
官网显示模型名为deepseek-V3-600B
Deepseek V3的Aider代码能力排行榜正确率为48.4%,仅次于OpenAI o1,超过Claude 3.5 Sonnet。
幻方量化旗下模型DeepSeek上线V3版本|界面新闻 · 快讯我觉得 deepseek v3 主要做成了 2 件事:
- 继 flash attention 之后,又一个相信自己比英伟达懂 GPU 计算,并且做到了的团队;
- 找到了 pretrain 的一个 10x 变化。
这里前者是指 fp8 训练,后者是指 pretrain batch size 的扩展。
fp8 训练应该算是各个工程团队长久的痛。大家都明白 fp8 的计算峰值是 bf16 的两倍,但是除了 23 年 Yi 团队对外宣传成功做了 fp8 的 pretrain,fp8 这里一直都没有一个相对公开的 recipe,更多地是 “训练极其不稳定” 的流言。而英伟达官方的 transformer engine 似乎也没有解决这个问题,并且如同英伟达的其他开源软件库一样,变得愈发笨重和冗杂。
deepseek 团队有这个勇气和能力直接抛开英伟达提出的 fp8 实践,给出了例如正反向都使用 e4m3,attention 后的 linear 输入的精度需要提升这样的细节,以及独立实现 per-group scaling 的训练(这部分也可以解读为受 B 系列显卡的 microscaling 启发),真的是非常令人佩服。就像是 Tri Dao 大大告诉大家 attention 的 kernel 应该这样写一样,deepseek 团队正在告诉大家,fp8 应该这样用。
相较于 fp8 这个可以被看做是相对独立的工程问题,我更喜欢的是他们通过扩大 batch size,提升工程效率的这种算法和工程的联调。相信很多朋友都听说过,系统领域的一个常见思路就是去考虑在某个维度放大 10 倍之后,会有哪些新的 trade-off,从而获取更充分的设计空间。deepseek 提出的将 pretrain batch size 从传统的 4M~8M tokens,提升至 4K * 15360 = 60M tokens 就是这样的变化。超大的 batch size 可能可以 makes pipeline parallel great again。
在此之前,我一直认为 pp 是相对鸡肋的并行方式,因为不管怎么优化 pp 算法,减小 bubble 的前提总是 micro batch 足够多,划分足够细。以 deepseek v3 这个 671B 模型为例,目前的设置是 2048 卡分 16 路 pp,没有 tp,也就是 2048 / 16 = 128 路 dp。那么在 context length 为 4k 的情况下,如果 batch size 为 4M,也就是 1024 条 sample,每一组 pp 的 16 张卡只能分到 1024 / 128 = 8 个 sample,连让 16 张卡同时运行都做不到。
而当 batch size 扩到 15360 个 sample 时,每一组 pp 的 16 张卡就能分到 120 个 sample,那么 bubble 就可以压下来,pp 也就变成了一个不错的候选:因为它通信较小,而且部分通信相较于 tp 更好隐藏。由此,引出了论文中 dualpipe 这样的新设计,这部分我估计这个问题下面会有很多细致解读,我就不展开了。
考虑到现在工业界的 sft 也走到了一个 epoch 10B token 这个量级,我觉得这种 batch size 上的调整会对 25 年训练框架的设计带来比较大的影响。
我倾向于扩大 batch size 会有一定程度的掉点(实际上最近还在和同事聊,是不是 llm 到了一个需要上 lamb 的时候),所以如之前 character.ai 的那个回答中提到的,我非常钦佩能够牺牲一点模型性能,换取工程效率提升的团队。真的太优秀了,太 nb 了!
最后,还要感谢 deepseek 让资源少的团队又燃起了从零训 sota 的火苗!
