硬件是成功训练的基础。下表详细列出了不同训练方法的硬件需求:
需要特别说明的是,显存不足时可以通过以下技术来降低需求:
- 梯度检查点(Gradient Checkpointing)
:以计算时间换显存空间
- 混合精度训练(FP16/BF16)
:使用半精度浮点数
- 8bit优化器
:如bitsandbytes的AdamW8bit
- 梯度累积
:减小批量大小,累积多步梯度
4.2 软件环境搭建
一个稳定的软件环境是训练成功保障。以下是详细的环境配置步骤:
# 创建独立的虚拟环境,避免依赖冲突 conda create -n diffusion python=3.10 conda activate diffusion # 安装PyTorch(根据CUDA版本选择) # CUDA 11.8 pip install torch torchvision --index-url https://download.pytorch.org/whl/cu118 # CUDA 12.1 pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121 # 安装Hugging Face生态核心库 pip install diffusers transformers accelerate # 安装数据处理和监控工具 pip install datasets wandb tensorboard # 安装显存优化库 pip install bitsandbytes # 8bit优化器 pip install xformers # 高效注意力实现 # 克隆训练工具 git clone https://github.com/huggingface/diffusers git clone https://github.com/kohya-ss/sd-scripts # 社区最成熟的训练工具 环境配置完成后,建议运行以下代码验证安装是否正确:
import torch print(f"PyTorch版本: {torch.__version__}") print(f"CUDA可用: {torch.cuda.is_available()}") print(f"GPU型号: ") print(f"显存大小: GB") from diffusers import StableDiffusionXLPipeline print("Diffusers导入成功!") 选择合适的基础模型是后训练的第一个重要决策。目前主流的开源文生图模型各有特点:
# 主流开源基础模型对比分析 BASE_MODELS = , "SDXL": , "SD 3 Medium": , "Flux.1-dev": { "repo": "black-forest-labs/FLUX.1-dev", "resolution": 1024, "params": "12B", "pros": "当前开源SOTA,细节惊人", "cons": "资源需求高,训练工具不完善", "适用场景": "追求极致质量,资源充足" } } 对于初学者,我强烈建议从SDXL开始。它在质量、资源需求和生态成熟度之间达到了**平衡。SD 1.5虽然资源需求更低,但其512分辨率在当前已经显得过时。Flux虽然质量最好,但其12B的参数量对训练资源要求极高,且社区工具支持尚不完善。
数据集的质量直接决定了训练效果。“垃圾进,垃圾出”(Garbage In, Garbage Out)在机器学习中是永恒的真理。一个精心准备的小数据集,往往比一个粗糙的大数据集效果更好。
6.1 数据收集原则
数量要求:不同的训练目标需要不同数量的数据:
- 风格LoRA:50-200张高质量图片
- 人物DreamBooth:5-20张清晰照片
- 概念学习:20-50张包含该概念的图片
- 全参数微调:1000张以上
质量要求:
- 分辨率至少达到训练目标分辨率(如SDXL需要1024x1024)
- 图片清晰,无模糊、噪点或压缩伪影
- 主题明确,避免过于杂乱的背景
- 风格一致(如果目标是学习特定风格)
多样性要求:
- 包含不同的角度、光照条件
- 涵盖概念的不同变体
- 避免过于重复的构图
6.2 数据处理流程
以下是一个完整的数据处理流程,包括图片预处理和自动标注:
import os from PIL import Image from transformers import BlipProcessor, BlipForConditionalGeneration import torch classDatasetPreparer: """ 数据集准备工具类 功能: 1. 图片尺寸调整和质量优化 2. 自动生成图片描述(caption) 3. 数据集格式整理 """ def__init__(self, image_dir, output_dir, target_size=1024): """ 初始化数据集准备器 Args: image_dir: 原始图片目录 output_dir: 处理后的输出目录 target_size: 目标图片尺寸 """ self.image_dir = image_dir self.output_dir = output_dir self.target_size = target_size # 加载自动标注模型BLIP # BLIP是一个强大的图像描述模型,能够生成准确的图片描述 print("正在加载图像描述模型...") self.processor = BlipProcessor.from_pretrained( "Salesforce/blip-image-captioning-large" ) self.captioner = BlipForConditionalGeneration.from_pretrained( "Salesforce/blip-image-captioning-large" ).to("cuda"if torch.cuda.is_available() else"cpu") print("模型加载完成!") defprocess_all_images(self): """处理目录下的所有图片""" os.makedirs(self.output_dir, exist_ok=True) # 支持的图片格式 supported_formats = ('.jpg', '.jpeg', '.png', '.webp', '.bmp') image_files = [f for f in os.listdir(self.image_dir) if f.lower().endswith(supported_formats)] print(f"发现 {len(image_files)} 张图片待处理") for idx, img_name inenumerate(image_files): print(f"处理中: [{idx+1}/{len(image_files)}] {img_name}") img_path = os.path.join(self.image_dir, img_name) try: # 加载并处理图片 image = Image.open(img_path).convert("RGB") # 1. 调整尺寸 image = self.resize_image(image) # 2. 生成描述 caption = self.generate_caption(image) # 3. 保存结果 base_name = os.path.splitext(img_name)[0] image.save(os.path.join(self.output_dir, f"{base_name}.png"), quality=95) withopen(os.path.join(self.output_dir, f"{base_name}.txt"), 'w', encoding='utf-8') as f: f.write(caption) print(f" 描述: {caption[:50]}...") except Exception as e: print(f" 处理失败: {e}") print(f" 处理完成! 