
马斯克旗下xAI发布Grok 3聊天机器人 数学推理性能超GPT4o
马斯克旗下人工智能公司xAI发布Grok 3聊天机器人。据xAI工程师介绍,Grok 3所涉及的训练是Grok 2的10倍。马斯克称,在数学推理、科学逻辑推理和代码写作等能力表现方面,Grok-3在多项benchmark测试中均取得了比DeepSeek-v3、GPT-4o、Gemini-2 pro更优的效果。
xAI推出名为Deepsearch的Grok-3智能搜索引擎
xAI推出名为Deepsearch的Grok-3智能搜索引擎。据xAI工程师介绍,Deepsearch是xAI的第一代广泛代理工具,它不仅帮助工程师、研究人员和科学家编写代码,而且实际上能帮助每个人回答日常遇到的问题。
舍掉工作看完全程,多图预警

关键因素:背景是我们的信念是了解宇宙,其次这张图片上出现两个华人。
接下来就是,各种跑分屠榜操作。
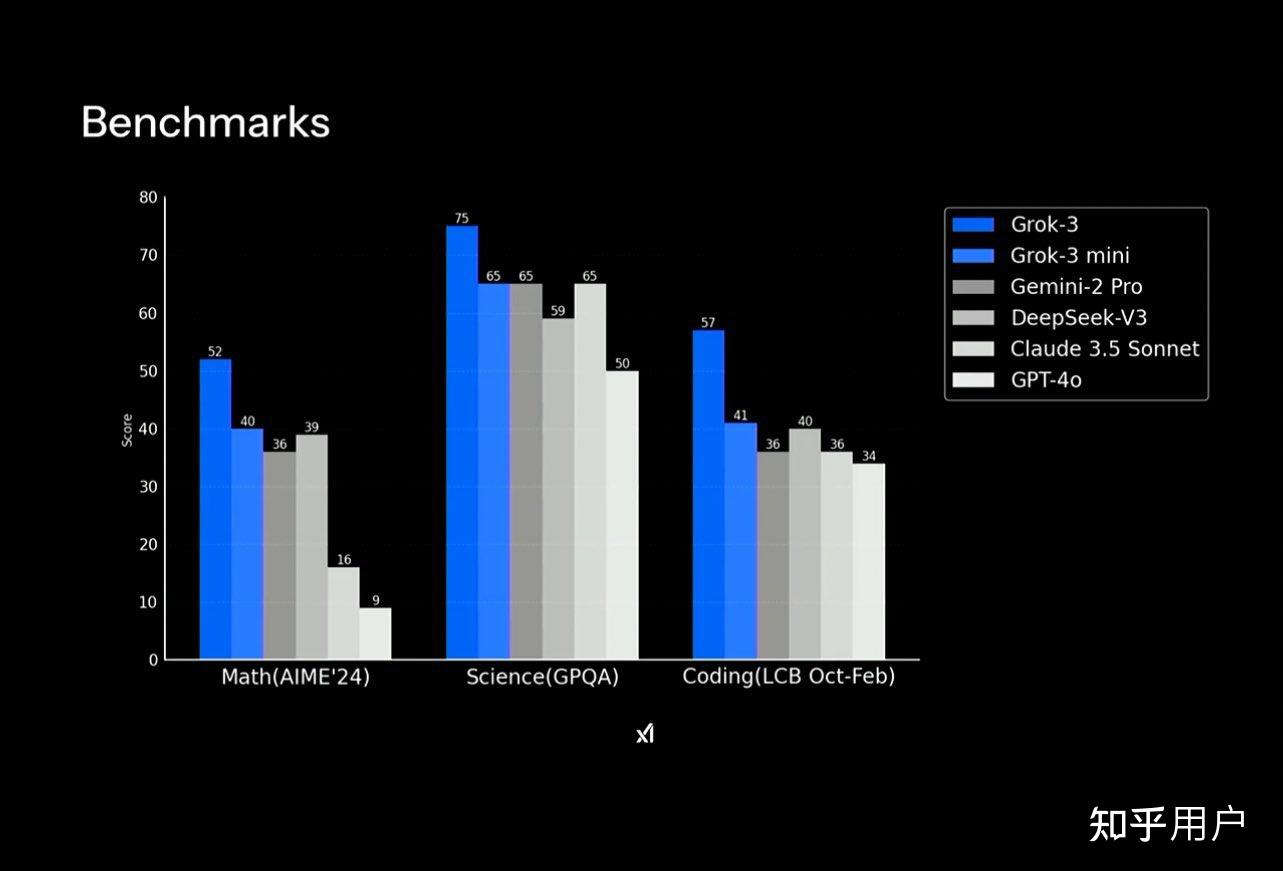
