
在跨境电商领域,数据获取能力直接决定了企业的竞争力。传统的数据抓取方式面临着诸多挑战:反爬虫机制日益复杂、平台API限制严格、维护成本居高不下。OpenClaw 作为新一代 AI Agent 框架,通过其 Skill 生态系统,为跨境电商从业者提供了一套完整的数据获取解决方案。本文将深入剖析 OpenClaw Skill 的技术架构、实现原理以及在跨境电商场景中的实战应用,手把手教你打造一个真正能干活的 AI 助手。
1.1 什么是 OpenClaw
OpenClaw 是基于 Claude AI 的智能代理框架,它通过 Model Context Protocol(MCP)实现了 AI 与外部工具的标准化交互。与传统的 RPA 工具不同,OpenClaw 具备自主决策能力,能够根据任务需求动态选择和组合工具。这种架构使得开发者无需编写复杂的爬虫代码,只需通过自然语言描述需求,AI 便能自动完成数据抓取、分析和处理的全流程。
1.2 MCP 协议与 Skill 机制
Model Context Protocol 是 Anthropic 提出的标准化协议,用于连接 AI 模型与外部工具。在 OpenClaw 中,每个 Skill 本质上是一个符合 MCP 规范的工具包,它定义了输入参数、执行逻辑和输出格式。这种标准化设计使得不同开发者创建的 Skill 可以无缝集成,形成强大的工具生态。
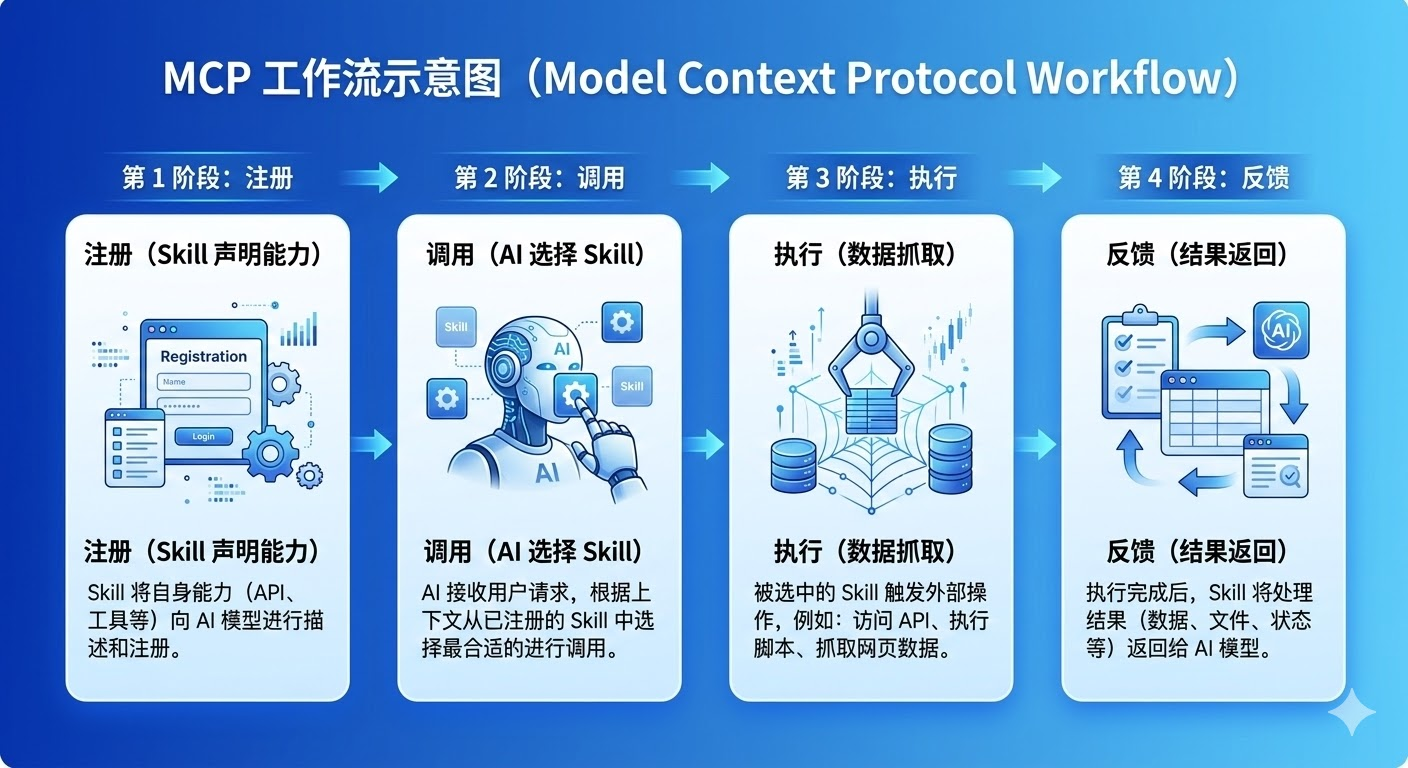
Skill 的工作流程可以分为四个阶段:注册阶段,Skill 向 OpenClaw 声明自己的能力和接口;调用阶段,AI 根据任务需求选择合适的 Skill;执行阶段,Skill 完成具体的数据抓取或处理任务;反馈阶段,执行结果返回给 AI 用于后续决策。这种机制确保了系统的可扩展性和灵活性。
GPT plus 代充 只需 145
1.3 Mac 权限配置实战:解锁 OpenClaw 完全体
OpenClaw 3.2 版本升级后,Mac 用户普遍遇到“权限不足”“没有权限执行此操作”等问题。这是官方收紧的安全策略,默认把工具执行权限降到最低(minimal/strict 模式),目的是防滥用、提升隐私安全。但对于想让 AI 真正“帮我干活”的用户来说,这等于把助手的手脚绑起来了。
