
或者
最简单的方案!!!
删除anaconda中之前装的shaply(文件夹和程序都删掉),重新安装,
参考:anaconda3+ paddleOCR安装使用
本机上,使用了anaconda默认环境,各种版本如下:
- python 3.7.6
- paddleocr 使用pip安装后看到的版本是:
requirments文件中的内容:
根据paddleocr的FAQ文档
Q3.4.23:安装paddleocr后,提示没有paddle
A:这是因为paddlepaddle gpu版本和版本的名称不一致,现在已经在whl的文档里做了安装说明。
所以还是老老实实安装上paddle吧
改改路径就好了。
其中有一点需要注意:
参考另一个文章:python opencv调用摄像头识别并绘制结果
发现一个神奇的事情,当你插着usb摄像头启动电脑时,,usb摄像头的序号就是0;当启动电脑之后再插上usb摄像头,usb摄像头的序号就是2(我的电脑是一个前置+一个后置摄像头)
关于摄像头参数的调节,可以参考另一篇文章:Opencv摄像头相关参数
由于使用了摄像头读取图像,图片背景比较杂,对检测有难度,发现使用DB效果不是很好。(由于还没怎么研究过检测模型,所以很难判断问题到底出在哪里)
2.3.1 换个模型
EAST高效,准确,但对弯曲文本检测较差。
在文件中看到:
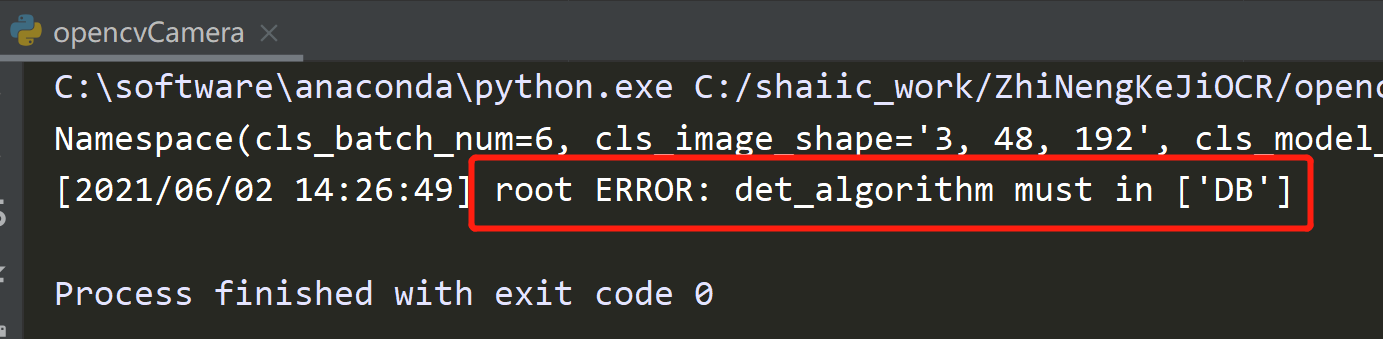
