
Mysql的执行计划
有的sql语句执行效率高,有的执行效率低,所以需要对sql语句做调整和优化,就会涉及到执行计划
执行计划具体来说就是一条sql语句的执行过程,我们只能看到执行过程中用到了哪些关键的信息,并根据这些信息做判断
面试官问到你做过哪些mysql的优化调整?大部分人会说添加索引,优化索引,那怎么判断一条sql语句有没有使用索引呢,这时候就需要通过执行计划进行显示了,执行计划说白了就是需要在sql语句前面加上关键字explain,在sql语句前面加上explain之后,它会输出n多个列
举例
这是表testnd5的数据
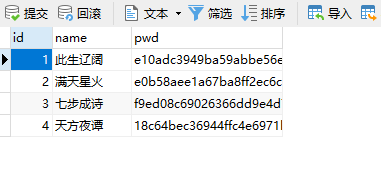
讯享网
explain SELECT * FROM `testnd5` 讯享网

这么多列,我应该看那些最关键的信息?
id:当sql语句非常复杂的时候,会有一个id序号的排列,根据序号的排列能显示出来哪个子查询或者子句优先执行,哪个字句后执行,仅此而已,有时候需要看,有时候不需要看,它不是一个关键信息
select_type:查询的类型,一般没什么用
table:sql语句执行的表的名称
type:很重要,表示查询对应的类型,mysql默认的是ALL,他有system/const/ref/range/index/all这几种,从前往后,效率依次降低,即system的效率是最高的,all要进行全表扫描,所以效率低,所以我们最少要保证type在range这个级别(通过加索引、调整当前子句…),达到ref更好但是某些情况是没法优化的,优化知识为了在一定程度上解决我们的问题,并不是一定有解。可以优化但并不是优化完一定有效果
官方文档地址
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain_type

有些同学写的sql语句非常简单,sql语句越简单,优化的程度就越低,
possible_keys:可能用到的索引,把可能用到的索引都给你列出来,意义不大
key:很重要,他表示你当前的sql语句中到底有没有用到索引,这个值尽量不要为空,

rows:过滤的行数,只是预估值,不是精确值
Extra比较重要,表示额外的信息

当出现的是using index:表示使用了索引覆盖
using index condition表示使用了索引下推
using filesort表示使用了临时空间进行排序,没有使用索引进行排序
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-extra-information
这些关键信息都可以帮助我们判断当前sql语句的执行效率
索引被问到过的相关技术点
让你来设计一套索引系统,你会怎么设计
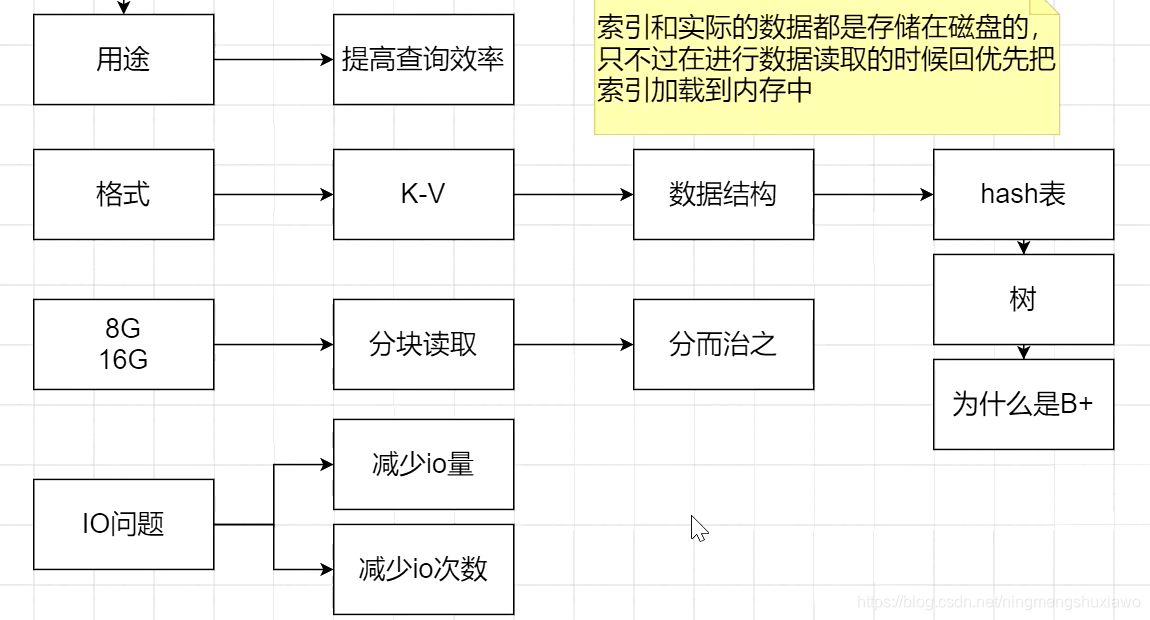
1:应该存哪些信息
2:索引和数据分别存储在什么地方
对于InnoDB:索引和实际的数据都是存储在磁盘上的,只不过在进行数据读取的时候会优先把索引加载到内存中
存储引擎:不同的数据文件在磁盘的不同组织形式
MyIsam存储引擎:.frm表结构 .MYD数据文件 .MYI索引

