
个人笔记本电脑Windows11硬件配置参考:
- CPU:AMD Ryzen 5 4600H with Radeon Graphics 3.00 GHz
- 内核:6
- 逻辑处理器:12
- 内存:16GB
- GPU:512MB
- 操作系统:Windows 11
ollama: 一个模型管理工具,可下载并运行不同的模型。
官网:ollama.com 下载windows版本
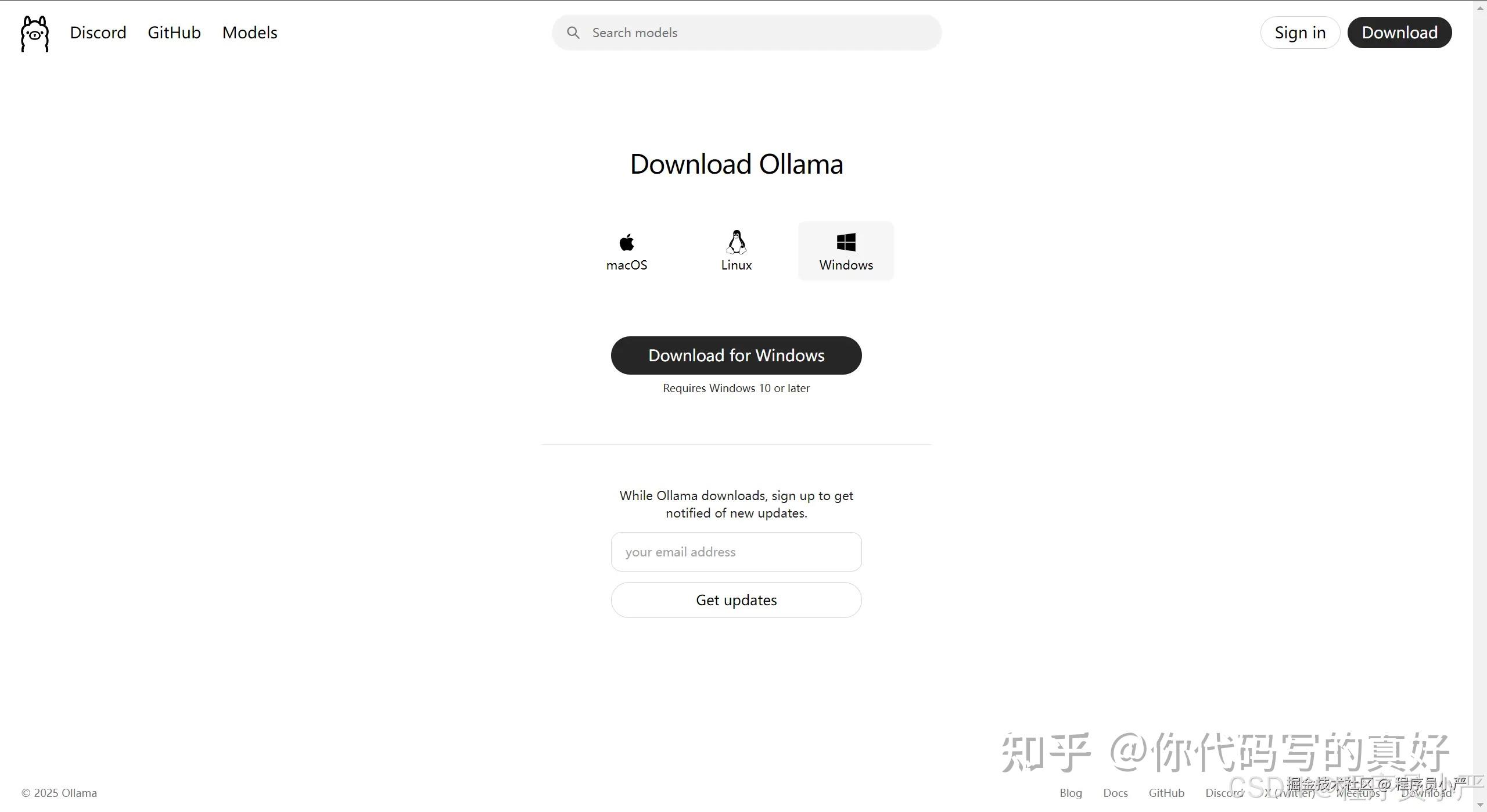
查看ollama是否安装成功:命令行输入 ollama -v 命令,出现如下版本号说明安装成功
注:常用ollama命令如下
# 运行模型 ollama run 模型名称 # 列出模型 ollama list # 拉取模型 ollama pull 模型名称 # 删除模型 ollama rm 模型名称 # 显示模型信息 ollama show # 启动ollama服务 ollama serve 【PS:为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集,内容包含:DeepSeek部署安装教程,AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频,有需要的朋友可以点击下方卡片免费获取!】
大模型:yyds!全网独一份的AI大模型学习教程资源!!可根据自己的需求,修改ollama的环境变量,一般本地部署修改OLLAMA_HOST和OLLAMA_MODELS即可
OLLAMA_HOST:Ollama 监听的网络接口,设置OLLAMA_HOST = 0.0.0.0,可以让 Ollama 监听所有可用的网络接口,从而允许外部网络访问:0.0.0.0:11434,否则在RagFlow中,模型url无法使用本地IP进行注册。OLLAMA_MODELS:指定模型镜像的存储路径。默认存储在C盘:C:\Users퇧ame%.ollama\models。例如,设置OLLAMA_HOST = D:\ollama,可节约内存。OLLAMA_KEEP_ALIVE:控制模型在内存中的存活时间。例如,设置OLLAMA_KEEP_ALIVE=24h可以让模型在内存中保持 24 小时,提高访问速度。OLLAMA_PORT:允许更改 ollama 的默认服务端端口(11434)。例如,设置OLLAMA_PORT=8080。OLLAMA_NUM_PARALLEL:决定了 Ollama 可以同时处理的用户请求数量。例如,设置OLLAMA_NUM_PARALLEL=4可以让 Ollama 同时处理两个并发请求。OLLAMA_MAX_LOADED_MODELS:限制了 Ollama 可以同时加载的模型数量。例如,设置OLLAMA_MAX_LOADED_MODELS=4可以确保系统资源得到合理分配。
