
请诸君谅解,AI大模型科普型的文章的确有点难写。首先,作者是一个在芯片行业从业了十几年的底层软件开发工程师,转型AI大模型开发还不足两年,对大模型的理解还不够深刻,写浅了感觉像是不入流的小儿科,贻笑大方;但毕竟作者不是纯小白起步,对计算机原理和编程思想已有较深刻的理解,如果完全按照自身学习路径回溯的话,写深了又会让人望而却步,多数人会毫无阅读的兴致。作者本意是想用最浅显易懂的语言来达到由浅入深的科普效果。

尽管一直尝试用比较容易理解的语言来描述AI大模型。奈何作为一个理工科出身的人,表达能力的短板还是太明显。作者也尝试过把文字编辑的工作交给AI去完成,但是发现目前AI写作的套路和格式又太固化了,写出来的东西很难契合作者的意图。况且作者并不期望通过文章流量来获利(要工作,一年也发不了几篇),就权当总结和反思来写,顺便提升一下表达能力吧。
说一千道一万,还是先希望读者不要被“大模型”这三个字给唬住了。这么说吧,你我都不具备大模型的开发和优化能力。你别看新闻里深圳某17岁高三学生陈广宇又参与了月之暗面的Kimi团队,且作为第一作者发表了技术论文《Attention Residuals》· 注意力残差,被马斯克在社交平台公开点赞,引发全球AI圈震动:
但你得承认,我们都不是那个17岁就能写出此等论文的天才,我们大多数人也不是奔着这条路线去走的。但是理解大模型的整体工作流程、甚至亲手去部署一个属于我们自己的AI还是可以实现的(只要跟着我们的全套教程走就能轻松实现)。不过,需要懂一点计算机和编程的基础知识哦,不然看不懂我们后续的实战指导。
也许你已经听说过“训练”和“推理”,但是并不知道它们具体含义是什么;也许你还对“部署”心存疑虑,对个人部署AI到底能不能实现,还在心里打鼓。别担心,这篇文章就是为你准备的。先给结论:大模型的开发,本质上和软件开发一样,是有清晰的流程和分工的,你不需要是数学天才,也能理解它在做什么。下面,我们会用一个开发->训练->推理->部署的四部曲框架,带你完整走一遍大模型的“生命旅程”,全程不讲晦涩的公式,只讲你能听懂的大白话。
- 大模型开发(选型与获取)
1.1 大模型开发到底在“开发”什么?
很多人还以为“大模型开发”就像写代码一样,必须从零开始敲出一个大模型来。非也!在今天,绝大多数人从事的所谓“大模型开发”其实是指选择和组装,而不是从无到有的创造,你可以简单的把它类比成做一顿饭:
- 纯自己开发:从种地开始,种菜、养猪、磨面…那是大厂干的事,一般的中小企业是没有这个能力去搞的,更别说是个人开发者了。
- 用模型开发:去超市买现成的食材(下载开源模型),然后根据自己的口味进行烹饪、调味(也就是本文提到的微调和部署)。
也就是说,大模型开发核心就三件事:
- 选一个现成的开源模型(选食材)。
- 决定要不要“调味”(微调)。
- 把它包装成你能用的服务(部署)。
1.2 如何选择模型(三个关键参数)
大模型选型就像买车:你得先明确需求,再看参数表。大模型一般有三个重要的参数要考虑:参数量、中文能力以及上下文长度:
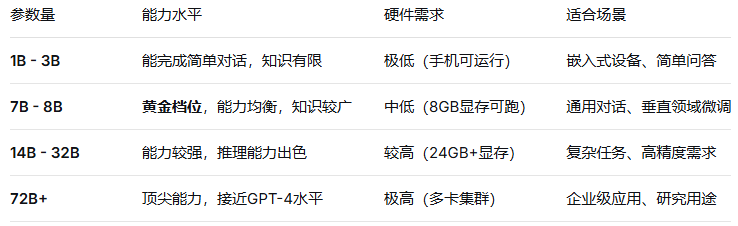
- 参数量:模型里可调整的“旋钮”,数量越多,模型越“聪明”,用B表示(1B表示10亿),如:深度搜索的deepseek-r1:7b-xxx版本,里面的7b表示70亿个参数。你也许对这个数量级没什么概念,我让AI整理了一个参数量与能力的对照表,请参考:

如果第一次上手,建议选7B-8B的模型,性价比最高,适合用来学习。而1B-3B虽然更便宜,但太弱、太傻了,啥也干不了。
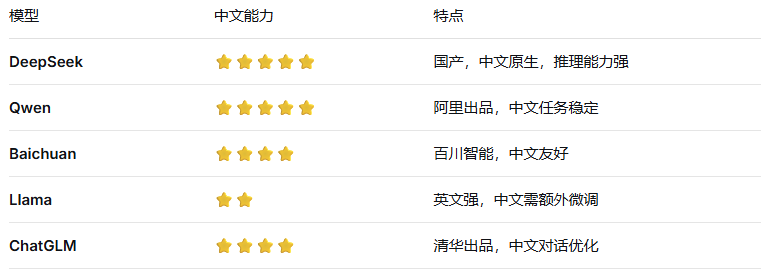
- 中文能力:如果做中文应用,不得不考虑中文的推理能力,下面是AI整理的模型中文能力对照表,建议选DeepSeek或Qwen:
- 上下文长度:决定模型“一次能看多少字”的参数。例如:DeepSeek-V2/V3支持128K-1M的上下文长度(相当于一整本书),可以进行长篇小说分析、复杂代码库分析等应用场景。而日常对话、短文本处理的话可能只需要4K到8K的上下文长度就足够了。
1.3 下载模型文件
可以通过魔塔网站(modelscope)搜索并下载AI大模型(需要注册并登录账号),网址:
https://www.modelscope.cn/my/overview
上面能搜到几乎所有开源大模型文件,如:

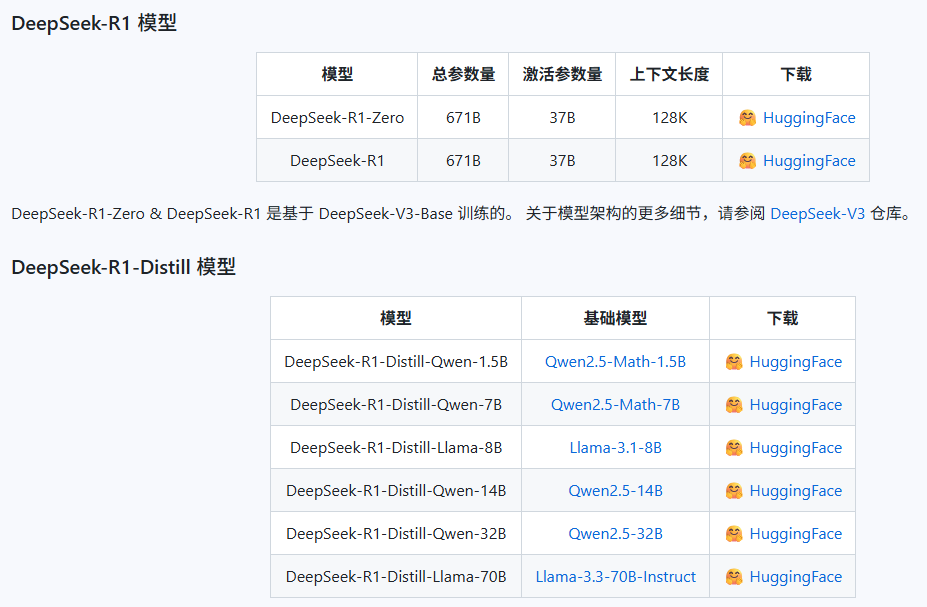
先别着急下载,毕竟这些模型的体积都很大,动辄几十个GB,下载了不知道怎么用它就等于是一团硬盘垃圾,纯浪费流量而已。我们后面的文章将会介绍怎么使用,届时再去下载也不迟。