InnoDb存储引擎 .frm表结构 。ibd 索引文件+数据文件

3:索引存储什么格式的数据?
K-V格式,类似于查字典,根据页数定位要查找的内容
4:选择合理的数据结构进行存储
为什么是B+数(为什么不是B树或者hash表)
当你的表非常大的时候,索引会不会一起变大?
因为你往表里存数据的时候,是没法判断这个表能够存多少数据的,表中数据量在增大的时候,索引也在增大
索引在变大的过程中,没办法直接加载到内存怎么办?
可能你的电脑内存只有8G,但是mysql数据的索引达到了16G,则可以分块读取,1G 1G地读,分而治之。
我们要尽可能多地提高IO效率
1:减少IO量
2:减少IO次数
操作系统基础知识
1:局部性原理
时间局部性:之前被访问过的数据很有可能再次被访问
空间局部性:数据和程序都有聚集成群的倾向
2:磁盘预读
内存跟磁盘再进行交互的时候有一个最小的逻辑单位,这个单位称之为页,或者datapage,一般是4kb或者8kb,由操作系统决定,我们在进行数据读取的时候,一般是读取页的整数倍,也就是4k,8k,16k,innodb存储引擎在进行数据架子啊的时候读取的是16kb的数据
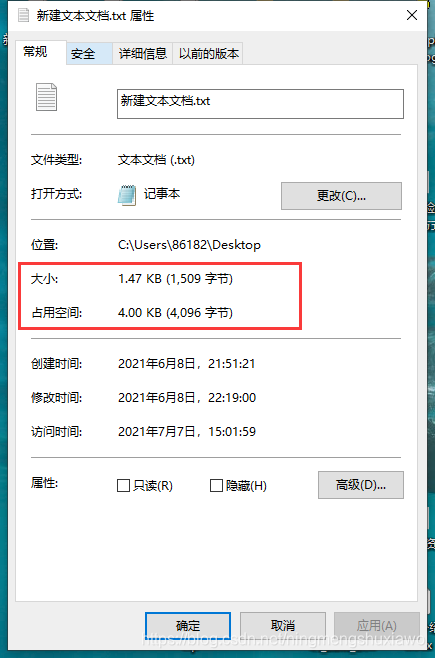
举例:如下图,我们可以看到,实际的文件大小是1.47kb,但是占用了4kb的大小(可以把磁盘看成一个一个的小格子,每一个格子都是4kb的大小,不管你有没有占满,都是4kb)
索引实现的数据结构为什么选择B+树?
hash表有什么问题?
hash表的结构,索引一样的时候添加链表
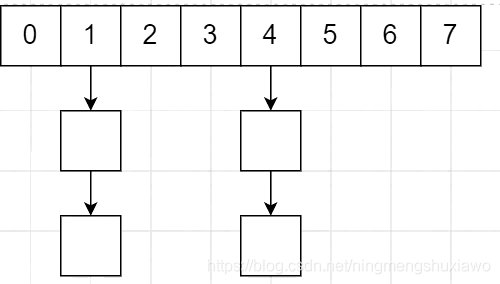
我们使用hash表的目的是是的数据足够散列(减少碰撞)