在ollama模型页面选择需要下载的DeepSeek参数规模,然后点击右侧的“复制”按钮,复制下载模型的命令。
ollama run deepseek-r1:7b 
打开windows命令提示符工具(WIN + R快捷键,然后输入cmd,回车)。输入安装运行命令ollama run deepseek-r1:7b,ollama会自动下载模型,成功之后,如下页面所示:
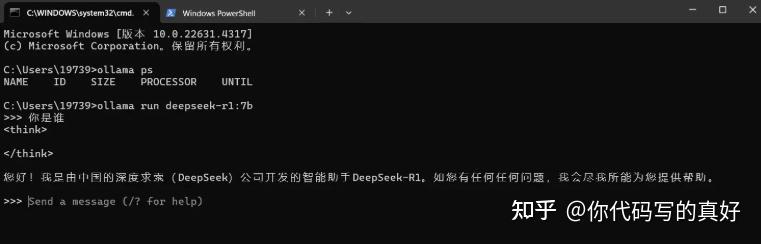
可查看当前加载的模型、所占的内存大小以及使用的处理器类型:
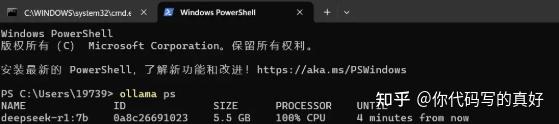
注意:运行过程中会出现以下问题
1)内存不够:需要释放本地内存,保证本地内存充足。

目的:RagFlow相关组件依赖于Docker运行。
下载Windows桌面端,官网下载地址:www.docker.com
如下图所示:打开Docker Desktop->点击设置->Docker Engine
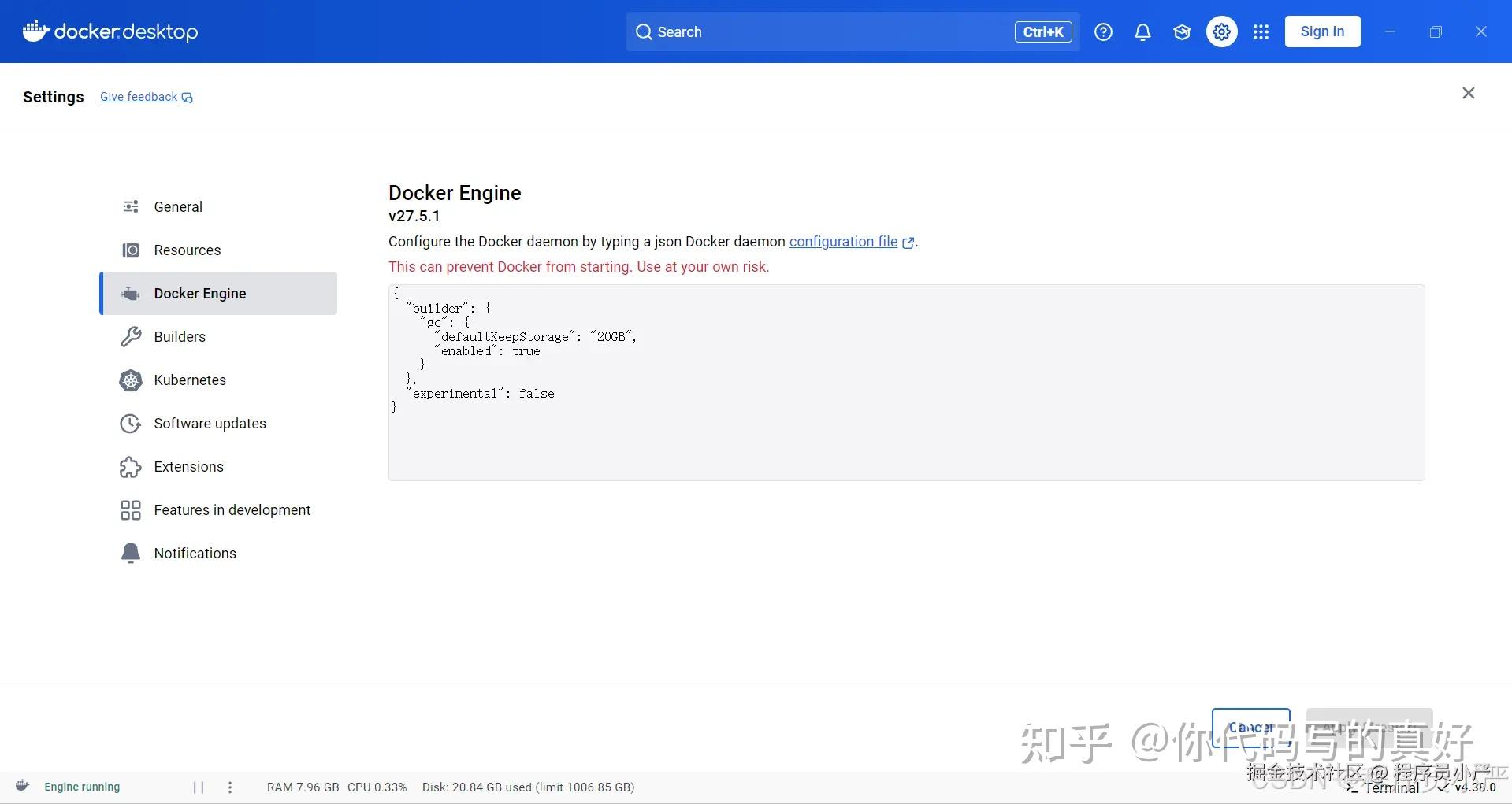
配置如下json镜像源,点击应用并重启 Docker。
“registry-mirrors”: ["https://docker.1ms.run" ]
官方环境要求如下:
CPU >= 4 核 RAM >= 16 GB Disk >= 50 GB Docker >= 24.0.0 & Docker Compose >= v2.26.1
下载或者克隆官方仓库至本地:
git clone https://github.com/infiniflow/ragflow.git - 镜像下载完整发行版 修改
ragflow/docker/.env文件,设置RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0来下载 RAGFlow 镜像的 v0.16.0 完整发行版

- 文档引擎修改 修改
ragflow/docker/.env文件,设置DOC_ENGINE=infinity切换文档引擎。

注意:Infinity 目前官方并未正式支持在 Linux/arm64 架构下的机器上运行.
