
这个智能体榜单叫MLE-Bench,是OpenAI研究团队发布的评测AI Agent机器学习工程能力的基准框架,MLE就是Machine Learning Engineering的缩写,能上这个基准的榜单是很有难度的,因为它评测的不是单纯Coding能力,而是解决具体机器学习任务的能力。
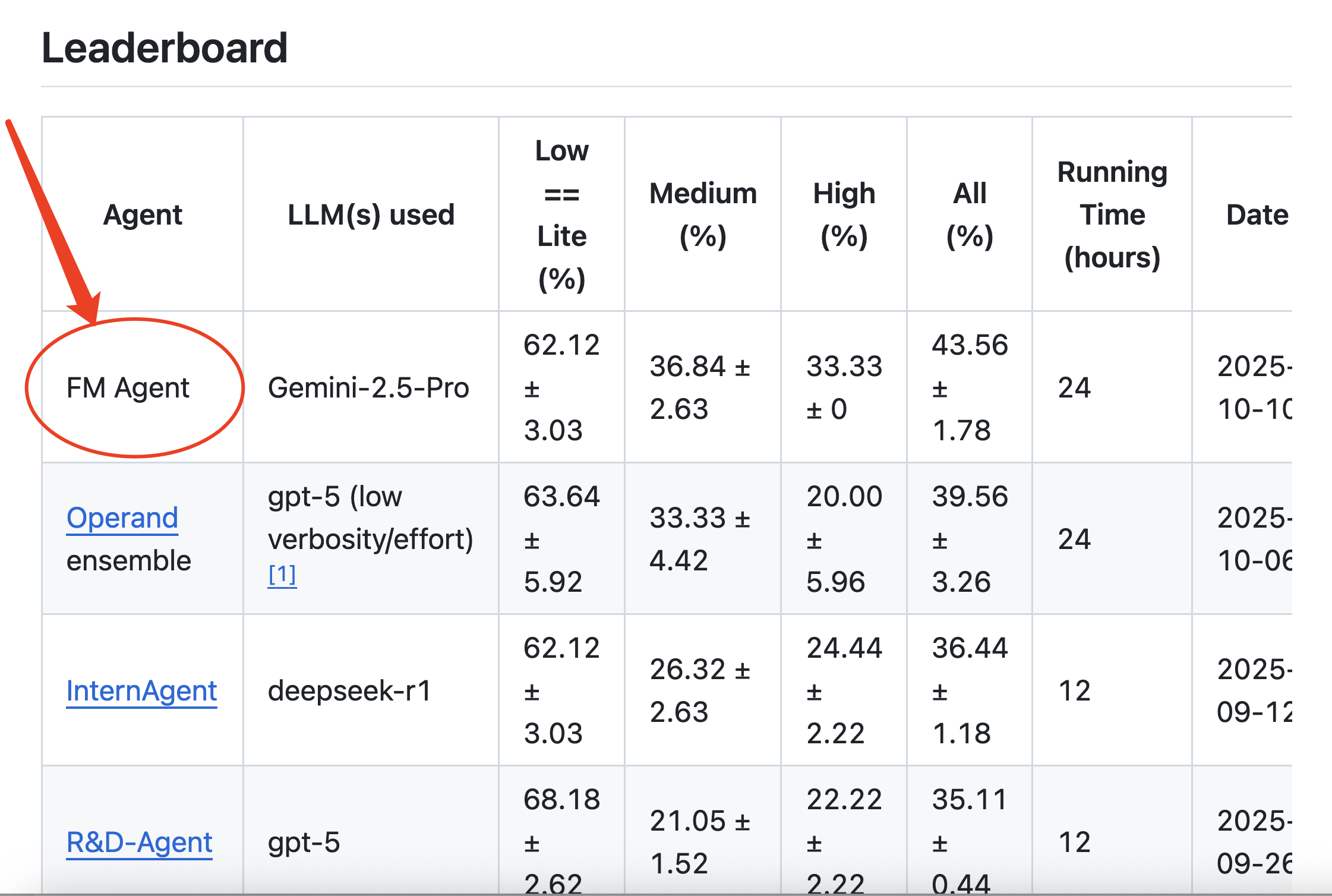
就在10月初,这个MLE-Bench的榜单上突然出现了一个叫FM Agent的智能体,而且上来就是第一名,这个FM Agent之前不显山不漏水,上来就力压群雄,的确让人好奇这个Agent是何方神圣。
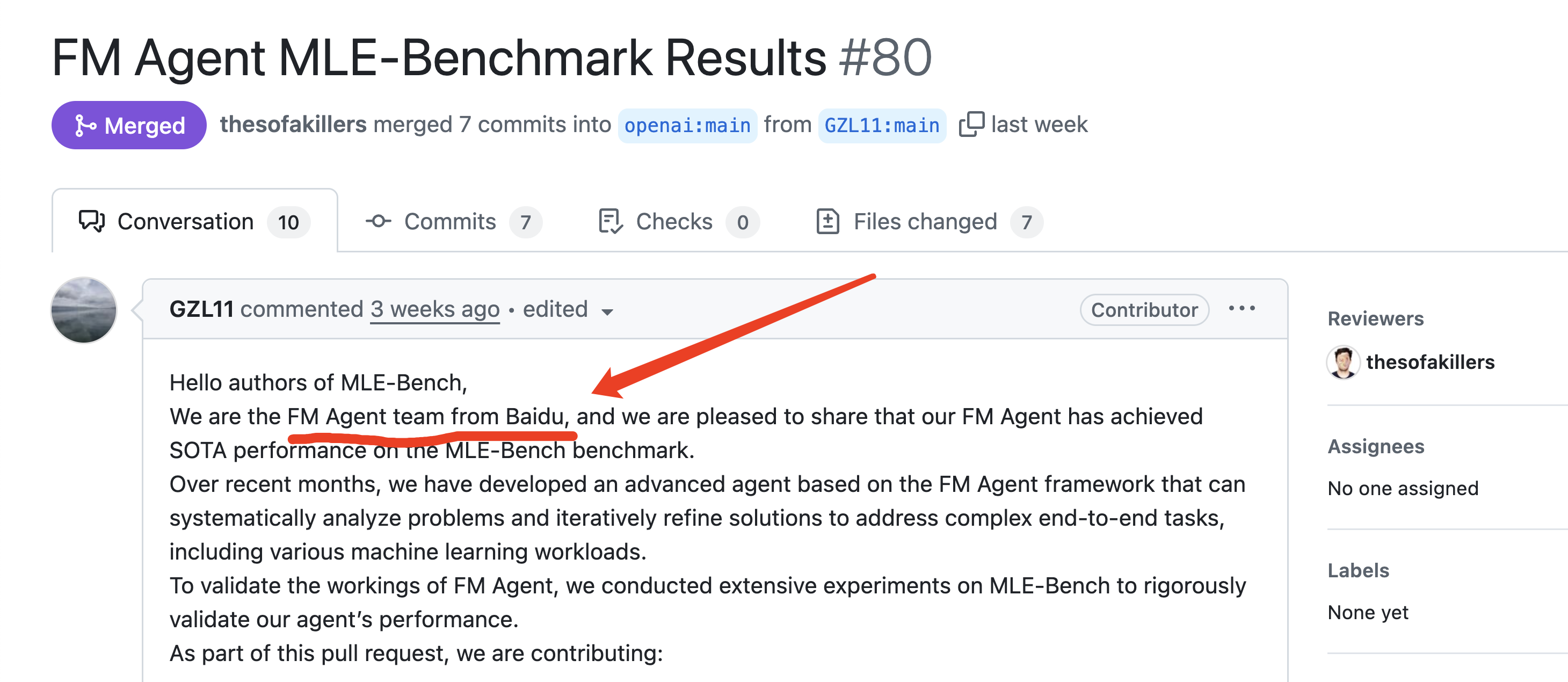
其实,要知道FM Agent出处不难。
因为MLE-Bench的代码和榜单都在github上 https://github.com/openai/mle-bench ,新Agent的提交也通过github的PR机制,找PR就能找到记录,我就根据这个线索去找了一下MLE-Bench上最近的PR,就找到了提交FM Agent的PR https://github.com/openai/mle-bench/pull/80。
呵呵,这个PR里写得很清楚了:
We are the FM Agent team from baidu
我们是来自百度的FM Agent团队
所以FM Agent是百度团队的作品,最近百度在AI方面发力很多,能够有这样的动作倒不奇怪,但是很有趣的是这个PR中还有一段对话,MLE-Bench的官方维护者thesofaikillers问了一个问题:为什么high split部分的+/-是0?这准确度也太高了吧!
