
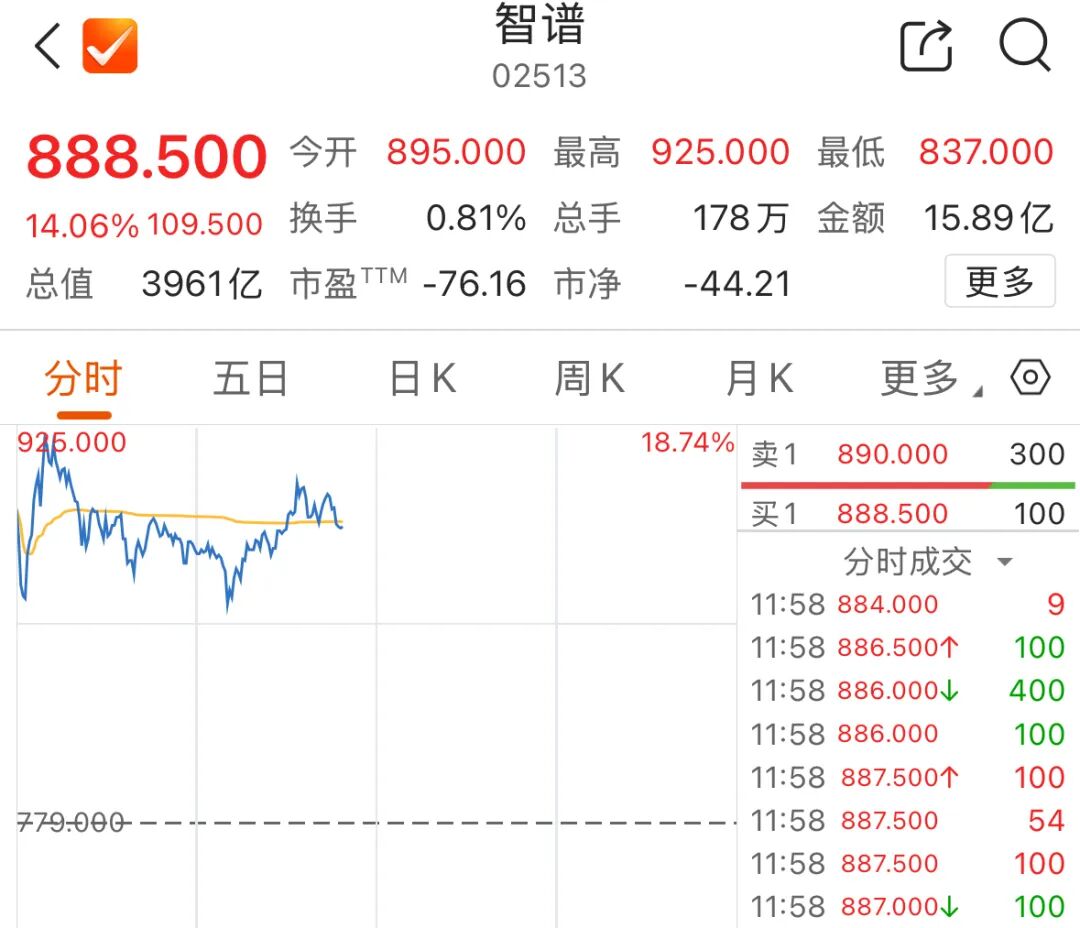
4月8日,“全球大模型第一股”开盘涨超18%,市值逼近4000亿港元。截至收盘,其涨幅有所回落,涨超14%。
当天,该公司发布了其迄今最智能的模型——GLM-5.1。GLM-5.1大大提高了代码能力,在完成长程任务方面提升尤为显著。和此前分钟级交互的模型不同,GLM-5.1能够在一次任务中独立、持续地工作长达8小时,期间自主规划、执行、自我进化,最终交付完整的工程级成果。
与此同时,GLM再度提价10%,编码场景定价追平海外头部厂商Anthropic,国产模型价格首次对齐海外。
模型独自“上班”8小时
2025年3月,AI安全研究机构METR提出了一个改变行业认知的指标:任务完成时间线(Task-Completion Time Horizon)——不再衡量模型“多聪明”,而是衡量它能独立完成多长时间的人类任务。
这对模型厂商提出了更深层次的挑战。在长程任务中保持稳定输出,模型面对的不只是更大的代码量,而是一连串复杂的工程决策点:主动跑benchmark、定位瓶颈、修改方案、再跑测试。
模型需要像一个真正的工程师一样,形成“实验→分析→优化”的完整闭环,而不是写完一版代码就停下来等人打分。
为此,团队在训练方法上做了几个关键的调整,包括扩展任务过程的训练窗口、特别优化模型的tool use能力。迭代后,GLM-5.1能够在单次任务中持续、自主地工作长达8小时。
这意味着,用户睡觉的8小时,可以变成模型“上班”的8小时。过程中,模型可以自主规划、执行、测试,碰壁时主动切换策略,出错后自行修复,最终交付完整的工程级成果。
以“8小时从零构建Linux桌面”任务为例,用户白天画好架构草图,睡前交给GLM-5.1,早上醒来已产出完整系统。
历时8小时整,执行1700多步,GLM-5.1在20分钟时产生第一个有意义的成果,8小时后产出了一套功能完善的Linux桌面系统,包括:完整的桌面、窗口管理器、状态栏、应用程序、管理器、中文字体支持、游戏库等,4.8MB的配套文件。这相当于一个4人团队一周的开发工作量。
智谱技术团队介绍,上述任务全程没有单元测试兜底、没有代码审查、没有文档。值得一提的是,它甚至给自己的代码写了一个14小时的回归测试——并且通过了测试。