然后看到代码中有:
2.3.2 限定检测位置
设置一个按键,opencv摄像头有键盘响应,可以有相应的操作,参考:cv2.VideoCapture.get、set详解可以获取相机参数。
另外,参考:opencv python全屏显示、置窗口大小和位置
参考:python cv2图片剪裁



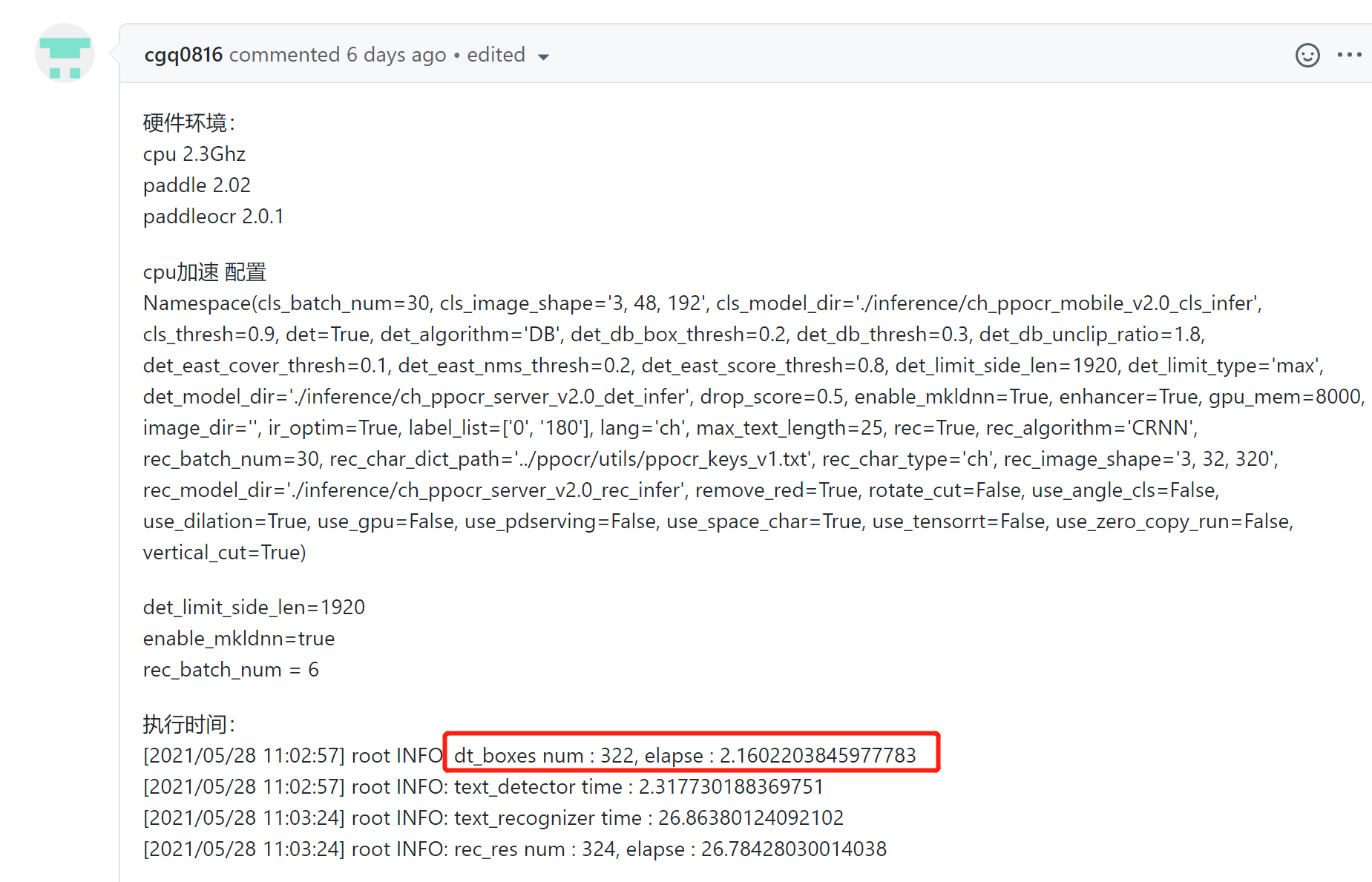
检测时间比较久,检测+识别的时间差不多是0.7~1.2s,在cpu机器上,其实比较尴尬。
先查看一下模型的size,运行检测的时候会打印出模型的配置信息,可以从这里看到
所以这个默认的模型目测已经是剪枝过的了。
识别模型是自己训练之后转为推理模型的,有,确实对于比较简单的一块数字仪表识别很重。
可知:
不使用mkldnn加速的情况下,使用+速度基本在0.7~1.2s
不使用mkldnn加速的情况下,使用+速度基本在0.7~0.9s
所以虽然识别时间本来就不到0.2s,但是可以变得更快,这样就只剩检测时间了。
个人猜测,是不是第一阶段检测模型是剪枝后的,比如是8位精度,第二阶段识别模型也是8位精度,这样系统处理是一致的。
如果两个阶段数据精度不一样,系统处理的时候不一致,是不是也会造成数据差异。
直接去FAQ文档中搜索,可以看到以下结果.
Q3.1.73: 如何使用TensorRT加速PaddleOCR预测?