输出目录: {self.output_dir}") defresize_image(self, image): """ 等比例缩放图片 保持图片比例,将最长边缩放到目标尺寸 同时确保尺寸是64的倍数(扩散模型的要求) """ w, h = image.size # 计算缩放比例 ratio = self.target_size / max(w, h) new_w = int(w * ratio) new_h = int(h * ratio) # 确保是64的倍数(VAE编码要求) new_w = (new_w // 64) * 64 new_h = (new_h // 64) * 64 # 使用高质量的Lanczos重采样 return image.resize((new_w, new_h), Image.LANCZOS) defgenerate_caption(self, image): """ 使用BLIP模型生成图片描述 这是自动标注的核心功能,生成的描述将作为训练时的文本条件 """ device = "cuda"if torch.cuda.is_available() else"cpu" # 预处理图片 inputs = self.processor(image, return_tensors="pt").to(device) # 生成描述 with torch.no_grad(): output = self.captioner.generate( inputs, max_length=75, # 限制长度,避免过长 num_beams=5, # 使用束搜索提高质量 early_stopping=True ) caption = self.processor.decode(output[0], skip_special_tokens=True) return caption # 使用示例 if __name__ == "__main__": preparer = DatasetPreparer( image_dir="./raw_images", # 原始图片目录 output_dir="./processed_dataset", # 输出目录 target_size=1024# SDXL需要1024分辨率 ) preparer.process_all_images() 6.3 Caption优化技巧
自动生成的caption通常需要手动优化以获得更好的训练效果。以下是一些实用的优化建议:
1. 添加触发词:在caption开头添加一个独特的触发词,便于后续调用
# 原始: a beautiful sunset over mountains # 优化: my_style, a beautiful sunset over mountains 2. 增加细节描述:补充风格、质量等关键词
# 优化后: my_style, a beautiful sunset over mountains, # golden hour lighting, vibrant colors, # professional photography, 8k uhd 3. 使用标签式描述:对于动漫风格,标签式描述效果更好
# 标签式: 1girl, solo, long hair, blue eyes, school uniform, # standing, smile, looking at viewer, outdoor 6.4 数据集目录结构
处理完成后,你的数据集应该呈现如下结构:
processed_dataset/ ├── image_001.png ├── image_001.txt # "a beautiful sunset over mountains, orange sky, ..." ├── image_002.png ├── image_002.txt # "portrait of a woman, professional photo, ..." ├── image_003.png ├── image_003.txt └── ... 每张图片都有一个同名的txt文件,包含对应的文字描述。这是大多数训练工具(包括Kohya_ss和diffusers)所采用的标准格式。
LoRA是目前最受欢迎的后训练方法,它在效果和效率之间达到了极佳的平衡。以下是一个完整的SDXL LoRA训练代码实现,包含详细的注释说明:
# train_lora.py """ SDXL LoRA训练脚本 本脚本实现了完整的LoRA训练流程,包括: 1. 模型加载和LoRA配置 2. 数据集处理 3. 训练循环 4. 检查点保存 使用方法: python train_lora.py 注意事项: - 确保有足够的显存(建议12GB+) - 数据集目录应包含.png图片和对应的.txt描述文件 """ import torch import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader from diffusers import AutoencoderKL, UNet2DConditionModel, DDPMScheduler from transformers import CLIPTextModel, CLIPTokenizer, CLIPTextModelWithProjection from peft import LoraConfig, get_peft_model from PIL import Image import numpy as np import os from tqdm import tqdm classTextImageDataset(Dataset): """ 文本-图像配对数据集 读取指定目录下的图片和对应的文本描述文件, 将它们组织成训练所需的格式。 """ def__init__(self, data_dir, tokenizer, tokenizer_2, size=1024): self.data_dir = data_dir self.tokenizer = tokenizer self.tokenizer_2 = tokenizer_2 self.size = size # 收集所有图片文件 self.images = [f for f in os.listdir(data_dir) if f.endswith(('.png', '.jpg', '.jpeg'))] print(f"数据集加载完成,共 {len(self.images)} 张图片") def__len__(self): returnlen(self.images) def__getitem__(self, idx): img_name = self.images[idx] img_path = os.path.join(self.data_dir, img_name) # 对应的文本文件 txt_name = os.path.splitext(img_name)[0] + '.txt' txt_path = os.path.join(self.data_dir, txt_name) # 加载并预处理图片 image = Image.open(img_path).convert("RGB") image = image.resize((self.size, self.size), Image.LANCZOS) # 转换为tensor并归一化到[-1, 1] image = np.array(image).astype(np.float32) image = (image / 127.5) - 1.0 image = torch.from_numpy(image).permute(2, 0, 1) # 加载文本描述 withopen(txt_path, 'r', encoding='utf-8') as f: text = f.read().strip() return {"image": image, "text": text} deftrain_lora(): """主训练函数""" # ==================== 配置参数 ==================== config = # 设置随机种子以确保可复现性 torch.manual_seed(config["seed"]) # ==================== 加载模型组件 ==================== print("正在加载模型组件...") # 加载分词器(SDXL使用两个CLIP文本编码器) tokenizer = CLIPTokenizer.from_pretrained( config["model_name"], subfolder="tokenizer" ) tokenizer_2 = CLIPTokenizer.from_pretrained( config["model_name"], subfolder="tokenizer_2" ) # 加载文本编码器 text_encoder = CLIPTextModel.from_pretrained( config["model_name"], subfolder="text_encoder" ) text_encoder_2 = CLIPTextModelWithProjection.from_pretrained( config["model_name"], subfolder="text_encoder_2" ) # 加载VAE(变分自编码器,用于图片编解码) vae = AutoencoderKL.from_pretrained( config["model_name"], subfolder="vae" ) # 加载UNet(扩散模型的核心) unet = UNet2DConditionModel.from_pretrained( config["model_name"], subfolder="unet" ) # 加载噪声调度器 noise_scheduler = DDPMScheduler.from_pretrained( config["model_name"], subfolder="scheduler" ) print("模型加载完成!") # ==================== 配置LoRA ==================== # 冻结不需要训练的组件 vae.requires_grad_(False) text_encoder.requires_grad_(False) text_encoder_2.requires_grad_(False) # 定义LoRA配置 # target_modules指定要应用LoRA的层 lora_config = LoraConfig( r=config["lora_rank"], lora_alpha=config["lora_alpha"], init_lora_weights="gaussian", target_modules=[ # Attention层 "to_k", "to_q", "to_v", "to_out.0", # 投影层 "proj_in", "proj_out", # 前馈网络 "ff.net.0.proj", "ff.net.2", ], ) # 将LoRA应用到UNet unet = get_peft_model(unet, lora_config) # 打印可训练参数信息 unet.print_trainable_parameters() # 输出类似: trainable params: 28,311,552 || all params: 2,567,979,012 || trainable%: 1.10% # ==================== 移动到GPU ==================== device = "cuda"if torch.cuda.is_available() else"cpu" dtype = torch.float16 if config["mixed_precision"] == "fp16"else torch.float32 unet.to(device, dtype=dtype) vae.to(device, dtype=dtype) text_encoder.to(device, dtype=dtype) text_encoder_2.to(device, dtype=dtype) # ==================== 准备数据集 ==================== dataset = TextImageDataset( config["data_dir"], tokenizer, tokenizer_2, size=config["resolution"] ) dataloader = DataLoader( dataset, batch_size=config["batch_size"], shuffle=True, num_workers=2, pin_memory=True ) # ==================== 配置优化器 ==================== optimizer = torch.optim.AdamW( unet.parameters(), lr=config["learning_rate"], betas=(0.9, 0.999), weight_decay=1e-2, eps=1e-8 ) # 学习率调度器(可选,这里使用余弦退火) from torch.optim.lr_scheduler import CosineAnnealingLR total_steps = len(dataloader) * config["num_epochs"] scheduler = CosineAnnealingLR(optimizer, T_max=total_steps, eta_min=1e-6) # ==================== 训练循环 ==================== os.makedirs(config["output_dir"], exist_ok=True) global_step = 0 print("开始训练...") for epoch inrange(config["num_epochs"]): unet.train() epoch_loss = 0.0 progress_bar = tqdm(dataloader, desc=f"Epoch {epoch+1}/{config['num_epochs']}") for batch in progress_bar: # ---------- 1. 编码图片到潜空间 ---------- with torch.no_grad(): # VAE将512x512的图片编码为64x64的潜在表示 pixel_values = batch["image"].to(device, dtype=dtype) latents = vae.encode(pixel_values).latent_dist.sample() latents = latents * vae.config.scaling_factor # ---------- 2. 