好消息是:Mac 上开满权限超级简单,不需要 root、不需要复杂配置,几条命令搞定。下面手把手教你把 OpenClaw 的内部工具权限和 macOS 系统 TCC 权限都开到最大。
⚠️ 重要提示:开满权限 = OpenClaw 几乎拥有你当前用户的全部能力,能读写文件、执行任意 shell、控制屏幕、网络操作等。风险自负!建议只在个人 Mac mini 或专用机上全开,主力机慎用。可以考虑用 balanced 模式 + 白名单更安全。
第一步:开启 OpenClaw 内部工具权限(解决 90% 问题)
打开终端(Terminal),执行以下命令:
如果返回 ,说明第一步完成。
第二步:授予 macOS 系统 TCC 权限
macOS 的隐私保护很严,OpenClaw 要读写桌面/文档、控制其他 App、截屏等,必须手动授权。
- 进入 系统设置 → 隐私与安全性(Privacy & Security)
- 重点开启以下几项(点“+”添加):
- 完全磁盘访问(Full Disk Access):添加 (M 系列芯片)或 (Intel 芯片),或者直接加
- 自动化(Automation):允许控制 Finder、Terminal 等
- 屏幕录制(Screen Recording):需要截屏时开启
- 输入监控(Input Monitoring):模拟键盘/鼠标时开启
- 如果找不到路径,先让 OpenClaw 执行一次读文件的命令(如“列出我的桌面文件”),系统会弹出授权窗口
- 权限弹窗不出现或丢失的解决方案:
- 在隐私设置里把相关条目删掉(点“-”)
- 关闭 OpenClaw Gateway
- 重新启动 Gateway,再触发一次需要权限的操作
- 极端情况重置 TCC(会清除所有 App 权限):
GPT plus 代充 只需 145
- 运行诊断命令(强烈推荐):
第三步:快速测试权限是否开满
在 OpenClaw 聊天界面试试这些指令:
- “在终端运行 whoami 并告诉我”
- “列出我的 ~/Desktop 所有文件”
- “在桌面创建一个 test.txt,内容写’权限测试成功’”
- “帮我截个当前屏幕并描述一下”
全部成功、无任何“permission denied” → 恭喜,你的 OpenClaw 已解锁最大能力!
