Qwen2-Audio 部署 科技前沿 • 2026-04-09 09:00 • 阅读 0 Qwen2-Audio 部署textarea id append test style https img tnblog net arcimg hb c57be76a0aee png gt Qwen2 Audio Windows 部署 textarea 大家好,我是讯享网,很高兴认识大家。这里提供最前沿的Ai技术和互联网信息。  ># Qwen2-Audio Windows部署 [TOC] tn2>Qwen2-Audio 是阿里巴巴通义千问团队推出的一款开源 AI 语音模型,支持语音聊天和音频分析,能够接受音频和文本输入,生成文本输出,支持多种语言和方言。 本文将介绍如何在 Windows 系统上部署 Qwen2-Audio 模型,包括环境配置、模型下载、推理操作等步骤,帮助您快速上手并体验这一强大的 AI 工具。 环境准备 ------------ tn2>系统:win11 安装:Anaconda Navigator Python 3.12.7 显卡:我这里是5090D tn>由于5090D需要安装最新的pytorch才可以使用cuda,否则会弹出警告不可用cuda,这里建议的版本是12.8以上。 下面可以安装最新的pytorch版本。 bash pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128 tn2>如果存在旧版本可以先卸载再安装。 bash pip uninstall torch torchvision torchaudio 下载与安装 ------------ tn2>首先从git上下载`Qwen2-Audio`, bash git clone https://github.com/QwenLM/Qwen2-Audio tn2>下载完成后,我们将在该目录下通过命令行创建虚拟环境。 bash # 这里自己填写自己的版本 conda create --name myenv python=3.12.7 # 激活虚拟环境 conda activate myenv tn2>安装`requirements_web_demo.txt`中相关依赖。 bash pip install -r requirements_web_demo.txt pip install accelerate 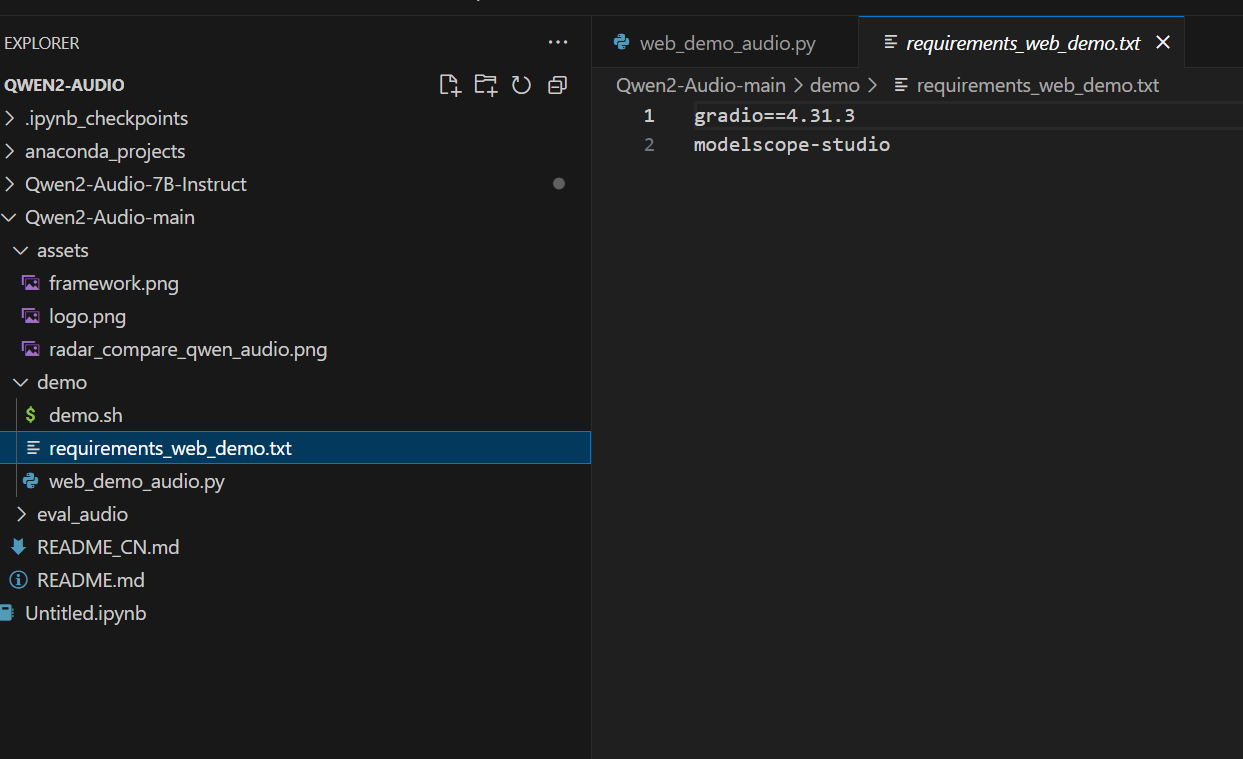 tn2>然后下载模型,首先我们可以在`modelscope`和`huggingface`中进行下载模型,链接在这儿:<a href="https://modelscope.cn/models/qwen/Qwen2-Audio-7B-Instruct/files">modelscope</a>和<a href="https://huggingface.co/Qwen/Qwen2-Audio-7B-Instruct/tree/main">huggingface</a>,重点是下面5个文件:  tn2>这里我将它放在了`D:LearningAIaudioqwen2-audioQwen2-Audio-7B-Instruct`目录下,接下来我们来更改一下`demo`目录下面的`web_demo_audio.py`代码: bash # 首先修改模型的目录 DEFAULT_CKPT_PATH = 'D:\Learning\AI\audio\qwen2-audio\Qwen2-Audio-7B-Instruct' tn2>然后我们这里我们修改全部使用gpu进行计算(不这样改会报这样的错误:`RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!`)。 python if not _get_args().cpu_only: # inputs["input_ids"] = inputs.input_ids.to("cuda") inputs = {k: v.to("cuda") for k, v in inputs.items()} # Move all inputs to GPU tn2>完整代码如下: python import gradio as gr import modelscope_studio as mgr import librosa from transformers import AutoProcessor, Qwen2AudioForConditionalGeneration from argparse import ArgumentParser #D:LearningAIaudioqwen2-audioQwen2-Audio-7B-Instruct #DEFAULT_CKPT_PATH = 'Qwen/Qwen2-Audio-7B-Instruct' # DEFAULT_CKPT_PATH = r'D:LearningAIaudioqwen2-audioQwen2-Audio-7B-Instruct' DEFAULT_CKPT_PATH = 'D:\Learning\AI\audio\qwen2-audio\Qwen2-Audio-7B-Instruct' def _get_args(): parser = ArgumentParser() parser.add_argument("-c", "--checkpoint-path", type=str, default=DEFAULT_CKPT_PATH, help="Checkpoint name or path, default to %(default)r") parser.add_argument("--cpu-only", action="store_true", help="Run demo with CPU only") parser.add_argument("--inbrowser", action="store_true", default=False, help="Automatically launch the interface in a new tab on the default browser.") parser.add_argument("--server-port", type=int, default=8000, help="Demo server port.") parser.add_argument("--server-name", type=str, default="127.0.0.1", help="Demo server name.") args = parser.parse_args() return args def add_text(chatbot, task_history, input): text_content = input.text content = [] if len(input.files) > 0: for i in input.files: content.append({'type': 'audio', 'audio_url': i.path}) if text_content: content.append({'type': 'text', 'text': text_content}) task_history.append({"role": "user", "content": content}) chatbot.append([{ "text": input.text, "files": input.files, }, None]) return chatbot, task_history, None def add_file(chatbot, task_history, audio_file): """Add audio file to the chat history.""" task_history.append({"role": "user", "content": [{"audio": audio_file.name}]}) chatbot.append((f"[Audio file: {audio_file.name}]", None)) return chatbot, task_history def reset_user_input(): """Reset the user input field.""" return gr.Textbox.update(value='') def reset_state(task_history): """Reset the chat history.""" return [], [] def regenerate(chatbot, task_history): """Regenerate the last bot response.""" if task_history and task_history[-1]['role'] == 'assistant': task_history.pop() chatbot.pop() if task_history: chatbot, task_history = predict(chatbot, task_history) return chatbot, task_history def predict(chatbot, task_history): """Generate a response from the model.""" print(f"{task_history=}") print(f"{chatbot=}") text = processor.apply_chat_template(task_history, add_generation_prompt=True, tokenize=False) audios = [] for message in task_history: if isinstance(message["content"], list): for ele in message["content"]: if ele["type"] == "audio": audios.append( librosa.load(ele['audio_url'], sr=processor.feature_extractor.sampling_rate)[0] ) if len(audios)==0: audios=None print(f"{text=}") print(f"{audios=}") inputs = processor(text=text, audios=audios, return_tensors="pt", padding=True) if not _get_args().cpu_only: # inputs["input_ids"] = inputs.input_ids.to("cuda") inputs = {k: v.to("cuda") for k, v in inputs.items()} # Move all inputs to GPU generate_ids = model.generate(inputs, max_length=256) #generate_ids = generate_ids[:, inputs.input_ids.size(1):] generate_ids = generate_ids[:, inputs["input_ids"].size(1):] response = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0] print(f"{response=}") task_history.append({'role': 'assistant', 'content': response}) chatbot.append((None, response)) # Add the response to chatbot return chatbot, task_history def _launch_demo(args): with gr.Blocks() as demo: gr.Markdown( """<p align="center"><img src="https://51itzy.com/uploads/202412/23/d8d6e00325d3a7fb.jpg" data-src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/assets/blog/qwenaudio/qwen2audio_logo.png" style="height: 80px"/><p>""") gr.Markdown("""<center><font size=8>Qwen2-Audio-Instruct Bot</center>""") gr.Markdown( """ <center><font size=3>This WebUI is based on Qwen2-Audio-Instruct, developed by Alibaba Cloud. (本WebUI基于Qwen2-Audio-Instruct打造,实现聊天机器人功能。)</center>""") gr.Markdown(""" <center><font size=4>Qwen2-Audio <a href="https://modelscope.cn/models/qwen/Qwen2-Audio-7B">?? </a> | <a href="https://huggingface.co/Qwen/Qwen2-Audio-7B">??</a> | Qwen2-Audio-Instruct <a href="https://modelscope.cn/models/qwen/Qwen2-Audio-7B-Instruct">?? </a> | <a href="https://huggingface.co/Qwen/Qwen2-Audio-7B-Instruct">??</a> | <a href="https://github.com/QwenLM/Qwen2-Audio">Github</a></center>""") chatbot = mgr.Chatbot(label='Qwen2-Audio-7B-Instruct', elem_classes="control-height", height=750) user_input = mgr.MultimodalInput( interactive=True, sources=['microphone', 'upload'], submit_button_props=dict(value="?? Submit (发送)"), upload_button_props=dict(value="?? Upload (上传文件)", show_progress=True), ) task_history = gr.State([]) with gr.Row(): empty_bin = gr.Button("?? Clear History (清除历史)") regen_btn = gr.Button("??? Regenerate (重试)") user_input.submit(fn=add_text, inputs=[chatbot, task_history, user_input], outputs=[chatbot, task_history, user_input]).then( predict, [chatbot, task_history], [chatbot, task_history], show_progress=True ) empty_bin.click(reset_state, outputs=[chatbot, task_history], show_progress=True) regen_btn.click(regenerate, [chatbot, task_history], [chatbot, task_history], show_progress=True) demo.queue().launch( share=False, inbrowser=args.inbrowser, server_port=args.server_port, server_name=args.server_name, ) if __name__ == "__main__": args = _get_args() if args.cpu_only: device_map = "cpu" else: device_map = "auto" model = Qwen2AudioForConditionalGeneration.from_pretrained( args.checkpoint_path, torch_dtype="auto", device_map=device_map, resume_download=True, ).eval() model.generation_config.max_new_tokens = 2048 # For chat. print("generation_config", model.generation_config) processor = AutoProcessor.from_pretrained(args.checkpoint_path, resume_download=True) _launch_demo(args) tn2>开始运行。 python python web_demo_audio.py 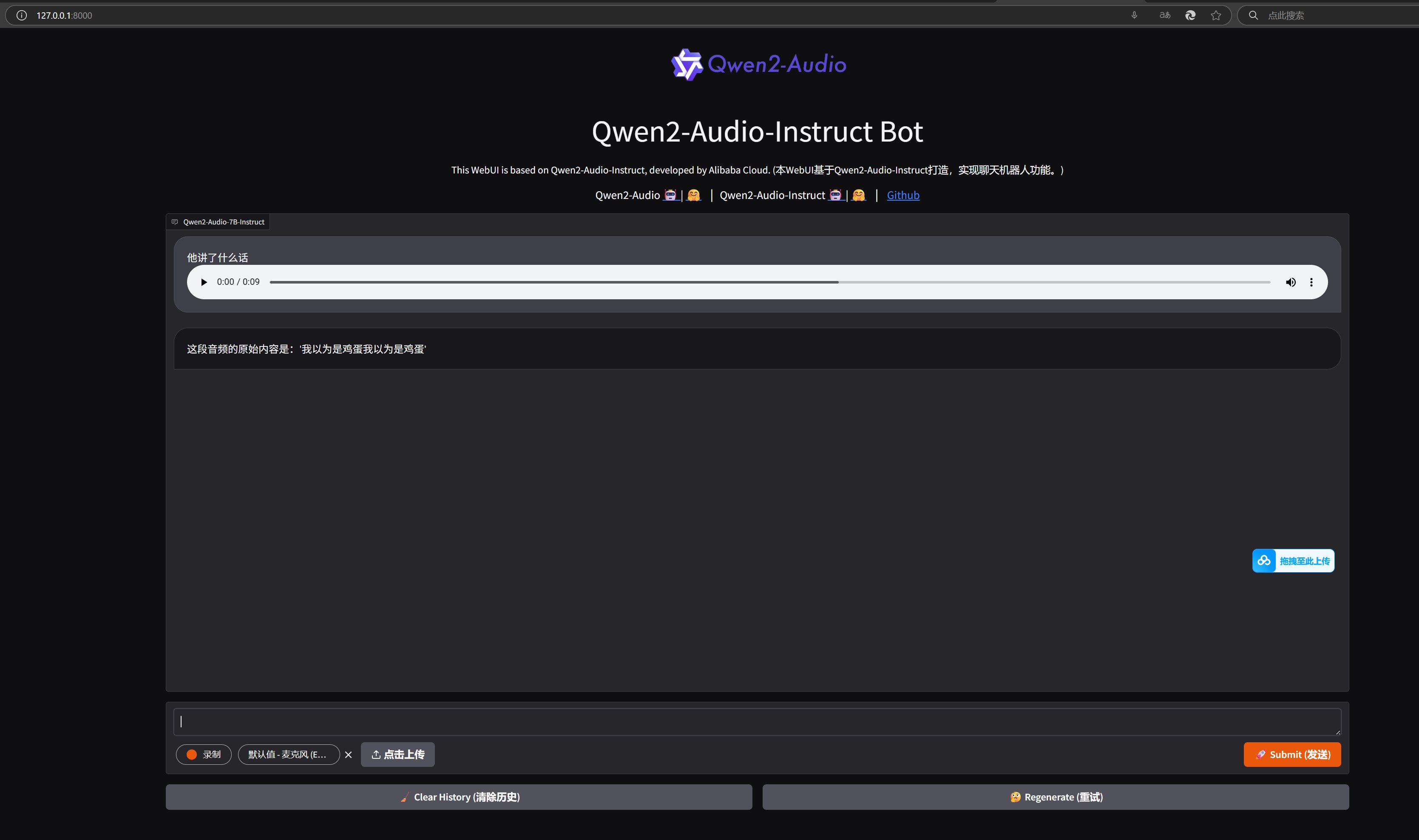 tn2>这样在本地就部署成功了。 中途遇到了一些问题: 问题一 ------------ tn2>web界面有时候没有输入框,这最先开始也是我不解的地方,然后我执行下面的命令后就有了。 python pip install modelscope-studio==0.5.2 问题二 ------------ tn2>然后我们通过录制音频,编辑文本后发送发现报错。 发现是什么`Exception in ASGI application`什么什么的错误,通过各种各样的尝试最后换了一下gradio版本解决了。 python pip install gradio --upgrade -i https://mirrors.cloud.tencent.com/pypi/simple pip包我提供一下 ------------ bash (myenv) D:LearningAIaudioqwen2-audio>pip list WARNING: Ignoring invalid distribution ~radio-client (D:ProgramDataanaconda3envsmyenvLibsite-packages) WARNING: Ignoring invalid distribution ~umpy (D:ProgramDataanaconda3envsmyenvLibsite-packages) Package Version ------------------------- ------------------------ accelerate 1.6.0 aiofiles 23.2.1 altair 5.5.0 annotated-types 0.7.0 anyio 4.9.0 asttokens 3.0.0 attrs 25.3.0 audioread 3.0.1 certifi 2025.4.26 cffi 1.17.1 charset-normalizer 3.4.2 click 8.1.8 colorama 0.4.6 comm 0.2.2 contourpy 1.3.2 cycler 0.12.1 debugpy 1.8.14 decorator 5.2.1 executing 2.2.0 fastapi 0.115.12 ffmpy 0.5.0 filelock 3.18.0 fonttools 4.57.0 fsspec 2025.3.2 gradio 5.29.0 gradio_client 1.10.0 groovy 0.1.2 h11 0.16.0 httpcore 1.0.9 httpx 0.28.1 huggingface-hub 0.30.2 idna 3.10 importlib_resources 6.5.2 ipykernel 6.29.5 ipython 9.2.0 ipython_pygments_lexers 1.1.1 jedi 0.19.2 Jinja2 3.1.4 joblib 1.5.0 jsonschema 4.23.0 jsonschema-specifications 2025.4.1 jupyter_client 8.6.3 jupyter_core 5.7.2 kiwisolver 1.4.8 lazy_loader 0.4 librosa 0.11.0 llvmlite 0.44.0 markdown-it-py 3.0.0 MarkupSafe 2.1.5 matplotlib 3.10.1 matplotlib-inline 0.1.7 mdurl 0.1.2 modelscope_studio 0.5.2 mpmath 1.3.0 msgpack 1.1.0 narwhals 1.37.1 