
年初已经有deepseek v4 发布的消息了,但是已经过去2个月了,还是没有看见v4的身影, qwen 已经在春节发布了新版本,确定已经不太成功了, 如果v4还不发布,感觉很多小厂会切换模型backbone了, 更新周期太长,跟不上进度!!!
官方从来没宣传过v4。官网上就算把上下文扩到了1m,显示的最新模型版本也一直是v3.2。
华尔街搞预期管理,防止出现去年那样的deepseek时刻搞得他们措手不及,花了极大的代价才把股市企稳。
国内就不要去凑这个热闹了。
先甩个暴论:DeepSeek 在尝试在国产芯片上完成旗舰模型的训练和推理部署。
V4的发布信号其实很早就有了。1月9日,路透社就报道说DeepSeek计划2月中旬推出一个专注编码能力的新模型。随后各方消息陆续放出来:春节前、春节后、2月底、3月第一周……每一个窗口都被言之凿凿地预测,然后每一个都落空了。
截至今天,2026年3月13日,V4仍未正式发布。这就很反常了。回头看DeepSeek之前的节奏:
- V2:2024年5月
- V2.5:2024年9月
- V3:2024年12月
- R1:2025年1月
- V3.1:2025年8月
- V3.2:2025年12月
从V2到V3用了七个月,从V3到现在已经过了一年三个多月了。
一个技术能力持续被验证、融资充裕、团队稳定的团队,模型训练大概率不会卡这么久。那卡在哪?
2月底路透社的那篇独家报道里,有个信息:DeepSeek在V4上优先向华为、寒武纪等国产芯片厂商开放早期访问。
意思很明确了,V4的训练和推理流程,正在主动脱离NVIDIA CUDA生态。
我们都知道,CUDA是整个深度学习基础设施的事实标准,从PyTorch的底层算子,到NCCL的多卡通信,再到cuBLAS的矩阵运算,到TensorRT的推理优化——你用的每一层软件栈,底下都是CUDA。
去CUDA化,需要要把这一整套软件栈在新的硬件架构上重新实现一遍,大概列一下:
- 算子层面:Transformer里的attention、layernorm、embedding等核心算子,全部要在华为昇腾的CANN或者寒武纪的BANG-C上重写和调优
- 通信层面:万卡集群训练时的AllReduce、Ring通信等操作,要适配国产互联芯片的拓扑结构,不能用NCCL
- 混合精度和显存管理:FP8/BF16的混合精度策略、ZeRO优化器的显存卸载方案,全部要针对国产芯片的硬件特性重新设计
- 推理部署:线上serving的KV Cache管理、Continuous Batching、Speculative Decoding等推理优化技术,也要适配新硬件
这里面任何一个环节做不好,训练效率可能直接掉一个数量级。而DeepSeek的核心竞争力恰恰是”用更少的算力做出更强的模型”——如果在国产芯片上训练效率大幅下降,那这个故事就不成立了。
所以他们必须把每个环节都打磨到足够好才能发。
有人可能会问:之前V3和R1不也训练得好好的吗?为什么V4要折腾这个?
