
在国庆这几天,deepseek,glm4.6,Claude4.5全部更新后,但是Claude4.5价格确实有点高,想在国内选一个好点的模型,选哪个好点,glm4.6?codebuddy?deepseek?
如果你在 Claude Code 里用 GLM-4.7 写代码,可能经常感觉它理解复杂需求或生成高质量方案的能力有限。
一个性价比很高的办法是:让 GLM-4.7 做它擅长的事——收集上下文,再交给 Gemini 3.0 Pro 做分析和设计,最后回到 Claude Code 执行修改。
具体步骤很简单:
1. 在 Claude Code 里开启 Plan 模式
用清晰的提示词描述你的问题或需求,让 GLM-4.7 帮你收集相关的代码文件、依赖、报错信息、结构说明等所有上下文。
GLM-4.7 的强项正在这里——它能很好地理解你要它“收集什么”,并且把相关文本整理出来。
不要觉得plan模式啰嗦慢,但是他能精确收集上下**计划,比直接开干改代码强太多。
2. 把整理好的完整上下文发给 Gemini 3.0 Pro
去 Google AI Studio(免费,经常被检测地区不对或者报错的,可以用家宽或者clas? party,他这个智能嗅探是真的强),将刚才收集的代码、需求、背景一起粘贴给 Gemini 3.0 Pro,让它分析问题、设计修改方案、提供具体代码改写建议。
Gemini 3.0 Pro 在复杂逻辑、架构设计上的表现明显更强,能给出更可靠的方案。
3. 将 Gemini 的建议带回 Claude Code
把分析结果和修改方案粘贴回 Claude Code(推荐先用plan模式让他自动收集上下文给出更加精细的指导),让 GLM-4.7 根据方案执行具体的代码改动。因为它已经有了明确的指引,此时只负责实施,效果会好很多。
这个流程的核心就是上下文工程:
用弱模型做它擅长的信息整理与聚合,强模型做它擅长的分析与设计,分工合作,低成本获得高质量输出。
这样既不需要全程使用高价 API,又避开了 GLM-4.7 在复杂推理上的短板,适合日常编码中那些“需要深度思考”的场景。
试试看,你会发现 GLM-4.7 + Gemini 3.0 Pro 的组合,效率提升非常明显。
达到“可用”级别,使用时感觉和Claude 3.x比较接近,两者患有类似的阿斯伯格症,很多时候会固执地反向执行你的要求。
无法执行较为复杂的任务,最好是一次提一个修改点,上下文较长时明显丢三落四,低级错误较多。喜欢用造火箭的手段拧螺丝,喜欢使用不存在的方法,喜欢假设所有准备已经完成并直接使用某些方法或类。和Claude 3.x一样,令人血压升高。
我偏向于认为,GLM模型的基础能力已经到位了,但是调教还有问题。给人的感觉是明明会做的题,到处粗心丢分。
在调用工具时并出错时,哪怕工具给出了明确的错误原因,GLM会固执地重复执行并重复失败,不要试图用它跑全自动Agent任务。
智谱提供了220元1亿1千万Tokens的三折资源包,三折的价格可以算是物美价廉,建议购买。至于原价的API不能算太便宜,但比其他选项确实便宜得多。资源包的总tokens数虽然有限,但是听说GLM5会在年底发布,到时候会有新的优惠。
单纯看价格,相对于Claude/GPT要便宜的多,但是注意,首先在不犯错的情况下,执行相同的任务GLM4.6和GPT5-Codex相比会多消耗将近一倍的tokens,而资源包按我的理解是没有缓存优惠的。同时解决相同的问题GLM4.6可能需要多尝试几次,如果考虑你自己的时间成本,那就不便宜了。
4bit MLX版本的精度已经到了可用的下限,大小199G已经到达256G版本Mac的上限。全精度模型在整体任务的把控能力尚且不足,我就不指望用低精度本地跑Agent了。而简单开着问些问题或者做一些自动化资料处理任务的话,似乎有些大材小用。也许智谱可以考虑下GPT-OSS的做法。
参考:M3 Ultra 256G最低配置下,4bit量化MLX模型速度约20 tokens每秒。这个速度只适合用来整晚跑后台任务,直接交互会让人急死。意外的是,能力看上去还可以,有空了做个全面的测试看损失到底在什么程度。
如果你全程使用单一模型,那么GLM4.6可能不是最好的选择,影响情绪和效率。
如果你的工具可以支持多模型混用,比如用GPT来做高级别计划,然后分派具体的实现内容给到GLM,那么也许OK。但节约的费用可能非常有限。
单纯从费用出发的话,可能你应该尝试Grok-Code-Fast-1,而不是GLM4.6,Grok的这款模型有些问题可能解决不了,但是发挥比GLM稳定地多,低级错误较少。
如果你是非开发人员但需要写代码来处理一些数据或简单的自动化,或者如果你是学生且预算有限,那么无脑选择GLM。任务的复杂度不高而难度较高时,GLM足够好,也足够便宜。
如前所述,GLM目前是个有力不会使的模型。请智谱的大佬再接再厉,最好在GLM5发布时,来一个能力更强的原生4bit MLX版本,这样我就不会为了tokens抠抠搜搜,而是开着Agent随便造了。
随着模型能力的提升,个人经济承受能力已经成了使用AI的最大障碍。Claude和GPT的能力虽然强,但跑起来真的是在烧钱。如今(假如不看写出来的内容)用Claude写代码已经没有之前那种高血压的情况了,让人觉得在愉快而流畅地烧钱。GPT更强也稍便宜,但Codex卡得只有Claude10分之一不到的速度,让我这个急性子觉得在一卡一卡地烧钱。整晚地跑Agent虽然美妙,但我已经实在没有钱了 。
Update 11⁄8
无语啊,昨天开始看到Claude Code里的报错:
API Error: Claude Code is unable to respond to this request, which appears to violate our Usage Policy
( https://www. anthropic.com/legal/aup ). Please double press esc to edit your last message or start a new session for
Claude Code to assist with a different task. If you are seeing this refusal repeatedly, try running /model
claude-sonnet-4- to switch models.