在Benchmarks测试中Grok全面领先,GPT一直垫底……前几天,马斯克和奥特曼吵架扬言要收购OpenAI ,然后被奥特曼怼回去,是不是报复也不好说。
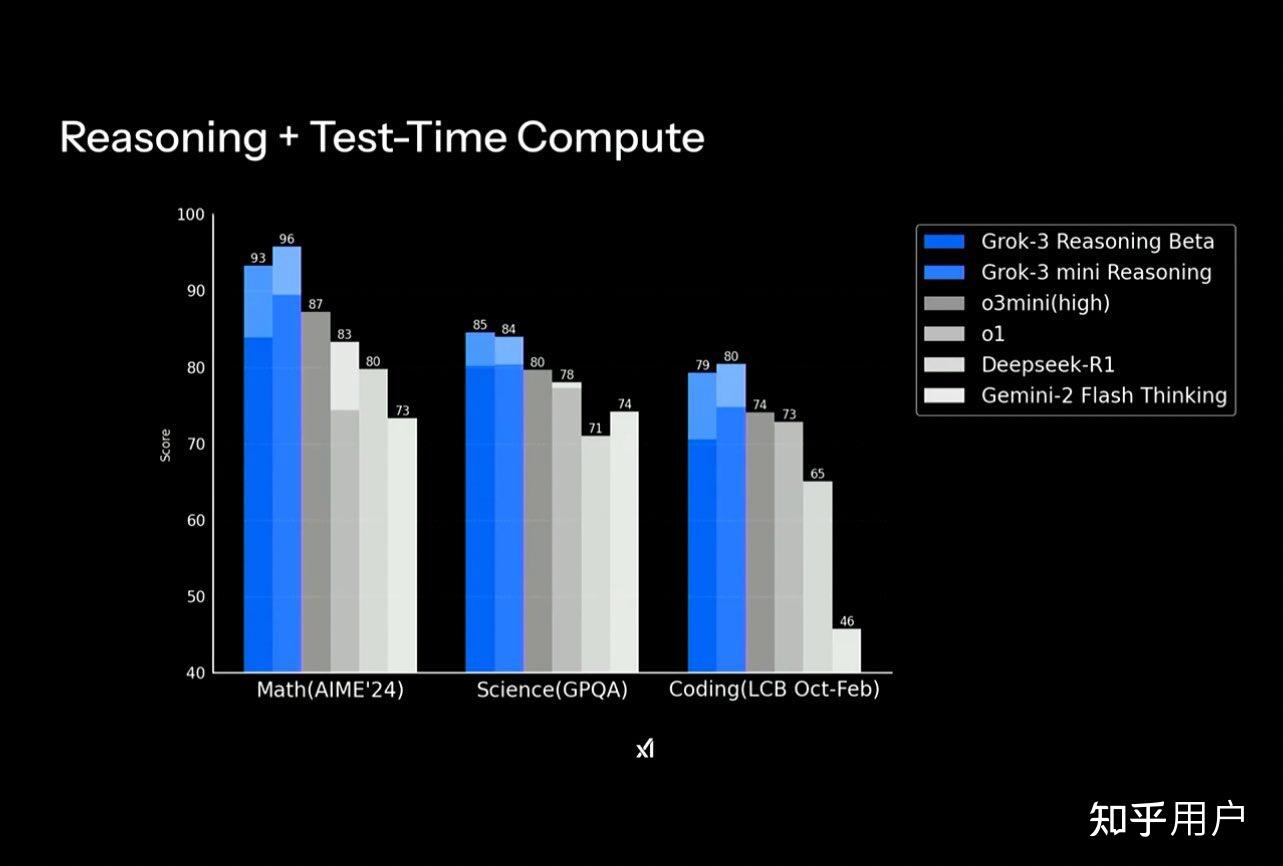
我也看不懂,没关系,能看懂数字就好。
xAI同时也在做推理模型和test time scale,能力同样全面屠榜。注意到Grok 3 mini部分能力甚至反超Grok 3。
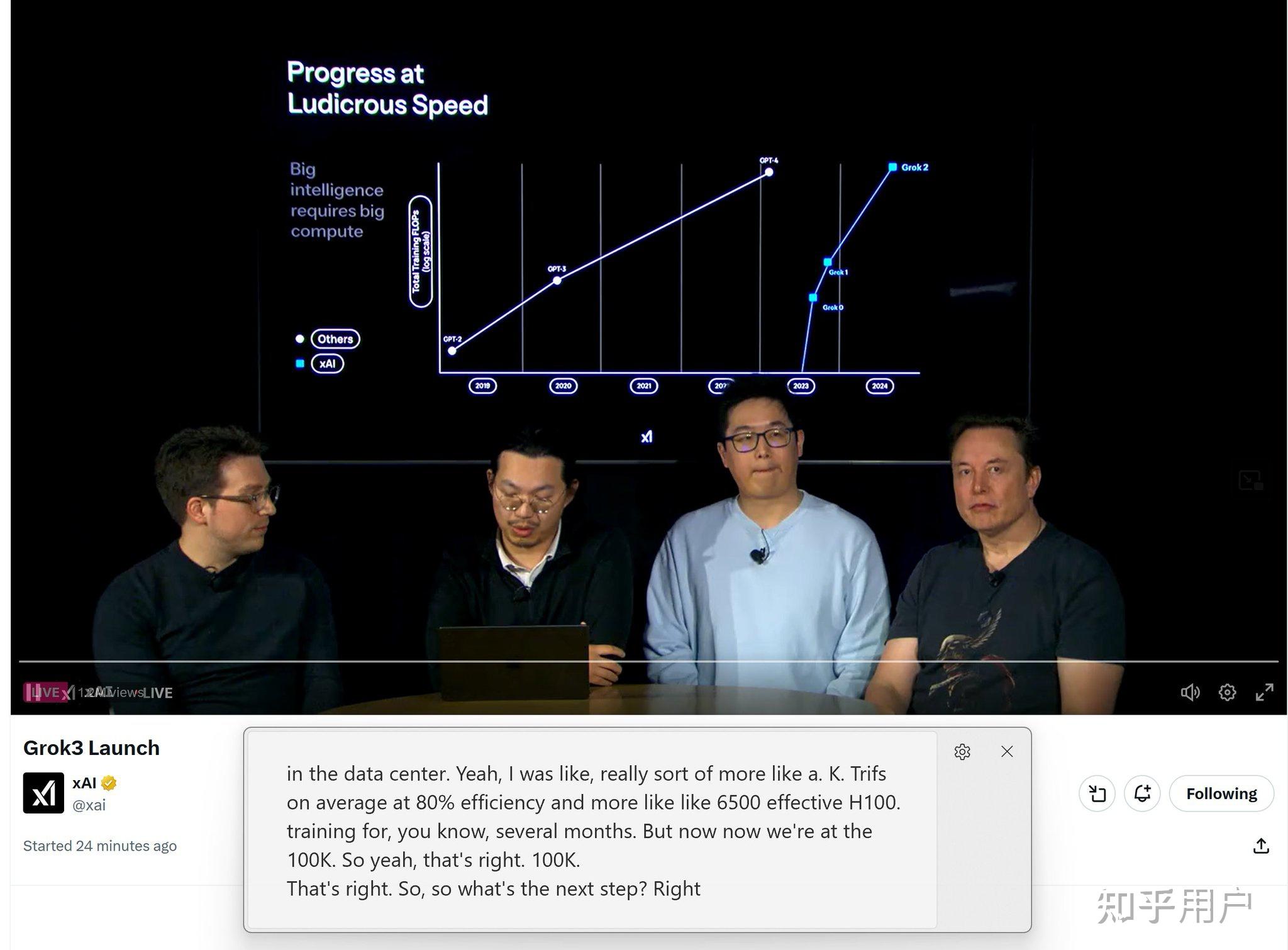
中间马斯克披露实际上Grok 2训练受制于稳定性、效率,只用到了6500个有效的H100。这一次10万卡集群,有效卡在65K-80K左右。现在他开始用数据来推翻市场一个结论:训练无效论。
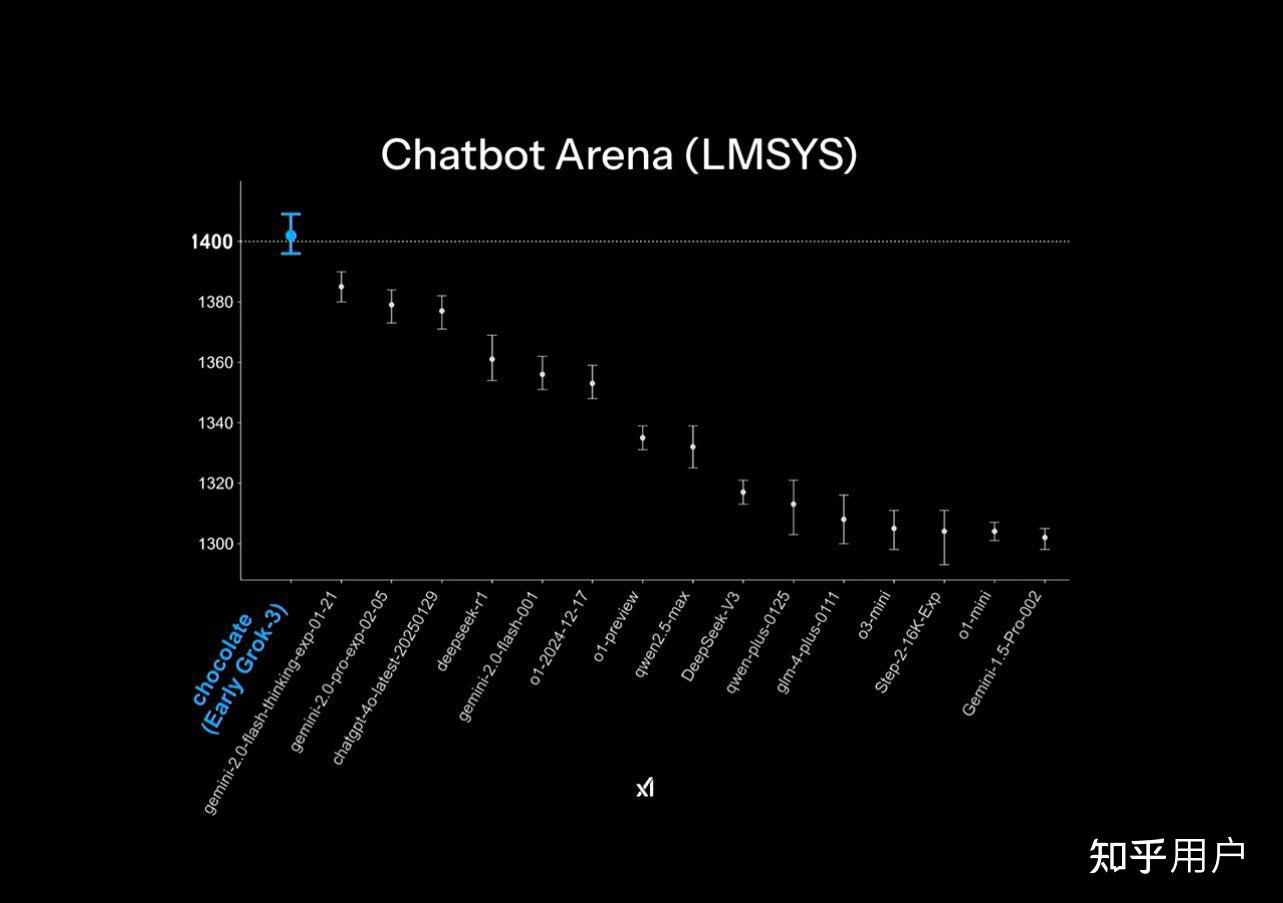
跑分全面领先、用户盲测1400分全球**。而且是断层领先。这是不是表明,重点研究方向从算力从芯片——算法——芯片,又回归到芯片?