A: 目前paddle的dygraph分支已经支持了python和C++ TensorRT预测的代码,python端inference预测时把参数–use_tensorrt=True即可, C++TensorRT预测需要使用支持TRT的预测库并在编译时打开-DWITH_TENSORRT=ON。 如果想修改其他分支代码支持TensorRT预测,可以参考PR。
注:建议使用TensorRT大于等于6.1.0.5以上的版本。
另外,搜索,可以看到:
Q3.4.40: 使用hub_serving部署,延时较高,可能的原因是什么呀?
A: 首先,测试的时候第一张图延时较高,可以多测试几张然后观察后几张图的速度;其次,如果是在cpu端部署serving端模型(如backbone为ResNet34),耗时较慢,建议在cpu端部署mobile(如backbone为MobileNetV3)模型。
这里建议在cpu端部署mobile模型
也可以只看预测部署部分,还可以看到以下比较有用的信息:
Q3.4.1:如何pip安装opt模型转换工具?
A:由于OCR端侧部署需要某些算子的支持,这些算子仅在Paddle-Lite 最新develop分支中,所以需要自己编译opt模型转换工具。opt工具可以通过编译PaddleLite获得,编译步骤参考lite部署文档 中2.1 模型优化部分。
🍱Q3.4.2:如何将PaddleOCR预测模型封装成SDK
A:如果是Python的话,可以使用tools/infer/predict_system.py中的TextSystem进行sdk封装,如果是c++的话,可以使用deploy/cpp_infer/src下面的DBDetector和CRNNRecognizer完成封装
3.2.1 CPU下使用mkldnn加速
由于慢的地方主要是检测,所以即便对剪枝进行优化也不是很有效,所以这里先尝试使用mkldnn来进行加速。
Q3.1.77: 使用mkldnn加速预测时遇到 ‘Please compile with MKLDNN first to use MKLDNN’
A: 报错提示当前环境没有mkldnn,建议检查下当前CPU是否支持mlkdnn(MAC上是无法用mkldnn);另外的可能是使用的预测库不支持mkldnn, 建议从这里下载支持mlkdnn的CPU预测库。
