
曾经风起云涌的“输入法右下角大战”,是否即将迎来一位重量级的新玩家?这一次,带着人工智能大模型技术光环的智谱输入法横空出世,不仅让人眼前一亮,更引发了业界对输入法未来形态的重新想象。它究竟带来了哪些值得期待的亮点?又在产品逻辑与用户体验上做出了哪些真正意义上的创新?让我们跟随镜头,一探究竟。
甫一打开智谱输入法的官网,扑面而来的不仅是简洁现代的设计语言,更是一种对“智能输入”全新定义的野心。在众多输入法厂商仍在优化词库、提升云同步速度或打磨皮肤视觉的背景下,智谱选择了一条更具前瞻性的道路——将大语言模型深度融入输入场景。这不仅是技术上的跃迁,更是一场从“工具型输入”向“认知型输入”演进的范式革命。
更值得一提的是,从官网呈现的信息来看,智谱在营销策略上也展现出罕见的敏锐与魄力。无论是概念视频的叙事节奏,还是功能亮点的包装方式,都透露出一种“不止于输入法”的格局。作为所有输入法厂商中最注重品牌表达与用户心智占领的一家,智谱显然不只是想做另一个输入工具,而是试图打造一个以AI为内核、以语言为接口的智能交互入口。
那么,这场由大模型驱动的输入法新战役,究竟会如何改写我们与文字、与设备、甚至与信息本身的关系?接下来,就让我们深入细节,一窥其背后的技术逻辑与产品哲学。
https://docs.bigmodel.cn/cn/coding-plan/benefits/autotyper
https://autoglm.zhipuai.cn/autotyper/
AutoGLM AutoTyper(智谱AI输入法)是一款智能的AI语音输入工具,通过说话就能实现高效创作,告别繁琐打字,实现说话即成文。据官方数据,其语音输入速度比传统打字快4倍。
语音转文字
- 实时转写:语音实时转换成文字
- 精准识别:支持耳语等低音量输入,细语皆闻
- 节省输入时间:平均节省输入时间72%
出口成章
- 碎片化口语专业呈现:将口语化表达转换为专业书面语
- 自动润色:让书面表达更流畅、更专业
- 多风格适配:支持最多9个版本的不同风格表达
自定义指令场景
支持多种工作场景的内容生成:
- 工作汇报:自动生成结构化的工作报告(日报、周报、月报)
- 邮件回复:快速生成专业的邮件回复
- 创意写作:辅助文案创作,适配博客、社交媒体等平台
- 专业报告:生成分析报告、技术文档和代码文档
小凹助手
- 语音直接调用:”小凹,为什么我输入的指令总是得不到满意的回复?”
- 一句话激活功能,随叫随到
文本润色
- 适配正式报告、日常邮件、社交媒体文案
- 自动调整语言风格,让表达更专业
多版本生成
- 最多可选择9个版本
- 展示不同风格的表达方式
- 支持用户DIY添加更多风格
职业角色覆盖
1. 创作者:语音实时转写,自动润色成稿,无缝同步Notion
2. 管理者:语音记录要点,自动生成结构化纪要
3. HR/律师:生成模板化文档,自动嵌入合规条款
4. 效率达人:全场景语音输入,跨应用实时转写
5. 销售/猎头:语音记录跟进,10分钟完成邮件+CRM录入
6. 投资人:语音速记核心观点,生成结构化报告
7. 翻译:语音转写+实时翻译,多语言无缝切换
8. 教师:语音描述教学思路,同步课件工具
9. 博主:语音口述大纲,适配多平台风格
10. 设计师:语音描述设计思路,同步设计工具
11. 程序员:语音描述逻辑,自动生成文档,适配代码风格
12. 运营:语音梳理要点,自动排版成稿
13. 采购:语音罗列需求,生成规范文档
14. 导游:语音描述路线,适配景点风格
- 语音识别准确率:97.8%
- 团队用户评分:4.8⁄5
- 效率提升:语音输入比打字快4倍
- 当前支持:MacOS/Windows版
解决的痛点
1. 思绪零散:整理文稿费时费力
2. 语言障碍:一遇外语,秒变”社恐”
3. AI协作复杂:与AI协作步骤繁琐,影响效率
4. 表达不准确:沟通对象多变,词不达意
核心价值
- 解放双手:告别键盘束缚,让想法自然流淌
- 效率翻倍:无论长文还是速记,动动嘴就完成
- 专业表达:自动润色,让每次输出都更专业
- 场景适配:精准匹配不同工作场景的表达需求
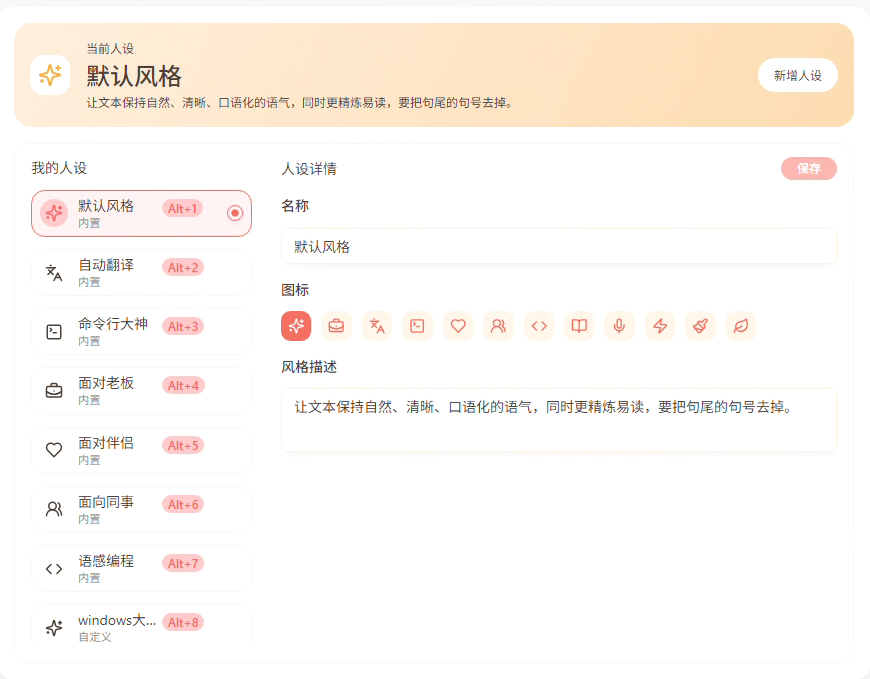
人设设置