上图很明显不够散列,1,4都是链各个数据,而其他地方却没有数据
使用hash表的时候需要比较好的hash算法,如果算法不够哈的话,会导致hash碰撞,hash冲突,导致数据散列不均匀,造成存储空间浪费
使用hash表的时候数据是否是有序的?
是无序的,如果需要进行范围查找,,需要挨个遍历,效率比较低,这种情况下不适合用hasn索引。memory的存储引擎使用的就是hash索引,而innodb的存储引擎支持自适应hash。
InnoDB关键特性之自适应hash索引
自适应hash:正常情况下。innodb的索引使用的是B+树这种结构,但是mysql的server会判断是使用hash索引还是B+树(这个过程是无法人为干预的)
树有哪些?
二叉树 二叉排序树 二叉平衡树 红黑树
这些树的共同点:每一个分支有且只有2个节点
这些数的弊端:当需要向这些树中插入更多的数据的时候,会导致当前树变得非常高(每一个分支最最多两个节点,节点多了,只能加深层数撒),数变深了会加大IO次数(每一层都相当于一次IO)影响查询效率
解决方法,能不能把节点变成多个分支?
你比如这个节点可以有多少个分支?
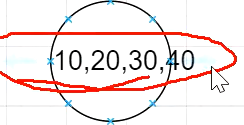
5个啊 小于10 10-20 20-30 30-40 大于40
于是B树应运而生
B树
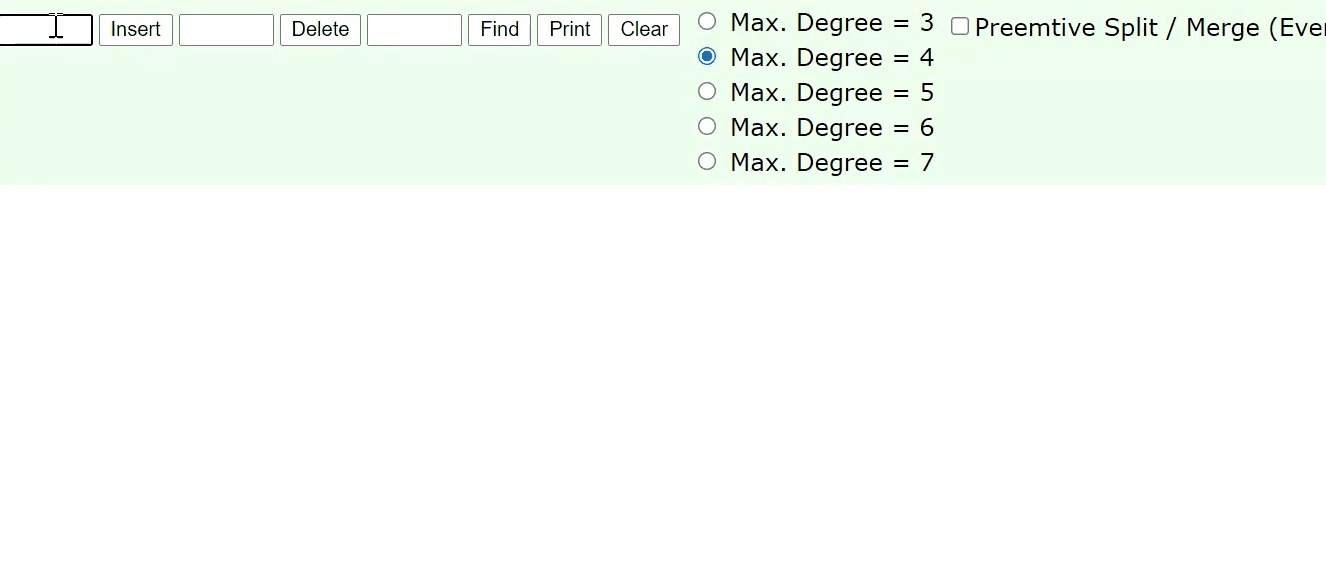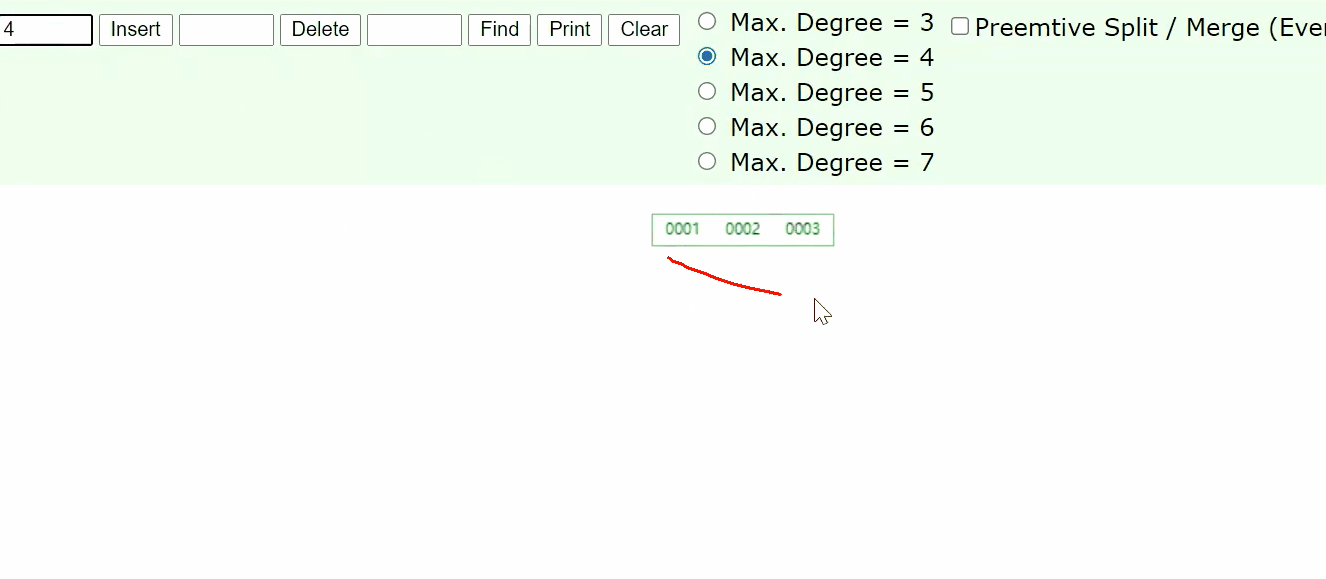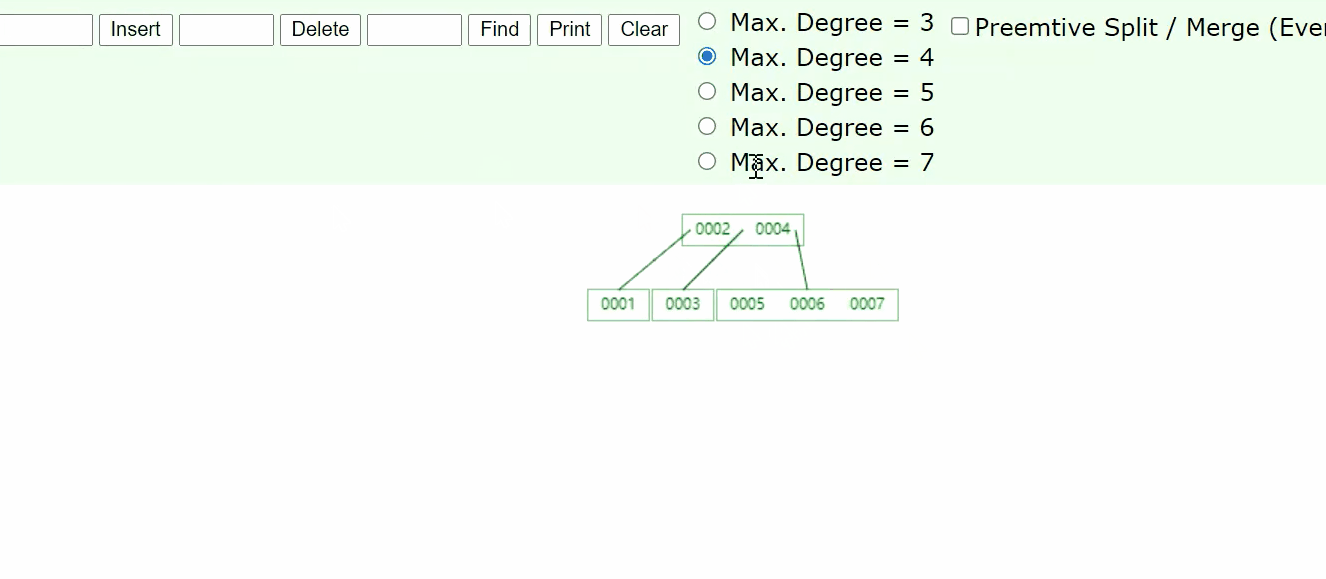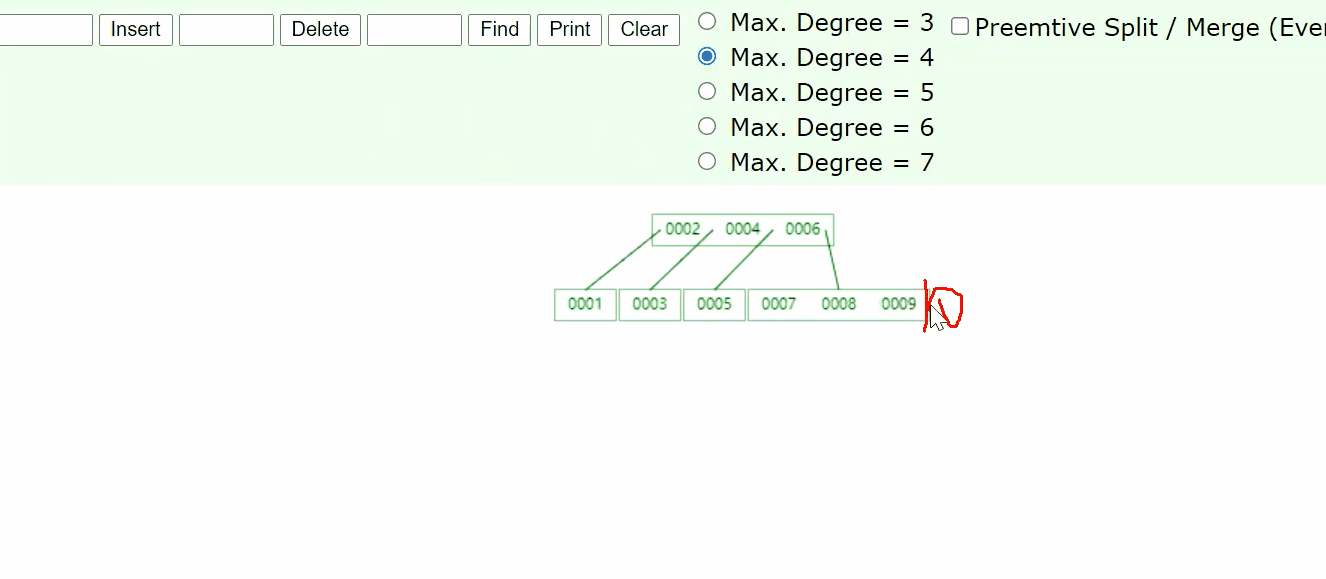

