
mHC: Manifold-Constrained Hyper-Connections我尝试着用让你爷爷奶奶都能理解的方式来描述mHC架构。
如果想理解mHC,先要知道HC(Hyper-Connections);如果想理解HC,先要知道Residuals(残差);要理解Residuals,先要知道深度神经元网络(Deep Neural Network)。
所以,有这样的一个认知递进:
Deep Neural Network -> Residuals -> HC -> mHC
好吧,还是有点复杂,可能你爷爷奶奶没兴趣听下去,但是你可以继续看下去,在本文结尾有直接给爷爷奶奶解释的版本。
这个太多介绍了,在这个问题中,只需要知道DNN是由很多层构成的,因为层数多,所以Deep,而且,每一层都以表示为一个函数

x是这一层的输入,y是这一层的输出。
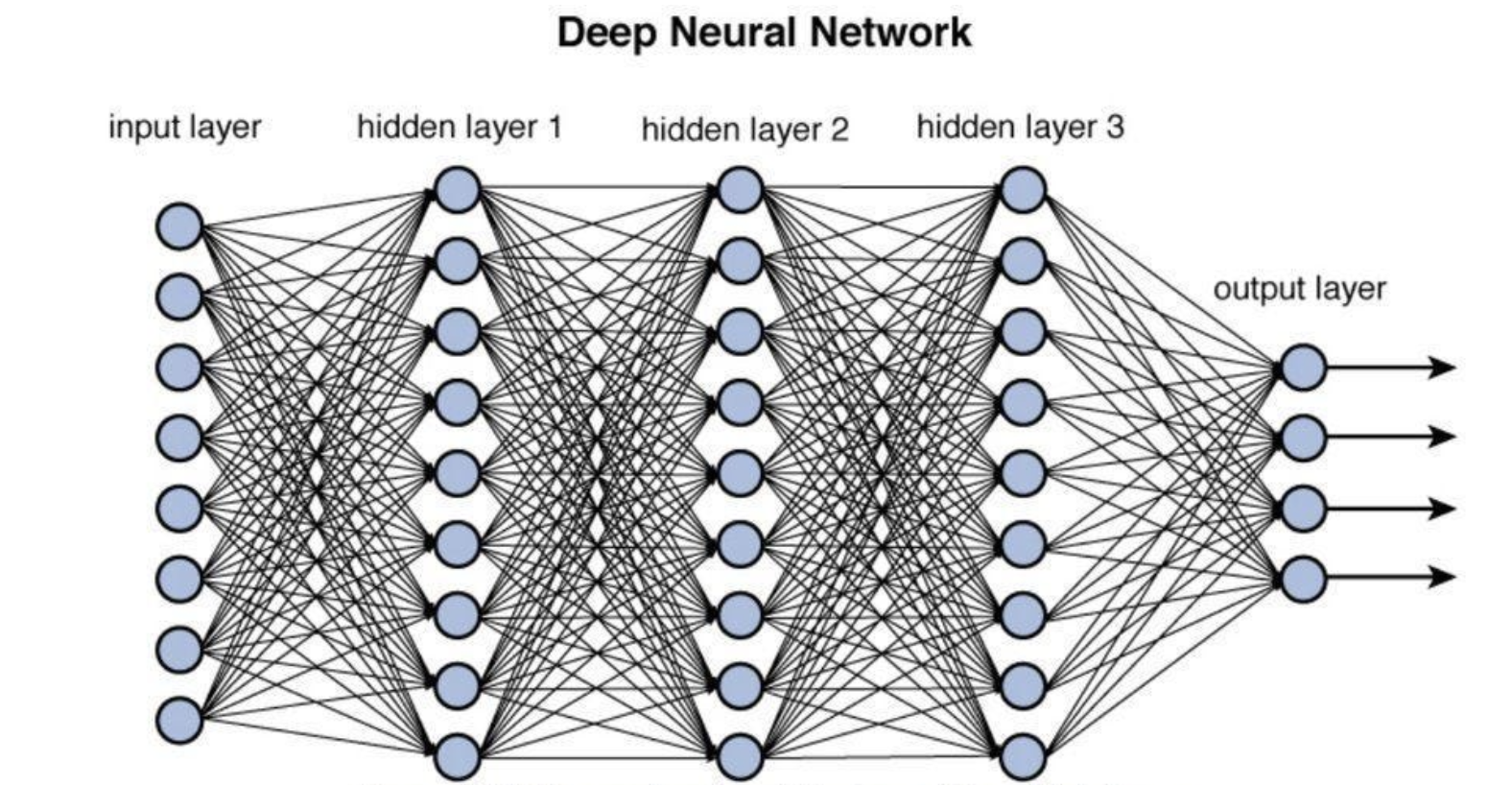
可以想想,当很多f函数叠加在一起,就可以表达复杂的函数关系,这也是DNN比较强大的原因。
但是,原本的输入,在每一层的传递过程中,特征会逐渐衰减,这给机器训练带来很大挑战。
打个比方:在一个大型公司里,CEO下达指令给CTO,CTO下达指令到VP,VP下达指令到Director,Director下达指令到Team Lead,Team Lead下达指令到基层组员,在这个指令传递链条中,原本CEO的想法会被模糊化,很容易被曲解,最后基层组员所理解的CEO最初想法可能大相径庭。
于是,有了——残差。
残差的概念是,把上面每一层的函数做一下修改,变成这样:
也就是,每一层给下一层的输出y,不只是这一层操作过的f(x),而且包含这一层的输入x。

还是拿大型公司打比方:
现在CEO给CTO下了指令,CTO在理解了CEO的指令之后,除了把自己的理解给下一层的VP,还把CEO原本的指令一起给了VP,这样VP不光拿到了CTO的指令,还有CEO原本的指令。
