
一、研究目的与核心思想
DeepSeek-OCR 是一次关于 “通过光学二维映射(optical 2D mapping)压缩长上下文” 的初步探索。它的目标是让模型能高效地从高分辨率输入中提取关键信息,把大量文本压缩成更少的视觉 token,从而实现高效的 OCR(光学字符识别)与长文本理解。
二、模型结构
模型包含两个主要组件:
DeepEncoder:核心引擎,负责在高分辨率输入下保持低激活量(即计算量低),同时实现高压缩率,把大规模文字信息压缩为少量视觉 token。
DeepSeek3B-MoE-A570M:作为解码器,用来从压缩后的视觉 token 中恢复文本(即执行 OCR)。
三、实验结果与应用价值
当文本 token 数量不超过视觉 token 的 10 倍(压缩比 <10×)时,模型的 OCR 精度达到 97%。即使压缩比提高到 20×,精度仍有 约 60%。在 OmniDocBench 基准测试上,DeepSeek-OCR 使用 更少的视觉 token 就超过了GOT-OCR2.0(256 tokens/页),以及MinerU2.0(6000+ tokens/页)。
在生产环境中,一张 A100-40G GPU 每天可处理超过 20 万页文档。这些结果显示,DeepSeek-OCR 不仅在研究上对 长上下文压缩与遗忘机制(memory forgetting) 有启发意义,也在实际应用中具有高价值(如为 LLM/VLM 生成大规模训练数据)。
一、研究动机:长文本处理的计算瓶颈
当前的大语言模型(LLMs)在处理长文本(long context)时面临巨大的计算开销——主要原因是序列长度平方级的计算复杂度(quadratic scaling)。为了解决这个问题,作者提出一个新思路:利用视觉模态(visual modality)作为文本信息的高效压缩介质。
一句话解释:
与其让 LLM 直接处理成千上万的文字,不如先把整页文字“变成一张图像”,再通过视觉 token 表示。因为一张图片能包含大量文字信息,却只需要少得多的视觉 token(vision tokens)。这就是所谓的 “光学压缩(optical compression)” 概念。
二、研究切入点:从视觉语言模型(VLM)到 LLM 效率优化
以往的 VLM(如做图像问答 VQA 的模型)主要研究人类视觉理解任务,而本文作者换了角度——从 LLM 的效率优化 角度重新审视 VLM,探索视觉编码器如何帮助 LLM 更高效地处理文本。在这一思路下,OCR(光学字符识别)任务 被选为理想的测试场景,因为:它天然建立了视觉 → 文本 的映射关系(压缩与解压缩)。同时可以用准确率等指标进行量化评估。因此,作者设计了 DeepSeek-OCR 作为一个概念验证模型(proof-of-concept)。
三、主要贡献
- 视觉-文本压缩比的定量分析
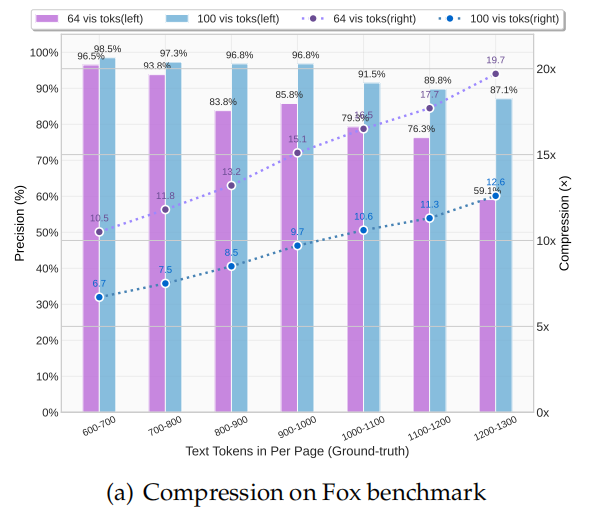
实验表明模型在不同压缩比下的 OCR 精度:
9–10× 压缩:96%+ 精度
10–12× 压缩:约 90% 精度
20× 压缩:约 60% 精度
即便压缩 10 倍以上,模型仍能准确还原文本。这说明:LLMs 未来可以通过适当预训练,学会从高压缩视觉信息中恢复文本内容。
3. 构建 DeepSeek-OCR 系统并实现 SOTA 性能
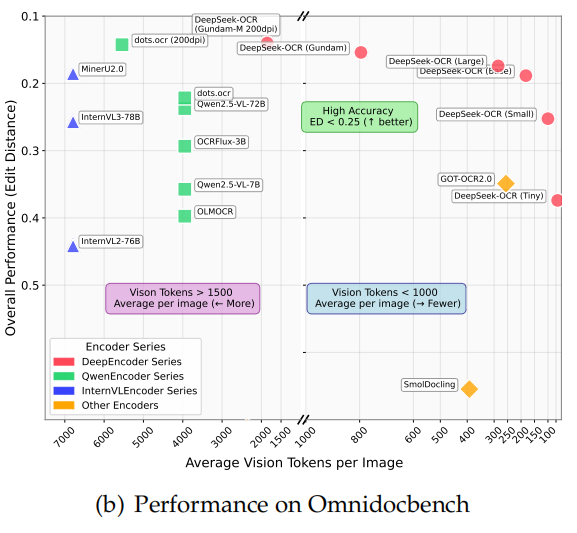
模型由 DeepEncoder + DeepSeek3B-MoE 组成;在 OmniDocBench 基准上取得 最先进(state-of-the-art)性能,且使用的视觉 token 数最少;还能解析图表、化学式、几何图形、自然图像等多种内容;具备极高生产效率:20 个节点(8×A100-40G)每天能生成 3300 万页训练数据。