P.S. 刚刚发现其实 deepseek v2 的时候 batch size 就已经很大了,是我后知后觉了…
看完技术报告,从infra的视角分享一些个人看法,供大家讨论。
首先,训练超大号的MoE模型,仅使用两千张H800加两个月的时间,就能达到如此好的效果,这点实在是太强了。只能说实践出先知,从DeepSeek过往的技术报告来看,明显可以感觉到团队的算法能力和系统能力都在持续升级。
遵循system-algorithm co-design原则,DeepSeek-V3继续沿用V2中的MLA和MoE结构,其中前者是为了降低kv cache/token开销,后者是为了降低flops/param开销。
1)MLA技术我之前就有介绍[1],简单来说就是通过类似LoRA的方式对kv进行降维压缩,同时将升维操作转移到Q和O上,避免反复解压缩。遗憾的是,MLA并没有收获太多关注。一个可能的原因是,它跟MQA相比似乎没有表现出什么优势[2],反而增加了系统复杂度。
2)MoE结构,不同于Mixtral中大专家的设计(将稠密模型中的MLP结构复制8份),DeepSeek-V3采用大量“小专家”的设计,能够显著提升模型的稀疏程度(总参数量除以激活参数量)。相比V2的236B总参数(21B激活参数),V3更加激进地引入256个专家,总参数量达到惊人的671B,而激活参数量仅仅增加到37B。
根据技术报告里的数据,得益于更加稀疏的MoE设计,以及系统上的一系列优化,训练V3每trillion数据的GPU小时数仅仅为180K(而V2对应的GPU小时数为172.8K),可谓是将V2技术报告标题中的Economical(性价比)贯彻到底。
3)除了继承V2的模型设计,V3中使用先前发布的auxiliary-loss-free策略[3]来缓解专家之间的负载不均衡(学术探索的技术能够如此迅速地上线到自家大模型,可见DeepSeek对于创新的重视程度)。另外,V3引入了multi-token prediction(MTP),不仅可以在训练时提供更多监督信息,还可以在推理时结合投机采样加速模型解码。从论文汇报的效果来看,MTP会是一个不错的训练技巧。