同样,CTO给VP下达指令的之后,VP不光给Director自己的理解,也把CTO给的指令传给VP
……
依次类推,VP、Director、Team Lead直到基层组员,不光能够直到上一层理解的指令,还知道上上一层的指令。
这样,每一层获得的信息更大,避免信息衰减,原本CEO的想法更保真地传递给基层。
在DeepSeek论文里的这张图,中间的部分就是HC,但这是简单起见只展示了一层HC的架构,实际上HC可以跨越多层。
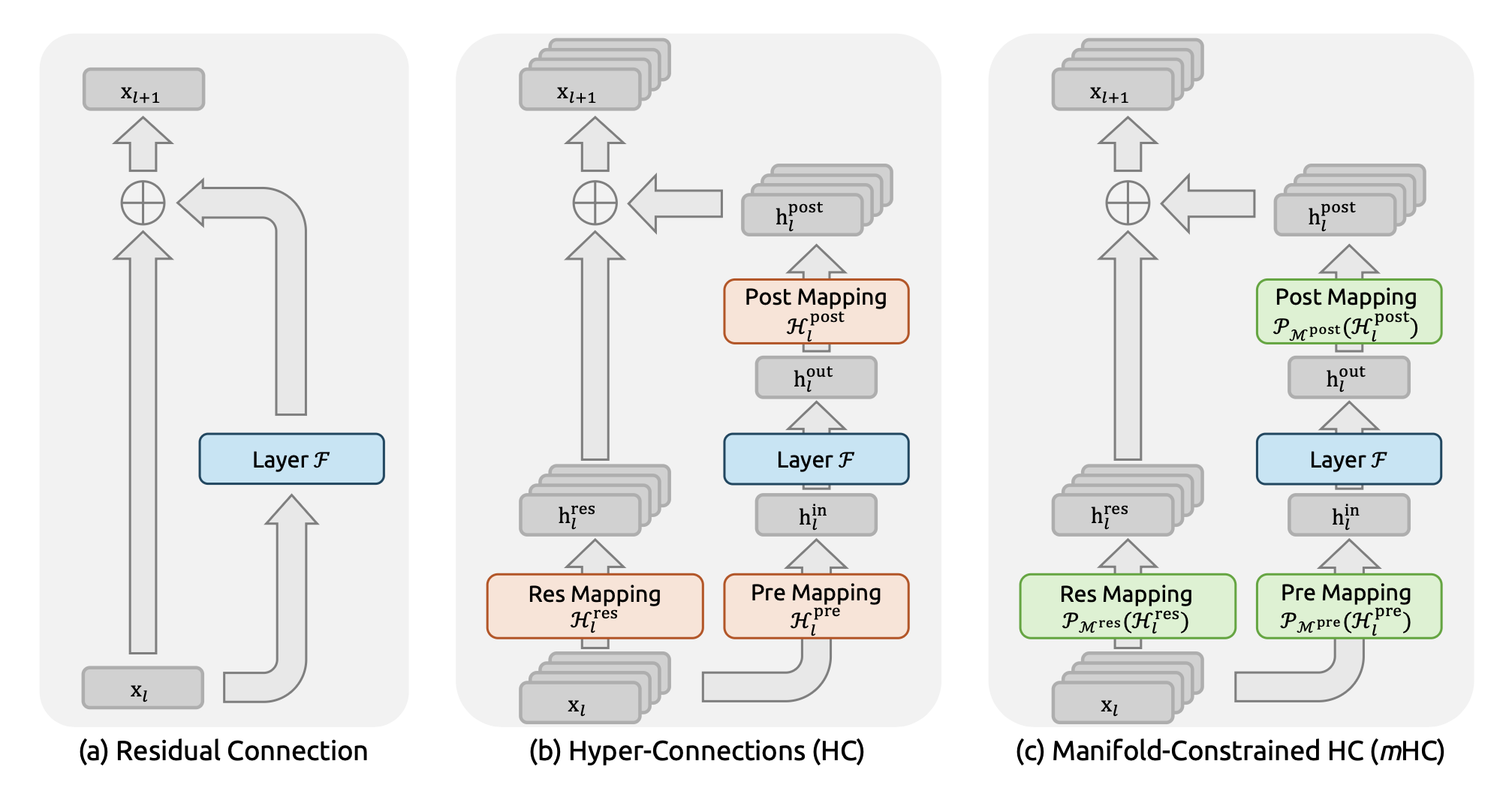
还是拿大型公司打比方:
为了进一步提高指令传递有效性,不只是越级传达,还可以有更多样的指令传递渠道。
比如,CEO传递给CTO的指令,CTO可以选择性传递,技术无关的信息,CTO就降低权重传递给下面的VP,和技术相关的信息,CTO就增加权重传递给VP。
CTO甚至还可以选择把重要指令直接越级传递给Director甚至Team Lead层,只要他觉得这非常重要。
毫无疑问,HC是Residuals的强化版,预期可以产生更保真的信息传递。
要理解mHC,先要理解什么是Manifold(流形)
Manifold是一个数学概念,用最简单的化描述就是:近看是N-1维的东西,实际是N维东西的投影,这就是N维流形。
举例来说,地图就是流形,因为地球实际上是圆的,地形也是有高低起伏的,是三维世界的东西,但是,看地球上的局部地区的时候,可以看成是二维的地图。
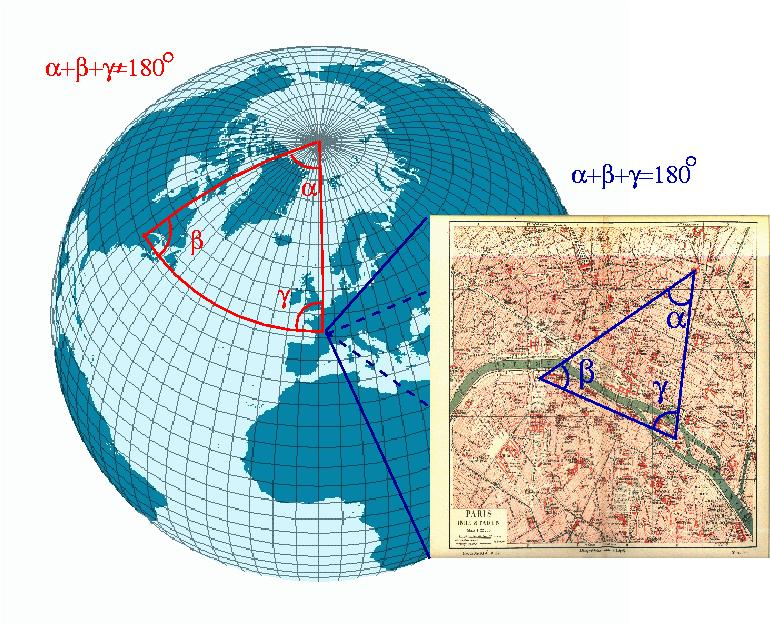
重点就是,虽然我以二维方式表达三维地球并不是全貌,但是看起来也能有我这个维度需要的所有信息,可以看得懂。
对于神经元网络中的数据空间,也存在这种N维数据可以在低维度看起来是连续平滑的流形。
我们再来看DeepSeek论文中的图,最右侧就是mHC,对比HC就很清楚了。
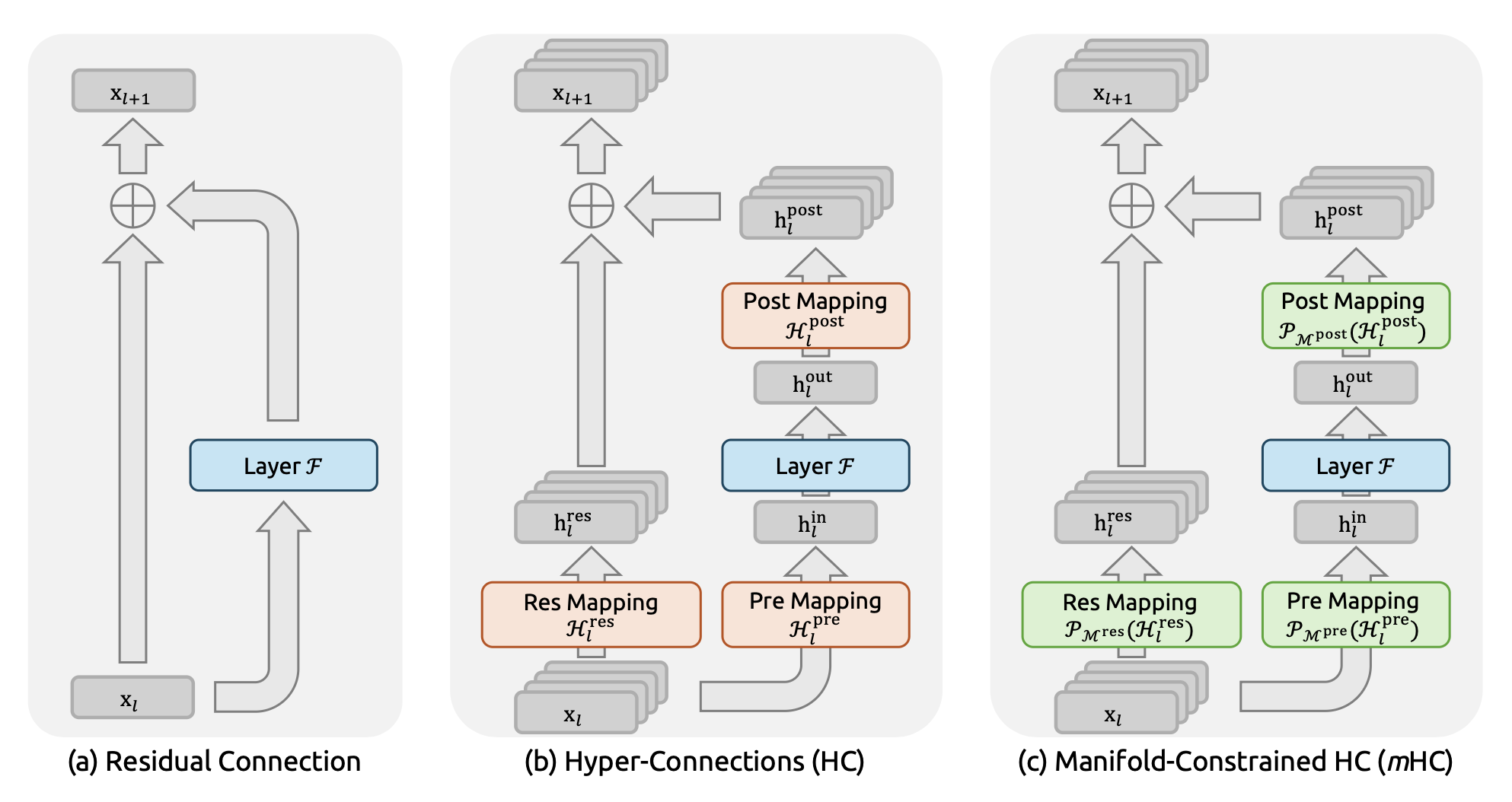
还是拿大型公司来打比方。
