
多数企业的大模型初步应用场景为:知识库、智能客服等。该部分场景主要使用模型增强和模型微调技术。两者在使用中,又经常结合使用。笔者现将学习相关技术过程遇到的信息整理成文。
技术 说明 工程化 地址 场景 模型增强 RAG RagFlow https://github.com/infiniflow/ragflow 知识库、智能客服 模型微调 Lora LLaMA-Factory https://github.com/hiyouga/LLaMA-Factory/ 垂直领域迁移
相应的使用流程如下:
底模选择 => Lora微调 => Rag增加 => 业务使用
- 环境准备
1.1 Conda环境准备
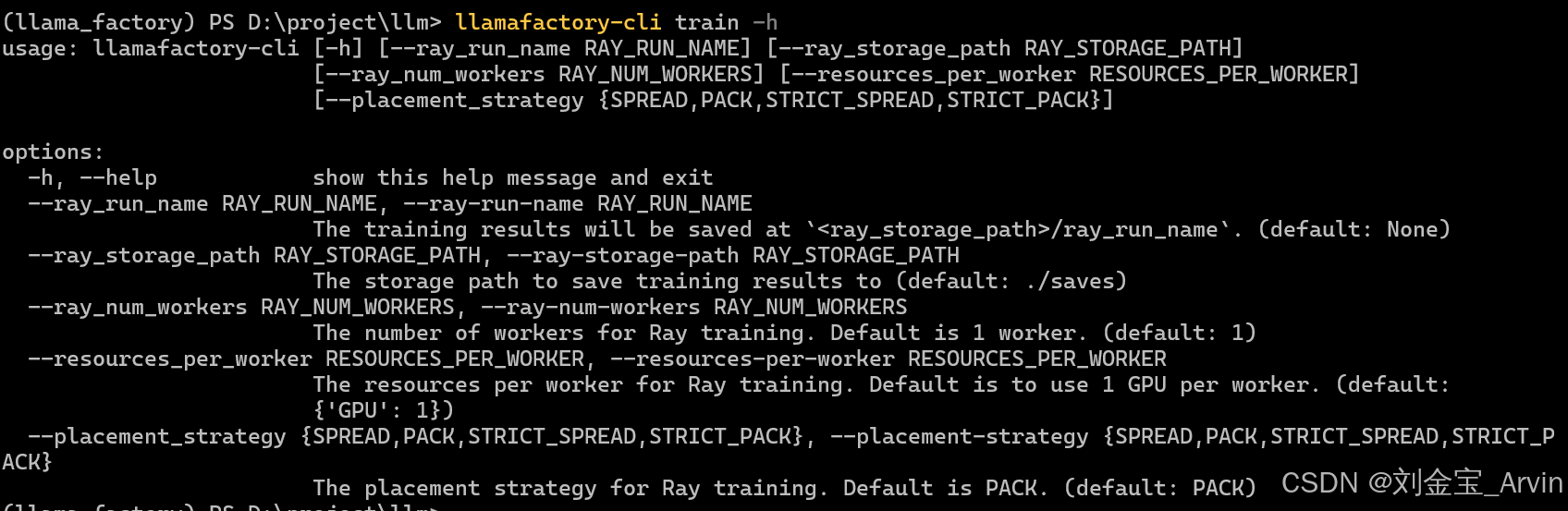
1.2 Torch、CUDA、LLaMA-Factory部署 - Lora微调与模型输出
2.1 模型、数据集下载 - Rag强化
- API调用