- 上传文件大小修改 修改
/ragflow/docker/nginx/nginx.conf文件,设置client_max_body_size大小

cd ragflow/docker docker compose -f docker-compose.yml up -d 这个下载过程本地如果没有搭建梯子会很慢,镜像下载容易失败,ragflow镜像大概有10个G,最好搭个梯子。
镜像拉取失败,如下:
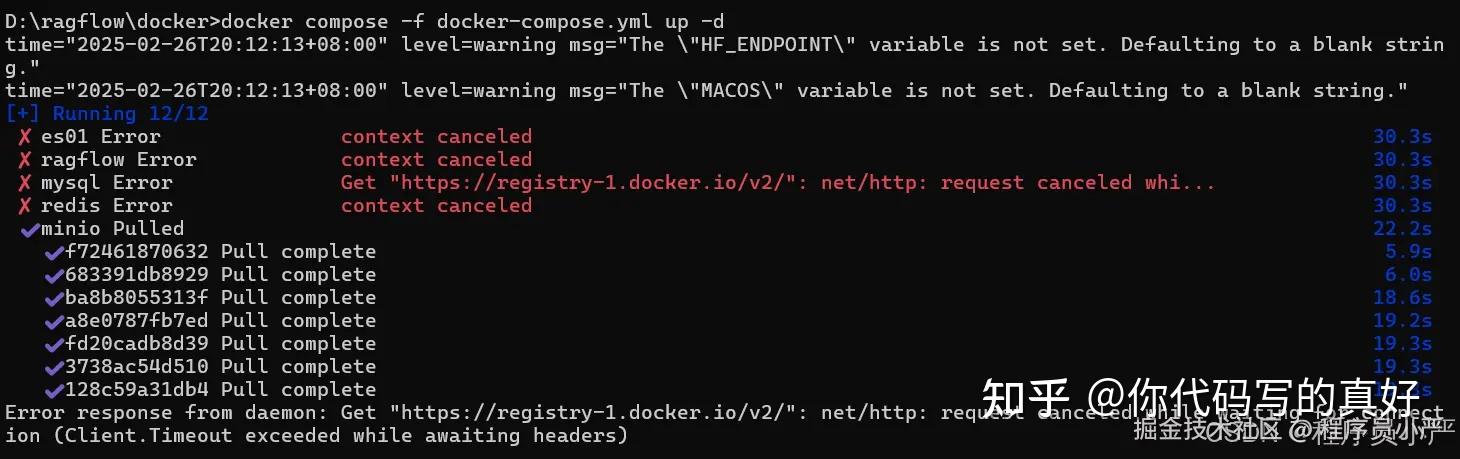
镜像拉取失败之后,先停止并删除容器,重新配置好docker镜像源,如果你搭建了梯子(科学上网),就不需要配置镜像源了:
docker compose -f docker-compose.yml down 镜像拉取成功之后,会自动启动ragflow,查看Docker Desktop控制台包含如下六个运行中的容器:
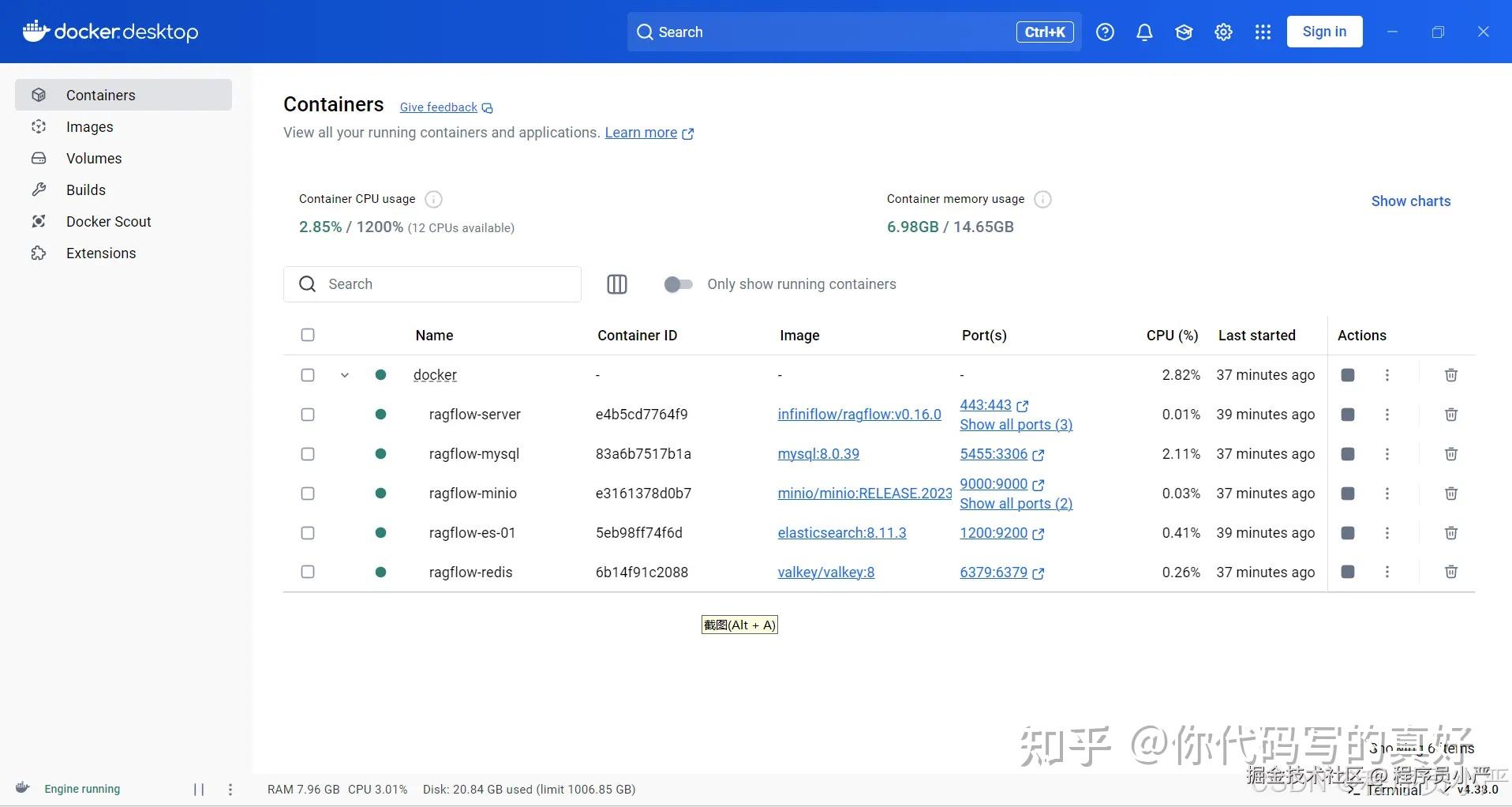
Minio:文件上传到此文件服务器。
Redis:文件解析度时候需要使用redis消息队列进行暂存,方便异步执行。
Elasticsearch:存储向量数据、任务信息。
MySql:存储用户信息、系统配置信息(比如配置知识库名称)、任务定义、执行状态、结果等。
在浏览器输入127.0.0.1,默认端口号是80,使用邮箱注册登陆即可。
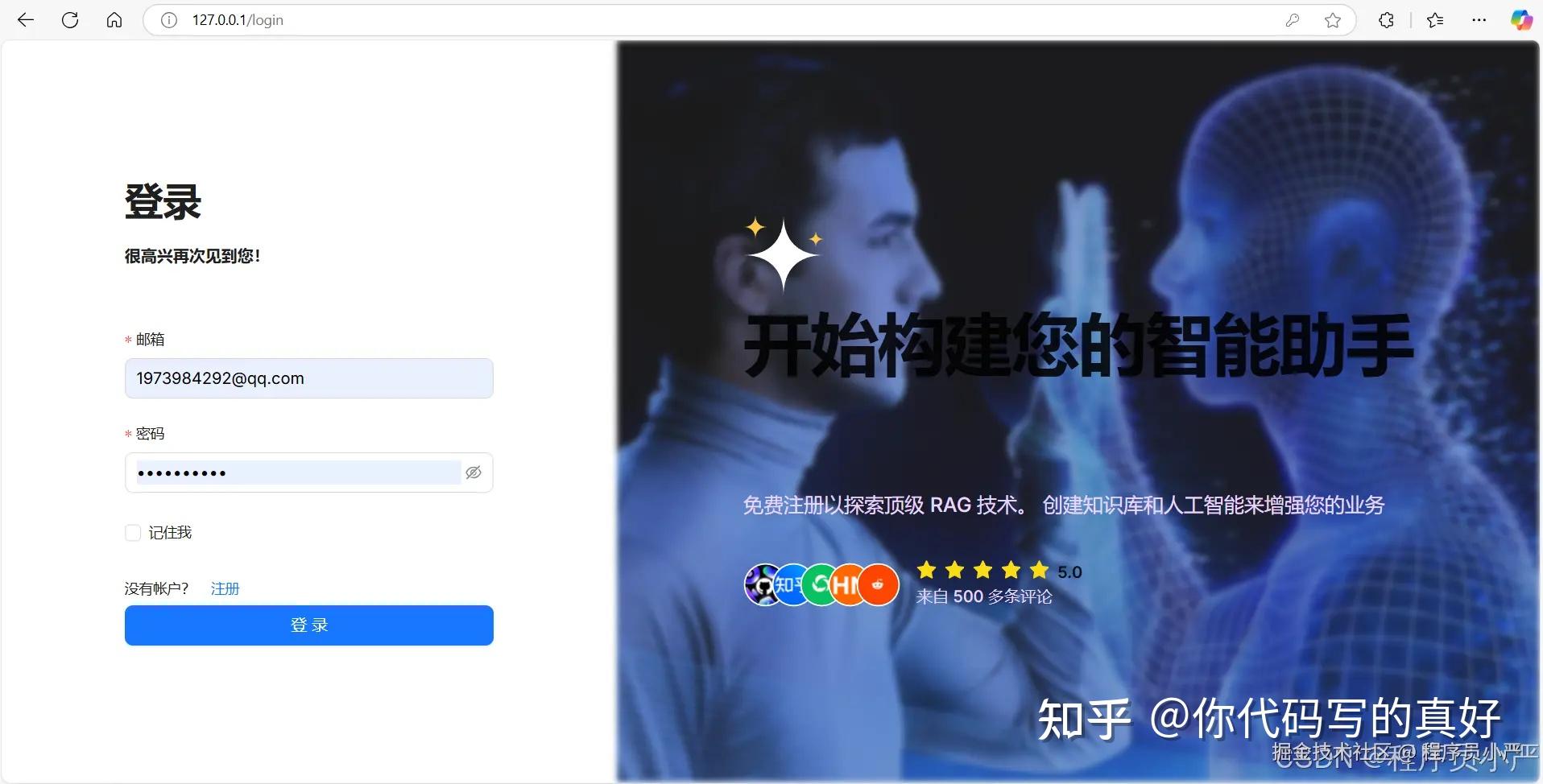
点击个人中心-》模型提供商-》在此设置模型参数
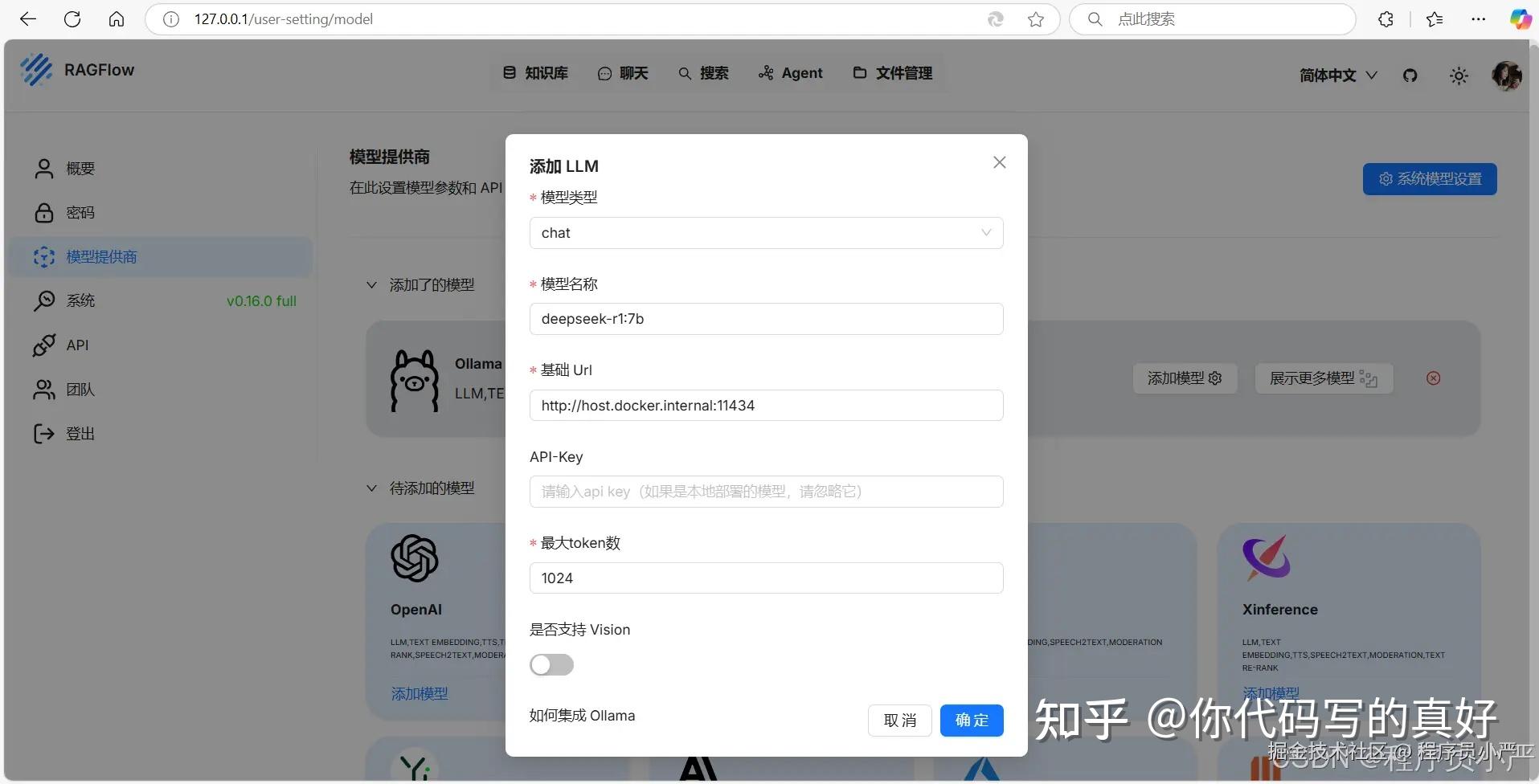
1)模型类型:DeepSeek 模型选择chat,bge-m3 模型选择 embedding
2)模型名称:Ollama -list命令中列出的模型名称填写(建议在列表中复制),如:deepseek-r1:7b