如果我们想用这样的结构来存储表中的数据,最终每一个节点应该放什么样的数据?或者说每一个节点应该放几个类型的数据?
id,以及整行的数据,以及指向下一层的指针
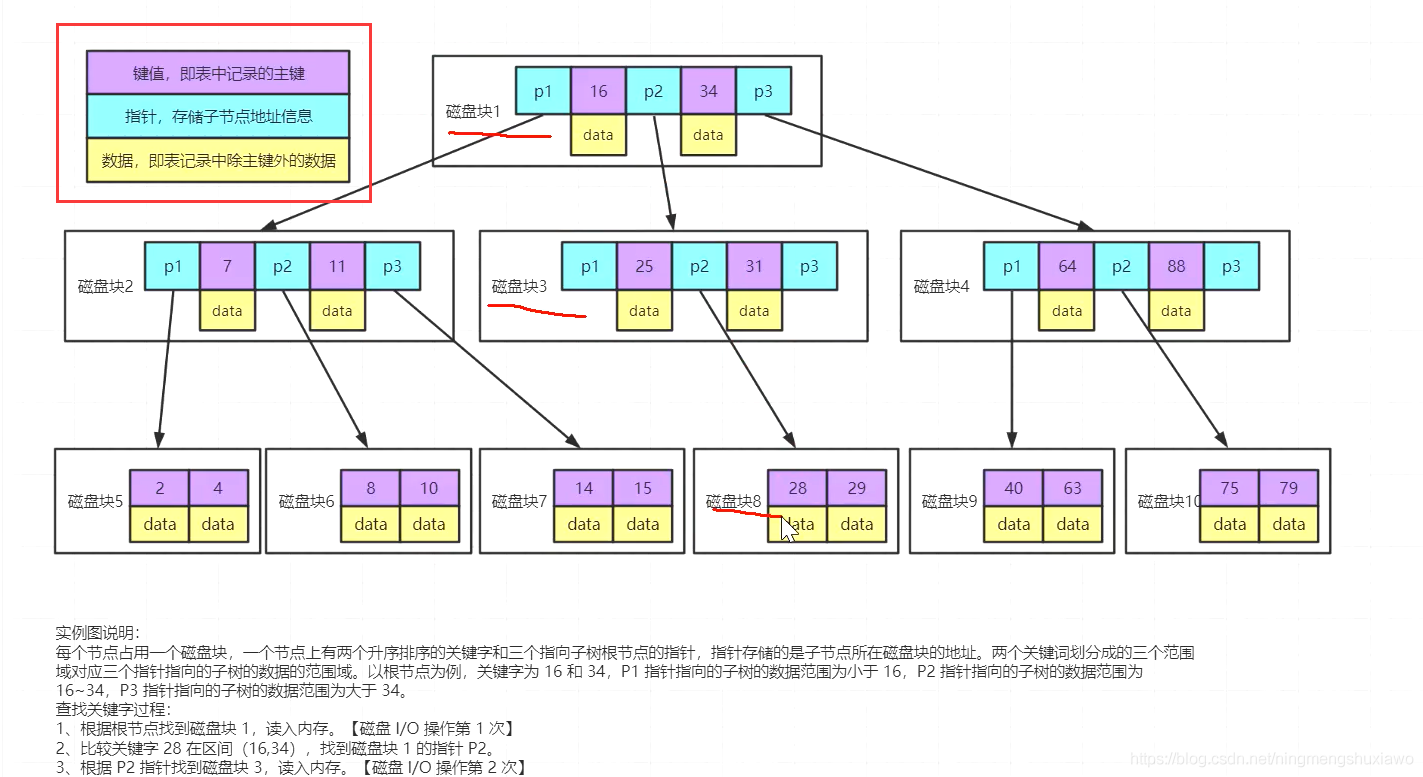
问题:上面的图中找id为28的数据需要读取多少数据?
答:48kb,因为innodb存储引擎每一次读取16kb,而查找到28需要读3个磁盘块,所以是48kb
3层B树存满了可以存多少条记录?
假设1个data是1kb,那么一个磁盘块最多可以存15条记录(指针,key值也要站空间),为了方便计算,就假设一个磁盘块可以存6条记录
3层存满,最多可以存的记录数为 16 * 16 *16 =4096条,但实际情况肯定存不了这么多的
