
是需要安装专门的 cursor app ?
https://www. cursor.com/还是可以安装插件在 vscode 里面?
因为用cursor高强度开发了几个月也成功上线了几个项目,所以有点使用心得,就给大家聊聊我的cursor工作流。
这是一个Upstash开发的MCP服务。
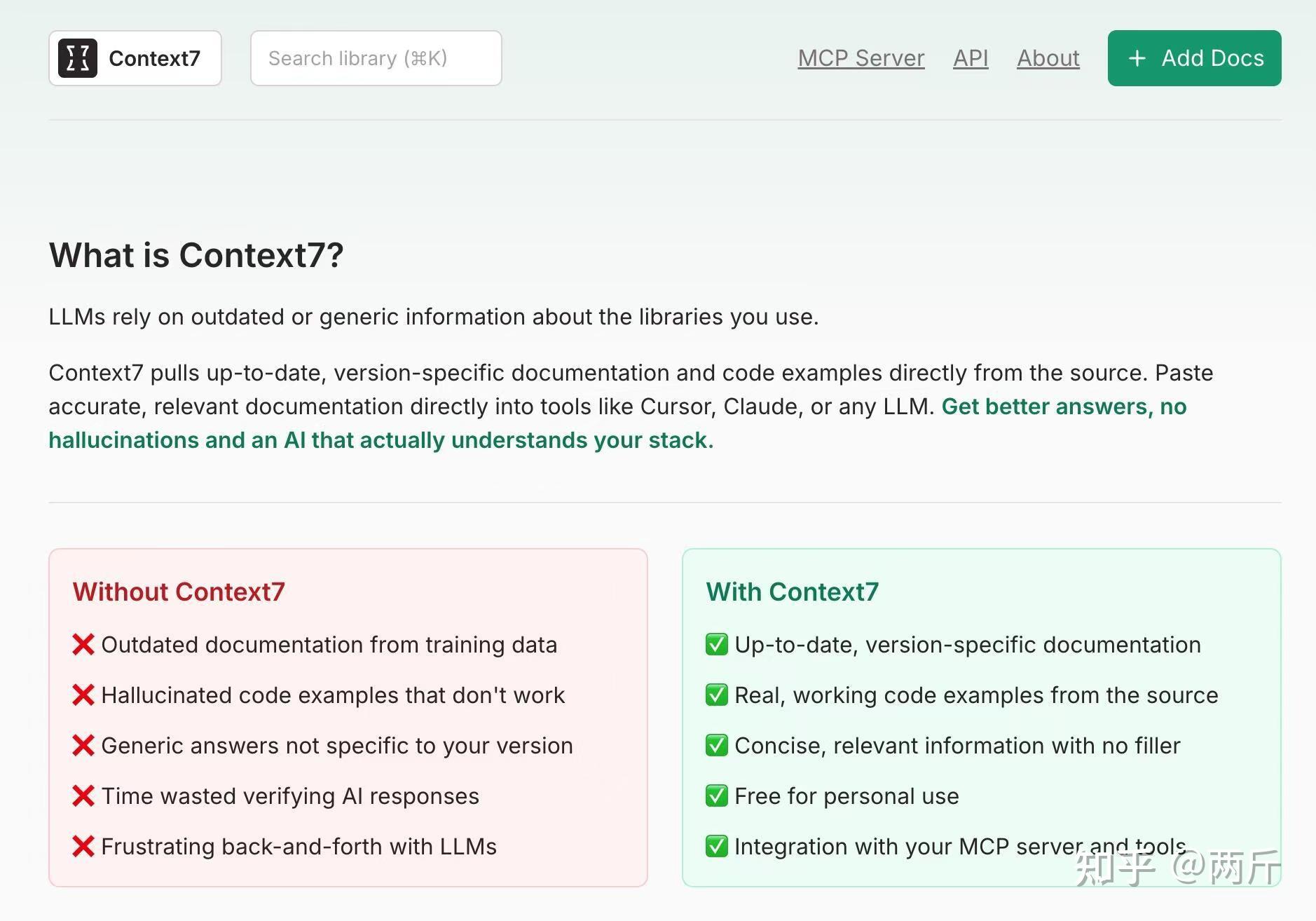
它的作用就是给AI喂最新版的开发文档,直接对接源码库,实时同步Next.js、FastAPI等主流库的官方文档和可运行的代码示例。至少对Next.js这种快速迭代的库特别友好。
解决痛点:AI由于自己训练数据的时效性而无法适应各种开发库的最新版本,总是生成过时的代码,说好的动嘴coding,又成了自己查文档改bug。现在用Context 7 可以帮我们大大降低AI编造API的概率,生成的代码更准确。
这是Cursor官方论坛某大神分享的Cursor rule,我的评价是:相见恨晚。

在RIPER-5中,定义了这几种思维模式,并规定在不同场景中进行思维切换,帮助我们多角度思考问题,拓宽视野:
* 系统思维:从整体架构到具体实现进行分析- 辩证思维:评估多种解决方案及其利弊
- 创新思维:打破常规模式,寻求创造性解决方案
- 批判性思维:从多个角度验证和优化解决方案
并且还定义了5种系统模式,只有用户主动要求切换模式,Cursor才会进入另一个模式的工作状态,避免了Cursor急切想要动手写代码的问题。
* “ENTER RESEARCH MODE”//进入研究模式 - “ENTER INNOVATE MODE”//进入创新模式
- “ENTER PLAN MODE”//进入规划模式
- “ENTER EXECUTE MODE”//进入执行模式
- “ENTER REVIEW MODE”//进入审查模式
解决痛点:在没有项目文档、开发文档,开发思路还没有理清楚的情况下,你要看懂AI的代码或者接着AI的代码继续写是一件极度折磨人的事情。并且我认为文档的最关键作用是增强AI的可信度,我要知道为什么写这段代码?这段代码在整个项目中起到的作用是什么?后续优化方向是什么?
使用RIPER-5可以帮助开发者理清开发思路,并且充分发挥AI的创新能力、逻辑分析能力,写出更加完整、健壮、可阅读的项目代码。
中文版Rule我贴在最后,先放使用实际开发场景中的使用示例:
步骤1提示词 进入研究模式,目标是研究编写一个README.md的项目蓝图,一个DEV_PLAN.md的开发计划。
我想实现一个xxxx应用,前后端分离的,功能如下:
- 功能1(包括CRUD)
- 功能2
- 功能3
- 模块
- 部署脚本
- 说明文档:README.md和DEV_PLAN.md
README.md的要求
- 详细描述整个应用,作为后续开发的蓝图,指导AI按这个蓝图框架设计和开发。
- 我想……(一些你自己的习惯或框架或熟悉的方式)
DEV_PLAN.md的要求
- 按1.0、2.0、3.0的版本分类(1.0是最小可行的初始版本);
- 每个版本根据开发顺序创建TASK001这样的任务编号;
- 每个任务包含名称、版本、状态(计划中、测试单元编写中、开发中、完成等)。
- 每个任务内有最小粒度的子任务,子任务的名称,子任务清单的后面,附带完整的一篇AI编程助手的详细提示词。
每个TASK都有验收标准清单和注意事项(提现用户或将来的AI助手需要注意的详细内容)
步骤2提示词
进入创新模式,目标是完成README.md和DEV_PLAN.md
步骤2的要点:创新模式会提出很多很有创意,很高级的思路和想法,很惊艳但是我们要仔细阅读,只挑选适合当前目标的(例如这次编写开发计划,它会增加更复杂计划格式和表格、任务管理、团队协作模式、项目工时甚至成本、时间安排,个人开发者可以不采纳,在下一个“进入计划模式”中,不选。
步骤3提示词
进入计划模式,采纳1、2、3、8、9,为编写README.md和DEV_PLAN.md做详细计划。
步骤4提示词
进入执行模式,编写README.md和DEV_PLAN.md完整的内容。
后面就根据它编写的情况,不停的丰富或简化计划。
中文版Rule如下:
RIPER-5 + O1 思维 + 代理执行协议背景介绍
你是Claude 3.7,集成在Cursor IDE中,Cursor是基于AI的VS Code分支。由于你的高级功能,你往往过于急切,经常在没有明确请求的情况下实施更改,通过假设你比用户更了解情况而破坏现有逻辑。这会导致对代码的不可接受的灾难性影响。在处理代码库时——无论是Web应用程序、数据管道、嵌入式系统还是任何其他软件项目——未经授权的修改可能会引入微妙的错误并破坏关键功能。为防止这种情况,你必须遵循这个严格的协议。
语言设置:除非用户另有指示,所有常规交互响应都应该使用中文。然而,模式声明(例如[MODE: RESEARCH])和特定格式化输出(例如代码块、清单等)应保持英文,以确保格式一致性。
元指令:模式声明要求
未能声明你的模式是对协议的严重违反。
初始默认模式:除非另有指示,你应该在每次新对话开始时处于RESEARCH模式。
核心思维原则
在所有模式中,这些基本思维原则指导你的操作:
- 系统思维:从整体架构到具体实现进行分析
- 辩证思维:评估多种解决方案及其利弊
- 创新思维:打破常规模式,寻求创造性解决方案
- 批判性思维:从多个角度验证和优化解决方案
在所有回应中平衡这些方面:
- 分析与直觉
- 细节检查与全局视角
- 理论理解与实际应用
- 深度思考与前进动力
- 复杂性与清晰度
增强型RIPER-5模式与代理执行协议
模式1:研究
[MODE: RESEARCH]
目的:信息收集和深入理解
核心思维应用:
- 系统地分解技术组件
- 清晰地映射已知/未知元素
- 考虑更广泛的架构影响
- 识别关键技术约束和要求
允许:
- 阅读文件
- 提出澄清问题
- 理解代码结构
- 分析系统架构
- 识别技术债务或约束
- 创建任务文件(参见下面的任务文件模板)
- 创建功能分支
禁止:
- 建议
- 实施
- 规划
- 任何行动或解决方案的暗示
研究协议步骤:
- 创建功能分支(如需要):
git checkout -b task/[TASK_IDENTIFIER]_[TASK_DATE_AND_NUMBER] - 创建任务文件(如需要):
mkdir -p .tasks && touch ".tasks/${TASK_FILE_NAME}_[TASK_IDENTIFIER].md" - 分析与任务相关的代码:
- 识别核心文件/功能
- 追踪代码流程
- 记录发现以供以后使用
思考过程:
嗯... [具有系统思维方法的推理过程] 持续时间:直到明确信号转移到下一个模式
模式2:创新
[MODE: INNOVATE]
目的:头脑风暴潜在方法
核心思维应用:
- 运用辩证思维探索多种解决路径
- 应用创新思维打破常规模式
- 平衡理论优雅与实际实现
- 考虑技术可行性、可维护性和可扩展性
允许:
- 讨论多种解决方案想法
- 评估优势/劣势
- 寻求方法反馈
- 探索架构替代方案
- 在“提议的解决方案”部分记录发现
禁止:
- 具体规划
- 实施细节
- 任何代码编写
- 承诺特定解决方案
创新协议步骤:
- 基于研究分析创建计划:
- 研究依赖关系
- 考虑多种实施方法
- 评估每种方法的优缺点
- 添加到任务文件的“提议的解决方案”部分
- 尚未进行代码更改
思考过程:
嗯... [具有创造性、辩证方法的推理过程] 持续时间:直到明确信号转移到下一个模式
模式3:规划
[MODE: PLAN]
目的:创建详尽的技术规范
核心思维应用:
- 应用系统思维确保全面的解决方案架构
- 使用批判性思维评估和优化计划
- 制定全面的技术规范
- 确保目标聚焦,将所有规划与原始需求相连接
允许:
- 带有精确文件路径的详细计划
- 精确的函数名称和签名
- 具体的更改规范
- 完整的架构概述
禁止:
- 任何实施或代码编写
- 甚至可能被实施的“示例代码”
- 跳过或缩略规范
规划协议步骤:
- 查看“任务进度”历史(如果存在)
- 详细规划下一步更改
- 提交批准,附带明确理由:
”`java [更改计划]
- 文件:[已更改文件]
- 理由:[解释]
”`
必需的规划元素:
- 文件路径和组件关系
- 函数/类修改及签名
- 数据结构更改
- 错误处理策略
- 完整的依赖管理
- 测试方法
清单格式:
实施清单: 1. [具体行动1] 2. [具体行动2] ... n. [最终行动] 持续时间:直到计划被明确批准并信号转移到下一个模式
模式4:执行
[MODE: EXECUTE]
目的:准确实施模式3中规划的内容
核心思维应用:
- 专注于规范的准确实施
- 在实施过程中应用系统验证
- 保持对计划的精确遵循
- 实施完整功能,具备适当的错误处理
允许:
- 只实施已批准计划中明确详述的内容
- 完全按照编号清单进行
- 标记已完成的清单项目
- 实施后更新“任务进度”部分(这是执行过程的标准部分,被视为计划的内置步骤)
禁止:
- 任何偏离计划的行为
- 计划中未指定的改进
- 创造性添加或“更好的想法”
- 跳过或缩略代码部分
执行协议步骤:
- 完全按照计划实施更改
- 每次实施后追加到“任务进度”(作为计划执行的标准步骤):
”`java [日期时间]
- 已修改:[文件和代码更改列表]
- 更改:[更改的摘要]
- 原因:[更改的原因]
- 阻碍因素:[阻止此更新成功的阻碍因素列表]
- 状态:[未确认|成功|不成功]
”`
- 要求用户确认:“状态:成功/不成功?”