四、研究意义与展望
作者最后总结:这是首次系统验证“视觉模态可作为高效文本压缩介质”的可行性;DeepSeek-OCR 实现了 7–20× token 压缩,显著缓解 LLM 的长上下文计算瓶颈;提供了 视觉-语言 token 分配优化 的实证依据;展示了该方法在实际大规模部署中的可行性;虽然本研究以 OCR 为起点,但这一范式预示了未来 视觉与语言的深度协同,可能成为提升 LLM 计算效率的新方向。
传统OCR
二、三种典型视觉编码器类型与分析
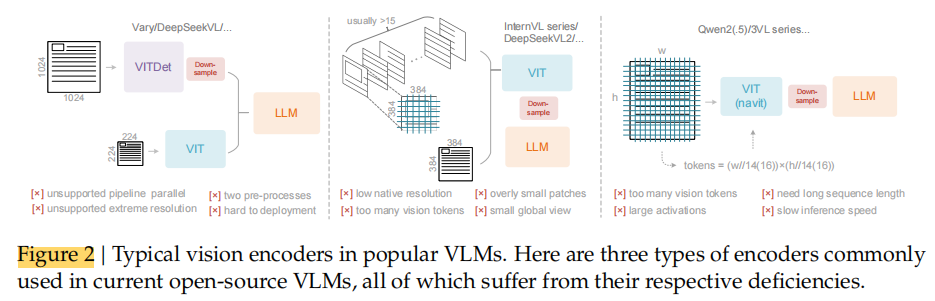
① 双塔结构(Dual-tower architecture)——代表模型:Vary [36]
做法: 使用两个并行的视觉编码器(如 SAM [17]),以提升视觉词汇参数数量,从而处理高分辨率图像。
优点:
参数规模可控;
激活内存(activation memory)可管理。
缺点:
需要 双重图像预处理(dual preprocessing),部署复杂;编码器管线在训练时难以实现高效并行(pipeline parallelism)。
总结: 性能可调,但训练和部署复杂。
② 分块方法(Tile-based method)——代表模型:InternVL2.0 [8]
做法: 将大图像划分成多个小块(tiles),分别处理并并行计算,以降低高分辨率输入下的内存占用。
优点:
能处理极高分辨率图像;
并行性好。
缺点:
原生编码器分辨率通常较低(<512×512);因此大图会被过度切碎,产生大量视觉 token→ 导致计算负担重、信息碎片化。
总结: 能处理大图,但 token 太多、效率低。
③ 自适应分辨率编码(Adaptive resolution encoding)——代表模型:Qwen2-VL [35]
做法: 采用 NaViT [10] 思路,直接对整张图进行基于 patch 的分块编码,而不是分 tile 并行。
优点:
能灵活处理不同尺寸的图像(更通用)。
缺点:
大图像会导致激活内存消耗巨大,容易GPU 溢出;序列打包(sequence packing)需要超长序列,训练代价高;太长的视觉 token 序列会拖慢推理的 prefill 和 generation 阶段。
总结: 灵活但资源消耗极高,难以扩展。
端到端OCR
但这些模型虽然性能强大,却没有回答一个核心科学问题:
文本信息量和视觉 token 数量之间的“最低对应关系”是什么?
也就是,一幅图像(视觉 token)能代表多少文字信息(文本 token)——
这正是 DeepSeek-OCR 想研究的“视觉压缩”原理。
意义: 证明了 end-to-end 框架能有效处理复杂、密集的文档解析任务。
贡献: 开启了端到端 OCR 的研究方向。
扩展了 OCR2.0 框架,涵盖更多合成图像解析任务(synthetic image parsing);
在性能与效率之间进行权衡(performance-efficiency trade-off)。
意义: 展示了端到端 OCR 在泛化性与计算效率之间的潜力。
特点:
虽然并非专为 OCR 设计,但不断增强了对文档解析(document OCR)的能力;
探索更广泛的“密集视觉理解(dense visual perception)”任务边界。
意义: 表明视觉语言模型正逐渐具备 OCR 能力,但仍缺乏底层原理研究。
“对于一份包含 1000 个词的文档,至少需要多少个视觉 token 才能正确解码?”