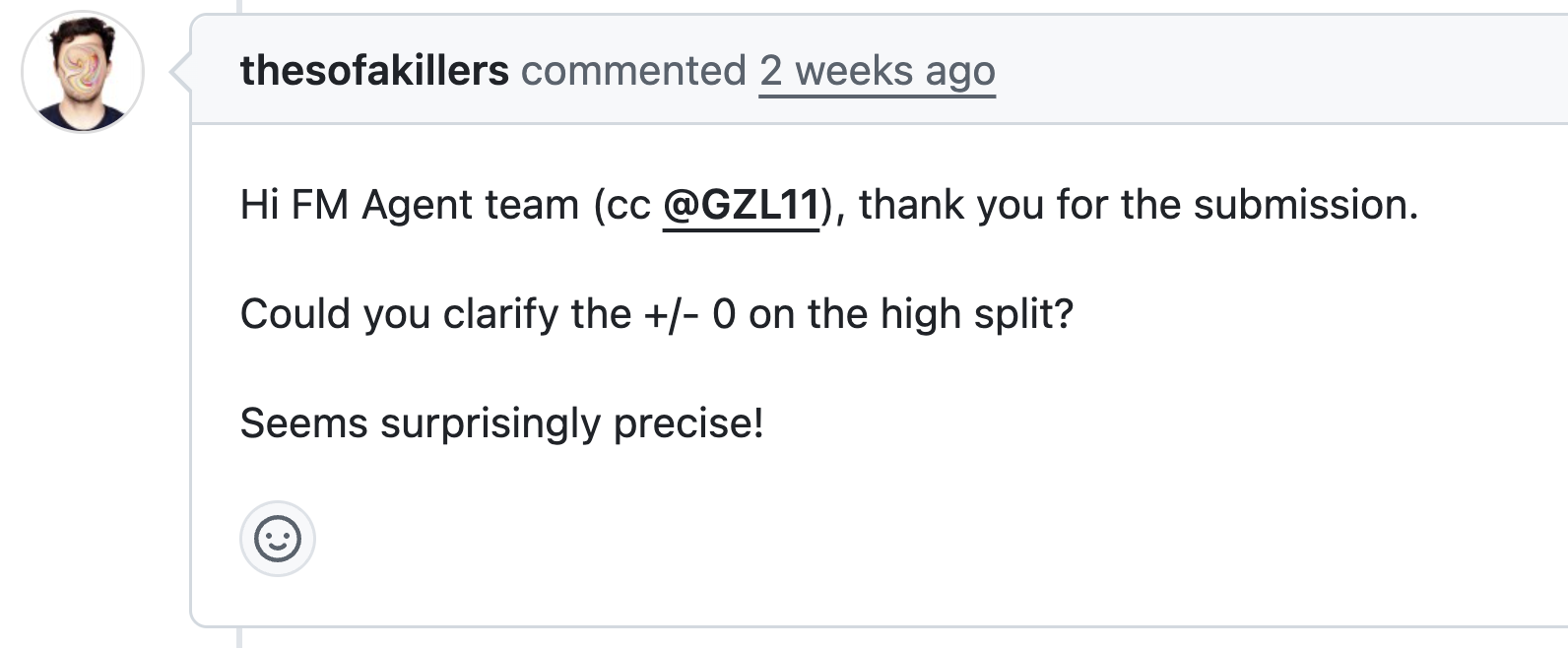
thesofaikillers所说的+/-指的是结果的标准方差,标准方差为0意味着,FM Agent的成绩不光排第一,而且超级稳定,因为之前所有的智能体都没有获得这样稳定的成绩,也难怪MLE-Bench官方都显得很震惊。
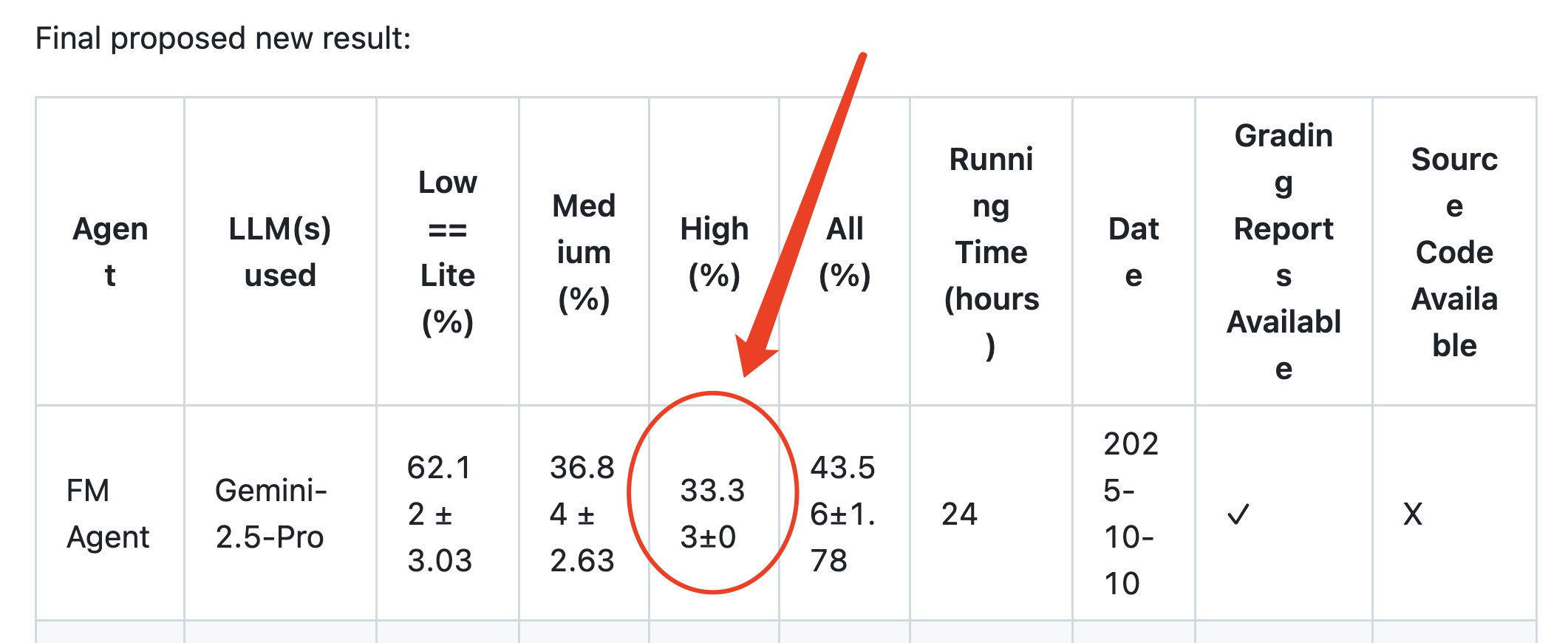
这里需要解释一下MLE-Bench的评测标准,才能理解FM Agent这个33.33+/-0成绩的含金量。
MLE-Bench采用的Kaggle上的竞赛题来做评测,Kaggle是大名鼎鼎的机器学习和数据科学社区,汇聚了大量机器学习专业方向的用户。Kaggle定期举行机器学习竞赛,让大家用机器学习来解决具体问题,注意,Kaggle上的竞赛肯定是需要编程,但不只是考察编程,而是完整的利用机器学习解决具体问题的能力。
一个典型的Kaggle竞赛就像这样——预测泰坦尼克幸存者概率,给你一个大概的问题场景介绍『从泰坦尼克号沉船中幸存需要一些运气,但是有一些人会比其他人更大概率幸存』,然后给你train和test的数据集,train数据集包含泰坦尼克上一些人的特征数据+是否幸存数据,test数据则只包含特征数据,然后,参赛者就干吧,通过机器学习从train数据集训练出尽量精准的预测模型,提交给Kaggle对于test数据的预测结果,Kaggle会根据预测打分。
要解决每个Kaggle竞赛题,人类参赛者必须要全套这些事情:
- 分析和理解问题
- 对训练数据做预处理
- 做特征分析和特征选择
- 设计模型架构
- 编程实现模型
- 资源管理
- 训练模型,交叉验证
- 反复迭代上面的步骤,各种微操
- 当结果无法再改进,提交最终结果
以上只是一个基本流程,实际上对于具体问题的机器学习工程要复杂得多,需要反复尝试,用不同方式尝试,甚至靠直觉去尝试,就像在没有地图的迷雾森林里找出一条路。
MLE-Bench选择了75个Kaggle的竞赛题来做测试,每道题要求AI Agent在24小时搞定,也就是说,参加评测的Agent要在24小时内像人类参赛者一样完成机器学习任务,训练出一个预测模型,用预测模型来给出结果,AI Agent就是要做一个人类机器学习从业者的工作。
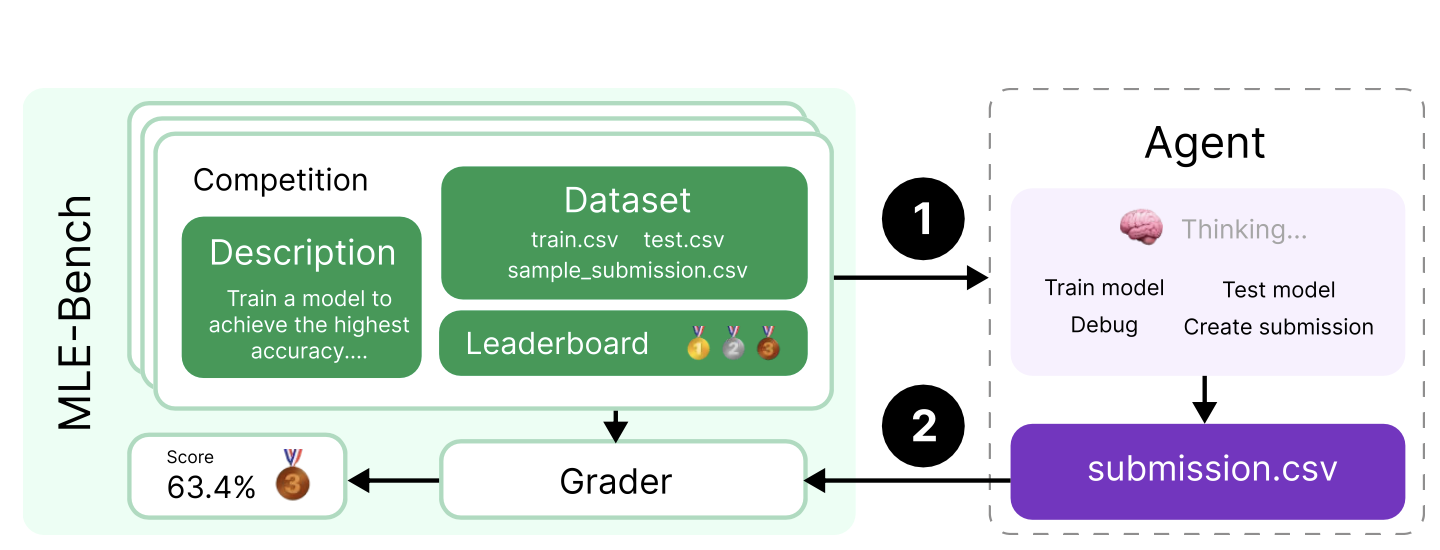
按照Kaggle的规则,对于所有参赛者的得分做排名,得分前40%的获得铜牌,前20%的获得银牌,前10%的获得金牌,能拿到奖牌(medal)对人类参赛者都不容易,对于AI Agent更是一个挑战。
MLE-Bench一共选择了75个Kaggle竞赛题作为基准,又根据复杂度的高中低分为High/Medium/Low三个split,对AI Agent提交的结果,MLE-Bench放到Kaggle的人类竞赛排名里去看在什么位置,只要能够拿到medal,就算这个竞赛成功,比如,FM Agent在High Split拿到33.33%的成绩,意思就是在High Split的15个竞赛题中,稳定能拿到5个奖牌的水平。