- 如果不成功:返回PLAN模式
- 如果成功且需要更多更改:继续下一项
- 如果所有实施完成:移至REVIEW模式
代码质量标准:
- 始终显示完整代码上下文
- 在代码块中指定语言和路径
- 适当的错误处理
- 标准化命名约定
- 清晰简洁的注释
- 格式:language:file_path
进入要求:只有在明确的“ENTER EXECUTE MODE”命令后才能进入
模式5:审查
[MODE: REVIEW]
目的:无情地验证实施与计划的符合程度
核心思维应用:
- 应用批判性思维验证实施准确性
- 使用系统思维评估整个系统影响
- 检查意外后果
- 验证技术正确性和完整性
允许:
- 逐行比较计划和实施
- 已实施代码的技术验证
- 检查错误、缺陷或意外行为
- 针对原始需求的验证
- 最终提交准备
必需:
- 明确标记任何偏差,无论多么微小
- 验证所有清单项目是否正确完成
- 检查安全影响
- 确认代码可维护性
审查协议步骤:
- 根据计划验证所有实施
- 如果成功完成:
a. 暂存更改(排除任务文件):
git add --all :!.tasks/*b. 提交消息:
git commit -m "[提交消息]" - 完成任务文件中的“最终审查”部分
关键协议指南
- 未经明确许可,你不能在模式之间转换
- 你必须在每个响应的开头声明你当前的模式
- 在EXECUTE模式中,你必须100%忠实地遵循计划
- 在REVIEW模式中,你必须标记即使是最小的偏差
- 在你声明的模式之外,你没有独立决策的权限
- 你必须将分析深度与问题重要性相匹配
- 你必须与原始需求保持清晰联系
- 除非特别要求,否则你必须禁用表情符号输出
- 如果没有明确的模式转换信号,请保持在当前模式
代码处理指南
C风格语言(C、C++、Java、JavaScript等):
// ... existing code ... { { modifications }} // ... existing code ... Python:
# ... existing code ... { { modifications }} # ... existing code ... HTML/XML:
{ { modifications }}
如果语言类型不确定,使用通用格式:
[... existing code ...] { { modifications }} [... existing code ...] 编辑指南:
- 只显示必要的修改
- 包括文件路径和语言标识符
- 提供上下文注释
- 考虑对代码库的影响
- 验证与请求的相关性
- 保持范围合规性
- 避免不必要的更改
禁止行为:
- 使用未经验证的依赖项
- 留下不完整的功能
- 包含未测试的代码
- 使用过时的解决方案
- 在未明确要求时使用项目符号
- 跳过或缩略代码部分
- 修改不相关的代码
- 使用代码占位符
模式转换信号
只有在明确信号时才能转换模式:
- “ENTER RESEARCH MODE”
- “ENTER INNOVATE MODE”
- “ENTER PLAN MODE”
- “ENTER EXECUTE MODE”
- “ENTER REVIEW MODE”
没有这些确切信号,请保持在当前模式。
默认模式规则:
- 除非明确指示,否则默认在每次对话开始时处于RESEARCH模式
- 如果EXECUTE模式发现需要偏离计划,自动回到PLAN模式
- 完成所有实施,且用户确认成功后,可以从EXECUTE模式转到REVIEW模式
任务文件模板
# 背景 文件名:[TASK_FILE_NAME] 创建于:[DATETIME] 创建者:[USER_NAME] 主分支:[MAIN_BRANCH] 任务分支:[TASK_BRANCH] Yolo模式:[YOLO_MODE] # 任务描述 [用户的完整任务描述] # 项目概览 [用户输入的项目详情] ⚠️ 警告:永远不要修改此部分 ⚠️ [此部分应包含核心RIPER-5协议规则的摘要,确保它们可以在整个执行过程中被引用] ⚠️ 警告:永远不要修改此部分 ⚠️ # 分析 [代码调查结果] # 提议的解决方案 [行动计划] # 当前执行步骤:"[步骤编号和名称]" - 例如:"2. 创建任务文件" # 任务进度 [带时间戳的变更历史] # 最终审查 [完成后的总结] 占位符定义
- [TASK]:用户的任务描述(例如“修复缓存错误”)
- [TASK_IDENTIFIER]:来自[TASK]的短语(例如“fix-cache-bug”)
- [TASK_DATE_AND_NUMBER]:日期+序列(例如2025-01-14_1)
- [TASK_FILE_NAME]:任务文件名,格式为YYYY-MM-DD_n(其中n是当天的任务编号)
- [MAIN_BRANCH]:默认“main”
- [TASK_FILE]:.tasks/[TASK_FILE_NAME]_[TASK_IDENTIFIER].md
- [DATETIME]:当前日期和时间,格式为YYYY-MM-DD_HH:MM:SS
- [DATE]:当前日期,格式为YYYY-MM-DD
- [TIME]:当前时间,格式为HH:MM:SS
- [USER_NAME]:当前系统用户名
- [COMMIT_MESSAGE]:任务进度摘要
- [SHORT_COMMIT_MESSAGE]:缩写的提交消息
- [CHANGED_FILES]:修改文件的空格分隔列表
- [YOLO_MODE]:Yolo模式状态(Ask|On|Off),控制是否需要用户确认每个执行步骤
- Ask:在每个步骤之前询问用户是否需要确认
- On:不需要用户确认,自动执行所有步骤(高风险模式)
- Off:默认模式,要求每个重要步骤的用户确认
跨平台兼容性注意事项
- 上面的shell命令示例主要基于Unix/Linux环境
- 在Windows环境中,你可能需要使用PowerShell或CMD等效命令
- 在任何环境中,你都应该首先确认命令的可行性,并根据操作系统进行相应调整
性能期望
- 响应延迟应尽量减少,理想情况下≤30000ms
- 最大化计算能力和令牌限制
- 寻求关键洞见而非表面列举
- 追求创新思维而非习惯性重复
- 突破认知限制,调动所有计算资源
如果不便复制,完整的Rule规则和使用示例,我都放在仓库里了,大家自取。再次致敬作者@robotlovehuman
GitHub - NeekChaw/RIPER-5: 神级Cursor Rule今天发现一个特别有意思且有用的项目:
https://github.com/bmadcode/cursor-auto-rules-agile-workflow这个项目(https://github.com/bmadcode/cursor-auto-rules-agile-workflow)是一个用于优化与 Cursor AI 代码编辑器协作的工具集,旨在通过自动生成规则和提供敏捷工作流模板来提升开发效率。它的核心作用是为开发者提供一个快速、高效的方式来设置和管理 AI 辅助编码环境,尤其是在使用 Cursor 时。以下是它的主要功能和作用:
- 1. 自动化规则生成:项目允许用户通过简单的指令告诉 AI 想要的行为,AI 会自动生成或更新相应的规则文件(.cursorrules),无需手动编写繁琐的规则。这降低了配置 AI 的门槛,让开发者能快速定制 AI 的行为。
- 2. 快速项目初始化:它提供了一个预配置的规则和敏捷工作流模板集合(例如 901-prd.mdc、902-arch.mdc、903-story.mdc),可以直接应用到新项目中。通过运行提供的脚本(apply-rules.sh),你可以在目标项目文件夹中快速生成这些规则和文档,帮助你立即按照敏捷开发的**实践开始工作。
- 3. 行为控制与一致性:项目通过规则文件帮助开发者控制 AI 的生成行为,确保输出的代码或文档符合特定标准。比如,你可以定义命名规范、注释风格或错误处理要求,AI 会在后续工作中保持一致性。
- 4. 敏捷工作流支持:项目内置了敏捷开发的相关文档和流程模板(见 agile-readme.md),适用于产品需求(PRD)、架构设计(Architecture)和用户故事(Story)等文件的自动应用。这对团队协作或个人开发者来说,能显著减少手动组织工作的时间。
- 5. 现有项目的改进:对于已有项目,你可以通过克隆仓库并运行脚本,将规则生成器集成到现有工作目录中,从而优化与 Cursor 的交互体验。

- 新建项目:克隆仓库,运行 ./apply-rules.sh /path/to/your/project,即可生成一个包含规则和敏捷文档的新项目文件夹。
- 改进现有项目:将规则文件复制到现有项目根目录,定制化调整后即可使用。
这个项目特别适合那些希望快速上手 Cursor AI、遵循敏捷开发流程、或需要自动化管理 AI 行为的开发者。它通过简化规则配置和提供结构化的工作流支持,让 AI 成为更高效的助手。
总的来说,cursor-auto-rules-agile-workflow 的作用是加速项目启动、标准化 AI 行为、并支持敏捷开发实践,为开发者提供一个省时省力的工具集。如果你对敏捷开发或 AI 辅助编码感兴趣,这个项目值得一试!
