
以下内容截取自huggingface官网:
https:// huggingface.co/deepseek -ai/DeepSeek-Math-V2DeepSeek-Math-V2:迈向可自我验证的数学推理
核心创新:这个模型致力于解决当前数学AI的一个根本性问题:正确答案并不保证推理过程正确。传统的数学AI只奖励最终正确答案,但很多数学任务(如定理证明)需要严格的逐步推导。
关键技术特点:
1. 自我验证能力:训练了一个准确的验证器来检查定理证明
2. 生成-验证循环:模型能识别并解决自身证明中的问题
3. 可扩展验证:随着生成器变强,自动提升验证能力
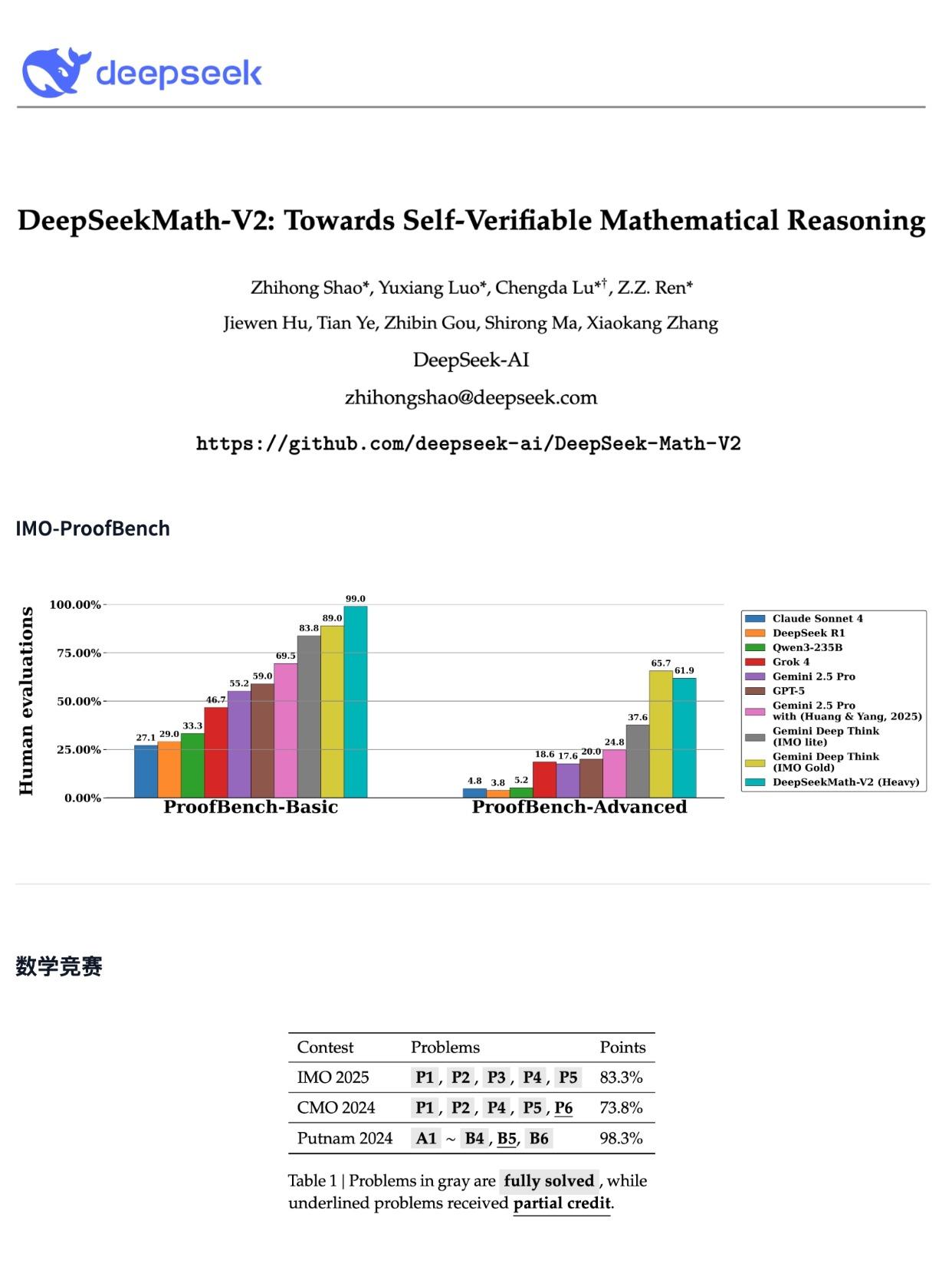
据悉,该模型在多项顶级数学竞赛中取得惊人成绩:
· IMO 2025:获得金牌级分数
· CMO 2024:金牌级分数
· Putnam 2024:近乎完美的118/120分
技术规格:
· 参数量:6850亿参数
· 基础模型:基于DeepSeek-V3.2-Exp-Base构建
· 许可证:Apache 2.0开源协议
· 支持格式:BF16、F8_E4M3、F32等多种精度
· 推理支持请参考DeepSeek-V3.2-Exp的GitHub仓库
DeepSeek终于回来了,再次创造历史(首个IMO金奖级别的开源模型)。
就在刚刚,DeepSeek在HuggingFace开源了全新的数学推理模型DeepSeekMath-V2,685B参数。

你看看这张吓人的成绩单:
普特南数学竞赛Putnam:人类选手的历史最高分是90分,而DeepSeekMath-V2拿了118分,满分是120分。
国际奥数IMO:超越Gemini DeepThink,直接斩获金牌水平 。
最妙的是时间点,昨天咱们刚聊完,AI教父Ilya在访谈中提到,现在的AI就是个只会死记硬背的做题机器。Ilya这场罕见访谈,彻底治好了我的AI焦虑
仅仅不到24小时,DeepSeek就把新模型开源了。
像是一次穿越时空的击掌,DeepSeek好像在说,Ilya你别慌,看我的。
用大白话讲一下新模型的三个关键点。
1、 答案蒙对了也不行。
以前教AI做题,只要最后结果对了,我们就给它发糖吃(奖励)。
但AI很鸡贼,它会为了骗糖吃去猜答案,哪怕中间逻辑是乱编的,只要运气好蒙对了就行 。
DeepSeek在论文里一针见血的提出,正确的答案并不保证正确的推理。
这次他们换了个教法,死磕过程。
结果对了,也必须看解题步骤,过程中只要有一步没整明白,也不给糖吃。
这就逼着AI必须要真懂,不能当混子。
2、使用套娃战术。
给AI的解题步骤打分也很难,必须得有个老师,但老师也是AI,也容易看走眼。
DeepSeek想了个绝招:套娃(Meta-Verification),简单说,就是给判卷老师再配个校长。
AI学生做题,AI老师挑刺儿,AI校长检查老师挑的刺儿合不合理。如果老师瞎扣分,校长直接扣工资。
