
本文基于 Ollama 0.6.x + DeepSeek-Coder-V2:16b,全程离线运行,数据不出内网。适合希望在本地搭建 AI 代码辅助能力的 Java 开发者或架构师。
在 SaaS API 盛行的今天,选择本地跑大模型看起来”多此一举”,但以下几个场景会让你觉得值:
- 代码隐私:企业内部代码、未公开算法不适合上传到云端 API;
- 零延迟抖动:内网请求无需排队,响应更稳定;
- 无 Token 计费:跑多少都不花钱,适合集成到 CI/CD 流程;
- 离线可用:断网环境(保密机房、飞行途中)照样跑。
| 模型规格 | 显存/内存需求 | 推荐场景 |
|---|---|---|
| deepseek-coder-v2:16b | 12 GB(GPU)/ 16 GB(CPU only) | 个人开发机、MacBook M 系列 |
| deepseek-coder-v2:236b | 128 GB+ | 服务器、高端工作站 |
本文以 16b 为例,M2 MacBook Pro(16 GB 统一内存)或 RTX 3080(12 GB 显存)均可流畅运行。
注意:CPU-only 模式也能跑,只是推理速度约为 GPU 的 1/5~1/10,日常调试够用。
- macOS 12+ / Linux(Ubuntu 22.04+)/ Windows 11(WSL2)
- Java 17+(本文示例基于 Java 21 虚拟线程)
- Maven 3.9+ 或 Gradle 8+
- Ollama(见下文安装)
curl -fsSL https://ollama.com/install.sh | sh安装完成后验证:
ollama –versionollama version 0.6.2
在 PowerShell 中启用 WSL2 后,进入 Ubuntu 子系统执行上述 curl 命令即可。Windows 原生版可直接从 https://ollama.com/download 下载安装包。
💡 扩展阅读:如果你希望用图形界面与本地模型对话(而不是纯 API 调用),可以配合 Open WebUI 使用,效果如下图所示:
▲ Open WebUI 提供类 ChatGPT 的本地对话界面,支持模型切换、文档上传、RAG 等功能(来源:Open WebUI 官方 GitHub)
ollama pull deepseek-coder-v2:16b模型文件约 9 GB,国内网络建议挂代理或等待耐心拉取。拉取完成后本地缓存于 ~/.ollama/models/,后续无需重新下载。
查看已安装模型:
ollama listNAME ID SIZE MODIFIED
deepseek-coder-v2:16b 8e9e29a4edce 9.1 GB 2 hours ago
Ollama 安装后会自动注册系统服务(macOS 为 launchd,Linux 为 systemd)。手动启动:
# 前台运行(方便看日志)ollama serve
或后台运行
nohup ollama serve > /tmp/ollama.log 2>&1 &
服务默认监听 http://127.0.0.1:11434,验证:
curl http://localhost:11434/api/tags返回 JSON 中能看到已拉取的模型列表即表示服务正常。
如果希望局域网内其他机器调用,修改监听地址:
OLLAMA_HOST=0.0.0.0:11434 ollama serve安全提示:生产环境请在前面加 Nginx 反向代理并配置认证,不要将 11434 端口直接暴露到公网。
在集成 Java 之前,先用命令行验证模型是否正常:
ollama run deepseek-coder-v2:16b “用 Java 写一个线程安全的单例模式,要求双重检查锁定”几秒内应该会流式输出代码。如能看到标准的 DCL 单例实现,说明模型已就绪。
Ollama 提供标准 HTTP REST API,兼容 OpenAI API 格式,因此 Java 接入方式非常灵活。下面从三个层次由浅入深演示。
ollama-demo/ ├── pom.xml └── src/main/java/com/example/├── OllamaClient.java # 原生 HttpClient 封装 ├── OllamaStreamClient.java # 流式输出版本 ├── OllamaOpenAIClient.java # OpenAI 兼容接口版本 └── Main.java # 示例入口
com.fasterxml.jackson.core
jackson-databind
2.17.2
com.theokanning.openai-gpt3-java
service
0.18.2
这是最轻量的方式,适合不想引入额外依赖的场景。
package com.example; import com.fasterxml.jackson.databind.JsonNode; import com.fasterxml.jackson.databind.ObjectMapper; import com.fasterxml.jackson.databind.node.ObjectNode;
import java.net.URI; import java.net.http.HttpClient; import java.net.http.HttpRequest; import java.net.http.HttpResponse; import java.time.Duration;
/
- Ollama 原生 REST API 封装
- 对应接口:POST /api/generate */ public class OllamaClient {
private static final String BASE_URL = “http://localhost:11434"; private static final String MODEL = ”deepseek-coder-v2:16b“;
private final HttpClient httpClient; private final ObjectMapper mapper;
public OllamaClient() {
this.httpClient = HttpClient.newBuilder() .connectTimeout(Duration.ofSeconds(10)) .build(); this.mapper = new ObjectMapper();
}
/
- 同步调用,返回完整响应文本 *
- @param prompt 用户输入的提示词
- @return 模型生成的文本 */ public String generate(String prompt) throws Exception { // 构建请求体 ObjectNode body = mapper.createObjectNode(); body.put(”model“, MODEL); body.put(”prompt“, prompt); body.put(”stream“, false); // 非流式,一次性返回全部结果