实战建议
全开权限后,OpenClaw 真的能 24 小时帮你干活:定时任务、浏览器自动化、写代码、监控社交媒体回复、甚至管智能家居。但它在你面前“一览无余”,隐私就是代价。主力机别全开,建议独立 Mac mini + Tailscale 远程管理。Token 账单大胆花,比雇助理划算多了。
2.1 Reddit 舆情监控的技术实现
Reddit 作为北美最大的社区平台,聚集了大量真实用户的产品讨论和购买反馈。然而,自2023年10月起,Reddit 关闭了免费的开发者API,传统的数据抓取方式面临巨大挑战。服务器IP频繁被封禁,返回403错误成为常态,评论区的分页和懒加载机制更是增加了抓取难度。
针对这一困境,社区开发了两套成熟的解决方案。第一种是基于 old.reddit.com 的公开JSON接口方案,这是 Reddit 为了兼容旧版客户端保留的数据接口,无需任何认证即可访问。reddit-readonly Skill 正是利用这一特性,通过构造特定的URL格式,直接获取版块热帖、搜索结果和评论串的结构化数据。这种方案的优势在于完全免费、无需维护API密钥,且稳定性较高。
GPT plus 代充 只需 145
第二种方案是 Decodo OpenClaw Skill,它提供了更高级的封装和更强的稳定性。Decodo 在后端维护了IP轮换池和请求重试机制,能够有效应对Reddit的反爬虫策略。其提供的 reddit_post 和 reddit_subreddit 两个工具返回标准化的JSON数据,开发者无需关心底层的网络请求细节。对于需要长期稳定运行的商业项目,这种方案更为可靠。
2.2 Amazon 商品数据的结构化提取
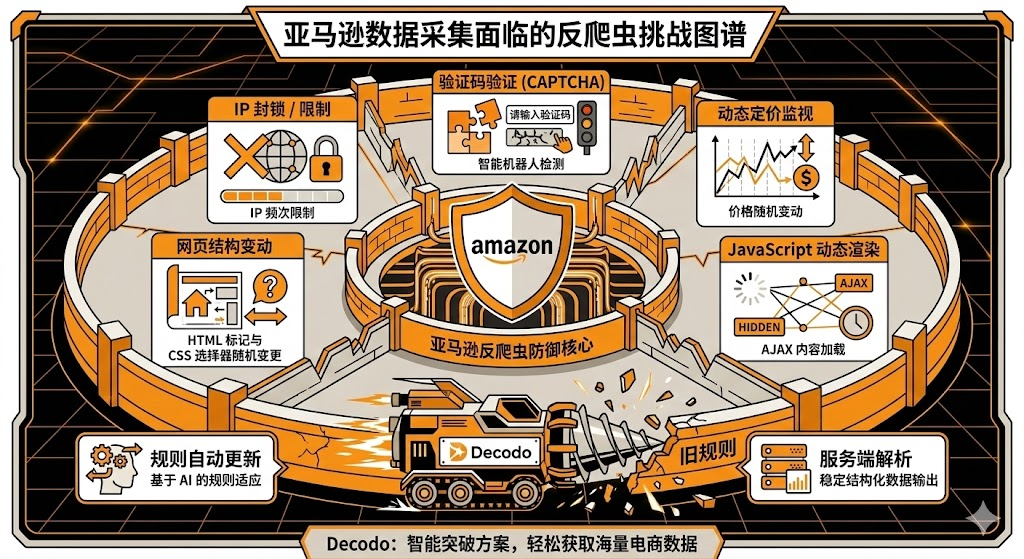
Amazon 作为全球最大的电商平台,其反爬虫机制极为复杂。IP封锁、JavaScript动态渲染、价格实时刷新、验证码挑战等多重防护措施,使得传统爬虫的维护成本极高。更棘手的是,Amazon 的页面结构频繁更新,基于CSS选择器的爬虫脚本往往在几周内就会失效。