当然,马斯克天生的营销大师,真正情况如何还是要上手用一下,毕竟很多时候,跑分没输过销量没赢过的例子见怪不怪了。
最后,grok3还是支持deep search功能,xAI 将其描述为一种类似智能体能力的早期版本,在数学、科学、编程基准测试中的表现超越了 OpenAI 的 GPT-4o、Claude 3.5、Deepseek V3 和 Gemini 2 Pro。

但是,对订阅用户开放,也就说,用全部功能,你得充会员。同时呢,还专门推出了SuperGrok的订阅套餐。
个人总结下来,就两点:1.我跑分领先市场所有模型,是因为大力出奇迹。芯片还是重要的。2.欢迎付费来用吧。
对了结尾还有个彩蛋,GROK3的语音模式声音,好像是个男人的声音。这也是个梗。
媒体风向变化太快,让人目不暇接。早上还在夸Deepseek成本低,性价比高,预训练Scaling Law死了,不需要太多机器和GPU卡,性价比优先,英伟达休矣;中午Grok 3一出来,说是用了10万张英伟达H100卡,效果力压OpenAI o3 mini和Deepseek R1,就转向说Scaling law还成立,还需要大量的卡,英伟达股价有救了,还是要大力出奇迹……
这两个观点明显对立,有一真必有一假,那事实的真相到底是啥呢?我们来推一推。
-预训练阶段的Scaling Law成立吗?当然是成立的,所谓“Scaling Law撞墙”,大家普遍遇到的问题是数据不够了,没有大量新数据,导致预训练阶段的Scaling Law走势趋缓,注意是趋缓但不是停顿,预训练阶段的Scaling Law并没到天花板。按照Chinchilla Scaling Law推断,即使没有新数据,也并不意味着模型效果提不上去了,很简单,只要增加基座模型尺寸,效果仍然会提高,只是从付出的算力和获得的效果提升来说很不合算,性价比过低,这是为何大家转到RL Scaling Law和Test Time Scaling Law的原因,是因为付出同样的算力,在后面两个阶段大模型智商提升更明显,就是性价比高。
-目前可以提高模型效果的Scaling方法,按照性价比由高到低排序的话: Test time Scaling Law> RL Scaling Law>预训练阶段Scaling Law(数据不够了,只能推大模型尺寸),有性价比高的Scaling,当然优先做这种,性价比低的Scaling,只有在没有性价比更高的情况下才会采用。这跟购物一个道理,有性价比高的当然不会去买性价比低的商品。
-如果哪天RL Scaling Law和Test Time Scaling Law到了天花板,又没有找到新的性价比更合算的Scaling law,也不是说模型效果就提不上去了,大家仍然可以回归预训练阶段的Scaling Law,没有新数据也没关系,推大模型尺寸规模就可以,效果仍然会上升。但这基本是最后的选择,没办法的办法,只要有性价比高的方法就不会走这条路。
-有人问了:那按照你的意思,囤那么多GPU算力,其实对训最好的模型也没啥用?要是按照上面的理论,那确实是没有太大必要,比如Deepseek 2000卡也可以作出最好的模型不是。但是卡多有个好处,就是能压缩实验新想法和训练大模型基座的时间周期。比如你总得探索一些不同的算法、参数或数据配比的模型进行各种实验,你有10个新想法,如果只有2000张卡,可能得跑5天才能得出结论,要是有几万张卡,可能1天就能得出结论,所以卡多对于探索效率是有极大帮助的。卡多创新多,这点肯定成立。
-为何Grok 3作为通用基座模型,它的评测指标只有数学、科学和代码数据集?没有通用能力比如最常用的MMLU指标的对比,这是不太规范的对比模式。推断可能Grok 3的通用能力相对OpenAI和Deepseek的模型没有大幅提升,所以不拿出来比?
-如果想要提升基座模型的数学、科学和代码能力,无论从方法还是从成本角度来讲,难度并不大,目前比较标准的做法是类似Deepseek V3从Deepseek R1蒸馏数学、代码等逻辑题的长COT数据,即深度思考过程数据,就是说把深度思考长COT数据引入基座的Post-Training阶段、甚至前置到预训练阶段(所谓大模型“左脚(Deepseek基座)踩右脚(Deepseek R1)自我飞升”的模式),这样就能大幅提升基座模型在数学和代码方面相关的能力,也就是Grok3宣传具备的“有思维链推理和自我纠错机制”,评测指标看着会比较好看,而且蒸馏的数据总量也不会太大(几百B级别应该够了),成本很低,对算力要求不高。
-OpenAI 很快会发布的非逻辑推理模型GPT 4.5,大概也应是类似的思路,从o3模型蒸馏COT数据,用深度思考数据来提升GPT 4.5基座模型的智商,大模型“左脚踩右脚自我飞升”大法,这会是之后基座模型提升能力的主要手段。
-Grok 3的算力消耗是Grok 2的10倍,如果遵照Chinchilla Scaling Law,**做法是Grok 3的训练数据量比Grok 2增加3倍,模型大小同时比Grok 2增加3倍(但是目前的趋势是减小模型大小,增大数据量[就是说“小模型大数据”的模式],尽管这样不满足训练最优原则,但因为模型尺寸小了,所以这种模型更适合在线推理服务,降低服务成本)。
-如果像发布会宣称的,Grok 3耗费算力是Grok 2的10倍消息为真的话,那有两种可能。一种是数据量增长极大,这样只能是增加了大量多模态数据,比如数据量从10T增长到30T(目前文本模型使用的数据量,最多到18T到20T之间,基本到顶,再多没有了,要大幅增加只能加多模态数据,但是增加多模态数据对提升大模型智商帮助不大,所以这个增量按理说不应该太大),如果这样推算,Grok3的模型规模增长3倍左右;第二种可能是训练数据量比20T增加的不多,如果这样可以推出Grok3模型尺寸比Grok 2要大很多,至少4到5倍起步(若新增数据不多,那只能靠增加模型尺寸来消耗新增算力)。不论是哪种可能,Grok 3的模型大小肯定比Grok 2大了很多,而Grok 2模型本身可能就不小(Grok 2发布网页评测效果超过Llama 3.1 405B,所以无论数据还是模型大小,都不会太小,要是Dense模型, 70B是最小的估计了),所以Grok 3的尺寸规模很可能不是一般的大(感觉在200B到500B之间)。
-很明显,Grok 3仍然在采取推大基座模型尺寸的“传统”做法,也就是上面“Scaling Law”部分分析的预训练阶段增大模型尺寸的方法来提升基座模型能力,上面分析过,这种做法是性价比很低的。比较时髦的做法是把训练重心放在RL Scaling方面,性价比会高太多。但是为啥他要做这种赔本买卖呢?在后面会给出一个可能的解释。
-Grok 3的深度思考版本,不说体验,单从评测指标看,达到或者超过了o3 mini,确实是目前效果最好的,或者说最好的之一没有什么问题。
-说回上面提到的问题,为啥明知靠推大预训练阶段模型尺寸规模性价比低,Grok 3还要用这种模式呢?很可能内在的原因在于(推断无证据):Post-Training阶段采取RL Scaling,其效果可能跟基座模型的大小是有正相关关系的,就是说,同样的RL阶段的算力消耗,如果基座模型尺寸更大,则RL 阶段的Scaling效果越好。只有这样,才有在预训练阶段尽量把模型规模推大的必要性。而我们可以假设,Grok 3之所以采取这种过于耗费算力,看着性价比不高的方式,是希望通过加大基座,把深度思考版本的能力明显提起来。
-貌似Deepseek R1效果很好又开源,获得一片好评,但大家想要实际用起来,会发现基座太大,部署难度和消耗资源太高,对下游应用不太友好。那为啥Deepseek非得推这种对下游应用来说明显过大的模型呢?(小点的蒸馏模型看着指标很好,但是实际应用效果貌似差不少),是否也是因为基座模型如果不够大,深度思考模型效果就没那么好的原因?
-如果上述假设成立,那意味着:三个Scaling Law(Pre-train、RL 、Test Time),从提高大模型智商的性价比来说,由高到低是:Test Time > RL > Pre-Train,这个是之前的结论。但如果上述假设成立,说明Test Time Scaling的天花板最低,它的天花板依赖于RL阶段的Scaling能力,而RL阶段Scaling天花板次低,它的天花板依赖于预训练阶段Pre-Train的Scaling?如果这样,如果有一天当RL和Test Time天花板到顶,意味着我们可以再启动一轮,去推大基座模型的模型尺寸,RL阶段Scaling 的天花板随之升高,然后可以再去Scale RL和Test Time,就进一步得到智商更高的大模型。如果这成立,那意味着AGI的解决方案已经完整了?其实不需要新的Scaling Law存在就够?
