
当 AI 能写出 100 万行代码,真正的挑战不是让它写得更好——而是怎么驾驭它。
Harness Engineering 是一套围绕 AI Agent 构建的约束、反馈与控制系统,让 Agent 在人类设定的边界内自主、可靠、可持续地工作——它不优化模型本身,而是优化模型运行的“环境”。
你可以把它理解成:Prompt Engineering 教你怎么“跟 AI 说话”,Context Engineering 教你怎么“给 AI 喂信息”,而 Harness Engineering 教你怎么“给 AI 造一条高速公路,配上护栏、限速牌和加油站”。
2026 年 2 月 11 日,OpenAI 工程师 Ryan Lopopolo 发了一篇博文,标题翻译过来是“在智能体优先的世界中利用 Codex 进行工程实践”。文章披露了一个持续 5 个月的内部实验——3 名工程师不写一行代码,纯靠 Codex Agent 生成了约 100 万行代码,交付了一款真实产品的内测版。
这篇文章像一颗石子扔进水面,后续的涟漪是这样的:
这篇解读综合了上述六篇核心文献,试图把散落在不同文章里的碎片拼成一张完整的图。
回答这个问题之前,先看一个 AI Agent 最常见的“翻车”场景。
Anthropic 的工程师 Justin Young 观察到一个规律:给 Claude 一个复杂的全栈项目,它第一反应是试图在一个会话里把所有功能都做完。结果呢?做到一半上下文窗口耗尽,留下一堆半成品——有些功能写了一半没测试,有些模块之间的接口对不上,而且这些烂摊子全都没有记录。下一个 Agent 会话接手的时候,它以为项目才刚开始,或者更糟——以为项目已经做完了。
这不是 Claude 独有的问题。Cassie Kozyrkov 用了一个狠毒但精准的比喻:
AI 就像一个极其听话但缺乏背景知识的实习生。它倾向于填补你指令中的空白,进行“自信的即兴发挥”,编写你并未要求的功能。如果你不审计它的假设,就会积累“信任债务”。
“信任债务”这个词造得好。它指的是——AI 做了一堆你没要求的决定,这些决定目前看起来没问题,但在未来某个时刻会爆炸,届时你得花大价钱去逆向工程那些你从未意识到的假设。
问题的根源在于:我们从“人写代码”进入了“AI 写代码”的时代,但配套的工程体系还停留在“人写代码”的范式里。 Harness Engineering 就是为了填补这个空白而生的。
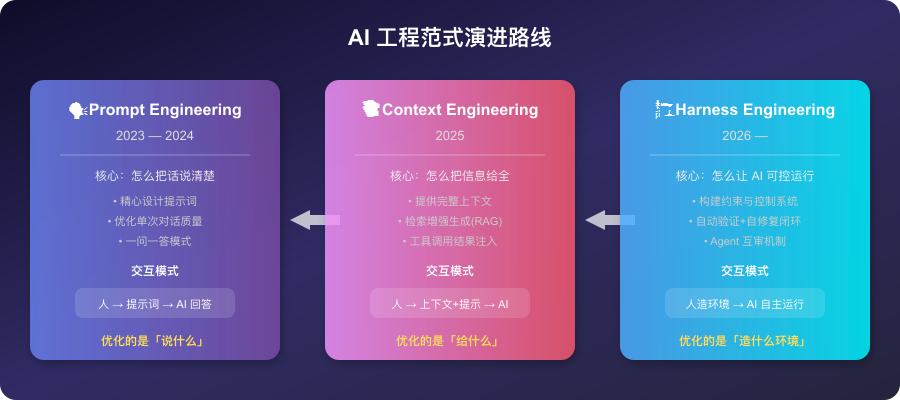
图1:AI工程三代范式的核心差异——优化对象从“输入”逐步转向“运行环境”
上面这张图浓缩了过去三年 AI 工程的演进脉络。拆开说:
Prompt Engineering(2023-2024) 的核心焦虑是“怎么把话说清楚”。你花大量时间调试提示词的措辞、格式、few-shot 示例,希望 AI 一次性给出好答案。这个阶段解决的是单次对话的质量问题。交互模式是“一问一答”,人和 AI 之间的关系像“出题者和答题者”。
Context Engineering(2025) 发现光靠 Prompt 不够——AI 需要看到相关文档、代码片段、历史对话、工具调用结果才能给出好答案。Shopify CEO Tobi Lutke 把这个概念推到了风口浪尖。这个阶段解决的是信息输入的质量问题。但本质上,交互模式没变——还是“你给信息,AI 生成内容”。
Harness Engineering(2026-) 的跃迁是质的变化。你不再优化“跟 AI 怎么说话”或“给 AI 什么信息”,而是构建一整套系统来约束、引导和验证 AI Agent 的自主行为。交互模式从“人给输入,AI 给输出”变成了“人造环境,AI 在里面跑”。
打个比方:Prompt Engineering 像教一匹马“左转”“右转”的口令;Context Engineering 像给马一张地图让它自己看路;Harness Engineering 像给马装上缰绳、马鞍和护栏——它可以自己跑,但跑不出你划定的范围。
OpenAI 的实验规则只有一条:用 Codex 构建并交付一款真实产品的内测版,不允许手写任何一行代码。
5 个月后的数据:
数字够震撼。但更有意思的问题是:工程师不写代码之后,80% 的时间花在了什么上?
答案不是写 Prompt,也不是审代码。是构建 Harness——那套让 AI 能够自主、可靠、可持续工作的基础设施。
Ryan Lopopolo 把这个过程的理念浓缩成八个字:人类掌舵,智能体执行。
当 Agent 遇到困难时,工程师不会想“我该怎么帮它写完这段代码”,而是追问“Agent 缺乏什么能力?需要什么工具、什么抽象层、什么结构?”然后由人类补充这些基础设施。工程师的角色从“代码的编写者”变成了“环境的建筑师”。
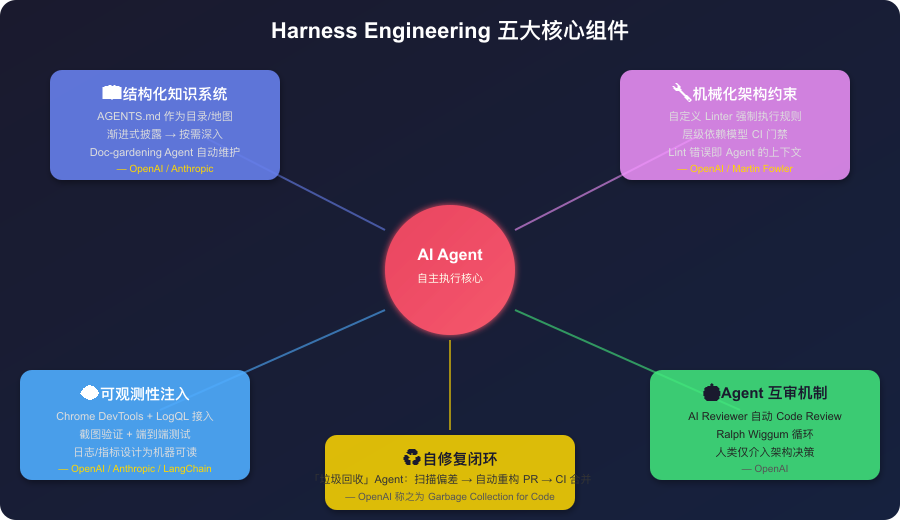
图2:五大核心组件环绕 AI Agent 运行——每个组件来自不同公司的实战提炼
综合 OpenAI、Anthropic、LangChain 和 Martin Fowler 网站四方的实践,Harness 的核心组件可以归纳为五层。下面逐个拆解。
📖 组件一:结构化知识系统
AI Agent 要在百万行代码库里干活,它得知道整体架构、各模块职责、API 约定、设计决策的背景。怎么给?
