
咒语体验型选手一枚,大神们能不能用比较适合小白的方式给解答一下
先自我介绍一下,
Stable diffusion使用时间二个月有余,除了炼丹之外的操作基本都会。已经实现色图自由,并且可以按身边好友XP要求产出色图供他们欣赏。
Midjourney30刀会员,使用时间一月有余。
(5.9更新,感悟不同,略有修改)
说一下自已的感受。
Stable diffusion有开源的免费软件下载。下文描述的都是特指秋叶大佬的版本。下载地址详见B站秋叶大佬的相关视频。
Midjourney需要按月支付会员费来使用。
Stable diffusion总的来说,是一个偏娱乐向的软件。如果用商业用途上,Stable diffusion只能生成一张原画/立绘/壁纸形式的大图。使用LORA的话,可以满足生成多视角设定图等需求。但Stable diffusion无法稳定生成同一个角色不同动作的图,所以Stable diffusion无法满足游戏制作的需求。通过LORA锁定某个人物的脸蛋,或许可以达到这个需求,但还是略有变形。
Midjourney总的来说,偏向商业设计而设计的。除了生成艺术大图之外,Midjourney还能设计LOGO和产品概念图。就出图质量而言,Midjourney极少极少会出错错肢错手指的情况,不需要用户特别费心。而Midjourney可以通过输入命令生成同一人物,不同表情,不同动作,目测同样会略有变形。(见文末附上的例子)
Stable diffusion的使用必须依赖用户的GPU,如果算力不足有些功能会无法使用或者出错。(除非用户租用网上云算力)
Midjourney在多破的电脑上都能跑,在普通手机上都能跑,因为计算全在云端。
Stable diffusion已经被秋叶大佬打包成一个相当完美的软件包。使用简便,维护和升级也相当方便的软件包。但用户依旧需要自行下载模型和LORA、插件去扩展。使用上有无限的可能性。
Midjourney不需要额外维护,模型数量虽然不多,但官方版本最新版本的V5和Niji5,相当利害。V5做的特朗普系列的整活图相信很多人都看过了,而Niji5画的漫画插图也相当可爱。两个模型的下限极高,随手画画就是好图。
Stable diffusion的用户想要啥图,只要把关键字一个个往软件里面填,然后在滑条上划来划去地调整参数,就能够出图了。人机交互方式比较机械,但相对容易学习。
Midjourney的用户想要啥图,可以使用近乎口语句子一样的描述去概括。再配合少量关键字就能出图。人机交互方式比较自由,但因为没有一个公式化的模版,也相对难掌握。
Stable diffusion的出图质量,如果没有插件ControlNet控制,那么会生出多余肢体的错图是很常见的,机率随缘。4月底ControlNet插件更新了手指和表情控制之后,错肢体和错手指的情况已经大大减少,但稳定性依旧和Midjourney有段距离。5月之后ControlNet插件几天一更新,只会越来越稳定,功能也越来越大,个人抱乐观地展望。
Midjourney在肢体与手指方面,很早之前已经控制得很完美,不需要用户额外操心。
Stable diffusion可以产出字面意义上的各种色图,配合LORA可以满足不同LSP各种奇怪的XP。
Midjourney不能产出色图。当然生成不露点的性感图片还是没问题的。
Stable diffusion的最大缺点,是出图质量不稳定。一般来说故障会出在生成角色的肢体增多,手指出错,甚至是生成没有逻辑的混乱画面。加上ControlNet的控制可以有效减少这种故障。
Midjourney的最大缺点是角色的姿势完全不可控,如果需要角色配合画面摆出某个姿势,很大可能是做不到的。Midjourney整活的图太多,给人的感觉就是Midjourney无所不能,但其实Midjourney和Stable diffusion一样,在生成图片的时候有自已的极限。而这个极限受到模型限制。在用户交互方面,Midjourney不像Stable diffusion那么直观,所以Midjourney并不是那么容易操纵的。
而Midjourney有很多功能,比如可以生成卡牌或者程序的UI版式,或者生成产品包装效果图,这些功能产出的图虽然不能直接作为商用,只能作为启发设计灵感之用。但肉眼可见,Midjourney更新相当勤快,也许将来可以有直接作为商用的一天。
最后是才艺时间,
请让我直观地为大家展示一下,Stable diffusion和Midjourney能够做什么。
Stable diffusion:
这里有一张漫画插图

