
快科技3月19日消息,小米深夜炸场发布了三款模型,其中包括面向Agent时代的全模态基座模型——Xiaomi MiMo-V2-Omni。
该模型专为现实世界复杂多模态交互与执行场景打造,从底层构建了文本、视觉、语音融合的全模态基座,以统一架构深度绑定“感知”与“行动”,原生具备多模态感知、工具调用、函数执行及GUI操作能力,可无缝接入各类Agent框架,大幅降低全模态Agent的落地门槛。
在正式发布前,该模型早期测试版本以「Healer Alpha」为代号匿名上架全球最大API聚合平台OpenRouter,未做任何宣传便实现调用量自然攀升至平台前列,还在OpenClaw测评榜单PinchBench上拿下均分第一,能力得到用户与专业测评的双重认可。

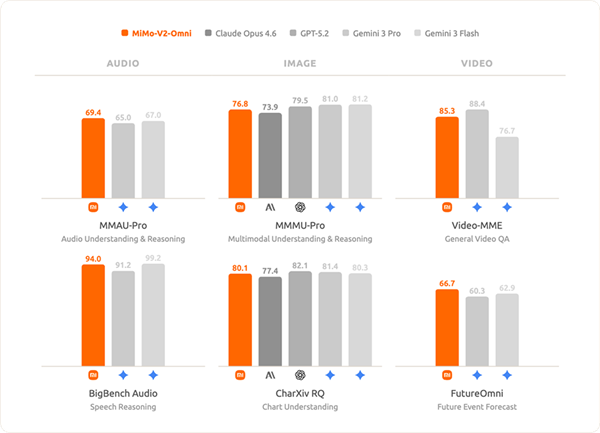
MiMo-V2-Omni拥有对标国际前沿的全模态感知能力,是高效执行的坚实基础。
-音频理解上,支持环境声分类、多说话人分离等功能,可深度理解超10小时连续长音频,综合表现超越Gemini 3 Pro,跻身当前最强音频理解基座模型之列。
-图像理解上,具备强大的多学科视觉推理和复杂图表分析能力,超越Claude Opus 4.6,逼近Gemini 3 Pro等顶尖闭源模型水平。
-视频理解上,支持原生音视频联合输入,依托创新预训练技术,拥有出色的情境感知与未来推理能力。
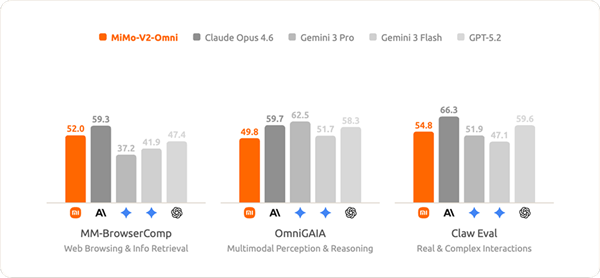
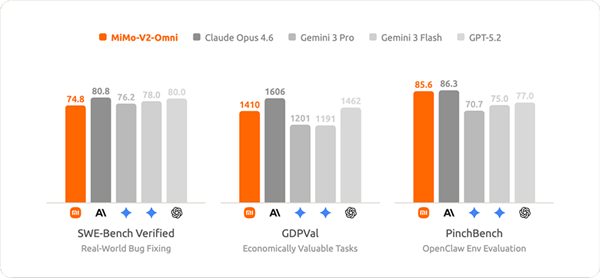
同时,该模型实现了从理解到完成任务的智能体能力升级,能跨模态理解复杂环境,自主制定并执行计划,遇异常时实时修正策略,最终端到端交付完整结果。
在真实数字环境交互的评测基准中,其表现比肩Gemini 3 Pro,前沿感知能力与原生行动能力形成复合优势,且在纯文本智能体任务上也保持着高度竞争力。
经过一周迭代优化,模型的全模态感知和智能体行动能力更稳定,在日常生产力场景中展现出巨大潜力。
目前MiMo-V2-Omni已正式开放API服务,支持256K上下文长度,定价为输入0.4美元/百万tokens、输出2美元/百万tokens,开发者可通过指定平台接入;同时模型联合OpenClaw、OpenCode等五大Agent开发框架团队,为全球开发者提供为期一周的限时免费接口支持。
该模型在多场景下的能力表现亮眼,跨模态层面能深度解读电影片段的隐喻与情感,长音频层面可精准提炼数小时访谈的核心论点与逻辑脉络。
结合OpenClaw框架还能像真人一样操控浏览器,完成选品比价砍价下单、制作并发布短视频等复杂操作,遇网页报错、多标签切换等问题可自主解决。
在智能办公场景,模型与金山办公合作接入WPS Office,可根据指令直接生成高质量Word、结构化Excel、规范排版PDF及完整PPT,跳出对话机器人限制,切实提升日常工作效率。
【本文结束】如需转载请务必注明出处:快科技
责任编辑:建嘉
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/245011.html