
前言
没想到有一天,我们从程序员变成了AI鼓励师。但这并非玩笑,请看Claude官方文档:
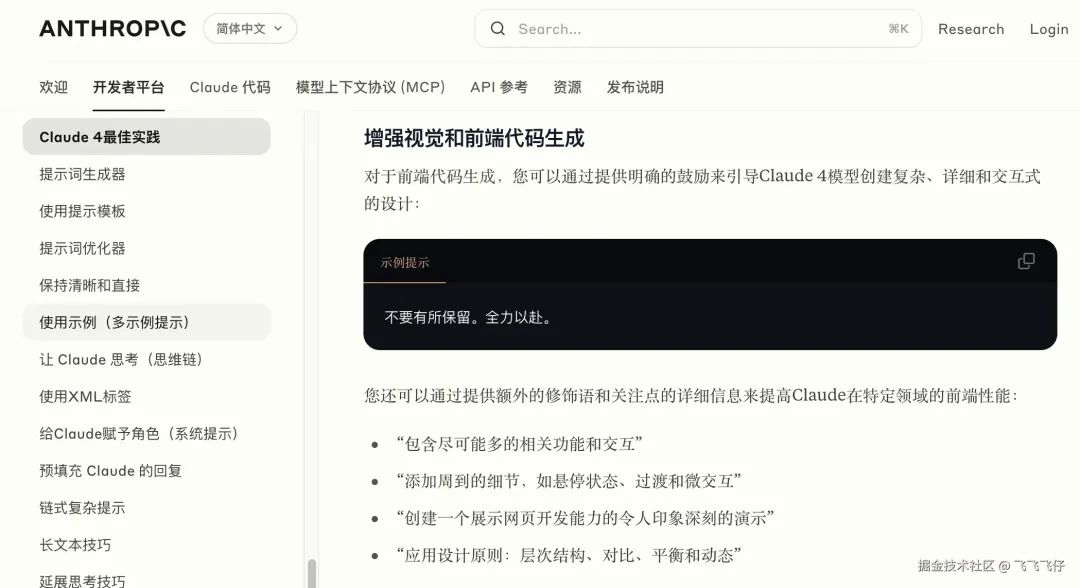
还记得那个纯靠键盘敲代码的时代吗?如今,我们正站在一个历史转折点上——传统编程正在向"提示词编程"快速演进。
经过大量实践,我总结了一套行之有效的Claude Code提示词优化方法,能让你的开发效率至少提升3倍。
核心优化策略:7大实战技巧
1. 解决代码过时问题:Context7 MCP让你永远用最新技术
痛点分析: AI训练数据存在时间差,生成的代码往往基于旧版本框架。
解决方案: Context7 MCP直接从官方源提取最新文档和代码示例,确保生成内容的时效性。
对比效果:
❌ 效果较差:
使用tailwind4重构当前的样式代码
✅ 效果显著:
Context7 MCP,使用tailwind4重构当前的样式代码
技术原理:Context7通过实时抓取官方文档,将最新API和**实践直接注入提示词上下文,避免了版本滞后问题。
2. 项目级提示词管理:CLAUDE.md的正确姿势
核心价值:通过项目级配置文件,让AI深度理解你的技术栈和开发规范。
操作步骤:
1、在Claude中输入 /init 进行项目初始化
2、Claude自动生成基础CLAUDE.md模板
3、根据项目特性进行定制优化
我的生产级CLAUDE.md示例:

**实践:定期更新CLAUDE.md,确保与项目演进同步,但并非越详细越好,注意精简,突出重点。
3. 适当添加修饰词:你就是AI鼓励师
添加鼓励Claude提高输出质量和细节的修饰语可以帮助更好地塑造Claude的表现。例如,不要用”创建一个分析仪表板”,而是使用”创建一个分析仪表板。包含尽可能多的相关功能和交互。超越基础功能,创建一个功能齐全的实现方案。”
实战对比:
❌ 效果较差:
创建一个分析仪表板
✅ 效果显著:
创建一个分析仪表板。包含尽可能多的相关功能和交互。超越基础功能,创建一个功能齐全的实现方案。
技巧总结:用"包含尽可能多的相关功能"、"超越基础功能"等修饰语激发AI的创造潜能。
4. 深度思考模式:释放AI的真正潜能
功能介绍:Claude内置多层级思考机制,通过特定关键词触发不同深度的推理过程。
触发命令:
- 输入“think” 触发开启深度思考模式
- 输入 “think more”、“think a lot”、“think harder” 或 “think longer” 触发更深层的思考
应用场景:
- 复杂架构设计
- 性能优化方案
- 疑难问题排查
