
本教程仅为个人学习总结,如有错误以实际为准。
核心文件:RAG向量知识库搭建教程.md (人与AI皆可读)
文章内容在:https://blog.csdn.net/_/article/details/?spm=1011.2124.3001.6209
把这个文章中的东西复制出来即可。
最终会生成build_rag.py(生成知识库索引) 和 query_rag.py(查询)
这个就不演示了,正常情况会在C:Users{你的名字}.openclawworkspaceMEMORY.md 中记住这个知识库
使用AI查询的好处是,它还能顺带帮你翻译一下英文内容
rag_index.pkl 是你的RAG知识库索引文件,包含了所有文档的向量化数据。
里面存储了什么:
- embeddings(向量): 7426个文本块,每个转换成384维的数字向量
- chunks(文本内容): 7426个原始文本片段(每个约500字符)
- sources(来源): 每个文本块来自哪个文档
作用:
- 查询时,你的问题也会转成向量
- 通过计算向量相似度,快速找到最相关的文档片段
- 不需要每次都重新处理原始PDF文档
大小: 14.9 MB(比原始文档小很多)
可以理解为:把16个文档"压缩"成了一个可快速搜索的数据库文件。
如何使用GPU:
修改构建脚本,把 device='cpu' 改成 device='cuda':
前提条件:
- 有NVIDIA显卡
- 安装了CUDA
- 安装了GPU版本的PyTorch
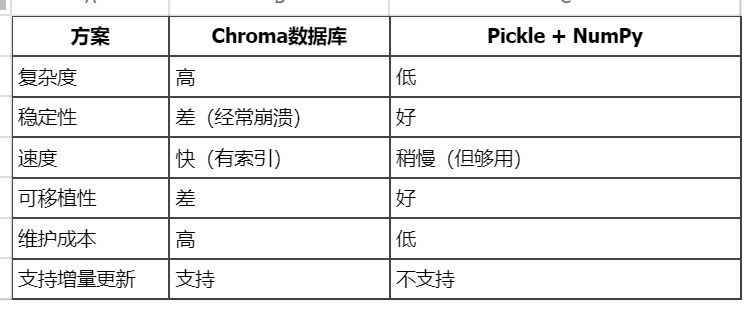
当前使用的方案是 Pickle + NumPy ,除了这个也可以使用Chroma数据库,会快一些,需要改脚本直接和AI说
Pickle + NumPy 方案:
- 用pickle直接保存向量数组
- 用numpy计算余弦相似度
- 简单、稳定、可靠
Chroma的主要优势:
- 增量更新
- 当前方案:添加新文档需要重建整个索引
- Chroma:可以直接添加/删除文档,无需重建
- 持久化存储
- 当前方案:每次查询都要加载整个pkl到内存
- Chroma:数据存在磁盘,按需加载
两种方案对比:

视频可以放置一个同名txt文件,里面放置识别的文字,然后和AI说使用txt构建就好。扫描pdf 可以先使用工具(如福昕编辑器)识别文字,这样AI也是能使用的。
如果RAG知识库索引使用的是绝对路径,那就改不了。如果使用的是相对路径的话,可以移动。但是都需要保持文件夹层级名字层次结构一致。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/239388.html