
12月1日,DeepSeek宣布同时发布两个正式版模型:DeepSeek-V3.2和DeepSeek-V3.2-Speciale。
官方网页端、App和API均已更新为正式版DeepSeek-V3.2;Speciale版本目前仅以临时API服务形式开放,以供社区评测与研究。
DeepSeek-V3.2的目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用Agent任务场景;V3.2-Speciale是DeepSeek-V3.2的长思考增强版,同时结合了DeepSeek-Math-V2的定理证明能力。
https://www. jiemian.com/article/137 06093.html短的结论:同样配方的震撼
基本情况:
DeepSeek 已经给国产模型和开源世界带来了太多的震撼和颠覆,并不介意再来一次。而这一次,“保守”的DeepSeek甚至不愿意给V3.2 增加哪怕0.1的版本号。
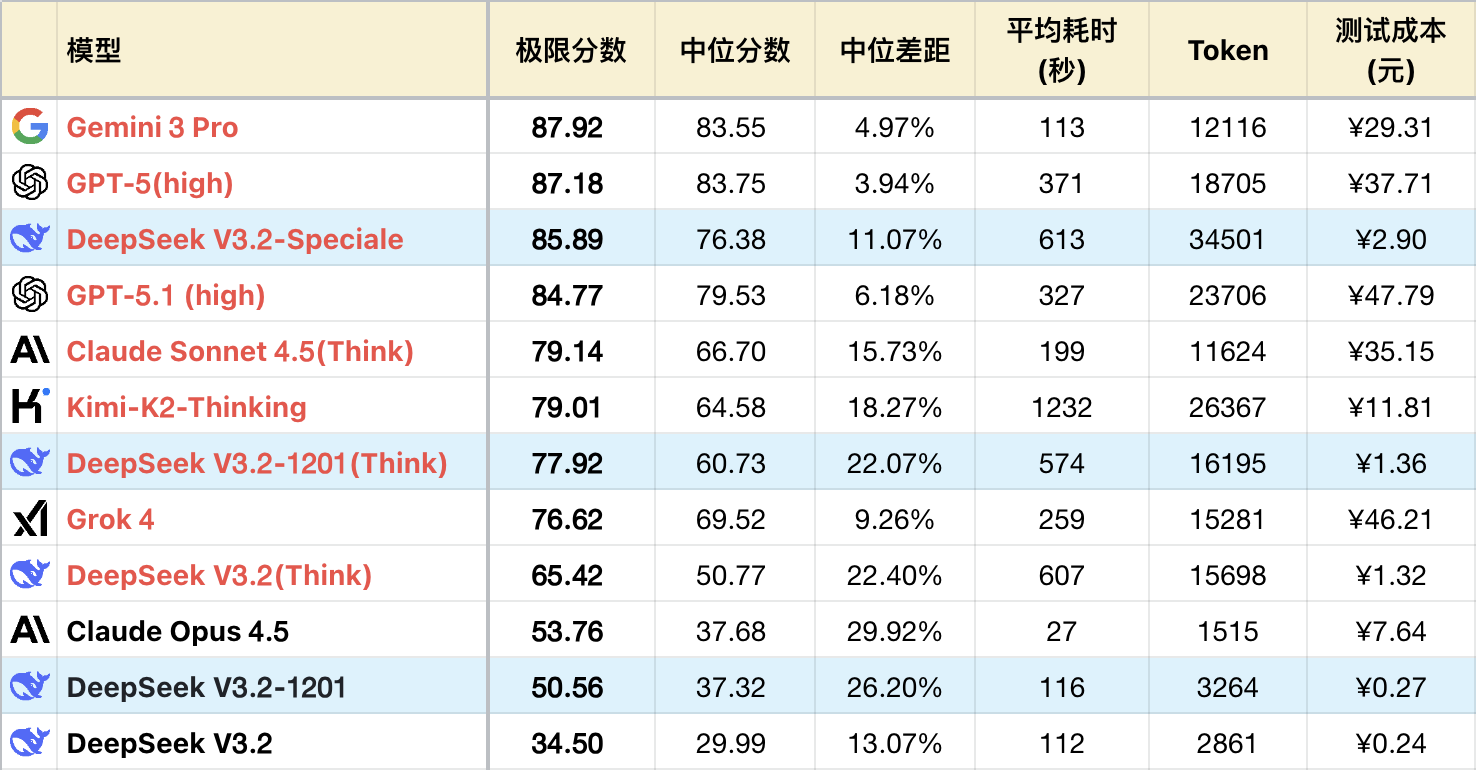
作为正式版,3.2相比3.2-Exp的提升已经足够大了,推理版+19%,基模也有+46%的提升,水平来到了国模第一梯队,一举跟上了国产最高水准。
而作为One-More-Thing的Speciale版本,能力冲进之前被北美四家牢牢占据的大本营,考虑测试误差范围,能力与GPT-5(high)相当,与DeepSeek自己公布的测试成绩相吻合。
先不要为性能突破而欢呼,如果你再多看一眼V3.2模型那特立独行的定价,会发现这事恐怕远不是“突破”那么简单。
逻辑成绩:
- 归纳洞察力:在之前的测试中,归纳能力几乎被GPT系列垄断,尤其在一些需要联系全文进行细致入微的推理,才能发现规律的难题上,GPT-5 一家独大。而Speciale模型打破了这一垄断。在#52 棋谱观察问题上,现在Speciale也可以得出正确的结论,答案甚至比GPT-5 还要精确。其他难度中等的同类题目,Speciale可以3 Pass 稳定满分,和GPT-5⁄5.1 相当,而Gemini 3 Pro虽然极限相同,但做不到3 Pass 稳定。一部分中等难题甚至V3.2正式版也可以稳定满分。此外,虽然Speciale 在相关题目上的Token 开销基本是GPT-5的1~1.5倍,但Gemini 3 Pro有时比Speciale 消耗更高。因此可以判定三者确实是同一水平,不分高下。