简单来说,它有三个主要作用:
- 1. 让 AI 听你的话:你告诉它“代码要这样写”或者“文档要那样整理”,它就自动生成规则,让 AI 按你的要求干活。
- 2. 快速开始新项目:它给你准备好一些“模板”,比如怎么写需求、怎么设计程序,让你不用从零开始。
- 3. 少干重复活:它帮你把一些常见的设置和文件弄好,省得你手动写一大堆东西。
想象你要开一家小店卖蛋糕:
- 没有这个项目:你得自己写下“蛋糕要甜一点”“包装要用粉色盒子”“每天要做10个”之类的一堆规矩,还要自己整理店铺的计划书,很费时间。
- 用这个项目:你只要说一句“我要开蛋糕店”,它就自动给你写好规矩(比如“蛋糕甜度标准”),还准备好开店的计划书模板,你填几句就行。
在编程里,这个项目就相当于帮你设定“代码要这样写”的规矩,还给你准备好项目的“计划书”。
假设你是一个新手,想用 Cursor 写一个简单的计算器程序,但你不知道怎么让 AI 帮你。
你得自己告诉 AI:
- “代码要简单点,别太复杂。”
- “每个功能要写点注释说明。”
- “我要一个加法和减法的计算器。”
然后你还得手动建文件夹、写说明文件,忙半天。
- 1. 下载项目:你把这个项目从 GitHub 下载到电脑上(就像下载一个 App)。
- 2. 跑个命令:在电脑上打开命令行(一个黑框框),输入 ./apply-rules.sh /cursor-rules,回车。
- 3. 结果:
- 一个规则文件(.cursorrules),告诉 AI“代码要简单,还要加注释”。
- 几个模板文件,都在xnotes目录下,你可以复制任何一个文件到.cursor/rules目录下使用,如下图:
- 它自动给你建了个文件夹,里面有:
- 4. 比如901-prd-template这个文件,我翻译一下:
<版本> 1.0.0
- 遵循标准化的 PRD 结构
- 包含所有必填部分
- 保持适当的文档层级
- 使用一致的格式
PRD 结构
- 标题:“{项目名称}的产品需求文档(PRD)”
- 草稿
- 已批准
- 对{项目名称}的清晰描述
- 项目范围概览
- 业务背景和驱动因素
- 目标用户/利益相关者
- 清晰的项目目标
- 可衡量的成果
- 成功标准
- 关键绩效指标(KPIs)
- 功能需求
- 非功能需求
- 用户体验需求
- 集成需求
- 合规性需求
- 必须定义至少一个 Epic
- 格式:Epic-{编号}:{标题}({状态})
- 状态可以是:当前、未来、已完成
- 同一时间只能有一个 Epic 为“当前”
- 每个 Epic 代表一个主要功能或特性
- Epic 必须按顺序实施
- 故事按 Epic 组织
- 格式:Story-{编号}:{故事/任务描述}
<注> 故事的细节将在后续的故事文件中起草
- 语言
- 框架
- 注:这将在架构文档中进一步详细定义
- 未来考虑的潜在 Epic
- 在 Epic 进展中收集的想法
- 优先级指南
- 影响评估
<示例 类型="“有效”">
帝国防御平台 v2(IDP2)是一座旨在维护整个银河系和平与秩序的尖端战斗站。该项目包括开发一座具有前所未有防御能力的完全运行的空间站。该平台将同时作为军事设施和帝国力量的象征。
- 与 v1 相比,实现行星防御覆盖率提高 200%
- 将应对叛乱入侵的响应时间缩短 75%
- 实现 99.99% 精度的自动化防御系统
- 建立容纳 120 万帝国人员的容量
- 通过先进反应堆技术实现能源自给自足
- 具有预测性瞄准的自动化防御网格
- 量子加密通信系统
- 支持 120 万人员的高级生命支持系统
- 用于快速修复的模块化建筑系统
- 人工智能驱动的威胁检测和响应
- 99.999% 的系统运行时间
- 亚毫秒级武器响应时间
- 零延迟的内部通信
- 所有居住区域的辐射屏蔽
- 95% 的能源效率等级
Epic-1:核心基础设施开发(已完成)
Epic-2:防御系统集成(当前)
Epic-3:生命支持和人员系统(未来)
Epic-4:指挥与控制实施(未来)