最天真的做法是写一个巨大的 ,把所有信息塞进去。
OpenAI 踩过这个坑,发现行不通。两个原因:第一,上下文窗口是稀缺资源,全塞进去关键信息反而被淹没;第二,大而全的文档腐烂得最快——代码改了文档没跟上,过时信息比没有信息更危险。
正确做法是渐进式披露——把 当地图,不当百科全书:
GPT plus 代充 只需 145
Agent 从地图出发,根据当前任务按需深入。就像去一个陌生城市——不是把整个城市的历史读一遍,而是先看地图搞清楚方向,走到具体地方再看详细介绍。
更关键的一步:OpenAI 建了一个 “doc-gardening Agent”——后台运行的 AI,唯一工作就是扫描文档和代码之间的不一致,自动提交 PR 修复过时文档。Martin Fowler 网站的文章把这类 Agent 叫“垃圾回收 Agent”——不做新功能只做清理,但没有它,整个系统的信息质量会不可逆地腐烂。
🔧 组件二:机械化架构约束
这是整个 Harness 中最反直觉但最有效的部分。
传统开发中,架构规范靠人维护——资深工程师在 Code Review 时指出“这个模块不应该直接调用那个模块”。但 Agent 一天几百个 PR 的吞吐量下,人工审查成了瓶颈。
OpenAI 的解法:把所有架构规则变成自定义 Linter,机械化强制执行。
他们的层级依赖模型:
每个业务域按这个层级组织,下层不能反向依赖上层。这条规则不是写在文档里靠人记的,是写成 Linter 规则——任何违反的代码都过不了 CI,无论人写的还是 AI 写的。
Linter 错误信息本身也是上下文工程的一部分。OpenAI 把自定义 Lint 错误写得很详细,不只说“你违反了规则 X”,而是解释“为什么这个规则存在、正确的做法是什么”。这样 Agent 遇到 Lint 错误时能自己理解为什么错了并自我修正,不需要人类介入。
Birgitta Böckeler 在 Martin Fowler 网站上写了一个精妙的总结:
为了获得更高的 AI 自主性,运行时必须受到更严格的约束。增加信任需要的不是更多自由,而是更多限制。
翻译成大白话:你越想让 AI 自由干活,就越要把规矩定死。 就像高速公路上的护栏——正是因为有护栏,你才敢踩到 120 码。
👁️ 组件三:可观测性注入
AI 写完代码,怎么知道对不对?
最原始做法是跑测试。但测试只覆盖你预想到的场景。OpenAI 的做法激进得多:让 Codex 直接接入应用的运行时环境。
具体操作:
- 通过 git worktree 启动独立应用实例
- 接入 Chrome DevTools Protocol,Agent 能像人一样在浏览器里操作应用、看到 UI 实际渲染
- 直接用 LogQL 和 PromQL 查询日志和监控指标
- Agent 可执行“确保服务启动在 800ms 内完成”这样的具体可量化验证任务
Anthropic 走了类似路线但更强调截图验证——要求 Agent 用 Puppeteer 像真实用户一样操作应用然后截图对比预期。他们发现这招“显著提高了性能,使 Agent 能够识别并修复仅从代码中看不出的 Bug”。