看我表演个戏法,
碰!
二次元的图真人化了。

原版波奇:

波奇真人化:

有人说我转的图不好看,那上个玛奇玛:


Midjourney:
案例一:
A:请帮我的工作室设计一个LOGO。
我:具体作什么用的,有什么要求?
A:我们的工作室主要是测评相机性能的。要求风格简约,突出主题。
我:(扔出一堆)随便挑。不够还有,量大管饱。





案例二:
A:我想画一个红衣小女孩的绘本。能帮我设计一下角色么。
我:没问题。
(把描述输入到MJ里面,生成六个红衣小女孩的形像)

A:还能再生成吗?必须是我指定的不同动作的图片。
我:没问题。
(把描述输入到MJ里面,再次生成红衣小女孩的形像)

A:(皱眉)虽然略有不同,但只要修饰一下就可以做成绘本了,也不用从头画了~(摊手)
(无广告版)
先说第一个问题的结论:普通人请直接选择Midjourney。
你好鸭,我是仙人球球~最近真的好焦虑呀,各种AI工具的横空出世,感觉分分钟就要失业……但与其焦虑被AI替代,不如积极探索如何用好这些工具。作为影视广告领域的老司机,除了关注ChatGPT能怎么帮我写视频脚本开拓思路外,最关注的当然还是视觉领域的AI绘画大神Stable diffusion 和 Midjourney。