两个原因。
第一,外部压力。 2025年以来,美国对中国AI芯片的出口限制持续收紧。DeepSeek之前能用上H800甚至有传言用上H100,但这个窗口正在关闭。如果V5、V6还依赖英伟达的硬件,那整个公司的技术路线就建立在一个随时可能被掐断的供应链上。V4是DeepSeek验证”国产芯片可用”的关键节点,这件事必须在这一代模型上完成,不能再拖。
第二,内部技术准备已经到位。 DeepSeek在2026年1月发表了两篇很重要的论文:mHC(Manifold-Constrained Hyper-Connections) 和 Engram(条件记忆机制)。mHC解决的是深层网络的梯度流动问题,Engram解决的是超长上下文的信息检索问题。这两个技术之所以重要,不仅仅是因为它们提升了模型能力,更在于——它们天然对硬件的算子类型要求更简洁。
换句话说,DeepSeek在设计V4架构的时候,大概率就已经把”如何让这个架构在非CUDA硬件上高效运行”纳入了考量。这不是事后的移植适配,而是从架构设计阶段就为国产芯片做了协同优化。
这也解释了为什么他们不急着发——因为这不是一个”模型训完就能上线”的项目,而是一个”模型+训练框架+推理引擎+硬件适配”的系统工程。
3月9日,有不少人注意到DeepSeek的网页端产品出现了一次更新,编码能力和上下文处理都有明显提升。社区里有人开始叫它”V4 Lite“。
我个人判断,这大概率是V4完整版发布前的一次灰度验证。可能是V4架构的一个较小参数量版本(传闻约2000亿参数),先在现有的NVIDIA集群上跑起来,同时在国产芯片集群上做对比测试。
这个操作在工程上完全说得通:先用小模型验证架构的正确性和推理效率,再把参数量推到万亿级别。特别是在换硬件平台的情况下,你不可能一上来就拿万亿参数的模型去试错,成本太高了。