架构
一、段落主旨
作者在这一节说明:
DeepSeek-OCR 是一个统一的端到端视觉语言模型(VLM)架构,
由 编码器(DeepEncoder) 和 解码器(Decoder)
两个主要部分组成。
模型的核心思想是:
由 编码器 将图像转化为压缩后的视觉 token 表示;
再由 解码器 基于这些 token 和输入提示(prompt)生成最终文本结果(如 OCR 输出)。
二、架构组成与参数规模
功能: 提取图像特征、进行视觉表示的 token 化与压缩;
参数规模: 约 3.8 亿(380M)参数;
结构组成:
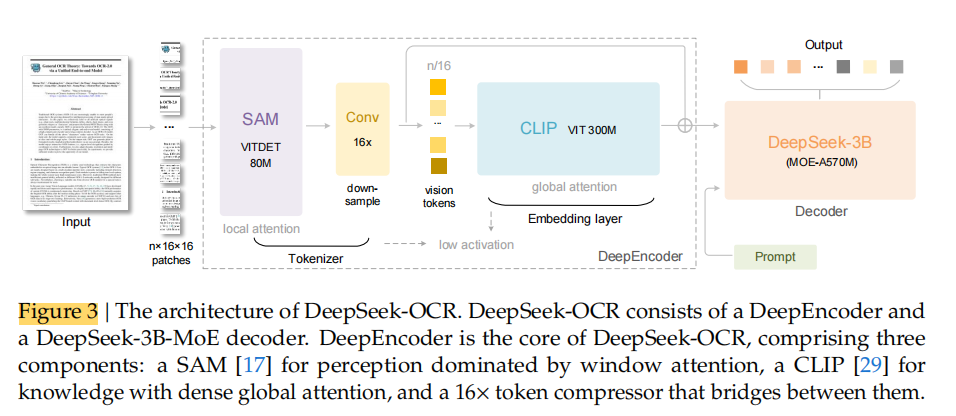
一个 80M 参数的 SAM-base 模型(用于高质量视觉特征提取);
一个 300M 参数的 CLIP-large 模型(用于语义级视觉编码);
两者是串联(connected in series)使用的。
特点:
高效地将图像转化为压缩的视觉 token,是实现视觉压缩和低显存占用的核心组件。
结构: 采用 3B MoE(Mixture of Experts)架构;
激活参数: 约 5.7 亿(570M)。
作用:负责语言生成部分;能灵活应对多类型任务(如 OCR、图表理解、化学式解析等)。
DeepEncoder
一、总体目标与设计动机
作者一开始说明了为什么要自己设计 DeepEncoder:
为实现“上下文的光学压缩(context optical compression)”,一个合格的视觉编码器必须同时具备以下五种能力:
能处理高分辨率输入;
在高分辨率下激活开销低(low activation);
输出少量视觉 tokens;
能支持多种分辨率输入;
参数规模适中(不过大)
但现有开源模型(如前面提到的 SAM、InternVL、Qwen2-VL 等)无法同时满足这些条件,因此作者设计了一个新的视觉编码器——DeepEncoder。
二、Architecture of DeepEncoder —— 编码器结构设计
DeepEncoder 由两个主要组件组成:
视觉感知特征提取模块(Visual Perception Feature Extraction):以 window attention 为主;
视觉知识特征提取模块(Visual Knowledge Feature Extraction):以 dense global attention 为主。
二者串联构成完整的视觉理解管线:局部注意力(捕捉细节) → 卷积下采样(压缩 tokens) → 全局注意力(捕捉全局语义)。
执行 16× 下采样;
卷积参数:kernel size = 3,stride = 2,padding = 1;
通道数从 256 → 1024。
1024⁄16 × 1024⁄16 = 4096 个 patch tokens。
三、Multiple Resolution Support —— 多分辨率支持机制
DeepEncoder 不仅要高效,还要适应不同分辨率输入,以便处理不同类型文档(如论文、报纸、表格等)。

“如果一张图中有 1000 个字符,最少需要多少视觉 tokens 才能准确解码?”