编码文本 ---------- with torch.no_grad(): # 第一个文本编码器 text_input_ids = tokenizer( batch["text"], padding="max_length", max_length=77, truncation=True, return_tensors="pt" ).input_ids.to(device) encoder_hidden_states_1 = text_encoder( text_input_ids, output_hidden_states=True ).hidden_states[-2] # 第二个文本编码器 text_input_ids_2 = tokenizer_2( batch["text"], padding="max_length", max_length=77, truncation=True, return_tensors="pt" ).input_ids.to(device) encoder_output_2 = text_encoder_2( text_input_ids_2, output_hidden_states=True ) encoder_hidden_states_2 = encoder_output_2.hidden_states[-2] pooled_prompt_embeds = encoder_output_2.text_embeds # SDXL需要concatenate两个编码器的输出 encoder_hidden_states = torch.cat( [encoder_hidden_states_1, encoder_hidden_states_2], dim=-1 ) # ---------- 3. 添加噪声 ---------- # 采样随机噪声 noise = torch.randn_like(latents) # 采样随机时间步 bsz = latents.shape[0] timesteps = torch.randint( 0, noise_scheduler.config.num_train_timesteps, (bsz,), device=device ).long() # 根据时间步添加噪声 noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps) # ---------- 4. SDXL额外条件 ---------- # 准备SDXL需要的额外嵌入 add_time_ids = torch.tensor([ [config["resolution"], config["resolution"], 0, 0, config["resolution"], config["resolution"]] ], device=device).repeat(bsz, 1) added_cond_kwargs = { "text_embeds": pooled_prompt_embeds, "time_ids": add_time_ids } # ---------- 5. 前向传播预测噪声 ---------- with torch.cuda.amp.autocast(dtype=dtype): noise_pred = unet( noisy_latents, timesteps, encoder_hidden_states=encoder_hidden_states, added_cond_kwargs=added_cond_kwargs, ).sample # ---------- 6. 计算损失 ---------- # 使用MSE损失,比较预测的噪声和真实噪声 loss = F.mse_loss(noise_pred.float(), noise.float(), reduction="mean") # ---------- 7. 反向传播 ---------- loss = loss / config["gradient_accumulation_steps"] loss.backward() # 梯度累积 if (global_step + 1) % config["gradient_accumulation_steps"] == 0: # 梯度裁剪,防止梯度爆炸 torch.nn.utils.clip_grad_norm_(unet.parameters(), 1.0) optimizer.step() scheduler.step() optimizer.zero_grad() # ---------- 8. 记录和保存 ---------- global_step += 1 epoch_loss += loss.item() * config["gradient_accumulation_steps"] progress_bar.set_postfix({ "loss": f"{loss.item() * config['gradient_accumulation_steps']:.4f}", "lr": f"" }) # 定期保存检查点 if global_step % config["save_every"] == 0: save_path = os.path.join( config["output_dir"], f"checkpoint-{global_step}" ) unet.save_pretrained(save_path) print(f" 检查点已保存到: {save_path}") # 每个epoch结束时的统计 avg_loss = epoch_loss / len(dataloader) print(f"Epoch {epoch+1} 完成, 平均损失: {avg_loss:.4f}") # ==================== 保存最终模型 ==================== final_save_path = os.path.join(config["output_dir"], "final_model") unet.save_pretrained(final_save_path) print(f" 训练完成! 最终模型已保存到: {final_save_path}") if __name__ == "__main__": train_lora() DreamBooth是另一种重要的后训练技术,特别适合学习特定的人物、宠物或物体。与LoRA侧重于学习整体风格不同,DreamBooth更擅长让模型记住具体的视觉实例。
8.1 DreamBooth的工作原理
DreamBooth的核心思想是将新概念与一个稀有的标识符(identifier)绑定。这个标识符通常是一个在自然语言中很少出现的词,如"sks"、"xyz"等。通过在少量(通常5-20张)包含目标概念的图片上训练,模型学会将这个标识符与特定的视觉特征关联起来。
训练完成后,只需在提示词中包含这个标识符,模型就能生成包含该概念的图片。例如,训练了一个人物后,可以使用"a photo of sks person wearing a spacesuit on Mars"来生成该人物在火星上的图片。
8.2 DreamBooth数据准备
DreamBooth对数据的质量要求很高,但数量要求很低。以下是准备数据的要点:
my_photos/ ├── photo1.jpg # 5-10张高质量照片即可 ├── photo2.jpg # 不同角度、光线、表情 ├── photo3.jpg # 清晰、主体明确 ├── photo4.jpg # 避免遮挡、避免极端角度 └── photo5.jpg # 背景尽量简单多样 关键要求: 1. 照片数量: 5-20张 2. 照片质量: 清晰、光线良好 3. 多样性: 不同角度、表情、光照 4. 一致性: 同一个主体,不要混入其他人/物 8.3 使用Diffusers训练DreamBooth
Hugging Face的Diffusers库提供了完善的DreamBooth训练脚本。以下是完整的训练命令和参数说明:
# 使用accelerate启动分布式训练 accelerate launch diffusers/examples/dreambooth/train_dreambooth_lora_sdxl.py # === 模型配置 === --pretrained_model_name_or_path="stabilityai/stable-diffusion-xl-base-1.0" # === 数据配置 === --instance_data_dir="./my_photos" # 训练图片目录 --instance_prompt="a photo of sks person" # 包含触发词的提示 # === 输出配置 === --output_dir="./dreambooth_output" # === 训练参数 === --resolution=1024 # SDXL需要1024分辨率 --train_batch_size=1 # 批量大小 --gradient_accumulation_steps=4 # 梯度累积 --learning_rate=1e-4 # 学习率 --lr_scheduler="constant" # 学习率调度 --lr_warmup_steps=0 # 预热步数 --max_train_steps=500 # 最大训练步数 # === LoRA配置 === --rank=32 # LoRA秩 # === 其他配置 === --seed=42 # 随机种子 --mixed_precision="fp16" # 混合精度 --enable_xformers_memory_efficient_attention # 显存优化 8.4 正则化技术
DreamBooth训练中一个常见的问题是语言漂移(Language Drift):模型过度拟合训练图片,导致相关词汇的语义被破坏。例如,训练一个人物后,所有"person"都可能变成那个人。
为了解决这个问题,DreamBooth引入了先验保持损失(Prior Preservation Loss)。具体做法是,在训练时同时生成一些通用的类别图片(如一般的人脸),确保模型不会忘记类别的一般特征。
# 启用先验保持 accelerate launch train_dreambooth_lora_sdxl.py --with_prior_preservation # 启用先验保持 --prior_loss_weight=1.0 # 先验损失权重 --class_data_dir="./class_images" # 类别图片目录 --class_prompt="a photo of a person" # 类别提示(不含触发词) --num_class_images=200 # 类别图片数量 ControlNet是一种强大的条件控制技术,它允许用户通过边缘图、深度图、姿态骨架等额外输入来精确控制图像生成过程。训练自定义ControlNet需要更多的数据和计算资源,但可以实现非常专业的控制效果。
9.1 ControlNet架构原理
ControlNet的设计非常巧妙。它不是直接修改原始的UNet,而是创建一个可训练的副本来处理控制信号。具体来说:
- 复制编码器
:将原始UNet的编码器部分复制一份,用于处理控制信号
- 零卷积连接
:使用初始化为零的卷积层(“零卷积”)将ControlNet的输出连接到原始UNet
- 特征注入
:训练后的ControlNet产生的特征被注入到UNet的各个层级
这种设计的优点是:训练开始时,由于零卷积的存在,ControlNet对输出没有任何影响,模型保持原有的生成能力;随着训练进行,ControlNet逐渐学会如何根据控制信号调制生成过程。
9.2 ControlNet训练代码
# train_controlnet.py """ ControlNet训练脚本 ControlNet允许通过额外的控制信号(如边缘图、深度图、姿态) 来精确控制图像生成过程。 """ import torch import torch.nn.functional as F from diffusers import ControlNetModel, AutoencoderKL, UNet2DConditionModel from transformers import CLIPTextModel, CLIPTokenizer deftrain_controlnet(): """训练自定义ControlNet""" # 配置 config = # 加载基础模型组件 unet = UNet2DConditionModel.from_pretrained( config["model_name"], subfolder="unet" ) vae = AutoencoderKL.from_pretrained( config["model_name"], subfolder="vae" ) text_encoder = CLIPTextModel.from_pretrained( config["model_name"], subfolder="text_encoder" ) # ========== 初始化ControlNet ========== # ControlNet从UNet初始化,复制其编码器结构 controlnet = ControlNetModel.from_unet( unet, conditioning_channels=3, # 控制信号的通道数(RGB=3) ) # 冻结基础模型,只训练ControlNet unet.requires_grad_(False) vae.requires_grad_(False) text_encoder.requires_grad_(False) controlnet.requires_grad_(True) # 移动到GPU device = "cuda" unet.to(device, dtype=torch.float16) vae.to(device, dtype=torch.float16) text_encoder.to(device, dtype=torch.float16) controlnet.to(device, dtype=torch.float16) # 优化器 optimizer = torch.optim.AdamW( controlnet.parameters(), lr=config["learning_rate"] ) # ========== 训练循环 ========== for epoch inrange(config["num_epochs"]): for batch in dataloader: # batch包含: # - image: 目标图片 # - text: 文本描述 # - control_image: 控制图(边缘/深度/姿态) with torch.no_grad(): # 编码图片到潜空间 latents = vae.encode(batch["image"]).latent_dist.sample() latents = latents * vae.config.scaling_factor # 编码文本 encoder_hidden_states = encode_text(batch["text"]) # 添加噪声 noise = torch.randn_like(latents) batch_size = latents.shape[0] timesteps = torch.randint(0, 1000, (batch_size,), device=device) noisy_latents = scheduler.add_noise(latents, noise, timesteps) # ========== ControlNet前向传播 ========== # 处理控制信号,生成特征注入 down_block_res_samples, mid_block_res_sample = controlnet( noisy_latents, timesteps, encoder_hidden_states=encoder_hidden_states, controlnet_cond=batch["control_image"], # 控制图 return_dict=False, ) # ========== UNet前向传播(带ControlNet特征注入)========== noise_pred = unet( noisy_latents, timesteps, encoder_hidden_states=encoder_hidden_states, # 注入ControlNet产生的特征 down_block_additional_residuals=down_block_res_samples, mid_block_additional_residual=mid_block_res_sample, ).sample # 计算损失 loss = F.mse_loss(noise_pred, noise) # 反向传播 optimizer.zero_grad() loss.backward() optimizer.step() # 保存模型 controlnet.save_pretrained(config["output_dir"]) 9.3 ControlNet数据集准备
ControlNet训练需要配对的数据:原始图片、控制图和文本描述。以下是准备边缘检测ControlNet数据集的示例:
import cv2 import numpy as np from PIL import Image defprepare_canny_dataset(image_dir, output_dir): """为Canny边缘ControlNet准备数据集""" for img_name in os.listdir(image_dir): img_path = os.path.join(image_dir, img_name) image = cv2.imread(img_path) # 生成Canny边缘图 edges = cv2.Canny(image, 100, 200) edges = cv2.cvtColor(edges, cv2.COLOR_GRAY2RGB) # 保存原图、边缘图 base_name = os.path.splitext(img_name)[0] cv2.imwrite(f"{output_dir}/images/{base_name}.png", image) cv2.imwrite(f"{output_dir}/conditioning/{base_name}.png", edges) 随着文生图模型在商业场景的广泛应用,如何让模型生成更符合人类偏好的图片变得越来越重要。RLHF(基于人类反馈的强化学习)和DPO(直接偏好优化)是两种主要的对齐技术。
10.1 为什么需要对齐训练
预训练和常规微调的优化目标是重建损失——让模型学会准确复现训练数据中的图片。然而,这个目标与"生成人类喜欢的图片"并不完全一致。例如:
- 模型可能生成技术上"正确"但审美上不佳的图片
- 模型可能无法理解某些细微的风格偏好
- 模型可能生成不适当或有偏见的内容
对齐训练的目标是直接优化"人类偏好"这一指标,让模型学会生成人们真正喜欢的图片。
10.2 DPO:直接偏好优化
DPO是一种比RLHF更简洁高效的对齐方法。它不需要训练单独的奖励模型,而是直接从偏好对数据中学习。
DPO的核心思想是:给定一个提示和两张生成的图片(一张是人类偏好的"chosen",另一张是不偏好的"rejected"),优化模型使其更倾向于生成chosen类型的图片。
# DPO训练示例 classDPOTrainer: """ 直接偏好优化训练器 DPO直接从偏好对中学习,无需显式的奖励模型 """ def__init__(self, model, ref_model, beta=0.1): """ Args: model: 待训练的模型 ref_model: 参考模型(冻结,用于计算KL散度) beta: 温度参数,控制偏好学习的强度 """ self.model = model self.ref_model = ref_model self.ref_model.requires_grad_(False) # 冻结参考模型 self.beta = beta defcompute_dpo_loss(self, prompt, chosen_image, rejected_image): """ 计算DPO损失 Args: prompt: 文本提示 chosen_image: 人类偏好的图片 rejected_image: 人类不偏好的图片 Returns: DPO损失值 """ # 计算模型对两张图片的对数概率 chosen_logp = self.get_log_prob(self.model, prompt, chosen_image) rejected_logp = self.get_log_prob(self.model, prompt, rejected_image) # 计算参考模型的对数概率(用于防止模型偏离太远) with torch.no_grad(): ref_chosen_logp = self.get_log_prob(self.ref_model, prompt, chosen_image) ref_rejected_logp = self.get_log_prob(self.ref_model, prompt, rejected_image) # 计算相对于参考模型的隐式奖励 chosen_reward = self.beta * (chosen_logp - ref_chosen_logp) rejected_reward = self.beta * (rejected_logp - ref_rejected_logp) # DPO损失:最大化chosen和rejected奖励的差距 loss = -F.logsigmoid(chosen_reward - rejected_reward).mean() return loss defget_log_prob(self, model, prompt, image): """ 计算生成给定图片的对数概率 这需要在整个扩散过程中累积每一步的对数概率 """ # 将图片编码到潜空间 latent = vae.encode(image).latent_dist.sample() latent = latent * vae.config.scaling_factor # 编码文本 encoder_hidden_states = encode_text(prompt) total_log_prob = 0.0 # 遍历扩散过程的每一步 for t inreversed(range(self.num_timesteps)): timestep = torch.tensor([t], device=latent.device) # 获取当前时间步的噪声预测 with torch.cuda.amp.autocast(): noise_pred = model(latent, timestep, encoder_hidden_states).sample # 计算这一步的对数概率 # 这涉及到扩散过程的数学推导 step_log_prob = self.compute_step_log_prob(latent, noise_pred, t) total_log_prob += step_log_prob # 执行反向扩散步骤 latent = self.scheduler.step(noise_pred, t, latent).prev_sample return total_log_prob 10.3 准备偏好数据
DPO训练需要偏好对数据,即对于同一个提示,收集"好"和"不好"的图片对。这可以通过以下方式获得:
- 人工标注
:让人类标注者比较同一提示生成的多张图片
- AI辅助
:使用图像质量评估模型(如ImageReward)进行初步筛选
- 众包平台
:使用Amazon Mechanical Turk等平台收集大规模偏好数据
Kohya_ss是目前社区中最成熟、功能最完善的Stable Diffusion训练工具。它提供了丰富的训练选项和优化技术,支持LoRA、DreamBooth、全参数微调等多种训练方式。
11.1 安装和配置
# 克隆仓库 git clone https://github.com/kohya-ss/sd-scripts cd sd-scripts # 安装依赖 pip install -r requirements.txt # 安装加速库 pip install accelerate accelerate config # 配置分布式训练(可选) 11.2 配置文件详解
Kohya_ss使用TOML格式的配置文件,以下是一个完整的SDXL LoRA训练配置示例:
# config.toml - SDXL LoRA训练配置 # ===== 模型配置 ===== [model] pretrained_model_name_or_path = "stabilityai/stable-diffusion-xl-base-1.0" # v2 = false # SD2.x模型设为true # v_parameterization = false # SD2.x v-prediction设为true # ===== 输出配置 ===== [output] output_dir = "./output" output_name = "my_character_lora" save_model_as = "safetensors"# 推荐使用safetensors格式 save_every_n_epochs = 1# 每个epoch保存一次 save_every_n_steps = 0# 或者每N步保存一次 # ===== 训练参数 ===== [train] train_batch_size = 1 max_train_epochs = 10 # max_train_steps = 1000 # 或者指定总步数 gradient_accumulation_steps = 4# 梯度累积,等效增大批量 gradient_checkpointing = true# 显存不足时启用 mixed_precision = "fp16"# 或 "bf16" seed = 42 # ===== 数据集配置 ===== [dataset] train_data_dir = "./dataset" resolution = "1024,1024"# SDXL分辨率 caption_extension = ".txt"# 描述文件扩展名 shuffle_caption = false# 是否打乱描述中的标签顺序 keep_tokens = 1# 保持前N个标签不变 color_aug = false# 颜色增强 flip_aug = false# 水平翻转增强 random_crop = false# 随机裁剪 # ===== LoRA网络配置 ===== [network] network_module = "networks.lora" network_dim = 32# LoRA维度(秩) network_alpha = 16# LoRA alpha,通常设为dim的一半 # network_weights = "" # 从已有LoRA继续训练 # ===== 优化器配置 ===== [optimizer] optimizer_type = "AdamW8bit"# 8bit优化器节省显存 # 其他选项: AdamW, Lion, Prodigy, DAdaptation learning_rate = 1e-4 unet_lr = 1e-4# UNet学习率(可单独设置) text_encoder_lr = 5e-5# 文本编码器学习率 lr_scheduler = "cosine_with_restarts" lr_warmup_steps = 100 lr_scheduler_num_cycles = 1 # ===== 高级配置 ===== [advanced] min_snr_gamma = 5.0# Min-SNR加权,提升训练稳定性 noise_offset = 0.0# 噪声偏移,改善暗部/亮部 adaptive_noise_scale = 0.0# 自适应噪声 clip_skip = 2# CLIP跳过层数 max_token_length = 225# 最大token长度 11.3 运行训练
# 使用accelerate启动训练 accelerate launch --num_cpu_threads_per_process=2 sdxl_train_network.py --config_file="config.toml" # 或者直接运行(单GPU) python sdxl_train_network.py --config_file="config.toml" 11.4 常用参数调优建议
有效的训练监控是确保训练成功的关键。它能帮助你及时发现问题、调整参数,并在**时刻停止训练。
12.1 使用Weights & Biases监控
Weights & Biases(wandb)是最流行的机器学习实验跟踪工具之一,提供了强大的可视化和比较功能。
import wandb from PIL import Image # 初始化wandb项目 wandb.init( project="text2img-training", name="lora-v1-character", config={ "model": "SDXL", "method": "LoRA", "rank": 32, "learning_rate": 1e-4, "epochs": 100, } ) # 在训练循环中记录指标 for step, batch inenumerate(dataloader): # ... 训练代码 ... # 记录标量指标 wandb.log() # 定期生成并记录样本图片 if step % 500 == 0: with torch.no_grad(): # 使用固定的提示词生成样本 test_prompts = [ "a portrait of sks person, professional photo", "sks person wearing a red dress, fashion photography", "sks person in a garden, natural lighting", ] samples = [] for prompt in test_prompts: image = pipeline(prompt, num_inference_steps=30).images[0] samples.append(wandb.Image(image, caption=prompt)) wandb.log({"samples": samples}) # 训练结束时 wandb.finish() 12.2 关键指标解读
- 训练损失(Loss)
-
- 应该整体呈下降趋势
- 如果loss突然上升或剧烈震荡,可能学习率过高
- 如果loss下降后长时间不再下降,可能需要降低学习率
- 生成样本质量
-
- 定期检查生成的样本图片
- 关注目标特征是否被正确学习
- 警惕过拟合迹象(如背景重复、姿态固定)
- 学习率曲线
-
- 确保学习率按预期变化
- 余弦退火等调度策略能有效防止过拟合
12.3 过拟合与欠拟合
训练完成后,你需要知道如何正确加载和使用你的模型。