-上述推论,是在一个前提成立的条件下的推出来的,这个前提是:Grok 3耗费这么大算力推大模型规模,这是个深思熟虑或小规模实验的结果,而不是仅仅受到之前老观念(预训练阶段算力越高效果越好)影响下的决策。如果这个前提不成立,则上述推论不成立。总之,一切责任在马斯克,Over。
Grok-3(Beta)、Grok-3 mini
首个推理模型Grok-3 Reasoning(Beta)、Grok-3 mini Reasoning:击败o3-mini/DeepSeek-R1,解锁推理时计算
首个AI智能体「DeepSearch」:联网深入搜索

一股OpenAI发布会的味道扑面而来
据介绍,三代Grok的训练计算量竟是Grok-2的10倍,那么实际表现又如何?


世界最大超算集群Colossus已有20万块GPU:10万块GPU同步训练(第一阶段用时122天搭建);20万GPU(第二阶段用时92天)
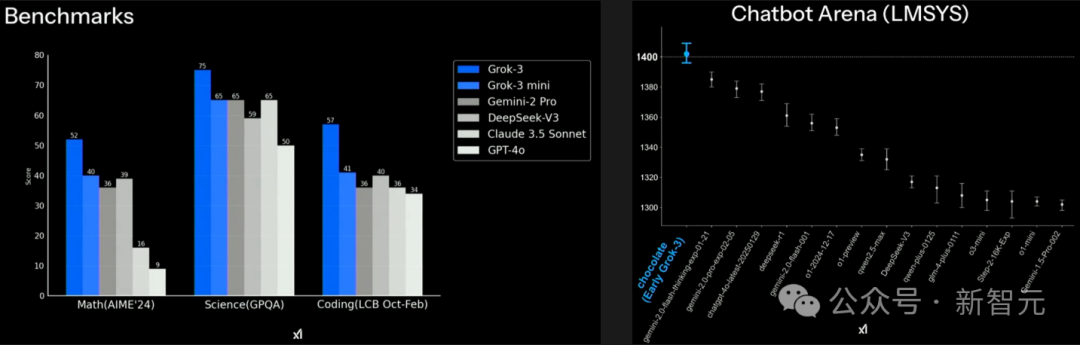
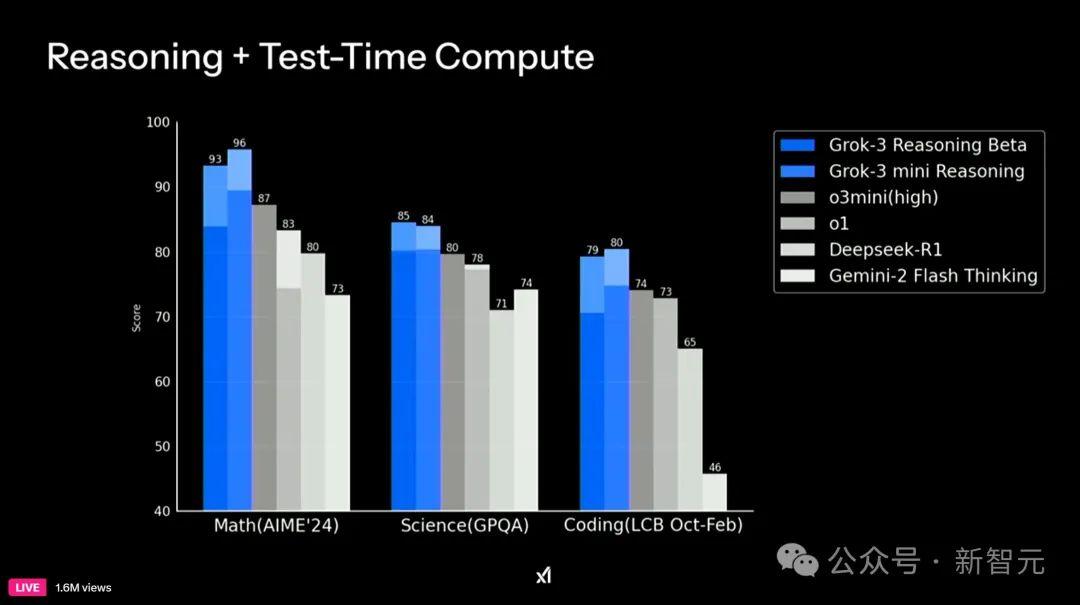
在多项基准测试中,Grok-3在数学(AIME 2024)、科学问答(GPQA)、编码(LCB)上刷新SOTA,大幅超越DeepSeek-V3、Gemini-2 Pro、GPT-4o。
Grok-3 mini的性能基本上领先或媲美其他闭源/开源模型。
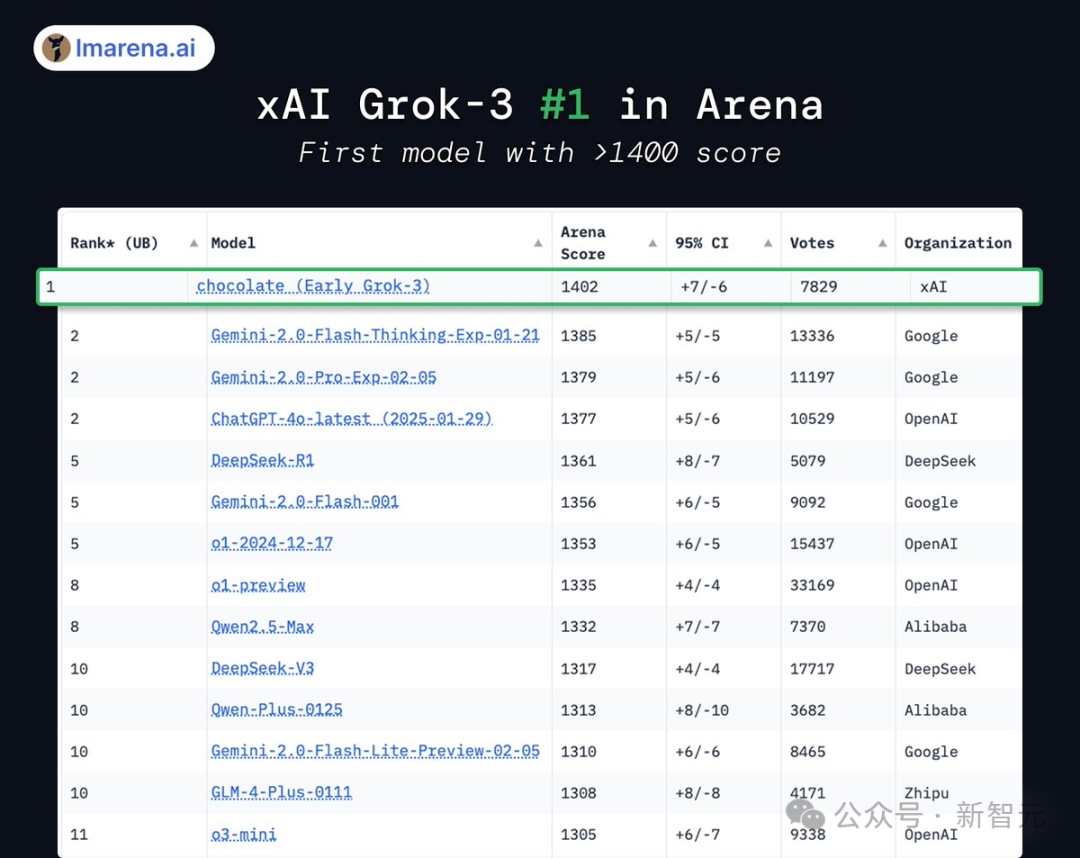
在著名大模型LMSYS Arena排行榜中,Grok-3(chocolate终于揭秘)刷榜,Elo评分超1400位列最高,没有任何一个模型能与之相比。
Grok-3的数学能力十分惊人,几乎能完成大部分美国数学专业能力测试的题目。
更令人惊喜的是,Grok-3此次还带来了推理模型——Grok-3 Reasoning,在回答问题时会展示出思维过程。
进入聊天入口,直接选择「Think」模式,即可开启魔法。
此外,还有「Big Brain」模式、智能体「深度搜索」(Deep Search)模式同步上线。

几天前,马斯克曾在预告中放出豪言,「这是地球上最聪明的AI」,此言不虚。
总爱搞点事情的奥特曼,一会儿说GPT-4.5让自己深刻感受到AGI,一会儿又要开源模型全网投票。
甚至有网友提议,不如咱就7:30pm发布GPT-4.5吧!奥特曼:这不太好吧。
奥特曼的这番言论,摆明了是要扰乱军心。据传言,Grok-3发布这一历史性时刻,OpenAI全员观战。

OpenAI前脚发布的o3-mini刚刚击败了R1,如今又被Grok-3追回。不知今晚,GPT-4.5会不会降临?