这里有个深刻的认知转变:传统软件工程中,观测是给人看的(仪表盘、报警);Harness Engineering 中,观测是给 AI 看的。 日志、指标、UI 状态都要设计成“机器可读”的格式。
♻️ 组件四:自修复闭环
任何大型代码库都有个天敌:熵增。代码越多,模式越分裂,技术债务越堆积。
Agent 大量生成代码时这个问题放大十倍。AI 会复现代码库中已有的坏模式——如果某处有一段写得烂的代码,Agent 在相邻模块工作时可能模仿这种写法,导致坏模式扩散。
OpenAI 的解法是把清理也变成自动化 Agent 任务:
- 后台定期运行“清洁 Agent”
- 扫描代码库中偏离“黄金标准”的地方
- 自动提交重构 PR
- CI 验证通过后自动合并
这就是代码库的“垃圾回收机制”——不等技术债务堆到崩溃才还,而是小额、高频、持续地偿还。前面提到的 doc-gardening Agent 也是自修复闭环的一部分——代码变了,文档自动跟着变。
🤖 组件五:Agent 互审机制
传统流程里每个 PR 需要人审。但系统一天几百个 PR 时,人工审查是严重瓶颈。
OpenAI 引入了 AI Reviewer——专门负责 Code Review 的 Agent。Agent A 写代码,Agent B 审代码,有问题 Agent A 改完再提交,直到 Agent B 通过。内部叫这个 “Ralph Wiggum 循环”。
人类的角色缩减到只介入架构层面的重大决策。 日常代码风格、逻辑正确性、测试覆盖这些,全部 Agent 互审。
如果上面这些听起来偏理论,LangChain 给了一个硬核的定量实验。
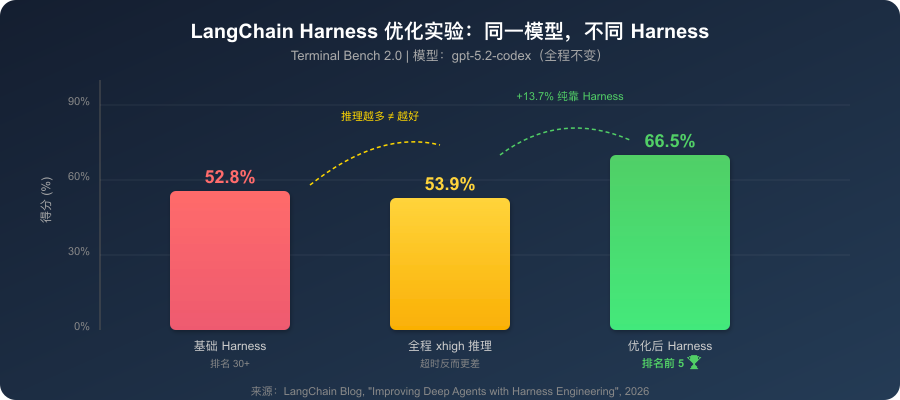
图3:同一模型(gpt-5.2-codex),三种配置下的 Terminal Bench 2.0 得分对比——Harness 优化带来 13.7% 的绝对提升
模型完全没变。从 30 名开外一跃进入前 5,纯靠 Harness 优化。
他们的 Trace Analyzer Skill 特别值得说。这套工具的工作流程类似机器学习中的 Boosting:
- 从 LangSmith 获取上一轮运行的追踪数据
- 并行启动多个错误分析 Agent,各自诊断失败原因
- 主 Agent 综合所有发现,提出 Harness 改进建议
- 对 Harness 做针对性修改,进入下一轮
也就是说,用 Agent 来优化 Agent 的 Harness——meta 层面的自动化。
四个关键改动值得展开说:
改动一:Plan-Build-Verify-Fix 流程。 Agent 有个通病——写完代码自我审查一遍就停了,不跑测试。LangChain 加了 ——Agent 宣告完成之前必须跑验证。不验证不让退出。
改动二:环境上下文注入。 Agent 最浪费时间的事之一是“搞清楚自己在哪”。 在启动时就把目录结构、可用工具、超时时间注入进去,省去了 Agent 自己摸索的时间和错误。
改动三:死循环检测。 Agent 容易陷入 “doom loop”——反复改同一个文件,每次都觉得“应该好了”,但根本问题没解决。 跟踪编辑次数,对同一文件编辑超过 N 次时自动注入提示:“你是不是该换个思路了?”