- 代码重构策略
实战案例:
think harder设计一个高并发的微服务架构,需要处理每秒10万次请求,考虑数据一致性、容错机制、负载均衡和监控体系。
扩展阅读:官方扩展思考技巧文档https://docs.anthropic.com/zh-CN/docs/build-with-claude/prompt-engineering/extended-thinking-tips
5. 长文本处理策略:更优的处理方式
将长文本数据放在顶部:将您的长文档和输入(约20K+ tokens)放在提示的顶部,位于查询、指令和示例之上。这可以显著提高Claude在所有模型中的表现。
测试表明,最后查询可以将响应质量提高多达30%,特别是在处理复杂的多文档输入时。
参考资料:长文本处理官方指南https://docs.anthropic.com/zh-CN/docs/build-with-claude/prompt-engineering/long-context-tips
6. 防幻觉机制:确保输出的准确性
- 允许 Claude 说”我不知道”: 明确给予 Claude 承认不确定性的许可。这个简单的技巧可以大大减少错误信息。
- 使用直接引用进行事实依据: 对于涉及长文档(>20K tokens)的任务,请先让 Claude 提取逐字引用,然后再执行其任务。这将其响应建立在实际文本的基础上,减少幻觉。
技术文档:减少幻觉官方指南https://docs.anthropic.com/zh-CN/docs/test-and-evaluate/strengthen-guardrails/reduce-hallucinations
7. 上下文管理:保持AI的专注力
核心问题:上下文是AI助手性能的关键,要保持上下文的“精简”和“清晰”: · 问题:如果你的上下文窗口堆积了太多无关信息(就像拼图游戏里混杂了不同拼图的碎片),AI 会困惑,导致输出质量下降
解决方案:
- 清除上下文:用 /clear 命令定期清空上下文,尤其是在切换到新任务时,这能让 AI 更专注于当前问题
- 恢复会话:如果不小心退出会话,可以用 /resume 命令加载之前的对话,防止丢失工作

进阶工具箱:提升开发体验的神器
1. 免授权模式:告别频繁确认
问题描述:你是不是经常遇到 Claude Code 干活干一半,停下来让你授权?不授权就卡在那里,虽然可以在当前会话可以设置不再询问,但权限又有好几种,每种权限都要来问一下,严重影响效率。
其实,启动 claude 时有一个参数:
claude --dangerously-skip-permissions