Decodo Skill 针对 Amazon 场景进行了深度优化。其核心优势在于将页面解析规则的维护工作转移到了服务端,当 Amazon 更新页面结构时,Decodo 团队会及时更新解析规则,客户端无需任何修改即可继续使用。amazon 工具用于解析单个商品详情页,可提取价格、评分、评论数、ASIN码、Best Seller标志、卖家信息等关键字段。amazon_search 工具则支持按关键词批量搜索,返回搜索结果页的所有商品数据。
这种方案的实战价值在于可以快速构建竞品分析流程。例如,跨境卖家可以每天自动抓取目标品类的Top 50商品数据,监控价格变动、评分趋势和Best Seller的更替情况,从而及时调整自己的定价和营销策略。
2.3 多模态内容平台的数据获取
YouTube 和 TikTok 作为视频内容平台,承载着大量的产品评测、使用教程和用户反馈。这些视频内容对于理解用户真实需求、发现产品痛点具有重要价值。然而,视频数据的处理难度远高于文本,传统方式需要人工观看并记录要点,效率极低。
针对 YouTube 平台,Decodo Skill 提供了 youtube_subtitles 工具,能够直接提取视频的完整字幕文本。这个工具的实现原理是解析 YouTube 的字幕文件格式,无需调用官方API,避免了配额限制和认证复杂度。获取字幕后,可以利用 AI 的文本分析能力,快速提炼视频中的关键信息。
GPT plus 代充 只需 145
2.4 GitHub 技术产品情报挖掘
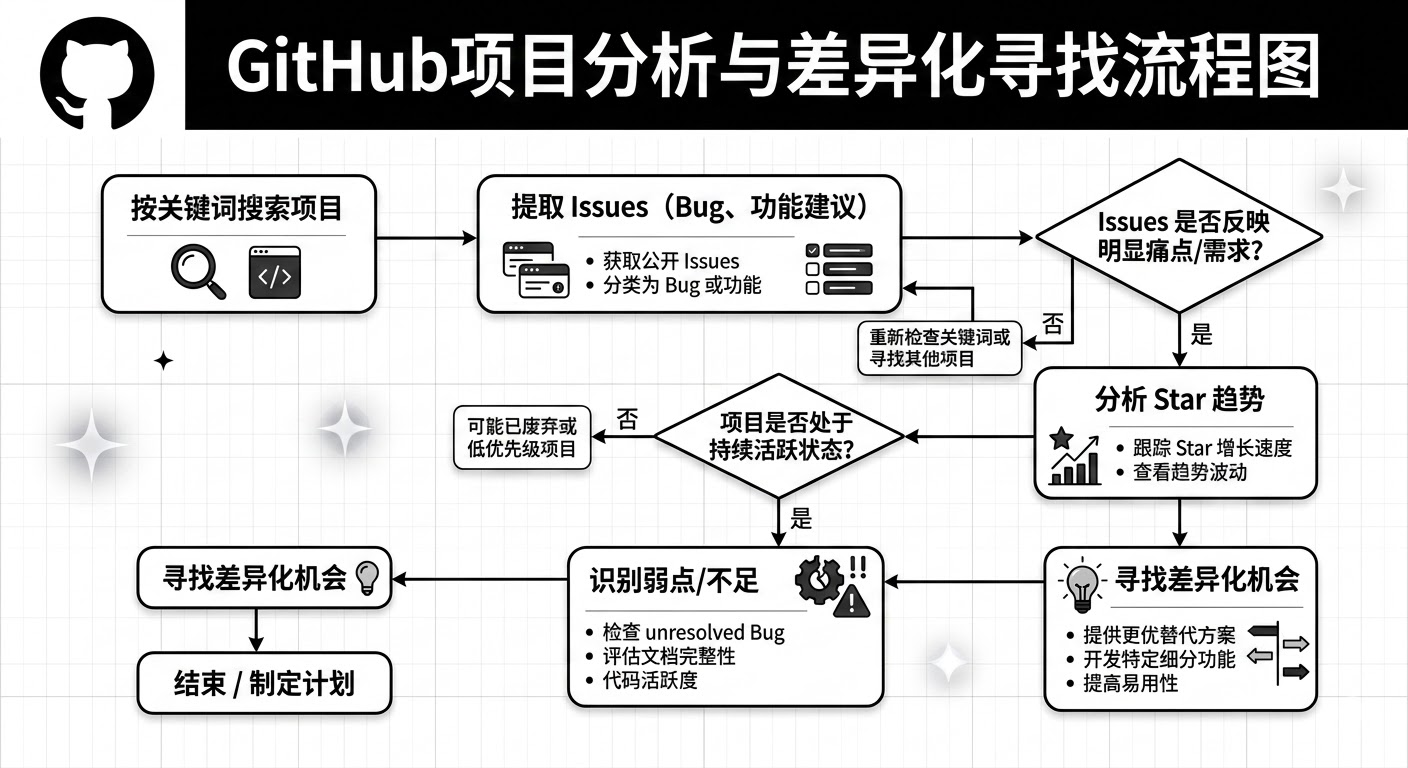
在跨境电商领域,工具型产品(如SaaS服务、浏览器插件、开发者工具)的竞品分析往往被忽视。实际上,GitHub 上的开源项目蕴含着大量有价值的情报信息。项目的 Issue 区域记录了真实用户遇到的问题和功能需求,Star 增长趋势反映了市场热度,代码提交历史揭示了技术演进路径。
Agent-Reach 内置了 GitHub 官方的 gh CLI 工具,提供了比网页爬虫更稳定的数据获取方式。通过命令行接口,可以搜索仓库、读取 Issue、分析 Pull Request、追踪 Star 历史等。这种方式的优势在于数据格式标准化,且不会触发 GitHub 的反爬虫机制。