内置8个人人设风格,准备体验 默认风格/自动翻译/命令行大神/语感编程,然后试下新建一个windows命令行大师风格,试试看自定义效果如何。
这里面的人设的设置比较难理解,看起来是控制喂给大模型的prompt,一段没有开放的prompt前缀+下面这段话风格设置
基础ASR测试
环境:存在一定的背景音乐,带降噪的拾音MIC
原文:主机和某些配件包含可充电锂电子电池。电池中所包含成分的泄漏,或成分的燃烧产物,可能导致人身伤害以及系统的损坏
翻译提取后:电池包含可充电锂电子电池,电池中所包含成分的泄漏或成分的燃烧产物可能会导致人身伤亡以及系统的损坏
语音翻译速度:2秒左右
语音评价:中规中矩,识别是在线ASR,中间区域有实时的识别结果输出,但是体验效果不佳,语音识别暂停之后,如果可以在800ms内出结果是最优的体验。
注意: 非带噪音/背景音乐厂家,识别正常

翻译
设定是在默认人设下,但是用语音指令控制他帮我翻译,翻译内容原始字数1659
翻译速度(包含语音识别):7秒左右
总体耗时还是比较大的,如果经常翻译,又不想拷贝复制粘贴,建议订阅GLM Coding Plan + VS Code 插件或者Claude Code,借助大模型的能力进行翻译

写故事
这个也是大模型基础能力,ASR只是当做输入,仅做测试,这个需要不断完善纠偏的,不适合用没有上下文的语音对话优化,另外一个比较重点是,你不知道你说语音的时候,是否有发音错误,这个在整个体验中是无法感知的。
体验了10轮,成功次数很低,存在一定的大模型幻觉,无法争取提取用户的用途。
执行shell
试了很多次,效果都不好,linux命令知道也是有限,windows底下基本残废
写代码
效果不好
- 写个C语言的hello world,出来个markdown格式的hello world,头文件都没有包含
- 写个C语言的递归算法,直接输出文本
安装程序的第一时间,让GLM Coding Plan配合Claude Code干活,分析下程序实现的方式
看来跨平台最简单的方式还是选择了 Electron的桌面应用
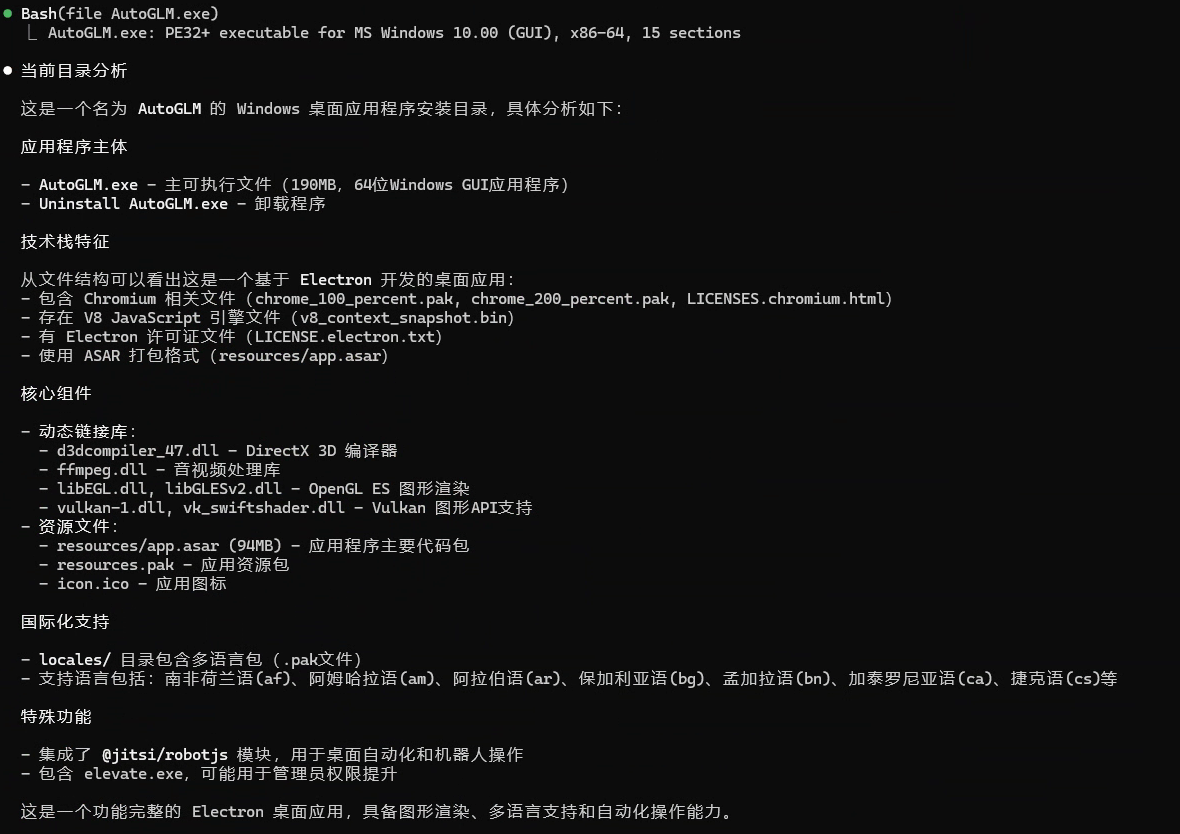