- 极限智力:在长链思考,复杂推理任务相关的题目上,Speciale版与GPT-5 不相上下,互有高低。其中#49 激光器布局问题,Speciale首次拿到满分,但代价是消耗了接近80K Token。V3.2正式版得分也不低。受幻觉影响,这类中间思维链偏长的问题,Speciale和V3.2 都无法稳定拿到高分,下限很低,可能退化到完全不得分,并且这种概率并不低。体现在显著更低的中位数得分上。
- 计算能力:在常规计算上,Speciale版是继GPT-5 之后第二个,所有题目全部稳定满分。受益于其高智力水平,即便需要绕一点弯的间接计算,Speciale版也稳定高分,比如#31 题,计算满足要求的三角形顶点。V3.2版则没有这样的稳定高精度,但情况依然大幅好于3.2-Exp版,属于国模第一梯队。
- 幻觉:V3.2正式版没有彻底解决长期存在的幻觉问题,长文本中信息提取,或者信息汇总等任务,表现并没有比之前Exp版好。Speciale版本有改善,但无法稳定保持,有不小的概率输出幻觉偏高,内容不可用。这方面离低幻觉的GPT-5⁄5.1 仍有差距。
- 空间能力:Gemini 3 Pro的看家本领空间想象力和推理,DeepSeek显然还没有彻底领悟。有些平面问题Speciale 可以凭借远超出Gemini 的Token消耗,仔细的搜索解空间,而转到三维空间,Speciale 就无法维持相同表现。
- 编程能力:V3.2与Speciale的编程水平仅比3.2-Exp小有进步,离顶级编程模型还有差距。V3.2的编程实测将另外发文分析。
先省流:DeepSeek 更新并开源 V3.2 正式版,同时开源长思考增强版 V3.2 Speciale 模型。亮点:
- Agent 能力进化:V3.2 支持在思维链思考过程中动态调用工具,实现边想边做,大幅提升了复杂任务的泛化能力。
- 挑战 SOTA 推理:DeepSeek-V3.2-Speciale 模型融合 DeepSeek-Math-V2 的定理证明能力,专攻逻辑极限 ,数学能力硬刚闭源的 Gemini 3 Pro(但推理成本较高)。

已经进 12 月了,再过一段时间就是 DeepSeek V3 发布一周年了,我还挺期待 DeepSeek 今年圣诞节再搞波大的,求求了!只要有 V4,我什么都会做的!V3.5 也行啊!