这种分析方法的实战价值在于能够发现竞品的薄弱环节。例如,某个选品工具的 GitHub 仓库中,如果大量 Issue 反映“数据更新不及时”或“某个平台支持不完善”,这就是你的产品可以切入的差异化点。通过系统化地监控竞品的技术债务,可以在产品规划时避开已知的坑,或者针对性地推出更优的解决方案。
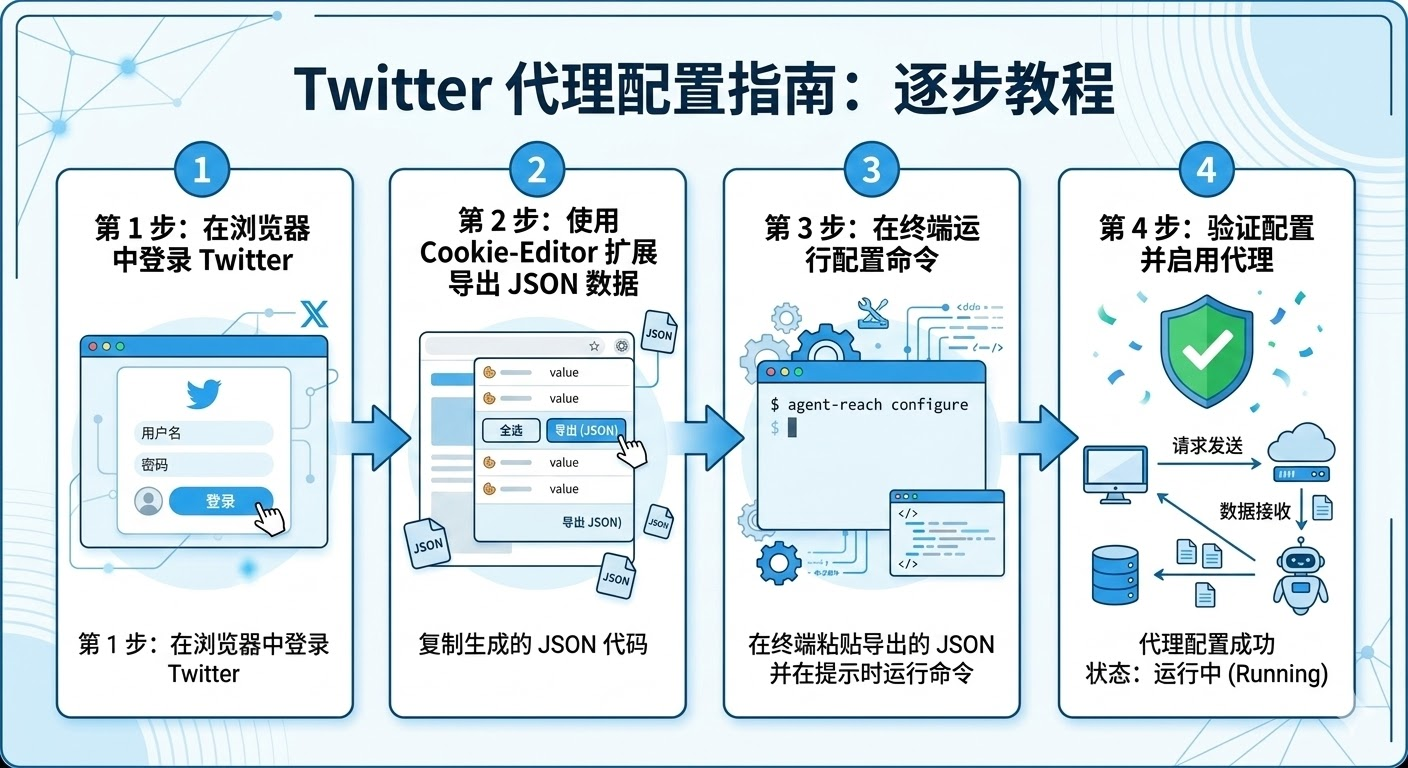
3.1 Twitter/X 平台的数据获取策略
Twitter 作为全球实时信息流的核心平台,对于跨境电商从业者而言具有不可替代的价值。平台政策变化、行业热点事件、竞品动态往往最先在 Twitter 上发酵。然而,自2023年起,Twitter API 实行严格的付费政策,免费层级几乎无法满足商业需求。使用浏览器自动化方案又面临会话保持困难、频繁断线等问题。
Agent-Reach 项目提供的 xreach 工具采用了 Cookie 登录方案,这是目前最稳定且成本最低的解决方式。具体实现流程是:首先在浏览器中正常登录 Twitter 账号,然后使用浏览器扩展(如 Cookie-Editor 或 Get cookies.txt LOCALLY)导出完整的 Cookie 数据,最后将 Cookie 配置到 xreach 工具中。这种方式模拟了真实用户的访问行为,能够绕过大部分的反爬虫检测。
GPT plus 代充 只需 145
需要注意的是,Cookie 方案存在时效性问题。根据 Twitter 的安全策略,Cookie 通常在7到30天后会失效,需要定期重新导出。为了保证长期稳定运行,建议设置自动化监控脚本,当检测到 Cookie 失效时及时发送通知。此外,避免在短时间内发起大量请求,建议在请求之间添加随机延迟,模拟人类的浏览行为。
3.2 动态网站的深度抓取技术
现代电商网站普遍采用单页应用(SPA)架构,大量数据通过 JavaScript 异步加载。速卖通的商品详情页、独立站的产品列表、展会网站的议程信息,这些页面使用传统的 HTTP 请求只能获取到空白的 HTML 框架,真正的内容需要等待 JavaScript 执行后才会渲染出来。
