
<p><strong>导读:</strong> 用了几个月小龙虾(OpenClaw),装了不少 SKILL,有些几乎每天都在用。<br /> <br /> 这次挑出 15 个下载量高、自己实际在用的,每个说清楚干什么用——不废话,看完就知道要不要装。</p> 小龙虾是一个 AI 助手框架,SKILL 是给它装的插件——装一个,多一项能力。
所有 SKILL 都能在 clawhub.ai 免费找到。
你不知道有什么插件可以用的时候,跟 AI 说"我想订阅日历"、"帮我搜 Reddit",它会主动去 ClawHub 找合适的 SKILL,推荐给你安装。
装了这个,以后不用自己翻,AI 替你主动发现新能力。
🔗 clawhub.ai/JimLiuxinghai/find-skills
扔给它一个链接或文件——网页、PDF、图片、音频、YouTube 视频——直接输出摘要。
碰到一篇长文或者视频不想看完,先扔给它过一遍,值得细看再细看。
🔗 clawhub.ai/steipete/summarize
把音频或视频的语音转成文字,本地运行,不需要 API key,不花钱,数据不上传。
会议录音、采访录音、视频出字幕,全能搞。
🔗 clawhub.ai/steipete/openai-whisper
跟 AI 说"把第三页的标题改成 XX"、"在第二页末尾加一段",它真的帮你改。
PDF 从此不是只读文件了,不需要 Adobe,不需要记操作路径。
🔗 clawhub.ai/steipete/nano-pdf
描述你想要的图,AI 直接生成,支持 1K/2K/4K 分辨率。也支持把现有图片当输入再编辑——换背景、加文字、改风格都行。
不用单独订阅 Midjourney,对话框里就能出图。
🔗 clawhub.ai/steipete/nano-banana-pro
搜索 GitHub 开源项目、提 Issue、看 PR、查 CI——全在聊天框里完成。
程序员不用来回切窗口了。
🔗 clawhub.ai/steipete/github
把文章里"值得注意的是"、"不仅……而且……"、"总而言之"这类套话揪出来换掉,让内容读起来更像人写的。
AI 写完用这个过一遍,基本能解决 AI 腔问题。
🔗 clawhub.ai/biostartechnology/humanizer
默认 AI 是你问才回答。这个 SKILL 让它学会主动预判你的需求、定时巡检要关注的事、上下文丢了能自动恢复、用得越久越懂你。
从"被动工具"到"有主见的助理",差的就是这个。
🔗 clawhub.ai/halthelobster/proactive-agent
如果你用 Obsidian 做笔记,这个 SKILL 让 AI 直接读写你的 Vault——搜笔记、新建文档、更新内容。
说"找一下我去年记的关于 XX 的笔记",它真的能找到。
🔗 clawhub.ai/steipete/obsidian
默认的 AI 每次对话都是全新的,没有记忆。这个 SKILL 给它配置持久记忆系统,从"金鱼脑"变"大象脑"——你的偏好、工作习惯、历史决策,它都记得。
🔗 clawhub.ai/jrbobbyhansen-pixel/memory-setup
本地优先的股市分析工具,输入股票代码直接出带 RSI/MACD/布林带等技术指标的高清图表,一键输出分析报告。不用打开炒股软件,问 AI 就行。
🔗 clawhub.ai/kys42/stock-market-pro
PDF、Word、PPT、Excel、HTML、图片、音频——各种格式一键转成 Markdown,方便 AI 处理和分析。接到什么格式的文件都能直接喂给 AI。
🔗 clawhub.ai/steipete/markdown-converter
AI 做错了或者被你纠正之后,自动把这次的经验记下来,建立分层记忆库。下次同类问题不再犯同样的错。越用越聪明,不只是靠你反复教。
🔗 clawhub.ai/ivangdavila/self-improving
装陌生 SKILL 之前,先让它帮你过一遍——检查有没有可疑权限、异常行为、潜在安全风险。不知道来路的插件别直接装,先审再说。
🔗 clawhub.ai/spclaudehome/skill-vetter
用 ffmpeg 从视频里提取关键帧或短片段,方便内容分析和素材剪辑。做内容的人常用——不用自己一帧一帧截图了。
🔗 clawhub.ai/steipete/video-frames
这是我自己开源的一个 SKILL,专门解决网页内容抓取的问题。
Jina Reader 读不到的页面、需要登录的网站、微信公众号文章——用这个都能读到,支持三级降级策略自动兜底,返回干净的 Markdown 格式正文。
特别是微信公众号文章,这是大多数其他抓取工具做不到的。
OpenClaw 永久免费的提取任何网页的终极方案
🔗 github.com/shirenchuang/web-content-fetcher
把这个内容直接复制给你的小龙虾,让它帮你批量安装:
> 帮我安装这些 SKILL:find-skills、summarize、openai-whisper、nano-pdf、nano-banana-pro、github、humanizer、proactive-agent、obsidian、memory-setup、skill-vetter
或者直接把本文链接丢给它:「帮我把这篇文章里推荐的 SKILL 都装上」
参考链接
- ClawHub SKILL 库:https://clawhub.ai/skills?sort=downloads
- web-content-fetcher 开源地址:https://github.com/shirenchuang/web-content-fetcher
从0到1!大模型(LLM)最全学习路线图,建议收藏!