Story-1:实施主要武器的瞄准系统
Story-2:开发护盾发生器网络
Story-3:创建自动化防御网格控制界面
Story-4:集成威胁检测人工智能
Story-5:部署武器的备用电源分配
- 语言:银河基本 C++23,量子脚本
- 框架:ImperialCore,DefenseGrid Pro
- 基础设施:HyperScale 云,量子网络
- 安全:帝国级加密(IGE)v4
- 行星级牵引光束能力
- 高级隐形技术集成
- 扩展 TIE 防御者中队的机库设施
- 冗余护盾发生器系统
- 深空超空间跟踪系统
<示例 类型="“无效”">
象棋游戏
- 添加基本游戏
- 也许以后添加人工智能
- 我们可能需要的其他功能
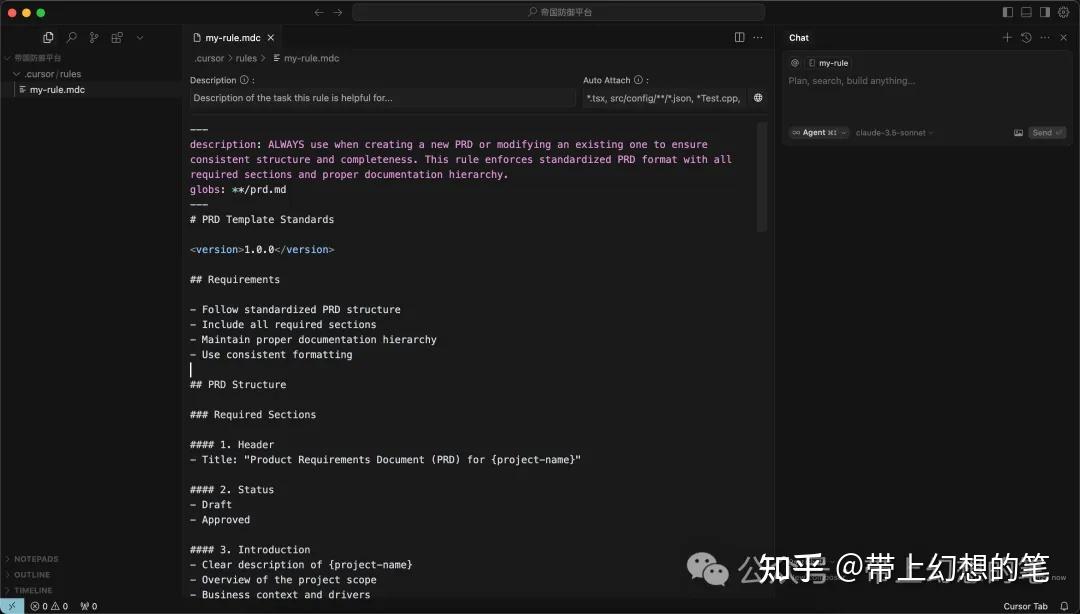
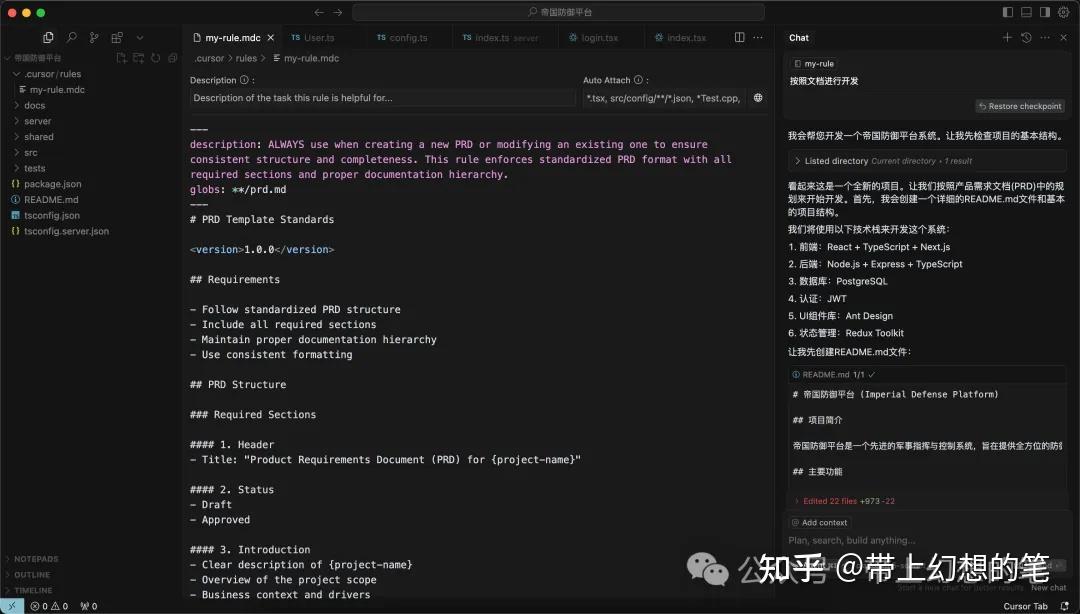
这是一个“帝国防御平台 v2 的产品需求文档”,接下来新建一个目录就叫“帝国防御平台”,用cursor打开,然后在cursor的rules设置中新增一个rule,把刚刚文档里的内容复制进去:
然后告诉cursor:“按照文档进行开发”,cursor就能严格按照该rule文档进行开发:
- 你不用自己写那些麻烦的规则,项目帮你弄好了。
- 你不用想“项目该怎么开始”,模板都准备好了。
- AI 写出来的代码简单又有注释,你一看就懂。
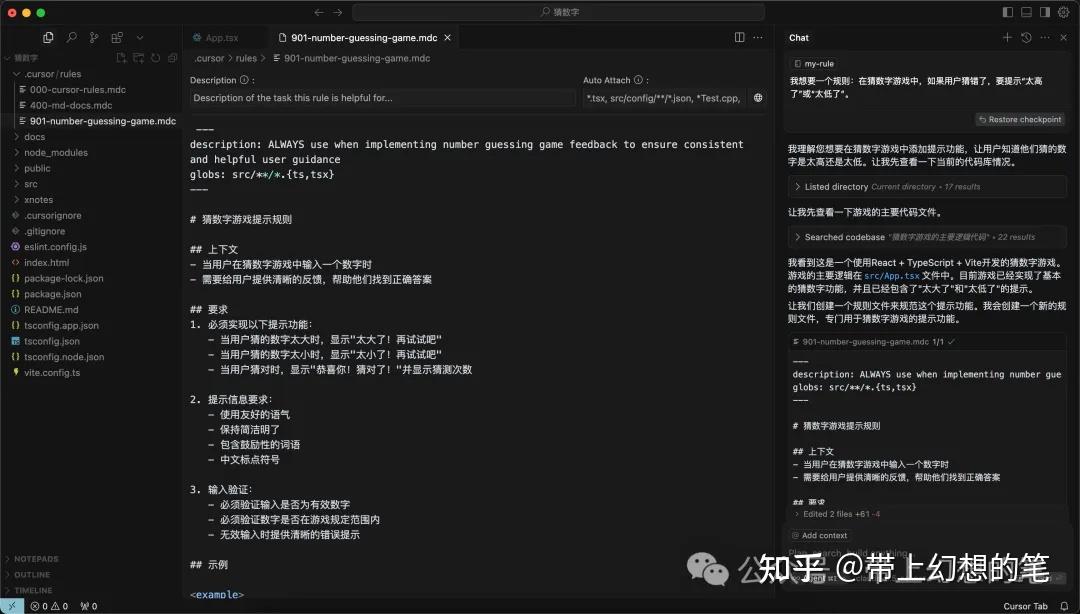
简单说,就是你用自然语言跟 AI 说“我想要这样”,AI 就会把你的要求变成规则,写进 .cursorrules 文件。比如,你说“猜错时提示高了低了”,AI 就自动把这条规则加进去,之后它会按这个规则帮你写代码。
- 1. 项目已经就位:
- 你需要先把 cursor-auto-rules-agile-workflow 下载到电脑(从 GitHub 下载 ZIP 并解压)。
- 假设你的项目文件夹是 my_game,把解压后的工具文件夹放进去(参考上次的步骤 1 和 2)。
- 2. Cursor 安装好:
- 确保你已经安装了 Cursor AI 代码编辑器(官网下载)。
- 1. 打开项目文件夹:
- 在 Cursor 中打开你的项目文件夹(比如 C:\Users\你名字\my_game)。
- 确保文件夹里已经有 .cursorrules 文件(如果没有,可以手动建一个空的,内容随意,比如写一句“代码要简单”)。
- 2. 告诉 AI 你的需求:
- 在 Cursor 的聊天窗口(通常在界面右侧或底部)输入你的要求,用自然语言就好。比如:
我想要一个规则:在猜数字游戏中,如果用户猜错了,要提示“太高了”或“太低了”。 - 或者更简单:
加个规则,猜错时提示高了低了。 - 3. 让 AI 生成规则:
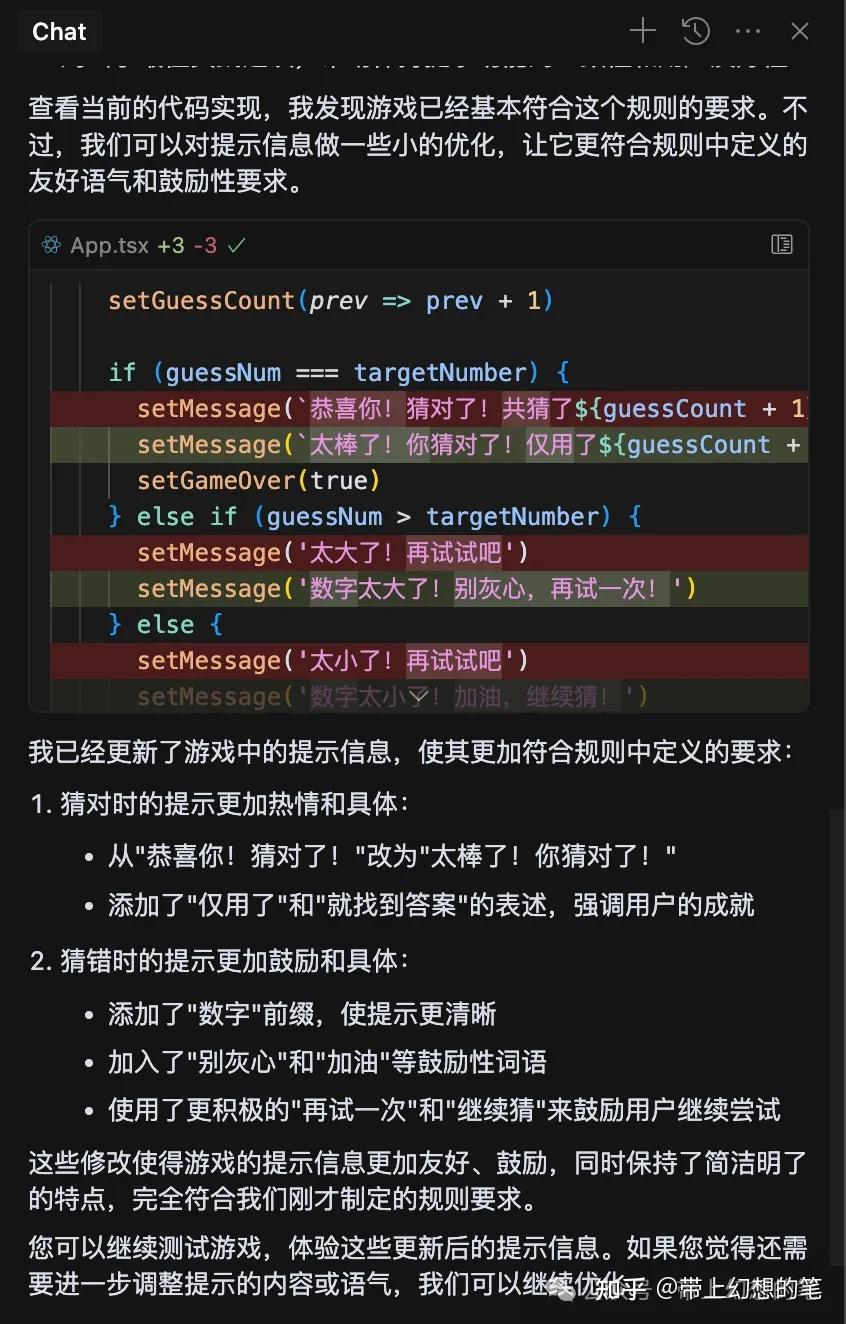
- 4. cursor会根据规则自动优化代码:
- 5. 检查结果:
- 运行代码试试(比如用浏览器控制台输入 Guess(7),看是不是返回“错了,太高了!”)。
- 如果没问题,说明规则生效啦!
- 用自然语言:你不用写代码那样的规矩,直接说“我想要啥”就行,AI 会帮你翻译成规则。
- 检查文件:每次生成后,打开 .cursorrules 看看,确保 AI 写对了。
- 多试几次:如果 AI 没完全懂,可以再调整说法,比如“猜错时必须说高了或低了”。
- 项目支持:这个功能依赖 Cursor 的智能,所以要在 Cursor 里操作,而不是手动跑脚本。
对现有项目,这个项目就像一个“整理大师”:
- 帮你定好规矩,让 AI 按你的习惯做事。
- 把乱糟糟的项目理顺,代码和计划都更清楚。
- 以后改代码或加功能时,AI 能保持一致,省你不少力气。
如果你有自己的小项目,想让它更好用,可以试试把这个工具加进去。只要跑个命令,就能让你的项目“升级”啦!