在HC状态下,层级之间的壁垒是被打破了,信息传递更加充分了,但是容易带来不稳定性。
设想一下,CEO直接给一个编程的基层组员下达指令,这个组员肯定会很疑惑,大家不在一个层面上啊,你CEO掌握的是公司方向,我基层程序员解决的是具体bug,换句话说,CEO的流形和基层组员的流形根本不搭。
mHC就是给HC施加一些约束,比如,CEO的KPI之一是『提高产品质量』,那这个流形基层程序员可以看懂,对应于『减少Bug』,可以看得懂;但是,CEO的另一个KPI是『扩大融资额』,这就和基层程序员的工作完全不相关,看不懂啊,就不要听CEO哔哔这些了。
CEO有自己的世界观和地图,但是这种流形如果无法被其他层理解,那就不要做为那一层的参考了,或者,要换成那一层能理解的样子,这样才有参考意义。
总之,mHC就是给HC一些约束,让多样的信息流动也有一些约束,避免不稳定性。
这次DeepSeek只是一篇论文,并没有对应的模型发布来验证这个想法,后续应该能看到产品发布,不过,这个『Deep Neural Network -> Residuals -> HC -> mHC』演化如此自然,感觉就是水到渠成。
值得一提,Residuals、HC和mHC全都由中国人贡献!
最后,给出你爷爷奶奶也能理解的mHC版本:
就像织毛衣一样,以前手工织毛衣只用一根线,效率不高。然后,我们发明一种机器,使用多股线一起编织(HC),这样效率就高多了,但是容易多根线头之间容易缠绕。现在用mHC方法,添加了一个智能理线器来防止线缠绕。这样一来,我们织出的毛衣更加结实耐用,而且更加美观。
你学会了吗?
打那么多字干嘛,你们写着不累,我看着都累,就简单说说吧。
首先说一下,这篇论文跟黎曼流形优化没关系,跟最优传输也没关系,没太多数学,放心看。
我们先从 ResNet 的残差开始说起,之前的结构是 ,这里给了一个 shortcut,直接将 传到下一层。
但是呢,这是单流结构,也就是只有一个 ,信息通道的带宽太窄,在大网络中就变成了瓶颈。