要研究这个问题,模型必须支持可变数量的视觉 tokens,即支持多分辨率输入。
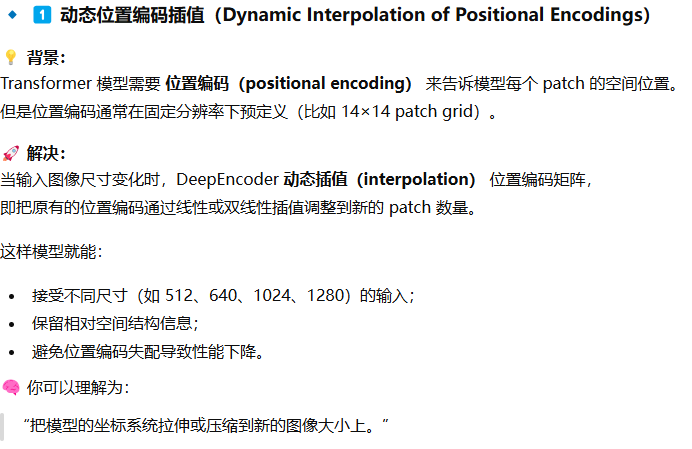
动态位置编码插值(dynamic interpolation of positional encodings)
多分辨率联合训练(multi-resolution joint training)
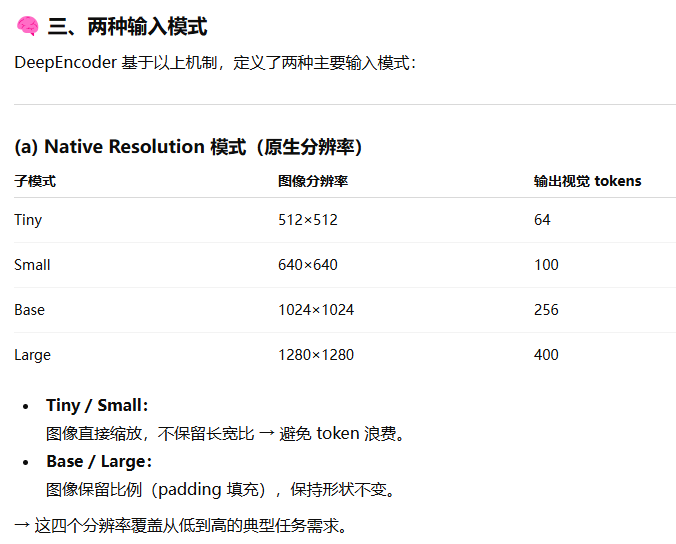
DeepEncoder 因此支持两大输入模式:
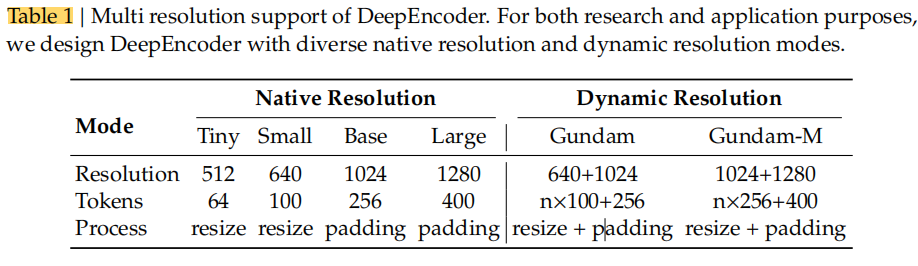
对于 Tiny / Small:直接缩放图像(不保留比例),防止 token 浪费。
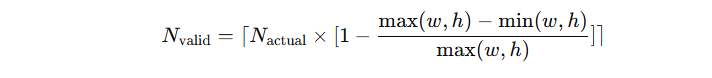
“Gundam mode” = n×640×640 局部视图 + 1 个 1024×1024 全局视图;
遵循 InternVL2.0 的分块(tiling)策略;
目的是:处理超高分辨率输入(如报纸、表格),进一步降低激活内存。
由于原生分辨率已经较大,每张图的分块数量 n 控制在 2–9 之间,避免过度碎片化。
Gundam 模式输出的视觉 token 数为:
![]()
若图像尺寸较小(宽高均 < 640),则 n=0,Gundam 模式自动退化为 Base 模式。
此外,还提到:
Gundam mode 与四种原生模式一起联合训练;
Gundam-master mode(1024×1024 局部视图 + 1280×1280 全局视图)是在已训练模型上继续训练得到的,用于负载均衡与超高分辨率任务。
MOE Decoder
一、段落主旨
这一节说明:
DeepSeek-OCR 的 解码器(Decoder) 采用 Mixture-of-Experts(MoE)结构,具体使用的是 DeepSeek-3B-MoE 模型,它能在保持较高表达能力的同时,大幅提升推理效率。
二、解码器架构:DeepSeekMoE
解码器使用 DeepSeekMoE 框架,具体型号是 DeepSeek-3B-MoE;在推理阶段(inference):模型总共有 64 个专家(experts);每次只激活其中 6 个路由专家(routed experts) 和 2 个共享专家(shared experts);实际激活参数量约为 5.7 亿(570M)。
这样做兼顾了:
大模型的表达能力(expressive capability);
小模型的推理效率(inference efficiency)。
这使得它非常适合“领域特定任务”(domain-centric research),例如本论文的 OCR 视觉语言建模。
三、解码过程(从视觉 token 到文本 token)
作者用一个公式来描述这一过程:

训练数据构建
一、总体思路:多源、多模态、高多样性
作者强调:
为了让 DeepSeek-OCR 同时具备 强 OCR 能力 + 一定通用视觉理解能力 + 语言生成能力,
他们构建了一个复杂且多样的训练数据体系,包含四类数据源:
二、OCR 1.0 Data —— 传统 OCR 数据
主要包含两部分:

文档 OCR(Document OCR)
自然场景 OCR(Scene OCR)
文档 OCR
收集 3000 万页 PDF 文档,覆盖约 100 种语言;
中文 + 英文:约 2500 万页;
其他语言:约 500 万页。