基于AutoGLM应用程序源码分析,详细说明了三大核心流程:登录认证、ASR语音识别和大模型调用。
流程图
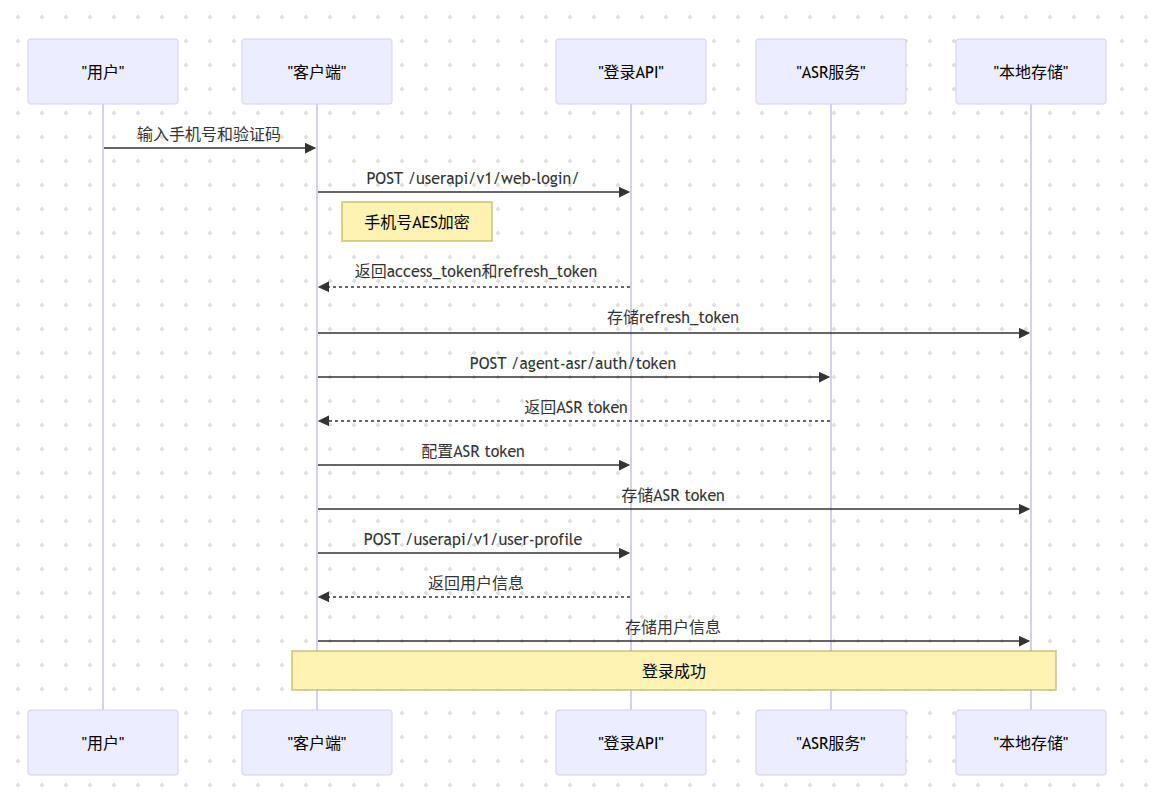
核心代码实现
登录处理函数 (`dist-electron/app/contexts/user/login.js`):
GPT plus 代充 只需 145
关键API接口:
- - 手机验证码登录
- - 获取ASR认证token
- - 获取用户信息
- - 刷新access_token
认证机制
1. 双Token系统:
- : API访问令牌
- : 刷新令牌,用于获取新的access_token
2. ASR独立Token:
- 登录后需要额外获取ASR服务的专用token
- 使用函数处理token格式
3. 自动刷新机制:
- Token过期时自动调用刷新接口
- 刷新失败则触发重新登录
流程图
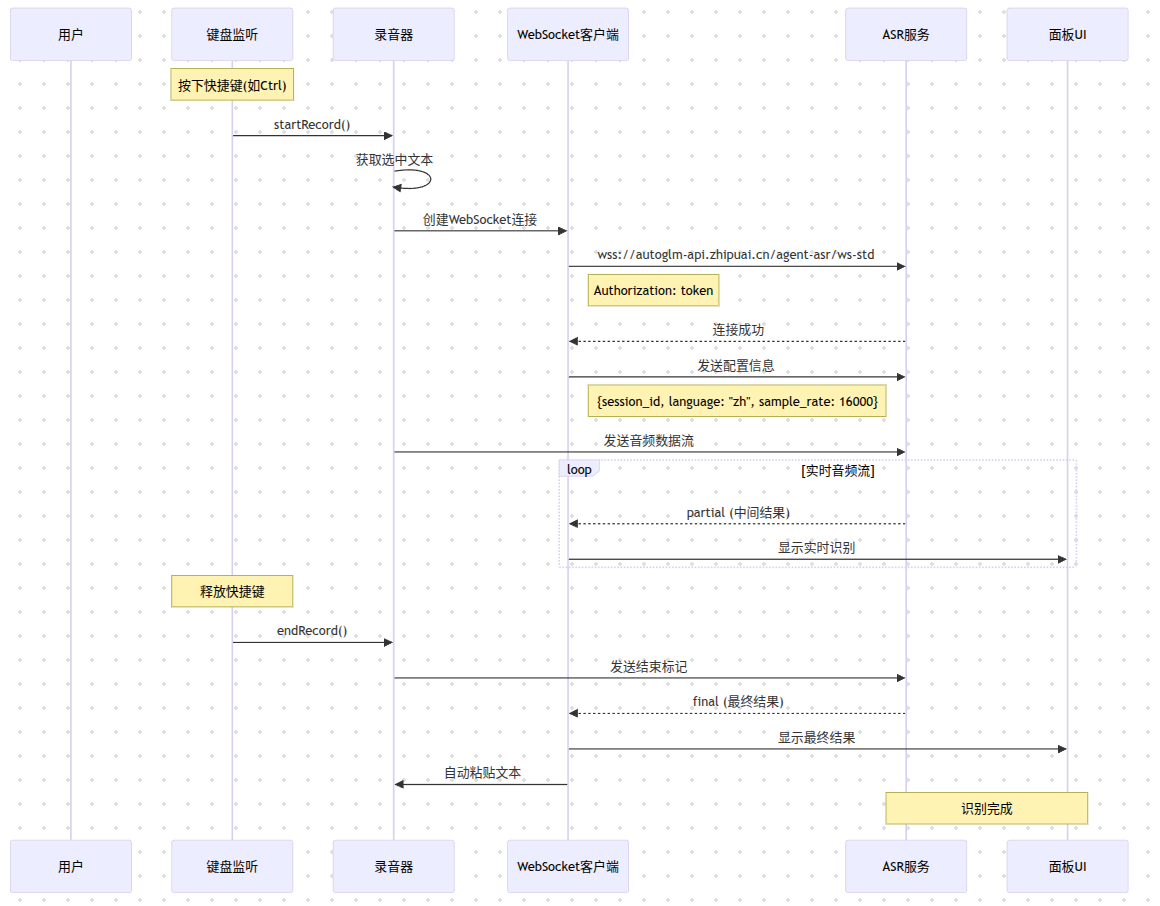
核心代码实现
WebSocket客户端 (`dist-electron/app/api/ws.js`):
GPT plus 代充 只需 145
录音控制器 (`dist-electron/app/contexts/settings/record.js`):
GPT plus 代充 只需 145
ASR技术细节
1. 通信协议:
- WebSocket实时双向通信
- JSON格式数据交换
- 支持心跳保活机制
2. 音频格式:
- 采样率: 16kHz
- 格式: WAV
- 编码: PCM
3. 识别模式:
- : 实时中间结果
- : 最终识别结果
- : 指令模式(语音命令)
4. 错误处理:
- 权限过期提示
- 网络断线重连
- Token自动刷新
流程图
指令构建逻辑
处理模式
模式判断逻辑
GPT plus 代充 只需 145
关键判断依据:是否有选中文本 (`options.selection`)
1. Command模式(指令模式)
触发条件:
- 用户在按下录音快捷键之前或录音过程中选中了文本