// 可选:设置推理参数 ObjectNode options = mapper.createObjectNode(); options.put(”temperature“, 0.2); // 代码场景建议低温,减少随机性 options.put(”top_p“, 0.9); options.put(”num_ctx“, 8192); // 上下文窗口,根据显存调整 body.set(”options“, options);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(BASE_URL + "/api/generate")) .header("Content-Type", "application/json") .POST(HttpRequest.BodyPublishers.ofString(mapper.writeValueAsString(body))) .timeout(Duration.ofMinutes(5)) .build();
HttpResponse
response = httpClient.send(
request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
throw new RuntimeException("Ollama 返回异常状态码:" + response.statusCode() + "\n" + response.body());
}
JsonNode json = mapper.readTree(response.body()); return json.get(”response“).asText(); }
public static void main(String[] args) throws Exception {
OllamaClient client = new OllamaClient(); String result = client.generate( "请用 Java 实现一个泛型栈(Stack),要求线程安全,并附上单元测试示例。" ); System.out.println(result);
} }
代码生成场景下,流式输出能让用户感知到”正在思考”的过程,体验更接近 Copilot。
package com.example; import com.fasterxml.jackson.databind.JsonNode; import com.fasterxml.jackson.databind.ObjectMapper; import com.fasterxml.jackson.databind.node.ObjectNode;
import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.URI; import java.net.http.HttpClient; import java.net.http.HttpRequest; import java.net.http.HttpResponse; import java.time.Duration; import java.util.function.Consumer;
/
- 流式调用封装,逐 token 回调 */ public class OllamaStreamClient {
private static final String BASE_URL = ”http://localhost:11434"; private static final String MODEL = “deepseek-coder-v2:16b”;
private final HttpClient httpClient; private final ObjectMapper mapper;
public OllamaStreamClient() {
this.httpClient = HttpClient.newBuilder() .connectTimeout(Duration.ofSeconds(10)) .build(); this.mapper = new ObjectMapper();
}
/
- 流式生成,每收到一个 token 就触发 onToken 回调 *
- @param prompt 提示词
- @param onToken token 消费者,可用于实时打印或写入 SSE 响应
- @param onDone 完成回调 */ public void generateStream(String prompt,
Consumer
onToken, Runnable onDone) throws Exception {
ObjectNode body = mapper.createObjectNode(); body.put(“model”, MODEL); body.put(“prompt”, prompt); body.put(“stream”, true); // 开启流式
ObjectNode options = mapper.createObjectNode(); options.put(“temperature”, 0.2); body.set(“options”, options);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(BASE_URL + "/api/generate")) .header("Content-Type", "application/json") .POST(HttpRequest.BodyPublishers.ofString(mapper.writeValueAsString(body))) .timeout(Duration.ofMinutes(10)) .build();
// 使用 InputStream 逐行读取 NDJSON(Newline-Delimited JSON) HttpResponse
response = httpClient.send(
request, HttpResponse.BodyHandlers.ofInputStream());
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(response.body()))) { String line; while ((line = reader.readLine()) != null) { if (line.isBlank()) continue; JsonNode node = mapper.readTree(line); String token = node.path("response").asText(""); if (!token.isEmpty()) { onToken.accept(token); } // done=true 表示本次生成结束 if (node.path("done").asBoolean(false)) { onDone.run(); break; } }
} }
public static void main(String[] args) throws Exception {
OllamaStreamClient client = new OllamaStreamClient(); System.out.print("AI: "); client.generateStream( "用 Java 21 虚拟线程实现一个简单的 HTTP 服务器", token -> { System.out.print(token); // 实时打印每个 token System.out.flush(); }, () -> System.out.println("\n\n[生成完毕]") );