Q1.1.10:PaddleOCR中,对于模型预测加速,CPU加速的途径有哪些?基于TenorRT加速GPU对输入有什么要求?
A:(1)CPU可以使用mkldnn进行加速;对于python inference的话,可以把enable_mkldnn改为true,参考代码,对于cpp inference的话,在配置文件里面配置use_mkldnn 1即可,参考代码
(2)GPU需要注意变长输入问题等,TRT6 之后才支持变长输入
3.2.2 修改参数
想起来还有一些参数可以考虑修改,比如:
根据FAQ文档
Q3.3.2:配置文件里面检测的阈值设置么?
A:有的,检测相关的参数主要有以下几个:
det_limit_side_len:预测时图像resize的长边尺寸
det_db_thresh: 用于二值化输出图的阈值
det_db_box_thresh:用于过滤文本框的阈值,低于此阈值的文本框不要
det_db_unclip_ratio: 文本框扩张的系数,关系到文本框的大小
这些参数的默认值见代码,可以通过从命令行传递参数进行修改。
3.2.3 内存泄露
根据FAQ文档,
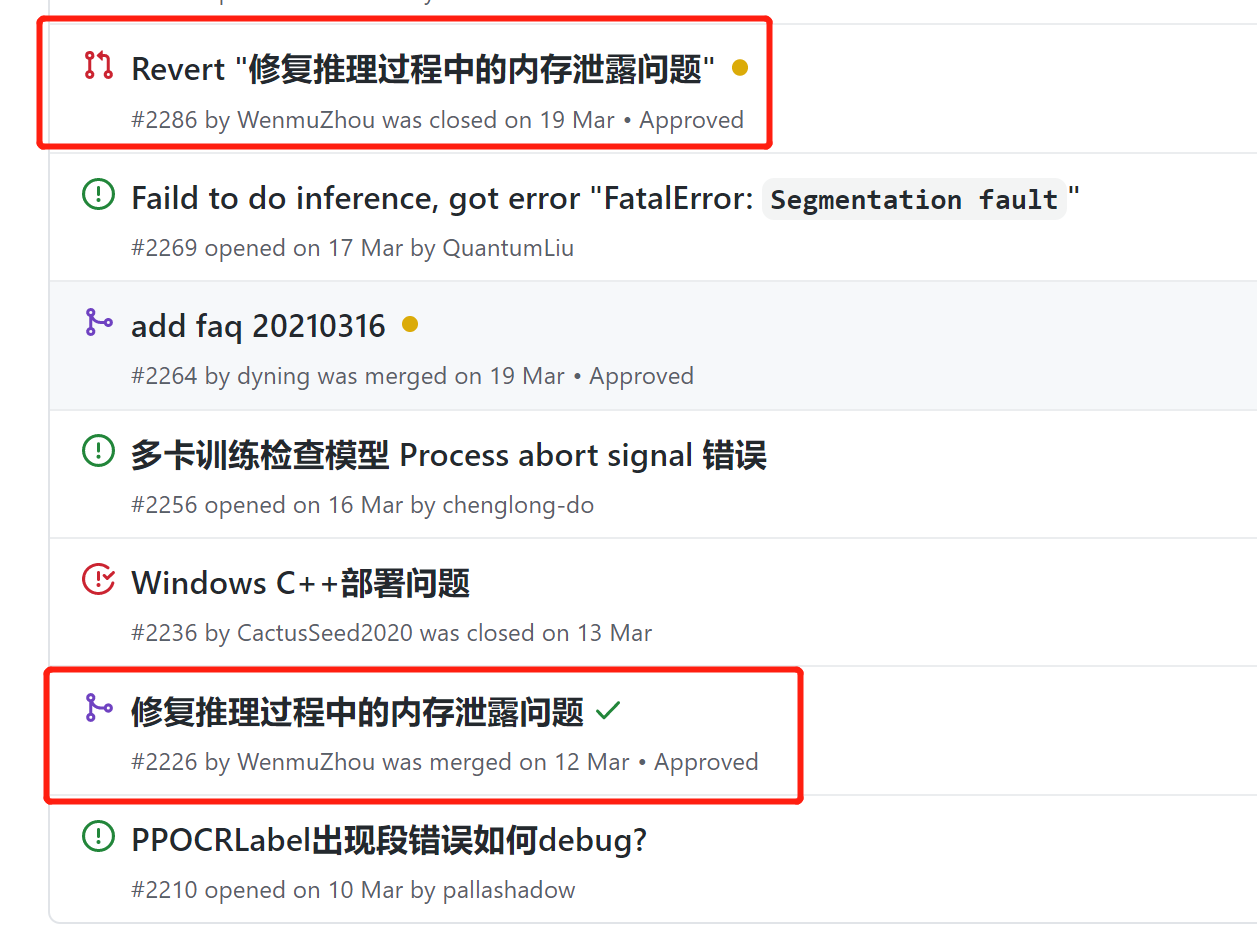