工作方式:
- 用户先选中文本(如一段中文)
- 按下录音快捷键(如F6)
- 说出指令(如"翻译成英文"、"总结这段话"、"扩写")
4. 大模型对选中的文本执行语音指令
示例场景:
- 选中文本:"今天天气很好"
- 语音指令:"翻译成英文"
- 结果:"The weather is great today"
prompt_type:`"voice-command"`
处理流程:
2. Polish模式(润色模式)
触发条件:
- 用户没有选中文本
工作方式:
- 用户直接按下录音快捷键(如F6)
- 说出想要表达的内容
3. 大模型对语音识别的文本进行润色和优化
示例场景:
- 语音输入:"呃...今天那个...天气不错"
- 润色后:"今天天气很好"
prompt_type:`"transcript-polish"`
处理流程:
GPT plus 代充 只需 145
两种模式对比
特性
Command模式
Polish模式
触发条件
有选中文本
无选中文本
处理对象
选中的文本
语音识别的文本
功能定位
执行指令
文本润色
应用场景
翻译、总结、扩写等
语音输入优化
prompt_type
voice-command
transcript-polish
结果处理
替换原选中文本
粘贴到光标位置
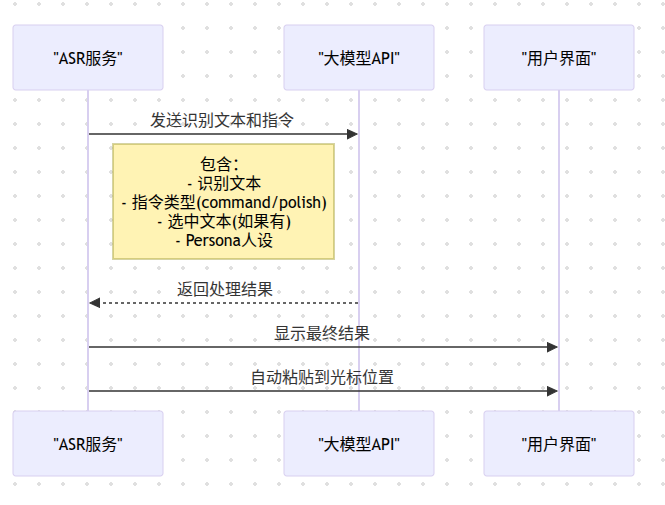
3. Persona人设
- 可自定义AI回复风格
- 支持多个人设切换
- 影响回复的语气和风格
大模型API接口
核心处理接口:
- - 大模型指令处理接口
接口功能:
- 接收ASR识别的文本和指令类型
- 根据不同模式进行处理(Command/Polish)
- 返回处理后的文本结果
请求参数结构:
GPT plus 代充 只需 145
环境配置
主要API列表
端点
方法
描述
POST
手机验证码登录
POST
刷新访问令牌
POST
获取ASR令牌
WebSocket
ASR语音识别
POST
大模型指令处理
POST
获取用户信息
GET
获取识别历史
GET/POST/PUT
