
如果你最近关注AI圈,大概率会被一串缩写刷屏:LLM、MLLM、VLM、VLA…… 紧接着是“原生多模态”“世界模型”“基座模型”“具身智能”这些听起来很高深的概念。它们到底是什么意思?之间是什么关系?
今天,我们就用一篇文章,帮你理清这条从“神经网络”到“原生多模态”的演进脉络。
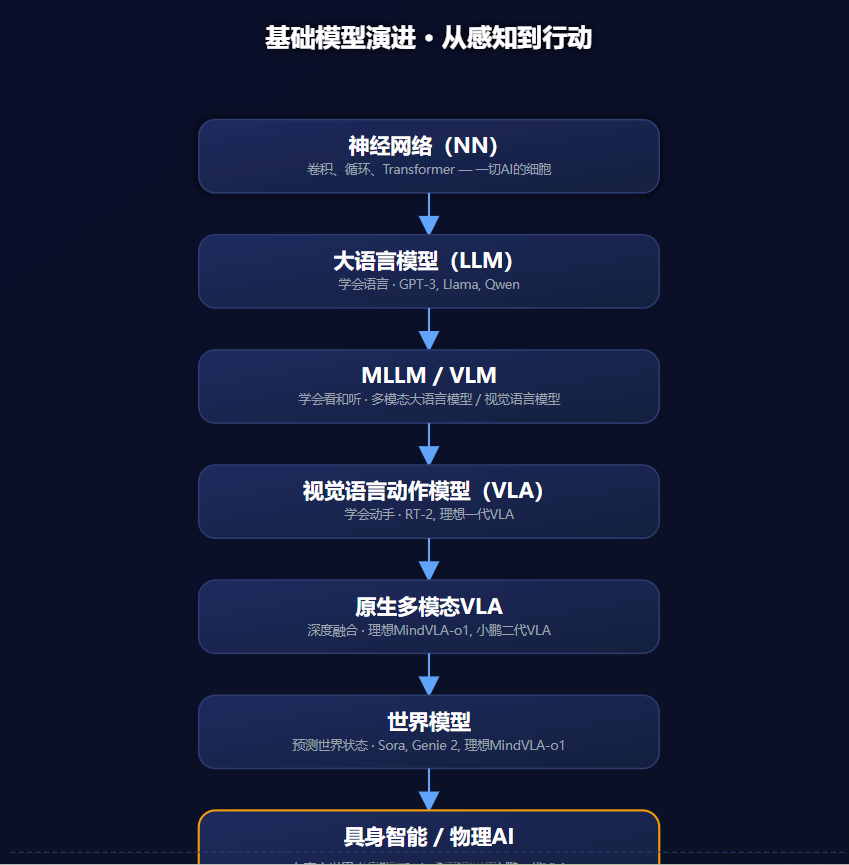
- 神经网络(NN)—— 一切AI的基础
- 大语言模型(LLM)—— 让AI“能说会道”
- 多模态大语言模型(MLLM)—— 给LLM装上“眼睛和耳朵”
- 视觉语言模型(VLM)—— 专注“看图说话”
- 视觉语言动作模型(VLA)—— 从“看懂”到“动手”
- 原生多模态—— 从“拼接”到“融合”
- 世界模型—— 预测“世界的下一步”
- 具身智能—— AI拥有“身体”
- 基座模型—— 从“单一能力”到“通用智能”
- 物理AI—— 数字智能的物理延伸
- 多模态推理—— 跨越模态的思考
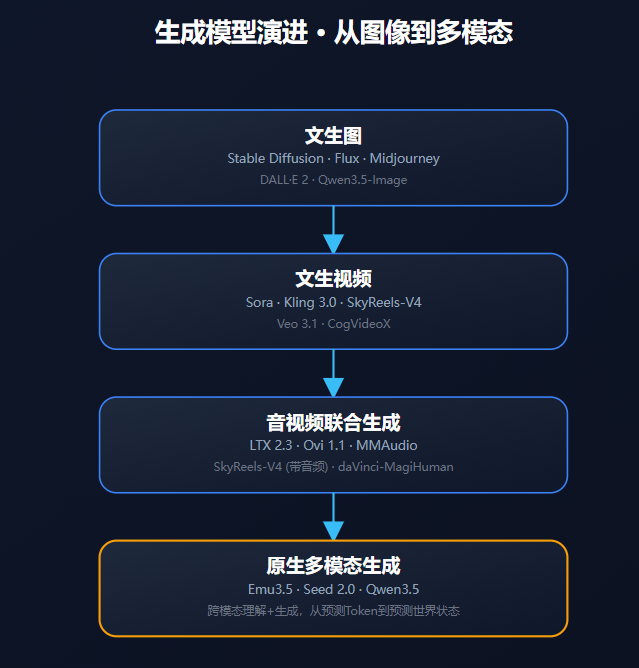
- 生成模型—— AIGC的核心引擎
- 视频生成(Text-to-Video / Audio-Video)
- 图像生成(Text-to-Image)
- 音频生成(Text-to-Audio / Music)
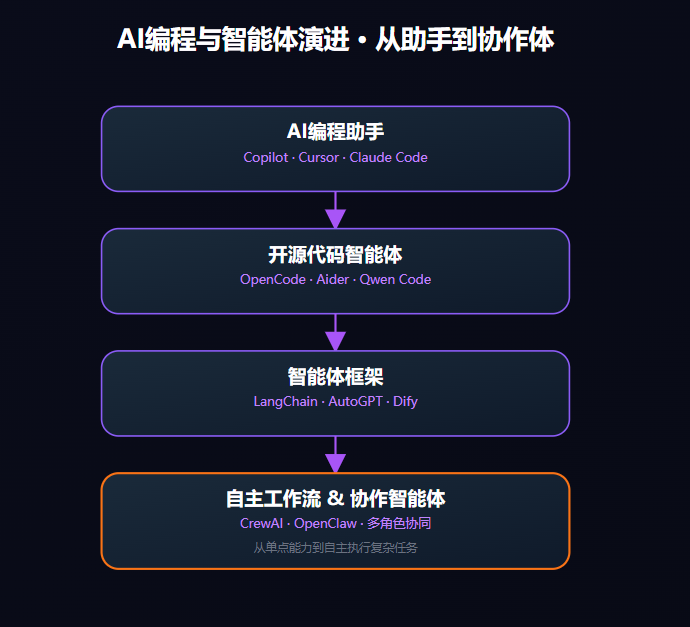
- 代码智能体与AI编程工具—— AI从“写代码”到“帮写代码”
- 智能体框架与工作流—— AI从“单点能力”到“自主执行”
- 技术演进路线图
AIGC(人工智能生成内容) 是指通过深度学习、自然语言处理、计算机视觉等技术,由算法自动生成文本、图像、音频、视频、代码等内容的创作方式。其核心在于让机器模拟人类创造力,从海量数据中学习规律,并生成符合特定需求的原创内容。
从最早的文本生成到如今的多模态创作,AIGC的演进史,正是我们今天要梳理的这些关键词串联起来的技术革命。
Neural Network(神经网络),是所有现代AI模型的共同祖先。它模仿人脑神经元的结构,通过大量简单计算单元的连接,学习数据中的规律。
无论是图像识别、语音识别还是下围棋,早期的AI几乎都建立在各种神经网络之上:卷积神经网络(CNN)处理图像、循环神经网络(RNN)处理序列、Transformer则是目前最主流的架构。
一句话总结:它是所有AI模型的“细胞”。
时代关键作品
Large Language Model(大语言模型),是近年来AI爆发的核心。它以Transformer架构为基石,在海量文本上训练,学会预测下一个词(Token)。
核心能力:文本理解、生成、推理、编程。
局限:只懂文字,不懂图像、声音、视频。
时代关键作品
Multimodal Large Language Model(多模态大语言模型),在LLM的基础上,增加了对图像、视频、音频等模态的感知能力。
常见做法:用视觉编码器(如CLIP)将图像转换成“视觉Token”,再与文本Token一起输入LLM,让模型既能“读”又能“看”。
一句话总结:MLLM是“会看图说话”的LLM。
时代关键作品