Q3.4.43: 预测时显存爆炸、内存泄漏问题?
A: 打开显存/内存优化开关enable_memory_optim可以解决该问题,相关代码已合入,查看详情。

改了之后,内存依然占用量很高,而且推理速度还变慢了。。。。都超过1s了,但是效果好像好了一些,连一些虚的都变好了。换成自带的识别模型之后,也比之前时间长了,无语。
但是更新到2.1之后,打开mkldnn,速度变快了,基本控制在0.3-0.5s。。。但是内存占用是100%基本上。



加速之后,超级快,但是内存占用非常高。
3.2.4 内存泄漏的问题记录
发现paddle的issue中有很多说速度很慢的:
- 使用CPU下进行加速处理,但是识别的速度将近30S,请问有什么方法提高嘛? #2950
这个用的是服务器端的模型,看到了server

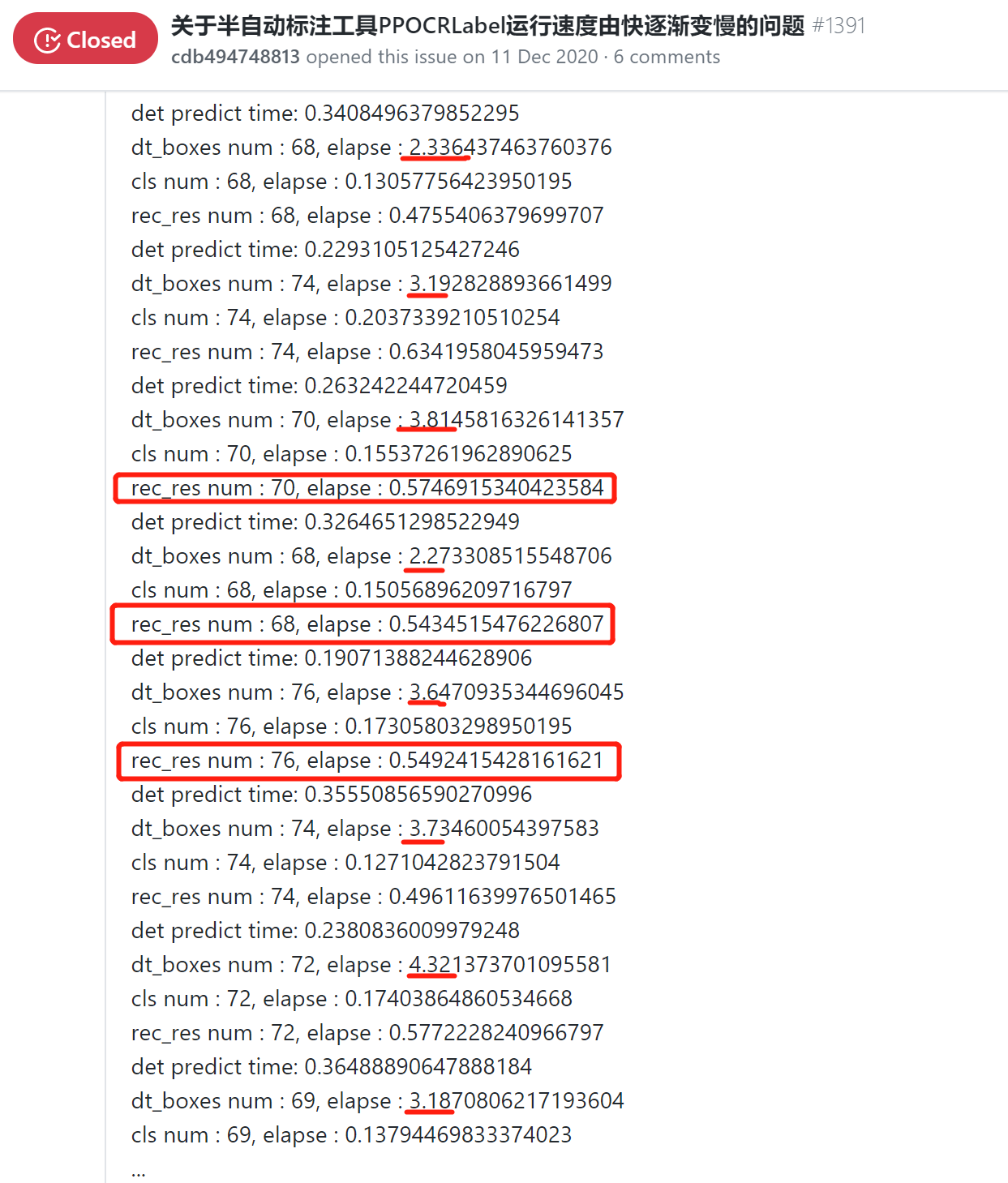
还有关于PPOCRLabel也是自动标记过程中由快到慢: - 关于半自动标注工具PPOCRLabel运行速度由快逐渐变慢的问题 #1391
- 类似的也有:PPOCRLabel自动标注跑着跑着就自己闪退了 #2724