- 大模型训练(让AI学习知识)
为了避免误导读者,我们先声明:通过上面的介绍,从魔塔网站下载的大模型文件就是AI厂家已经训练好的大模型成品,普通开发者不需要、也不具备自己训练大模型的能力。这里只是为了简单介绍大模型训练的基本知识,且读者很有必要去了解一下大模型训练的概念,因为它决定了模型的能力上限,也解释了为什么模型有“知识截止日期”这一说法,同时它还能让你理解“微调”到底在调什么(你可能不需要训练大模型,但肯定逃不过微调大模型)。就好比你学习“马力”和“排量”不一定是为了去造发动机一样,但是知道这些知识对你选车的时候更有帮助。
大模型训练的本质,是让模型从数据中悟出规律。训练就是把海量数据喂给模型,让它自己去发现规律。可以把它想象成让AI去“上学”:
- 教材:海量的文本、代码、对话记录等
- 老师:训练算法(告诉AI学得对不对)
- 考试:验证集(检查AI学得好不好)

大模型的训练分为两个阶段:预训练和微调。预训练的任务是让AI掌握语言、知识、推理能力,成本极高,通常需要消耗数万亿的Token;而微调只是为了让AI学会特定领域的专业能力。你可以提前下载一个开源模型(如DeepSeek),用你自己的医疗/法律/代码数据去“微调”它,让它变成你的专属AI,此过程可能仅消耗数千到数万条标注数据就行,成本较低。对大多数企业来说,微调是更现实的选择。

一个大模型的能力强弱,取决于三个要素:数据、算力和时间。数据就是指你给模型喂什么,包括文本、代码和对话等,数据的质量决定了模型的下限,也就是说,如果你给模型投喂的是垃圾数据,那它得到的就是一个垃圾的模型;算力指的是用什么去喂,训练模型依赖算力极强的训练芯片(专门做矩阵乘法),甚至还需要集群互联(也就是成千上万块芯片一起工作)。常见的训练芯片如英伟达的A100/H100、华为的昇腾910等;时间则是指投喂所消耗的时间。
以DeepSeek-v3为例,大概使用了2048块H800,消耗了14.8万亿token,训练时间则花费了近2个月,总训练成本大约558万美元。而GPT-4的训练成本就更高了,大概使用了2.5万块A100,耗时3个多月,总训练成本超1亿美元,这就是顶级大模型的造价。不过,你先别慌,如果只是微调一个7B模型的话,那几百美元就足够了,相信大多数人都能付得起。