人设管理
GET
使用统计
GET
获取应用状态
POST
激活用户账户
GET
获取Banner信息
POST
提交问题反馈
POST
应用内购买
GET
获取钱包信息
GET
获取余额明细
GET/PUT
热词管理
POST
发送验证码
POST
用户注销
数据加密
1. 手机号加密:
GPT plus 代充 只需 145
2. API签名:
GPT plus 代充 只需 145
3. 认证信息:
- App ID:
- App Key: 38de2369a5fb8227d8e6cd5e5
- 用户ID: 从token中解析 (示例: )
- 设备ID: 唯一设备标识符 (示例: ad960c82-70f6-478f-94b1-f00dacf882e1)
4. Token管理:
- 本地加密存储
- 定期自动刷新
- 异常立即失效
存储位置
Windows系统:
- 主目录:
- - 存储token和用户信息
- - 存储用户设置(包括人设配置)
具体路径:
GPT plus 代充 只需 145
存储格式
cache.json文件内容:
GPT plus 代充 只需 145
存储机制实现
使用的库:
- - Electron的持久化存储库
- 基于JSON文件存储,支持加密
代码实现 (`dist-electron/app/store.js`):
Token类型和用途
1. refreshToken:
- 用于刷新access_token
- 有效期较长(从payload看约为30天)
- API调用:
2. token (ASR Token):
- ASR服务的专用token
- 用于WebSocket连接认证
- 有效期较短(约24小时)
- API调用:
3. JWT Payload解析:
GPT plus 代充 只需 145
Token刷新流程
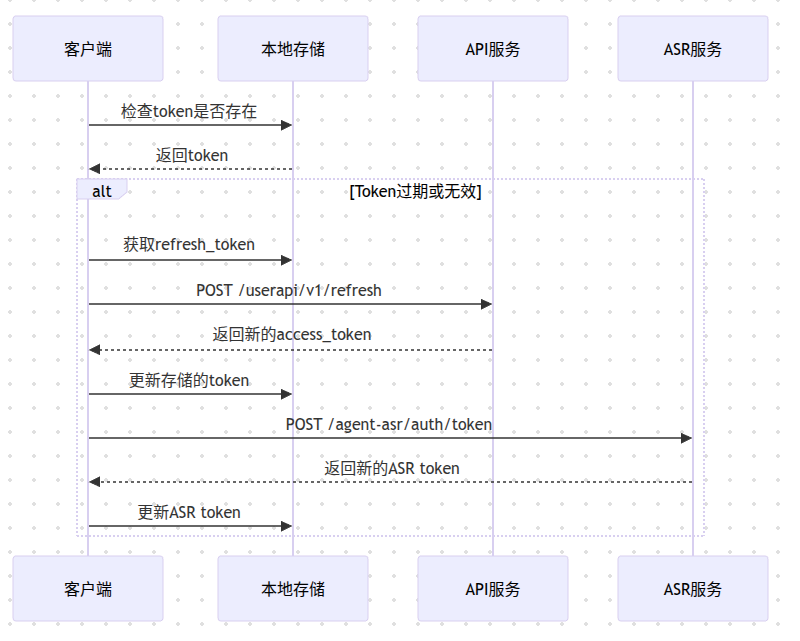
安全机制
1. 文件权限:
- 存储在用户目录下,只有用户本人可访问
- 但文件内容为明文JSON,未加密
2. Token安全:
- Token采用JWT格式
- 使用HMAC-SHA256签名
- 包含过期时间自动失效机制
3. 错误处理:
GPT plus 代充 只需 145
- 全局监听右边Ctrl按键按下状态
- 当右边Ctrl出发按下状态,调用GLM ASR能力实现语音转文字
- 当右边Ctrl出发按下状态
- 角色prompt可配置
- 意图识别使用funcation call功能
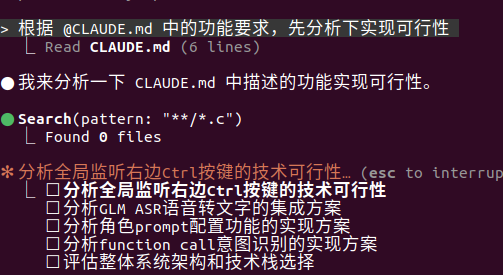
结果方案基本可行
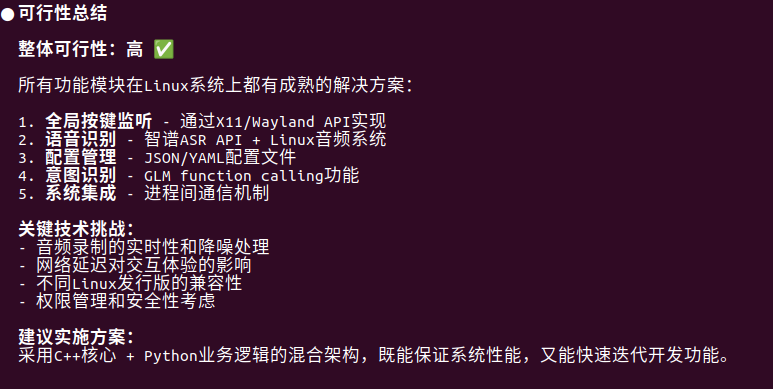
完善设计文档
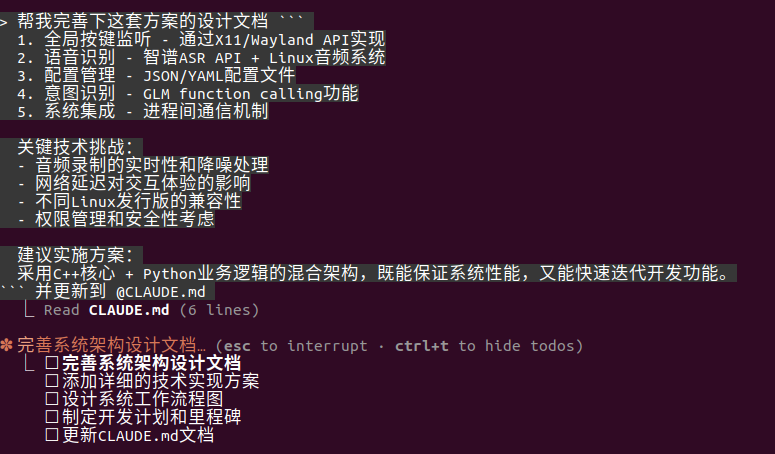
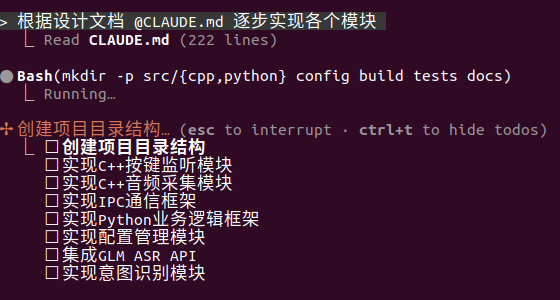
耗时4分钟写完,GLM的速度还是杠杠的快

代码还没看,再让GLM帮我们写个构建脚本
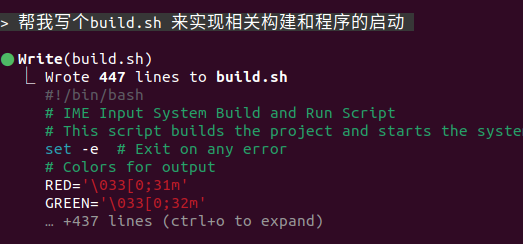
22:17 -- 00:15
耗时约2个小时,不写一行代码,GLM帮我最终实现以下功能,基本上框架是开放的,剩下就是结构化输出调优,代码放到github上了,感兴趣的可以自行下载研究,欢迎提交pull
开源地址
GPT plus 代充 只需 145
成品演示视频
整体体验效果还是满意的,对应测试指令
核心功能
1. 全局按键监听 - 监听右Ctrl键触发语音输入
2. 语音录制 - 采集麦克风音频,支持VAD语音活动检测
3. 语音识别 - 使用智谱ASR将语音转文字
4. 智能处理 - 基于GLM大模型进行意图识别和文本处理
5. 自动输入 - 将处理后的文本自动输入到当前应用程序
智能特性
1. 唤醒词检测 - 支持"小凹"等多个唤醒词变体
2. 多角色模式 - 智能助手、翻译官、程序员、英文助手
3. 意图识别 - 自动识别用户意图并执行相应操作
4. Function Calling - 支持搜索、计算、翻译、执行命令等功能
5. 选中文本处理 - 自动识别并处理用户选中的文本
输入优化