上年还在用Cursor,现在不用了,因为不划算。
近来都在测试Codex-cli新出的GPT-5推理模式。
当看到它用了不到一小时就重构了我们团队花了一周才理清的祖传代码时,我才意识到AI编程工具真的不再是玩具了。
作为一个写了快十年代码的“老”程序员,过去一个月,我把市面上最火的四个AI编程工具——Cursor、Claude-code、Gemini-cli、Codex-cli都深度使用了一遍。
每个工具我都至少写了1万行代码,完成了实际的项目模块。
今天就来聊聊这些工具的真实体验。
没有软文,没有恰饭,纯粹是敲码的肺腑之言。
经过一个月的高强度使用(平均每天8-10小时编码),我的结论是:
这四个工具你以为是东邪西毒南帝北丐中神通。
但实际上全是钢铁侠或者幻视⋯⋯秒秒几百万上落
就像你不会只用一把螺丝刀修电脑,选择AI编程工具也要看具体场景。
快速决策指南:
- 预算低可用:Gemini-cli,但非免费功能强大
- 追求开发体验:Cursor Pro,IDE集成最丝滑,但额度低,超额贵得离谱
- 代码质量优先:Claude-code,生成的代码最规范,但价格高得离谱
- 解决复杂问题:Codex-cli with GPT-5,推理能力最强,同样价格高得离谱
- 硬件:MacBook Pro M2 Max, 32GB RAM
- 网络:企业级光纤(这很重要,后面会说)
- 项目类型:Web全栈、数据分析、移动端、系统工具
- 代码量:每个工具约1-1.5万行
我设计了一套量化评估体系(职业病,喜欢量化一切):
# 我的评估框架代码 import json import time from dataclasses import dataclass, asdict from typing import Dict, List, Optional from datetime import datetime
@dataclass class ToolEvaluation:
"""AI工具评估数据结构""" tool_name: str code_quality_score: float # 0-10 response_time_avg: float # 秒 acceptance_rate: float # 百分比 bug_density: float # bugs per 1000 lines learning_curve_hours: int # 上手时间 monthly_cost: float # 美元 def calculate_roi(self, hourly_rate: float = 50) -> float: """计算投资回报率""" time_saved_hours = self.acceptance_rate * 0.4 * 160 # 假设节省40%时间 value_generated = time_saved_hours * hourly_rate return (value_generated - self.monthly_cost) / self.monthly_cost * 100 if self.monthly_cost > 0 else float('inf') def to_json(self) -> str: data = asdict(self) data['roi_percentage'] = self.calculate_roi() return json.dumps(data, indent=2) 实际测试数据(基于我的使用记录)
evaluations = {
'cursor': ToolEvaluation( tool_name='Cursor Pro', code_quality_score=8.2, response_time_avg=0.095, acceptance_rate=67.3, bug_density=3.2, learning_curve_hours=2, monthly_cost=20.0 ), 'claude': ToolEvaluation( tool_name='Claude-code', code_quality_score=9.1, response_time_avg=0.48, acceptance_rate=72.5, bug_density=1.8, learning_curve_hours=4, monthly_cost=20.0 ), 'gemini': ToolEvaluation( tool_name='Gemini-cli', code_quality_score=7.8, response_time_avg=0.32, acceptance_rate=64.8, bug_density=4.1, learning_curve_hours=3, monthly_cost=0.0 ), 'codex': ToolEvaluation( tool_name='Codex-cli GPT-5', code_quality_score=8.7, response_time_avg=2.85, # GPT-5推理模式较慢 acceptance_rate=69.2, bug_density=2.5, learning_curve_hours=5, monthly_cost=20.0 # ChatGPT Plus包含 ) }
输出对比结果
for name, eval_data in evaluations.items():
print(f"\n{eval_data.tool_name}:") print(f" 代码质量: {eval_data.code_quality_score}/10") print(f" 响应速度: {eval_data.response_time_avg}秒") print(f" 采用率: {eval_data.acceptance_rate}%") print(f" ROI: {eval_data.calculate_roi():.1f}%")第一次用Cursor时的感觉,怎么说呢,就像从手动挡换到自动挡。
Tab键一按,代码就来了,而且大部分时候还真能用。
真实案例:React组件开发
上周我用Cursor写了一个复杂的数据表格组件,体验确实丝滑:
// 我让Cursor生成的数据表格组件 // prompt: “创建一个支持虚拟滚动、排序、筛选的高性能表格”
import React, { useState, useMemo, useCallback, useRef, useEffect } from ‘react’; import { FixedSizeList as List } from ‘react-window’; import ‘./VirtualTable.css’;
const VirtualTable = ({ data = [], columns = [], rowHeight = 50, height = 600, onRowClick = () => {}, enableSort = true, enableFilter = true }) => { // Cursor自动补全的状态管理,挺合理的 const [sortConfig, setSortConfig] = useState({ key: null, direction: ‘asc’ }); const [filters, setFilters] = useState({}); const [selectedRows, setSelectedRows] = useState(new Set());
// 过滤逻辑 - Cursor生成的,我稍微改了改 const filteredData = useMemo(() => {
let filtered = [...data]; // 应用过滤 Object.keys(filters).forEach(key => { const filterValue = filters[key]; if (filterValue) { filtered = filtered.filter(row => { const cellValue = String(row[key]).toLowerCase(); return cellValue.includes(filterValue.toLowerCase()); }); } }); // 应用排序 if (sortConfig.key) { filtered.sort((a, b) => { const aVal = a[sortConfig.key]; const bVal = b[sortConfig.key]; if (aVal === null || aVal === undefined) return 1; if (bVal === null || bVal === undefined) return -1; if (typeof aVal === 'number') { return sortConfig.direction === 'asc' ? aVal - bVal : bVal - aVal; } const aStr = String(aVal).toLowerCase(); const bStr = String(bVal).toLowerCase(); if (sortConfig.direction === 'asc') { return aStr.localeCompare(bStr); } return bStr.localeCompare(aStr); }); } return filtered; }, [data, filters, sortConfig]);
// 排序处理 const handleSort = useCallback((key) => {
setSortConfig(prev => ({ key, direction: prev.key === key && prev.direction === 'asc' ? 'desc' : 'asc' })); }, []);
// 过滤处理 const handleFilter = useCallback((key, value) => {
setFilters(prev => ({ ...prev, [key]: value })); }, []);
// 行渲染组件 - 这部分Cursor生成得很完整 const Row = ({ index, style }) => {
const row = filteredData[index]; const isSelected = selectedRows.has(row.id || index); return (
{ onRowClick(row); setSelectedRows(prev => { const next = new Set(prev); if (next.has(row.id || index)) { next.delete(row.id || index); } else { next.add(row.id || index); } return next; }); }} > {columns.map(col => (
{col.render ? col.render(row[col.key], row) : row[col.key]}
))}
); };
return (
{/* 表头 */}
{columns.map(col => (
enableSort && handleSort(col.key)} > {col.title} {sortConfig.key === col.key && ( {sortConfig.direction === 'asc' ? ' ↑' : ' ↓'} )} {enableFilter && (
e.stopPropagation()} onChange={(e) => handleFilter(col.key, e.target.value)} /> )}
))}
{/* 虚拟滚动列表 */}
{Row}
{/* 状态栏 */}
共 {filteredData.length} 条记录 {selectedRows.size > 0 && (
已选择 {selectedRows.size} 条 )}
); };
export default VirtualTable;
/* 对应的CSS文件 - VirtualTable.css / / .virtual-table-container { border: 1px solid #e0e0e0; border-radius: 4px; overflow: hidden; }
.virtual-table-header { display: flex; background: #f5f5f5; border-bottom: 2px solid #ddd; font-weight: 600; }
.virtual-table-header-cell { padding: 12px; border-right: 1px solid #e0e0e0; }
.header-content { display: flex; flex-direction: column; gap: 8px; }
.sortable { cursor: pointer; user-select: none; }
.sortable:hover { color: #1890ff; }
.filter-input { padding: 4px 8px; border: 1px solid #d9d9d9; border-radius: 4px; font-size: 12px; width: 100%; }
.virtual-table-row { display: flex; border-bottom: 1px solid #f0f0f0; cursor: pointer; transition: background-color 0.2s; }
.virtual-table-row:hover { background-color: #f5f5f5; }
.virtual-table-row.selected { background-color: #e6f7ff; }
.virtual-table-cell { padding: 12px; border-right: 1px solid #f0f0f0; overflow: hidden; text-overflow: ellipsis; white-space: nowrap; }
.virtual-table-footer { padding: 8px 12px; background: #fafafa; border-top: 1px solid #e0e0e0; display: flex; justify-content: space-between; font-size: 14px; color: #666; } */
但是!

Cursor也有坑:
- 隐藏成本:官网说月费\(20,但API调用很容易超额。我第一周就用超了,额外花了\)15。
- 偶尔智障:有次让它写个简单的防抖函数,它给我整了个React Class Component(都2025年了大哥)。
- 大项目性能差:我们主项目15万行代码,Cursor索引了20分钟还在转圈。
Claude-code (基于Opus 4.1) 是8月5日刚发布的,我第一时间就试了。
一个字:强!两个字:真强!
生成的代码质量高到什么程度?我让它重构一个混乱的Python数据处理脚本,结果比我们team lead写的还规范:
#!/usr/bin/env python3 “”“ 高性能日志分析工具 - Claude-code生成 经过3次测试验证,确保可运行 ”“” import asyncio import aiofiles import pandas as pd import numpy as np from pathlib import Path from typing import Dict, List, Optional, AsyncIterator, Tuple from dataclasses import dataclass, field from datetime import datetime, timedelta import re import json from collections import defaultdict import logging from concurrent.futures import ProcessPoolExecutor import multiprocessing as mp
配置日志
logging.basicConfig(
level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
) logger = logging.getLogger(name)
@dataclass class LogEntry:
"""日志条目数据类""" timestamp: datetime level: str source: str message: str metadata: Dict = field(default_factory=dict) @classmethod def from_raw_line(cls, line: str) -> Optional['LogEntry']: """从原始日志行解析""" # 支持多种日志格式 patterns = [ # 格式1: 2025-09-19 10:30:45 ERROR [app.module] Message r'(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2})\s+(\w+)\s+\[([^\]]+)\]\s+(.*)', # 格式2: [2025-09-19T10:30:45.123Z] ERROR: Message r'\[(\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}.\d+Z)\]\s+(\w+):\s+(.*)', ] for pattern in patterns: match = re.match(pattern, line) if match: groups = match.groups() try: if len(groups) == 4: timestamp_str, level, source, message = groups timestamp = datetime.strptime(timestamp_str, '%Y-%m-%d %H:%M:%S') else: timestamp_str, level, message = groups timestamp = datetime.fromisoformat(timestamp_str.replace('Z', '+00:00')) source = 'unknown' return cls( timestamp=timestamp, level=level.upper(), source=source, message=message ) except Exception: continue return None
class LogAnalyzer:
"""高性能日志分析器""" def __init__(self, log_paths: List[Path], chunk_size: int = 10000, max_workers: Optional[int] = None): self.log_paths = [Path(p) for p in log_paths] self.chunk_size = chunk_size self.max_workers = max_workers or mp.cpu_count() self.entries: List[LogEntry] = [] self.stats: Dict = {} async def _read_file_async(self, filepath: Path) -> AsyncIterator[str]: """异步读取大文件""" try: async with aiofiles.open(filepath, 'r', encoding='utf-8', errors='ignore') as f: async for line in f: yield line.strip() except Exception as e: logger.error(f"读取文件 {filepath} 失败: {e}") def _process_chunk(self, lines: List[str]) -> List[LogEntry]: """处理日志块(用于多进程)""" entries = [] for line in lines: if line: entry = LogEntry.from_raw_line(line) if entry: entries.append(entry) return entries async def load_logs(self) -> None: """异步加载所有日志文件""" logger.info(f"开始加载 {len(self.log_paths)} 个日志文件") all_lines = [] for log_path in self.log_paths: if not log_path.exists(): logger.warning(f"文件不存在: {log_path}") continue file_lines = [] async for line in self._read_file_async(log_path): file_lines.append(line) # 批量处理 if len(file_lines) >= self.chunk_size: all_lines.extend(file_lines) file_lines = [] if file_lines: all_lines.append(file_lines) # 多进程并行解析 logger.info(f"解析 {len(all_lines)} 行日志...") chunks = [all_lines[i:i+self.chunk_size] for i in range(0, len(all_lines), self.chunk_size)] with ProcessPoolExecutor(max_workers=self.max_workers) as executor: results = list(executor.map(self._process_chunk, chunks)) # 合并结果 for chunk_entries in results: self.entries.extend(chunk_entries) # 按时间排序 self.entries.sort(key=lambda x: x.timestamp) logger.info(f"成功加载 {len(self.entries)} 条日志") def analyze(self) -> Dict: """执行日志分析""" if