提供两种标注层级:
粗标注(coarse annotation):
使用 fitz 工具直接从 PDF 中提取文本;
用于训练模型识别不同语言的文字形态;
精标注(fine annotation):
200 万页中文 + 200 万页英文;
使用先进布局模型(PP-DocLayout)和 OCR 模型(MinerU、GOT-OCR2.0)标注;
构建“检测 + 识别交替”的训练样本;
少数语言通过“小样本自训练(model flywheel)”生成 60 万条标注数据。
在训练时,通过不同的 prompt 区分粗标与精标。
另有 300 万份 Word 文档 用于生成高质量图文对,特别有助于公式与 HTML 表格任务。
补充使用了一些开源数据集(如 [28,37])。
自然场景 OCR
主要支持中英文;
图片来源:LAION 与 Wukong;
使用 PaddleOCR 自动标注;
共计 2000 万样本(中英文各 1000 万);
同样可以通过 prompt 控制是否输出检测框。
总结: OCR 1.0 数据覆盖多语言、多场景文字识别,支持从简单文本到复杂布局的学习。
三、OCR 2.0 Data —— 复杂人工图像解析数据
该类数据用于训练模型识别和解析复杂的视觉结构,包括:
图表(Charts)
化学结构式(Chemical Formulas)
平面几何图形(Plane Geometry)
图表数据
参考 GOT-OCR2.0 与 OneChart;
使用 pyecharts 和 matplotlib 渲染 1000 万张图表;
包括折线图、柱状图、饼图及复合图;
定义任务为:图像 → HTML 表格生成(image-to-HTML-table)。
化学式数据
来源:PubChem SMILES 格式;
使用 RDKit 渲染化学式图像;
生成 500 万图文对。
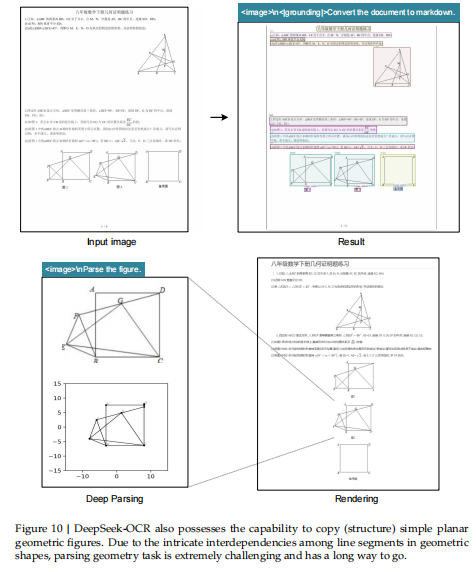
平面几何数据
参考 Slow Perception [39];
每个图形的“perception-ruler size”设为 4;
采用平移不变(translation-invariant)增强来提升多样性;
构建 100 万样本;
任务为:解析几何图形(见图6(b))。
总结: OCR 2.0 数据让模型能理解结构化图像(图表、公式、几何图),突破传统 OCR 的“纯文本”局限。
四、General Vision Data —— 通用视觉数据
由于 DeepEncoder 基于 CLIP-large,具备一定视觉知识承载能力;
因此作者加入少量通用视觉数据以保持模型的“视觉接口”。
参照 DeepSeek-VL2 [40],包含任务:
图像描述(caption)
目标检测(detection)
视觉定位(grounding)
占总训练数据约 20%。
目的:
不是让模型成为通用 VLM;
而是方便后续研究者继续扩展通用视觉任务。
五、Text-only Data —— 纯文本数据
为了保持语言能力,引入 10% 的纯文本预训练数据;
所有样本长度统一为 8192 tokens(即模型最大序列长度);
确保模型不仅能识别视觉信息,也能流畅生成自然语言。
六、总体数据比例总结
训练流程
一、总体结构:两阶段训练流程
作者一开始说明整个训练管线由两步组成:
阶段 a:单独训练 DeepEncoder;
阶段 b:联合训练完整的 DeepSeek-OCR 模型。