对于训练而言,最引人注目的自然是FP8的使用。DeepSeek-V3据我所知,是第一个(至少在开源社区内)成功使用FP8混合精度训练得到的大号MoE模型。
众所周知,FP8伴随着数值溢出的风险,而MoE的训练又非常不稳定,这导致实际大模型训练中BF16仍旧是主流选择。现有FP8方案[4]的训练困难主要来自两个方面,一个是粗粒度的per-tensor E4M3量化会因为个别异常值增加量化误差,另一个则是反向过程中使用的E5M2格式会带来较大的舍入误差。
为了解决以上问题,DeepSeek-V3在训练过程中统一使用E4M3格式,并通过细粒度的per-tile(1x128)和per-group(128x128)量化来降低误差。这种设计更加接近micro-scaling格式[5],然而,当前硬件架构并不支持这种格式的运算,这给FP8矩阵乘法的实现带来了挑战(需要通过partial sum的方式来实现)。
尽管DeepSeek-V3展示了per-tile和per-group量化对于模型收敛的重要性,论文中并没有给出对应的FP8矩阵乘法的算子效率。另外,论文中缺乏per-token加per-channel量化的讨论,不清楚这种实现上更加友好的量化方法对于训练稳定性的影响会有多大。
当然,FP8的好处还体现在节省显存上(尤其是激活值)。此外,DeepSeek-V3使用BF16来保存优化器状态,以及对部分操作进行选择性重计算(例如RMSNorm, MLA Up-Proj, SwiGLU)。显存的优化有助于设计更好的并行策略,例如可以减少甚至消除张量并行的使用。
在并行策略上,DeepSeek-V3使用64路的专家并行,16路的流水线并行,以及数据并行(ZeRO1)。其中,专家并行会引入all2all通信,由于每个token会激活8个专家,这导致跨节点的all2all通信开销成为主要的系统瓶颈。