} }
Ollama 同样支持 OpenAI 格式的 /api/chat 接口,便于维护多轮上下文。
package com.example; import com.fasterxml.jackson.databind.JsonNode; import com.fasterxml.jackson.databind.ObjectMapper; import com.fasterxml.jackson.databind.node.ArrayNode; import com.fasterxml.jackson.databind.node.ObjectNode;
import java.net.URI; import java.net.http.HttpClient; import java.net.http.HttpRequest; import java.net.http.HttpResponse; import java.time.Duration; import java.util.ArrayList; import java.util.List;
/
- 多轮对话封装,维护完整的消息历史 */ public class OllamaChatClient {
private static final String BASE_URL = “http://localhost:11434"; private static final String MODEL = ”deepseek-coder-v2:16b“;
// 系统提示词,设定 AI 角色 private static final String SYSTEM_PROMPT = ”“”
你是一位资深 Java 架构师,代码风格遵循阿里巴巴 Java 开发手册。 回答时请: 1. 先给出核心思路 2. 提供可直接运行的完整代码 3. 指出潜在的性能或安全风险 """;
private final HttpClient httpClient; private final ObjectMapper mapper; private final List
messages; // 消息历史
public OllamaChatClient() {
this.httpClient = HttpClient.newBuilder() .connectTimeout(Duration.ofSeconds(10)) .build(); this.mapper = new ObjectMapper(); this.messages = new ArrayList<>(); // 注入系统角色 ObjectNode sysMsg = mapper.createObjectNode(); sysMsg.put("role", "system"); sysMsg.put("content", SYSTEM_PROMPT); messages.add(sysMsg);
}
/
- 发送用户消息,返回 AI 回复 */ public String chat(String userMessage) throws Exception { // 追加用户消息 ObjectNode userMsg = mapper.createObjectNode(); userMsg.put(“role”, “user”); userMsg.put(“content”, userMessage); messages.add(userMsg);
// 构建请求 ObjectNode body = mapper.createObjectNode(); body.put(“model”, MODEL); body.put(“stream”, false);
ArrayNode msgArray = mapper.createArrayNode(); messages.forEach(msgArray::add); body.set(“messages”, msgArray);
ObjectNode options = mapper.createObjectNode(); options.put(“temperature”, 0.1); body.set(“options”, options);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(BASE_URL + "/api/chat")) .header("Content-Type", "application/json") .POST(HttpRequest.BodyPublishers.ofString(mapper.writeValueAsString(body))) .timeout(Duration.ofMinutes(5)) .build();
HttpResponse
response = httpClient.send(
request, HttpResponse.BodyHandlers.ofString());
JsonNode json = mapper.readTree(response.body()); String assistantReply = json
.path("message") .path("content") .asText();
// 将 AI 回复追加到历史,维护上下文 ObjectNode assistantMsg = mapper.createObjectNode(); assistantMsg.put(“role”, “assistant”); assistantMsg.put(“content”, assistantReply); messages.add(assistantMsg);
return assistantReply; }
/
- 清除对话历史(保留系统提示) */ public void clearHistory() { messages.subList(1, messages.size()).clear(); }
public static void main(String[] args) throws Exception {
OllamaChatClient client = new OllamaChatClient(); // 第一轮 System.out.println("=== 第一轮 ==="); System.out.println(client.chat("帮我写一个 Redis 分布式锁的 Java 实现")); // 第二轮(AI 记得上轮对话) System.out.println("\n=== 第二轮(追问)==="); System.out.println(client.chat("刚才的实现中,如果业务执行时间超过锁过期时间怎么办?给出看门狗机制的改进版本"));
} }
真实项目中通常会把 Ollama 封装为 Spring Bean,统一管理配置和生命周期。