暴击o3-mini、DeepSeek-R1,解锁测试时计算
有人说,Grok-3是终极的Scaling Law测试,如今看来,事实如此。

从2023年Grok-1首次面世,到Grok-1.5,再到Grok-2逐步迭代,模型推理性能飞速飙升的同时,还吞噬了大量的算力。
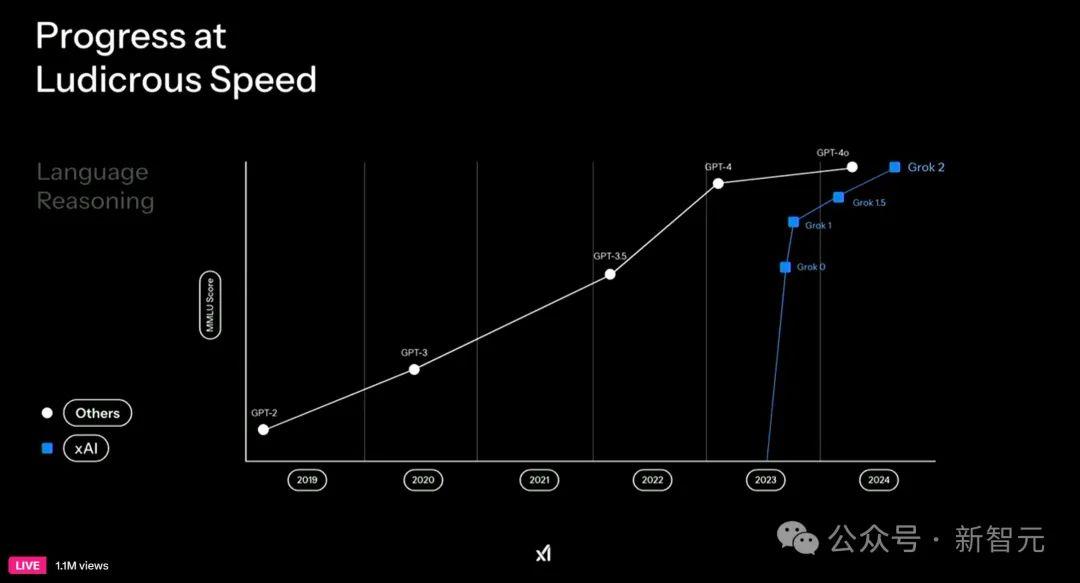
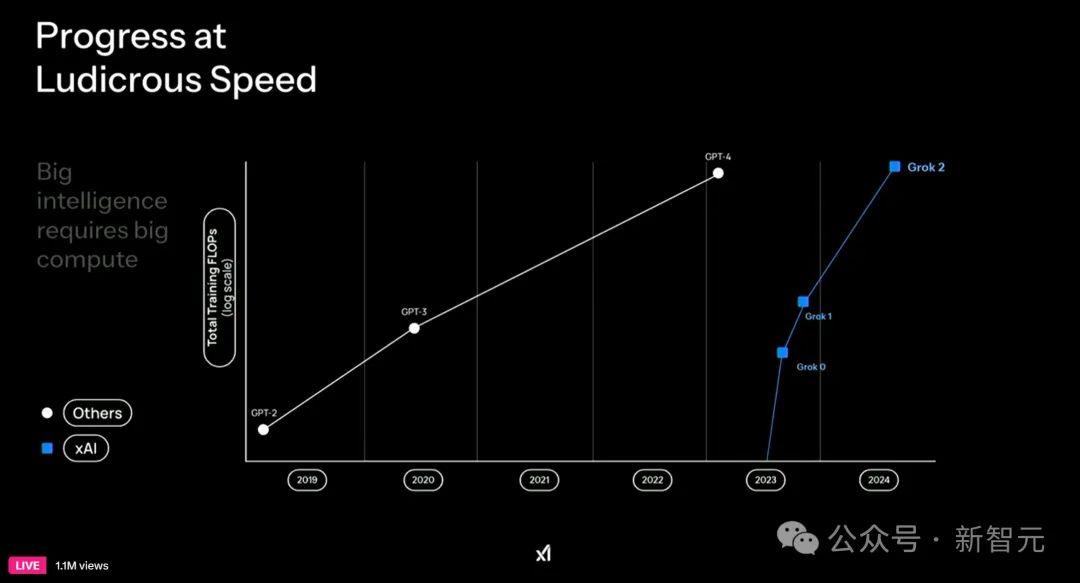
Grok-3家族,更是将「测试时计算」发挥到了极致。10万块H100超算,训出的野兽几乎无「模」能敌。
它成为首个Elo评分打破1400的模型,在所有分类测试中位列第一。
在多项基准测试中,推理模型Grok-3 Reasoning和Grok-3 mini Reasoning在数学、科学、编码上,性能均大幅超越o3-mini(high)、o1、DeepSeek-R1,还有Gemi-2 Flash Thinking。
可以说,迄今为止最强「推理模型」,全部败给了Grok-3 Reasoning,可以说,它是名副其实的「世界上最聪明的模型」。
团队表示,允许Grok去进行更长时间的思考和推理。
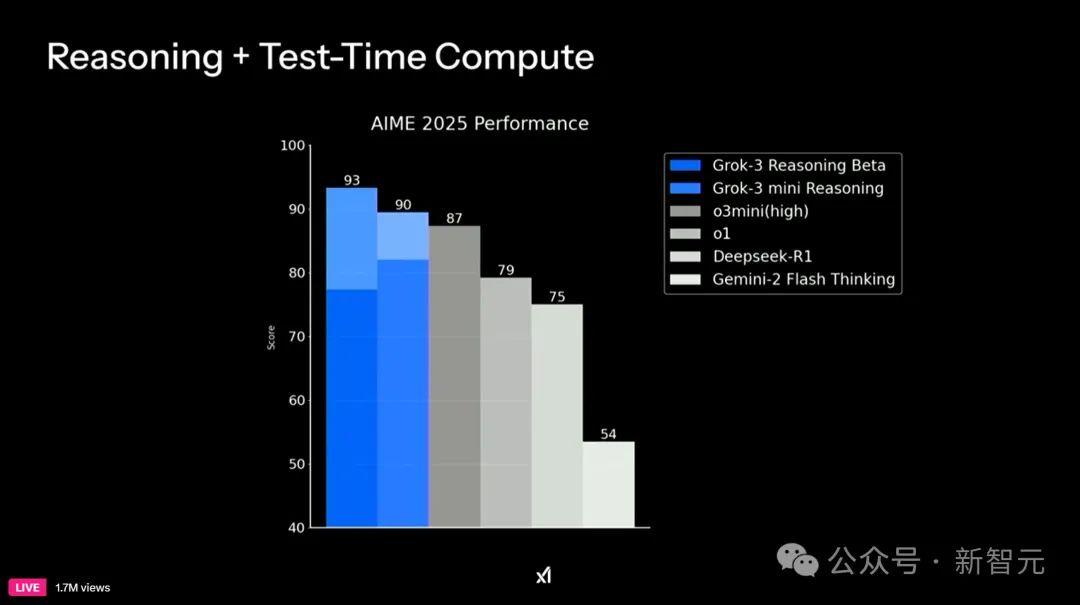
在最新的数学基准AIME 2025上,Grok-3两款新模型性能同样刷新SOTA,分别拿下了93和90分。
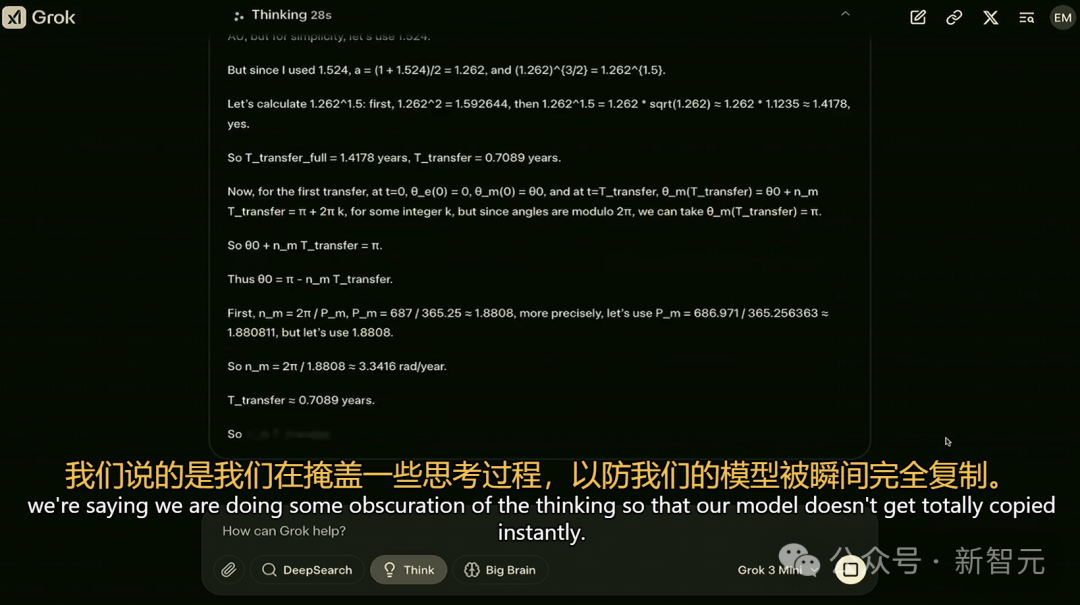
顺便提一句,Grok-3思维链和o3-mini套路一样——防止被偷家xAI掩盖了部分思考过程。
接下来,让我们一睹Grok-3强大的推理能力。
首先是一个太空飞船任务,生成一个地球发射、火星着陆以及下一次发射窗口返回地球的动画3D代码。
注意,这个问题的难点在于,过程中涉及到了大量数学和物理模型的计算。在此之前,团队从未试过让大模型去计算航天的发射窗口。
在「Think」模式下,可以看到Grok的思维痕迹,甚至可以进去看看Grok在解决问题时到底在想什么。
Grok 3很快生成了完整可运行的3D动画。在代码中,Grok-3数值上求解了开普勒定律。
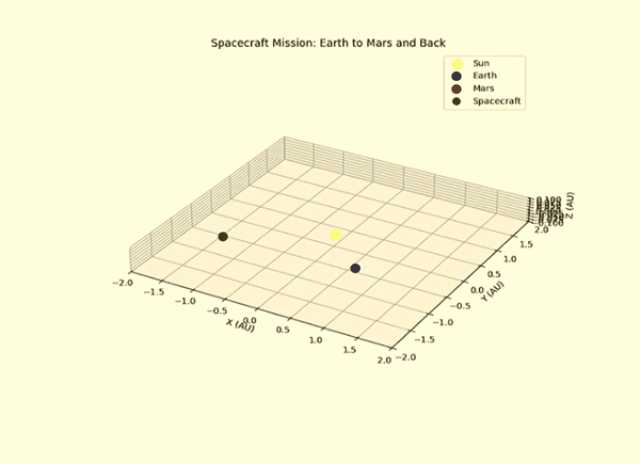
下图是3D动画的画面,直观展示了任务过程中,太阳、地球、火星和飞船之间的位置关系。
甚至,宇航员可以据此直接算出出舱时间和距离。这上面有地球-火星往返的转移路径,这种穿越每26个月发生一次。接下来,我们现在正处于一个过渡窗口期。
研究者经过检查后激动表示:Grok-3给的答案完全正确!
