
gpt好像出了o3,但似乎是更追求效率?
deepseek听说是更专门针对代码编写的,有没有大佬说说体验。
其他大模型也可以讲讲
最好的代码编写AI模型,我觉得应该是不固定的,目前而应该是DeepSeek、GPT、
Qwen、Claude、Gemini中的某一个。
为什么这么说呢?
我们来看几个AI编程能力排行榜,
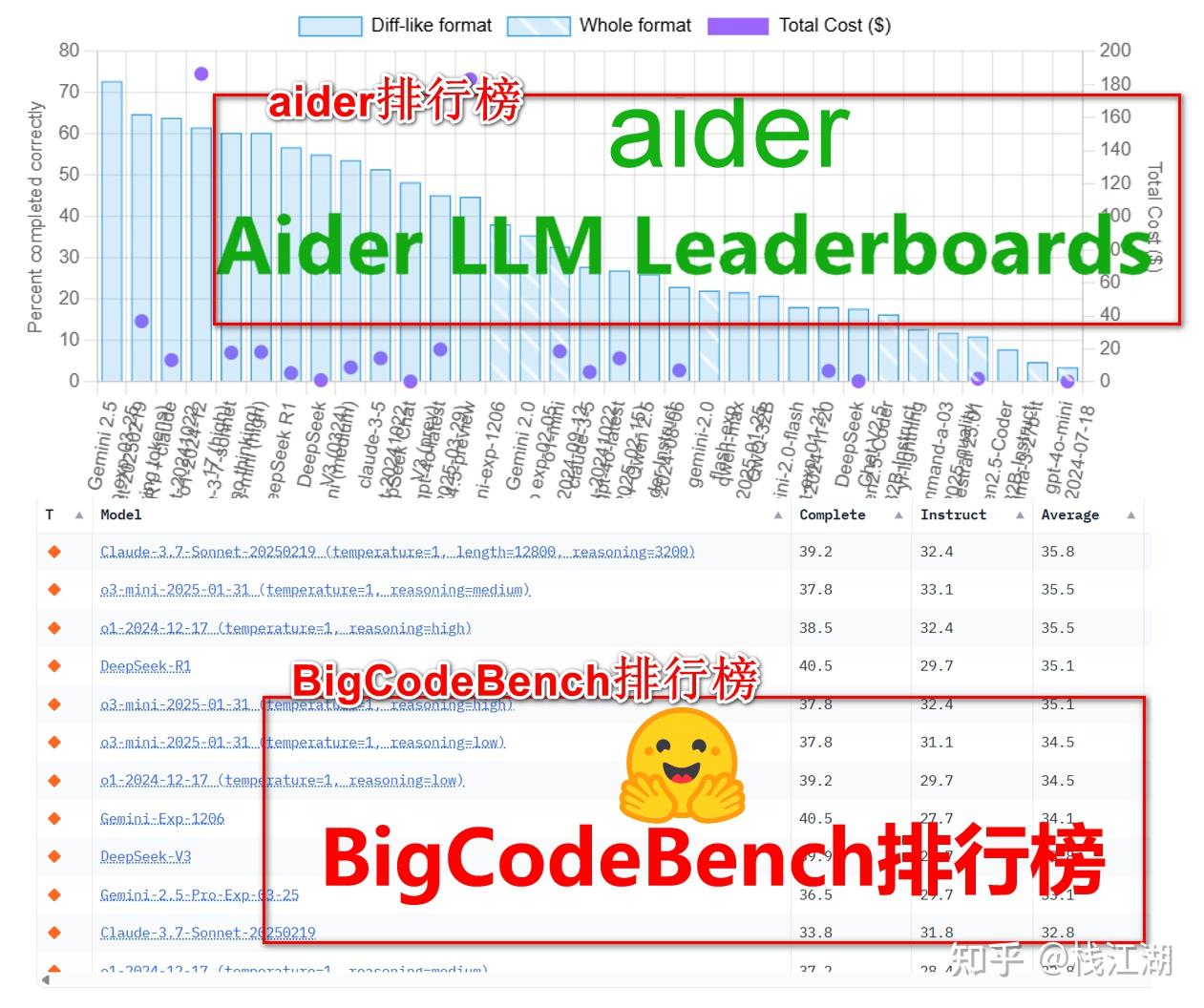
其实这种AI编程能力排行榜还很多,这里只是选择了huggingface和aider网站上的排行榜。我们可以发现他们两者的结果并不一样,另外翻看这两个网站的历史排行榜也会发现前后也是不一样的,也就是说这个排行榜是在变的。
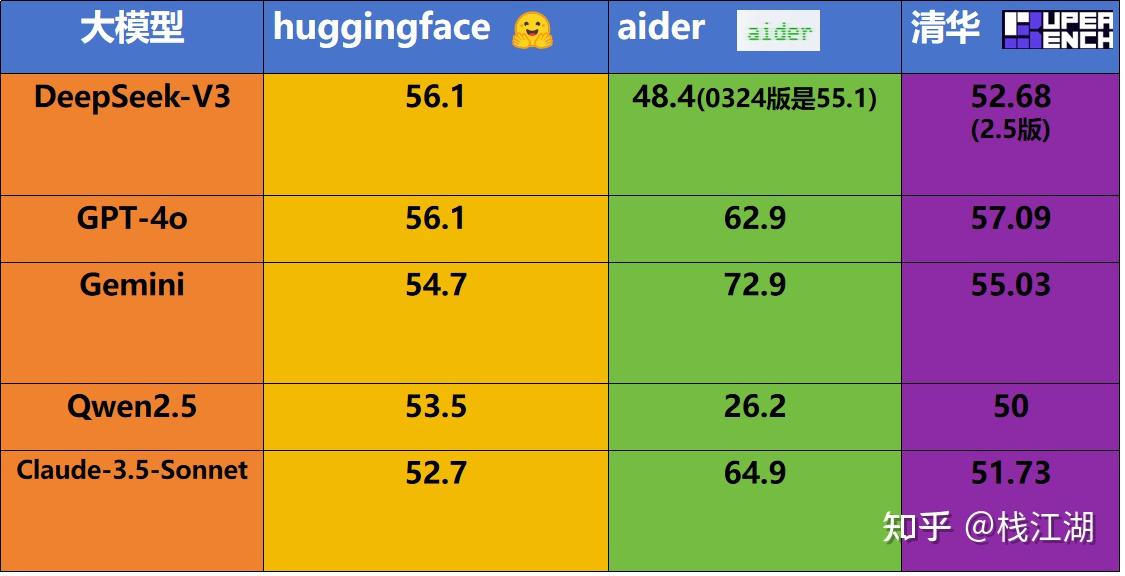
比如,huggingface的BigCodeBench、aider的Aider LLM Leaderboards及清华大学的SuperBench。数据都不太一样,当然清华大学的是2024年11月的榜deepseek还是2.5的版本,但整体的数据还是相差不少。不过也能说明一个问题就是现阶段全球比较顶尖的AI模型中在编程能力方面比较优秀的就是DeepSeek、Claude、Gemini及Qwen这些了。