如果这个判断成立,那V4 Lite的表现基本可以作为V4完整版能力的一个下界参考。从社区反馈来看,编码能力的提升已经非常显著了。
那到底什么时候能发?说实话,可能,DeepSeek自己也没有一个100%确定的日期。有几个信号可以关注一下:
- V4 Lite的出现说明模型架构已经定型,不存在”还在探索技术方向”的风险
- 多家国内云厂商(阿里云、百度智能云等)已经表态要第一时间接入V4,说明商务层面的准备工作已经在推进
- 两篇核心论文早在1月就公开了,DeepSeek不是一个会提前很久放出技术细节的团队,论文公开通常意味着距离产品发布不远
我个人的猜测是3月中下旬,大概率会分两步走:先开放API访问,再放出开源权重。不排除国产芯片版本和NVIDIA版本会有一个时间差。
DeepSeek V4,在我的认知里,”它能不能打赢GPT-5”“benchmark能刷多高”,都不太关注了。如果DS能用非NVIDIA硬件,也能训出世界一流的大模型,我绝对为它摇旗呐喊。
如果这件事被证明可行,影响的可不只是DeepSeek一家公司。意味着整个中国AI产业有了一条不依赖于美国芯片供应链的技术路径。后面的阿里、字节、百度、腾讯,都可以沿着这条路走。
这大概也是DeepSeek宁愿多拖几周也不愿意草率发布的原因
今天头部模型已经进入一个很明显的阶段:虽然大家各自的大模型还在涨分,但很多场景里,用户真正感知到的提升,已经不再和 benchmark 提升线性对应了。真正能够让用户和企业感到有兴趣的地方,是需要现在的大模型有足够的低延迟、更强的工具调用能力、还有更加稳定的任务链成功率。
所以如果 V4 的本质还是:V3.2 的放大版 + 参数更多 + 成本更高。那它的战略意义会很有限。
