
这两天需要在一些网站上抓些数据下来,按照以前的方式,那我已经开始动手些代码了,不管是用 Python 直接走 API ,还是用 Puppeteer、Playwright 这种无头浏览器的方式,总之多少都是要写一些代码的。
现在呢,完全变了,只要告诉 OpenClaw 就行了,不需要费劲巴拉的找 API 激活成功教程、调试,更不用担心被封号了。
关键是这两个方法非常简单,基本上可以抓取任何网页的数据。
在介绍这两个方法之前先说明一下,其实 OpenClaw(包括其他 agent)内置了 web-fetch能力,但是这种能力更像搜索引擎,适合那种泛信息的获取,不适合精准数据获取,比如抓取某个B 站 up 主的视频、某个小红书博主的帖子等。
OpenClaw 内置浏览器能力
在你装好 OpenClaw 之后,OpenClaw 就自带这个能力了。
当你跟它明确的说打开浏览器获取 xxxx信息,或者给它一个网址,有时候它就会自动触发,打开一个 Chrome 浏览器。
这种方式比较适合明确的网站或多个网站,并且在使用时最好明确告诉OpenClaw 打开浏览器。
这种方式打开的浏览器是没有你之前网站登录状态的,更适合不需要登录的网站,有些网站需要登录才能访问,比如小红书,这时候,就需要你手动登录,然后再告诉 OpenClaw,你登录成功了,让它继续操作。
我让它抓取B 站热门视频列表,中间出现了一个小问题,然后它自己修复了,最终完美获取到了。

在执行期间, OpenClaw 自动打开如下图的浏览器,并访问页面,都是能看到的。
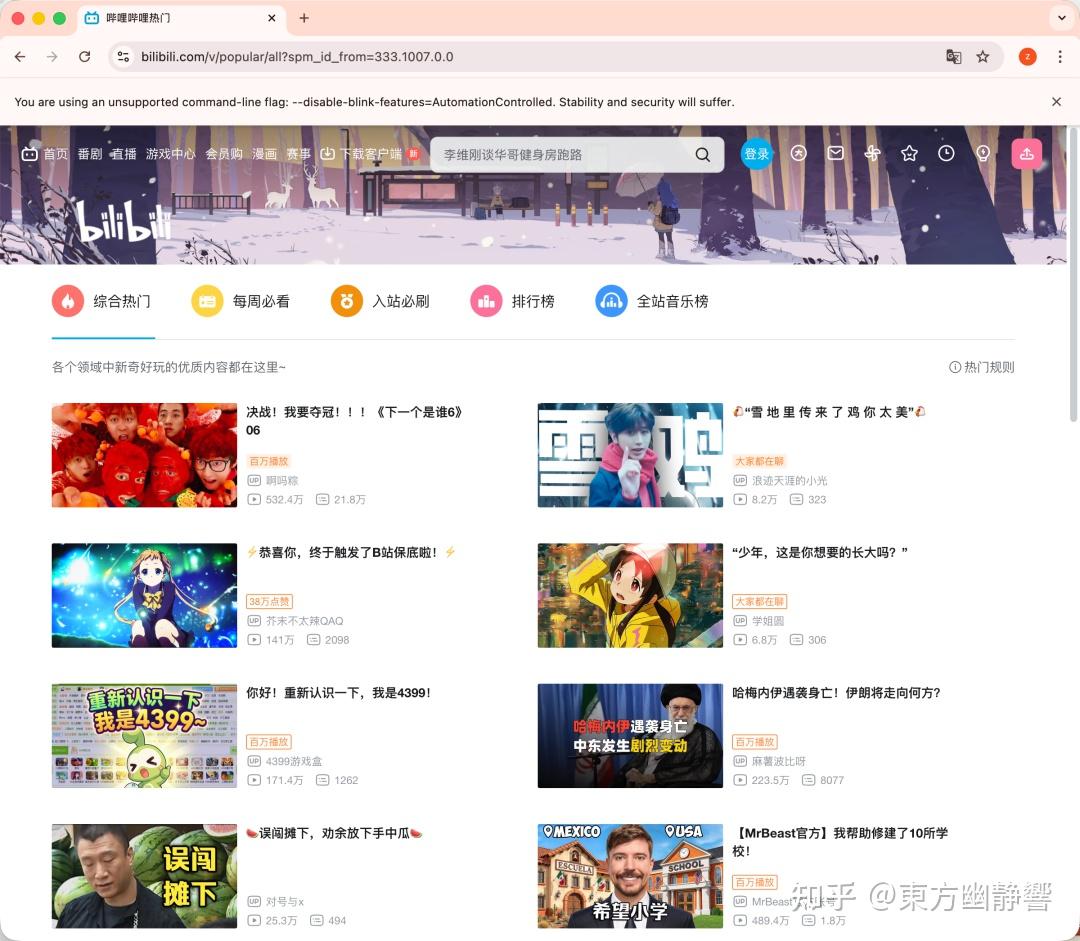
万能数据抓取
如果觉得,前一种方式对于需要登录的网站还是有点儿麻烦的,那这种方式就无敌了。
这是 OpenClaw 推出的一个专门对应这种情况的一个浏览器插件,叫做 OpenClaw Browser Relay,装上这个插件,就可以利用你正在使用的 Chrome 中的登录信息,想抓谁抓谁了。