改动四:推理三明治策略。 不是“推理越多越好”。全程最高推理模式 xhigh 反而因超时只得 53.9%。他们在规划和验证阶段用 xhigh,中间执行阶段降档,平衡了质量和效率,最终得分 66.5%。
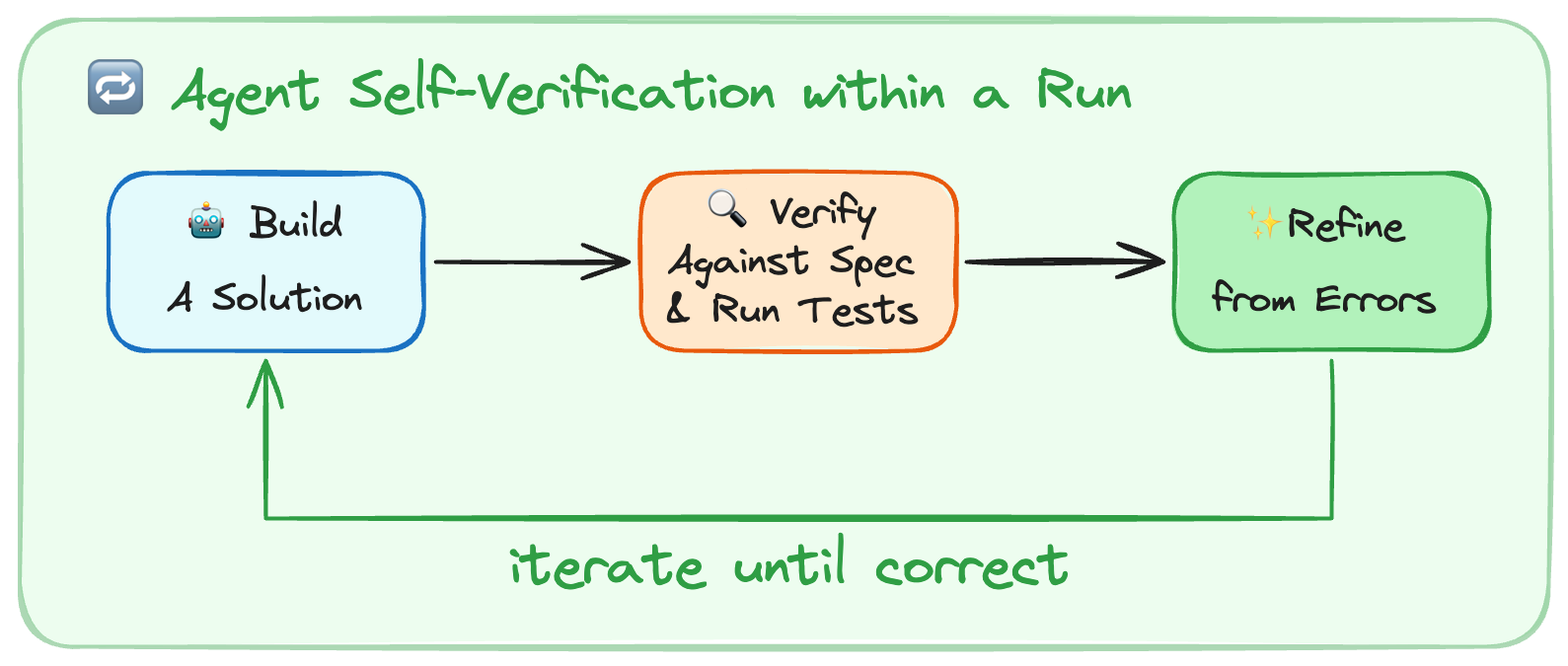
图4:LangChain 的 Plan-Build-Verify-Fix 自验证循环——强制 Agent 在提交前运行测试(来源:LangChain Blog)
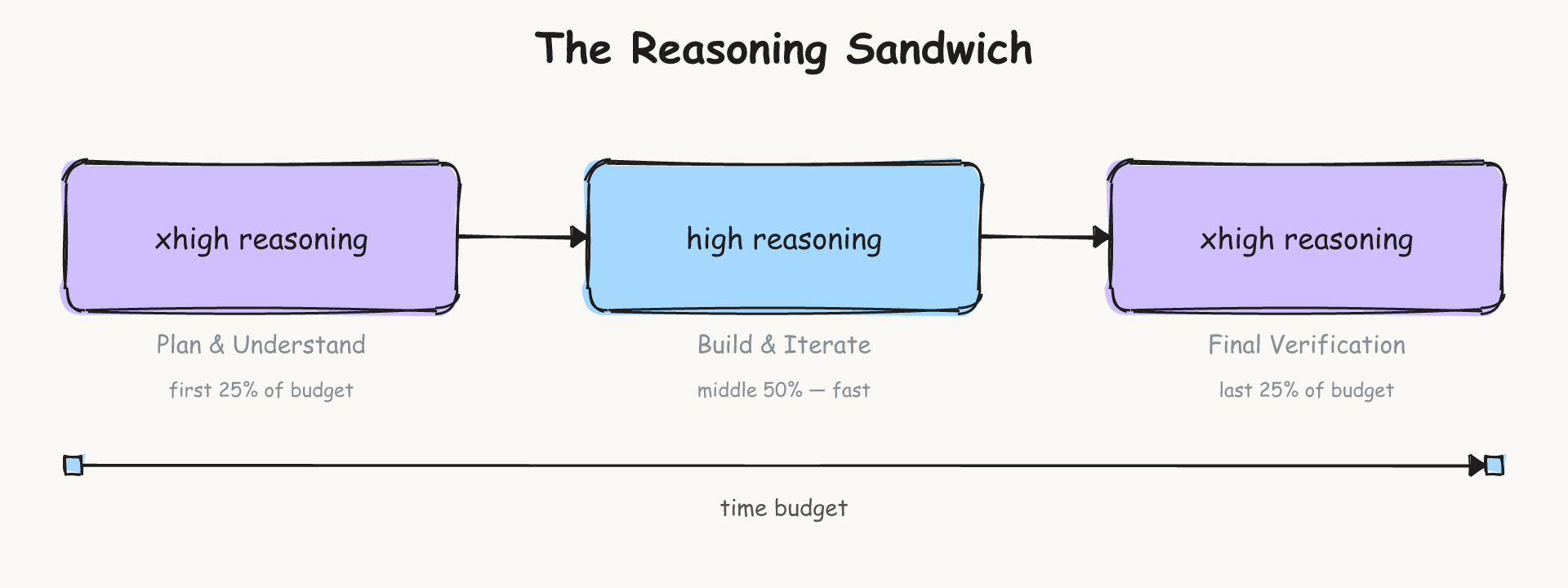
图5:推理资源的“三明治”分配策略——规划和验证阶段投入最多推理,执行阶段降档节省时间(来源:LangChain Blog)
LangChain 对 Harness Engineering 有一个很到位的定义:
Harness Engineering 是对模型智能的“塑形”——模型的能力参差不齐,Harness 的工作就是把这些能力塑造成适合具体任务的形状。
OpenAI 展示了 Harness 的全貌,LangChain 给了定量验证,Anthropic 解决的是一个更底层的问题:Agent 怎么跨越上下文窗口的限制,实现真正的长期运行?
这个问题的本质是:AI 的上下文窗口有限,一个复杂项目不可能在单个窗口内完成。每次新开会话,Agent 就像失忆了——不知道之前做过什么。
Anthropic 的解法是双层架构:
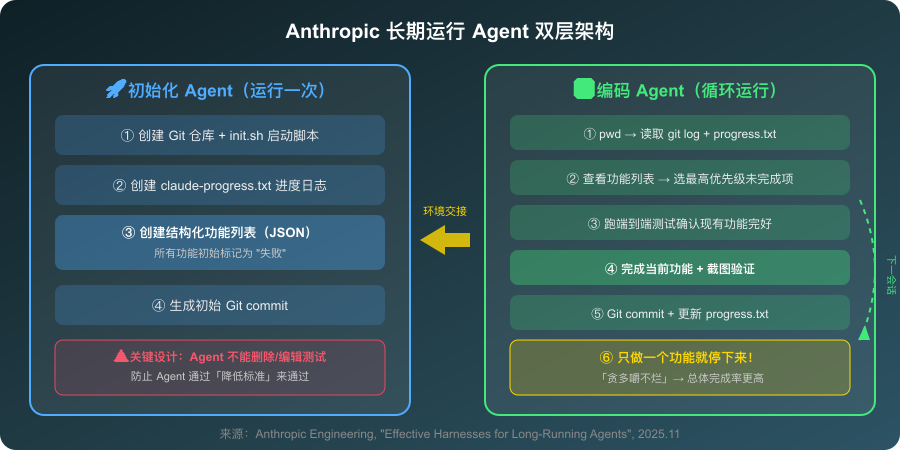
图6:Anthropic 的初始化 Agent + 编码 Agent 双层架构——通过结构化进度追踪实现跨会话连续工作