最近各大媒体一直把V4 视作 DeepSeek 的下一次关键发布,甚至把它和中国本土芯片适配、对美系硬件依赖下降、下一轮中美 AI 竞争放在一起讨论。无论这些报道里有多少市场放大成分,它至少说明一件事:V4 已经不只是DS的一个简单的版本号,目前各大厂商一直对它寄予厚望,而且市场对 DeepSeek 下一阶段能力充满想象。

要说DeepSeek V4版本的能力,从最近公开出来的研究方向,本身就在说明他们可能也不想只做“更大的 V4”。那么V4 模型到底是什么样的具体框架和技术呢?目前还没有出,只能从它之前发布的几个技术去猜测一下。
V4 大概可能也是采取了 V3.1一样的推理融合技术。Chat模型和Reasoning模型进行融合,形成一个融合推理模型来进一步提升模型效果,这种一般训练需要经过四个阶段。
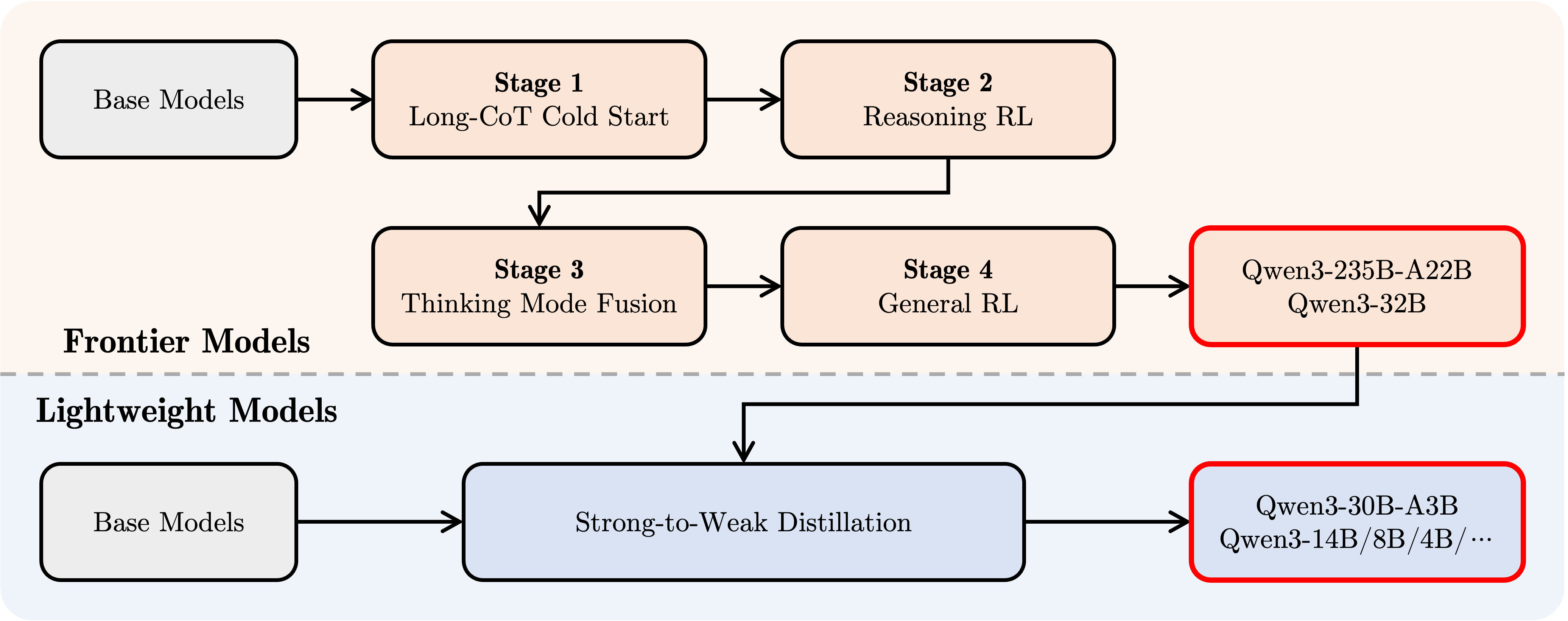
阶段一:长思维链冷启动
- 方法:使用涵盖数学、代码、逻辑推理和 STEM 问题等多样化的长思维链数据对模型进行微调。
- 目的:建立模型的基本推理能力。
阶段二:基于推理的强化学习(RL)
- 方法:利用基于规则的奖励机制,进行大规模的强化学习。
- 目的:增强模型的探索和利用能力,提升推理深度。
阶段三:思维模式融合
- 方法:在结合长思维链数据与常用指令微调数据的组合数据上对模型进行微调。
- 目的:将非思考模式整合到思考模型中,实现推理与快速响应能力的无缝结合。
阶段四:通用强化学习
- 方法:在包括指令遵循、格式遵循和 Agent 能力等在内的 20 多个通用领域的任务上应用强化学习。
- 目的:进一步增强模型的通用能力并纠正不良行为。
在注意力机制上,可能还是选用之前的 DSA(稀疏注意力,DSA),旨在在处理长上下文(long context)时提升训练与推理效率,同时尽可能保持输出质量不变。
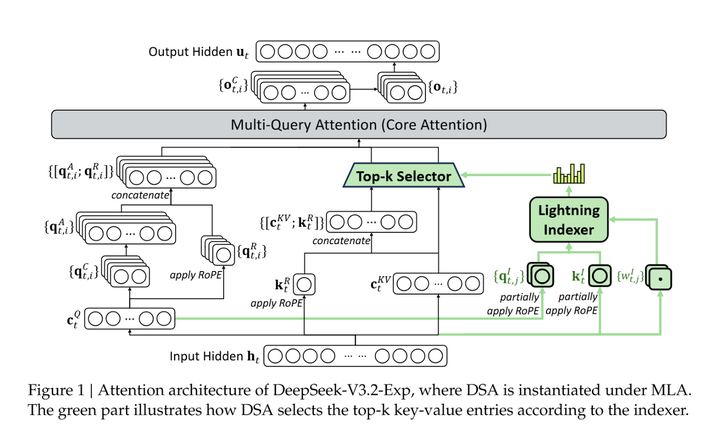