安装方式
使用下面的命令下载这个插件。
openclaw browser extension install然后输入下面这个命令,
openclaw browser extension path执行完成后,会得到一个下图中的路径,也就是插件的地址。
~/.openclaw/browser/chrome-extension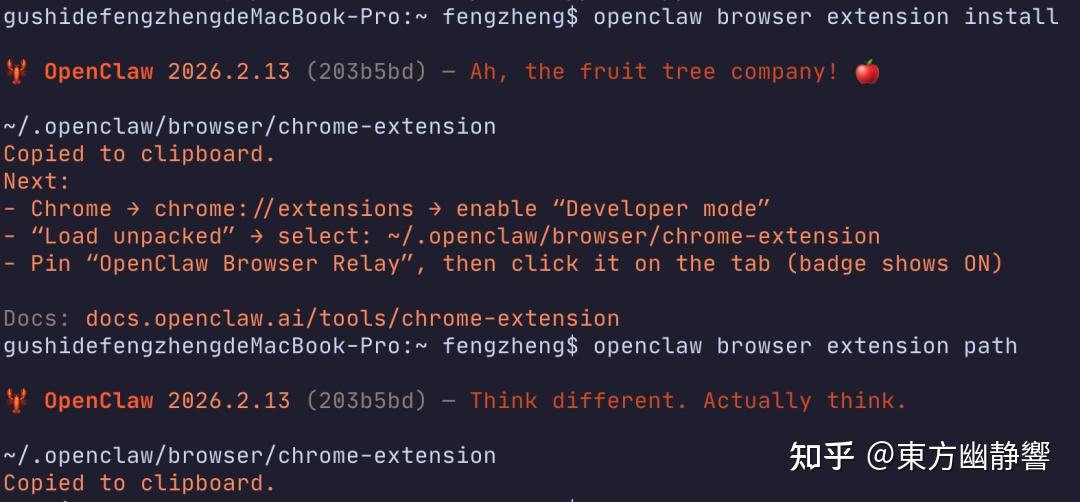
然后在浏览器中访问 chrome://extensions/,打开右上角的开发者模式。
点击加载解压文件,选择前面获取的那个插件路径。
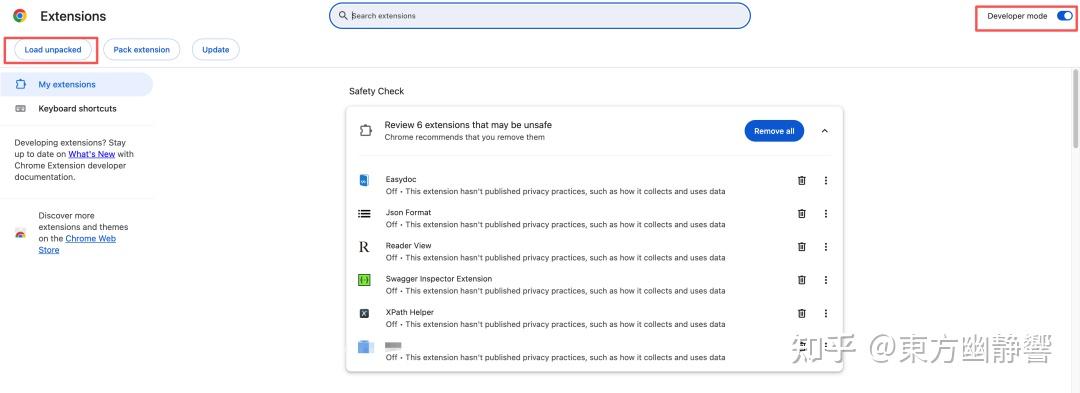
之后会自动打开下面这个页面,如果看到了,说明一切正常。
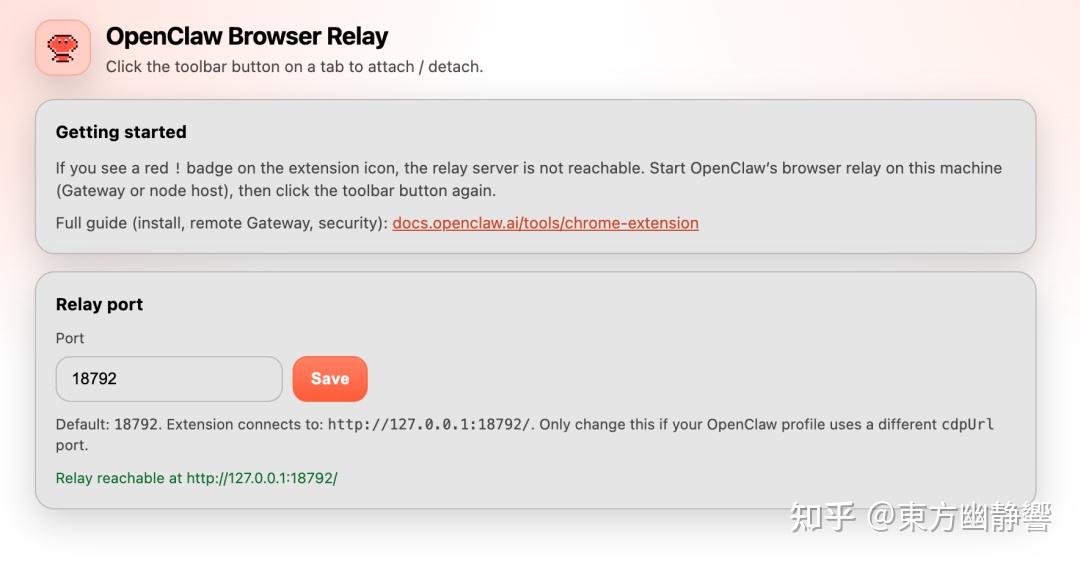