这个架构里有几个精妙的设计值得注意:
功能列表的“全标失败”策略。 所有功能初始状态标记为“失败”,Agent 只能通过修改状态字段来标完成,不允许删除或编辑测试用例。这堵死了 Agent 通过“降低标准”来“完成”任务的路。
“每次只做一件事”的强制约束。 Anthropic 发现 Agent 有强烈的“贪多嚼不烂”倾向——试图一个会话把所有功能做完,结果上下文耗尽留下半成品。强制“做一个功能就停”看起来效率低,但总体完成率高得多。
进度文件作为“跨会话记忆”。 不只是日志,它是 Agent 的“外部记忆”。每个新会话的第一件事是读这个文件和 git log,搞清楚“上一个自己”做了什么。这把“失忆问题”从根本上解决了。
Harness Engineering 不是没有争议。Latent Space 2026 年 3 月那篇文章直接把业界劈成两个阵营。
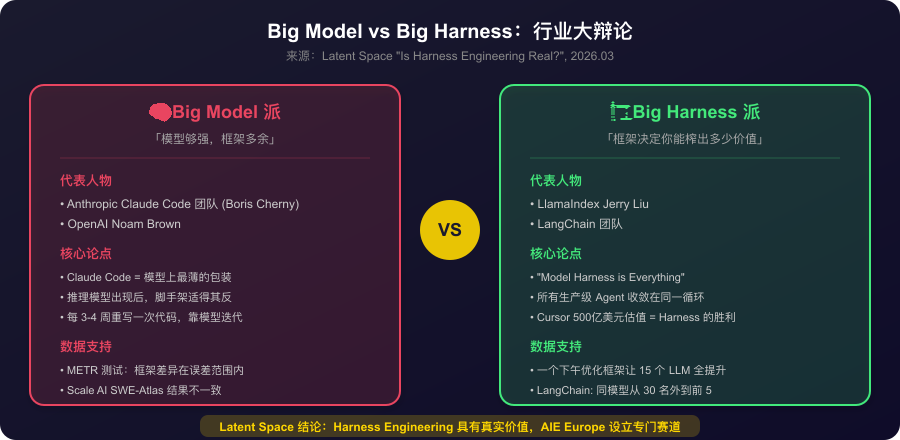
图7:行业两大阵营的核心论点、代表人物与数据支持对比
Big Model 派最有力的支持者竟然来自 Anthropic 内部的 Claude Code 团队。Boris Cherny 明确表示 Claude Code 的架构“极简”,所有秘方在模型本身——“模型上最薄的包装”,每三到四周重写一次代码,靠模型迭代保持领先。OpenAI 的 Noam Brown 更激进:“在推理模型之上构建脚手架往往适得其反。”
METR 的独立测试也给了支持数据:Claude Code 和 Codex 在严格对比中并没有战胜基础脚手架。Scale AI 的 SWE-Atlas 测试发现框架选择的差异基本在误差范围内。