Vision-Language Model(视觉语言模型),是MLLM的一个重要分支,专门处理图像和文本的交互。
典型任务:图像描述、视觉问答、图文检索、视频理解。
在自动驾驶和机器人领域,VLM被用来理解路况、识别物体、感知环境。
时代关键作品
Vision-Language-Action Model(视觉语言动作模型),是在VLM基础上更进一步:它不仅理解视觉和语言,还能输出动作指令。
核心思想:既然大模型能预测下一个Token,为什么不能预测下一个动作?动作可以表示为坐标、关节角度等数据,这些数据也是“语言”。
经典架构(RT-2式):先用图像+文本训练一个VLM,再用动作数据微调,让模型学会根据视觉输入和指令,输出机器人或汽车的下一步动作。
局限:这类VLA本质是“拼接式”的——V、L、A三个模块独立训练后再组合,容易导致模型在微调后“遗忘”语言能力。
时代关键作品
原生多模态,是Google在2023年底发布Gemini时首次提出的概念。
它指的是:模型在预训练阶段就同时使用图像、文本、视频、音频等多种模态的数据,让模型从一开始就学习不同模态之间的内在关系,而不是分别训练单模态模型再拼接。
好处:模态之间融合更深,推理能力更强,能更好地理解世界的复杂性。
注意:目前大多数原生多模态模型还停留在“理解”阶段,无法生成动作或预测物理世界变化。
时代关键作品
World Model(世界模型),是比原生多模态更进一步的概念。它不仅要理解当前状态,还要预测未来状态。
如果一个原生多模态模型能根据当前画面和指令,预测出接下来几秒的世界状态(比如车会往哪开、物体会怎么动),那它就是一个世界模型。
关键能力:模拟物理规律、因果关系、长期规划。
时代关键作品
Embodied AI(具身智能),指AI不仅仅是软件层面的思考和生成,而是拥有“身体”并能与物理世界交互。
传统AI在“虚拟世界”中运作(处理文本、图像、视频),而具身智能体需要感知环境、做出决策、执行物理动作。
典型载体:人形机器人、自动驾驶汽车、四足机器人。
与VLA的关系:VLA是具身智能的核心技术之一——它让AI能够根据视觉和语言指令,输出控制身体的动作。
时代关键作品
Foundation Model(基座模型),原指在大规模数据上预训练、可适配多种下游任务的基础模型。
但在最新的语境中,基座模型的含义正在扩大:它不再只是一个“能说会道”的LLM,而是一个既能理解世界、又能与世界交互的通用模型。
新一代的VLA基座模型(如理想MindVLA-o1、小鹏二代VLA)不仅能输出动作,还能输出语音、视觉等多种模态,成为“物理AI”的核心。
时代关键作品
Physical AI(物理AI),指能够理解物理世界规律、并在物理环境中行动的AI系统。
与只处理文本图像的“数字AI”不同,物理AI需要理解重力、惯性、碰撞、因果关系等物理常识。
典型应用:自动驾驶、工业机器人、家庭服务机器人。
李想曾发文称:“自动驾驶,只是物理AI的一个起点。”同一套VLA基座模型既能开车也能控制机器人。
时代关键作品
Multimodal Reasoning(多模态推理),指模型能够整合来自不同模态的信息,进行跨模态的逻辑推理。