那我们想增加存的数据的数量怎么办,增加数的高度?树越高,会导致IO次数变多,从而使效率变低
思考:为什么我能存储的空间比较小,谁占用了大量的存储空间
能不能不存data?,所以就有了B+树
B+树
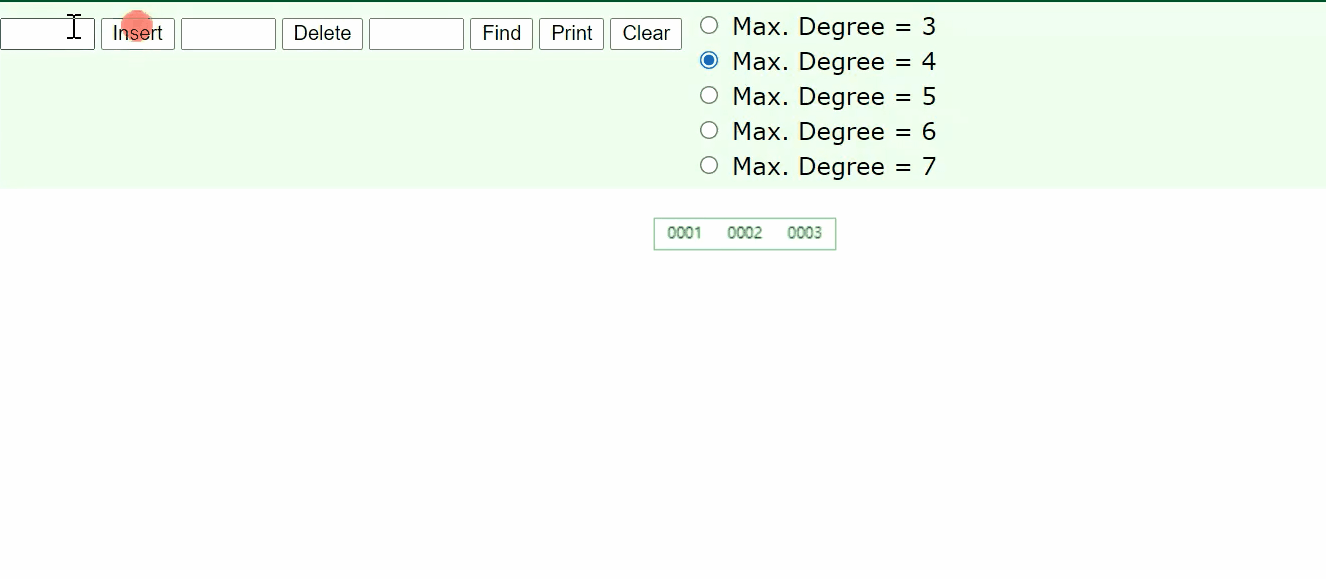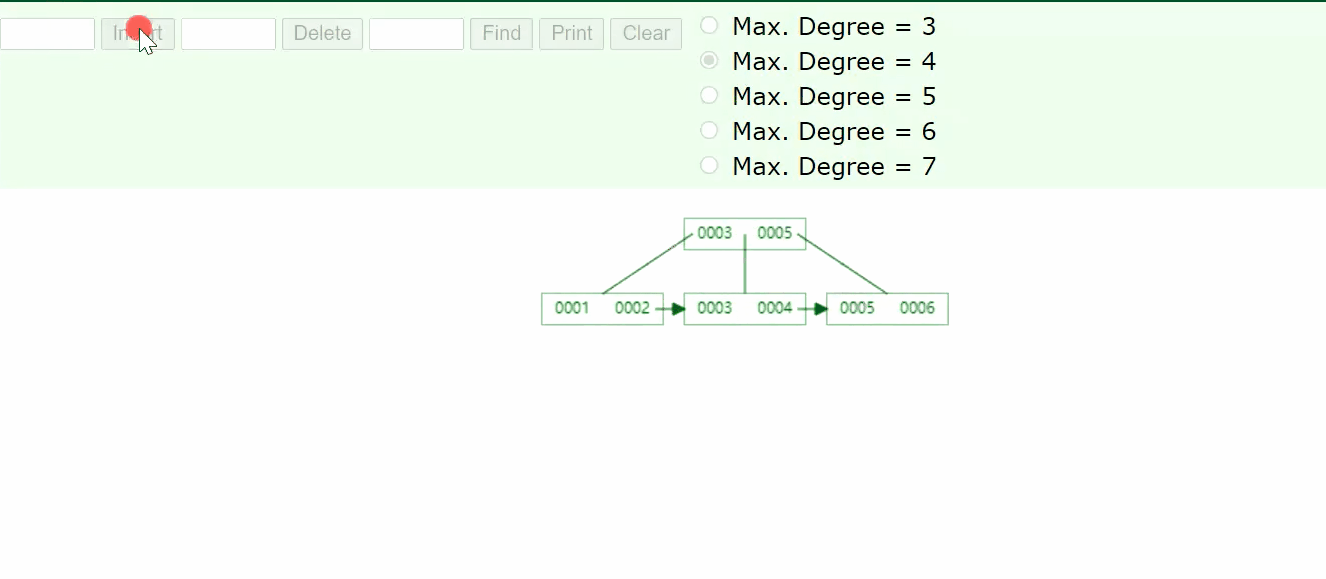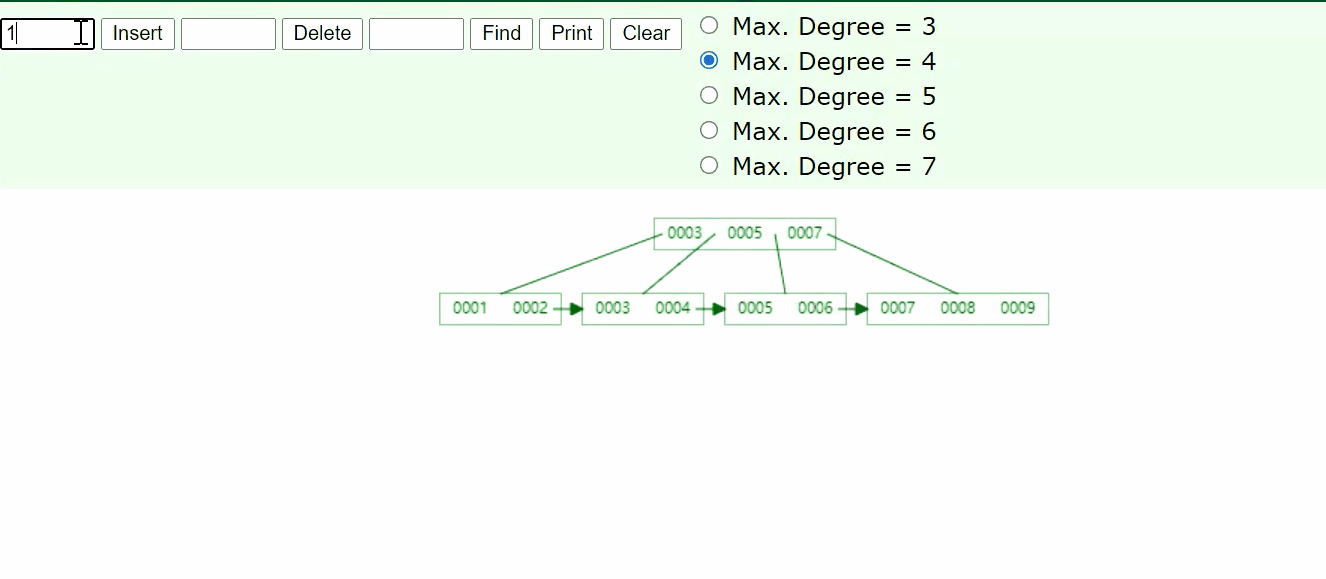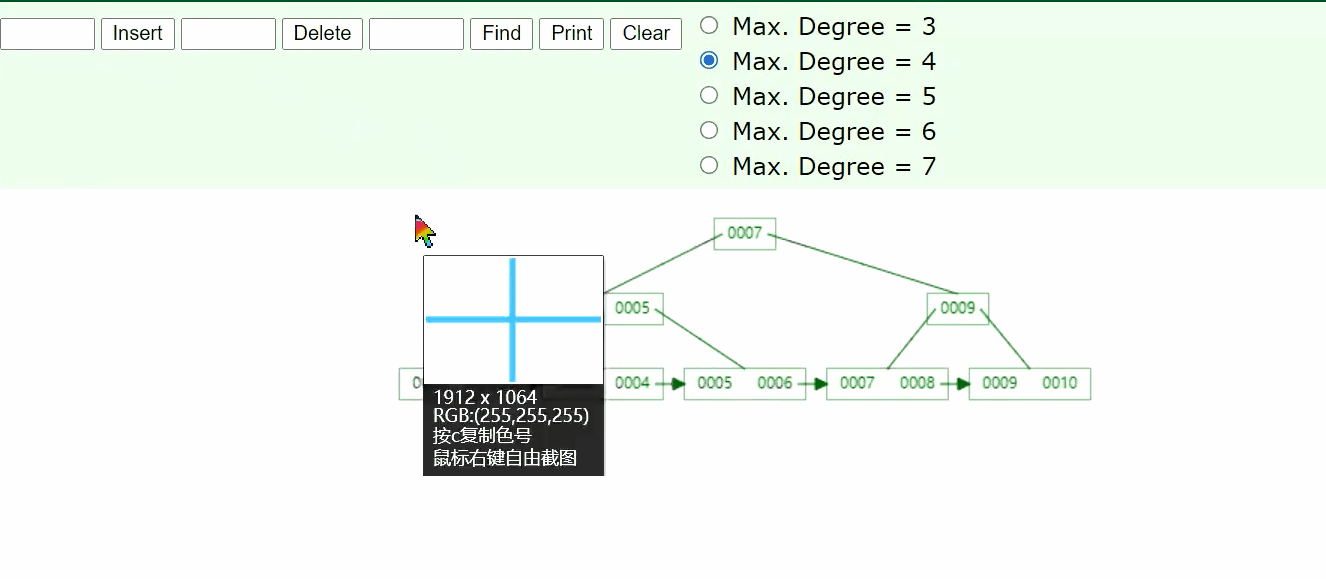
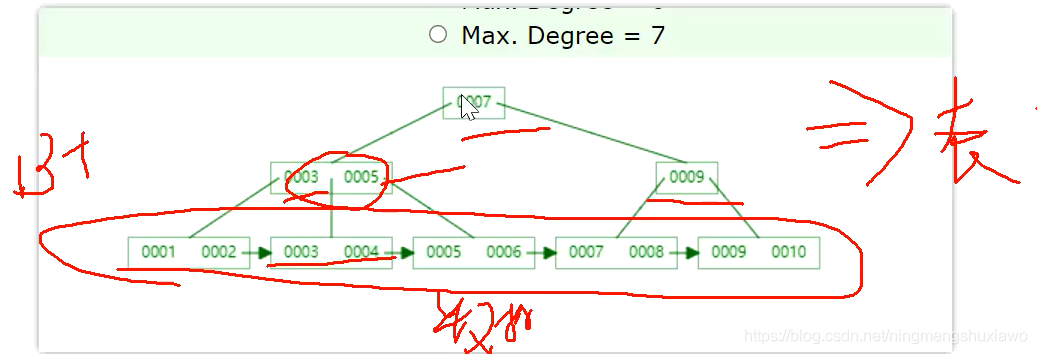