稀疏注意力的思路在很多新一代 Transformer 变体中都在被探索:即不是所有 token 间都做全连接的 self-attention,而是选一些关键 token 或局部连接,从而减少计算复杂度。DeepSeek 在这个版本中尝试了一种“细粒度稀疏”的策略。具体就是用到了两个关键组件:Lightning Indexer和Top-k Token Selection。
Lightning Indexer:给定一个 query token ,它会和之前的 token计算一个轻量的 index score。
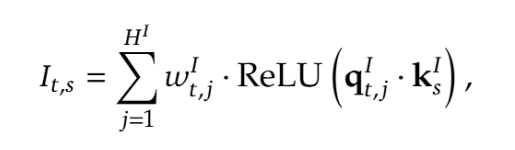
它的计算量极小,主要负责快速判断哪些 token 可能相关。
Top-k Token Selection:对每个 query token,indexer 会输出一组分数 I,然后选取 top-k 的 key-value token,丢掉其余的。接下来只在这些 top-k 上计算真正的注意力。
经过两个组件之后,这样复杂度从 O(L^2)降低到O(LK),其中 k<
包括在最新的 V3.2 模型中,有更多的 Agent 技术进行调用。表现包括:
- 在“思考—执行”两步之间切换更自然
- 给出的 action 更干净、更利于自动化
- 思考链条(CoT)不会疯狂拉长内容
- Token 成本可控
这一点在实际应用里非常重要:因为大部分公司真正需要的不是“聊天模型”,而是能独立完成任务的 AI agent。
新版本的V3.2 模型不同于过往版本在思考模式下无法调用工具的局限,它是首个将思考融入工具使用的模型,并且同时支持思考模式与非思考模式的工具调用。
在具体的训练当中,DeepSeek使用一种大规模 Agent 训练数据合成方法,构造了大量「难解答,易验证」的强化学习任务(1800+ 环境,85,000+ 复杂指令),大幅提高了模型的泛化能力。