最后马斯克揭开谜底:其实,这就是SpaceX真正的探索轨道。他充满信心地表示,两年内,地球和火星就会被连接在一起。
很快有网友评论,「可以确认,Grok-3强得离谱!」
与之相对比的是,o1、o1-pro、o3-mini(high)全都在这个问题上栽了:生成一段代码,实现从地球发射、登陆火星,然后在下一个发射窗口返回地球的3D动画。
「它们生成的代码能跑是能跑,但很不幸,飞船根本就没靠近过火星,更别说回来了。」该网友表示。
然后团队又让Grok-3制作一个游戏。要求是结合俄罗斯方块和宝石迷阵两个游戏的混合体。
「显然,如果你让AI去创作一款像俄罗斯方块这样的游戏,互联网上有许多例子,或者类似宝石迷阵的游戏。它可以复制它们。」演示人员表示。
所以,现场他们让Grok-3制作了一个结合了俄罗斯方块和宝石迷阵两个游戏的混合体,这次他们使用了「Big Brain」模式,可以使用更多计算能力的一种模式。
Grok-3随后开始使用python编写代码,可以看出它调用了pygame、random和time这3个库来完成游戏的编写。
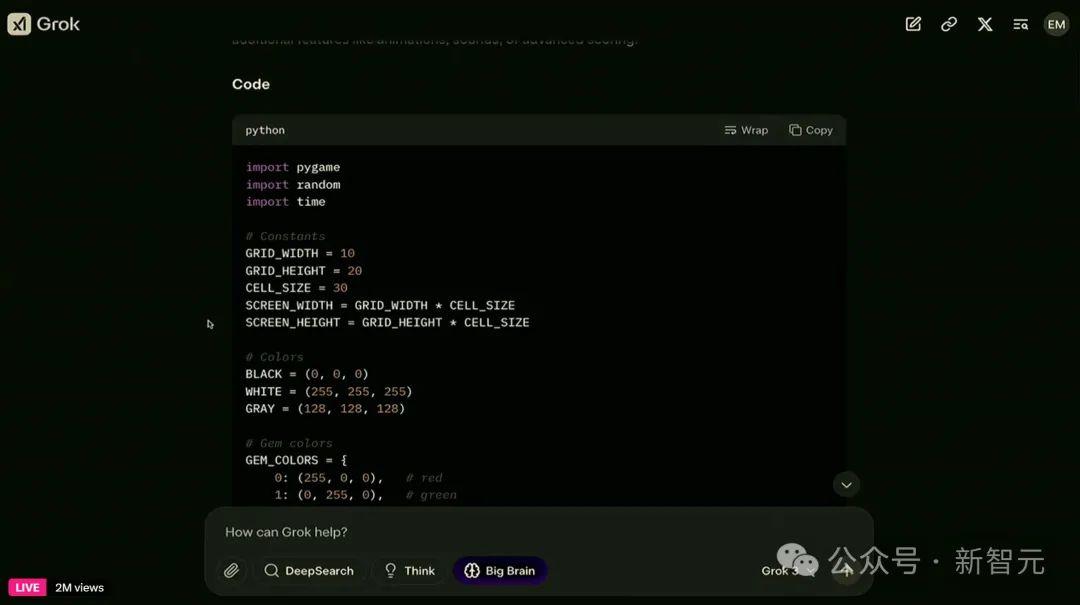
代码完成后,Grok-3生成的俄罗斯方块和宝石迷阵两个游戏的混合体成功运行,虽然游戏逻辑有些随意,但是界面挺美观。
「我们在x.ai准备好成立一个游戏工作室了吗?」演示人员激动地说道,「是的,所以我们正在x.ai启动一个人工智能游戏工作室。」
在此过程中,研究者们讨论道:最好的AI模型,必须像人类一样思考,会去想所有可能的对策和解法,会自我批评、回溯,还会从第一性原理去思考。
甚至,Grok能够了解自己的逻辑和推理过程中的一些失误所在,更正自己的错误,将一些数学推理过程概念化,而现实生活中,也正是这些问题的延伸。
研究者表示,真正令人兴奋的就是,可以用Grok-3去完成现实世界中的任务,比如打造一辆特斯拉,或者去发射火箭。
这正是Grok团队目前正在思考的问题。
没想到,这一次马斯克还带来了Grok-3首个智能体——DeepSearch。
DeepSearch是Grok的第一代智能体,能够在互联网上进行更深入的搜索。
它允许用户对互联网和X平台进行全面搜索。该模式分析大量信息,并通过快速高效的搜索过程提供详细、合理的答案。
此外,它的信息检索过程对用户更加透明。你可以直接告诉它只使用来自X的内容,它会尽量遵守这个要求,因此可控性更强,也更智能。
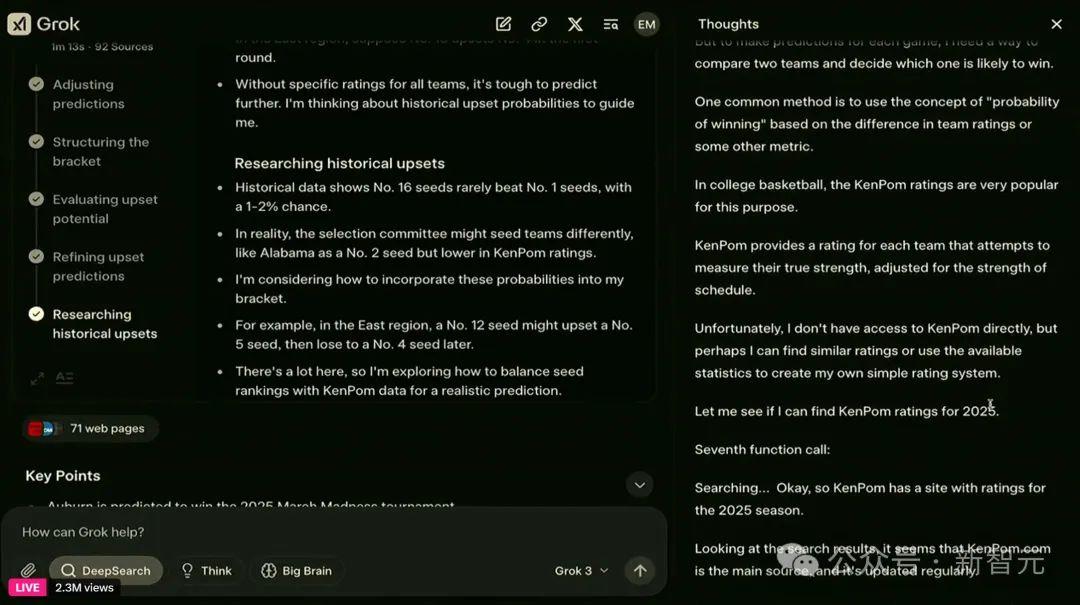
我们可以问DeepSearch智能体:下一次星舰发射是什么时候?