可以看到B+树有横向的箭头,同时,B+树中有重复的元素
把B+树类比到表结构,让所有的数据只存储在叶子结点上面,非叶子结点不存储数据
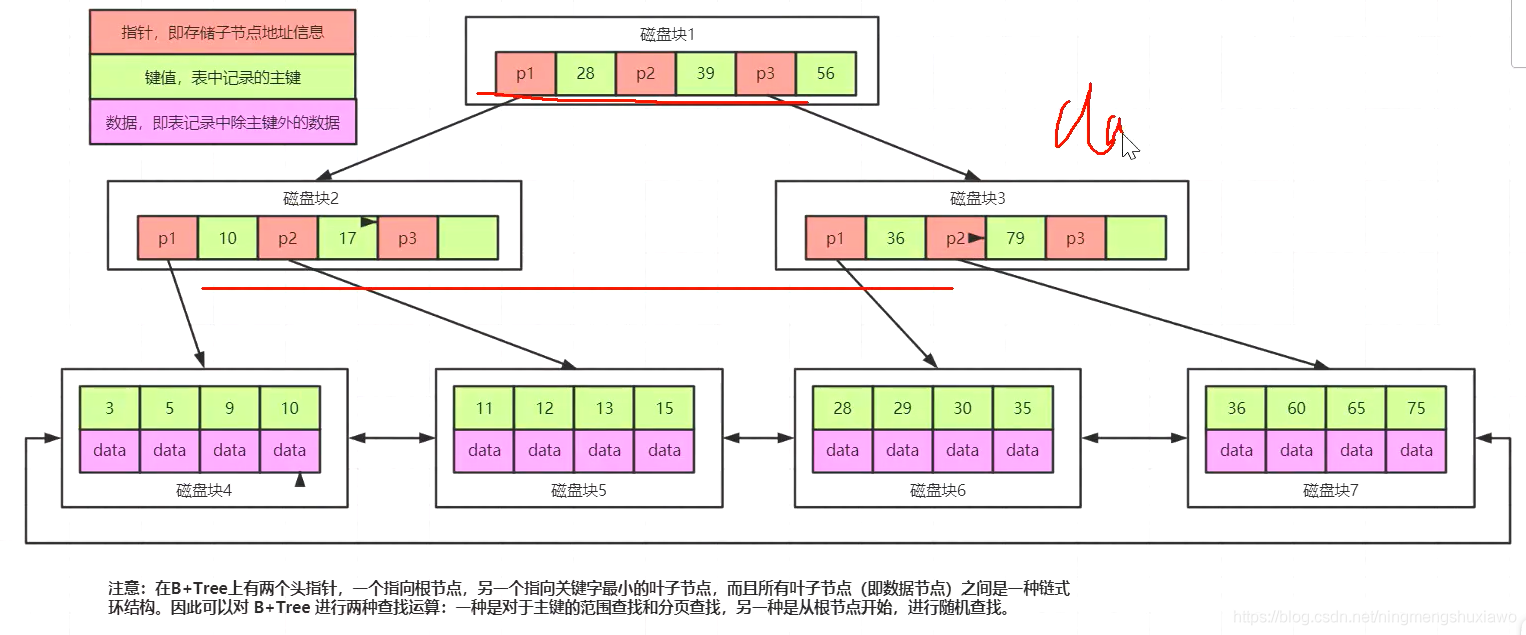
B+Tree是在BTree的基础之上做的—种优化,变化如下:
1、B+Tree每个节点可以包含更多的节点,这个做的原因有两个,第一个原因是为了降低树的高度,第二个原因是将数据范围变为多个区间,区间越多,数据检索越快
2、非叶子节点存储key,叶子节点存储key和数据
3、叶子节点两两指针相互连接(符合磁盘的预读特性),顺序查询性能更高
注意;在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。