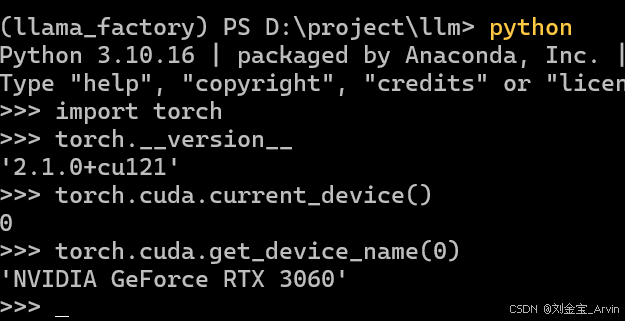
注:对电脑配置有一定要求,高于本机配置,理论可流畅执行下属步骤,低于本机配置,不保证正确运行。配置信息如下:
参考该文章:Windows安装Conda
2.2.1 Conda创建llama_factory环境:
2.2.2 下载安装LLaMA-Factory
选择目录,并Git clone代码:
2.2.3 安装CUDA torch
- 进入该链接下载版本对应的gpu torch即可(torch whl下载)
- 进入下载地址,进入llama_factory环境,安装whl包
注:该包为本人所用torch包,请根据上文替换为你自己的包
国内推荐魔塔社区(能访问外网的话可以huggingface),类似于模型界的gitee:魔塔社区
注:这里也可以下载其他模型,在魔塔社区搜索即可。
此处训练一个新闻分类的模型。
3.3.1 webui,启动