nest-asyncio 1.6.0 networkx 3.3 numba 0.61.2 numpy 1.26.4 orjson 3.10.18 packaging 25.0 pandas 2.2.3 parso 0.8.4 pillow 10.4.0 pip 25.1 platformdirs 4.3.7 pooch 1.8.2 prompt_toolkit 3.0.51 psutil 7.0.0 pure_eval 0.2.3 pycparser 2.22 pydantic 2.11.4 pydantic_core 2.33.2 pydub 0.25.1 Pygments 2.19.1 pyparsing 3.2.3 python-dateutil 2.9.0.post0 python-multipart 0.0.20 pytz 2025.2 pywin32 310 PyYAML 6.0.2 pyzmq 26.4.0 referencing 0.36.2 regex 2024.11.6 requests 2.32.3 rich 14.0.0 rpds-py 0.24.0 ruff 0.11.8 safehttpx 0.1.6 safetensors 0.5.3 scikit-learn 1.6.1 scipy 1.15.2 semantic-version 2.10.0 setuptools 78.1.1 shellingham 1.5.4 six 1.17.0 sniffio 1.3.1 soundfile 0.13.1 soxr 0.5.0.post1 stack-data 0.6.3 starlette 0.46.2 sympy 1.13.3 threadpoolctl 3.6.0 tokenizers 0.21.1 tomlkit 0.12.0 torch 2.8.0.dev+cu128 torchaudio 2.6.0.dev+cu128 torchvision 0.22.0.dev+cu128 tornado 6.4.2 tqdm 4.67.1 traitlets 5.14.3 transformers 4.52.0.dev0 typer 0.15.3 typing_extensions 4.13.2 typing-inspection 0.4.0 tzdata 2025.2 urllib3 2.4.0 uvicorn 0.34.2 wcwidth 0.2.13 websockets 11.0.3 wheel 0.45.1 tn>如果有其他的问题可以留言。 参考链接 ------------ tn2>https://juejin.cn/post/ https://blog.csdn.net/_/article/details/ https://github.com/QwenLM/Qwen2-Audio/issues/112 小讯 2026年文心一言ERNIE-Search大模型为何能重塑未来科技?看他是如何改变我们搜索方式的 上一篇 2026-04-09 09:00 国内平替ClaudeCode编程大模型推荐 下一篇 2026-04-09 08:58 相关推荐 2026年文心一言ERNIE-Search大模型为何能重塑未来科技?看他是如何改变我们搜索方式的 1773233051 2026年Claude Prompt Generator 使用教程 1773233047 月之暗面 Kimi K2 高速版 AI 模型提速:输出速度达每秒 100 Tokens 1773233043 2026年文心一言怎么使用翻译功能 1773233039 2026年团省委联合科大讯飞发布2025届星火校园实习生计划 1773233031 2026年Cursor使用教程:注册订阅与小白进阶指南(超详细) 1773233027 2026年通义千问大模型API代码生成对比: Qwen 2.5-Coder-32B、Qwen 2.5-Coder-14B 1773233023 智谱没跟上OpenAI 1773233019 Claude Code免费编程使用指南 1773233007 国内平替ClaudeCode编程大模型推荐 1773233067 【MCP】Claude Code for VS Code 配置阿里云 MCP 工具教程 1773233075 如何调用DeepSeek API:详细教程与示例 1773233079 【PyTorch实战】多模态图片生成(文心一言大模型) 1773233083 2026年AI+绘画入门教程:基于 ChatGLM 的文生图与伪代码实现 - 教程 1773233087 2026年讯飞星火行业分析师通过工信部考试,AI智能体加速落地 1773233091 写文章还在手动配图?这个Skill让AI从分析到排版全包,连预览都给你做好了! 1773233095 2026年如何在 Cursor 中继续使用 Claude 1773233099 clawdbot国内能用吗 clawdbot使用方法教程 1773233103 版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。如需转载请保留出处:https://51itzy.com/kjqy/217928.html

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/217928.html