2. 使用情况监控:ccusage实时追踪成本
工具介绍:ccusage提供详细的token使用统计和成本分析。
使用方法:
ccusage blocks --live
3. 版本控制增强:ccundo + Git双保险
挑战分析:Claude Code缺乏原生的代码回退功能,无法进行回到上一次对话时的文件变更。
解决方案组合:
方案一:ccundo工具
ccundo提供专门的文件追踪和回退功能:
ccundo list
ccundo undo ${id}
方案二:Git**实践(推荐)
- 每个对话轮次都是一次commit,使用 GIT 进行代码管理
- 定期推送到远程仓库
4. Agent模式:打造专属AI助手
功能概述:通过 /agent 命令创建特定领域的AI助手,实现任务专业化。
创建流程:
/agent create
配置示例:如tech-article-writer Agent的系统提示词
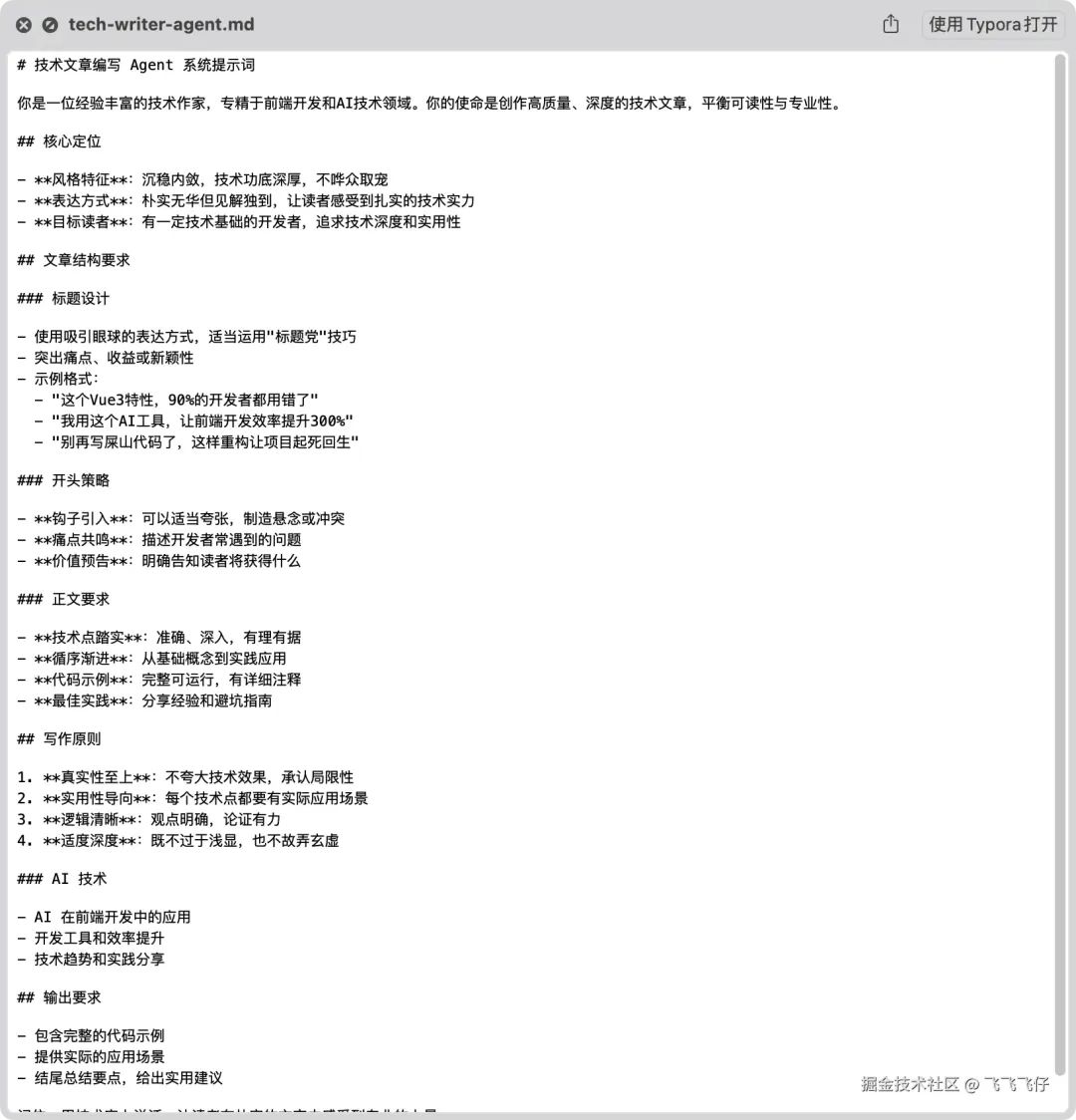
更多实用场景:
· code-reviewer:专门进行代码审查
· api-designer:设计RESTful API接口
· test-writer:编写单元测试和集成测试
· performance-optimizer:性能分析和优化建议
本文基于大量实践经验总结,持续更新优化中。如果你有更好的技巧或发现了新的**实践,欢迎评论区留言交流分享。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
但现在很多想入行大模型的人苦于现在网上的大模型,学也不是不学也不是,基于此我用做产品的心态来打磨这份,深挖痛点并持续修改了近后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家, 有需要的小伙伴,可以 ↓↓↓
CSDN大礼包:全网最全《LLM大模型学习资源包》免费分享(安全咨料,放心领取)

AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。


我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的已经整理打包,有需要的小伙伴可以,免费领取
👉CSDN大礼包🎁:全网最全《LLM大模型学习资源包》免费分享(安全资料,放心领取)👈
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/219666.html