3.3.2 模型与数据集加载
3.3.3 训练参数设置
3.3.4 预览与训练
3.3.5 评估
3.3.6 Chat
3.3.7 Lora合并
3.3.8 加载合并的模型
包含以下三个步骤:
- Ollama安装部署
- Docker部署RAGFlow
- RAG构建个人知识库
环境变量配置:
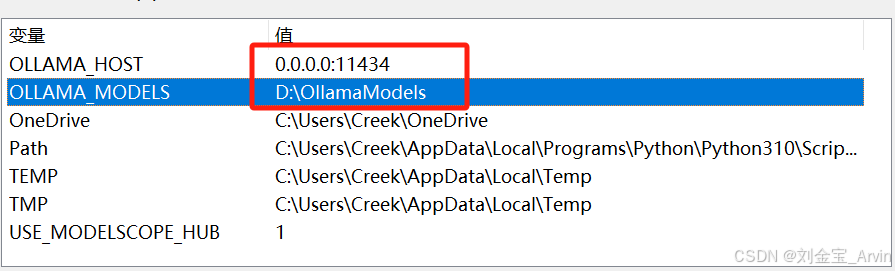
配置完成重启电脑。
4.2.1 Docker安装
国内docker可用镜像(通过deepseek问出来的)
参考该文章:Windows安装Docker
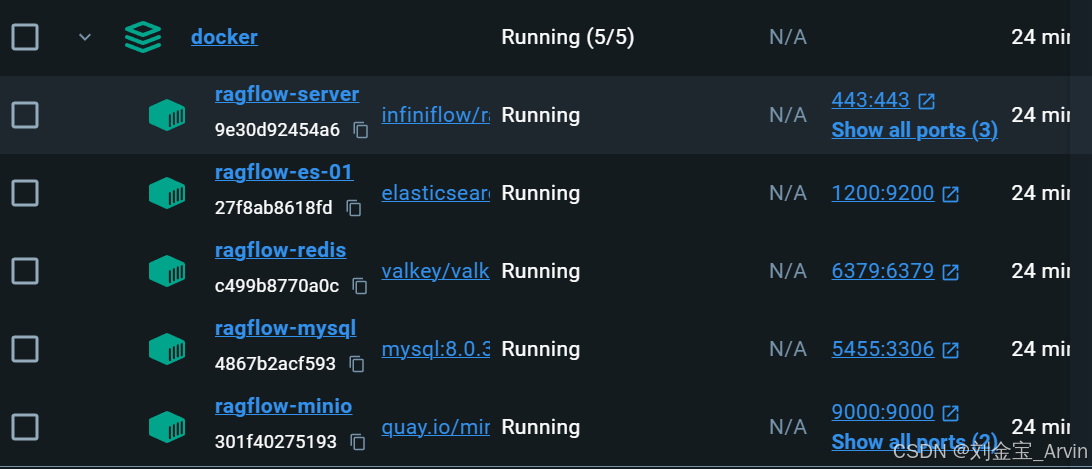
Docker用于ragflow运行过程中所依赖的组件:es、redis、minio、mysql等
4.2.2 安装ragflow
在自己规划的目录中,clone ragflow工程,比如我放在了llama-factory的同级目录下