可以看到,在左边,它展示出了搜索和推理的过程,而在右边,则展示出了深度思考过程,以及模型正在浏览什么样的网址和网页。

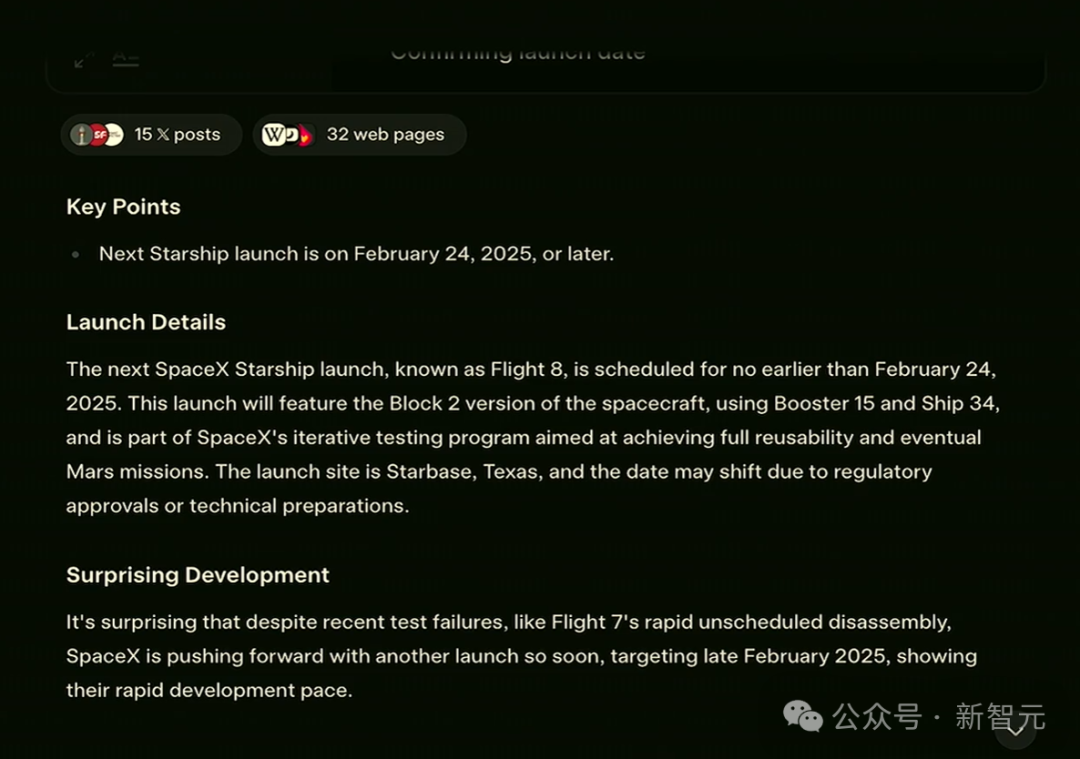
最终,智能体给出了答案:25年2月24日。
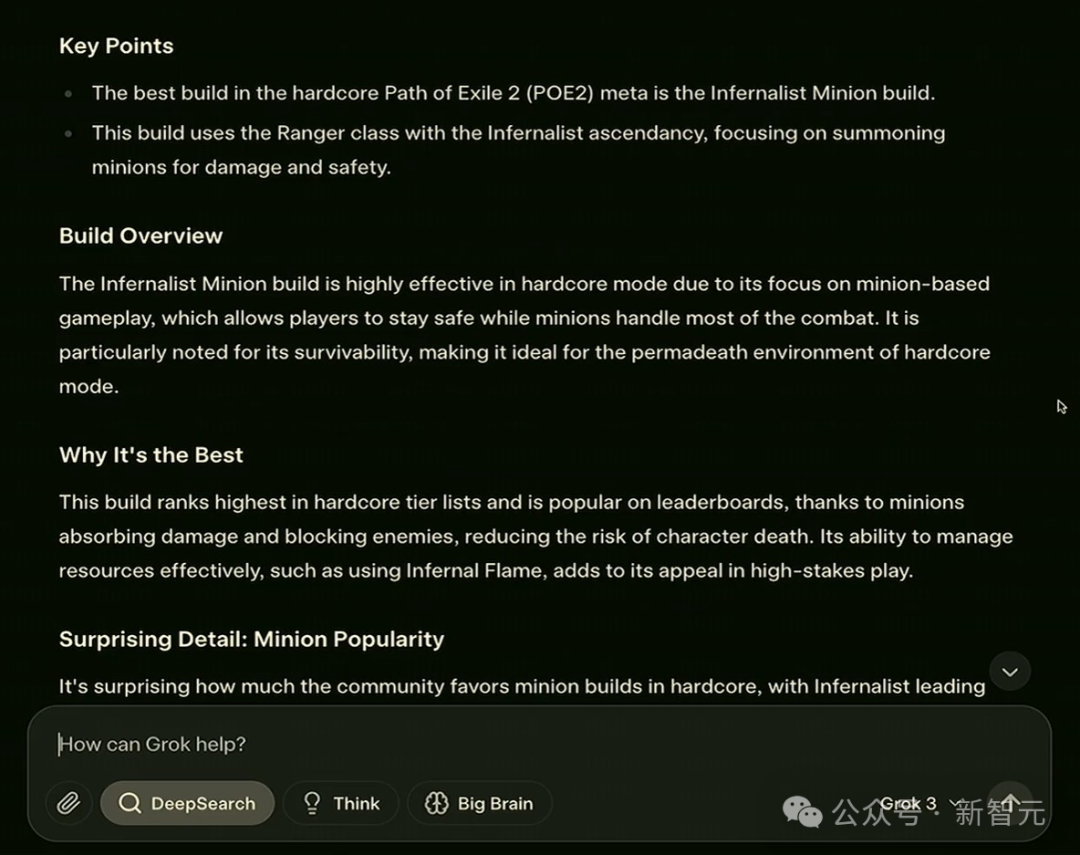
游戏玩家还可以提问:在Poe 2中最硬核的流派是什么?