Big Harness 派的旗手是 LlamaIndex 的 Jerry Liu——“Model Harness is Everything”。有案例显示仅通过优化 Harness(不换模型),“一个下午让 15 个 LLM 的编码能力全部提升”。Cursor 500 亿美元的估值也被当作“Harness 价值”的证据——Cursor 的模型不是自己的,它的核心竞争力全在 Harness 层。
我的判断是:这不是非此即彼的问题,而是“时间尺度”的问题。
短期内(单次任务),强大模型确实可以用最简 Harness 达到好效果——Claude Code 的成功就是证据。但长期(持续运行、多人协作、大型项目),没有 Harness 的 Agent 会因为熵增、上下文丢失和模式漂移而失控。
类比一下:让一匹好马跑 100 米,不需要缰绳。让它拉着货物跑 100 公里穿越山路,没有缰绳不行。Harness 的价值随着任务的复杂度和持续时间指数增长。
影响一:“Harness 模板”会成为新的基础设施
Birgitta Böckeler 在 Martin Fowler 网站指出了一个值得关注的趋势:未来可能出现“Harness 模板”。
现在大多数公司有两三种主要技术栈,用服务模板帮团队快速启动新项目。未来的模板会长得不一样——不只包含代码脚手架,还包含自定义 Linter、结构化测试、基础文档、架构约束规则。团队启动一个新项目,选一套 Harness 模板,AI Agent 就能在预设的轨道上跑起来。
这也意味着技术栈的选择标准会变。过去我们选框架看社区活跃度、文档质量、开发者体验。以后可能要加一条:“AI 友好性”——这个技术栈有没有好的 Harness 支持?