字节写了篇论文 HC,就是把单流变成 M 条流,之前的向量变成了矩阵:
但是问题也来了,当我们忽略残差时,第 L 层大约为
如果 H 的谱范数,也就是最大特征值不恒为 1,那么在多层累乘下,最终的 X 的谱范数会变得非常大或非常小,也就是梯度爆炸或梯度消失,导致训练不稳定。
所以正常人都会想到把 H 的谱范数设定为 1,这里就有很多种选择:
- 谱归一化,就是简单粗暴地除以最大奇异值,但这会导致某一条流极强,其他流被压制,看起来就不利于传输信息的样子
- 正交化,做一个 SVD,然后把奇异值都变成 1,这个看起来好像没问题, 而且你也可以宣称是Stiefel 流形,也是很唬人利于包装的名字,但缺点是很多 AI 小将可能不知道怎么写 SVD,而且 Householder 变换也慢,还是算了
- 双随机矩阵,用Sinkhorn 算法把原矩阵投影到双随机矩阵空间。这个好啊, Sinkhorn 就是矩阵乘法,迭代几次也收敛得快,那就是它了。
所谓投影,就是在双随机多面体中,寻找原矩阵KL散度最接近的矩阵。
所谓Sinkhorn 算法,就是一个交替投影算法,在行约束流形和列约束流形之间交替进行 KL 投影,最终收敛到它们的交集,也就是双随机流形上。
但最后写论文了,如果说我的贡献就是把一个矩阵行归一化再列归一化,那肯定不好看,那就包装一下:
- 双随机矩阵不fancy,改成Birkhoff Polytope
- 谱范数约束不fancy,改成流形约束
- 交替投影算法不fancy,改成Sinkhorn 算法
这下终于 fancy 了,意满离。
最后叠甲,论文是好论文,包装也是学术圈惯例,但别过度神话 DS,正常讨论就好。
DeepSeek 这群人是真的闲不住啊。
残差连接,这个从 2015 年 ResNet 开始统治深度学习界的基础范式,十年了,就没人敢动它。结果 DeepSeek 直接上手了——基于字节跳动 2024 年提出的 Hyper-Connections (HC) 思路,搞出了一个“流形约束版” mHC。