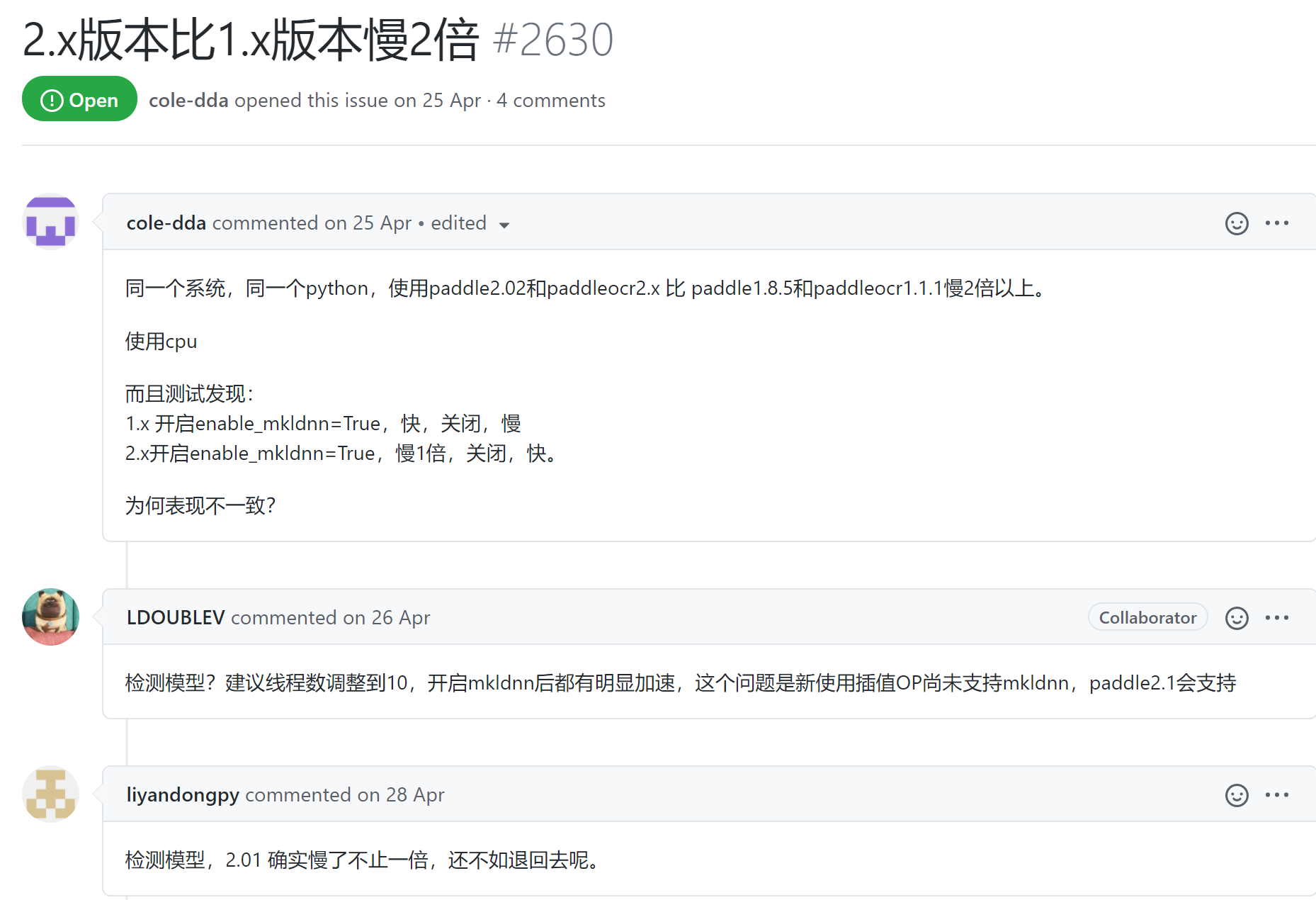
- 有说版本变慢的:2.x版本比1.x版本慢2倍 #2630
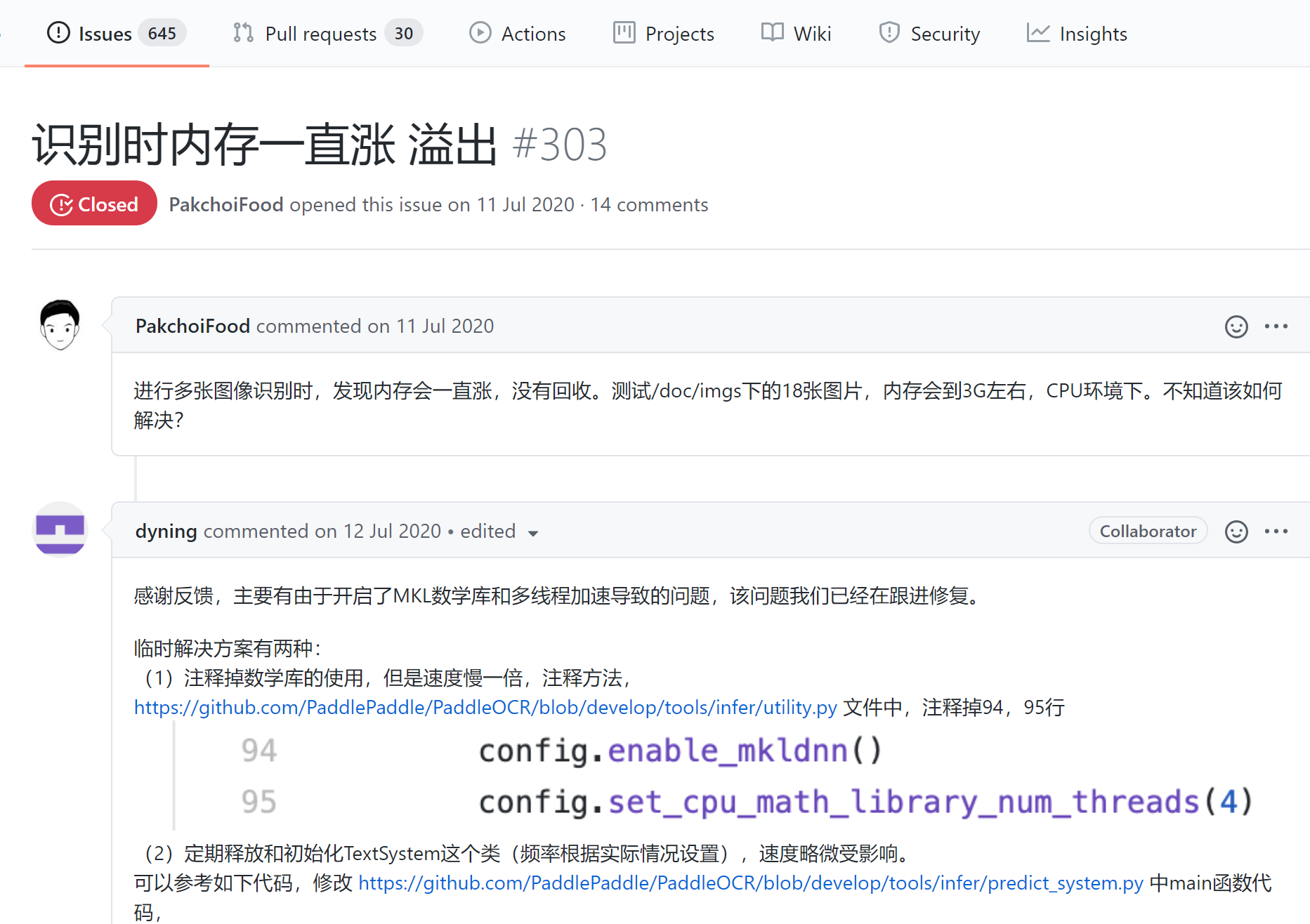
- 还有识别时内存一直涨 溢出 #303
虽然这个issue关闭了,但是下面还是有人再报错。。。
在上面下载支持mlkdnn的CPU预测库的时候,看到了一个很有用的说明文档:https://paddle-inference.readthedocs.io/en/latest/index.html,就是针对paddle系列的推理模型的。
模型量化(主要就是剪枝)——X86 CPU 上部署量化模型
大概介绍一下,搬运
一开始其实不太想用剪枝的,因为慢的原因主要在于检测,但是检测的模型已经是剪枝后的了,在比较过全都使用默认的剪枝模型(检测+识别),和使用默认的检测+自己的识别模型之后,发现其实还是有些效果的。
但是相比于剪枝的代价,并不值得。
3.3 更换模型
3.4 多进程
FAQ-如何多进程运行paddleocr?
Q3.4.33: 如何多进程运行paddleocr?