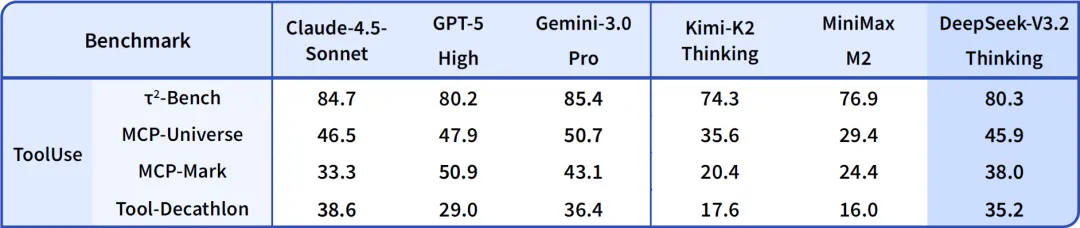
从上面的图来看,DeepSeek-V3.2 模型在智能体评测中达到了当前开源模型的最高水平,大幅缩小了开源模型与闭源模型的差距。值得说明的是,V3.2 并没有针对这些测试集的工具进行特殊训练,也就是能够广泛适配不同的任务。
这个技术就是为了解决三个问题:
- Degradation problem:深层网络不是过拟合,是根本训不好
- Residual explosion:残差叠加后范数不可控
- 表示空间塌缩 / 扭曲:深层特征不再可解释
mHC 的改进的核心点在于:把每层的 residual mixing 矩阵 (H^{res}_l) 约束为“双随机矩阵(doubly stochastic)”,也就是落在 Birkhoff polytope(双随机矩阵集合/置换矩阵凸包)这个流形/多面体上
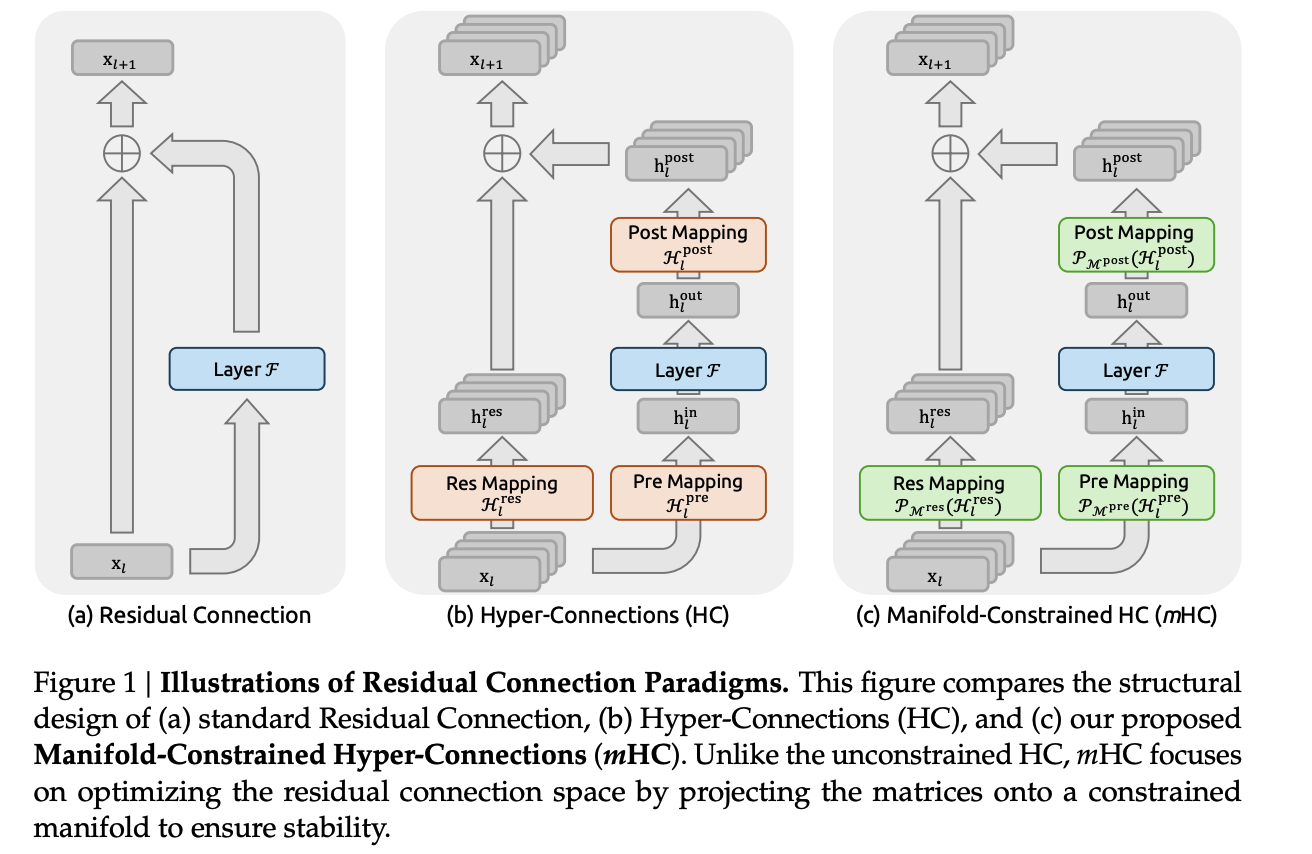
DS研究团队通过实验观察到,由于缺乏有效约束机制,HC系统在训练过程中会出现控制参数无序波动的现象。为解决这一问题,研究团队引入了Birkhoff polytope这一特定流形结构作为优化空间。选择该流形的主要依据在于其具备多重优良特性:
- 范数不扩张(Non-expansive) 双随机矩阵的谱范数有界,因此能抑制梯度爆炸风险
- 连乘闭包(Compositional Closure) 双随机矩阵集合对乘法封闭:多层连乘 仍是双随机,因此“跨很多层”的直通项也保持同样的守恒/稳定属性
- 几何解释:置换的凸组合 Birkhoff polytope 是置换矩阵的凸包,所以 可视作“对多种置换混合方式的加权平均”;反复作用会带来更强的跨流混合,但仍是单调增强的融合而非失控放大