之后点击浏览器工具栏最右边的这个小图标,在弹出的插件列表中将 OpenClaw Browser Relay 后面的图标选中,表示固定到工具栏,然后工具栏就会出现大龙虾的图标。
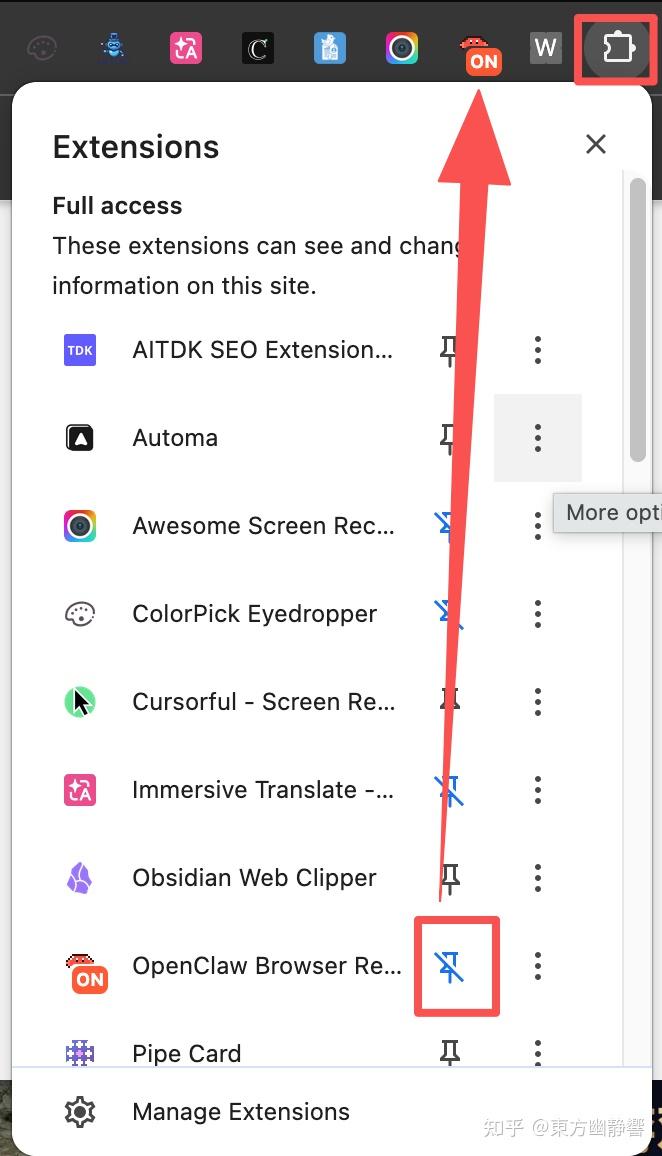
使用 Browser Relay 抓取数据
下面我演示一下如何用这个插件配合 OpenClaw 来抓数据。
非常的简单,只需要两步。
加入要抓取我的小红书点赞最多的前 5 条帖子。
打开我的小红书(也就是你想抓的网页,比如某 up 主视频列表页),然后点击刚才固定到工具栏的大龙虾图标,点击之后图标上会出现一个 ON 的红色状态,表示连接成功了。
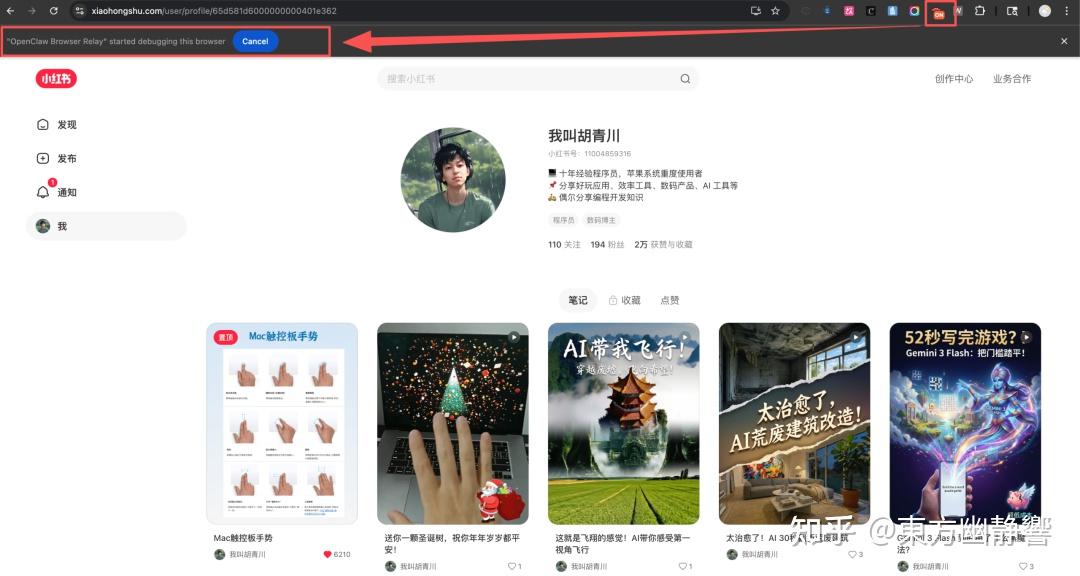
连接成功后,就直接告诉 OpenClaw:现在已经连上了一个博主的小红书首页,请获取 like 数量最多的 5 篇内容。
稍等一会儿,就成功获取到了。