ollama: base-url: http://localhost:11434 model: deepseek-coder-v2:16b options: temperature: 0.2 num-ctx: 8192 top-p: 0.9@ConfigurationProperties(prefix = “ollama”) @Configuration public class OllamaProperties { private String baseUrl; private String model; private Options options; // getters/setters 略
public static class Options {
private double temperature = 0.2; private int numCtx = 4096; private double topP = 0.9; // getters/setters 略
} }
@Service @Slf4j public class CodeAssistantService { private final OllamaProperties props; private final WebClient webClient; private final ObjectMapper mapper;
public CodeAssistantService(OllamaProperties props) {
this.props = props; // Spring WebFlux WebClient,支持响应式流 this.webClient = WebClient.builder() .baseUrl(props.getBaseUrl()) .codecs(c -> c.defaultCodecs().maxInMemorySize(10 * 1024 * 1024)) .build(); this.mapper = new ObjectMapper();
}
/
- 响应式流式代码生成,适合 SSE 接口
- 返回 Flux
,每个元素是一个 token */ public Flux
generateCodeStream(String prompt) { Map
requestBody = Map.of(
"model", props.getModel(), "prompt", prompt, "stream", true, "options", Map.of( "temperature", props.getOptions().getTemperature(), "num_ctx", props.getOptions().getNumCtx() )
);
return webClient.post()
.uri("/api/generate") .bodyValue(requestBody) .retrieve() .bodyToFlux(String.class) .flatMap(line -> { try { JsonNode node = mapper.readTree(line); String token = node.path("response").asText(""); return token.isEmpty() ? Flux.empty() : Flux.just(token); } catch (Exception e) { log.warn("解析 token 失败: {}", line); return Flux.empty(); } });
} }
@RestController @RequestMapping(“/api/code”) public class CodeAssistantController { private final CodeAssistantService service;
@GetMapping(value = “/generate”, produces = MediaType.TEXT_EVENT_STREAM_VALUE) public Flux
generate(@RequestParam String prompt) {
return service.generateCodeStream(prompt);
} }
前端通过 EventSource 即可实时接收生成内容,轻松实现类 ChatGPT 的打字机效果。

▲ Spring Boot SSE 接口 + 前端 EventSource = 流畅的打字机输出体验(Open WebUI 同款交互逻辑)
Ollama 默认单队列处理请求(一次跑一个推理任务),多并发时请求会排队。如果需要处理多并发,可以:
- 启动多个 Ollama 实例(绑定不同端口),前面用 Nginx upstream 负载均衡;
- 设置环境变量
OLLAMA_NUM_PARALLEL=4(需 GPU 显存足够)。
推理大模型的响应时间随 prompt 长度变化较大,建议 Java 客户端设置合理超时:
// 连接超时 10s,读取超时 5min(复杂代码生成可能需要更长时间) HttpClient.newBuilder() .connectTimeout(Duration.ofSeconds(10)) .build(); request = HttpRequest.newBuilder()
.timeout(Duration.ofMinutes(5)) ...
服务启动后第一次推理会加载模型到显存,耗时较长(约 10~30 秒)。可以在应用启动时发送一个 warmup 请求:
@EventListener(ApplicationReadyEvent.class) public void warmup() {
log.info("Ollama 模型预热中..."); try { client.generate("hello"); log.info("Ollama 预热完成"); } catch (Exception e) { log.error("Ollama 预热失败,请检查服务是否正常", e); } }
代码场景下,Prompt 质量直接影响输出质量,几个经验:
// ❌ 模糊 Prompt “写一个排序算法” // ✅ 精确 Prompt,明确语言、约束、预期输出格式 “”“ 请用 Java 17 实现归并排序,要求:
- 泛型支持,元素实现 Comparable 接口
- 时间复杂度 O(n log n),空间复杂度 O(n)
- 包含完整 Javadoc 注释
- 附带 JUnit 5 单元测试(覆盖空数组、单元素、已排序等边界情况) ”“”
Q: ollama pull 卡在 0% 不动?
A: 国内网络访问 http://ollama.com 受限,建议:
- 配置 HTTP 代理:
export https_proxy=http://127.0.0.1:7890 - 或使用国内镜像(社区维护,以最新为准)
Q: 调用 API 返回 model not found?
A: 检查模型名称是否完全匹配,运行 ollama list 确认本地已有该模型,名称区分大小写。
Q: Java 程序抛出 SocketTimeoutException?
A: 推理时间超过客户端超时设置,适当延长 .timeout(Duration.ofMinutes(10)) 即可。
Q: 输出中文乱码?
A: Java HttpResponse 默认 UTF-8 解码,如有问题显式指定:
HttpResponse.BodyHandlers.ofString(StandardCharsets.UTF_8)Q: GPU 显存不足(CUDA out of memory)?