此外,“Gundam-master 模式” 是在训练好的 DeepSeek-OCR 模型上继续微调得到的(使用 600 万条样本),由于训练协议一致,因此不再赘述。
这体现了一个渐进式训练思路:先让编码器具备强视觉压缩能力,再与语言解码器结合形成完整系统。
二、Training DeepEncoder —— 编码器预训练阶段
训练目标
目标:让 DeepEncoder 学会从图像中提取有意义的视觉 token 表示;使用 next-token prediction(下一个 token 预测) 框架进行自监督训练;
参考模型:Vary [36] 的训练范式;语言模型部分使用 紧凑型语言模型(compact LM)[15] 作为辅助学习器。
训练配置
目标效果: 让 DeepEncoder 能在高分辨率下稳定运行、压缩 token,同时保持语义表达能力。
三、Training DeepSeek-OCR —— 完整模型训练阶段
在 DeepEncoder 训练完成后,作者将其与解码器结合,训练完整的 DeepSeek-OCR 模型。
模型被划分为 4 个部分(PP0~PP3):
多模态数据(图文混合):70B tokens/天。这说明模型在超大规模分布式系统上具有很高的训练吞吐率与工程可扩展性。
DeepSeek-OCR 在“视觉—文本压缩”任务中的性能表现
一、研究目的
作者的核心目标是:
换句话说,他们要验证“一张图片能代表多少文字”这个关键科学问题(即上下文压缩可行性)。
二、实验设置
数据集
使用 Fox [21] benchmark(一个包含大量文本密集文档的评测集);
选取其中的 英文文档部分 进行测试;
用 DeepSeek-OCR 自身的 tokenizer(词表约 12.9 万词)对文本进行分词;
选择 长度在 600–1300 tokens 的文档,共计 100 页;
由于文本量较小,只测试:
Tiny 模式(64 vision tokens)
Small 模式(100 vision tokens)
由于输出格式与基准集格式不完全一致,因此作者说明:
实际真实精度会略高于测试结果。
三、主要实验结果
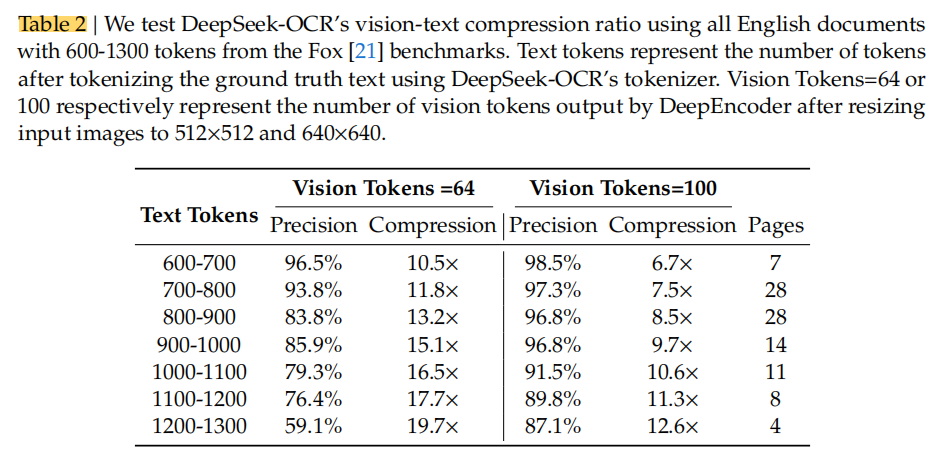
结论:
在 10× 压缩率以内,模型几乎可以无损恢复原始文本(97%精度);
当压缩率超过 10× 时性能下降,主要原因有两个:
文档版式(layout)更复杂 → 增加视觉解析难度;
长文本在低分辨率图像(512×512 或 640×640)中变得模糊 → 信息丢失。
四、作者分析与启示
对于问题①(复杂布局),可以通过将文字渲染到单页布局来缓解;
对于问题②(模糊导致信息遗忘),作者提出:
这可能正体现出 “遗忘机制(forgetting mechanism)” 的一种自然特征。
即在极高压缩比下,模型自然丢弃部分信息,这与人类记忆的遗忘规律相似。
五、研究意义
这些结果表明:
“光学上下文压缩”是可行且高效的。
这种方法几乎不带额外开销(因为多模态系统本就配有视觉编码器)。
DeepSeek-OCR 在实际 OCR 应用中的性能表现与研究意义
一、段落主旨
作者强调:
二、实验与结果
实验基准
测试平台:OmniDocBench [27] —— 一个综合文档 OCR 基准。
对比模型:GOT-OCR2.0 [38]、MinerU2.0 [34] 等。
实验结果总结
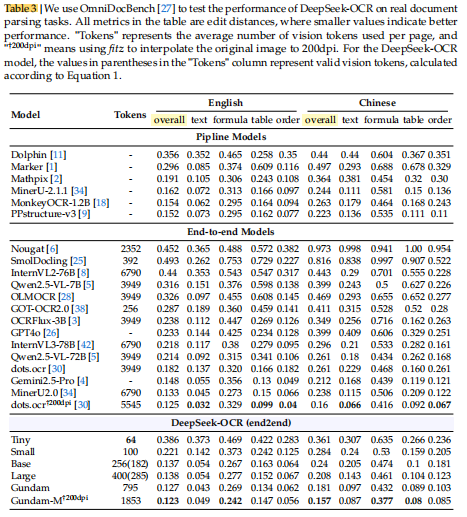