- 大模型推理(让AI回答问题)
大模型完成训练后,你得到一个模型文件。它只是一个静静的呆在那里的死知识库,所以模型本身是不会“说话”的,你需要通过推理来让它回答问题。推理的本质就是把用户输入的问题“翻译”给模型,让模型计算出一个答案。

例如:用户提问:“甘蔗是什么味道?”,推理服务器负责把这个问题“翻译”成模型能理解的数字(tokenization),然后模型拿到这些数字进行内部亿级别的数学运算。这些运算通俗的讲就是理解用户意图(通过“是什么”推理出用户在发起提问)、提取关键信息(“甘蔗”和“味道”),然后注入风格约束等过程。最终模型通过计算得到“甜”的token ID,反向映射为用户认识的汉字,组成句子展示给用户。
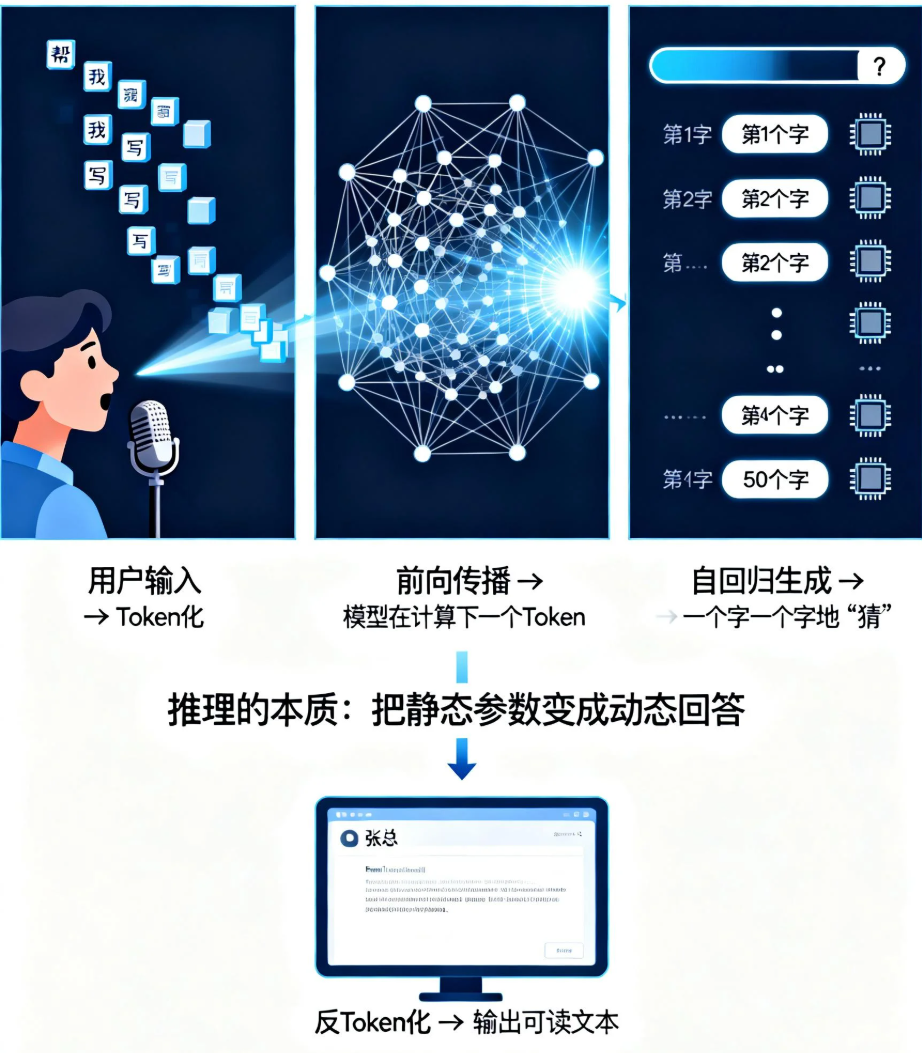
推理和训练不一样,虽然它也需要对应的芯片支持,但是对芯片没那么高的算力要求,成本和功耗较低的芯片即可完成。例如英伟达的L40S、华为的昇腾310、高通的手机NPU芯片等。训练一般是部署在大型的数据中心完成的,而推理一般部署在云服务器或边缘设备上即可,此外,要说训练的过程是追求“慢工出细活”的话,那推理则该用“快如闪电的回应”来形容。
为了让推理更快、更省成本,现在还出现了一个叫量化的技术。量化就是指把模型的“高精度”计算变成“低精度”计算。比如:原本模型里的每个参数都是一个“小数点后8位”的精确数字,量化后变成了“小数点后2位”的近似数字。虽然精度略有损失,但速度翻倍、内存减半。量化技术可以让一个70亿参数的模型从几十个GB压缩到几个GB,甚至能装进手机里运行!
- 大模型部署(AI放在哪运行)
理论上,大模型训练好之后,你可以把它部署任意方便你使用的地方均可。但常用的有三种部署方法:云端部署、边缘部署和端侧部署。
云端部署是指将大模型部署在云服务器的机房里,特点是维护简单但有一定的网络延时,适合海量用户的通用大模型,DeepSeek官方提供的服务就是典型的云部署模式;边缘部署又称为本地部署,也就是将大模型部署到医院、工厂或者园区等本地服务器里,特点是延迟较低但需要自行维护硬件;端侧部署则是将大模型部署到手机或者物联网等终端设备上,特点是完全离线、隐私性极强,但是算力有限,仅适合手机助手或智能家居等轻量级应用的场景。