13.1 加载LoRA模型
from diffusers import StableDiffusionXLPipeline, DPMSolverMultistepScheduler import torch # 加载基础模型 pipe = StableDiffusionXLPipeline.from_pretrained( "stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True, ).to("cuda") # 使用更快的调度器 pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config) # 加载训练好的LoRA权重 pipe.load_lora_weights( "./lora_output", # LoRA目录 weight_name="pytorch_lora_weights.safetensors"# 权重文件名 ) # 可以调整LoRA的影响强度 pipe.fuse_lora(lora_scale=0.8) # 0-1之间,1为完全应用 # 生成图片 image = pipe( prompt="a portrait of sks person, professional headshot, studio lighting", negative_prompt="blurry, low quality, distorted", num_inference_steps=30, guidance_scale=7.5, width=1024, height=1024, ).images[0] image.save("generated_portrait.png") 13.2 多LoRA组合使用
LoRA的一个强大特性是可以组合多个LoRA,实现风格混合。
# 加载多个LoRA pipe.load_lora_weights("./style_lora", adapter_name="style") pipe.load_lora_weights("./character_lora", adapter_name="character") # 设置各LoRA的权重 pipe.set_adapters( ["style", "character"], adapter_weights=[0.7, 0.9] # 风格权重0.7,人物权重0.9 ) # 生成 image = pipe("...").images[0] 13.3 模型导出与分享
# 将LoRA保存为标准格式 from safetensors.torch import save_file # 导出为Civitai等平台支持的格式 lora_state_dict = pipe.unet.get_lora_state_dict() save_file(lora_state_dict, "my_lora_for_sharing.safetensors") # 添加元数据(可选) metadata = { "modelspec.title": "My Character LoRA", "modelspec.author": "Your Name", "modelspec.description": "A LoRA trained on my character", } save_file(lora_state_dict, "my_lora.safetensors", metadata=metadata) 在训练过程中,你可能会遇到各种问题。以下是一些常见问题及其解决方案:
14.1 显存不足(OOM)
症状:CUDA out of memory错误
解决方案:
# 1. 启用梯度检查点 unet.enable_gradient_checkpointing() # 2. 减小批量大小,增加梯度累积 config["batch_size"] = 1 config["gradient_accumulation_steps"] = 8 # 3. 使用8bit优化器 from bitsandbytes.optim import AdamW8bit optimizer = AdamW8bit(unet.parameters(), lr=1e-4) # 4. 降低分辨率(不推荐,会影响质量) # 5. 使用xformers高效注意力 pip install xformers unet.enable_xformers_memory_efficient_attention() 14.2 训练损失不下降
可能原因及解决方案:
- 学习率过低:尝试提高学习率
- 数据集问题:检查图片和caption是否正确配对
- 模型冻结问题:确保正确的参数被设为可训练
14.3 生成质量差
可能原因及解决方案:
- 训练不足:增加训练步数
- 过拟合:减少训练步数,增加数据多样性
- LoRA维度太低:提高network_dim
- Caption质量差:优化训练数据的描述
14.4 人物脸部变形
这是人物LoRA常见的问题,解决方案包括:
- 使用更高质量的训练图片
- 启用min_snr_gamma=5
- 使用面部增强数据集
- 减小学习率
从LoRA的基础训练到DreamBooth的个性化定制,从ControlNet的条件控制到RLHF/DPO的对齐优化,每种技术都有其独特的应用场景和价值。记住,成功的模型训练不仅需要技术知识,更需要大量的实践和经验积累。建议你从简单的项目开始,逐步增加复杂度,在实践中不断学习和成长。祝你训练顺利,创造出属于自己的精彩模型!
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线科技企业深耕十二载,见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我们整理出这套 AI 大模型突围资料包:
- ✅ 从零到一的 AI 学习路径图
- ✅ 大模型调优实战手册(附医疗/金融等大厂真实案例)
- ✅ 百度/阿里专家闭门录播课
- ✅ 大模型当下最新行业报告
- ✅ 真实大厂面试真题
- ✅ 2026 最新岗位需求图谱
所有资料 ⚡️ ,朋友们如果有需要 《AI大模型入门+进阶学习资源包》,下方扫码获取~

(包含提示工程、RAG、LangChain、Agent、模型微调与部署、DeepSeek等技术点)

作为学习AI大模型技术的新手,方向至关重要。 正确的学习路线可以为你节省时间,少走弯路;方向不对,努力白费。这里我给大家准备了一份最科学最系统的学习成长路线图和学习规划,带你从零基础入门到精通!

学习AI大模型离不开书籍文档,我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。

2025最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

学以致用,在项目实战中检验和巩固你所学到的知识,同时为你找工作就业和职业发展打下坚实的基础。

面试不仅是技术的较量,更需要充分的准备。在你已经掌握了大模型技术之后,就需要开始准备面试,我精心整理了一份大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。


最近科技巨头英特尔宣布裁员2万人,传统岗位不断缩减,但AI相关技术岗疯狂扩招,有3-5年经验,大厂薪资就能给到50K*20薪!

不出1年,“有AI项目经验”将成为投递简历的门槛。
风口之下,与其像“温水煮青蛙”一样坐等被行业淘汰,不如先人一步,掌握AI大模型原理+应用技术+项目实操经验,“顺风”翻盘!


这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。



版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/253576.html