不得不说,这波操作属实有点猛。
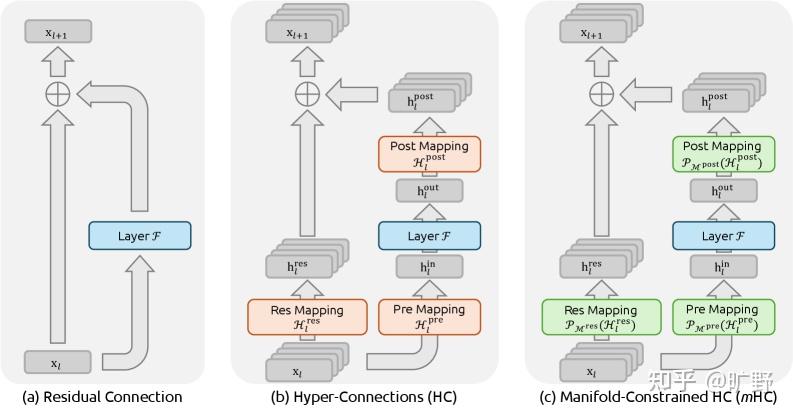
在聊mHC之前得先理解HC到底解决了什么问题,又制造了什么新问题。
传统的残差连接,公式大家都熟悉得不能再熟悉了:
就这么个简单的东西,支撑了Transformer这十年的繁荣。为什么?因为恒等映射这个性质实在太好了——信号从浅层直接传到深层,不修改、不衰减、不放大。梯度反传的时候也是如此。
但HC觉得 你这残差流太窄了,我给你扩展成n条流,再用可学习的矩阵去mix它们。
这想法确实很好。你想啊,原来的残差连接就是个 1×1 的“矩阵”,其实就是个标量 1,现在变成 n×n 的可学习矩阵,拓扑复杂度一下子就上去了。而且关键是——不增加 FLOPs,只是多了点小矩阵运算。
HC在小规模实验上效果确实不错。但随之而来的也有问题:
规模一上去就炸了。
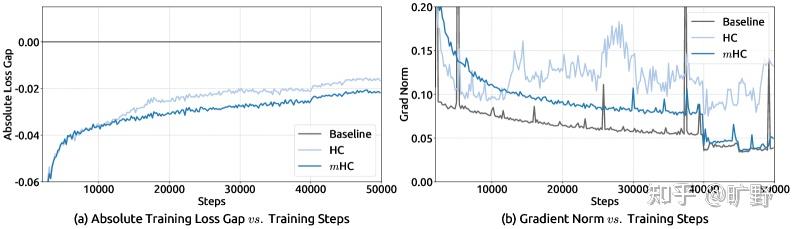
论文里有个很有意思的图(Figure 2),27B 模型训练到 12k step 左右,HC 的 loss 突然飙升。与此同时,梯度范数也开始疯狂震荡。
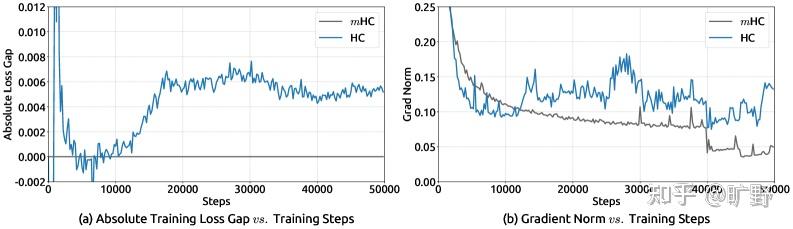
为什么会这样?原因其实不难理解。
当你把单层的残差映射矩阵 连续相乘 L 层之后:
由于这些矩阵是unconstrained的,这个复合映射可以往任意方向发散。论文测量了一个叫 “Amax Gain Magnitude” 的指标——这个值在 HC 里飙到了 3000。
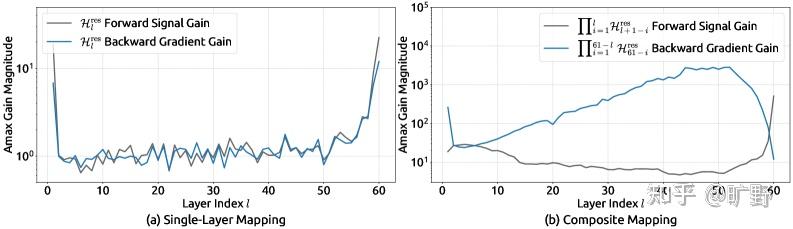
这个信号在残差流里被放大了 3000 倍。在大规模训练中,这就是爆炸的前奏。
好,问题搞清楚了。现在 DeepSeek 的解法来了。
mHC 的核心思想给个省流版就是:
把残差矩阵 约束在双随机矩阵构成的流形上。
等等,什么是双随机矩阵?