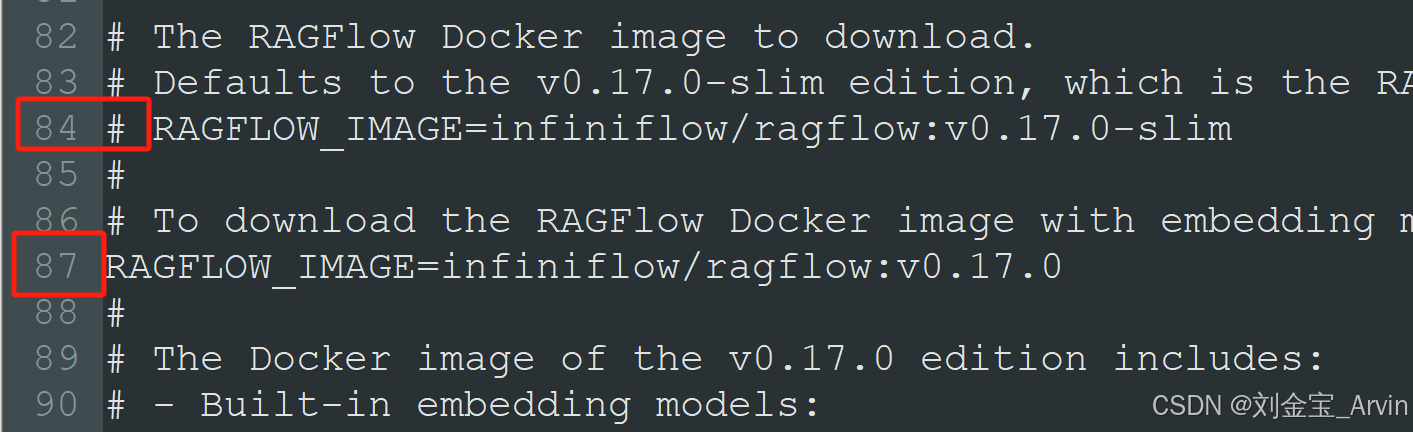
修改ragflow配置,使其下载完整版本embedding模型:
修改,将84行注释,并取消87行的注释,保存。
在该目录下,执行,等待拉取镜像并启动完成即可(如果遇到端口冲突,多半重启下电脑就好了)。
访问,注册一个账户即可,页面如下:
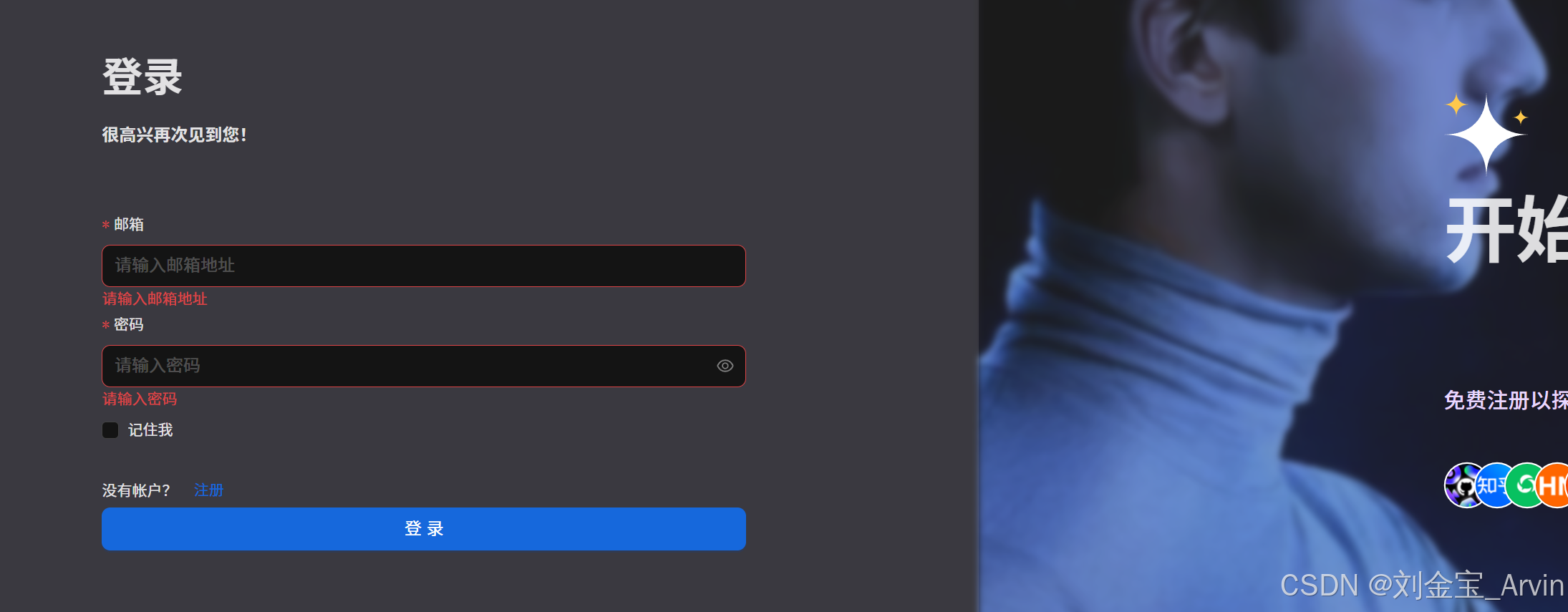
至此,部署成功。
4.3.1 将个人模型集成到ollama
微调后的模型为safetensor文件,新版本的ollama是可以集成的,但需要简单修改下:
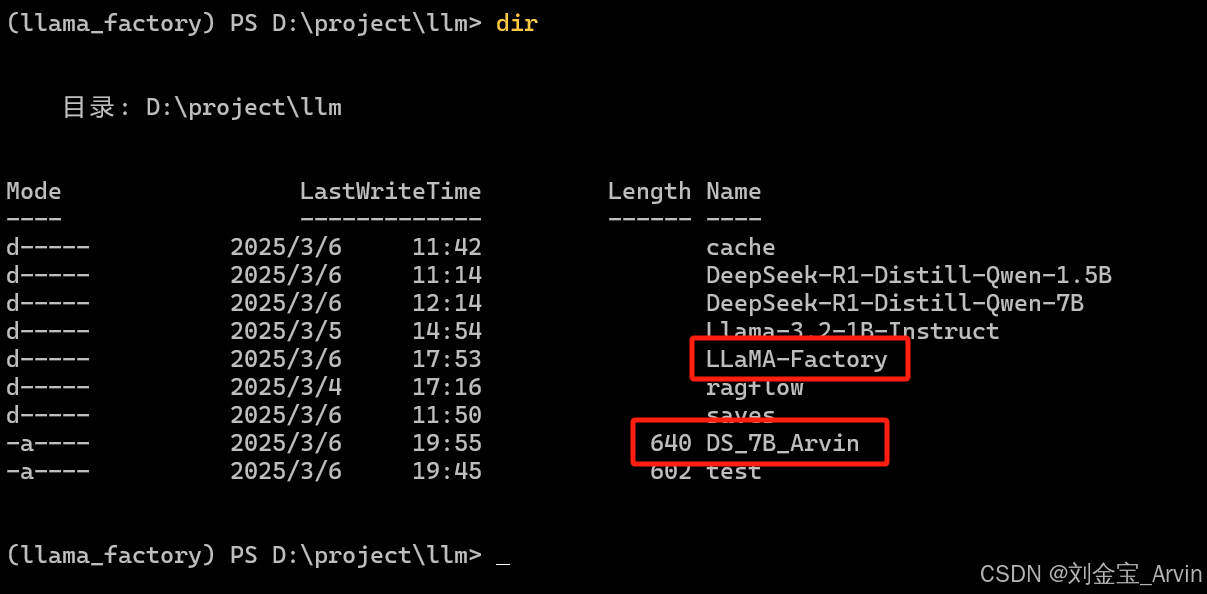
4.3.1.1 创建启动文件
- from后面为自己的模型的相对路径
- 第二行及以后需要加上,不然模型虽然可以正确加载,但是会胡言乱语(具体原因未知)