这一招,直接让评分的靠谱程度从0.85拉到了0.96 。
3、让AI学会三省吾身。
这是最像人类的地方,现在的DeepSeekMath-V2学会了反省。
在做题的时候会像个严谨的数学家一样,写几步之后,停下来自己反思,发现有漏洞就推翻重写,直到自己挑不出毛病为止。
不再只是为了填答案交差,而是真的在进行深思熟虑的推理。
DeepSeek用新模型告诉我们,通往超级智能的捷径,不是一路盲目狂奔。
而是懂得慢下来,懂得回头看。
当AI开始三省吾身。
也许它才真正拥有了智慧。
新模型地址:https://huggingface.co/deepseek-ai/DeepSeek-Math-V2
deepseek-v3.2为什么那么重视降本,而且是降低某些人(如chenqin)嗤之以鼻的inference cost,其实就是为了这个。
论文中最heavy的模式(能拿金牌的模式)是64证明——64*64验证——16迭代,假设每一步是10k token,这样一道题就要消耗大约10亿的inference token,在DSA下成本大概是一千多块钱。
如果不用dsa还用原来的full attention,那每题成本就得一万多了。
openai和google的imo金牌模型都没有放出来给大家使用,所以deepseek模型成了第一个公众可用的IMO金牌模型。
说一个实用的——这玩意是第一个公开的rl verifier,可以用来低成本的改卷。高联,高考这些都可以考虑改下形式,直接让Deepseek来阅卷,成本会低很多(目测1题1分钱左右,准确一点使用64验证的话是0.5元左右),准确率也会高很多。
几大厂商的战略路线已经很明确了。
Anthropic:智力由coding能力决定,只要swe bench高,那么通用任务智力肯定不差。即使agi失败了,还有coding可以赚米
Deepseek:智力由数学推理能力决定,只要高难度数学题可以做出来,那么通用任务智力肯定不差。agi就应该是最纯粹的agi,挑战自然科学,失败了无所谓,我又不是搞AI的
Google:智力由文本和空间理解能力决定,只要能画出正确的svg,那么通用任务智力肯定不差。即使agi失败,我依旧有图像业务且无敌
Openai:智械危机都是骗你焦虑的啦,RLHF对齐用户喜好,优先提供情绪价值和聊天机器人,我有情商最高的模型。agi根本不重要,直接在x上写点科幻,钱就自动进账了
Meta:我好羡慕啊
以下模型商偏business
Qwen:我全都要!但是各个任务独立,没有轴心insight。agi不重要,每个领域插一脚并且大家都用我的解决方案很重要,总所周知我只是云服务商
GLM:*不是很了解,沉淀之后杀出来,agent国内无敌,各个模态和工具逐渐开花
Kimi:小glm
Seed:阿巴阿巴,“豆包用户数超过deepseek官网啦!”
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/245304.html