3)基础Url:http://host.docker.internal:11434
4)最大token数:可随便填写(本地部署不消耗在线 token),如:1024
还是点击个人中心-》模型提供商-》系统模型设置
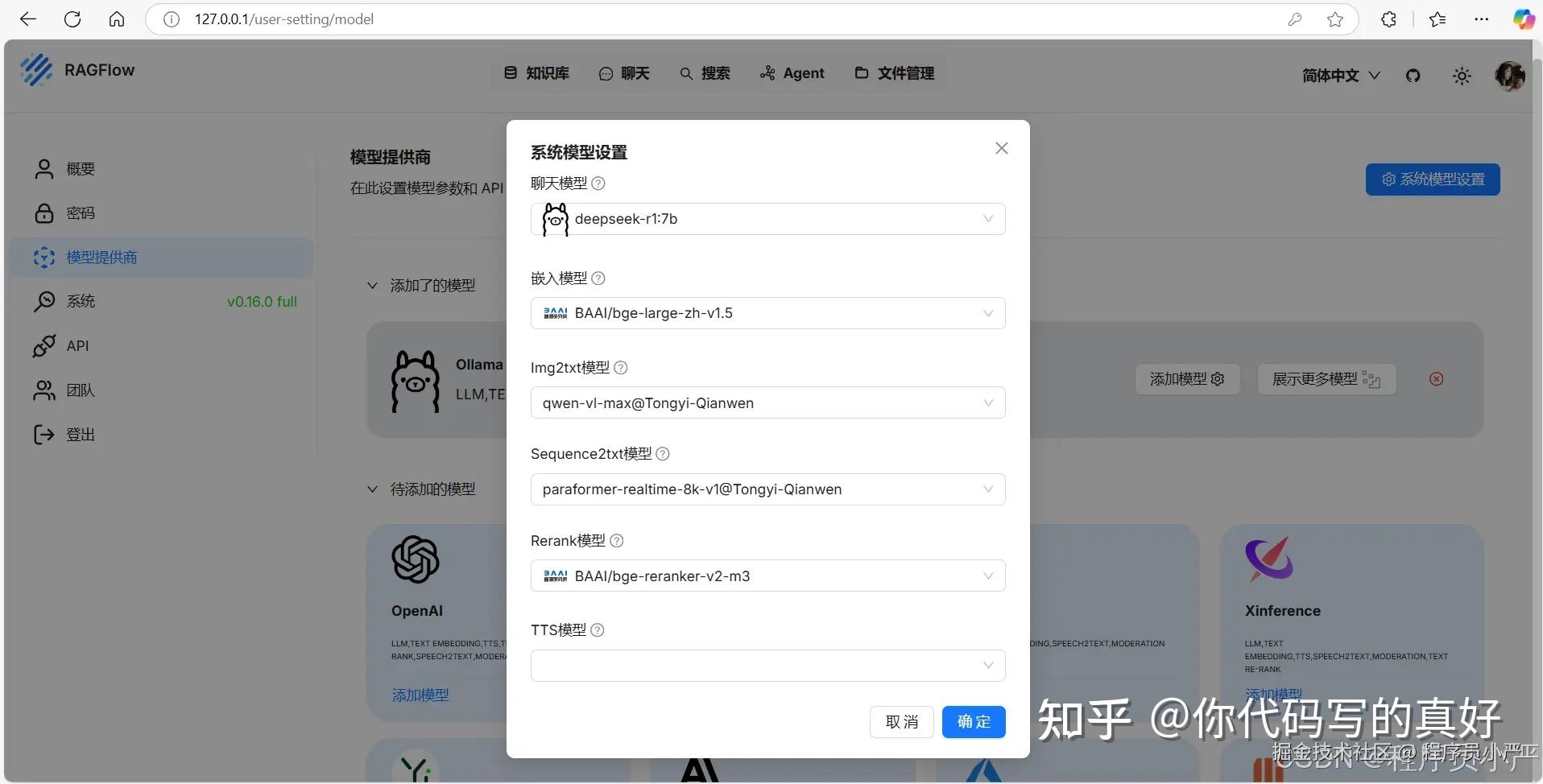
聊天模型选择:本地部署的deepseek-r1:7b
嵌入模型,Img2txt模型、Sequence2txt模型、Rerank模型、都是RagFlow默认的
这里简单说一下这几个模型之间的联系:
嵌入模型提供数据表示,Img2txt和Sequence2txt模型生成文本,Rerank模型优化结果,聊天模型生成最终回复,TTS模型将文本转为语音。
知识库的内容检索回答,需要先将文件解析成块后才能问答。
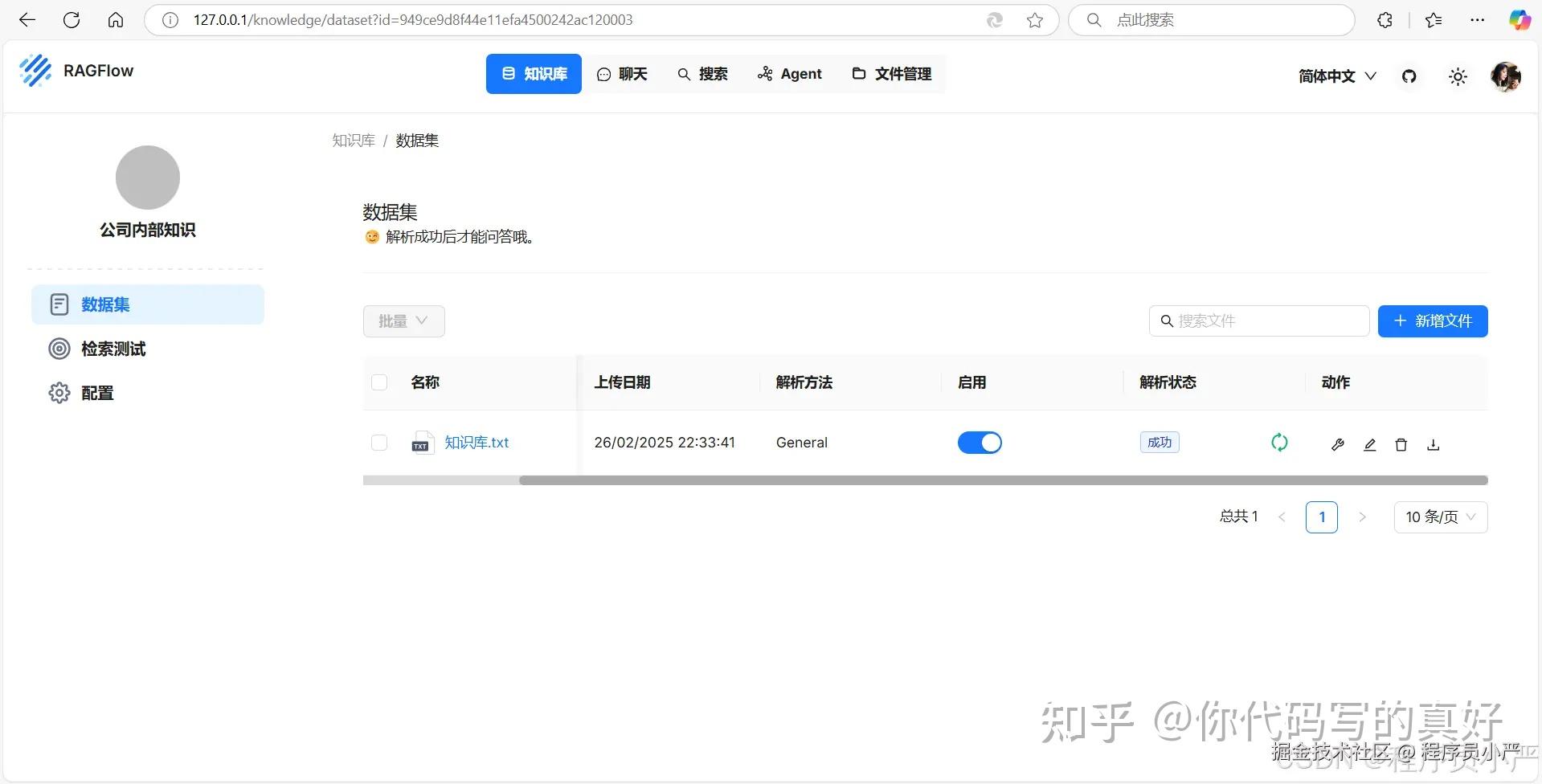
配置创建好的知识库模型,就可以进行检索了。