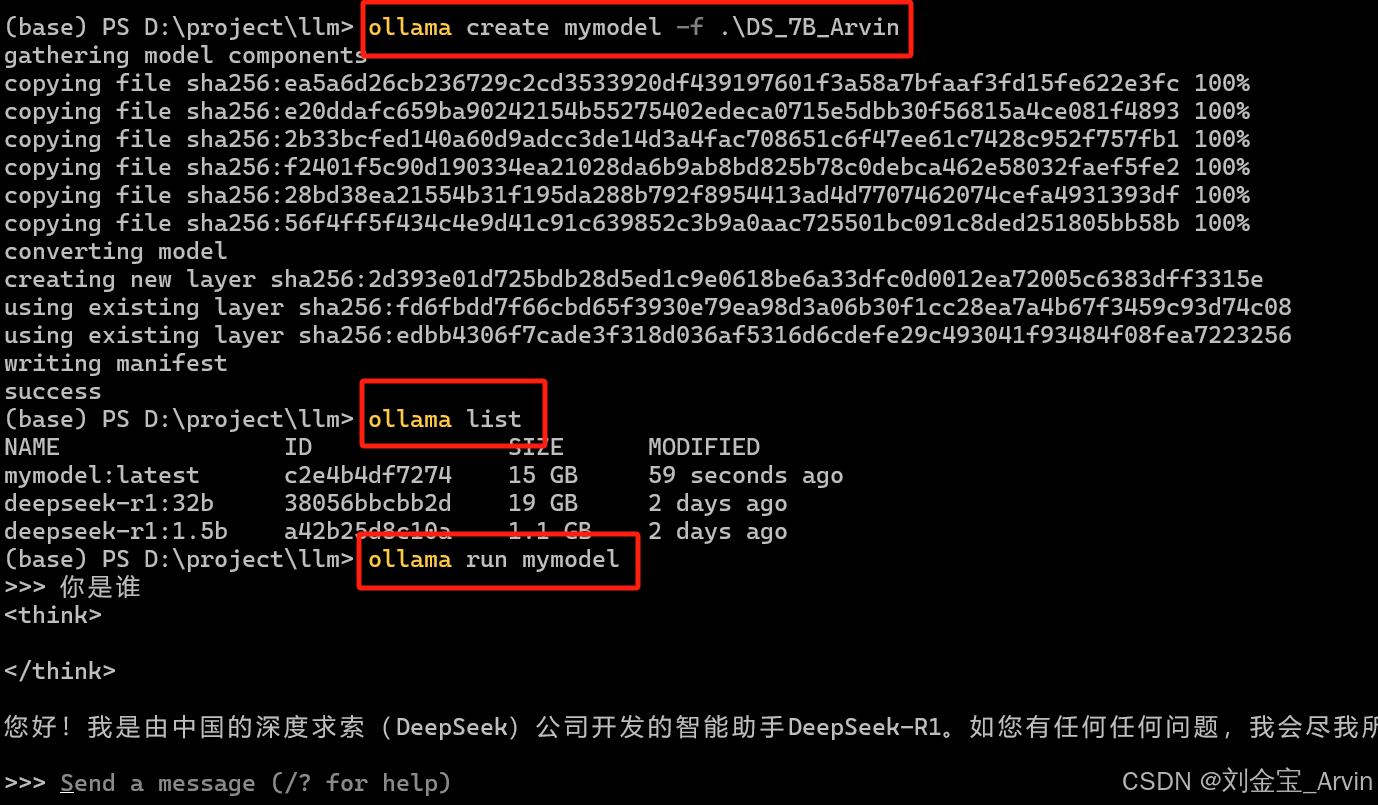
4.3.1.2 启动运行模型
加载模型,在指定目录加载启动文件,并等待:
4.3.2 RAGFlow集成
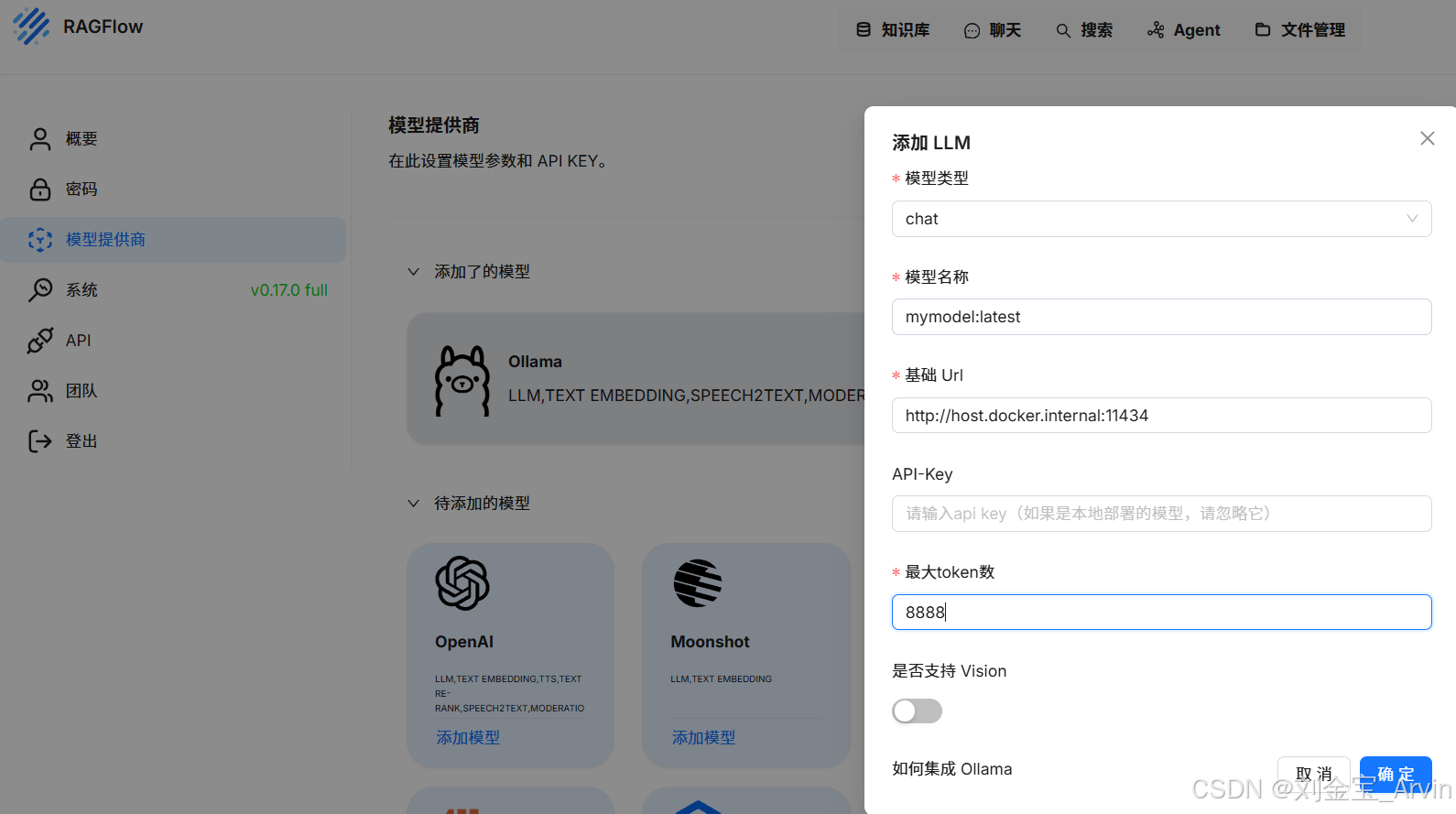
4.3.2.1 模型添加
配置信息
- 模型名称为输出的名字
- 基础url写死为:
- chat模型
设置系统模型:
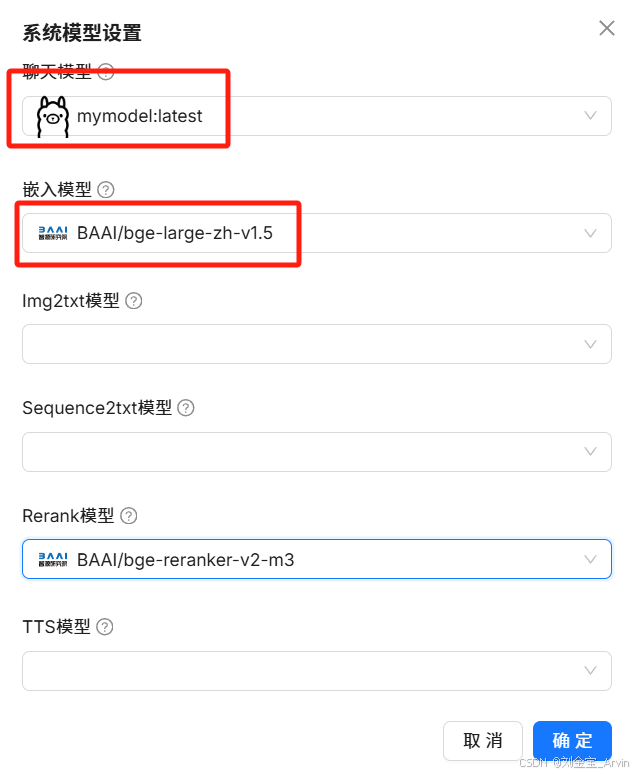
4.3.2.2 创建知识库
4.3.3 API调用
参考文章:
- https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md
- https://github.com/infiniflow/ragflow
- https://gallery.pai-ml.com/#/preview/deepLearning/nlp/llama_factory_deepseek_r1_distill_7b
- https://zhuanlan.zhihu.com/p/
- https://zhuanlan.zhihu.com/p/
- https://www.bilibili.com/video/BV1WiP2ezE5a/?spm_id_from=333.1387.upload.video_card.click&vd_source=babebb18c335657782b80a2ec6cecf84
- https://blog.csdn.net/yierbubu1212/article/details/
- https://www.cnblogs.com/sun8134/p/
- RAGFlow API调用讲解视频
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/217773.html