过去两年,行业用Benchmark衡量模型有多智能。下一阶段的衡量标准应该是“能工作多久”,即模型在长程任务中的持续表现,独立完成人类专家几小时甚至几天才能做完的工作。
智谱认为,延长模型的“有效工作时长”是提升智能体能力的一个基础维度。在这条路上仍然有显著的技术挑战:如何克服模型面对复杂任务的上下文焦虑、如何在数千次工具调用后保持执行的一致性、如何更早地跳出局部最优,以及更重要的是如何在没有确定数值指标的任务上建立可靠的自我评估机制。
“GLM-5.1是我们在这个方向上迈出的一步,我们会持续推进。”智谱表示,其究极目标是全自治智能体(Autonomous Agent),模型7×24小时不间断地感知任务、分解目标、执行交付、自我评价与纠正、自我进化,从此无需人类介入。
国产模型价格首次对齐海外
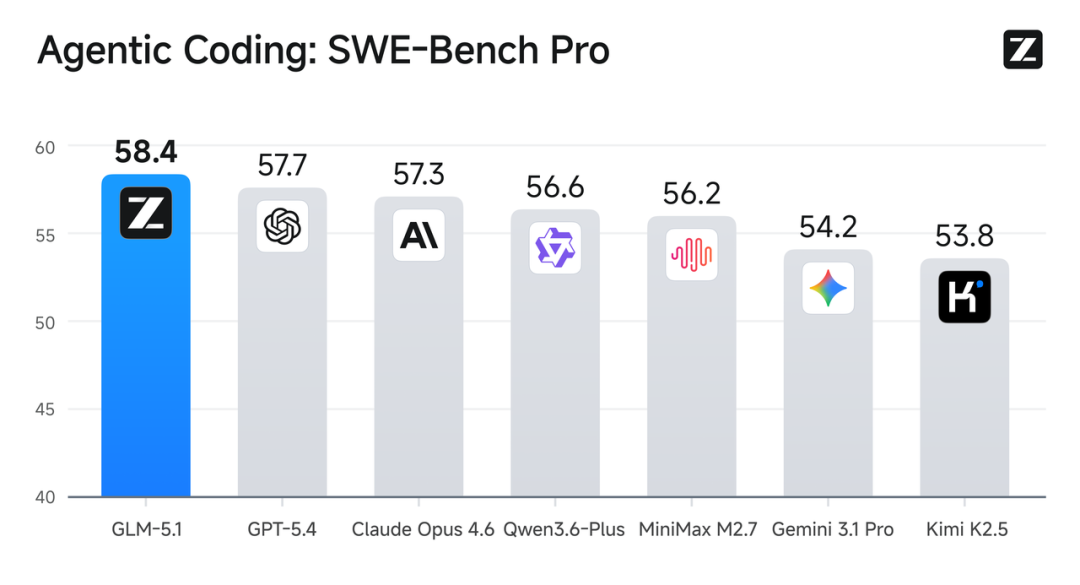
让海外技术社区格外关注的是,在编程能力方面,GLM-5.1的性能首次实现了与国际头部模型的对齐。
Claude Opus 4.6由Anthropic开发,该公司年化收入近期首次超越OpenAI,被视为商业化能力最强的海外头部厂商。最新业务数据显示,Anthropic年化收入(ARR)已达到300亿美元,这超过了OpenAI此前公布的250亿美元年化收入。
在这一背景下,中国开源AI在最核心的工程能力指标上,首次具备与国际先进水平同场竞技的能力。以往国内开源模型常被定位为落后一方,与国际最强闭源模型的成绩始终存在一定距离。而GLM-5.1此次的榜单结果,一定程度上打破了这种固有认知。
性能提升的同时,智谱在价格层面也与海外厂商看齐。模型聚合平台OpenRouter显示,智谱GLM再度提价10%。调价后,GLM-5.1在Coding场景的缓存命中Token价格接近Anthropic旗下Claude Sonnet 4.6。
公开资料显示,这是国产大模型首次在核心场景实现与海外头部厂商的价格对齐。
这一变化超出了不少人的预料——一年前,大模型行业还陷在“价格战”中,普遍降价九成以上争夺份额。如今的转变,意味着国产模型正逐步从低价策略转向以性能为本,尝试建立与国际头部厂商的对等地位。
作者:孙小程
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/252096.html