针对这类场景,有两种主流的技术方案。第一种是 playwright-npx Skill,它基于 Playwright 浏览器自动化框架,让 AI 编写爬虫脚本并通过 CSS 选择器执行操作。这种方案的优势在于一旦脚本调试通过,就可以持续稳定运行,适合结构固定的目标网站。
第二种方案是 browser-use Skill,它采用视觉识别技术,让 AI 像人类一样“看”网页并进行操作。这种方案的优势在于无需预先了解页面结构,适合处理未知或频繁变化的网站。但缺点是 Token 消耗较大,每次操作都需要对页面截图进行视觉分析,成本较高。实际应用中,建议优先使用 playwright-npx 方案,只有在遇到复杂的反爬虫机制或页面结构完全未知时,才启用 browser-use 作为备选方案。

4.1 AI 专用搜索引擎的选择与配置
传统搜索引擎返回的结果是为人类阅读设计的,包含大量广告、导航元素和无关内容。当这些数据直接喂给 AI 时,会造成严重的“信息消化不良”,影响分析质量。AI 专用搜索引擎应运而生,它们返回的是经过清洗和结构化的数据,更适合机器处理。
目前主流的 AI 搜索引擎有三个选择。Tavily 是国内用户的首选方案,无需信用卡验证,国内网络可直连,免费额度足够个人使用。其 API 返回的数据包含标题、摘要、URL 和相关性评分,格式统一且易于解析。Brave Search 的数据质量更高,索引覆盖面更广,但需要海外信用卡注册,适合有条件的用户。Exa 则专注于意图理解,特别适合研究型查询,例如“找真实买家写的便携榨汁机独立评测”这类需求。
GPT plus 代充 只需 145
搜索策略的设计至关重要。与其执行一次宽泛的查询“蓝牙耳机市场分析”,不如分解为三次精准查询:“bluetooth earbuds under 30 site:reddit.com complaints 2026”、“bluetooth earbuds amazon best seller negative reviews”、“bluetooth earbuds temu compe***** comparison”。三次结果合并后的信息质量远超单次宽泛查询,这是因为每次查询都针对特定的信息源和角度,减少了噪音数据的干扰。