除了给出答案——炼狱师召唤流之外,智能体还在回答中给出了如何获得更多武器的攻略。
因此,比起现在普通的搜索引擎,使用Grok智能体能节约更多的时间。
Grok团队表示,从此,或许所有实习生都要失业了,我们需要的只是向大模型下任务。每个月花40美元,就能带来数十亿美元的回报。
马斯克:一周内所有功能上线,几个月内全面开源
所以,Grok-3到底什么时候开放?
对此,马斯克表示,订阅Premium Plus的X用户现在已经可以用上了。
而Grok忠实粉丝则可以单独订阅SuperGrok,从而解锁深度搜索和思考模型等先进功能,并成为早体验新特性的那一波。
全新网址是http://grok.com,另外App Store里也可以下载了。
马斯克强调,最新版本一定是网页版,App Store里是比较落后的。
目前,Grok-3每天都在更新推理功能,马斯克放话说:一周内,Grok的所有功能都将上线!
传送门:https://grok.com/
什么时候出语音助手版?会花一周时间。
Grok-3 API什么时候上线?几周内。
Grok 3语音模式是原生的,还是文本转语音?它是Grok-3的一个变体,能理解你说的话,并且直接生成音频。
Grok-3能否将音频转录成文本?没问题。这个声音模型不仅仅是语音转文字那么简单,它还具备对话记忆功能,能记得和你之前的交互记录。
马斯克表示,几个月之后会对Grok-3进行全面的开源。
Grok-3最令人兴奋的部分是什么?训练模型,以及百分百的逻辑推理,都是最难的部分,就像你需要随时随地设计宇宙的最新进展。
如何设计这样一个史上最难推理模型?研究者表示,我们花了24个月去打磨这个模型,确定它在逻辑推理上有了最新进展,同时他们使用了一个废弃工厂,数据中心之所以落地在孟菲斯,是因为既需要算力,又需要能源功能,需要1/4吉瓦来向GPU供能,同时还需要冷却设施。
此前,从没有人真正在数据中心实现过液冷,但Grok团队做到了!
为了进一步对数据中心供能,我们使用了特斯拉的Megapacks,并且重新计算了建筑物的能源供给。最终证明:团队的计算是有效的!
而且,过程中还需要把不同计算机联结在一起,共享信息。在此过程中,团队会看到模型之间供给不平衡的情况。
一方面,是对建筑供能和节能的重新设计;另一方面,团队设计了大模型,设计了全新的算法过程。
研究者表示,不知道其他大模型是否也像Grok-3一样,需要如此多的人力和物力。
当然,团队也希望在接下来,减少模型的能耗,把数据中心的耗能从1/4吉瓦降低下来,或许需要重新设计,让它成为世界上效率最高的数据中心。
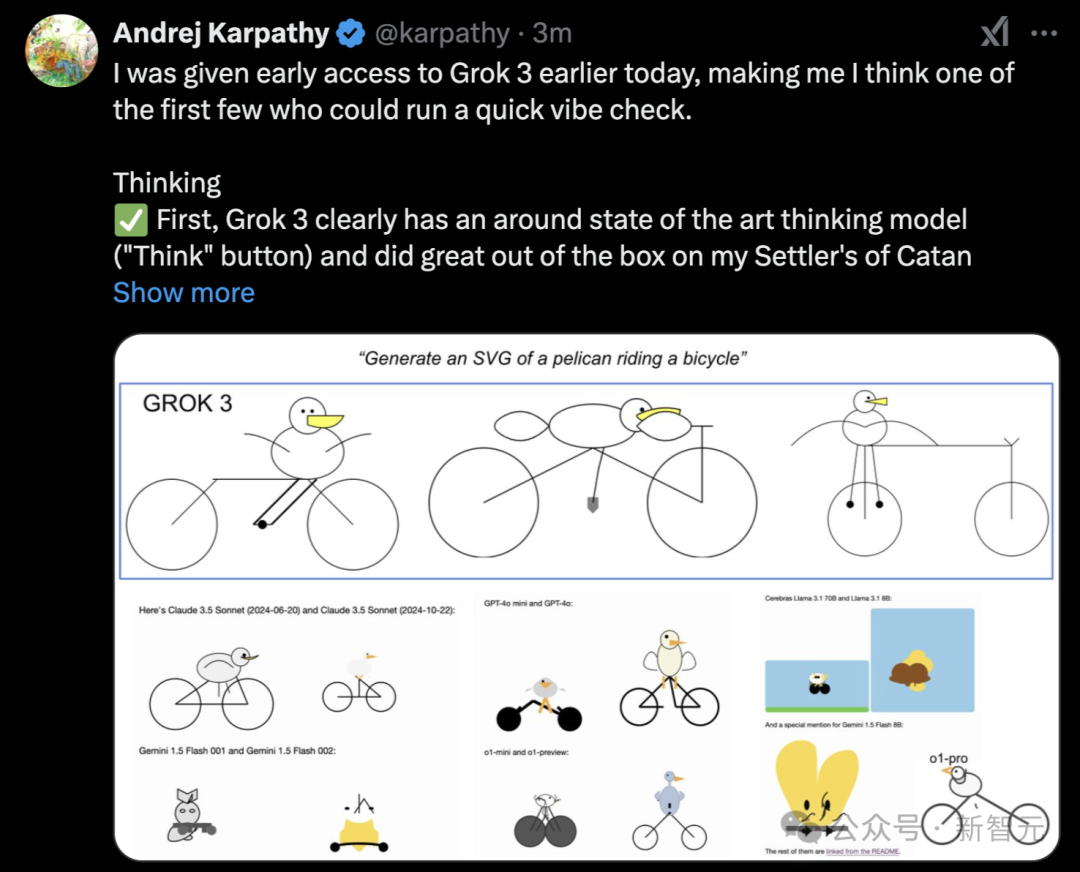
提前拿到内测资格后,AI大佬Karpathy展开了一番评测,分享的感悟比一篇文章还要长。
总结来说,Grok-3推理模型最领先,解决了卡坦岛(Settler‘s of Catan)难题。上传GPT-2论文后,Grok-3完成了简单的查找问题。
它没有解决黎曼假设难题,仅是说「这是一个伟大未解决的难题」。
在体验「深度搜索」功能时,结合了思考+深度研究的能力,能对需要研究、查找的问题提供高质量回答,并给出参考链接。
最后,Karpathy给出的评价是,「Grok-3 + Thinking表现似乎达到了与o1 Pro(每月200美元)相当的水平,并且略优于DeepSeek-R1和Gemini 2.0 Flash Thinking」。
大约一年前,xAI团队从0开始的,这么短时间内就达到了顶尖水平,这是前所未有的惊人成就。
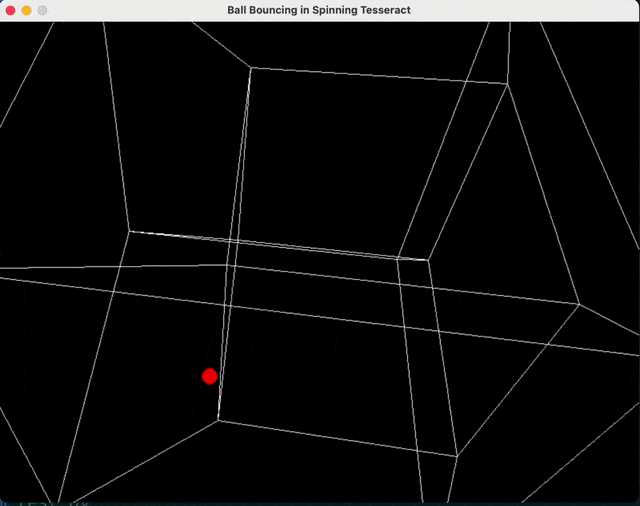
Grok-3同样通过了物理模拟测试,效果堪比o3-mini。

xAI联创同样表示,「我们改进模型和系统的速度,比任何单一的里程碑都更重要。Grok-3证明了我们能够在19个月内从零起步达到了最先进的水平」。

此外,xAI工程师还曝出了即将上线的「高级语音模式」
Grok-3横空出世,再次把xAI带回到世界第一梯队。
用马斯克的一句话做个总结——要判断哪家公司会在技术竞争中胜出,你只需要关注其创新速度的一阶导数和二阶导数。

xAI团队胜利的这一刻,值得被记录。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/219249.html