有人可能会觉得,月初才发 V3.2,元旦前估计就这了。这就是不懂 DeepSeek,我个人觉得 DeepSeek 圣诞节搞事的可能性依然很大。
先回顾一下 DeepSeek 一年来的发布:
- 2024/12/10:发布 DeepSeek V2.5
- 2024/12/26:发布 DeepSeek V3(间隔半个月):初见端倪
- 2025/1/20:发布 DeepSeek R1(间隔不到一个月):改写历史
- 2025/3/24:发布 DeepSeek-V3-0324(顺便一提:我自己今年消耗 token 最多应该就是 DeepSeek V3-0324,一方面是懒得改 API,一方面是够用)
- 2025/5/28:发布 DeepSeek-R1-0528
- 2025/8/21:发布 DeepSeek V3.1:混合推理,不再发布单独的推理模型
- 2025/9/22:发布 DeepSeek-V3.1-Terminus:修复 V3.1 版本中的异常字符问题
- 2025/9/29:发布 DeepSeek-V3.2-Exp(间隔一周):引入 DSA 稀疏注意力机制,在不影响输出效果的前提下大幅降价
- 2025/10/23:发布 DeepSeek-OCR
- 2025/11/27:发布 DeepSeek-Math-V2
- 2025/12/1:发布 DeepSeek V3.2 正式版和 DeepSeek-V3.2-Speciale
看上去,DeepSeek 似乎花了一整年的时间,只从 V3 走到了 V3.2,但实际上,DeepSeek 这一年来就是在做一件事情:如何在不增加模型规模的前提下,通过架构优化和强化学习,不断提升模型的「思考密度」、「执行效率」和「Agent 能力」,同时降低模型的推理成本。
DeepSeek 是缺人力物力财力数据去训 T 级参数规模的模型吗?我觉得不是。单纯就是发展路线的选择,我相信 DeepSeek 用一年时间,已经把 V3 的基模调出花了。
说实话,这种不为外部环境所动,坚持自我路线的节奏,太稳了,太可怕了。因为高速发展的创新产业,拼的就是机会成本,毕竟团队的人财物力都是有限的,可以探索的方向也是有限的。