为了降低通信开销,在算法层面,DeepSeek-V3使用分组路由的方式,限制每个token只会激活4个节点上的专家,从而减半跨节点的通信流量。在系统层面,将节点间通信和节点内通信进行流水,最大化使用网络带宽和NVLink带宽。
通过以上优化,DeepSeek-V3可以将通信计算比例控制在大约1:1,这为后面的通信隐藏带来了机会。具体来说,我们可以将不同micro-batches里前向和反向的计算通信任务做并发调度,使得计算和通信尽可能相互掩盖。
对于流水线并行,DeepSeek-V3设计了类似于Chimera[6] 中的双向流水来降低bubble,而没有采用更加常见的interleaved 1F1B(尽管interleaved 1F1B中的steady阶段同样可以将前向和反向的计算通信相互进行隐藏)。
最后,DeepSeek-V3模型的部署同样十分挑战。
对于MoE模型来说,开源框架大多沿用稠密模型的推理方案,例如Mixtral模型仍旧采用张量并行的方式部署。然而,这种处理方式使得MoE模型相比稠密模型在推理上失去优势。这是因为,MoE节省flops的好处主要体现在计算密集的prefill阶段,而在访存密集的decode阶段,MoE巨大的参数量然而会带来更加昂贵的数据搬移开销。哪怕能解决访存密集的问题,MoE参数消耗如此多昂贵的HBM空间,这可能也不是一个相当划算的决定。
可见,要发挥出MoE架构在推理侧的价值,必须改变并行策略,回到训练时DP+EP的方式。这意味着我们需要使用更大的机器单元来部署MoE模型,并尽可能避免专家层的冗余存储,从而降低每个设备上的模型参数量,缓解HBM容量和带宽的压力。
在这种部署方案下,负载均衡和all2all通信成为了核心挑战。了解以上背景之后,让我们回到DeepSeek-V3的推理方案。
首先,DeepSeek-V3采取PD分离的方式,分别应对prefill和decode两阶段的挑战。
在prefill阶段,attention模块采用4路张量并行+8路数据并行,moe模块采用32路专家并行。这样并行的目的是在满足首token时延的要求下,最大化系统吞吐(和训练任务类似)。
