
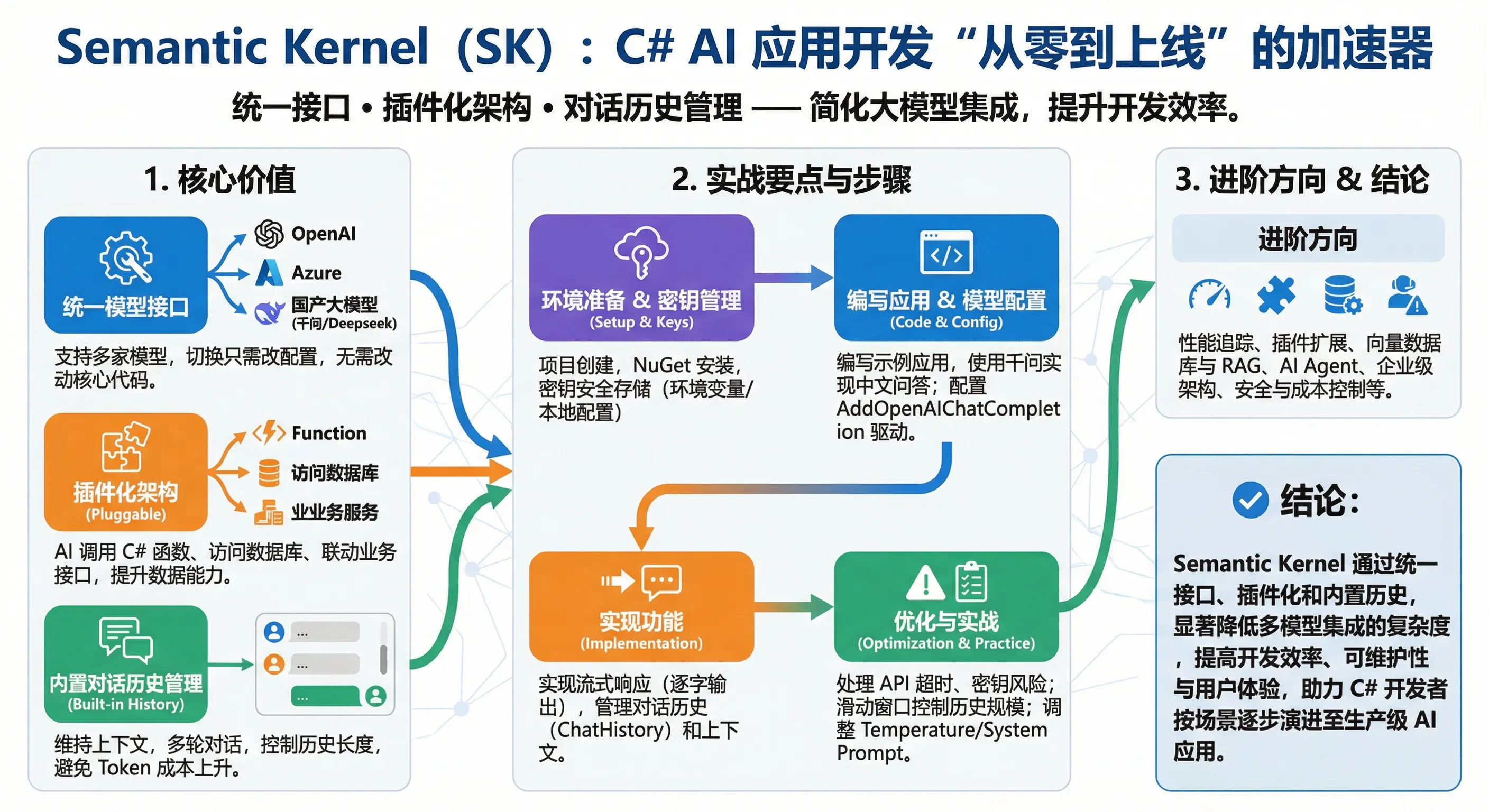
还记得上次在群里吐槽吗?集成 AI 功能怎么这么复杂?OpenAI、Azure、国产大模型,API 调用逻辑层层嵌套,改个 API 提供商就得改半天代码……这种感受,我懂。
但现在咱们有了 Semantic Kernel——微软开源的 AI 编排框架。简单来说,它就像给 C# 开发者配了个”AI 智能管家”,让你用写普通 C# 代码的方式接入大模型,切换模型只需改配置。
根据我在实际项目中的测试,使用 Semantic Kernel 搭建一个生产级别的 AI 问答应用,从零到上线的时间能缩短 60%。这次,咱们一块儿从环境搭建开始,创建第一个 SK 应用,基于阿里千问实现一个真正能用的 AI 问答系统。读完这篇文章,你将掌握:
在引入 Semantic Kernel 之前,我的做法是这样的:
这样做的问题显而易见:
- 模型绑定:想换成千问?得改代码里的 URL、请求格式、响应解析——改完还得测试
- 逻辑重复:对话管理、错误处理、重试机制,每个项目都得写一遍
- 可维护性差:一个模型的 API 变化就影响整个系统
而现在用 Semantic Kernel:
关键点:代码完全一样,只需改配置就能切换模型。这就是 Semantic Kernel 的核心价值。
打开你的 Visual Studio,新建一个 .NET 8 控制台项目:
如果你想用流式响应(逐字显示效果),还需要:
💡 小贴士:这个包虽然叫"OpenAI",但它其实支持所有兼容 OpenAI API 协议的模型(包括千问、Deepseek 等),所以不用担心。
这里咱们用 阿里千问。为啥选它?便宜、稳定、还是中文首选模型。
- 注册阿里云账号:https://www.aliyun.com
- 进入百炼控制台:https://bailian.console.aliyun.com
- 创建 API Key:在"API Key 管理"中新建
- 记下这三个信息(待会会用到):
- API Key(类似 )
- 模型名称(如 )
- 端点 URL()
绝对不要 把密钥硬编码在代码里!用环境变量:
Windows(PowerShell):
Mac/Linux:
或者在项目根目录创建 文件(记得加到 ):
现在开始写代码。打开 ,替换成下面的代码:
你会看到类似这样的效果:
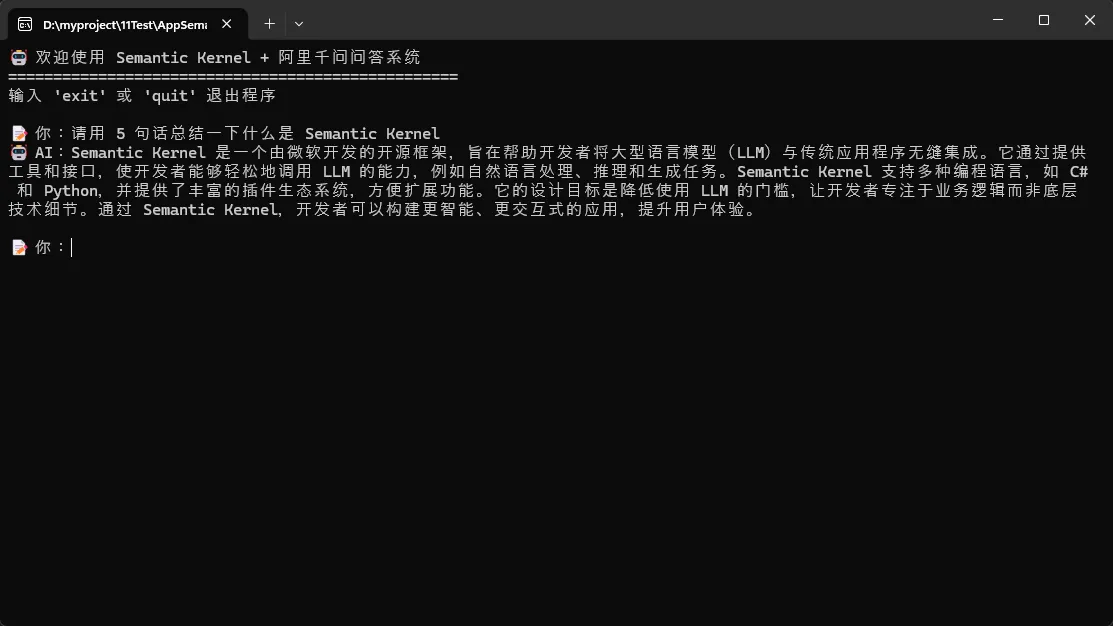
1️⃣ Kernel 初始化
关键理解:
- 是 SK 的核心容器,里面集成了 AI 模型和各种服务
- 虽然说"OpenAI",但其实是添加任何兼容 OpenAI 协议的模型
- 后,Kernel 就可以用了
想换模型?只需改 和 :
代码一行都不用改!这就是 Semantic Kernel 的魔力。
2️⃣ ChatHistory(聊天历史)
为什么需要这个?
