
大家好,我是小锋老师,最近更新《2027版 基于LangChain的RAG与Agent智能体 开发视频教程》专辑,感谢大家支持。
本课程主要介绍和讲解RAG,LangChain简介,接入通义千万大模型 ,Ollama简介以及安装和使用,OpenAI 库介绍和使用,以及最重要的基于LangChain实现RAG与Agent智能体开发技术。
链接:https://pan.baidu.com/s/1_NzaNr0Wln6kv1rdiQnUTg
提取码:0000
前面我们使用invoke是完整输出形式,当返回数据量大的时候,会有延迟,显示效果也不好,我们企业级开发,肯定是一段一段的像流水一样的输出形式。
在LangChain中,我们使用stream()方法,来实现流式输出。
实现代码:
GPT plus 代充 只需 145 from langchain_community.llms.tongyi import Tongyi # 创建模型 model = Tongyi(model="qwen-plus") # 调用模型 result = model.stream(input="你是谁") for chunk in result: print(chunk, end="", flush=True)
运行返回的就是一段一段的流式输出了。
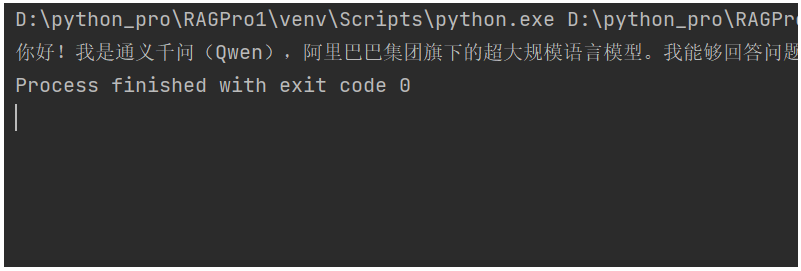
同样,如果我们使用本地ollama里的大模型,代码也改下:
from langchain_ollama import OllamaLLM # 创建模型 model = OllamaLLM(model="qwen3:4b") # 调用模型 result = model.stream(input="你是谁") for chunk in result: print(chunk, end="", flush=True)
运行也是流式效果:
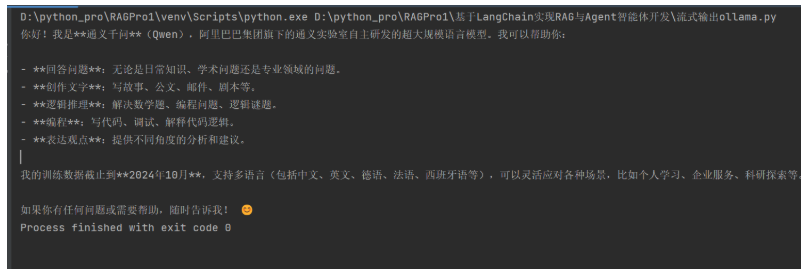
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/246919.html