怎么计算B+树支持存储的数据量?
假设

4千万的存储量够了吧,在公司里面,千万级的数据量就需要涉及分库分表了
mysql的B+树一般是多少层?
答:一般情况下3-4层的B+树足以支撑千万级的数据量存储
key是用int类型还是用varchar类型?
答:int占用4个字节,varchar占用的字节数根据你传入的参数而定 varchar(n),即小于4就用varchar,大于4就用int类型。我们要让key尽可能少地占用空间
前缀索引
取前缀索引的时候取前几个字符?怎么取?
取前3个字符
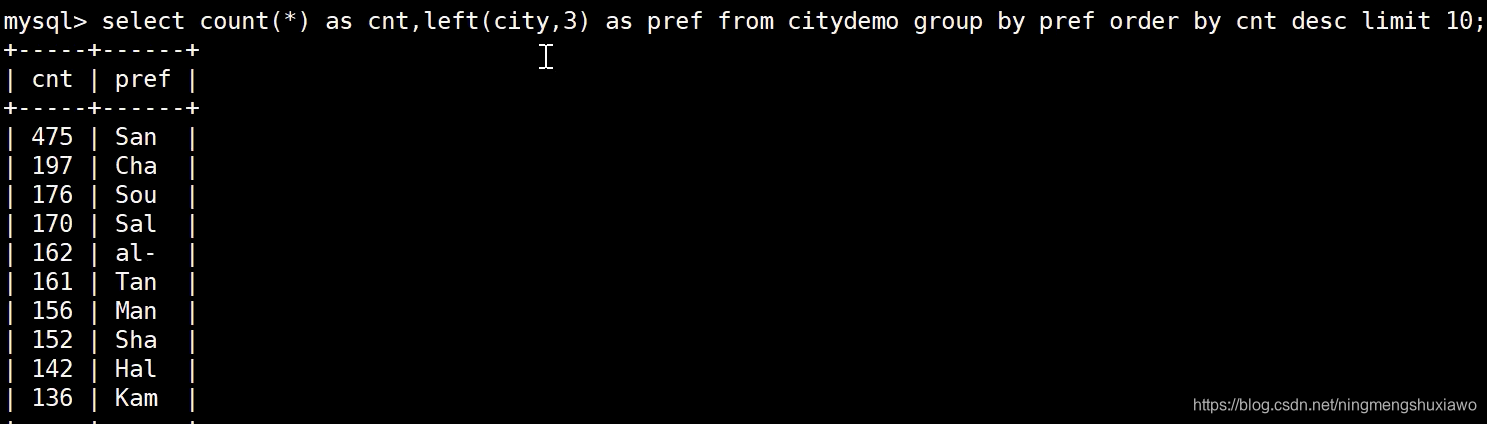
取前4个字符
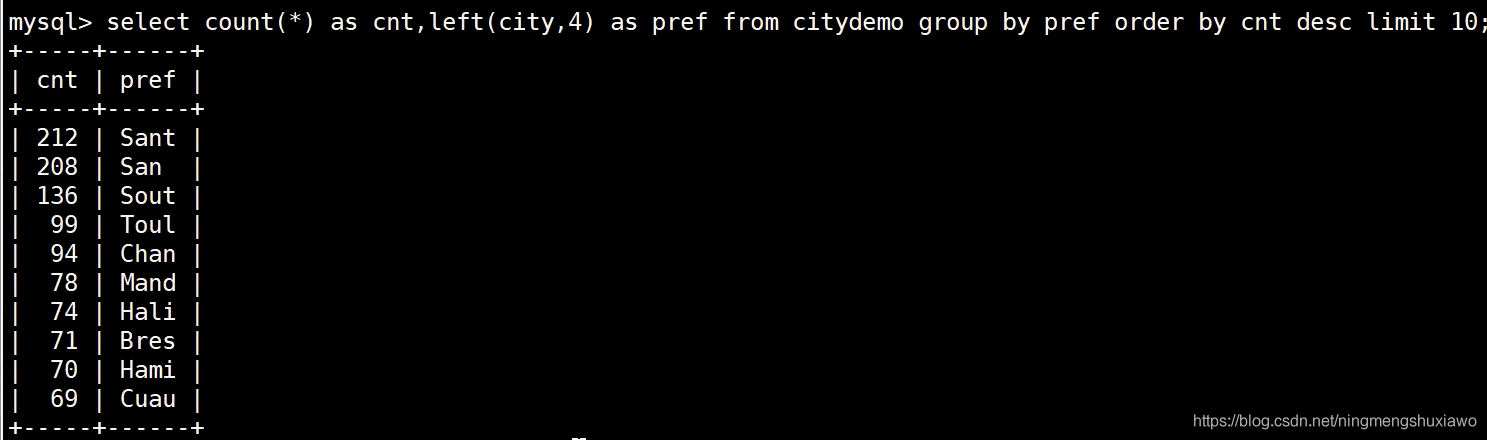
取前5个字符
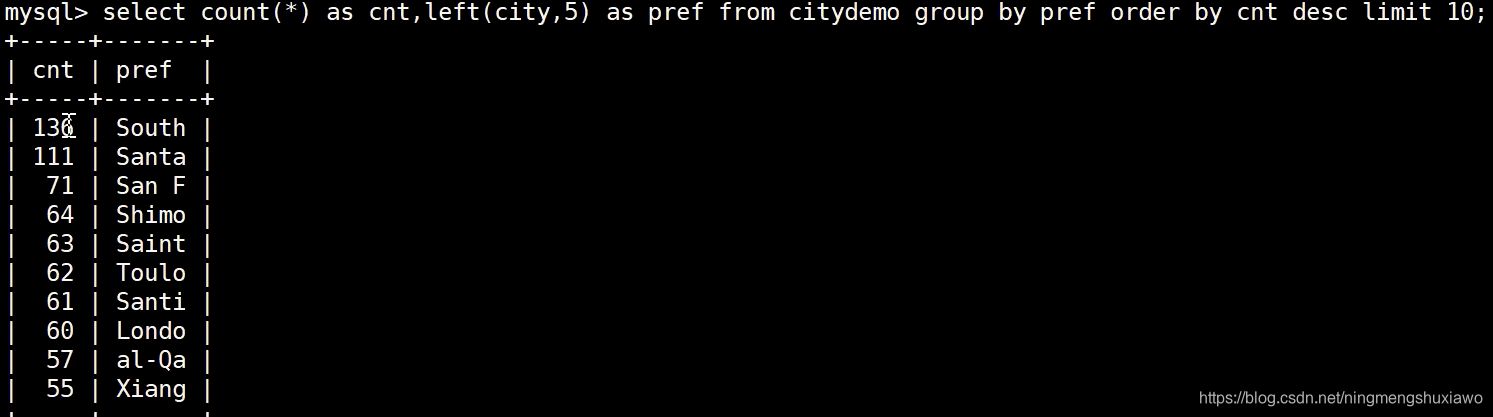
取前7个字符
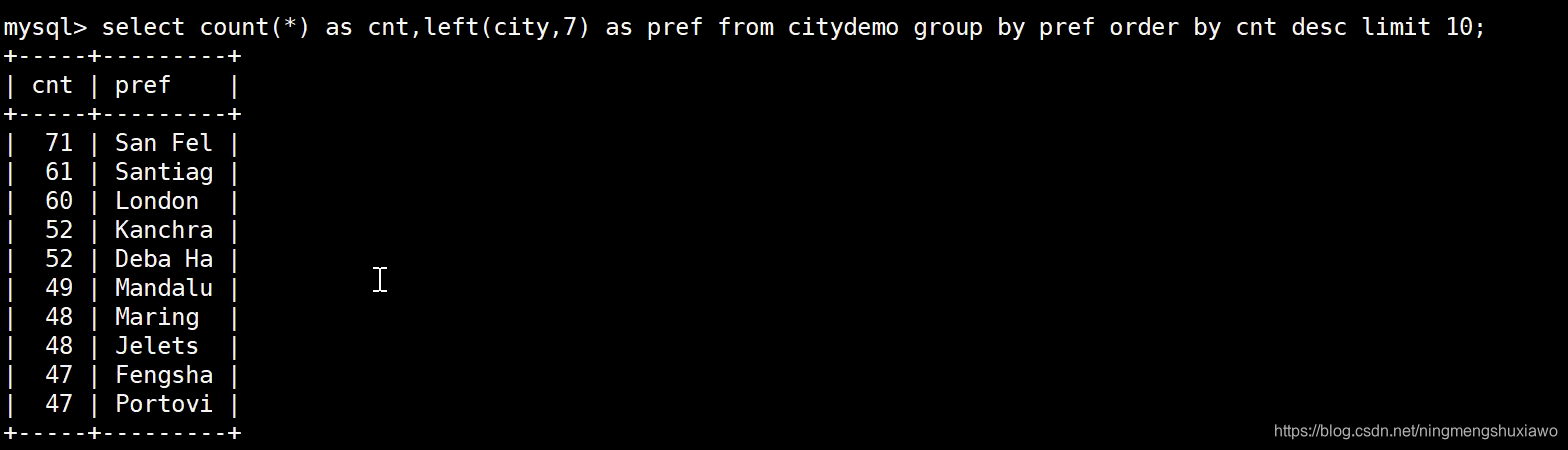
取前9个字符
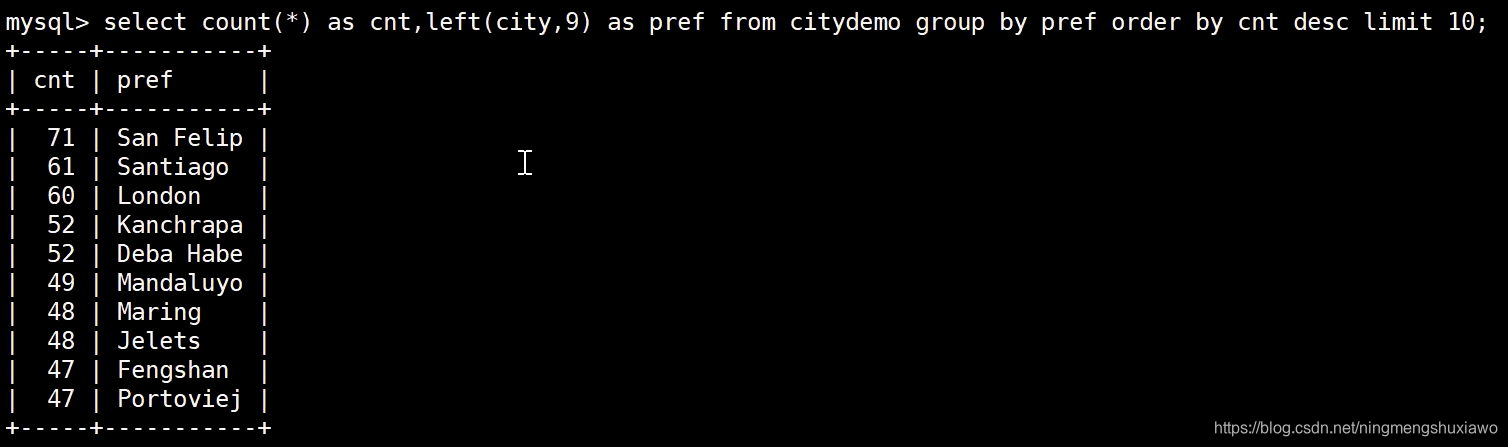
7 8 9 的时候已经没有什么变化了,说明7是临界值
那么创建索引的时候把索引的钱7个字符当作key可以吗?可以的,节省索引占用的存储空间


为什么选择B+树?
聚簇索引和非聚簇索引
数据必定是跟某一个索引绑定在一起的,绑定数据的索引叫做聚簇索引,其他索引的叶子结点中存储的数据不再是整行的记录,而是聚簇索引的Id值