第一反应是Claude Code把GLM禁了。然后在Roo Code里也看到连续的报错:模型没有给出任何有意义的回复。我一拍脑门Roo Code升级后对GLM不兼容了。掏出Postman测了下,api正常的呀,那应该就是anthropic和roo的问题了。
今天在ChatBox里连GLM问技术问题,又报错。福至心灵,检查提示词,发现和梯子相关的敏感词。再测试发现API网关会直接拒绝包含敏感词的请求。
我倒是能理解屏蔽特定内容的初衷和必要性,但好歹把API网关的拒绝包装成一个回答吧,直接把工具链搞断了会让用户摸不着头脑吧。
用本地的4.6跑了下,模型倒没有拒绝,直接输出了完整的回答。代码可用,在4bit精度下和其它模型比较均略有不足,唯一比它拉跨的是GPT5,不晓得Open AI干了什么,最近半个月感觉GPT一直在梦游。
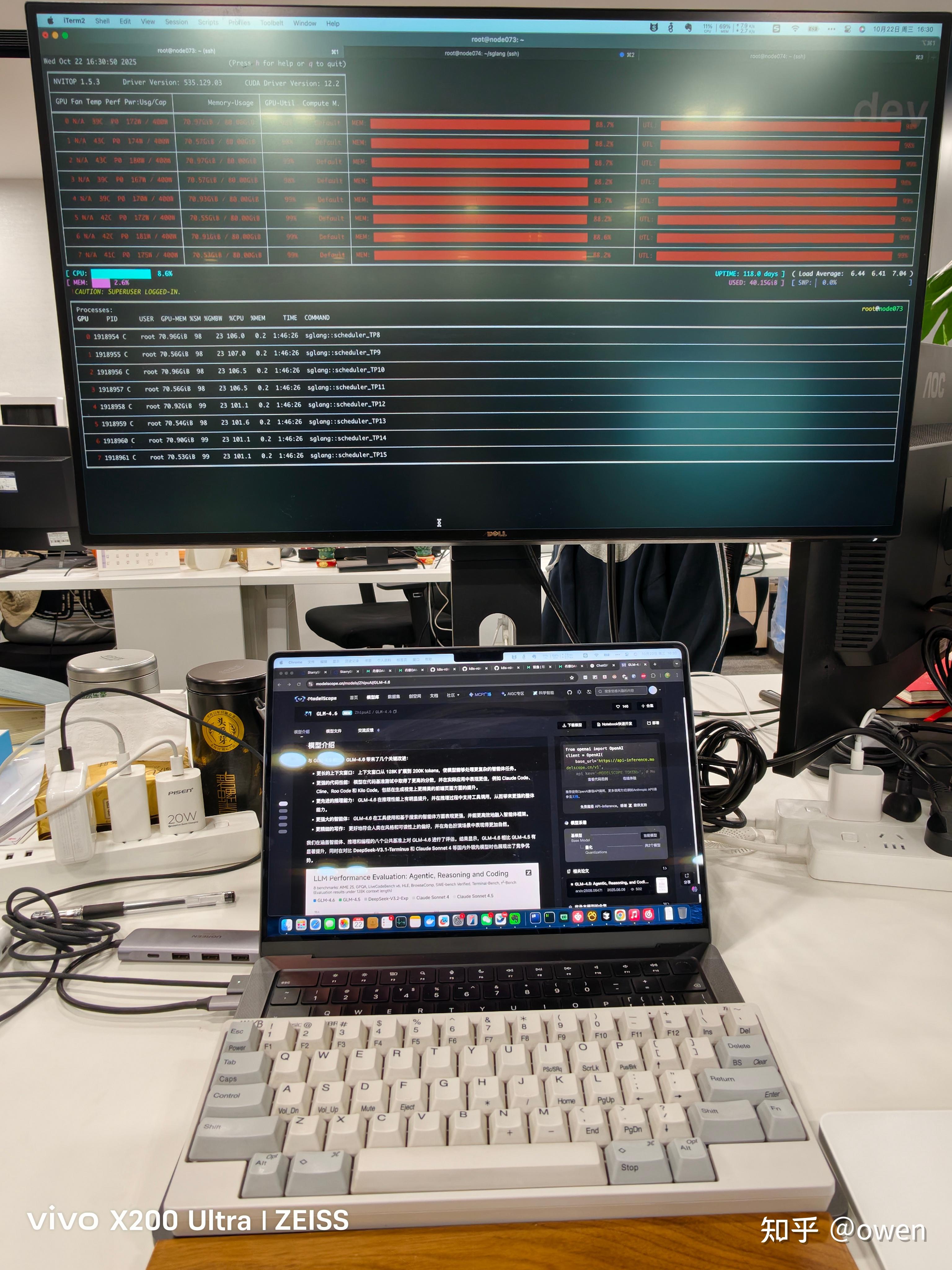
最近找了三台 nvidia a800 运行 glm4.6 模型,试了一段时间,claude code 输出质量还是可以的。
现在智普官方提供了 20元的包月套餐,便宜实惠,api 还兼容了 claude 协议。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/244989.html