
短的结论:刷新纯国产算力的智力上限
基本信息:
- 成本:¥12每百万
- 平均长度:约14800字
- 速度:约44字每秒
- 平均耗时: 337秒
逻辑成绩:
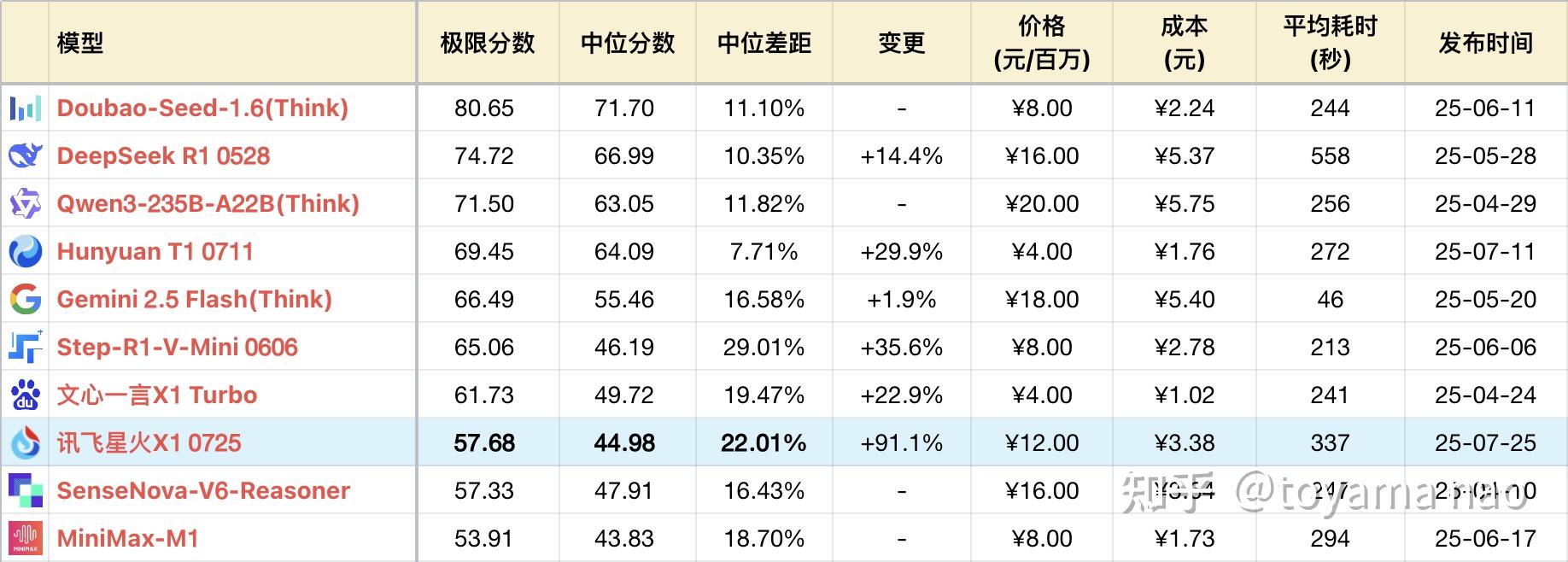
*表格为了突出对比关系,有一定裁剪,不是完整排序
测试方式:参见大语言模型-逻辑能力横评 25-06月榜(R1/Gemini 2.5/Doubao-Seed-1.6…
*完整榜单更新在Github
讯飞是很有意思的,每一代模型发布总要宣称可以打当时世界最好的产品,从当初星火4.0打GPT-4,到发布推理模型X1要打o1,再到这次X1新版要打o3。讯飞整体的宣传水平稳定发挥,从不令人失望和意外。
同样没有令人失望的是新X1的整体表现。X1从最初发布时赶鸭子上架,人工限制了只回答数学问题,到4月版本解除限制,但整体表现难堪大用,作为一个推理模型,性能混迹在一众非推理模型之间。而新X1终于追上了主流推理模型的中等水平。正如笔者在测试4月X1时所说,讯飞需要“做更好的自己”,一个季度后,讯飞确实做到了,纯国产算力底座能做到的上限被再一次刷新。
新版性能上涨的代价是输出长度,Token消耗均翻倍,不过耗时仅涨60%,说明输出效率有改进。不过目前平均14800字的输出长度在推理模型里并不突出,比这高的大有模型在。
以下是其新版表现的具体分析。
改善:
- 幻觉改善:正如在讯飞官方宣传中所言,新版在幻觉控制方面确实比旧版提升巨大,其旧版以极其严重的幻觉,导致大多数上下文,指令等场景表现近乎不可用。改进后的新版在相关问题上发挥正常,甚至偶尔智力爆发,取得远超平均水平的成绩,如#40代码推导,此题仅第一梯队模型可稳定满分,而新版也做对1次。在长上下文的题目中,新版也有不小提升。
- 计算精度:得益于幻觉改善,其计算精确度也有较大提升,#38函数求交,#22连续计算,均有较大概率拿到高分。相关表现也达到推理模型平均水平。不过计算稳定性并不高,偶尔一些简单加法计算也会出错。
不足:
- 暴力偏好:在需要解题技巧的题目上,新版偏好使用暴力,有些题用暴力可以解出,比如#36六阶数独。但有些不行,如#23解密,#29符号还原,新版用尽全力(Token),最后放弃。不过对第三梯队的推理模型而言,这些难题做不出是正常表现。
- 指令理解:X1对指令的理解难以捉摸,尽管已经有较大改善,但在许多简单指令理解上依然频繁出错。如#30日记整理,混淆多条指令。#20桌游模拟,推理中途遗忘指令。这类题目要求明确,只需要严格执行一遍就能拿到答案,一些非推理模型也能拿到高分。X1表现低于平均水平。
- 输出粗糙:新版的输出存在较多Badcase,整体显得粗糙。例如在计算类题目中,回答使用的数字不是普通数字字符,而是用于上标或者下标的特殊字符,甚至是Unicode中代表数字的Emoji。甚至在计算问题中,思考过程使用汉字数字,过于离奇,难以揣测讯飞团队是如何训练的。此外,频繁输出NBSP,EMSP等空格标记,也让人怀疑其训练语料混合了太多了蒸馏数据。甚至在一些输出markdown表格的场景,新版偶现不输出换行,导致文本排版完全混乱不可读。相比之下,输出风格不统一已经是最微不足道的问题了。
赛博史官曰:
在众多国产大模型厂商中,讯飞是被特别关注的一家,不但是因为讯飞坚持用纯国产算力,还因为讯飞掌握了大量的政企,教育资源。如果讯飞争气一些,则能福泽众多社会领域。也正因如此,怒其不争久矣。而讯飞坚持自己的道路,每一个季度迭代一次,看似落后,却不掉队。如此团队,一旦解决掉历史积弊,正视问题,走上正确道路,快速进步并非不可想象。
目前所有评测文章在公众号:大模型观测员 同步更新。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/217200.html