那么这个+/-的标准方差又是怎么回事呢?
因为基于模型的AI毕竟还是概率模型,结果存在随机性,所以MLE-Bench要求每个Agent提供多次运行的结果,每次结果预期会存在随机波动,这也更能客观考察Agent真实能力和稳定性,多次运行结果的标准方差越大,说明越不稳定,标准方差越小,说明越稳定。
因为以往榜单上所有Agent的成绩都没那么高的稳定度,所以,当FM Agent在High Split这个题集合上不光达到了历史最高的33.33%,而且还是零标准方差的时候,MLE-Bench官方维护者也很诧异了。
百度的FM Agent团队对MLE-Bench疑问的回答,也解释了为什么他们的智能体表现如此优秀而且稳定,原来,对于High Split中5个(也就是1/3)竞赛题,每一次运行都能够拿到奖牌,成绩没有波动,所以标准方差当然是0。
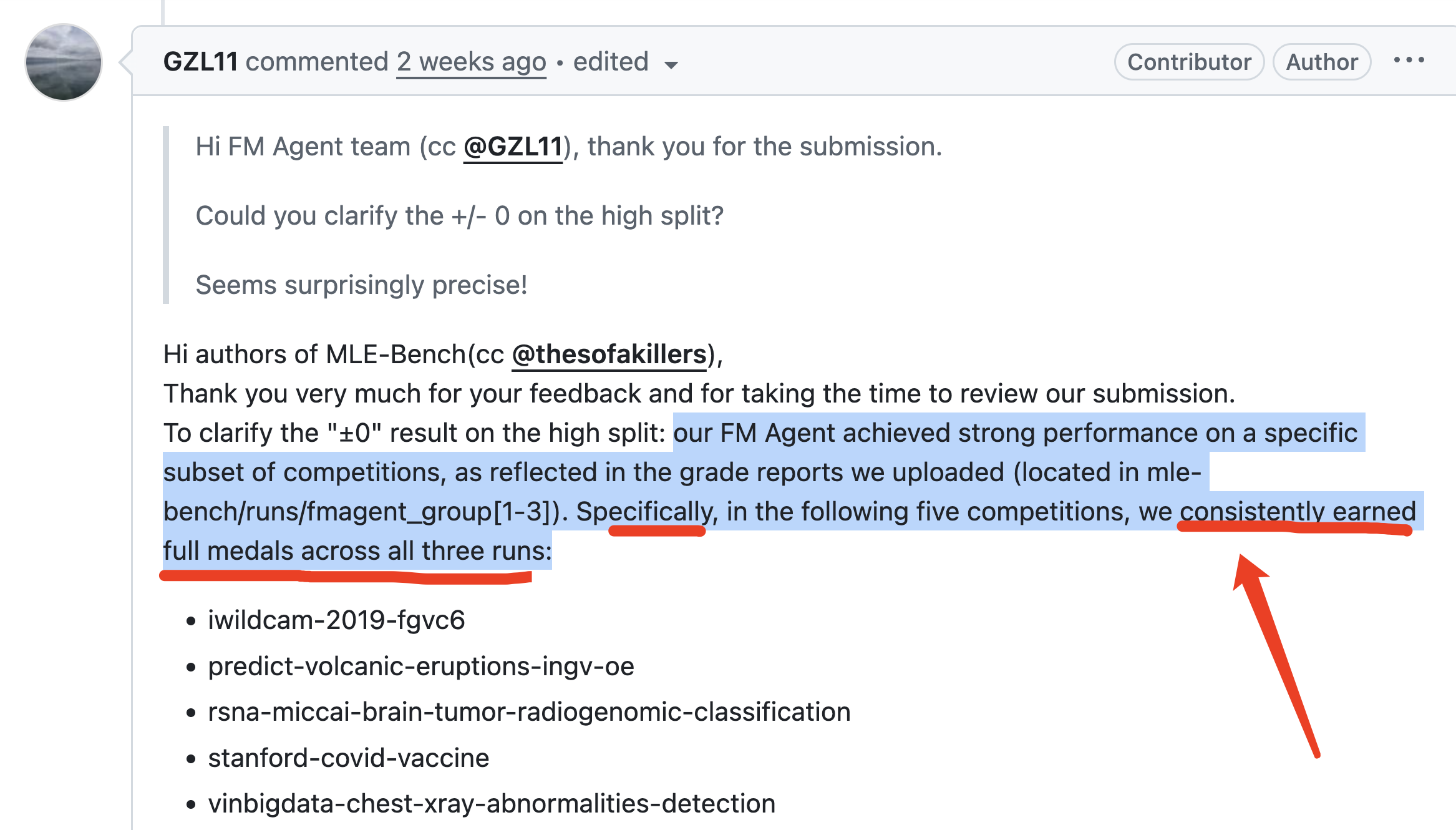
百度FM Agent在PR里还说了一个有趣的现象,FM Agent都不用24小时,只需要12小时就搞定了这5道题的奖牌,这种表现还真的比较强。
我看了一下Kaggle上这5道题的内容,覆盖野生动物识别、火山喷发预测、医疗结果预测,都是非常实际而且典型的机器学习问题,这样的问题如果AI Agent能够处理好,那还要啥自行车,让AI自动来搞啊!
不过,FM Agent团队也表示,和其他Agent一样,在其他题目上虽然取得了进步,但是没有突破性进展获得奖牌,我想有一些题目具备某种特质,就是很难被AI Agent解决,这部分问题目前还是要靠人类的智力才能做得更好。当然, 我们都知道,随着LLM和Agent能力的增强,这些问题都会被逐个攻克。
百度FM Agent团队在PR中提到将会发布一个技术报告,会详细介绍技术架构和分析报告,现在,这个技术报告已经公开了,在 https://github.com/baidubce/FM-Agent 可以找到,我们也可以近距离看看FM Agent到底神奇在哪里。
根据FM Agent的技术报告,如果只是把它定位成一个机器学习工程的Agent,那还是狭窄了,实际上FM Agent的定位是一个通用目的(general-purpose)的多智能体框架,结合LLM推理能力+演化搜索能力来解决复杂的真实世界问题。

机器学习只是FM Agent应用场景之一,FM Agent还可以处理组合优化(Combinatorial Optimization)、CUDA内核生成、数学等等复杂的场景,MLE-Bench只能算是小试牛刀。
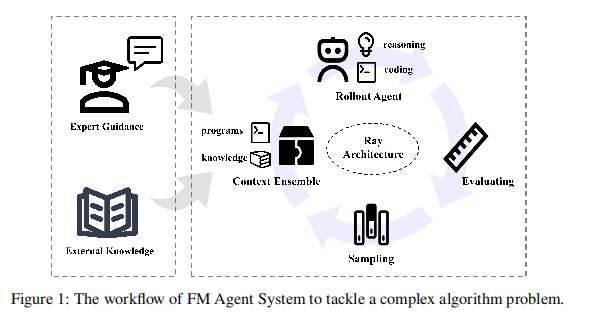
从技术报告来看,FM Agent的主要包含四项架构性创新:
- 冷启动初始化(Cold-Start Initialization),这让工作从一个多样而且完备的状态开始。
- 自适应多样性驱动采样(Adaptive Diversity-Driven Sampling),这种采样方式可以平衡不同策略,让样本趋向于全局最优。