影响二:遗留代码库的“两个世界”
对从零开始的新项目,Harness Engineering 很美好。但那些跑了十年的老系统呢?
Birgitta Böckeler 给了一个扎心的比喻:给遗留代码库改造 Harness,“就像在一个从未运行过静态分析工具的代码库上突然开启全部规则——你会被警报淹没”。
这意味着行业可能分裂成两个世界:新项目用 Harness Engineering 实现高度 AI 自治,老项目继续以人工为主。两个世界需要的技能组合截然不同。
不需要从零搭建 OpenAI 那样的完整系统。按难度排序:
今天就能做
1. 把 AGENTS.md 写成地图,不是百科全书。 列出项目结构、核心模块、关键约定,指向详细文档位置。Agent 需要的是“去哪里找信息”,不是“所有信息”。
2. 把反复出现的 Review 意见变成 Linter 规则。 “不要在 Controller 里直接查数据库”、“所有公共 API 必须有入参校验”——ESLint 自定义规则、pre-commit hook、ArchUnit 结构化测试,把人的“品味”编码成机器可执行的检查。
一周内能做
3. 给 AI 工具加“完成前必须验证”的规则。 在系统提示中加一条:标记任务完成之前,必须跑测试、启动应用验证、UI 变更要截图检查。
4. 建立进度追踪文件。 对复杂任务创建 Agent 可读写的进度文件(JSON 或 Markdown),每个工作单元完成后更新。解决上下文断裂问题。
需要投入时间
5. 让日志和指标对 Agent 可查。 最简单做法:关键日志输出到文件,Agent 工具列表加一个“查看最近 N 行日志”的能力。
6. 定期跑“清洁 Agent”任务。 每周一次,检查文档和代码是否一致、是否有违反架构规范的新代码、是否有可抽象的重复模式。
三句话理解 Harness Engineering:
Harness Engineering 解决的不是“怎么让 AI 更聪明”,而是“怎么让 AI 可控地持续工作”。 聪明是模型公司的事,可控是工程师的事。
它的核心逻辑是“用约束换自主”——给 AI 设的规矩越明确,它能独立做的事情就越多。 听起来矛盾,但和人类社会的运转逻辑完全一致:法律越完善的社会,个人自由度越高。
它正在重新定义“工程师”这个职业。 你的价值不再取决于你写代码的速度,而取决于你设计系统的能力——约束、反馈回路和控制系统,才是真正不可替代的东西。
用 OpenAI 那篇文章的结尾来收束:
构建软件仍然需要纪律,但这种纪律更多地体现在支撑结构上——工具、抽象、反馈回路——而不是代码本身。
AI 已经是千里马。千里马没缰绳,跑得再快也到不了目的地。
Harness Engineering,就是这个时代最重要的缰绳。
参考文献
- Ryan Lopopolo, Harness Engineering: Working with Codex in an Agent-First World, OpenAI, 2026.02.11
- Birgitta Böckeler, Harness Engineering, MartinFowler.com, 2026.02.17
- LangChain, Improving Deep Agents with Harness Engineering, 2026
- Latent Space, Is Harness Engineering Real?, 2026.03.05
- Justin Young, Effective Harnesses for Long-Running Agents, Anthropic Engineering, 2025.11.26
- Cassie Kozyrkov, Harness Engineering: How to Supervise Code You Can’t Read, Decision Intelligence, 2026.03.03
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我的微信公众号:机器懂语言。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/241487.html