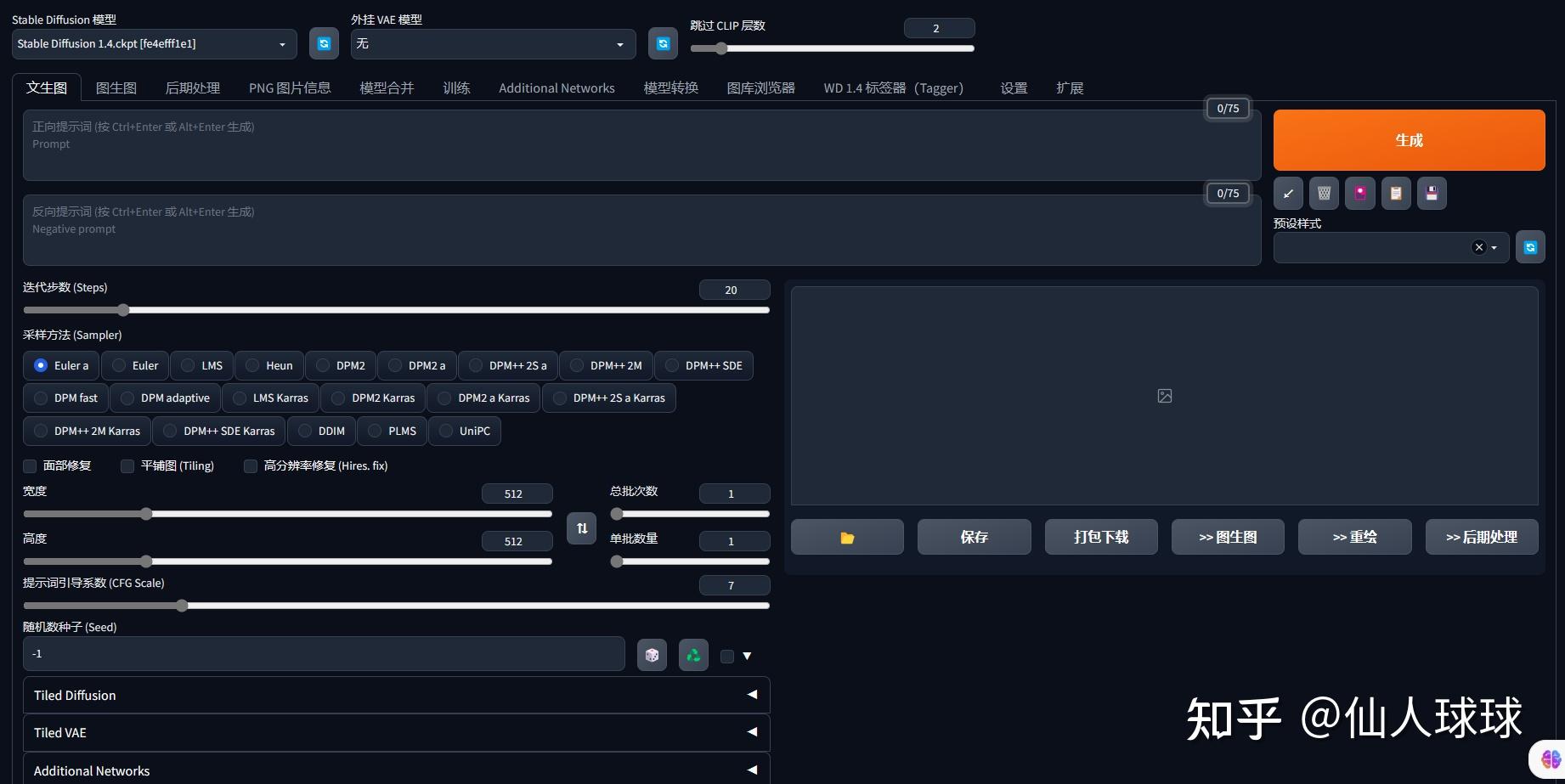
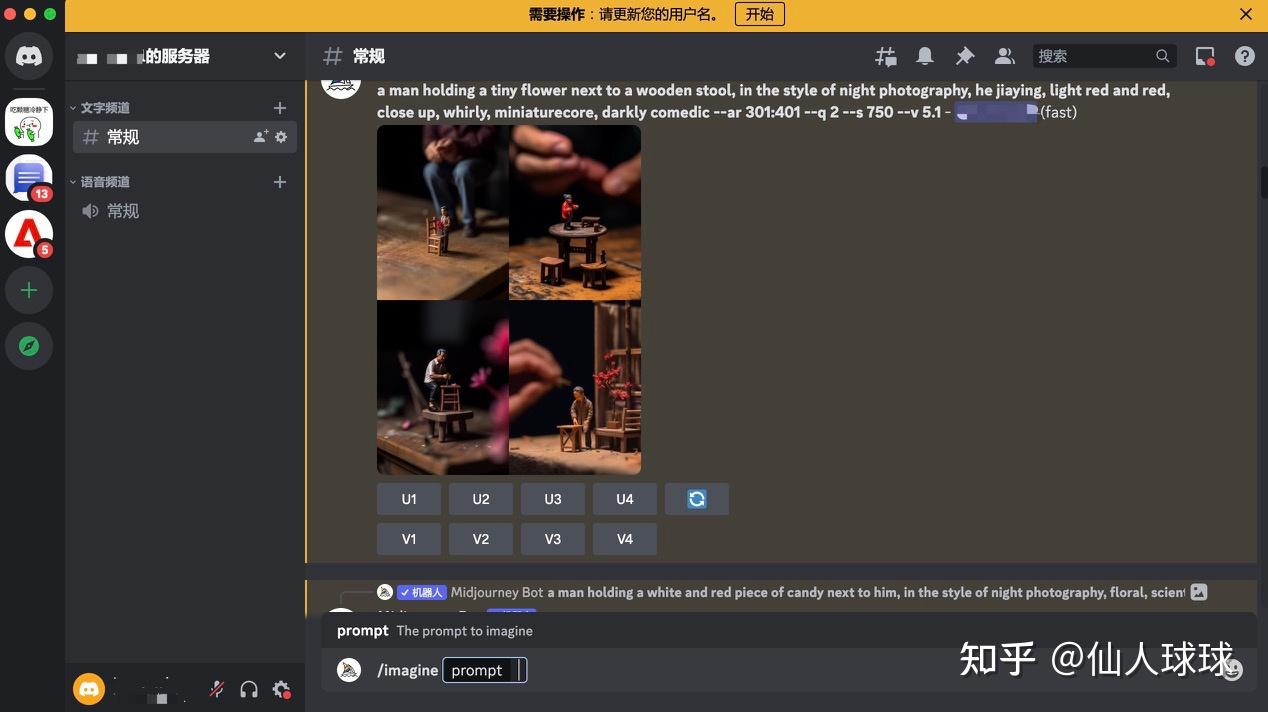
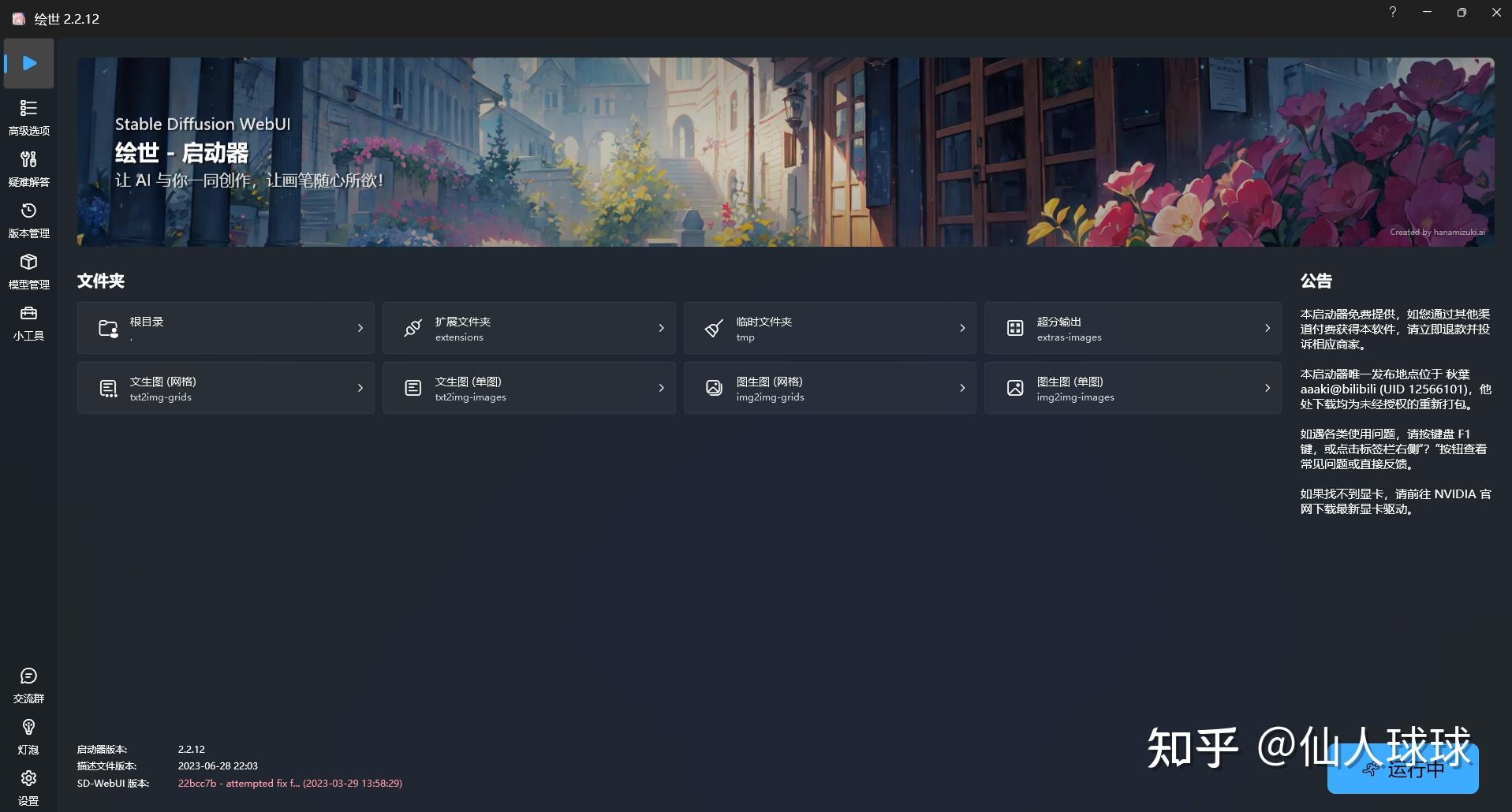
现在,Midjourney70几块钱一个月是不是瞬间变得也能接受了!!!!只需要下载一个Discord,绑定好Midjourney后就能直接在电脑和手机上像聊天一样使用。是的,在手机上也可以使用。
你可以简单的把Stable Diffusion理解为手动挡的专业单反相机,而Midjourney 则是一个人人抬手就能拍照的傻瓜相机。所以,对于普通人来说,初次尝试AI绘画,建议直接使用Midjourney,当你真的觉得其对你生活和工作有帮助,愿意更深入的去学习和研究,再使用Stable Diffusion也不迟。