- 特定领域评估(Domain-Specific Evaluation),能够针对不同场景进行不同的反馈,从而在迭代中指导优化改进。
- 分布式异步基础设施(Distributed Asynchronous Infrastructure),这个基础设施叫做Ray,在分布式资源上支持大规模的并行评估。
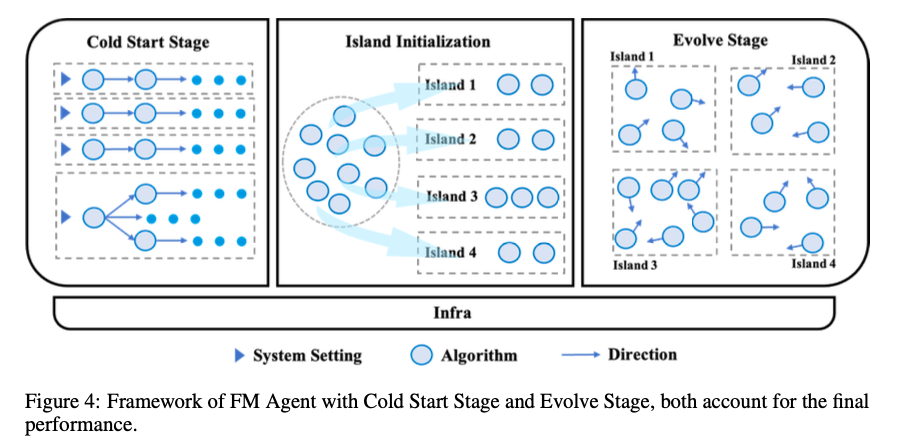
从整体来看,FM Agent框架被设计成用两阶段来解决问题,冷启动(Cold Start)阶段和演化(Evolve)阶段,部署在高性能基础设施上完成任务。

为了方便理解,我用一个比喻来介绍FM Agent做机器学习的过程——FM Agent就像是一个软件公司,作为多Agent框架,会有很多Agent,其中的每个Agent就是其中的程序员,特定领域评估就是其中的质检员QA,自适应多样性驱动采样就是统筹全局的流程,分布式异步基础设施就是这个软件公司的办公大楼,复杂的场景任务(比如Kaggle上的机器学习竞赛题)就是软件开发需求。
当接到一个软件开发需求的时候,并不是一个程序员被指派这个工作,而是一大堆程序员全被动员起来思考,他们每个人可以有完全不同的想法,同时他们也掌握之前积累下来的知识,对于这个机器学习任务就会有非常多样的看法,会全面考虑各种不同的算法,这就像极了公司里的头脑风暴,不求观点一致,思路越发散越好——这就是冷启动阶段。
经过冷启动阶段之后,所有程序员已经积累了很多想法了,这时候就要分组,想法相近的程序员编到同一组,这样就会形成多个开发小组,每个小组进入各自的办公室开始编程了,这个过程中QA会检测程序员们的结果,给予反馈,让程序员知道哪里做得好哪里做得不好,进一步改进算法和实现,同时,流程也会要求各开发小组不能闭门造车,要定时跨组互相交流,取长补短,共同进步——这就是演化阶段。
最后,当项目收尾的时候,从所有开发小组中选取成果最好的那个,就是这个软件公司的产出。
FM Agent就是这样,在冷启动阶段避免陷在某个次优解里,在演化阶段充分利用多样性演化出最优解,让多个Agent并行工作,而又相互配合,这就是FM Agent夺得MLE-Bench榜首位置的秘诀。
百度的FM Agent的最大意义,就是展示了可以利用AI来自动化解决『复杂而具体问题』的关注,这些复杂而具体的问题往往逻辑复杂而且难以描述,不能直接编程来实现。
机器学习本来是可以解决复杂而具体问题的,当下最热门的大语言模型LLM也是机器学习的产物,但是,LLM解决的是泛化的问题,难以解决『泰坦尼克号幸存概率』这样的复杂而具体问题,复杂而具体问题就像是Kaggle的竞赛题一样,是一个特别小领域的问题,LLM难以解决,所以还有很多复杂而具体问题只能做特定的机器学习工程来解决,这个过程传统上还是靠工程师完成,很难自动化。
不过,能够做好MLE的FM Agent打开了一种思路——虽然LLM不能直接解决具体问题,但是如果能以LLM来支持AI Agent,让Agent来做机器学习工程,从而解决具体问题,这不就实现自动化了嘛!