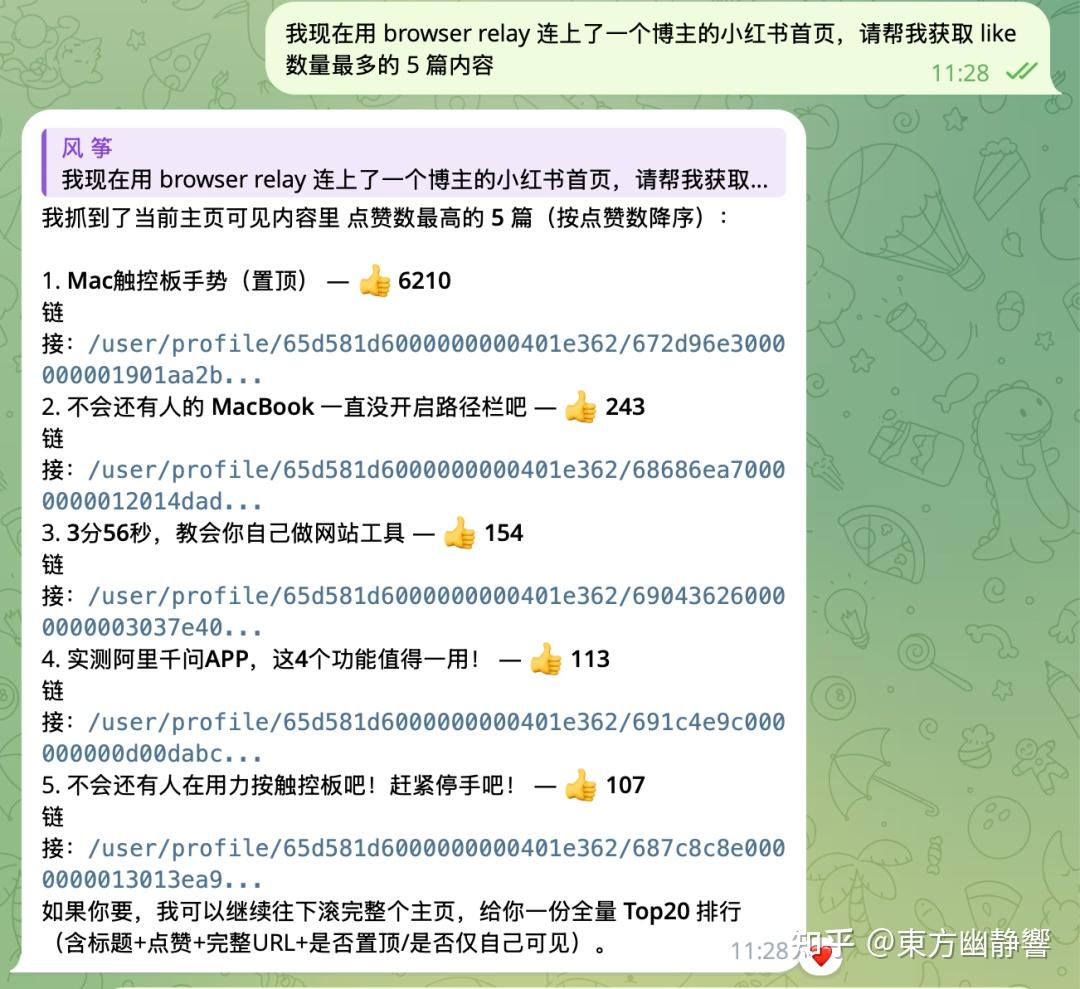
这种方式的好处就相当于你把你正在使用的浏览器委托给 OpenClaw 了,你登录了什么网站,它自动就能访问,不需要再验证了。
其实这个插件除了能获取数据外,还有更多的用处,比如配合开发浏览器插件就非常好,前两天我就用它做了一个浏览器插件。
开发方式非常简单,我点开一个页面,就让它看一眼记住,然后点一个按钮,就告诉它点了什么按钮,出现了一个页面,再让它看,直到出现最终的页面,告诉它抓取什么内容。最火让它把前面我的操作整理成一个 Chrome 插件,稍微测试修改两下就好了。
最后
赶紧尝试一下吧,强烈推荐第二种插件的方式,定向抓取数据非常方便。
来源: https:// mp.weixin..com/s/RvPd R2txe0xM4p5rWwswbQ
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/228114.html