那么具体如何,我们可以来实操体验一下。
要对比首先,我们需要选择一款AI编程的开发工具。
目前AI编程开发工具有两种模式:一种是AI原生IDE,另一种是插件式AI编程工具。
AI原生的IDE目前市场上推出来的并不多,但还是非常火爆的。比如在B站被称为AI编程神器的Cursor,当然咱们国内字节也推出了MarsCode IDE。
磨刀不误砍柴工,我们先来看看AI编程工具:
Cursor是国外一家公司在2023年发布的一款AI原生的IDE,主要功能就是通过AI能力自动检索理解代码的上下文、可以自动编写并运行终端命令、可以自动检测并修正代码、具有强大的自动补全代码的能力,当然强大的聊天功能也是它基本的功能。
在设置页面可以设置选择AI大语言模式
MarsCode 是豆包旗下的AI智能编程工具,它分为网页版和编程插件。提供以智能代码补全为代表的核心能力,能在编码过程中提供单行或整个函数的建议,同时支持在用户编码过程中提供代码解释、单测生成、问题修复、技术问答等辅助功能,提升编码效率与质量。
最近收到Marscode网页版2025年4月15日正式下线的通知,当然它并不是停止开发了而是把编程产品转到另一款AI原生IDE Trae,通知里说后续字节将聚焦资源优化本地IDE(Trae)与插件(MarsCode 编程助手)服务。早期Trae是说针对国外市场而MarCdoe是针对国内市场现在应该是合并了,不过还是不影响我们的使用。
这是MarsCode IDE的效果图:
这是Trae的效果
基本上上面提到的AI模型Trae都是支持的。
相比AI原生IDE,插件式AI编程工具就非常的多,并且在AI火爆后就出来很多AI编程插件。

下面我们来看看目前Intellij与Visual Studio Code插件市场相关AI辅助编程插件的下载量情况:
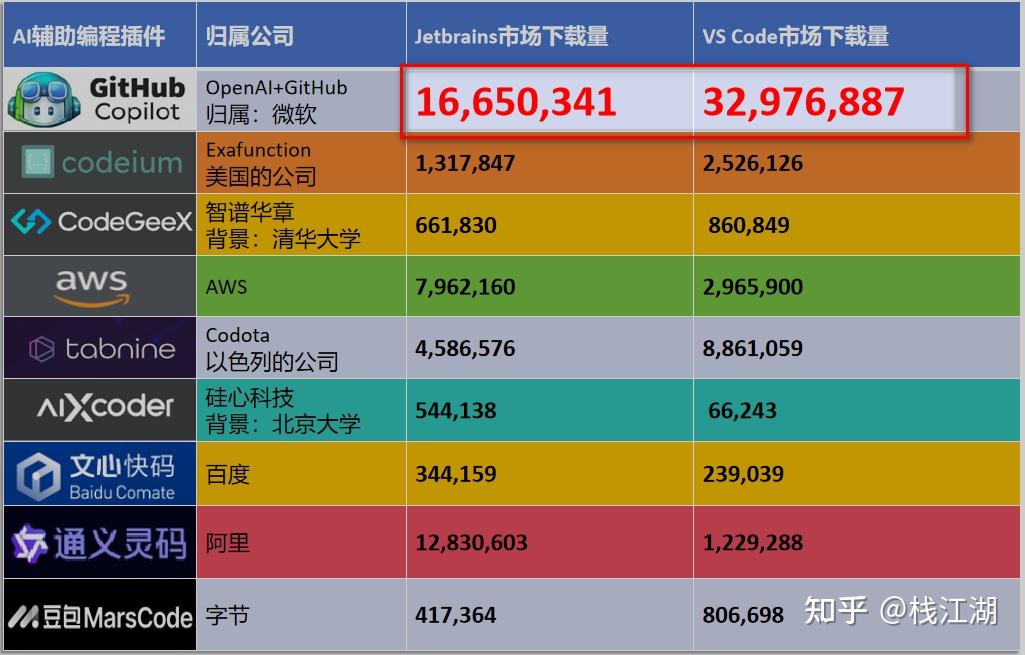
p.s.以上的下载量只是plugins.jetbrains的marketplace数据,发布的时长也不相同,数据仅供参考。
基本AI编程工具的功能都差不多:
- 代码补全:根据当前代码上下文自动补全代码。
- 根据注释生成代码:根据注释描述生成相应的代码。
- 方法和函数生成:根据方法名或函数名自动生成该方法或函数的代码。
- 生成测试代码:生成测试代码。
- 自动优化代码、异常解决、代码生成….