结论:innodb中既有聚簇索引,也有非聚簇索引,MYiSAM中只有非聚簇索引
回表

讯享网select * from table where name='zhangsan '
上面这条sql的检索过程是什么样的?
先根据name的B+树匹配到对应的叶子结点,查询到对应行记录的id值,再根据id去id的B+树中检索整行记录,这个过程称之为回表
回表的效率是高还是低?
要尽量避免回表操作
索引覆盖

select id,name from table where name='zhangsan ' 上面这条sql的检索过程是什么样的?
根据name的值去name的B+树检索对应的记录,能获取到id的属性值,索引的叶子结点中包含了查询的所有列,此时不需要回表,这个额过程叫做索引覆盖,会有using index的提示,推荐使用。在某些场景中,可以考虑将要查询的所有列都变成组合索引 ,此时会使用索引覆盖(不会回表),加快查询效率。
最左匹配

索引下推
把原来在server层进行的条件过滤下推到存储引擎层,索引下推是默认开启的

在存储引擎直接匹配name和age可以减少返回给server层的数据量
如何回答优化问题
加索引 看执行计划 优化sql语句 分库分表 表结构设计

一些练习题
1 索引是对数据库表中一个或多个列的值进行排序的数据结构,以协助快速查询、更新数据库表中数据。以下对索引的特点描述错误的是:C
加快数据的检索速度
加速表和表之间的连接
在使用分组和排序子句进行数据检索时,并不会减少查询中分组和排序的时间
通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
索引的特点:
创建索引的好处
(1)通过创建索引,可以在查询的过程中,提高系统的性能
(2)通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性
(3)在使用分组和排序子句进行数据检索时,可以减少查询中分组和排序的时间
创建索引的坏处
(1)创建索引和维护索引要耗费时间,而且时间随着数据量的增加而增大
(2)索引需要占用物理空间,如果要建立聚簇索引,所需要的空间会更大
(3)在对表中的数据进行增加删除和修改时需要耗费较多的时间,因为索引也要动态地维护
2 下面关于索引的描述不正确的是(C)
索引是一个指向表中数据的指针
索引是在列上建立的一种数据库对象
索引的建立和撤消对表中的数据毫无影响
表被撤消时将同时撤消在其上建立的索引
3 关于索引下面哪些描述是正确的:( BEF )
索引是为了提高查询效率的,通过建立索引查询效率会得到提高
索引对数据插入的效率有一定的影响
唯一索引是一种特殊的索引,表中的行的物理顺序与索引顺序一致,且不允许两行数据在索引列上有相同的值
每个表都必须具有一个主键索引
对于数据重复度高,值范围有限的列如果建索引建议使用位图索引
可以在多个列上建立联合索引
4 select A,B from Table1 where A between 60 and 100 order by B,下面哪些优化sql性能(CD)。
字段A 建立hash索引,字段B btree索引
字段A 建立hash索引,字段B不建立索引
字段A 建立btree索引,字段B不建立索引
字段A 不建立 索引,字段B建立btree索引
hash索引适合单值查询,btree索引既适合单值查询又适合范围查询

5 哪些字段适合建立索引?BCD
在select子句中的字段
外键字段
主键字段
在where子句中的字段

6 关于数据库索引,以下说法错误的是?ABC
针对某些字段建立索引,能够有效的减少相关数据库表的磁盘空间占用;
针对某些字段建立索引,能够有效的提升相关字段的读与写的效率;
常见数据库管理系统,通常使用hash表来存储索引;
数据库索引的存在,可能导致相关字段删除的效率降低;
A.索引需要额外的磁盘空间,为一索引页,包含着索引记录,每条索引记录包含键值和逻辑指针。
B. 不会提升写效率
C.B+树
D.正确,删除相关字段需要动态维护索引,故效率降低。
7 下面关于数据库唯一索引正确的是(ABC )?
表可以包含多个唯一约束,但只能有一个主键
唯一约束列可以包含null值
唯一约束列可修改和更新
唯一约束不能用来定义外键


8 为了提高数据的查询效率,需要在数据库中建立索引,则下列设计索引的原则描述正确的是(AB)
在频繁进行排序或分组(即进行group by 或order by操作)的列上建立索引
考虑列中值的分布,列的基数越大,索引的效果越好
在select关键字后选择列表的列上,建立索引
在表中,索引越多越好
http://blog.itpub.net//viewspace-/

9 如果对一个表创建索引,下列索引的设计不正确的是(B)
一个聚集索引
多个聚集索引
一个非聚集索引
多个非聚集索引
10 关于索引(index)的说法哪些是错误? A
创建索引能提高数据插入的性能
索引应该根据具体的检索需求来创建,在选择性好的列上创建索引
索引并非越多越好
建立索引可使检索操作更迅速
数据库的索引,在查找的时候,可以快速的找到位置。对于数据库的插入,一般都是插入在最后的一行,索引不能提高插入的性能。
建立索引是加快查询速度的有效手段,能快速定位到需要查询的内容。
索引虽然能够加快数据库查询,但需要占用一定的存储空间,当基本表更新时,索引要进行相应的维护,这些都会增加数据库的负担,因此要根据实际应用的需要有选择地创建索引。
索引是关系数据库管理系统的内部实现技术,属于内模式的范畴。
11 如果系统现在需要在一个很大的表上创建一个索引,你会考虑那些因素,如何做以尽量减小对应用的影响? ABC
增大sort_area_size(8i)/pga_aggregate_target(Arrayi)值
如果表有分区(一般大表都要用到分区的),按分区逐个建索引,如果是本地索引的话
系统空闲的时候建。
把日志文件放到另一个地方
12 有关聚集索引的描述,说法正确的是?
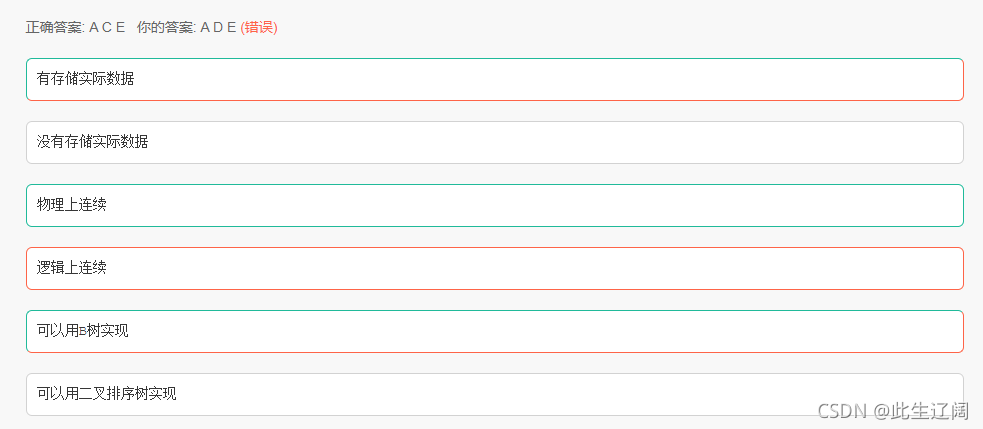
13 关于索引下面哪些描述是正确的:( )

参考视频
300分钟,我把MySQL索引、锁、事务、MVCC、分库分表全部总结出来了
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/24393.html