例如:看到一张下雨的图片,听到“带伞”的语音指令,模型需要理解图像中的雨、语音中的指令,并结合常识推理出“需要拿伞”这一结论。
原生多模态模型由于在预训练阶段就学习了模态间的深层关系,天然具备更强的多模态推理能力。
时代关键作品
如果说前面的概念定义了AI如何“思考”,那么生成模型则定义了AI如何“创造”。在AIGC时代,视频、图像、音频生成模型的突破,让创作变得触手可及。

视频生成(Text-to-Video / Audio-Video)
视频生成从无声到有声、从短片段到长叙事,正在经历爆发式进化。今年2月,昆仑万维旗下SkyReels-V4 Preview版在权威评测平台Artificial Analysis的全球视频生成排行榜中登上全球第二,超越OpenAI的Sora 2和Google的Veo 3.1。不到一个月,SkyReels-V4在文生视频(带音频)榜单中登顶全球第一,成为全球AI视频生成能力最强的大模型。
🖼️ 图像生成(Text-to-Image)
图像生成是AIGC最早爆发的领域之一,从早期GAN到扩散模型,再到如今的DiT架构,质量已接近专业设计水平。
🔊 音频生成(Text-to-Audio / Music)
音频生成从语音合成到音乐创作,再到音视频同步生成,正在构建沉浸式体验的基础。
如果说生成模型让AI能创作图文视频,那么代码智能体则让AI能自己写代码、改代码、甚至完成整个项目。这正在彻底改变软件开发的方式。
🔧 核心概念
- AI编程助手:集成在IDE中,提供代码补全、生成、解释、重构建议。
- 代码智能体:能够独立理解需求、规划步骤、调用工具、生成完整代码或执行自动化任务。
- 开源 vs 闭源:既有Claude Code、Cursor等闭源产品,也有OpenCode、Aider等开源工具。

🔥 时代关键作品
如果说代码智能体让AI能写代码,那么智能体框架则让AI能自主规划、调用工具、完成复杂任务。这是当前AI应用最火的方向之一。
🤖 核心概念
- 智能体(Agent):能够自主感知环境、制定计划、执行行动、并迭代优化的AI系统。
- 框架:提供一套标准化的组件(如记忆、工具调用、任务分解),方便开发者构建智能体应用。
- 代表作品:AutoGPT、LangChain、CrewAI,以及最近火出圈的OpenClaw(昵称“小龙虾”)。
🔥 时代关键作品
并行发展:生成模型
并行发展:AI编程与智能体
从文生图到文生视频,从纯视觉到音视频同步,AI的生成能力正在无限逼近真实世界。而AI编程工具和智能体框架,则让AI从“被使用”变成了“能使用工具、自主执行”的智能体。技术的演进,正在把AI从一个“文本生成器”变成一个“物理世界的推理者”,甚至是一个“能够完成复杂任务的数字员工”。
而我们刚刚站在这条路的新起点上。
AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,*我国人工智能人才缺口超过500万,*供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!

就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/248001.html