从这种角度上讲,大家觉得,DeepSeek 是发 V4 更恐怖,还是发 V3.3、3.4…3.9…3.99 更恐怖呢?
DeepSeek 现在就给我这种,厚积薄发练内功的感觉。
想想,Ilya 前几天说 Scale 时代快结束了,要回归 Research 时代。有没有一种可能…DeepSeek 一直在 Research,没有 Scale 呢?(这里指参数量级,推理还是 scale 了的)
当别家粗放地把参数卷到碰数据墙,卷到了边际效应递减,单纯增加参数量带来的性能提升越来越小时,DeepSeek 搁这里精耕细作。
换句话说:671B 都这样了,1T 参数还不起飞咯?!
扯远了,回归 DeepSeek V3.2。V3.2 不是独立的,是 V3.1 以来的延续。
V3.1 比较好理解,就是混合推理;
V3.2-Exp 主要是 DSA(稀疏注意力机制)。为了验证 DSA 的有效性,团队特意将 V3.2-Exp 的训练设置与 V3.1-Terminus 进行了严格对齐。在各领域的公开评测集上,DeepSeek-V3.2-Exp 的表现与 V3.1-Terminus 基本持平。
也就是说,V3.2-Exp 几乎实现「无损压缩」。模型在变快、变省资源的同时,智商并没有下降。
V3.2-Exp 解决了「效率」问题,V3.2 继续提升 Agent 和推理能力的改进版。
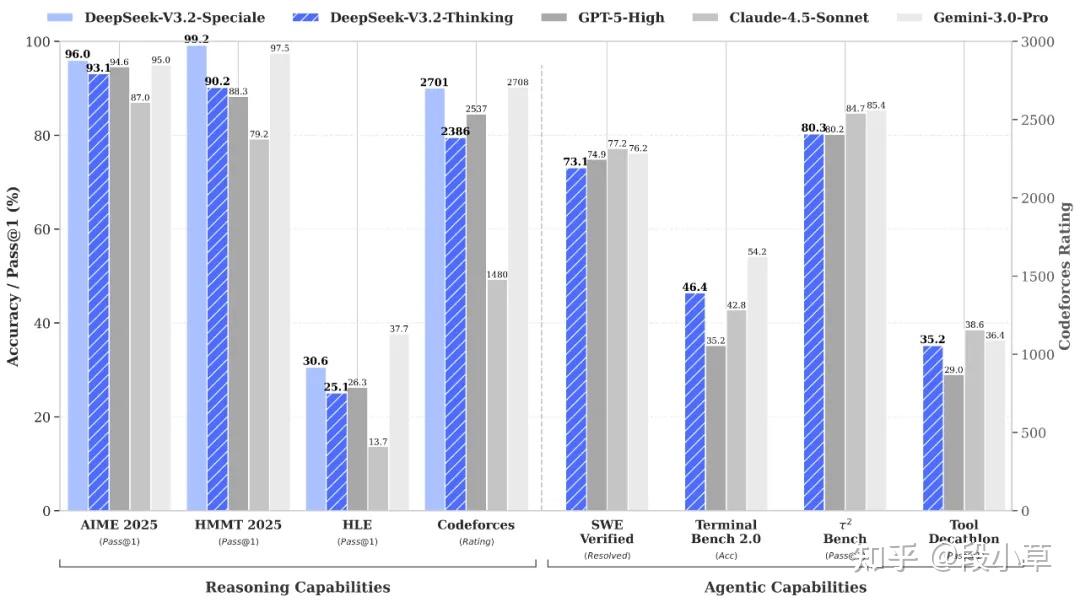
其次,就是工具使用融入思考过程,实现「思考-调用-再思考」。
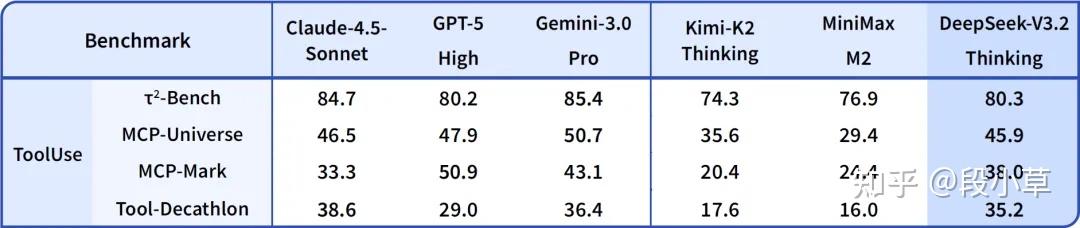
这种能力不是凭空而来的。DeepSeek 在技术报告中透露,他们提出了一种大规模 Agent 训练数据合成方法。
他们构造了 1800+ 个环境 和 85,000+ 条复杂指令。这些任务具有一个鲜明的特征:「难解答,易验证」。这正是强化学习最喜欢的场景。通过这种大规模的合成数据训练,模型在并未针对特定工具进行特训的情况下,展现出了极强的泛化能力。