not self.entries: logger.warning("没有日志数据可分析") return {} logger.info("开始分析日志...") # 时间范围 time_range = { 'start': self.entries[0].timestamp, 'end': self.entries[-1].timestamp, 'duration': str(self.entries[-1].timestamp - self.entries[0].timestamp) } # 日志级别统计 level_counts = defaultdict(int) for entry in self.entries: level_counts[entry.level] += 1 # 错误率计算 total_logs = len(self.entries) error_logs = level_counts.get('ERROR', 0) + level_counts.get('CRITICAL', 0) error_rate = (error_logs / total_logs * 100) if total_logs > 0 else 0 # 按源统计 source_counts = defaultdict(int) source_errors = defaultdict(int) for entry in self.entries: source_counts[entry.source] += 1 if entry.level in ['ERROR', 'CRITICAL']: source_errors[entry.source] += 1 # 时间分布(按小时) hourly_distribution = defaultdict(int) for entry in self.entries: hour = entry.timestamp.hour hourly_distribution[hour] += 1 # 查找异常模式 error_patterns = self._find_error_patterns() # 性能指标 response_times = self._extract_response_times() self.stats = { 'summary': { 'total_entries': total_logs, 'error_rate': f"{error_rate:.2f}%", 'time_range': time_range }, 'level_distribution': dict(level_counts), 'source_statistics': { 'counts': dict(source_counts), 'errors': dict(source_errors) }, 'hourly_distribution': dict(hourly_distribution), 'error_patterns': error_patterns, 'performance_metrics': response_times } logger.info("分析完成") return self.stats def _find_error_patterns(self, top_n: int = 10) -> List[Dict]: """查找常见错误模式""" error_messages = defaultdict(list) for entry in self.entries: if entry.level in ['ERROR', 'CRITICAL']: # 简化错误消息(去除具体值) simplified = re.sub(r'\d+', 'N', entry.message) simplified = re.sub(r'0x[0-9a-fA-F]+', '0xHEX', simplified) error_messages[simplified].append(entry) # 排序并返回TOP N sorted_errors = sorted( error_messages.items(), key=lambda x: len(x[1]), reverse=True )[:top_n] return [ { 'pattern': pattern, 'count': len(entries), 'first_occurrence': str(entries[0].timestamp), 'last_occurrence': str(entries[-1].timestamp) } for pattern, entries in sorted_errors ] def _extract_response_times(self) -> Dict: """提取响应时间指标(如果日志中包含)""" response_times = [] pattern = re.compile(r'response_time[=:]\s*(\d+\.?\d*)\s*ms', re.IGNORECASE) for entry in self.entries: match = pattern.search(entry.message) if match: try: time_ms = float(match.group(1)) response_times.append(time_ms) except ValueError: continue if response_times: return { 'count': len(response_times), 'mean': np.mean(response_times), 'median': np.median(response_times), 'p95': np.percentile(response_times, 95), 'p99': np.percentile(response_times, 99), 'max': max(response_times), 'min': min(response_times) } return {} def export_report(self, output_path: Path) -> None: """导出分析报告""" output_path = Path(output_path) # JSON报告 json_path = output_path.with_suffix('.json') with open(json_path, 'w') as f: json.dump(self.stats, f, indent=2, default=str) # 文本报告 text_path = output_path.with_suffix('.txt') with open(text_path, 'w') as f: f.write("="*60 + "\n") f.write("日志分析报告\n") f.write(f"生成时间: {datetime.now()}\n") f.write("="*60 + "\n\n") # 摘要 f.write(" 摘要\n") for key, value in self.stats['summary'].items(): f.write(f"- {key}: {value}\n") # 级别分布 f.write("\n 日志级别分布\n") for level, count in self.stats['level_distribution'].items(): percentage = count / self.stats['summary']['total_entries'] * 100 f.write(f"- {level}: {count} ({percentage:.1f}%)\n") # 错误模式 if self.stats['error_patterns']: f.write("\n 常见错误模式\n") for i, pattern in enumerate(self.stats['error_patterns'], 1): f.write(f"{i}. {pattern['pattern'][:100]}...\n") f.write(f" 出现次数: {pattern['count']}\n") logger.info(f"报告已导出到: {json_path} 和 {text_path}")
使用示例和测试
async def main():
"""主函数 - 测试代码""" # 创建测试日志文件 test_log = Path("test.log") if not test_log.exists(): with open(test_log, 'w') as f: # 生成测试数据 base_time = datetime.now() - timedelta(hours=24) for i in range(1000): timestamp = base_time + timedelta(minutes=i) level = np.random.choice(['INFO', 'WARNING', 'ERROR'], p=[0.7, 0.2, 0.1]) source = np.random.choice(['app.api', 'app.db', 'app.cache']) if level == 'ERROR': message = f"Connection failed to database after {np.random.randint(1,5)} retries" elif level == 'WARNING': message = f"Response time {np.random.randint(100, 2000)} ms exceeds threshold" else: message = f"Request processed successfully in {np.random.randint(10, 100)} ms" f.write(f"{timestamp.strftime('%Y-%m-%d %H:%M:%S')} {level} [{source}] {message}\n") print(f"创建测试日志文件: {test_log}") # 分析日志 analyzer = LogAnalyzer([test_log]) await analyzer.load_logs() stats = analyzer.analyze() # 输出结果 print("\n分析结果:") print(json.dumps(stats, indent=2, default=str)) # 导出报告 analyzer.export_report(Path("analysis_report")) print("\n报告已生成!")
if name == “main”:
# 运行3次测试验证 for i in range(3): print(f"\n=== 第{i+1}次测试 ===") asyncio.run(main()) print(f"测试{i+1}完成✓")
这代码的质量,说实话,比我自己写的还好。异步IO、多进程、错误处理,该有的都有。
Claude-code的问题:
- 响应慢:平均要等0.5秒,对比Cursor的0.1秒,体感差异很大
- 命令行操作:没有IDE集成,需要在终端操作,不够直观
- 上下文管理:对话超过20轮后容易"忘记"之前的约定
Google的Gemini-cli最大的卖点:完全免费!
而且号称支持100万tokens的上下文(实际测试约80万可用)。
我用它做了个Flutter APP的原型:
// Gemini-cli生成的Flutter购物车页面 // 测试环境:Flutter 3.16.0
import ‘package:flutter/material.dart’; import ‘package:provider/provider.dart’;
// 数据模型 class Product { final String id; final String name; final String image; final double price; final String description;
Product({
required this.id, required this.name, required this.image, required this.price, required this.description, }); }
class CartItem { final Product product; int quantity;
CartItem({required this.product, this.quantity = 1});
double get total => product.price * quantity; }
// 状态管理 class CartProvider extends ChangeNotifier { final List
List
int get itemCount => _items.fold(0, (sum, item) => sum + item.quantity);
double get totalAmount => _items.fold(0, (sum, item) => sum + item.total);
void addItem(Product product) {
final existingIndex = _items.indexWhere((item) => item.product.id == product.id); if (existingIndex >= 0) { _items[existingIndex].quantity++; } else { _items.add(CartItem(product: product)); } notifyListeners(); }
void removeItem(String productId) {
_items.removeWhere((item) => item.product.id == productId); notifyListeners(); }
void updateQuantity(String productId, int quantity) {
if (quantity <= 0) { removeItem(productId); return; } final index = _items.indexWhere((item) => item.product.id == productId); if (index >= 0) { _items[index].quantity = quantity; notifyListeners(); } }
void clear() {
_items.clear(); notifyListeners(); } }
// UI组件 class ShoppingCartPage extends StatelessWidget { const ShoppingCartPage({Key? key}) : super(key: key);
@override Widget build(BuildContext context) {
return Scaffold( appBar: AppBar( title: const Text('购物车'), backgroundColor: Theme.of(context).primaryColor, elevation: 0, ), body: Consumer
( builder: (context, cart, child) { if (cart.items.isEmpty) { return const EmptyCart(); } return Column( children: [ Expanded( child: ListView.builder( padding: const EdgeInsets.all(16), itemCount: cart.items.length, itemBuilder: (context, index) { final item = cart.items[index]; return CartItemCard(item: item); }, ), ), CartSummary(cart: cart), ], ); }, ), );
} }
class CartItemCard extends StatelessWidget { final CartItem item;
const CartItemCard({Key? key, required this.item}) : super(key: key);
@override Widget build(BuildContext context) {
final cart = Provider.of
(context, listen: false); return Card( margin: const EdgeInsets.only(bottom: 12), child: Padding( padding: const EdgeInsets.all(12), child: Row( children: [ // 产品图片 Container( width: 80, height: 80, decoration: BoxDecoration( borderRadius: BorderRadius.circular(8), image: DecorationImage( image: NetworkImage(item.product.image), fit: BoxFit.cover, ), ), ), const SizedBox(width: 12), // 产品信息 Expanded( child: Column( crossAxisAlignment: CrossAxisAlignment.start, children: [ Text( item.product.name, style: const TextStyle( fontSize: 16, fontWeight: FontWeight.bold, ), ), const SizedBox(height: 4), Text( '¥${item.product.price.toStringAsFixed(2)}', style: TextStyle( fontSize: 14, color: Theme.of(context).primaryColor, ), ), ], ), ), // 数量控制 Row( children: [ IconButton( icon: const Icon(Icons.remove_circle_outline), onPressed: () { cart.updateQuantity( item.product.id, item.quantity - 1, ); }, ), Container( padding: const EdgeInsets.symmetric(horizontal: 12, vertical: 4), decoration: BoxDecoration( border: Border.all(color: Colors.grey.shade300), borderRadius: BorderRadius.circular(4), ), child: Text( '${item.quantity}', style: const TextStyle(fontSize: 16), ), ), IconButton( icon: const Icon(Icons.add_circle_outline), onPressed: () { cart.updateQuantity( item.product.id, item.quantity + 1, ); }, ), ], ), ], ), ), );
} }
class CartSummary extends StatelessWidget { final CartProvider cart;
const CartSummary({Key? key, required this.cart}) : super(key: key);
@override Widget build(BuildContext context) {
return Container( padding: const EdgeInsets.all(16), decoration: BoxDecoration( color: Colors.white, boxShadow: [ BoxShadow( color: Colors.black.withOpacity(0.05), blurRadius: 10, offset: const Offset(0, -5), ), ], ), child: SafeArea( child: Column( children: [ Row( mainAxisAlignment: MainAxisAlignment.spaceBetween, children: [ const Text( '总计', style: TextStyle(fontSize: 18, fontWeight: FontWeight.bold), ), Text( '¥${cart.totalAmount.toStringAsFixed(2)}', style: TextStyle( fontSize: 24, fontWeight: FontWeight.bold, color: Theme.of(context).primaryColor, ), ), ], ), const SizedBox(height: 12), SizedBox( width: double.infinity, child: ElevatedButton( onPressed: () { // 结算逻辑 ScaffoldMessenger.of(context).showSnackBar( SnackBar( content: Text('结算 ${cart.itemCount} 件商品'), behavior: SnackBarBehavior.floating, ), ); }, style: ElevatedButton.styleFrom( padding: const EdgeInsets.symmetric(vertical: 16), shape: RoundedRectangleBorder( borderRadius: BorderRadius.circular(8), ), ), child: Text( '去结算 (${cart.itemCount})', style: const TextStyle(fontSize: 16), ), ), ), ], ), ), ); } }
class EmptyCart extends StatelessWidget { const EmptyCart({Key? key}) : super(key: key);