简单点看就是一个”特别均匀”的矩阵——所有元素都是非负的,而且每一行加起来等于 1,每一列加起来也等于 1。
比如一个 3×3 的双随机矩阵,它可能长这样:

这个矩阵每一行相加都是 1,每一列相加也都是 1。这种矩阵有一种天然的”能量守恒”特性——它不会凭空放大或缩小信号。
而DeepSeek的这个选择,简直是神来之笔。
具体来看看双随机矩阵的一些性质,你就能明白Deepseek这样选择的深意。
先说谱范数的事儿。 双随机矩阵有个非常好的性质——它的谱范数,你可以理解为”最大放大倍数”,恒定小于等于 1。这个性质就是说不管你的信号怎么过这个矩阵,它最多保持原样,绝对不会被放大。还记得前面说的 HC 那个 3000 倍放大的灾难吗?双随机矩阵从根本上就杜绝了这种可能。
再说复合封闭性。 这个性质更妙——两个双随机矩阵乘起来,得到的还是双随机矩阵。这有点像说“龙生龙,凤生凤,老鼠的儿子会打洞”——不管你网络堆多少层,只要每一层的残差矩阵都是双随机的,那整个复合映射 依然保持双随机的性质。所以说稳定性不是靠运气,而是有数学上的铁保证。
最后还有关于它的几何意义。 这里要提一个概念叫 Birkhoff多面体。所有双随机矩阵构成的集合,在几何上形成了一个凸多面体,而这个多面体的顶点恰好就是所有的置换矩阵(0-1 矩阵,每行每列有且仅有一个 1)。也就是说任何一个双随机矩阵,都可以看作是若干个”纯粹的重新排列”的加权平均。
什么意思呢?如果ResNet的恒等映射像是”原封不动地传递信息”。那双随机矩阵做的事情,就像是在说:”我不只是原封不动,我允许把特征稍微重新洗一洗、混一混,但我保证这种混合是可控的、能量守恒的。”
这就形成了一种漂亮的泛化关系,
当残差流宽度 n=1 时,双随机约束退化成标量 1,也就是回到了最原始的恒等映射。mHC 并没有抛弃 ResNet,而是把它包进了一个更大的框架里。
这个约束选得太精妙了……
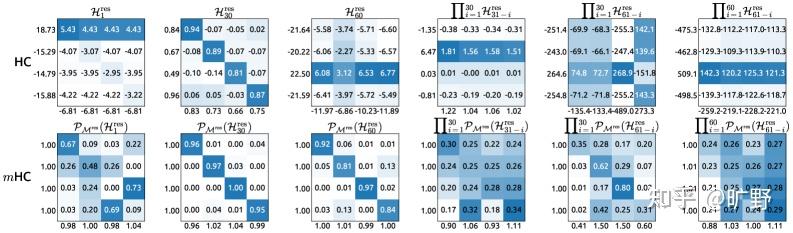
理论上的说完了,怎么保证训练过程中,矩阵始终落在双随机流形上?
这就涉及到一个经典的算法:Sinkhorn-Knopp 迭代。
算法的思路也很简单,有点像”打乒乓球”。比如你有一个普通的矩阵,想把它变成双随机矩阵,那就这么干:
- 先把每一行做归一化(让行和变成 1)
- 再把每一列做归一化(让列和变成 1)
- 但这时候行和又不是 1 了… 没关系,再归一化一次
- 如此反复,来来回回地”打”
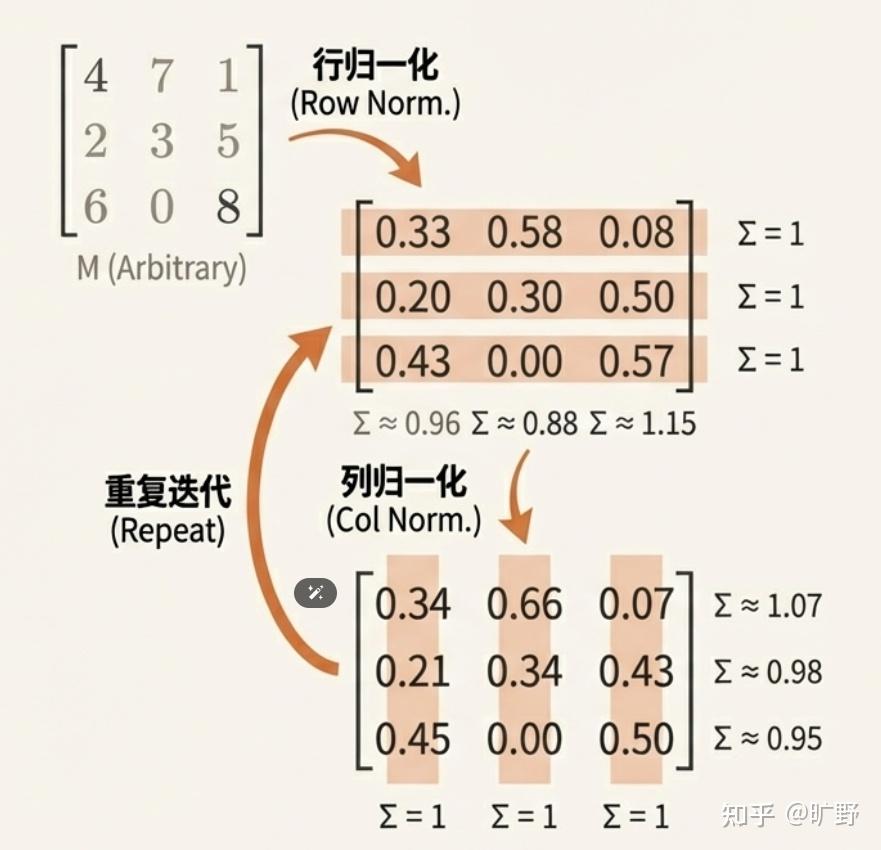
神奇的是,这个过程会收敛。理论上需要无穷多次迭代,但实践中 20 次左右就足够接近双随机矩阵了。写成公式的话:
其中 是行归一化, 是列归一化。就这么简单。
但有个细节很重要,双随机矩阵要求所有元素非负,那原始矩阵如果有负数怎么办?DeepSeek 的做法是在迭代之前,先对矩阵元素取指数—— 永远是正数,问题解决。
这个算法有几个天然的好处,让它非常适合深度学习。它完全可微分,所以梯度能直接反传回去,不需要任何特殊处理;每次迭代就是矩阵运算,并行度极高,GPU跑起来好;收敛还很快,20 次迭代在现代硬件上几乎可以忽略不计。