在decode阶段,DeepSeek-V3采取320路专家并行(256个小专家+64个热点专家),有效降低解码时延,并缓解负载不均衡的问题。
最后,为了填充all2all通信阶段的设备空闲时间,DeepSeek-V3采用NanoFlow[7]中的双流推理策略,将不同micro-batch中的计算和通信任务并发执行,从而提高设备资源利用率。
最近的OpenCode爆火,为了试试水,我也配置,非常好搭配,复制好了DeepSeek的KEY,直接/models选到 DeepSeek,粘贴进去就完事了,具体可参考:OpenCode | The open source AI coding agent
使用感受:当前版本是V3.2,但我的感受依然非常明显,具体对比如下:
- 我在OpenCode也接入了Github Copilot的Claude Haiku 4.5,但是根据需求生成的业务代码尝试多次之后,实现是能达到我描述的需求,就是这代码一直存在的语法错误它解决不掉。切换到 DeepSeek后直接解决。我分析可能的原因是CC Haiku 没有思考能力所导致的,之后再用Claude Sonnet 4.5 再做对比,至少目前DeepSeek V3.2 强于 CC Haiku 4.5应该没有问题。
- 对比国产新秀MiniMax M2.1,其表现和Claude Haiku 4.5非常像,但是更差的地方在于,我使用PLAN模式计划好、核对好、确认好的需求它写的不对,更搞笑的是反复强调后,它总有自己的想法,切到DeepSeek后秒解决,目前MiniMax已放弃了。虽然MiniMax只花了9.9尝鲜,但是只用了两天就很亏,这DeepSeek一天2块不到的开销,够我用五天了。
缺点也非常明显:
- DeepSeek 不支持多模态,想让它根据截图生成相应的前端代码还不知道该怎么用好,目前通过用户问题反馈跟它提了意见,不知道是否有作用。
- 慢!很慢,无论代码生成、需求讨论的,每个问题都大概要花费前面的MiniMax所需的三到四倍的时间,希望速度这块也能得到优化了,每次让DeepSeek干活后,我都切到后台等10到15分钟。