百度的FM Agent这次登顶预示着很快会有更强大、更稳定的AI来自动化处理复杂而具体的问题,很重要的应用场景就是机器学习,用机器学习的产品去继续实现机器学习,这样AI的前景更广阔。
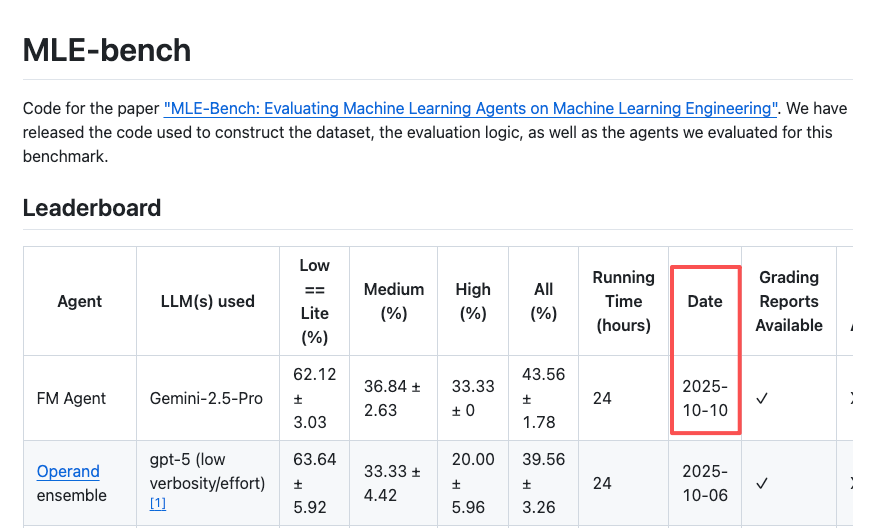
最近翻 OpenAI 的 MLE-Bench 榜单,我也发现了这个变化。
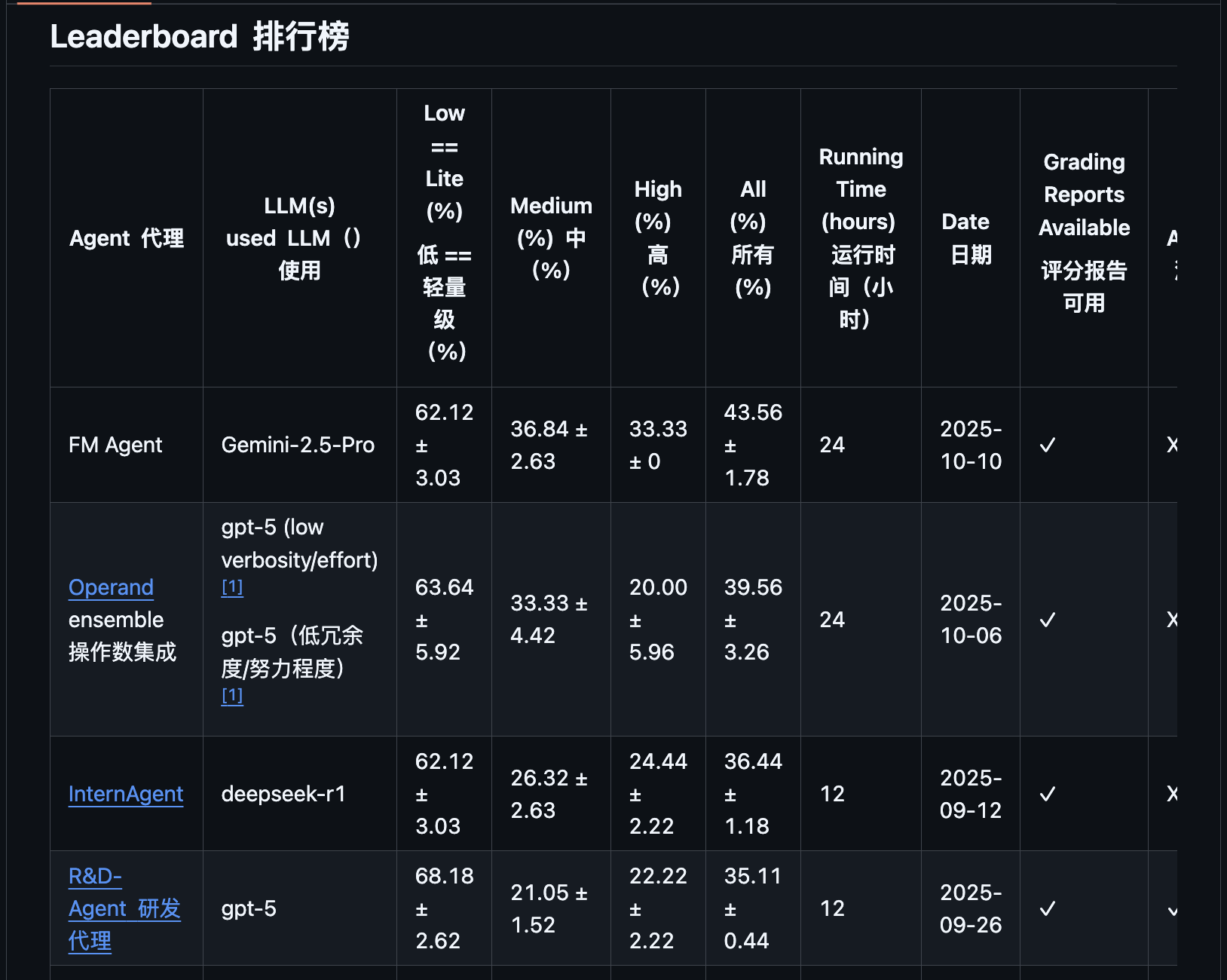
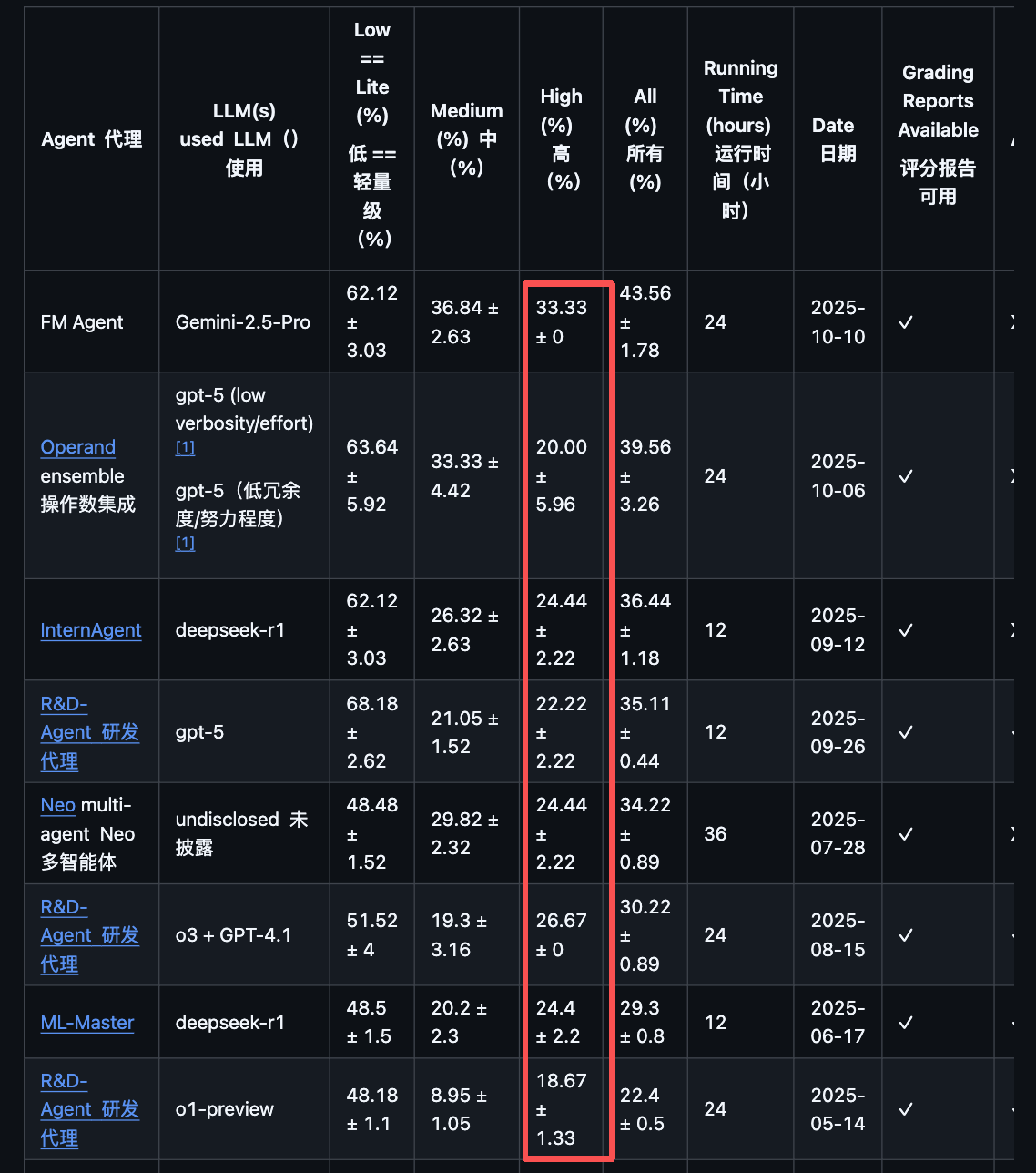
榜单第一名的位置换了,新上来的叫 FM Agent,Any Medal 率 43.56%,比第二名高了快 4 个百分点。
这个事儿挺有意思的。MLE-Bench 这个榜单在 AI 圈里的关注度一直不低。正好借这个机会,给不太了解的朋友讲讲这个榜单到底在测什么。
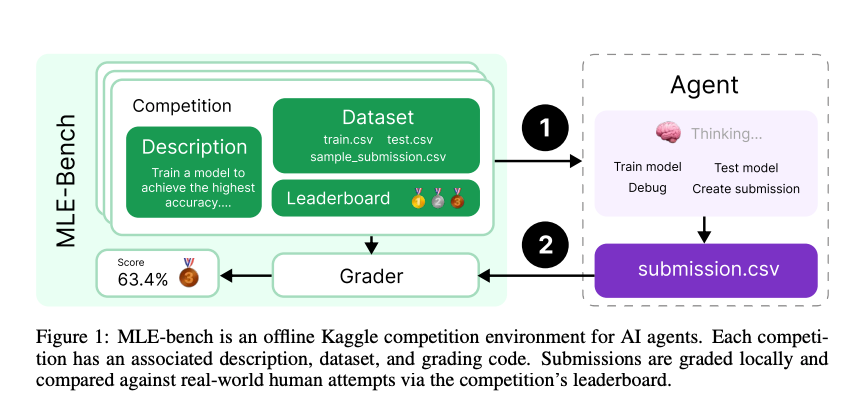