DeepSeek 在工程实现上更进一步,他们把整个 Sinkhorn 迭代塞进一个 CUDA kernel 里,反向传播的时候不存中间结果,直接在 on-chip memory 里重算。这样既省了 HBM 带宽,又避免了显存占用。
但他们对于输入输出映射 和 ,mHC 没上双随机,只做了简单的非负约束(用 Sigmoid)。因为这俩是 1×n 的向量,根本不是方阵,没办法做”行列和都等于 1”的约束。用 Sigmoid 保证非负,已经足够防止正负系数互相抵消导致的信号衰减了。
该精细的地方精细,该简化的地方简化。这种取舍拿捏得恰到好处。
说完算法,就来到了工程层面。一个好想法如果没有高效的实现,就等于没有。
HC当初没能大规模推广,除了训练不稳定之外,还有一个问题就是太慢了。
传统的残差连接,每一层只需要读写 O© 个元素(C 是通道数)。但 HC 把残差流宽度扩展了 n 倍,I/O 成本直接涨到 O(nC)。问题是在GPU里计算往往不是瓶颈,内存带宽才是。这额外的 I/O 开销,在大规模训练中会像滚雪球一样放大。
那mHC是怎么解决这个问题的?
他们在Kernel Fusion上下了大功夫。把原本分散的多个小操作合并成一个大 kernel,这样数据只需要从 HBM 读一次、写一次,中间的所有计算都在 on-chip memory 里完成。他们用 TileLang 实现了混合精度的融合 kernel(bfloat16 计算 + float32 累加),还把 RMSNorm 里的除法挪到矩阵乘之后执行——数学上完全等价,但省了一次除法的内存往返。这种操作,真的能看出对硬件的绝对理解。
另一个核心优化是选择性重计算。这听起来有点反直觉:为什么要”重新算”?直接存下来不好吗?
问题在于存中间结果要占显存。在大规模训练中,显存往往是最紧张的资源——它直接决定了你能跑多大的 batch size。mHC那些小矩阵操作,像几十乘几十的矩阵乘法这种,算得飞快,重算的代价很低。但如果把这些中间结果都存下来,占用的显存却不少。
“空间换时间”还是”时间换空间”?mHC 选择了后者,用微量的重计算开销,换来更大的 batch 和更高的吞吐。
他们甚至推导出了最优的重计算块大小:
这个公式就是在说应该把多少层打包成一个重计算单元,才能在时间和空间之间取得最优平衡。简洁,优雅,有理论支撑。
最后是大规模分布式训练的适配。DeepSeek-V3 引入了一种叫DualPipe的流水线并行策略,而 mHC 需要和这套系统无缝协作。他们做了不少针对性优化:把关键的 kernel 放到专用的高优先级 CUDA stream 上,确保它能及时完成不拖后腿;Attention 部分特意不用 persistent kernel,这样当 mHC 操作需要 GPU 资源时可以随时抢占;重计算逻辑和流水线通信完全解耦,互不干扰。

最终效果那就是惊人的n=4 的 mHC 只增加 6.7% 的训练时间开销。

6.7%,考虑到 mHC 带来的性能提升和训练稳定性改善,这点代价简直可以忽略不计。如果有人告诉你,多花 6.7% 的训练时间,就能让你的 27B 模型在 BBH 上涨 7 个多点、在 GSM8K 上涨 7 个点,你干不干?