A:实例化多个paddleocr服务,然后将服务注册到注册中心,之后通过注册中心统一调度即可,关于注册中心,可以搜索eureka了解一下具体使用,其他的注册中心也行。
Q3.4.44: 如何多进程预测
A: 近期PaddleOCR新增了多进程预测控制参数,use_mp表示是否使用多进程,total_process_num表示在使用多进程时的进程数。具体使用方式请参考文档。
看了一下,其实这个文件https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.1/paddleocr.py
和另一个PaddleOCR/tools/infer/utility.py文件内容很像,
wheel包里的那个其实就是这个文件的一部分内容的简化,方便调用而已。
查看自己电脑核数
win10系统如何查看cpu核数
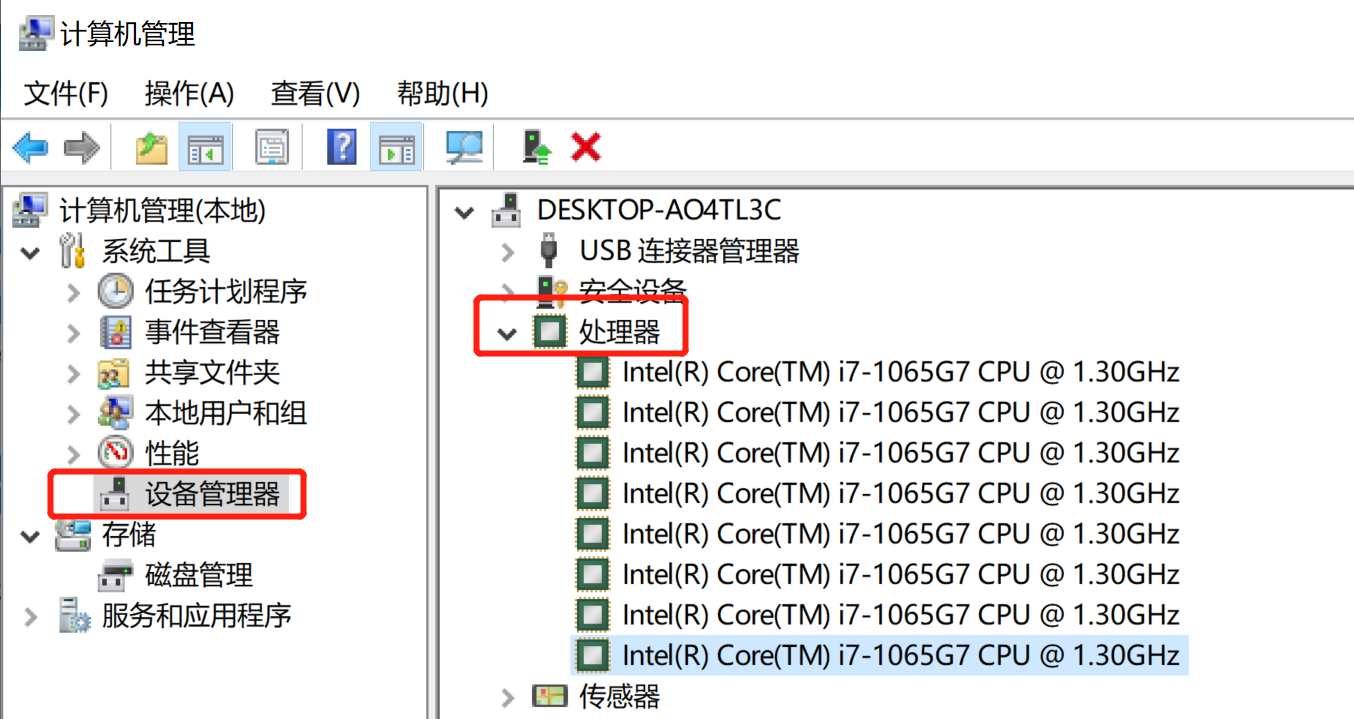
所以我这个电脑是8核。
3.5.1 paddle绑定cpu问题
其实文件中,有一段代码,找到自己本机安装paddleocr的地方,,133行左右
根据文档Docs » Python API 文档 » Config 类 » 3. 使用 CPU 进行预测说明,
在 CPU 可用核心数足够时,可以通过设置 set_cpu_math_library_num_threads 将线程数调高一些,默认线程数为 1
所以如果想要限制这个使用cpu的核数量,可以设置代码中
另外,由于启用了,还是根据上面那个文档:
最后将cpu个数从6变成4,mkldnn从10变成5,需要重启电脑才生效,使用函数重新加载库似乎没什么用,关掉pycharm重新启动pycharm也没啥用。
但是检测速度又降低了。
而且重启电脑之后,第一次是控制在了50%左右,但是第二次再去进行的时候就不行了。
from:https://blog.csdn.net/Castlehe/article/details/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/231525.html