最近总能收到DeepSeek 更新V4的各种爆料和新闻消息,我说说我的的期望:
未来DeepSeek 能出一套针对Coding Plan的产品,希望这版有能赶得上Claude Sonnet 4.5的90%得代码水平,这都会非常好用,我将大充特充,大用特用。
最近翻看DeepSeek使用文档发现现在可以接入 Claude Code 了。
具体操作如下:
* 注: 使用Win系统的请开启 WSL2, 在应用商店安装一个 Linux 子系统, 详见: 如何使用 WSL 在 Windows 上安装 Linux
- 安装 Node.JS, 详见 Node.js 官网
- 安装Claude Code:
npm install -g @anthropic-ai/claude-code - 获取 DeepSeek API Key, 具体步骤上面有
- 终端运行:
code ~/.bashrc, 编辑设置环境变量:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic export ANTHROPIC_AUTH_TOKEN=${DEEPSEEK_API_KEY} # 替换成你自己生成的key export API_TIMEOUT_MS= export ANTHROPIC_MODEL=deepseek-chat export ANTHROPIC_SMALL_FAST_MODEL=deepseek-chat6. 重启终端, 或终端键入: source ~/.bashrc
完成以上准备工作, 即可开始使用 Claude Code + DeepSeek API
具体使用如下:
- 进入新建的工作区目录, 开启 Claude, 选 1. Yes
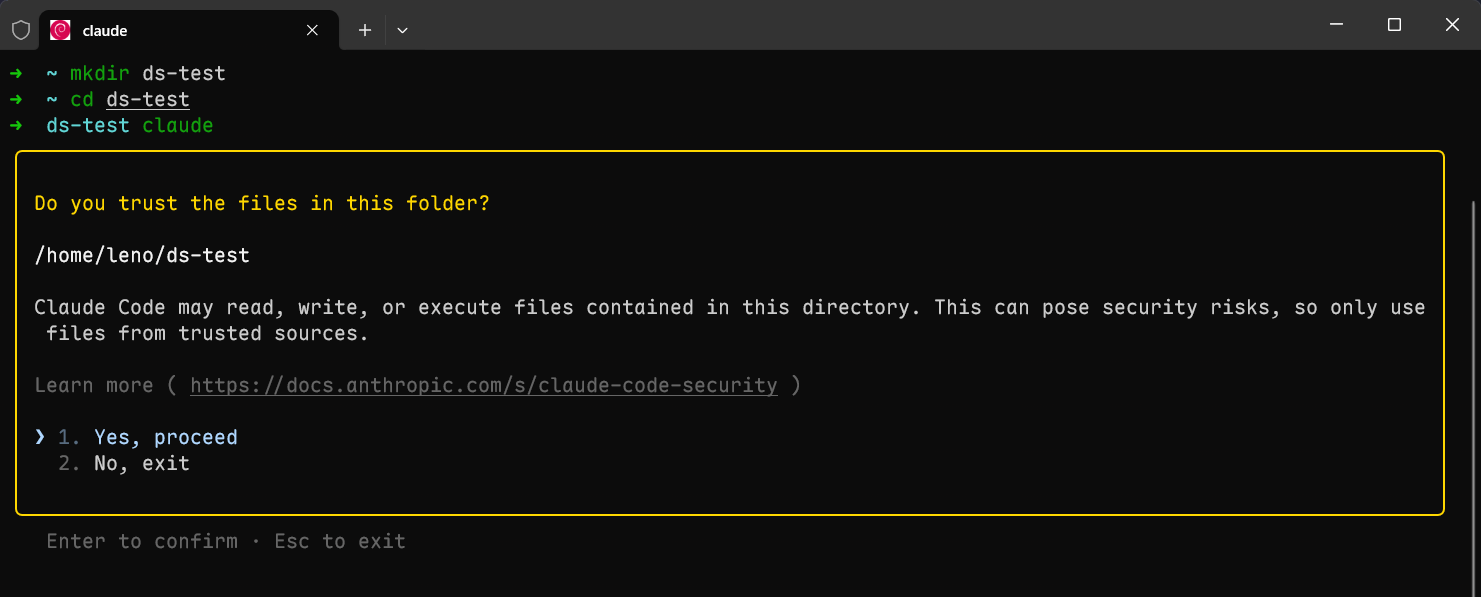
2. Ping 一下试试看
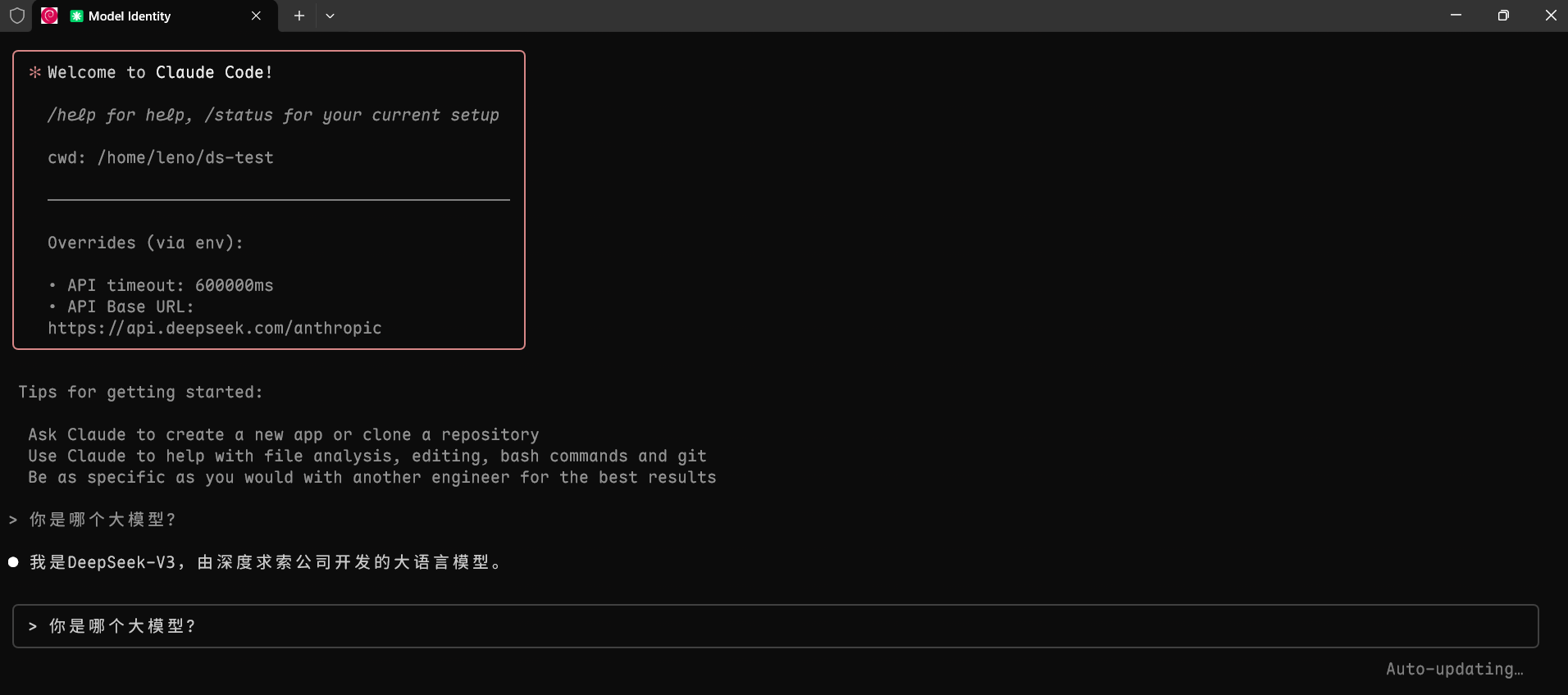
正常有回答返回, 说明 Claude Code + DeepSeek API 配置成功了
3. 使用示例:
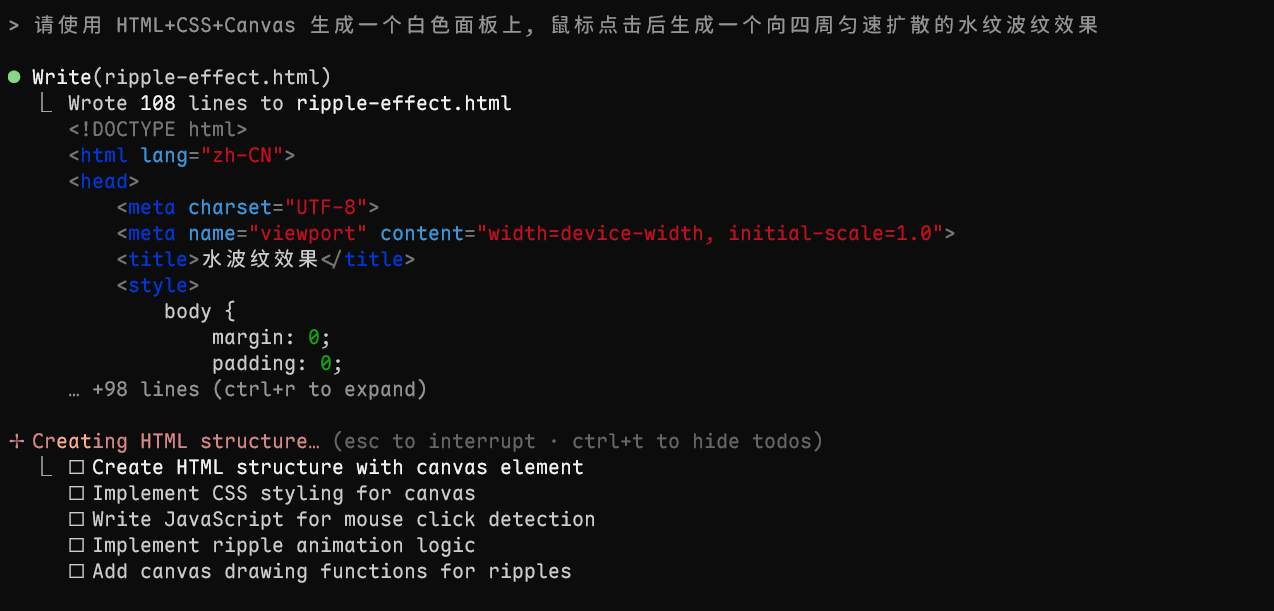
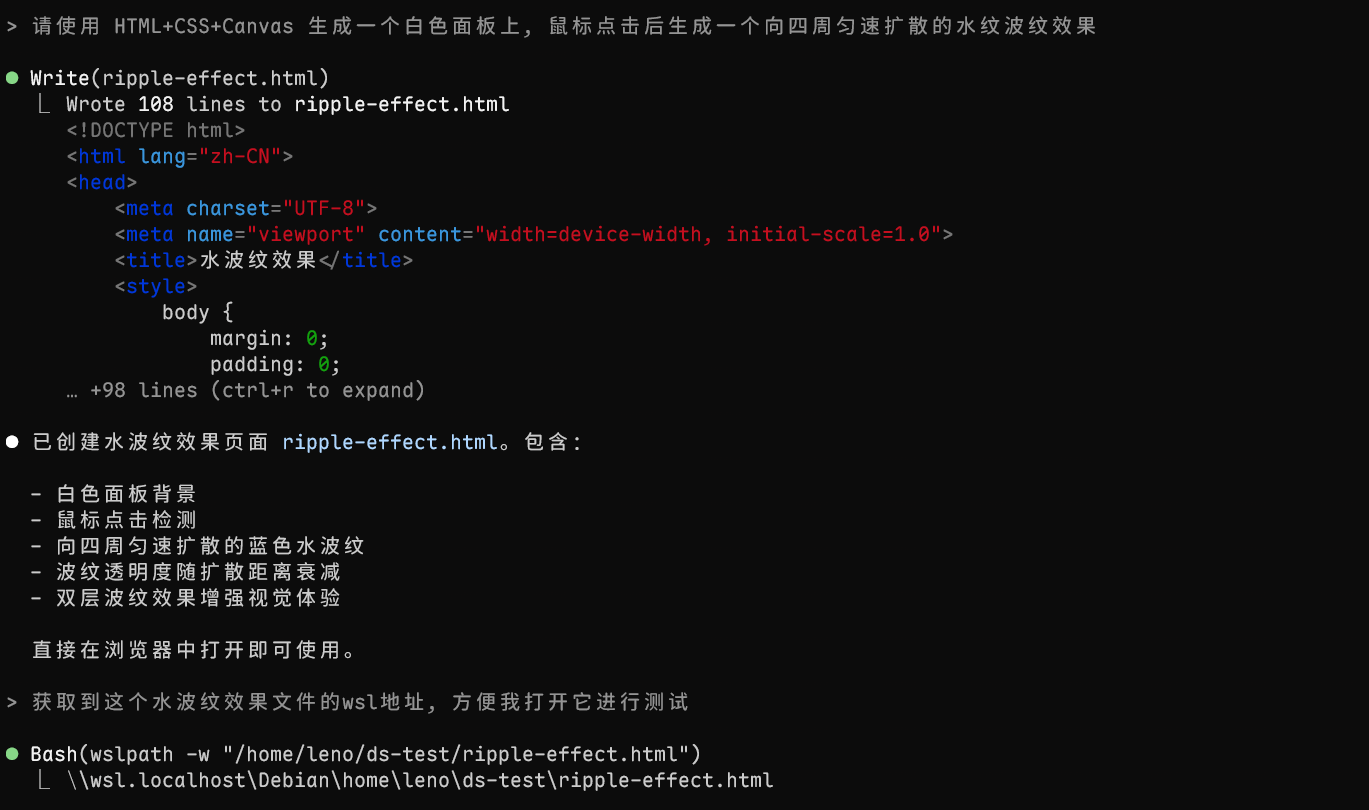
这样它就会生成你需要的代码, 测试效果一把过, 质量还是杠杠的, 很不错
总体使用感受
总体代码生成的质量很不错, 需求理解也是到位的, 现在的唯一缺陷是最大只能输出 32000 Tokens, 在对大任务和复杂需求的代码生成上力不从心, 生成速度也亟需提升,
总之, 目前处于一个基本能用的状态, 至少只要能正常生成, 代码质量和内容质量都会很高, 但离非常好用还有很多需要完善的地方
发现cursor只有订阅pro时才可自定义模型,所以免费使用cursor是不可能的了,基本功能都没法使用。
目前最便宜的方案可能还是 VS Code + Cline + Continue。然而问题出在 Continue 还没那么好用 …
Vue程序员(后端Go),最近高强度使用之后,现在来回答一波。
优点
量大管饱、便宜好用,第一梯队
网页版chat是免费的,注册就能用,目前应该是不消耗Token额度,比其chatGpt这种不可用的东西,用这个就绝对足够了。
目前用的免费赠送的10元额度,有效期一个月,这周高强度使用(疯狂加班周,每天干了12小时那种),每天消耗也不过五角钱。
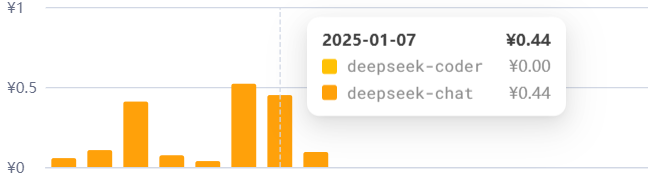
尝试一周之后就充值了100块,感觉还是很实惠的,加免费送的10元额度,估计能用一年(按工作日算)。
VS Code中Cline + Continue
DeepSeek Platform点击上面的链接,生成 api_key 之后分别在VS Code的插件 Cline 和 Continue 中配置即可,目前已提供了 DeepSeek的快捷配置了,看一下就能配。
使用体验:
- Cline 相当好用,与 cursor 的使用体验相差无几,问啥都能直接帮你操作好,无脑用就行;缺点是没有提供 tab 自动补全的功能,所以我需要同时用 Continue 来配合;