这笔账,怎么算都是血赚。
27B 模型的实验结果,说实话有点夸张:
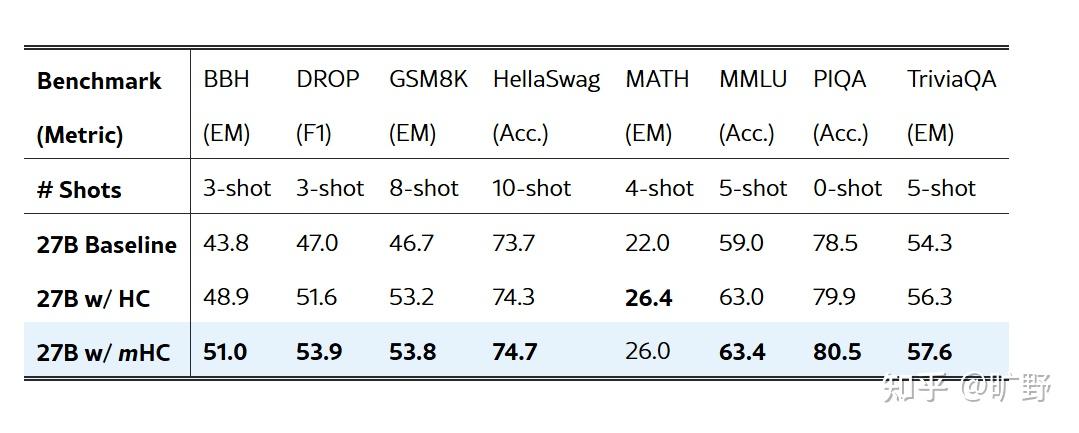
8 个 benchmark,mHC 全面超越 baseline,在大多数任务上也超过了不稳定的 HC。
BBH 相对 baseline提升 7.2 个点,这个幅度在 27B 规模上已经非常可观了。要知道这只是通过改残差连接的拓扑结构实现的,没加参数、没加数据、没改训练流程。
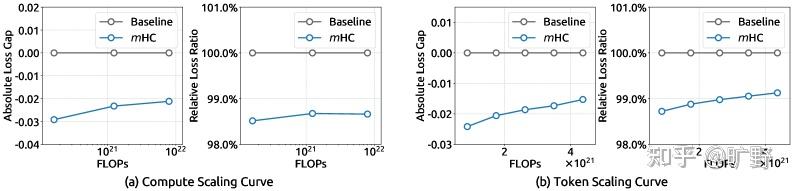
更重要的是稳定性。mHC 的 loss 曲线平滑得像 baseline 一样,梯度范数也很稳定。而 HC 在 12k step 附近那个 loss spike… 在大规模训练中这种抖动是要人命的。Scaling实验也很漂亮。从 3B 到 9B 到 27B,mHC 相对 baseline 的优势始终保持。这说明这不是小模型上的 overfitting,而是真正的架构改进。
跳出论文本身,
残差连接这个古董还有多少可挖的空间?
在 mHC 之前,我一直觉得残差连接已经是个“已解决”的问题了。He Kaiming那篇Identity Mappings in Deep Residual Networks 把道理讲得透透的,后人只需要照抄就完事。
但 mHC又告诉我们,即使是看似最基础、最“完美”的设计,也存在泛化的空间。关键是要找到正确的约束——既能拓展表达能力,又能保持原有的好性质。
双随机矩阵这个选择,就是在“自由度”和“稳定性”之间找到了一个甜点。属于一种四两拨千斤的操作,很厉害。
DeepSeek 的工程能力也是越来越恐怖了。
从 V2 的 MLA 到 V3 的 DualPipe,再到现在 mHC 的 kernel 优化,DeepSeek 展现出来的系统工程能力是国内甚至国际顶尖的。算法创新当然重要,但把算法创新高效落地的能力同样关键。很多学术界的好想法最后没能普及,往往就是因为 overhead 太大。mHC 把额外开销控制在 6.7%,这是真正的工程功底。
现在的AI不是“有个好 idea 就能发顶会”的时代了。 你得能训、能量化、能部署。不然你的创新就只能躺在论文里积灰。DeepSeek 这帮人显然深谙此道。
还有就是Macro Design可能是下一个金矿。
这几年大家都在卷Attention变种(MQA、GQA、MLA)和 FFN 结构(MoE、GLU)。这些属于 Micro Design——相当于在打磨每一块砖的质地。
但 Macro Design——也就是层与层之间怎么连接、信息怎么流动——相对被忽视了。这相当于建筑的框架结构。可也许我们一直在用最先进的砖,盖着最传统的房子。DenseNet 当年提出 dense connection,但因为内存开销太大被放弃了。现在硬件变强了,工程技术也进步了,也许是时候重新审视这个方向了。
那些理所当然的默认选项,可能往往就是最大的突破口。 残差连接如此,LayerNorm 如此,Softmax 可能也是如此。
DeepSeek 这帮人是真卷啊。残差连接都被他们玩出花来了,下一个是啥?LayerNorm?Softmax?
我拭目以待。
如果觉得文章对你有帮助,欢迎点赞关注一波~
我是旷野,带你探索无尽技术!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/232003.html