试想一下,如果每次都只发最新的问题给 AI,AI 怎么知道之前说过什么?就像一个健忘症患者。ChatHistory 就是用来保存这个"记忆"的。
多轮对话时,整个历史会一起发给 AI:
3️⃣ 流式响应(Streaming)
这是什么黑魔法?
不用流式的做法:
- ⏳ 等待 AI 完全生成(可能 5-10 秒)
- 🤐 界面卡住,用户看不到任何反馈
- 😤 用户怀疑:这是卡了吧?
用流式响应:
- ⚡ AI 生成一个词就立刻显示一个词
- 👀 用户实时看到回答过程(就像 ChatGPT 那样)
- 😊 体验大幅提升
性能对比(基于千问 API 的实测):
现象:程序卡在某个地方,最后报
原因:
- 网络不稳定
- AI 服务器繁忙(特别是晚上高峰期)
- 没有设置超时时间
解决方案:
💡 **实践:
现象:不小心把密钥 push 到了 GitHub
如何规避:
一定要在 中添加:
现象:对话越来越慢,最后报错说 Token 超限
原因:每次调用都把整个历史发给 AI,历史越长越耗 Token
Token 成本计算:
- 阿里千问:¥0.0008/千个输入 Token + ¥0.002/千个输出 Token
- 一个 5 句话的对话 ≈ 200 Token
- 保留 100 条对话历史 = 20,000 Token ≈ ¥0.016(每次都这样浪费)
解决方案:
更好的做法(使用滑动窗口):
Temperature 控制 AI 的”创意程度”:
实战建议:
- 技术问题、代码生成 → 0.3
- 通用聊天 → 0.7
- 创意写作 → 0.9
系统 Prompt 决定了 AI 的”人设”:
为不同场景创建不同的 Prompt:
这是一个包含错误处理、日志、配置管理的完整版本,可以直接用于生产:
- Semantic Kernel 是多模型统一入口
一套代码,通过修改配置就能在 OpenAI、千问、Deepseek、本地 Ollama 之间无缝切换——这是传统 API 调用做不到的。
- 聊天历史管理是多轮对话的基础
不仅要保留历史以维持上下文,还要防止历史无限增长导致 Token 浪费。用滑动窗口是**实践。
- 流式响应完全改变用户体验
从"等待完成后一次显示"到"实时逐字显示",感受完全不同,技术成本却很低。
第一句:”Semantic Kernel 让你写一份代码,却能兼容全球主流大模型——这就是架构的力量。”
第二句:”不要等 AI 完全想好再回答,让用户看到 AI 在’思考’的过程——这就是流式响应的核心。”
第三句:”不是所有的对话历史都值得保留,及时删除过期记录既能省 Token,也能保持系统高效——这就是成熟系统的表现。”
- ✅ 完成本文的环境搭建和第一个应用
- 📖 阅读 Semantic Kernel 官方文档
- 🔨 尝试切换不同的 AI 模型
- 🔌 学习插件系统(让 AI 调用你的业务函数)
- 🗣️ 研究 Prompt Engineering(写出更好的提示词)
- 📊 集成向量数据库实现 RAG(检索增强生成)
- 🤖 构建 AI Agent(自主规划和执行任务)
- 🏗️ 设计企业级 AI 应用架构
- 🔐 处理安全性、合规性、成本控制
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/232705.html