1. 多种输入方式 - 支持xdotool、x11、自动选择
2. 智能粘贴 - 优先使用剪贴板快速输入
3. 应用适配 - 针对终端、浏览器、编辑器等不同应用优化
4. 重复内容清理 - 自动去除识别结果中的重复文本
5. 标点优化 - 基础标点符号自动修正
系统功能
1. 进程间通信 - C++音频采集与Python业务逻辑通过IPC通信
2. 配置管理 - 支持YAML配置文件和热重载
3. 日志记录 - 完整的操作日志和错误追踪
4. 权限管理 - 最小权限原则和安全机制
技术架构
- C++核心模块:按键监听、音频采集、IPC服务
- Python业务逻辑:ASR处理、GLM交互、文本输入管理
- 混合架构设计:兼顾性能与灵活性
- 安全层面上看,cache信息需要加密
- 体验过程中经常出现,意图判断失败,直接ASR结果返回了,这种体验非常差,但凡有1次失败,就不想再尝试了,文字出错还可以修改,语音出错无法修正了。
- 需要有个长期悬浮的窗体,做成可配置的,用来显示最终大模型对话的结果,有的时候只是要问问题,不需要直接帮忙执行
- 改进ASR相应速度,从协议方面分析,还在原生的使用PCM RAW流,数据量大,建议压缩成opus再传输,提升相应速度
- 指令遵从差,建议把正常ASR和命令执行区分开来,可以用是否有说小凹来区分,有小凹表示ASR结果需要提取意图并提交给大模型润色/相应要执行的内容
GPT plus 代充 只需 145<p>小凹,帮我翻译下这段文本</p></li>
<p>今天天气有点晴朗</p></li>
写作不易,若觉有帮助,还望点个赞!拼个好摸!
🚀 速来拼好模,智谱 GLM Coding 超值订阅,邀你一起薅羊毛!Claude Code、Cline 等 10+ 大编程工具无缝支持,“码力”全开,越拼越爽!立即开拼,享限时惊喜价!
链接:https://www.bigmodel.cn/claude-code?ic=YAE08BE9BV
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/216961.html