此外,mHC 还加了非负性约束,避免正负系数叠加造成信号抵消(也可理解为一种简单的流形/可行域约束)
HC 到底是“哪里不稳”?mHC 又是“怎么把它稳住的”呢?从实验上看,在前期训练过程中,HC loss 波动巨大,甚至有负值,说明训练初期 residual mixing 还没“学稳”。中后期的时候,HC 的 loss gap 稳定停在一个非零区间,且有明显的长期抖动。
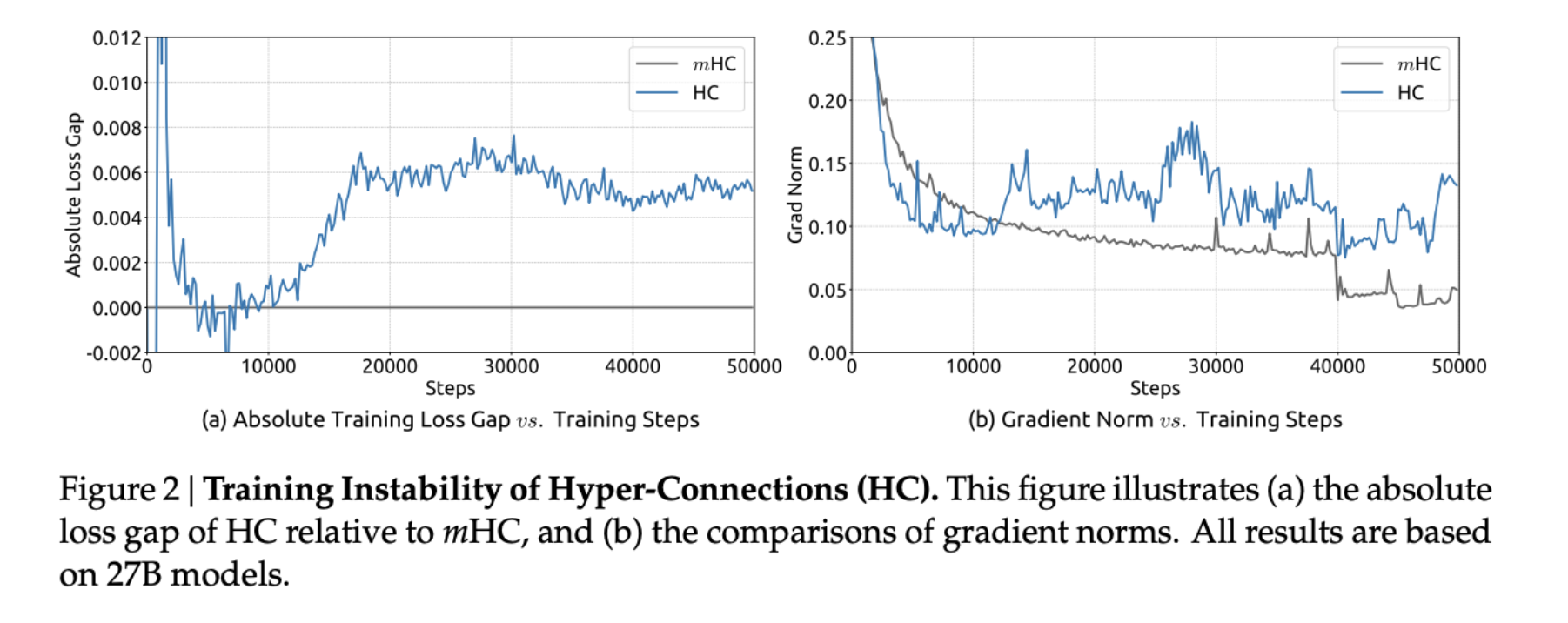
而 mHC作为 reference,整体的loss 基本单调、平滑,而且没有长期偏移
在前向和后向传播上,多层连乘后,梯度链路被放大成“指数塔”。这就是 HC 训练不稳的根因
不是某一层“坏”,而是可学习 residual mixing 的“连乘”失控导致的。
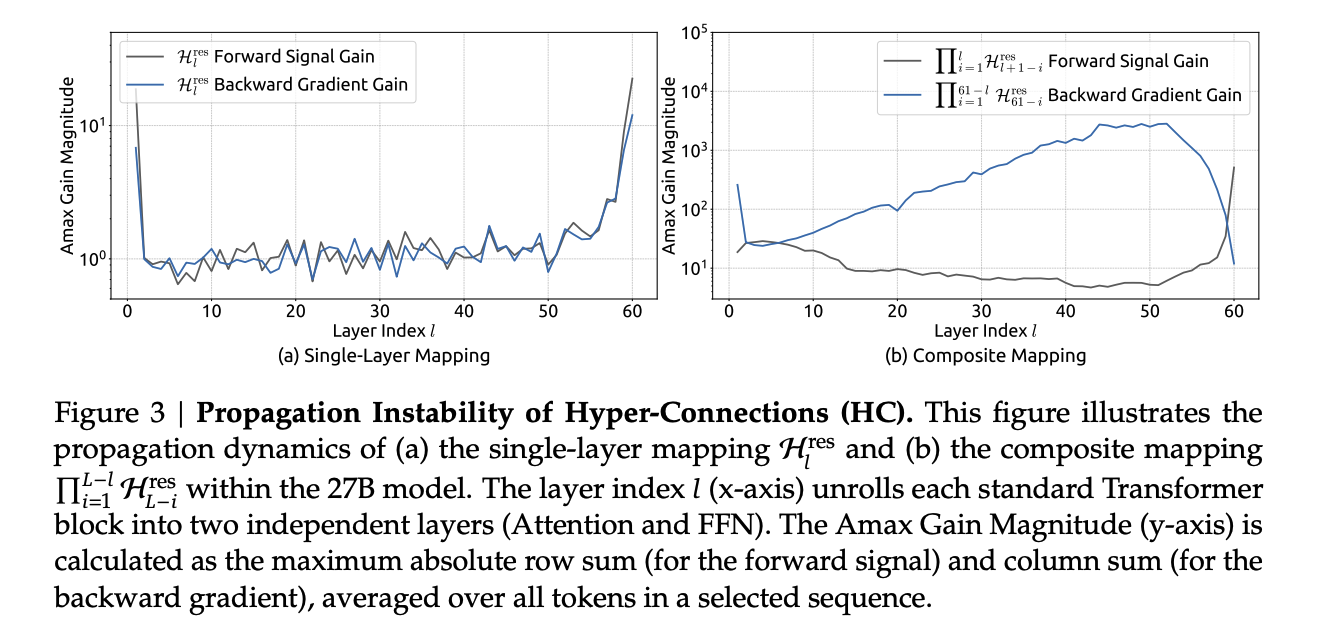
从上面的这几个技术上整合来看,DeepSeek 真正要解决的,不是简单的把模型做得更大更佳,它是在探索“下一代 AI 系统该怎么做”。
我们不一定需要“又一个 DeepSeek V4”;但我们很需要 DeepSeek 给出一个“为什么下一代 AI 还值得期待”的版本。
也就是:
- 不需要重复上一轮大模型军备竞赛
- 需要一个能把 模型、记忆、推理系统、Agent、多模态、部署效率 重新整合起来的新旗舰
如果 DeepSeek V4 做到的是后者,那它就不是“又一个 V4”;它会更像 从大模型,走向 AI 系统模型 的分水岭。因为再下一步,大家竞争的可能不再是 V4、V5、V6 这种编号,而是谁先做出真正可持续工作的 AI 系统。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/243943.html