想入门大模型(LLM)却不知道从哪开始? 我根据最新的技术栈和我自己的经历&理解,帮大家整理了一份LLM学习路线图,涵盖从理论基础到落地应用的全流程!拒绝焦虑,按图索骥~~
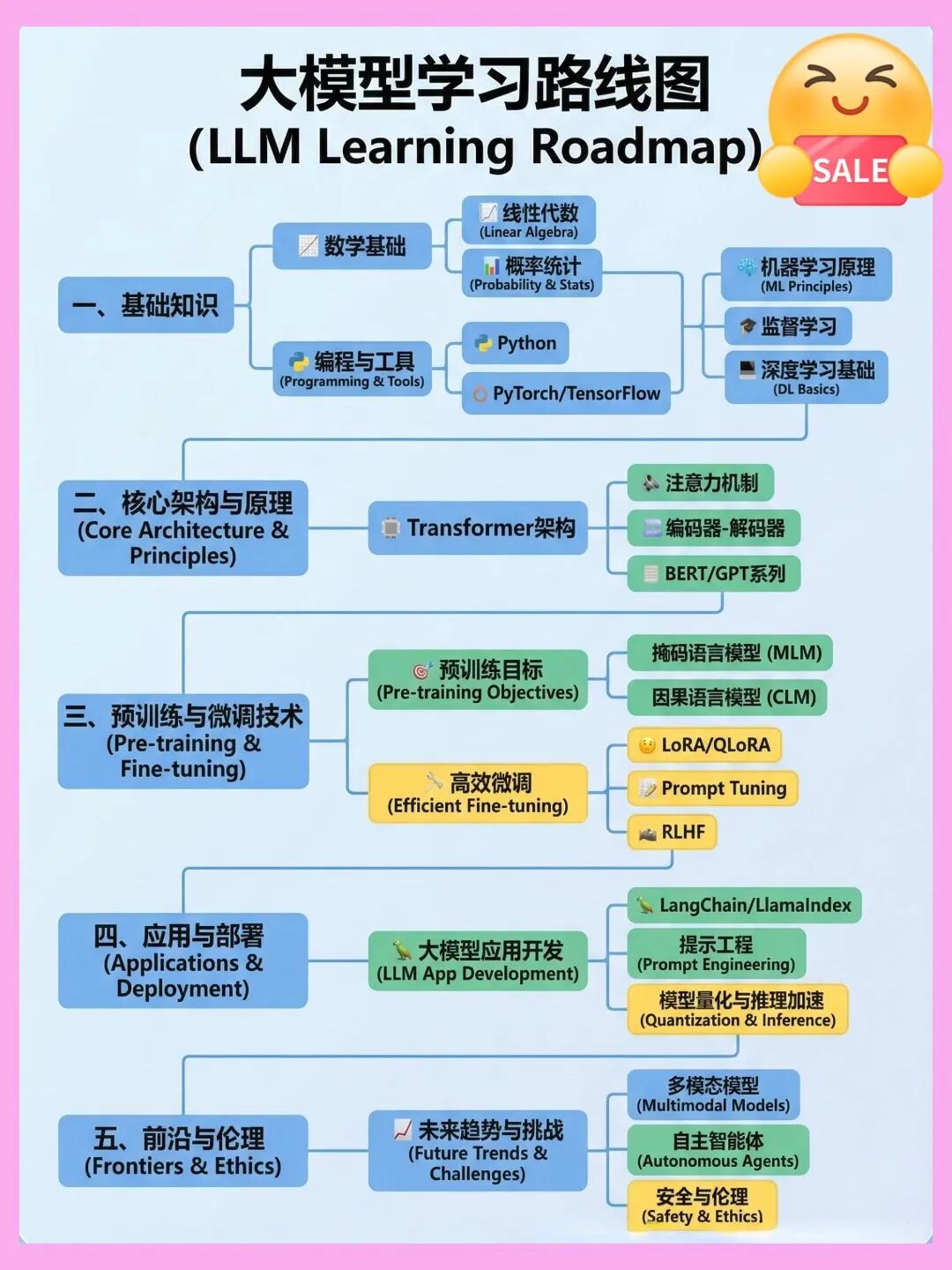
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取