至于 DeepSeek-V3.2-Speciale,这个版本并不适合普通用户使用,它依然是一个「偏科生」,一个为了解题而生的长思考增强版,一个探索推理极限的特别版本。
Speciale 版本结合了 DeepSeek-Math-V2 的定理证明能力,通过数学竞赛的测评,在处理高度抽象的逻辑符号和严谨证明方面,已经达到了人类顶尖选手的水平。尽管有代价:Speciale 模型在处理任务时,会消耗显著更多的 Token。
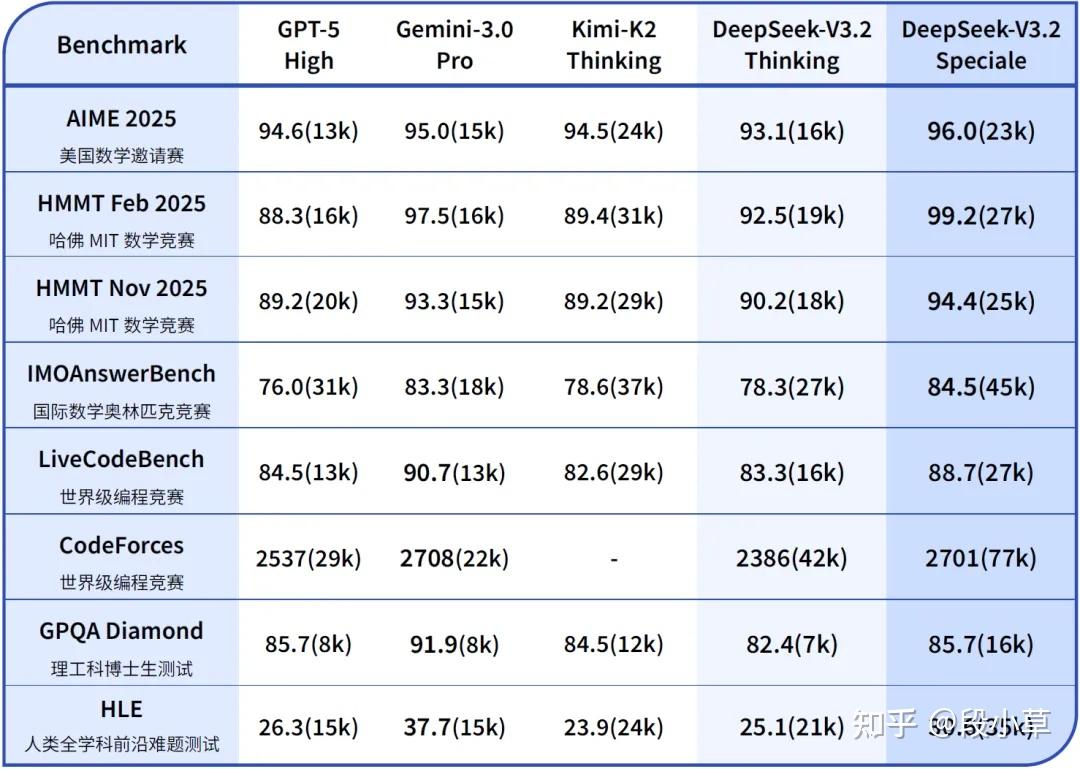
总之,V3.2 依然是一个扎实而稳步推进的更新版本,Agent 能力、推理能力都有极大提升。
对于开发者和企业用户来说,DeepSeek V3.2 的发布释放了一个信号:开源模型对闭源模型的追赶速度并没有放缓,反而会因为架构创新而变得更具性价比。
Agent 的 token 消耗量是巨大的,所以当模型能力持平而 Agent 大量落地的时候,谁更有性价比就会成为决定因素。
别忘了,DeepSeek 是第一个发起模型价格战的鲶鱼,显然已经抢先占领了有利地形。
对了,梁文锋曾经说过:
数学和代码是 AGI 天然的试验场,有点像围棋,是一个封闭的、可验证的系统,有可能通过自我学习就能实现很高的智能。
Math-V2、Speciale 已经来了,Coder 还会远吗?V4 还会远吗?我充满期待。
以上,详见 DeepSeek 官方的更新公告:
DeepSeek V3.2 正式版:强化 Agent 能力,融入思考推理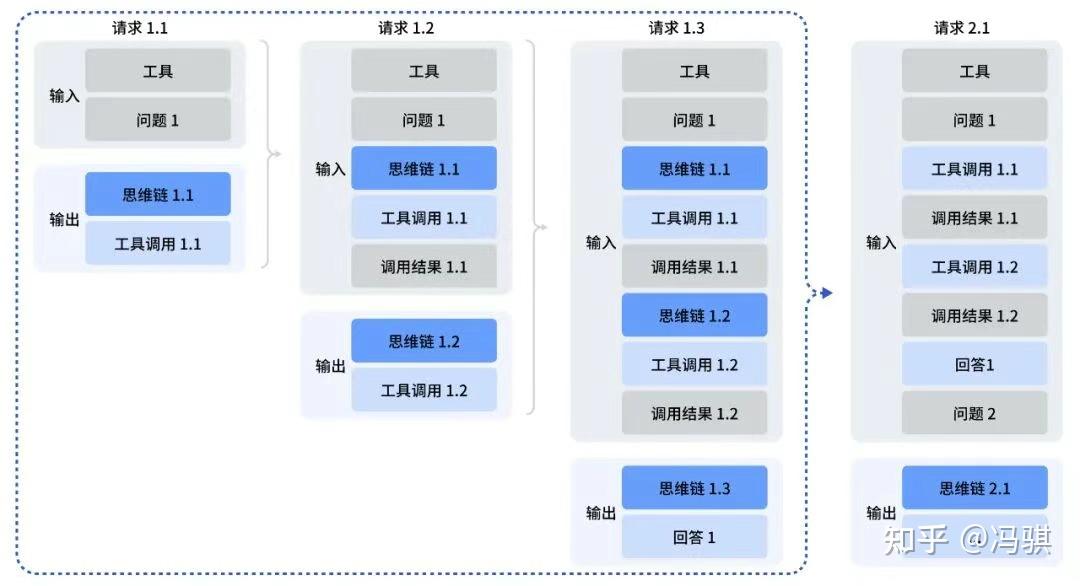
Github:https://github.com/freedomkk-qfeng/DeepSeek-ReAct-Native-example
知乎:基于 DeepSeek V3.2 的 Native Agent 实践指南,真香 - 知乎
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/233650.html