
很多开发者做Agent项目时,最痛苦的一件事就是模型“越跑越蠢”。
前面几十轮还挺聪明,工具调用也算稳。
跑上个几十上百轮以后,模型就开始胡说八道、重复错误、直接摆烂。

上下文再长一点,性能直接雪崩。
以前大家只能苦笑:大模型天生就这样,长时序任务就是它的死穴。之前我们还写过一篇文章来讲这个事情 AI 聊两句就翻车?性能暴跌 39%!别再难为它了。
但是现在,智谱把这个问题给干掉了。
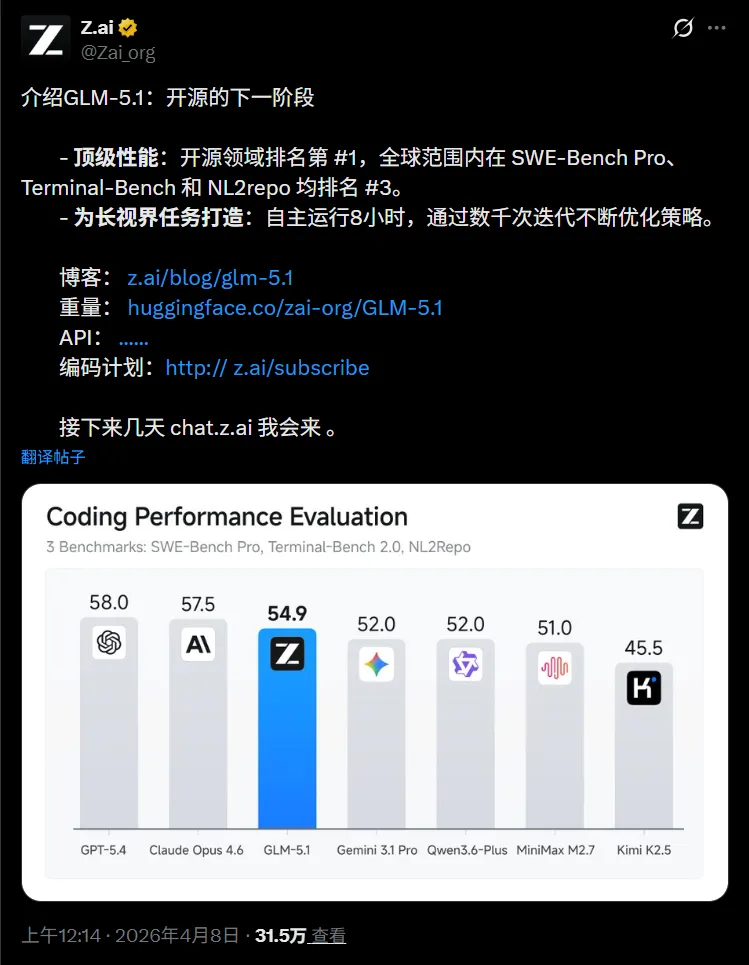
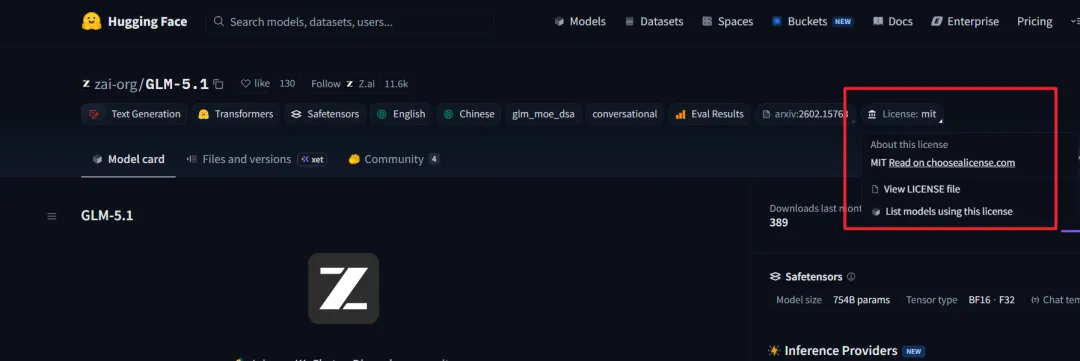
4月8日,也就是今天,智谱正式开源GLM-5.1,这是GLM-5系列的升级版,完全MIT协议,权重已经同步上线Hugging Face和ModelScope。
想本地部署?vLLM、SGLang直接拉取就行,商用也完全没限制。
官方给它的定位非常明确:专为长时序Agentic任务设计。
这话不是随便说的。
GLM-5.1能在600多轮迭代、6000多次工具调用里持续优化,几乎不出现性能平台期。
同时,在复杂编程、智能体工程、网络安全、工具调用等这些场景,它的表现直接拉到新高度。
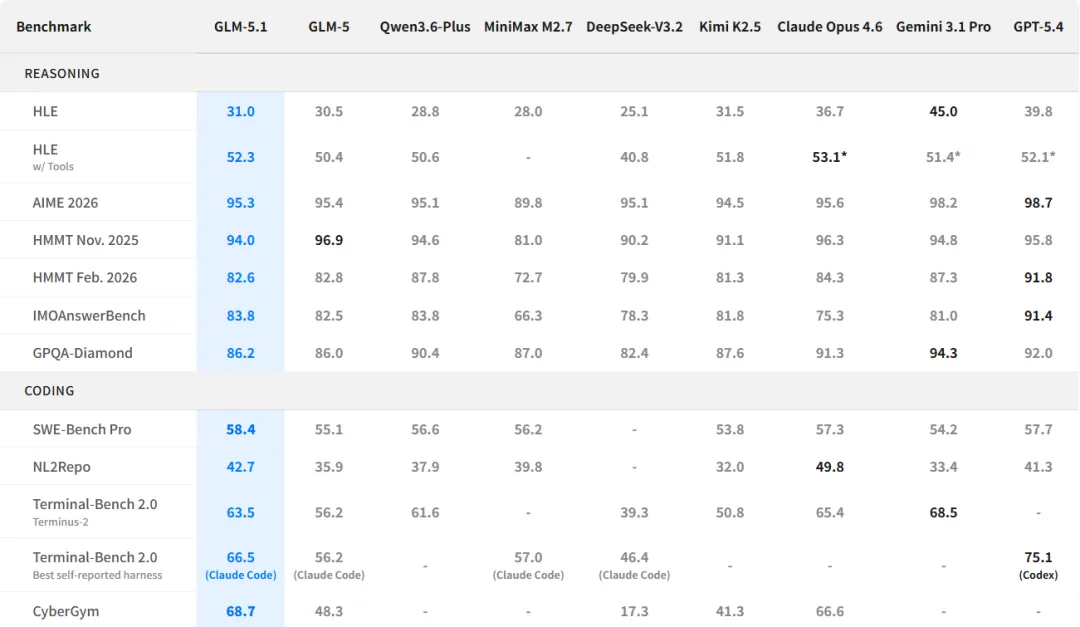
基准数据部分, GLM 5.1 则再一次展现出其实力。
SWE-Bench Pro拿到58.4分,高于GLM-5的55.1、GPT-5.4的57.7和Claude Opus的57.3。
Terminal-Bench 2.0是63.5,CyberGym直接68.7,比上一代提升了20多分。
上下文窗口更是夸张,最大生成长度 tokens,带工具调用时能到 tokens。