4.2 Apify 工业级爬虫平台
当数据抓取需求达到一定规模时,自建爬虫的维护成本会急剧上升。Apify 作为专业的网页抓取平台,提供了超过1000个预构建的 Actor(云端爬虫程序),覆盖 Google Maps、YouTube、Instagram、TikTok、Amazon 等主流平台。这些 Actor 经过长期优化,能够稳定应对目标网站的反爬虫机制。
Apify 的核心优势在于确定性和可扩展性。与 AI 实时生成的爬虫脚本不同,Apify Actor 是经过充分测试的固定程序,执行结果可预期。当需要抓取500家竞品店铺或1000条用户评论时,Apify 的云端执行环境可以并行处理,大幅缩短任务完成时间。此外,Apify 提供了完善的错误处理和重试机制,即使遇到网络波动或临时封禁,也能自动恢复执行。
这个工作流展示了 Apify 的组合能力。首先使用 Google Maps Scraper 获取商家基础信息,然后将网站 URL 传递给 Contact Info Scraper 提取邮箱地址。整个过程无需编写任何页面解析代码,只需配置参数和处理返回的结构化数据。对于跨境电商的 B2B 场景,这种方式可以快速构建潜在客户数据库。
5.1 价格监控与竞品预警系统
跨境电商的价格战往往在深夜悄然打响。竞品调价、促销活动、库存变动,这些关键信息如果不能及时捕获,就会错失市场机会。人工监控成本高昂且难以持续,自动化监控系统成为刚需。
构建价格监控系统的核心是建立“快照-比对-预警”机制。系统每天定时抓取竞品数据,与历史快照进行对比,当检测到显著变化时触发预警通知。这个流程可以通过 cron 定时任务和 Webhook 集成实现完全自动化。
GPT plus 代充 只需 145
这个系统可以通过 cron 配置为每天凌晨3点自动执行,这个时间点通常是竞品调整价格的高峰期。配合 Firecrawl 的远程沙盒执行,可以避免本地 Chromium 的资源消耗,实现轻量级的长期运行。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/236646.html