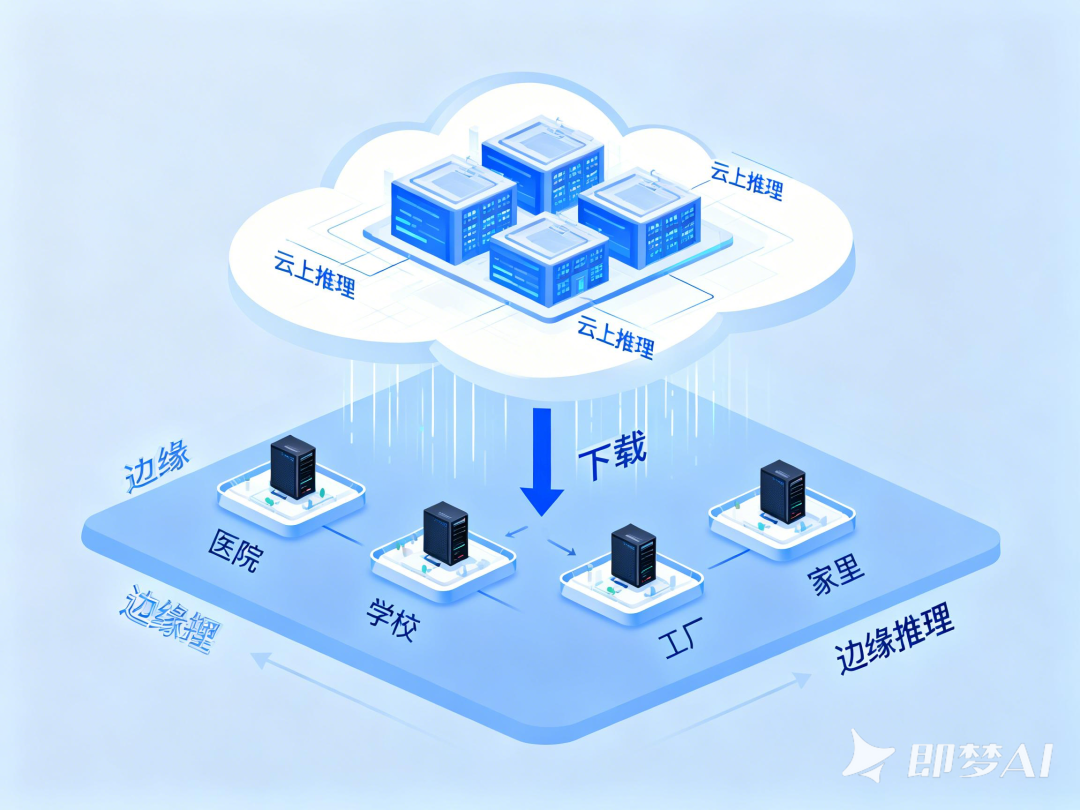
此外,边缘部署的核心,是推理芯片,这类芯片算力适中(足够运行7B-32B的大模型)、功耗极低(可以7×24小时运行不关机)、接口丰富(能直接连接摄像头、传感器等设备)。例如,华为的昇腾310P芯片就是一款专门应用于边缘部署的大模型推理芯片。
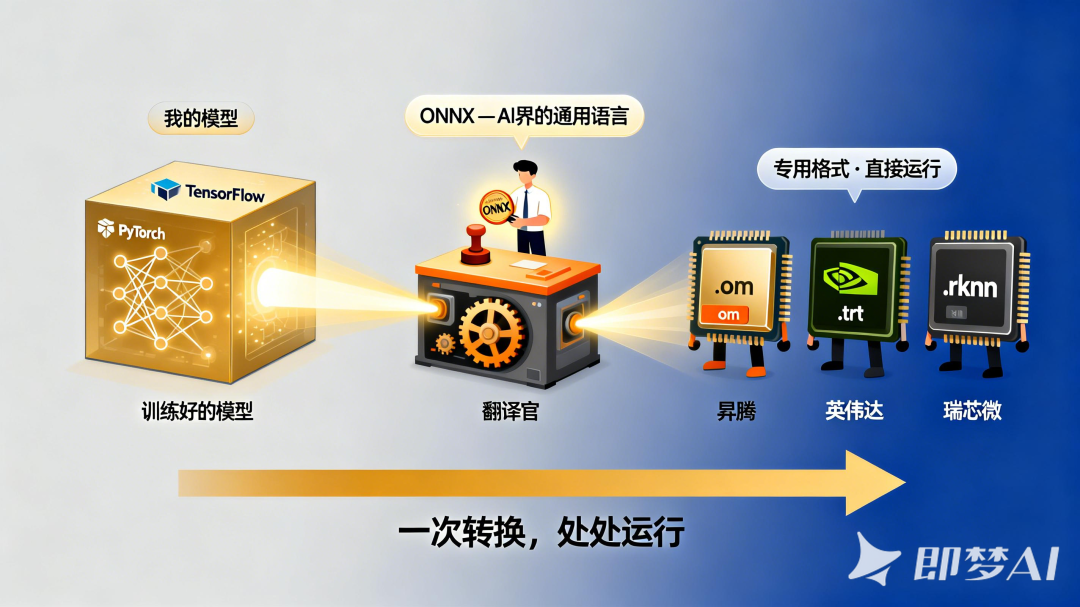
你可能会问:拿到训练好的模型后,就能直接“下载”到推理芯片上直接运行吗?答案是:不可以!还需要进行一次“翻译”,也叫“模型转换”。训练好的大模型文件,最初是在特定的框架(如PyTorch、TensorFlow)和特定的芯片生态(如英伟达CUDA)下生成的,它带有原生态的“印记”,要让它在昇腾310P或者其他芯片上运行,需要进行一次格式转换(移植)。一般的做法是把大模型导出为ONNX格式(开放神经网络交换格式,相当于AI界的通用格式),然后使用推理芯片厂商提供的转换工具(如昇腾提供的ATC工具),把ONNX模型转换为芯片能识别的专用格式。但是,这个转换过程和训练毫无关系,你并不需要重新训练模型。
大模型完成部署之后,你就可以将应用接入进行使用了,这里说的“应用”可以是API方式访问,也可以是Web或者App等其他方式封装。后续我们将会有详细的实战案例进行演示。
至此,AI大模型的整个开发部署流程已经简单介绍了一遍。看完之后,是不是感觉你和AI之间的距离并没有你想象的那么遥不可及了?
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 ,却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是**时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
- 掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
- 学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/247829.html