关键结论:
这种高压缩率意味着:
计算开销更低;
模型具备更高“研究上限”(research ceiling);
更适合大规模数据生成与部署。
三、不同文档类型的性能分析
作者进一步在 Table 4 中展示了不同类别文档所需的视觉 token 数量差异:
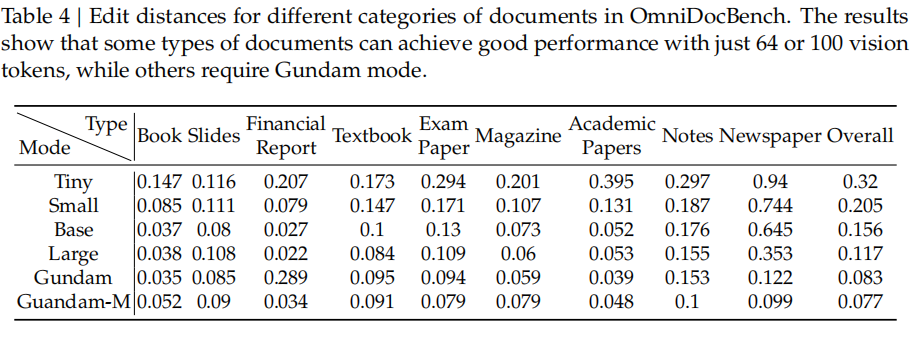
总结性观察:
不同文档类型的最优压缩比不同;
超过 10× 压缩时,模型性能开始下降;
这验证了前面提出的 “光学上下文压缩边界(compression boundary)”。
四、研究启示
这些结果进一步表明:
DeepSeek-OCR 可在高压缩条件下保持强识别性能,具备实际部署价值;
实验揭示了视觉 token 压缩的上限(约 10×);
这种分析对未来研究有指导意义,尤其是:
VLM 的视觉 token 优化(vision-token optimization);
LLM 的上下文压缩与遗忘机制(context compression & forgetting mechanisms)。
DeepSeek-OCR 模型的定性分析
一、Deep Parsing —— 深层解析能力
核心思想
DeepSeek-OCR 不仅能识别文字,还能“深入理解”文档内部的复杂视觉元素。
它可以通过 “二级模型调用(secondary model calls)” 对图像中的特定内容进行再解析(即二次分析),这种机制被作者称为 “Deep Parsing(深层解析)”。
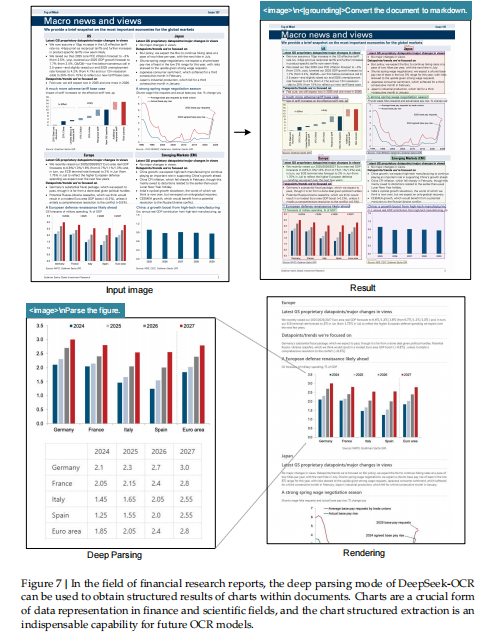


图表(charts):识别并结构化图形数据;
几何图形(geometry):分析图形的几何关系;
化学式(chemical formulas):识别并转化为结构化化学表达式;
自然图像(natural images):提取图像中的核心视觉语义。
这些任务全部通过 统一的 prompt 格式 实现,显示出 DeepSeek-OCR 在多任务场景下的通用性与一致性。
二、Multilingual Recognition —— 多语言识别能力
训练背景
由于互联网上的 PDF 数据涵盖上百种语言,
而多语言识别对于 LLM/VLM 训练数据生成 至关重要,
DeepSeek-OCR 被设计为能处理近 100 种语言的文档。
Layout OCR:保留页面版式;
Non-layout OCR:仅输出纯文本。

可视化结果(Figure 11)展示了模型在 阿拉伯语(Arabic) 和 僧伽罗语(Sinhala) 上的识别效果,表明模型具备跨语种泛化能力,能稳定处理不同书写系统。
这说明 DeepSeek-OCR 不仅是中英文 OCR 模型,而是一个通用多语言光学识别系统,适合全球文档场景。
三、 General Vision Understanding —— 通用视觉理解
虽然 DeepSeek-OCR 主要面向 OCR 场景,但作者也在训练阶段引入了部分 通用视觉数据,
因此模型具备一定的 图像理解能力(general image understanding)。

理解图像中的物体与场景;
执行基础描述(captioning)与内容识别任务。
DeepSeek-OCR 的研究意义、理论启发、未来方向与应用潜力
一、Discussion —— 对研究结果的反思与启示
作者的核心问题是:
“要解码 N 个文本 token,至少需要多少个视觉 token?”