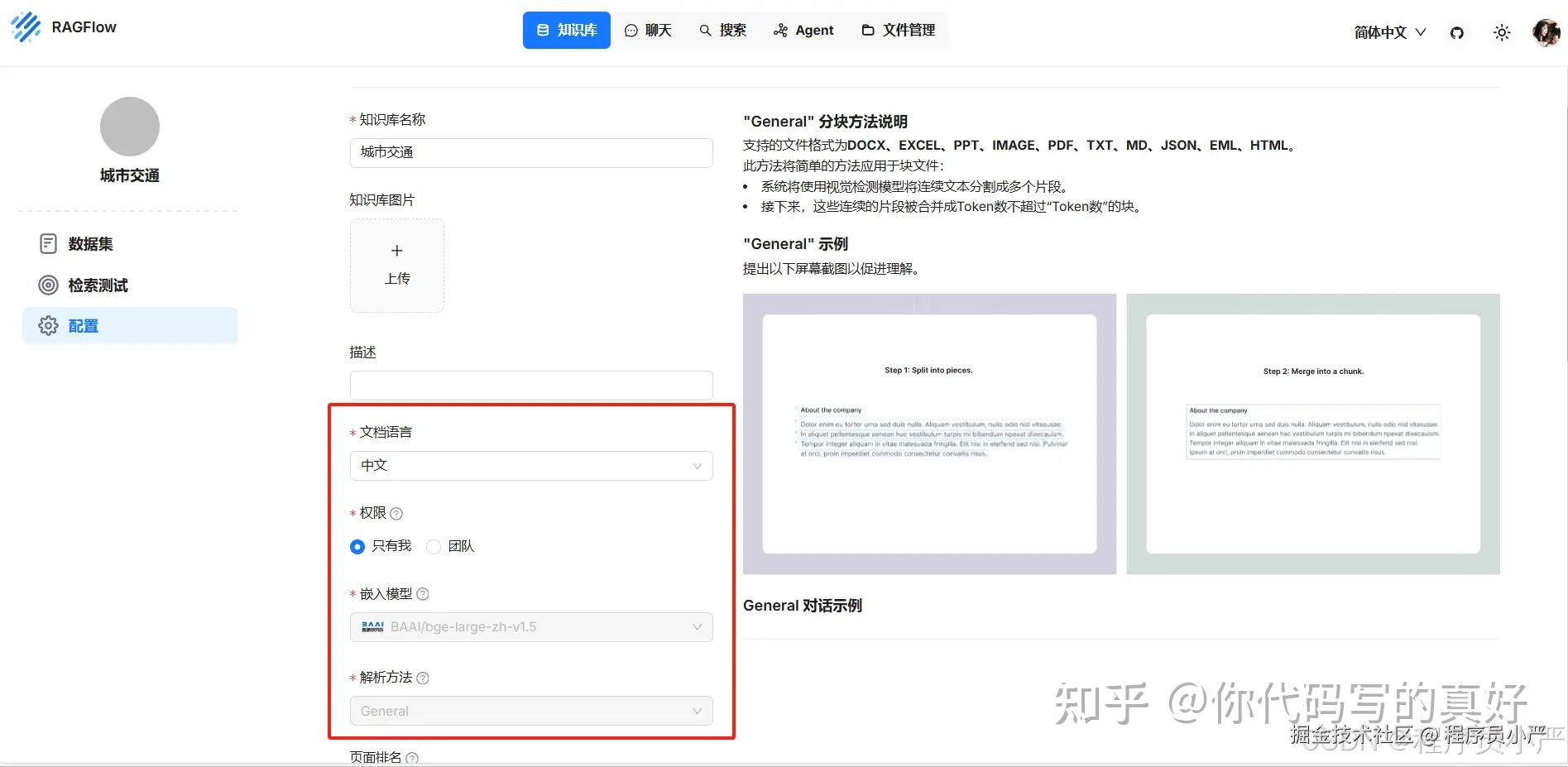
添加聊天助手做知识问答。
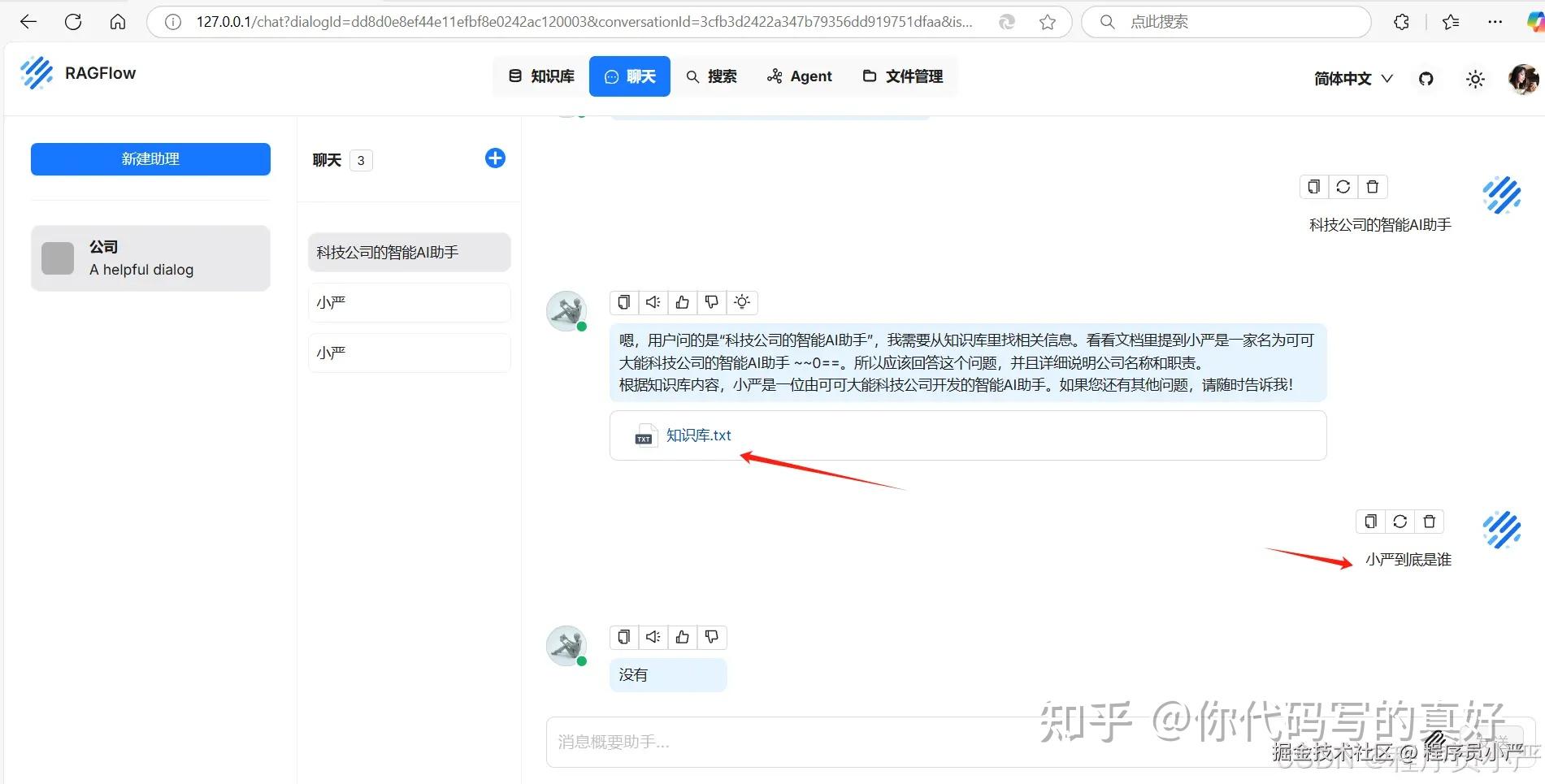
检索出错:
ERROR: Connection error caused by: ConnectionError(Connection error caused by: NewConnectionError(: Failed to establish a new connection: 【Errno 111】 Connection refused))
解决方案:
调整windows对docker desktop的内存分配。
win + r,调出运行,输入 %UserProfile%,进入用户文件夹
在用户文件夹下创建一个新的文件,改名为 .wslconfig,内容如下:
[wsl2] memory=16GB # 分配的内存 processors=12 # 处理器核心数量,考虑超线程 swap=0 localhostForwarding=true保存文件后,重启docker和WSL。
- 退出docker,任务管理器中确保无docker相关进程
- win+r调出运行,输入cmd并回车,在命令提示符中,输入以下内容并回车
wsl –shutdown重新打开docker,确保容器中所有的程序都运行,重新在浏览器中连接ragflow进行尝试
目前在官方发布的最版本v0.16.0中,还是会存在长文本回复中断问题这个问题,并且Github官方仓库中有很多关于此问题的issuse,后续看ragflow官方团队发布最新版本时是否会解决这个问题。
解决方案:升级到最新的经过测试的版本nightly,这里我查了一下官方升级文档如下:
ragflow.io/docs/dev/up…
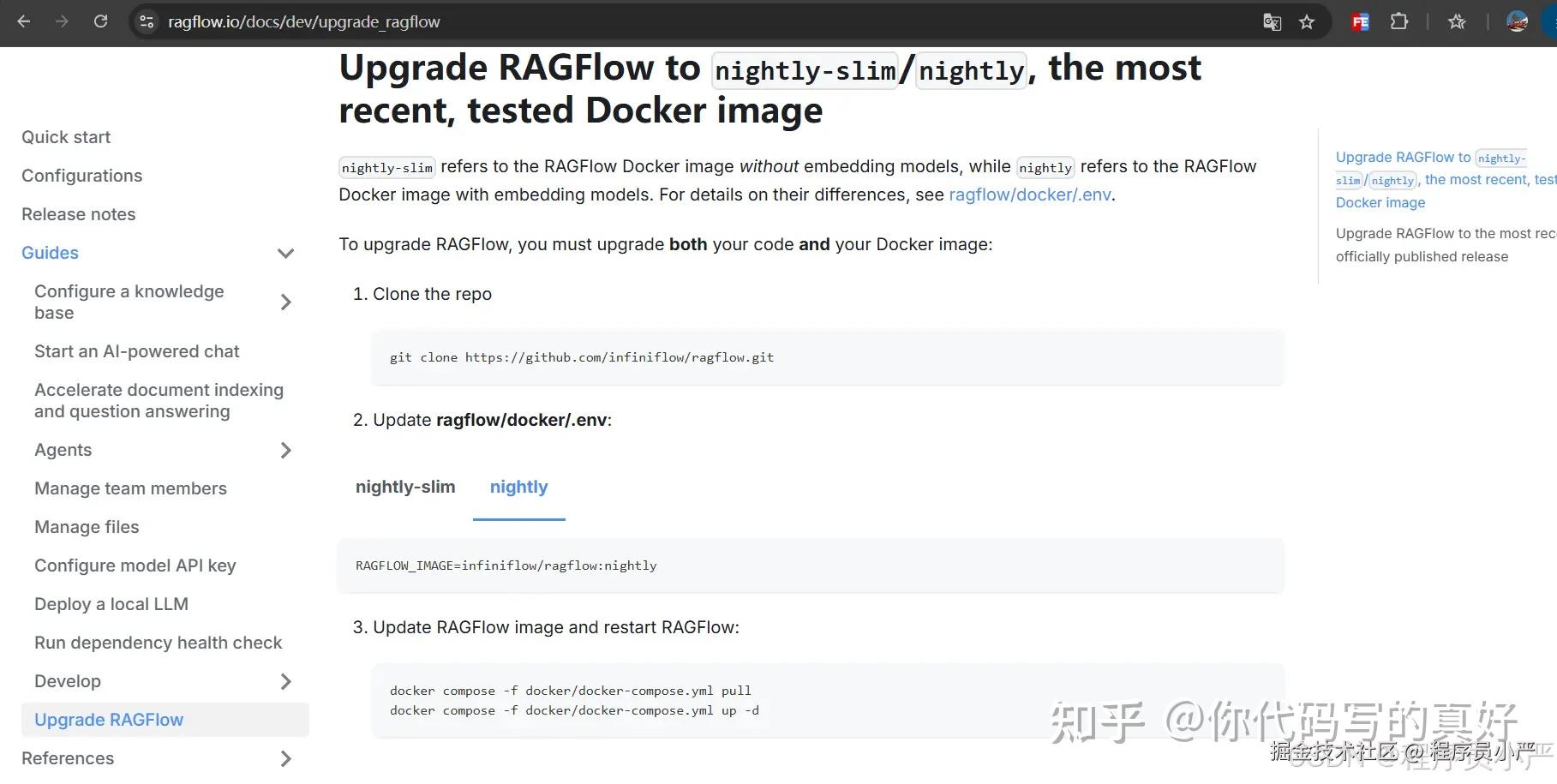