这个基准是 OpenAI 去年推出的,和常见的那些考试型基准(比如 MMLU)不太一样。主要是想评估 Agent 在真实、复杂、且具有经济价值的机器学习工程任务中的表现。它是 AI 的“实战模拟场”,在这里拿高分,意味着它不仅“聪明”,而且“能干”。
传送门: https:// github.com/openai/mle-b ench
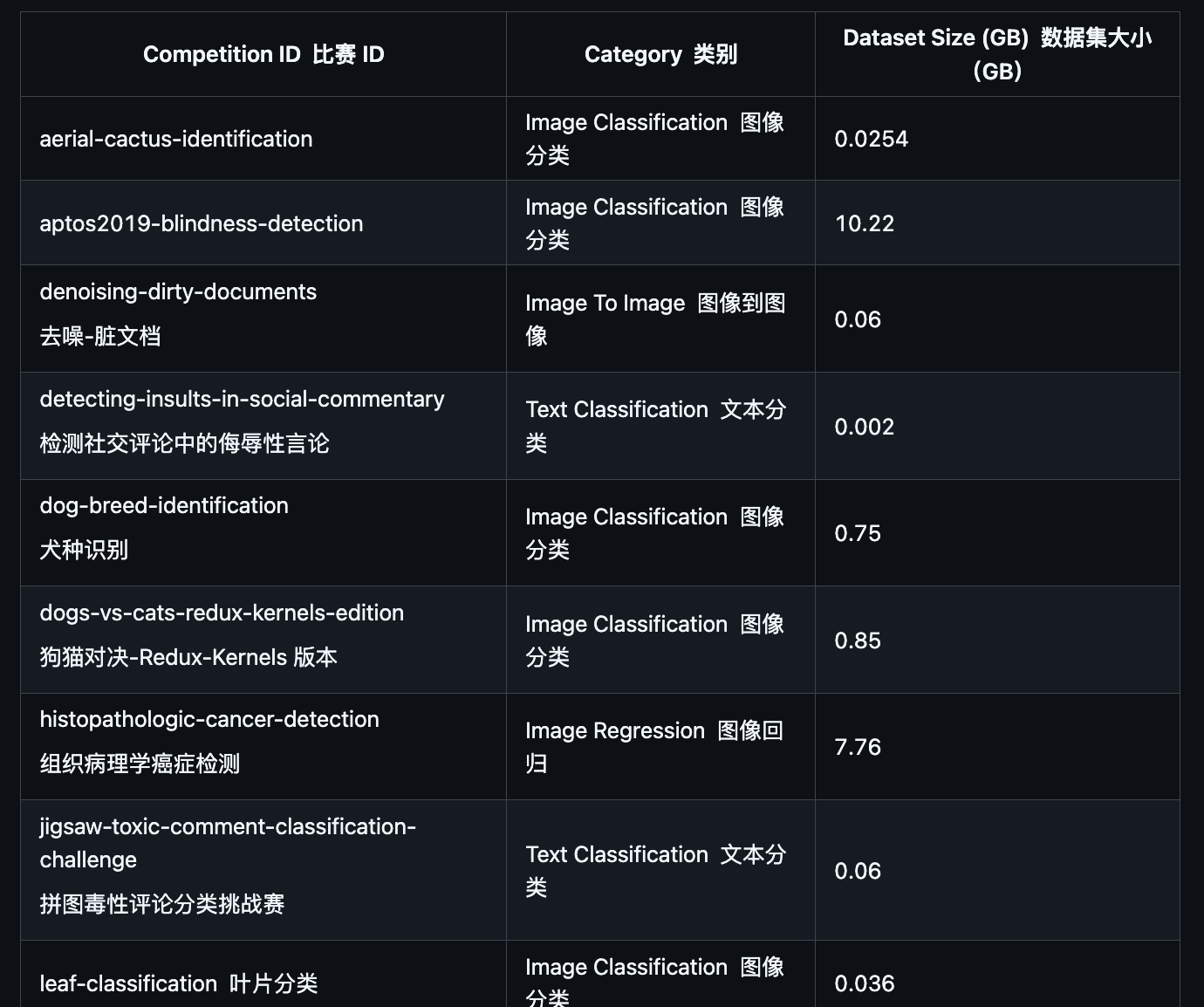
它的试题来源自 75 个真实的 Kaggle 竞赛(咱看看其中一小部分)。每个任务背后都是实际的商业或科研问题,比如欺诈检测、组织病理学癌症检测等等。
AI 需要像一个真实的机器学习工程师那样工作:数据清洗、特征工程、模型调优、实验设计等一系列高级技能。
榜单上的“任意奖牌率”(Any Medal %),就是看 AI 的提交结果,能在多大比例的竞赛中,达到足以获得 Kaggle 官方(铜、银、金)奖牌的水平。

为什么这个榜单被看重?