通过 DeepSeek-OCR 的实验,他们发现:
在 约 10× 压缩比 下可实现 近乎无损的 OCR 解码;
在 20× 压缩比 下仍可保留 约 60% 准确率。
这表明光学上下文压缩(vision-text compression)是可行且高效的,并可能成为未来解决长上下文处理计算瓶颈的新方向。
可以将“光学压缩”机制扩展到 多轮对话历史的存储与处理。
例如:
对最近的对话轮次(最近上下文)保持高分辨率编码;
对较久远的上下文(旧轮次)逐渐压缩或降采样;
形成一种分层的上下文记忆结构(hierarchical context memory)。
这使模型能在计算资源恒定的前提下处理“理论上无限长”的上下文。
人类记忆会随时间逐渐衰退;
图像的视觉感知精度会随距离(分辨率)降低;
两者都呈现 “渐进式信息损失(progressive information loss)”。
他们甚至称这种机制为一种“类生物遗忘曲线(biological forgetting curve)”。
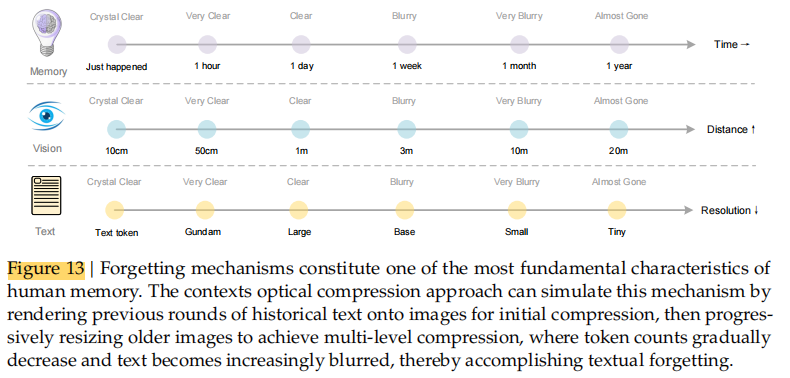
近的信息保持高保真(高分辨率);远的信息自然模糊(高压缩)
这种思想启发了“视觉化上下文记忆衰减”的设计思路,为未来 LLM 的记忆管理提供了新的理论路径。
尽管概念可行,但实际系统在以下方面仍需深入研究:
如何量化信息保真度;
压缩对语义一致性的影响;
视觉 token 的最优分配策略;
模型在极长上下文中的稳定性
他们认为这条路径能在信息保留与计算成本间实现理论平衡,但仍需在真实大模型体系中进一步验证。
二、Conclusion —— 总结与展望
本文提出并验证了 DeepSeek-OCR,
一个用于验证“光学上下文压缩(context optical compression)”可行性的模型。
实验证明:
模型能用少量视觉 token 解码出数量超过其 10 倍的文本 token;
验证了视觉压缩在文本处理中的有效性与潜力。
这为未来 VLM(视觉语言模型)与 LLM(大语言模型) 的结合开辟了新方向。
他们强调:
光学上下文压缩仍有巨大研究空间,是一个“极具潜力的新方向(promising new direction)”。
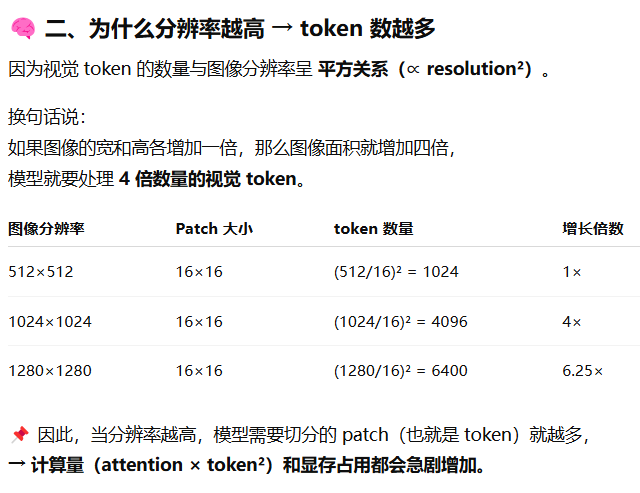
为什么分辨率越高视觉token越多

什么是MOE架构



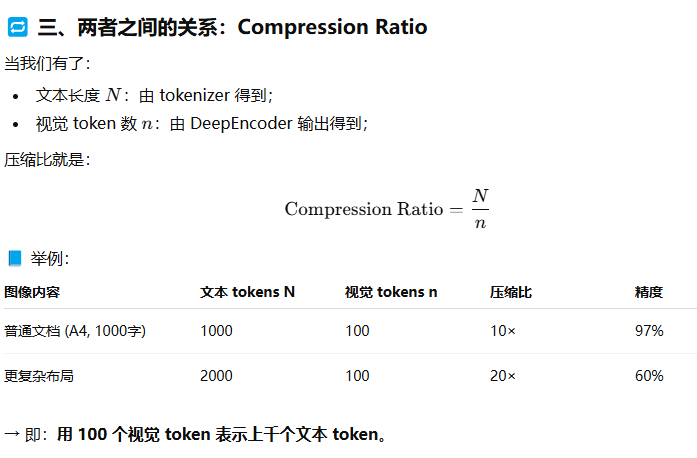
什么是压缩比



什么是多分辨率机制



下载vLLM
安装所依赖的包
最后安装加速器
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/226602.html