第一:修改/docker/.env文件,设置RAGFLOW_IMAGE=infiniflow/ragflow:nightly
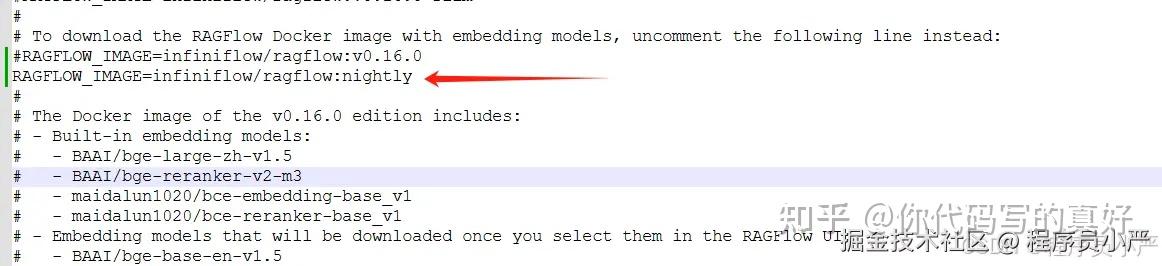
第二:重新更新RagFlow镜像
# 停止所有容器运行,并且删除挂载卷 docker compose -f docker-compose.yml down -v # 重新拉去RagFlow相关镜像 docker compose -f docker-compose.yml pull # 运行 docker compose -f docker-compose.yml up -d感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
大模型:yyds!全网独一份的AI大模型学习教程资源!!为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/220139.html