这意味着什么?
正如前面我们提到的,以前跑长周期 Agent,模型对话次数一长,上下文一多,性能就开始雪崩。
现在,GLM-5.1能稳定跑到600轮以上,依然保持高水准。
那么开发者终于可以放心地把一些相对复杂工程任务、长期运维Agent、甚至网络安全红蓝对抗任务交给它。
在其官方示例中,还展示了使用 GLM 5.1 花费8小时从零构建一个Linux桌面环境。
同时,更重要的是,这次是完全开源、MIT协议。
这意味着不管你是个人开发者、小团队,还是企业,都可以随便商用、修改、二次开发,不用担心后面被收割,这比很多 Apache/GPL 许可证开源的大模型来得更加实在(当然这并不是在说这些就不好)。
如果把长时序不退化、能力强、完全开源、性价比高这几点放在一起看,GLM-5.1很有希望成为当前一段时间内最好的 OpenClaw 底座模型。
以前大家做复杂Agent时,总要在闭源大模型和本地部署之间纠结,但现在GLM-5.1直接把这个选择题变成了多选题,且答案还是很香的。
GLM-5.1的出现,把国产开源模型在长时序Agent领域的能力直接拉到新高度。
开源AI的竞争越来越卷,但卷的方向也越来越务实:不止参数提升,于实际工程里的痛点,也在被逐一解决。
GLM-5.1这一步,走得很实在,,以后做长时序Agent项目,应该会舒服很多。
希望后面有更多国产开源模型继续往这个方向卷,把“跑得越久越强”变成行业标配。
那样的话,普通开发者手里能用的Agent底座就会越来越靠谱,整个生态也会真正热闹起来。






版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/252072.html