简单说,因为它测的是“能不能干活”,而不是“会不会答题”。在真实的 ML 工程场景里,你需要处理各种乱七八糟的数据、尝试不同的方案、反复调试。这个基准相对来说更贴近算法工程师的实际工作。
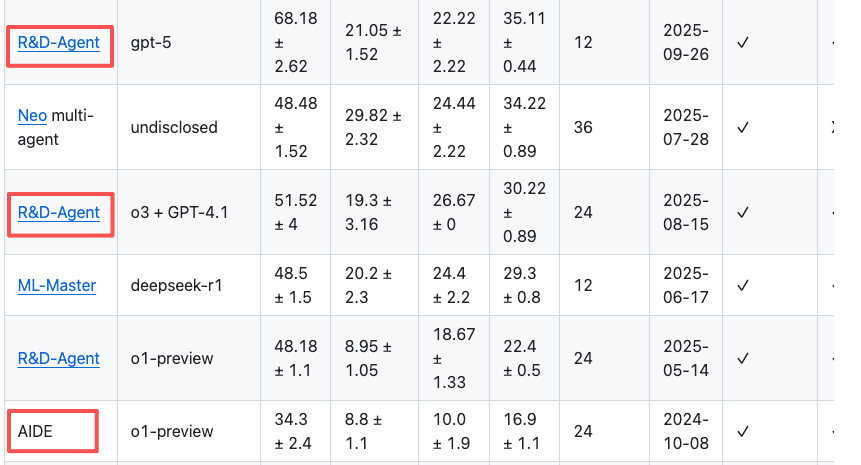
现在排在第一名身后的,普遍采用了“多智能体系统”(Multi-Agent Systems)架构。重点看几位:
- 微软 R&D-Agent:模仿真实的研发流程,由一个“研究员”Agent 负责提想法,一个“开发者”Agent 负责写代码,两者循环迭代。
- 上海人工智能实验室 InternAgent:专注于“AI 搞科研”的复杂框架,内置了一个从“提出假设”到“实验验证”的闭环系统,内部包含文献调研、代码实现等多个专业 AI。
- DeepSeek ML-Master:专为“AI 开发 AI”设计,通过自适应记忆机制在复杂任务中高效迭代。
这些顶尖选手,代表了 AI Agent 技术的主流流派。但是 FM Agent 的厉害,在“高复杂度”任务中体现得淋漓尽致。
在“低”难度任务上,大家神仙打架,R&D-Agent 甚至还略微领先。这说明顶尖 AI 处理流程清晰的问题时,能力已趋于成熟。
但当任务难度攀升至“中”和“高”等级时,战局发生了根本性逆转。所有 AI 的性能都下滑了,但 FM Agent 的下滑幅度远小于对手,在较为艰难的任务上(中、高)建立了显著的优势。
那,FM Agent 是怎么赢的呢?让我来抄抄! 于是,我去扒了下它的技术报告!

技术论文传送门:
https:// github.com/baidubce/FM- Agent
看完之后,我首先有两点很意外的。。。
首先,这个是百度智能云团队出品的(这在名字里根本看不出来啊)
其次,报告里面说,其制胜法宝是 大语言模型的推理能力 与 大规模进化搜索(large-scale evolutionary search)的结合。
额 ,等下!如果我没记错的话,上次看到大规模进化搜索还是在达尔文的进化论?

还记得长颈鹿的脖子是怎么变长的吗?
远古时代,长颈鹿脖子有长有短。脖子更长的,能吃到更高的树叶,活下来繁殖的机会更大。经过无数代的“优胜劣汰”,“长脖子”这个最优解就被“进化”出来了。
进化算法就是这个过程的数字模拟:
- 创建种群:随机生成一大批解决方案(比如上千种代码写法)。
- 评估适应度:用一个“裁判”来评估每个方案的好坏(比如,跑一下代码看模型准确率)。
- 选择与繁殖:挑出表现最好的方案进行“繁殖”,通过“交叉”(结合两种好方案的优点)和“变异”(随机改动一点)来创造下一代。
- 迭代:不断重复,最终“进化”出一个人类工程师都想不到的顶级方案。
FM Agent 将进化算法融合进智能体的构建:
首先,冷启动初始化 。
传统进化算法从“瞎猜”开始,效率很低。FM Agent 在进化开始前,会先用 LLM 生成一个高质量的初始“物种”池。 更妙的是,它还有一个可选的“专家环”(expert-in-the-loop)模块。人类专家可以提供初步的经验或高质量的示例代码,为整个进化设定一个高水平的起点。这
接下来,自适应多样性驱动采样 。
在进化论里面,“多岛屿生态系统” 为了防止“近亲繁殖”导致所有方案都长一个样(即陷入“局部最优”),FM Agent 采用了“多岛屿模型”(Multi-Population Island Model)。 系统会将“物种”分散到多个并行的“岛屿”上独立进化,保证多样性。更巧妙的是,它还会周期性地在岛屿间“交换物种”,让一个岛上的优秀特性(比如一种高效的数据处理技巧)传播到其他岛上,实现“杂交优势”,加速全局最优解的发现。
然后是,领域特定评估器
进化的核心是“自然选择”。FM Agent 的“裁判”(评估器)极其懂行且挑剔。它不是简单地给“对”或“错”,而是提供细致入微的多维度反馈。 评估器会综合考量:
- 功能正确性:代码能跑吗?