这个问题我觉得挺好,因为虽然Stable Diffusion(SD)和Midjourney(MJ)这2个AI绘画工具的名字已经深入广大AI爱好者的内心了,但对于普通人(包括刚接触到AI绘画的童鞋)来说,看到这2个名字仍然还是会感觉到陌生。
那么,今天我就来给新手用户来讲讲这2个AI绘画工具的区别,我们应该如何选择?
首先,我们先来做个简单的小游戏:

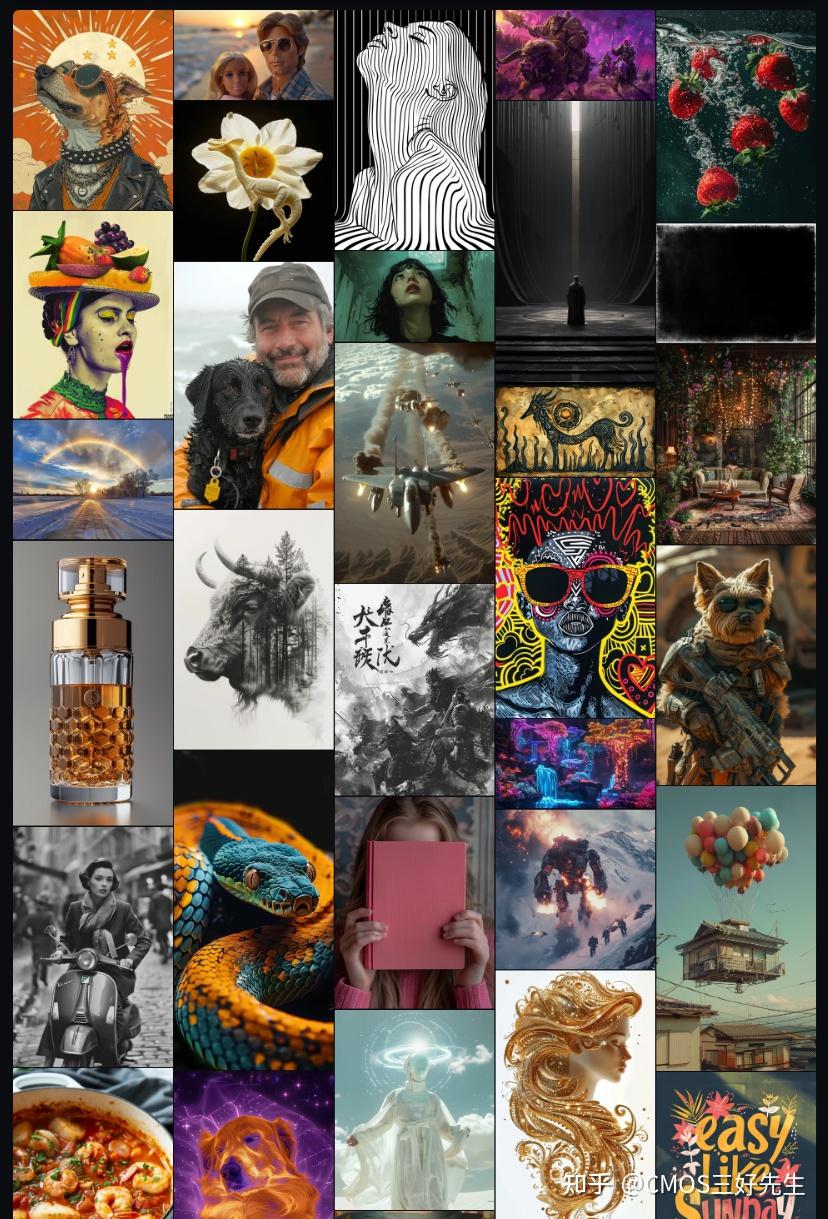
上面这2幅图,你更喜欢哪一张?
如果你更喜欢图1,那么你选择了Stable Diffusion;反之,你选择了Midjourney。
当然,上面的图片只是SD和MJ所有作品展示的冰山一角,如果你想看更多作品,可以自己去网上冲浪搜索一番。
其实,SD和MJ都是非常优秀的世界顶尖的AI绘画工具,在生成图片的效果方面可谓是不分伯仲。但对于普通人来说,我的建议是选择Stable Diffusion(SD)。
目前一共推出了SD1.4、SD1.5、SD2.0、SDXL1.0等多个版本,出图的效果也是越来越好。