A: 降低模型规格(如换用 7b),或降低 num_ctx(上下文长度),减少显存占用。
package com.example; public class Main {
public static void main(String[] args) throws Exception { System.out.println("========== 场景1:代码生成 =========="); OllamaClient basic = new OllamaClient(); String code = basic.generate(""" 用 Java 实现一个支持过期时间的本地缓存(LRU,容量 100), 不使用任何外部依赖,线程安全,附使用示例。 """); System.out.println(code); System.out.println("\n========== 场景2:流式代码审查 =========="); OllamaStreamClient stream = new OllamaStreamClient(); stream.generateStream( """ 请审查以下代码,指出潜在的 Bug 和性能问题: public String getUserName(Long userId) { User user = userDao.findById(userId); return user.getName(); } """, token -> { System.out.print(token); System.out.flush(); }, () -> System.out.println("\n[审查完毕]") ); System.out.println("\n========== 场景3:多轮对话重构 =========="); OllamaChatClient chat = new OllamaChatClient(); System.out.println(chat.chat("帮我把下面的 for 循环改成 Stream API:\n" + "List
result = new ArrayList<>();\n" + "for (User u : users) {\n" + " if (u.getAge() > 18) result.add(u.getName());\n" + "}")); System.out.println(chat.chat("很好,现在加上并行流优化,并解释适用场景和注意事项")); }
}
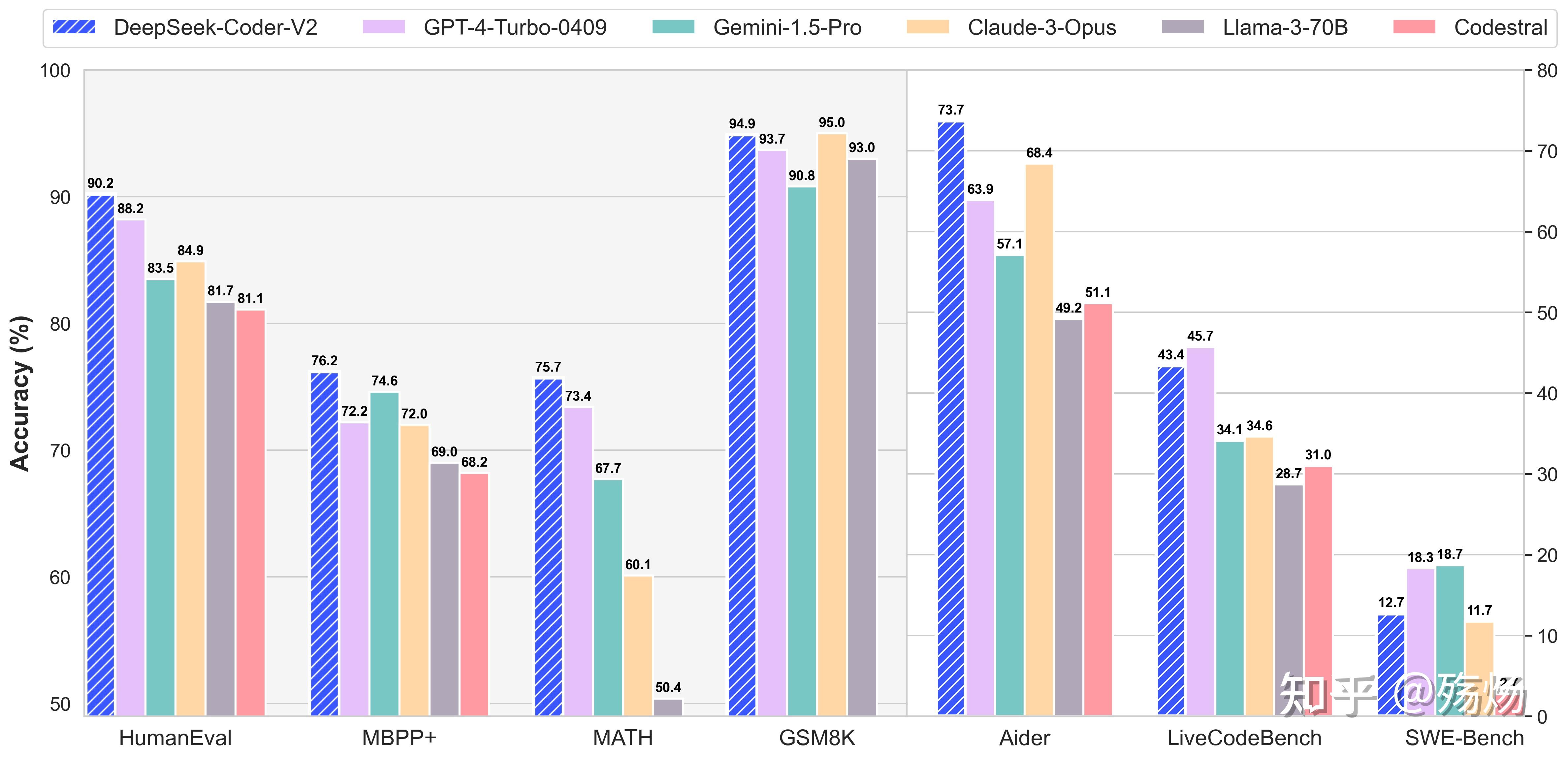
DeepSeek-Coder 系列在代码任务上的表现已经非常接近 GPT-4,结合 Ollama 的本地部署能力,是目前企业内网 AI 编程辅助的最优性价比方案之一。
原创技术文章 | 如有问题欢迎在评论区讨论
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/220901.html