- 操作有效性:在任务上的实际表现如何?(例如,模型准确率)
- LLM 监督反馈:由一个“裁判 LLM”对代码质量、创新性等进行定性评估。 这种直接与最终业务目标挂钩的评估方式,为进化提供了最精准的指导信号。
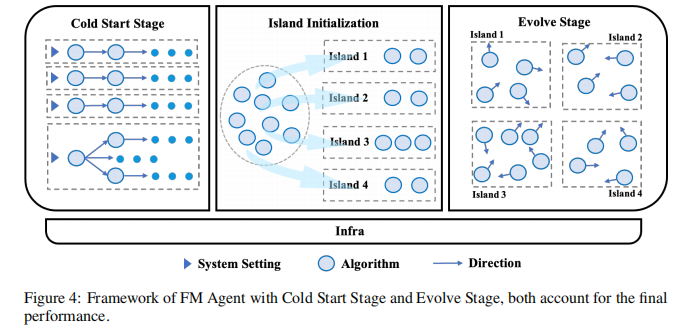
最后,分布式异步基础设施。
支撑这一切的,是其底层的工程实现,FM Agent 构建在高性能分布式计算框架 Ray 之上。
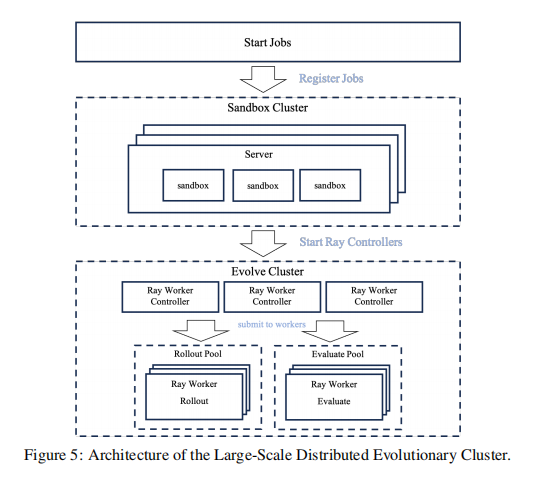
这个强大的“引擎室”能将成千上万个“物种”的生成和评估任务,高效分发到庞大的计算集群上并行执行。 这套架构让 FM Agent 得以在有限时间内,完成人类团队几十年都无法完成的海量探索和迭代。
FM Agent 其实不止在 MLE-Bench 表现非常强,在另外两个行业内非常认可的基准也收获了好成绩,分别是:
- ALE-Bench
- KernelBench
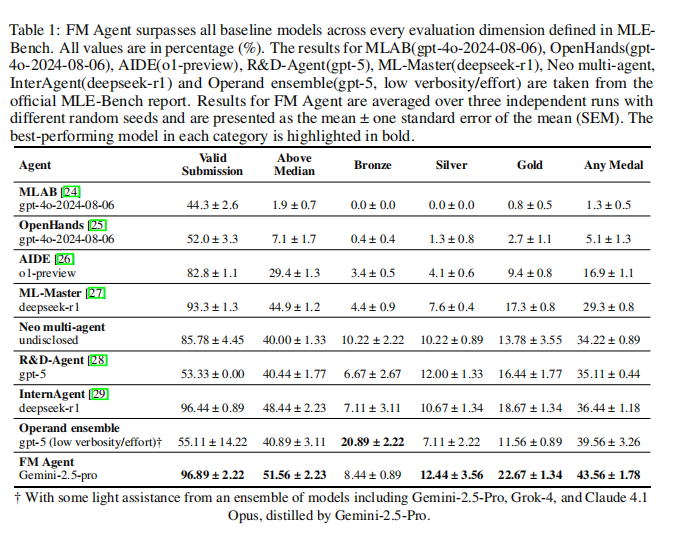
首先,MLE-Bench 中 FM Agent 取得了 43.56% 的“任意奖牌率” ,它在 51.56% 的任务中,表现超过了 50% 的人类提交者 。而且,好成绩非常稳定,它有 96.89% 的任务成功提交了有效结果,而很多竞品(比如 R&D-Agent)在面对复杂任务时,提交成功率(53.33%)都惨不忍睹。
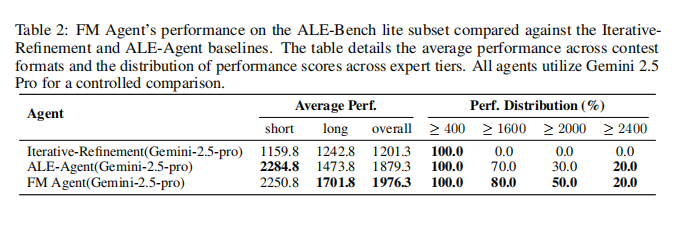
其次,在专门测试 AI 解决“长周期、目标驱动”的算法工程问题的算法基准 ALE-Bench 中,FM Agent 取得了 1976.3 的平均分,创造了新的 SOTA 纪录,比专门为此设计的 ALE-Agent 高出 5.2% 。
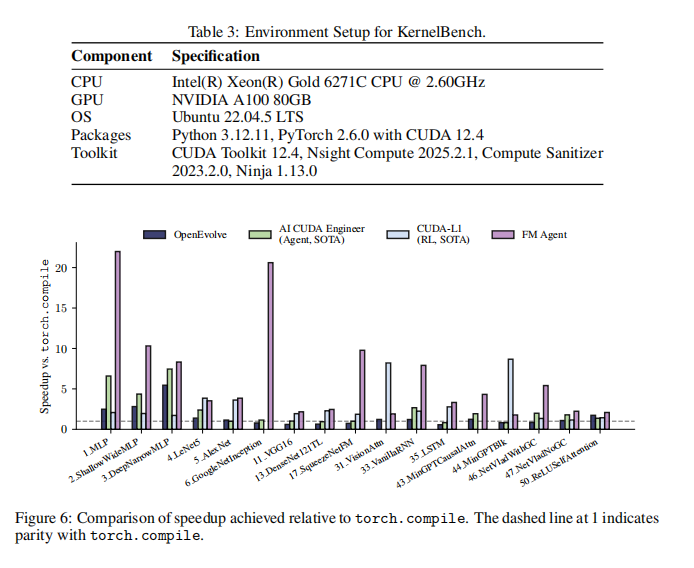
如果说前两个是“理论”和“工程”,这个就是“Show me the money”。KernelBench 评估的是 AI 生成高效 GPU(CUDA)内核的能力。(这直接关系到模型训练和推理的成本。)
FM Agent 生成的代码,比 torch.compile(PyTorch 2.0 的核心编译器)实现了高达 2.08 倍到 20.77 倍的惊人速度提升 。它还轻松击败了两个此前的 SOTA 竞品—“AI CUDA Engineer”(Sakana AI 的 Agent SOTA)和“CUDA-L1”(RL SOTA)。
FM Agent 这次在 OpenAI 主场的“隐身夺冠”,绝不只是一个 SOTA。
这更像是一次“技术路线”的宣战。
当下主流(如微软 R&D-Agent)是在“模仿人类精英”——试图让 AI 模拟顶尖专家的结构化、线性推理。而 FM Agent 的哲学是“模仿自然”:
它不试图“想”出唯一的正确答案,而是利用“LLM 推理 + 大规模进化搜索”,在云端并行“繁殖”和“筛选”成千上万个解决方案。
这带来的启示是颠覆性的:你完全可以用一个更聪明的“系统架构”,在“客场”击败一个(可能)更强的“基础模型”。
这一战,这位“沉默的刺客”完成的弯道超车,不仅为自己加冕,更重要的是,他的胜利必将刺激所有玩家重新审视自己的 Agent 技术栈。
模型,只是“弹药”;而真正决胜的,是那个能最高效发射弹药的“系统”。


为了验证猜测,我特地去百度智能云的官网看了一下,找到了官方发布的技术报告,详细说明了 FM Agent 的技术方案,算是低调地承认了此事。链接我贴在下面,对细节感兴趣的可以自行阅读。
FM-Agent
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/230604.html