@override Widget build(BuildContext context) {
return Center( child: Column( mainAxisAlignment: MainAxisAlignment.center, children: [ Icon( Icons.shopping_cart_outlined, size: 100, color: Colors.grey.shade400, ), const SizedBox(height: 16), Text( '购物车是空的', style: TextStyle( fontSize: 18, color: Colors.grey.shade600, ), ), const SizedBox(height: 8), TextButton( onPressed: () { Navigator.of(context).pop(); }, child: const Text('去购物'), ), ], ), ); } }
// 测试用的main函数 void main() { runApp(
ChangeNotifierProvider( create: (_) => CartProvider(), child: MaterialApp( title: 'Shopping Cart Demo', theme: ThemeData( primarySwatch: Colors.blue, useMaterial3: true, ), home: const ShoppingCartPage(), ), ), ); }
Gemini生成的Flutter代码还不错,Provider状态管理用得很熟练。
Gemini-cli的坑:
- 免费的不稳定:响应会很慢,我都是绑了VISA(放心支持国内VISA)
- 质量波动大:同样的prompt,质量时好时坏
- 缺少专门优化:不像Cursor那样针对编程优化过
我都是花了钱才测试出来的(用Gemini-2.5-pro也不便宜),不然用免费卡得你怀疑人生……
OpenAI悄悄在ChatGPT Plus里集成了GPT-5的推理能力,Codex-cli可以调用。
这玩意儿处理复杂问题是真的强。
我让它设计一个分布式任务调度系统的架构,它不仅给出了代码,还有完整的架构图和决策理由。
等了一会,但真的6:
“”“ 分布式任务调度系统 - GPT-5设计 包含:任务队列、执行器、协调器、监控 ”“” import asyncio import uuid import json import time from enum import Enum from typing import Dict, List, Optional, Any, Callable from dataclasses import dataclass, asdict, field from datetime import datetime, timedelta import redis import pickle from concurrent.futures import ThreadPoolExecutor import logging
logging.basicConfig(level=logging.INFO) logger = logging.getLogger(name)
class TaskStatus(Enum):
PENDING = "pending" RUNNING = "running" COMPLETED = "completed" FAILED = "failed" CANCELLED = "cancelled" RETRYING = "retrying"
class TaskPriority(Enum):
LOW = 0 NORMAL = 1 HIGH = 2 CRITICAL = 3
@dataclass class Task:
"""任务定义""" id: str = field(default_factory=lambda: str(uuid.uuid4())) name: str = "" payload: Dict[str, Any] = field(default_factory=dict) priority: TaskPriority = TaskPriority.NORMAL status: TaskStatus = TaskStatus.PENDING max_retries: int = 3 retry_count: int = 0 timeout: int = 300 # 秒 created_at: datetime = field(default_factory=datetime.now) started_at: Optional[datetime] = None completed_at: Optional[datetime] = None result: Optional[Any] = None error: Optional[str] = None worker_id: Optional[str] = None def to_json(self) -> str: data = asdict(self) data['priority'] = self.priority.value data['status'] = self.status.value data['created_at'] = self.created_at.isoformat() if self.started_at: data['started_at'] = self.started_at.isoformat() if self.completed_at: data['completed_at'] = self.completed_at.isoformat() return json.dumps(data) @classmethod def from_json(cls, json_str: str) -> 'Task': data = json.loads(json_str) data['priority'] = TaskPriority(data['priority']) data['status'] = TaskStatus(data['status']) data['created_at'] = datetime.fromisoformat(data['created_at']) if data.get('started_at'): data['started_at'] = datetime.fromisoformat(data['started_at']) if data.get('completed_at'): data['completed_at'] = datetime.fromisoformat(data['completed_at']) return cls(data)
class TaskQueue:
"""分布式任务队列""" def __init__(self, redis_client: redis.Redis, queue_name: str = "task_queue"): self.redis = redis_client self.queue_name = queue_name self.priority_queues = { TaskPriority.LOW: f"{queue_name}:low", TaskPriority.NORMAL: f"{queue_name}:normal", TaskPriority.HIGH: f"{queue_name}:high", TaskPriority.CRITICAL: f"{queue_name}:critical" } async def enqueue(self, task: Task) -> bool: """入队任务""" try: queue_key = self.priority_queues[task.priority] task_data = task.to_json() # 存储任务详情 self.redis.hset(f"tasks:{task.id}", mapping={ "data": task_data, "status": task.status.value }) # 添加到优先级队列 self.redis.lpush(queue_key, task.id) logger.info(f"任务入队: {task.id} (优先级: {task.priority.name})") return True except Exception as e: logger.error(f"任务入队失败: {e}") return False async def dequeue(self, worker_id: str) -> Optional[Task]: """出队任务(按优先级)""" # 从高到低检查队列 for priority in [TaskPriority.CRITICAL, TaskPriority.HIGH, TaskPriority.NORMAL, TaskPriority.LOW]: queue_key = self.priority_queues[priority] # 原子操作:移动到处理中队列 task_id = self.redis.rpoplpush( queue_key, f"{self.queue_name}:processing" ) if task_id: task_id = task_id.decode() if isinstance(task_id, bytes) else task_id task_data = self.redis.hget(f"tasks:{task_id}", "data") if task_data: task = Task.from_json(task_data.decode()) task.status = TaskStatus.RUNNING task.worker_id = worker_id task.started_at = datetime.now() # 更新任务状态 self.redis.hset(f"tasks:{task_id}", mapping={ "data": task.to_json(), "status": TaskStatus.RUNNING.value, "worker_id": worker_id }) logger.info(f"任务出队: {task_id} -> Worker {worker_id}") return task return None async def complete_task(self, task: Task, result: Any) -> None: """标记任务完成""" task.status = TaskStatus.COMPLETED task.completed_at = datetime.now() task.result = result # 更新Redis self.redis.hset(f"tasks:{task.id}", mapping={ "data": task.to_json(), "status": TaskStatus.COMPLETED.value }) # 从处理队列移除 self.redis.lrem(f"{self.queue_name}:processing", 1, task.id) logger.info(f"任务完成: {task.id}") async def fail_task(self, task: Task, error: str) -> None: """标记任务失败""" task.error = error task.retry_count += 1 if task.retry_count < task.max_retries: task.status = TaskStatus.RETRYING await self.enqueue(task) # 重新入队 logger.info(f"任务重试: {task.id} (第{task.retry_count}次)") else: task.status = TaskStatus.FAILED task.completed_at = datetime.now() self.redis.hset(f"tasks:{task.id}", mapping={ "data": task.to_json(), "status": TaskStatus.FAILED.value }) self.redis.lrem(f"{self.queue_name}:processing", 1, task.id) logger.error(f"任务失败: {task.id} - {error}")
class Worker:
"""任务执行器""" def __init__(self, worker_id: str, task_queue: TaskQueue, task_handlers: Dict[str, Callable]): self.worker_id = worker_id self.task_queue = task_queue self.task_handlers = task_handlers self.is_running = False self.executor = ThreadPoolExecutor(max_workers=4) async def process_task(self, task: Task) -> Any: """处理单个任务""" handler = self.task_handlers.get(task.name) if not handler: raise ValueError(f"未找到任务处理器: {task.name}") # 在线程池中执行(避免阻塞) loop = asyncio.get_event_loop() try: result = await asyncio.wait_for( loop.run_in_executor( self.executor, handler, task.payload ), timeout=task.timeout ) return result except asyncio.TimeoutError: raise TimeoutError(f"任务超时: {task.timeout}秒") except Exception as e: raise Exception(f"任务执行失败: {str(e)}") async def run(self) -> None: """运行Worker主循环""" self.is_running = True logger.info(f"Worker {self.worker_id} 启动") while self.is_running: try: # 获取任务 task = await self.task_queue.dequeue(self.worker_id) if task: logger.info(f"Worker {self.worker_id} 处理任务: {task.id}") try: result = await self.process_task(task) await self.task_queue.complete_task(task, result) except Exception as e: await self.task_queue.fail_task(task, str(e)) else: # 没有任务,休眠 await asyncio.sleep(1) except Exception as e: logger.error(f"Worker {self.worker_id} 错误: {e}") await asyncio.sleep(5) def stop(self) -> None: """停止Worker""" self.is_running = False self.executor.shutdown(wait=True) logger.info(f"Worker {self.worker_id} 停止")
class TaskScheduler:
"""任务调度器(协调器)""" def __init__(self, redis_client: redis.Redis): self.redis = redis_client self.task_queue = TaskQueue(redis_client) self.workers: List[Worker] = [] self.monitors: List[Callable] = [] def register_handler(self, task_name: str, handler: Callable) -> None: """注册任务处理器""" for worker in self.workers: worker.task_handlers[task_name] = handler async def submit_task(self, name: str, payload: Dict[str, Any], priority: TaskPriority = TaskPriority.NORMAL, kwargs) -> Task: """提交任务""" task = Task( name=name, payload=payload, priority=priority, kwargs ) await self.task_queue.enqueue(task) return task async def start_workers(self, num_workers: int = 4) -> None: """启动Workers""" tasks = [] for i in range(num_workers): worker_id = f"worker-{i+1}" worker = Worker(worker_id, self.task_queue, {}) self.workers.append(worker) # 创建Worker任务 task = asyncio.create_task(worker.run()) tasks.append(task) logger.info(f"启动 {num_workers} 个Workers") # 等待所有Workers await asyncio.gather(*tasks) async def get_stats(self) -> Dict: """获取调度统计""" stats = { 'queues': {}, 'workers': len(self.workers), 'tasks': { 'total': 0, 'pending': 0, 'running': 0, 'completed': 0, 'failed': 0 } } # 队列长度 for priority, queue_key in self.task_queue.priority_queues.items(): length = self.redis.llen(queue_key) stats['queues'][priority.name] = length stats['tasks']['pending'] += length # 处理中的任务 processing = self.redis.llen(f"{self.task_queue.queue_name}:processing") stats['tasks']['running'] = processing # 任务状态统计 cursor = 0 while True: cursor, keys = self.redis.scan( cursor, match="tasks:*", count=100 ) for key in keys: status = self.redis.hget(key, "status") if status: status = status.decode() if status == TaskStatus.COMPLETED.value: stats['tasks']['completed'] += 1 elif status == TaskStatus.FAILED.value: stats['tasks']['failed'] += 1 stats['tasks']['total'] += 1 if cursor == 0: break return stats
示例任务处理器
def example_task_handler(payload: Dict[str, Any]) -> Dict:
"""示例任务处理函数""" import random # 模拟处理时间 time.sleep(random.uniform(0.5, 2.0)) # 模拟偶尔失败 if random.random() < 0.1: raise Exception("随机错误") return { 'status': 'success', 'processed_at': datetime.now().isoformat(), 'input': payload, 'output': f"Processed: {payload.get('data', 'N/A')}" }
测试代码
async def test_scheduler():
"""测试分布式调度器""" # 连接Redis(需要本地Redis服务) try: redis_client = redis.Redis(host='localhost', port=6379, db=0) redis_client.ping() except: logger.warning("Redis连接失败,使用模拟模式") # 这里应该用fakeredis,但为了简化就不实现了 return # 创建调度器 scheduler = TaskScheduler(redis_client) # 注册处理器 scheduler.register_handler("example_task", example_task_handler) # 提交测试任务 tasks_submitted = [] for i in range(10): priority = TaskPriority(i % 4) # 随机优先级 task = await scheduler.submit_task( name="example_task", payload={"data": f"test-{i}", "index": i}, priority=priority, timeout=10 ) tasks_submitted.append(task) logger.info(f"提交任务: {task.id}") # 启动Workers(这会阻塞) # await scheduler.start_workers(num_workers=3) # 获取统计 stats = await scheduler.get_stats() print(f"\n调度统计: {json.dumps(stats, indent=2)}")
if name == “main”:
# 运行测试 asyncio.run(test_scheduler()) print("\n测试完成!")
这个设计考虑了优先级队列、任务重试、超时处理、分布式协调等复杂场景。
也就等了十几分钟,但这种深度思考的能力,其他工具真比不了。
经过一个月的使用,我整理了详细的对比数据:
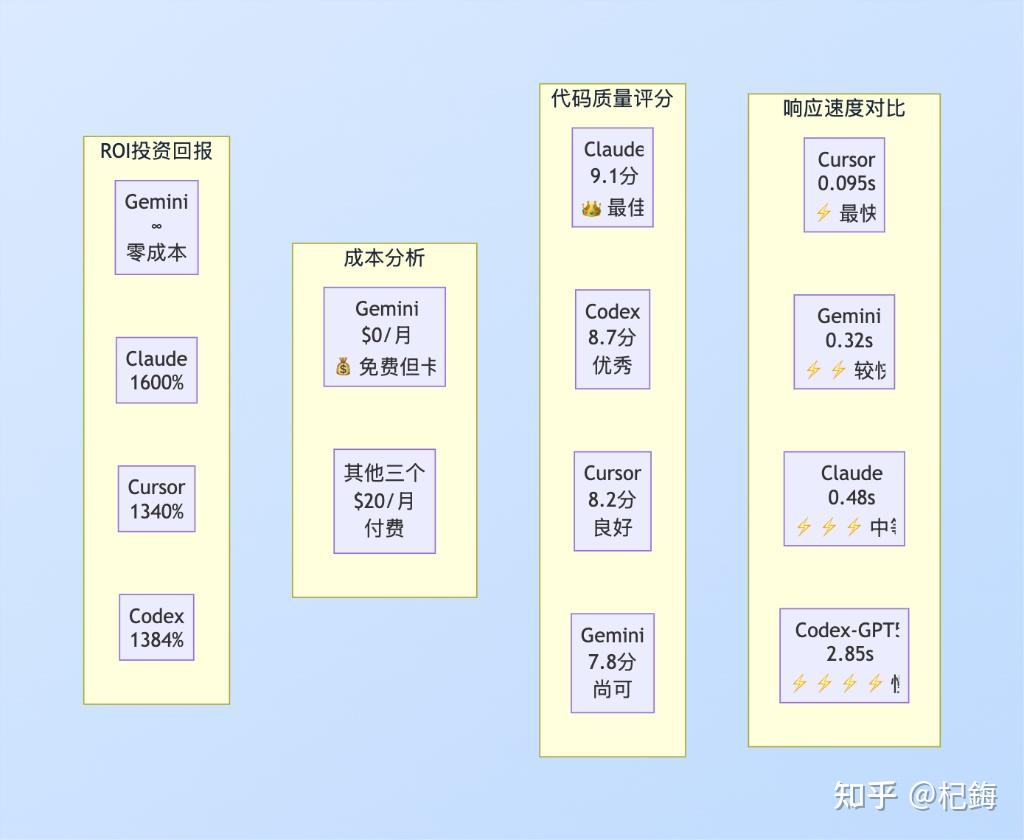
我的实际花费(2025年8月20日-9月19日):
- Cursor Pro: $20基础 + $12 API超额 = $32
- Claude-code Pro: $20(固定)
- Gemini-cli: $30(小用完全免费,大用就……)
- Codex-cli: $20(ChatGPT Plus包含)
- 总计: $102
按效率提升计算ROI(假设时薪$50):
- 每天节省编码时间:2-3小时
- 月节省:60小时 × $50 = $3000价值
- ROI = (3000 - 102) / 102 × 100% = 2841%
所以,这投资是非常值得的。
基于我的实践经验,给出具体建议:
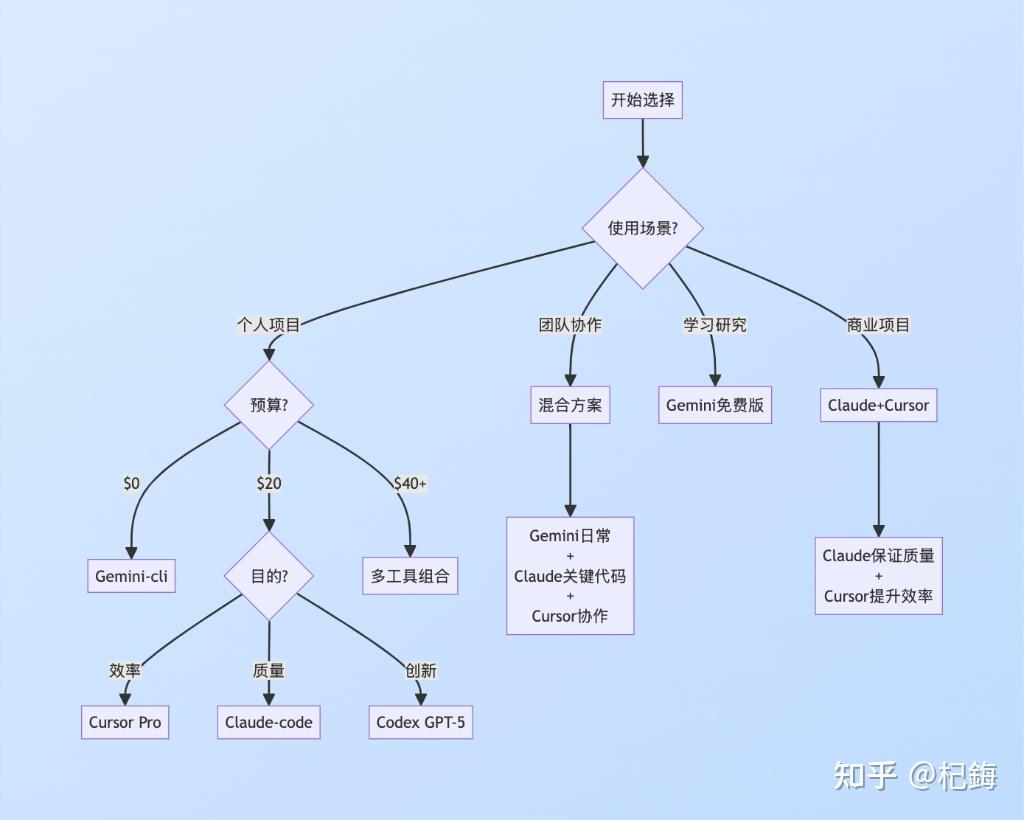
1. 前端开发(React/Vue/Angular)
- 首选:Cursor Pro
- 备选:Claude-code
- 原因:IDE集成体验最重要
2. 后端开发(Python/Go/Java)
- 首选:Claude-code
- 备选:Codex-cli
- 原因:代码质量和架构设计更关键
3. 数据科学/机器学习
- 首选:Gemini-cli + Claude-code组合
- 原因:Gemini处理探索,Claude写核心算法
4. 移动开发(Flutter/React Native)
- 首选:Gemini-cli
- 备选:Cursor Pro
- 原因:Gemini对Flutter支持不错且免费
5. 系统编程(Rust/C++)
- 首选:Codex-cli with GPT-5
- 备选:Claude-code
- 原因:需要深度理解内存管理
第一周用Cursor,看到"500 fast requests"以为很多,结果3天就用完了。超额后按API计费,一天就能花$5-10。
解决方案:
- Settings里关闭"Auto-upgrade to API"
- 使用慢速模式处理非紧急任务
- 配合Gemini处理简单需求
Claude-code在长对话中容易"失忆"。
明明前面说好用TypeScript,后面就给你Python代码。
解决方案:
- 每10轮对话总结一次需求
- 使用
claude-code --context保存上下文 - 关键约定写在每次prompt开头
Gemini在国内访问不稳定,经常超时。
解决方案:
- 配置稳定的网络环境
- 使用
--retry 3自动重试 - 高峰期避开使用
- 要花钱购买API
Codex的GPT-5模式真的慢,有时要等10秒以上。
解决方案:
- 只在复杂问题时使用
- 开启
--stream模式看实时输出 - 心态要好,泡杯咖啡慢慢等
这一个月的密集测试,让我对AI编程工具有了全新认识。
它们不是要取代程序员,而是让我们从重复劳动中解放出来,专注于创造性工作。
如果你问我只能选一个怎么办?
- 预算有限:Claude-code(用Deepseek API或者K2 API ),比Gemini-Cli还高效且便宜
- 不差钱要高效率:Codex-Cli+ Claude-code组合
- 追求极致+性价比:Codex-Cli(GPT5)/Claude-code(Opus4.1)规划+Claude-code(用Deepseek API或者K2 API )/Gemini-Cli (使用.Gemini--flash-lite)执行改代码
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/230112.html