- Continue 就很差了,一个是体感延迟,编写代码时那种顿挫感,像是新手在开手动挡的汽车一样难受,另外就是类似于copilot内联chat那种功能,用起来感觉很不对,离完善还有一段很长的距离,基本处于能用的状态吧。
同样的,在生成 api_key 之后,将其配置到 cursor 中。这个是要打开 cursor settings,具体这样配置:
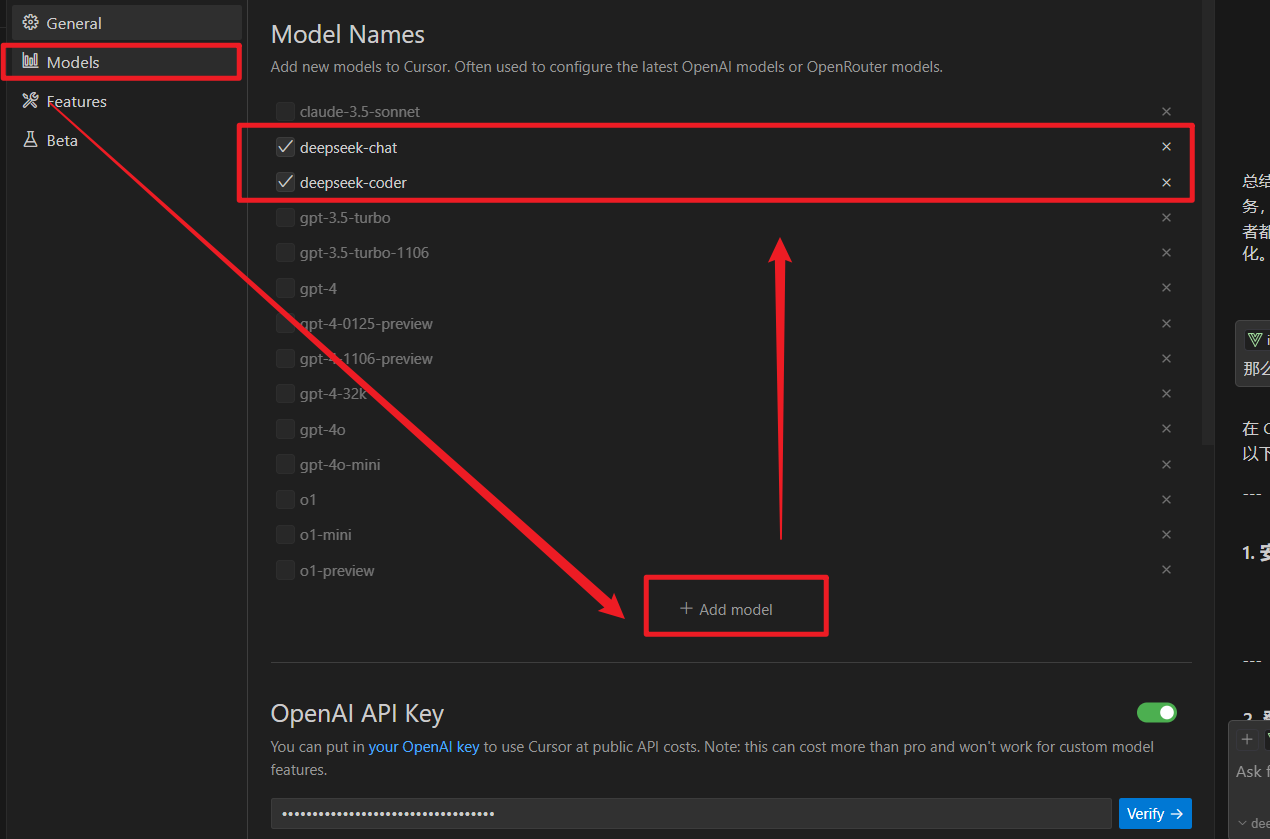
如图:点 Models,再点 Add model,我这添加了两个 deepseek-chat 和 deepseek-coder(评论区大佬说V3之后chat和coder合并了,那么现在配置只需要添加deepseek-chat即可)。
评论区大佬补充提醒:注意,要将其他模型都取消勾选再verify
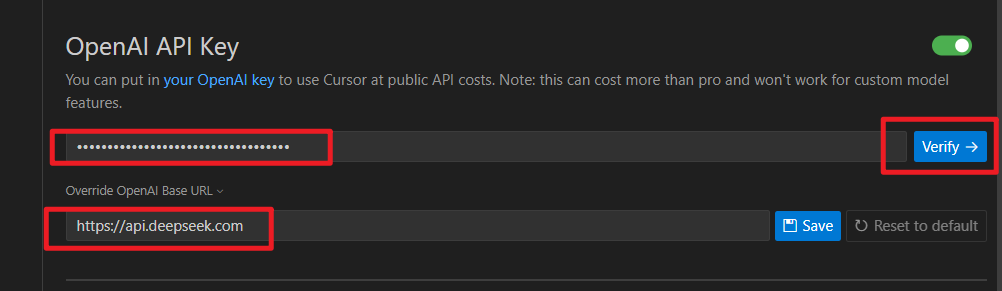
往下拉,在 Open API Key配置项这里将生成的 api_key 填进去,再用https://api.deepseek.com 覆盖Base URL,最后点击 Verify 校验通过,那么就能用了。

使用体验:
总体感觉 cursor 下的使用更优,tab 自动补全更加流畅,cursor chat 也好用,相比于 Cline + Continue 就好用在能够 cursor 的交互更为优秀和方便,不好用的地方就是 composer 不支持自定义了,这是挺大的缺陷,另外就是 cursor chat 下达了指令后要手动应用,这也是差点意思的地方。
最后
cursor + Cline 最终能够达到 cursor Pro 的效果,当然deepseek只用100块钱一年的事情,做到了1500元一年的事情正好契合了量大管饱、便宜好用的特点。
希望 deepseek 再接再厉,在使用插件和工具生态这方面也好好完善一下的话,我只能说:天下无敌。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/230394.html