优点
- 开源工具,可以部署在本地使用,完全免费
- 好的绘画提示词和参数配置出图效果非常好
- 用户可以自己训练属于自己的SD绘画模型,并上传到模型网站,有的模型网站还能赚钱
缺点
- 本地部署对电脑显卡配置有一定要求,对新手用户不够友好
- 绘画提示词太简单出图效果可能不好
目前一共推出了7个版本:V1V5、V5.1、V5.2和V6,从V3版本开始就一路大放光彩!

优点
- 对新手友好,简单的绘画提示词也能出很漂亮的图
缺点
- 不能本地部署
- 不能免费使用,30美元一个月
- 只能在Discord平台上使用或者调用API接口
- 不能自己训练自己的专属模型
所以,SD胜出的原因很简单——开源,可本地部署免费使用!而MJ则需要每个月30美元的费用,而且还需要访问Discord网页(或者下载Discord的App)来使用,还要科学地上网。
看到这里,你是不是有点想体验一下SD或者MJ的绘画效果了?
不过你先别急,作为一个刚接触AI的新手,你如果自己去摸索如何使用DS或MJ来绘画,那么你可能会走很多弯路。比如光是安装工具、下载模型这些步骤就很可能会让你望而却步,更别提进行后续的专业技术学习和将技术应用于商业变现了。
如果这个时候如果有经验丰富的老师来教我们快速入门并上手实践,那么一定能极大地加深我们对AI绘画的认识,甚至还能用AI绘画来给我们赚点外快!
在这里,我向大家推荐一门非常划算的AI绘画实践课——知乎知学堂的【AI 绘画设计师实战营】!
这门实践课有两场直播教学,资深老师从AI绘画入门最基础的部分开始讲起,教咱们如何运用Stable Diffusion和Midjourney等世界顶级的AI绘画工具。在这个课程中,我们可以学会如何用AI生成图像,制作3D模型等等!
无论你是图像设计行业从业人员还是没有接触过图像设计方面的工作,都可以用AI技术来帮你处理工作中涉及到图像设计相关的任务。
所以,别再犹豫了,赶快加入AI绘画技术学习的队伍吧!
课程结束后,咱们可以得到“Stable Diffusion 软件和安装教程”、“Midjourney 常用咒语合集”等超丰富的资料福利!一定要记得找助教老师领取,简直不要太划算!
下面,我就来简单介绍一下如何本地部署Stable Diffusion,对这一块感兴趣的小伙伴可以继续往下看哦
首先解释一下Stable Diffusion的中文翻译,就是“稳定扩散”的意思,扩散模型的工作原理也是目前主流的AI绘画的基本原理。简单的说,扩散的过程就是从一些随机像素点逐渐扩散,经过设定的扩散步数后,最终生成一幅图片,整个过程是非常不可思议的!能够想出这种方式生成图片的人简直是个天才!
下面这幅图展示了生成一幅图片扩散的过程:

想了解更多Diffusion扩散算法的童鞋,可以自行搜索“扩散模型详解”,网上已经有很多详细的讲解文章,在这里我也就不赘述了。
解下来,我简单说说如何在本地部署Stable Diffusion。
其实也不是很难,只需要按照大神们的步骤一步步来操作就可以了,需要解决的最关键的问题是——你得拥有一台有至少6G显存的Nvidia显卡的电脑!
下面是部署步骤:
注意,你需要会使用“Win+R”输入“cmd”命令打开CMD终端,如果这个不会,就不用继续往下看了!
- 下载并安装 3.10.X版本的Python(下载地址附在文末,安装的时候,记得勾选 Add to PATH添加至环境变量,如果不勾选就只能安装完成后自己手动添加)
- 下载并安装git(地址见文末),用git来下载大神提供的一键部署SD工具包(不想用git的,也可以去搜索百度网盘的资源下载,不过没会员下载就太慢了。)
再次注意:按Win+R输入cmd打开CMD终端,这个如果不会就别继续了。 - 在CMD终端运行命令:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui - 打开步骤3中下载的工具包所在的目录,打开stable-diffusion-webui文件夹,双击运行 webui-user.bat 文件
- 此时会自动开始自动安装(安装过程中可能会遇到问题,按照下面的解决方法解决即可)
- 打开浏览器,输入http://127.0.0.1:7860 就可以开始用SD来出图了!
如果卡在Installing gfpgan这里,然后报很多错误信息。
解决方法:
1)用文本编辑器(比如:记事本)打开stable-diffusion-webui文件夹launch.py
2)查找包含https://github.com 的链接,在链接前面加上 https://mirror.ghproxy.com/ 后重新双击运行webui-user.bat,如果正常的话,应该会一直安装下去,出现Running on local URL: http://127.0.0.1:7860的字样就OK了。
如果出现:No module ‘xformers’. Proceeding without it.
解决方法如下:
1)用文本编辑器打开 webui-user.bat文件
2)在set COMMANDLINE_ARGS=后面加上–xformers
3)重新运行webui-user.bat,就会开始安装xformers。
如果SD出图很卡,卡在95%不动了。
把webui-user.bat文件中之前修改过的位置set COMMANDLINE_ARGS= –xformers后面加上: –no-half-vae –medvram –theme dark,应该就可以了!
好了,本地部署SD就是这么简单!你学会了吗?要是没有大神提供的这个工具包,那就没这么简单咯!当然,还有秋叶大神提供的更简单的一键部署的工具包,比我这个步骤更简单,可在网上自行搜索!
看到这里,如果你仍然不想自己在本地部署,但是还是想马上体验SD和MJ,那么赶紧加入知学堂的【AI 绘画设计师实战营】吧!
最后,希望大家能够像我一样,积极投身AI时代的浪潮,通过AI给我们赋能,让我们成为优秀的AI时代的弄潮儿!
【下载地址】
Python3.10.6 Git 2.44.0
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/245894.html