功能还是非常多的,AI编程和AI程序员刚出来那会谈论最多的是AI代替程序员,而现在谈论更多的是AI如何辅助和提交程序员编程。如果你已经使用上了AI辅助编程我想你一定会感觉AI带来的便利。
身处这样的技术浪潮中的我们,以其担心AI替代我们,还不如好好利用。毕竟明天AI替代我们是未知的,但明天能替代我们的一定是会AI的人。
而解决这个问题根源的唯一办法就是学习,相比网上高额的付费课,这里有个知乎知学堂的大模型应用公开课是免费送的。这门课里,你能掌握前沿 AI 技术,熟悉大模型架构,获得实战项目经验。课程还会详细剖析大模型应用开发的各种知识,像揭秘知乎直答底层原理、解析 DeepSeek 核心技术等。
目前还在活动期,不知道啥时候结束,建议先报名占坑:↓↓↓
满满的AI干货,听了不亏,还可以领取丰富的资料。
这里就选择使用字节的Trae来体验一下,几款AI大模型的编程能力。
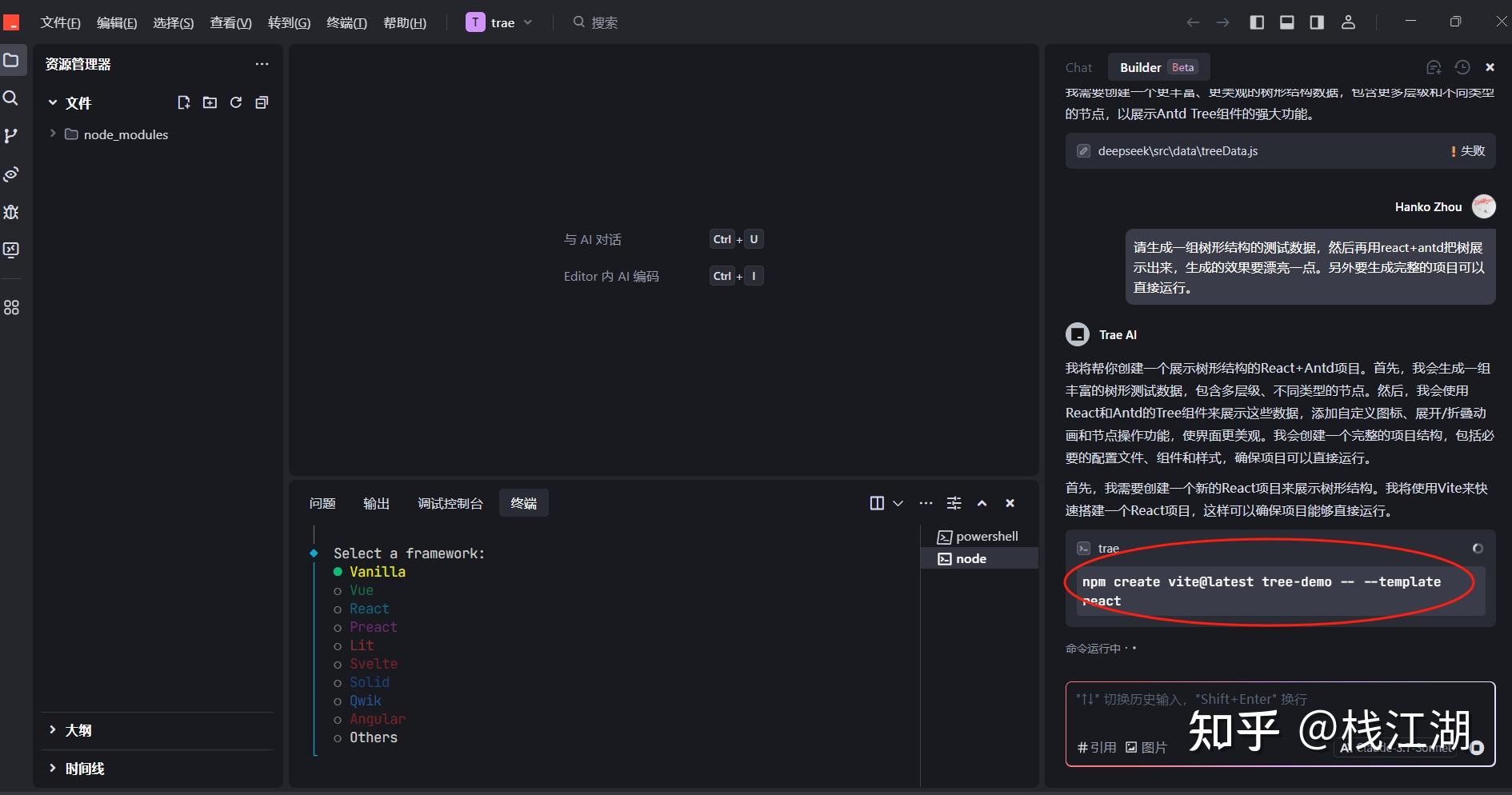
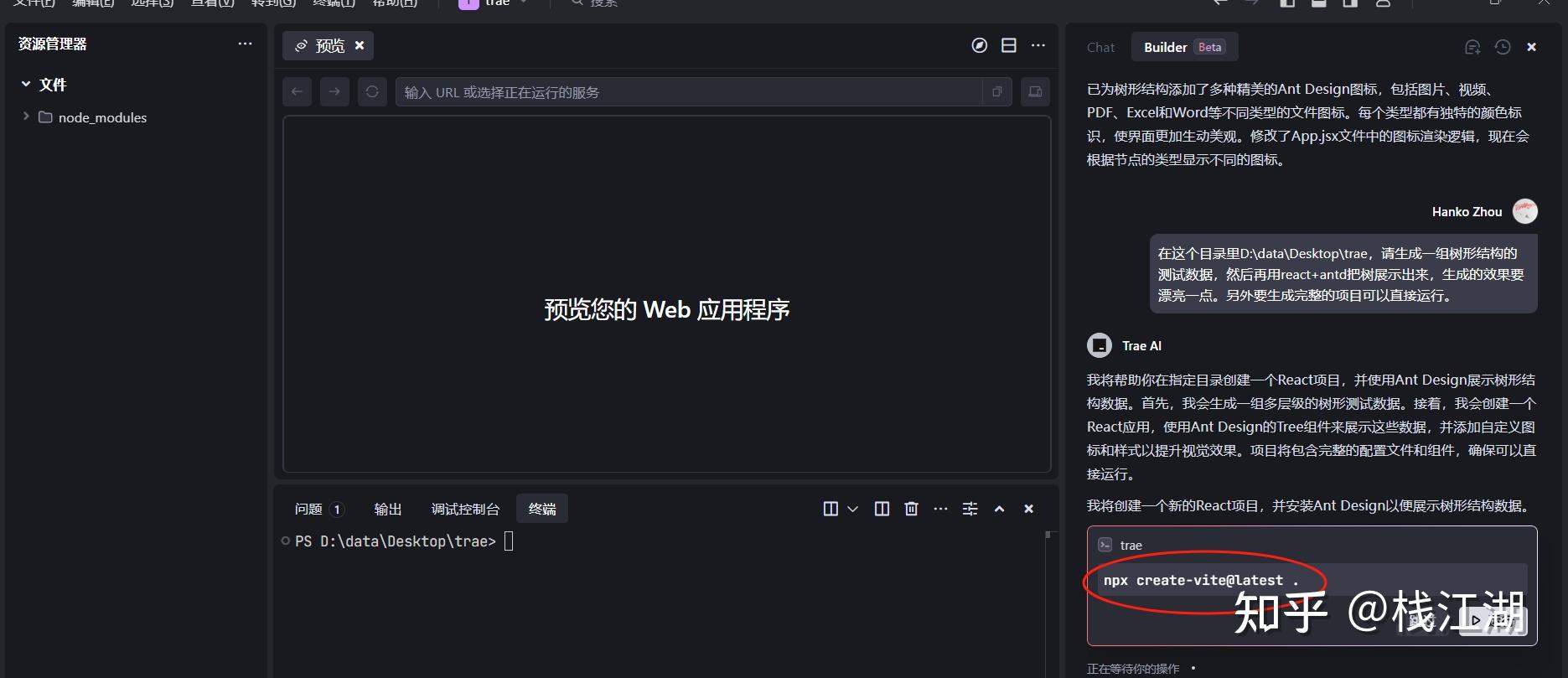
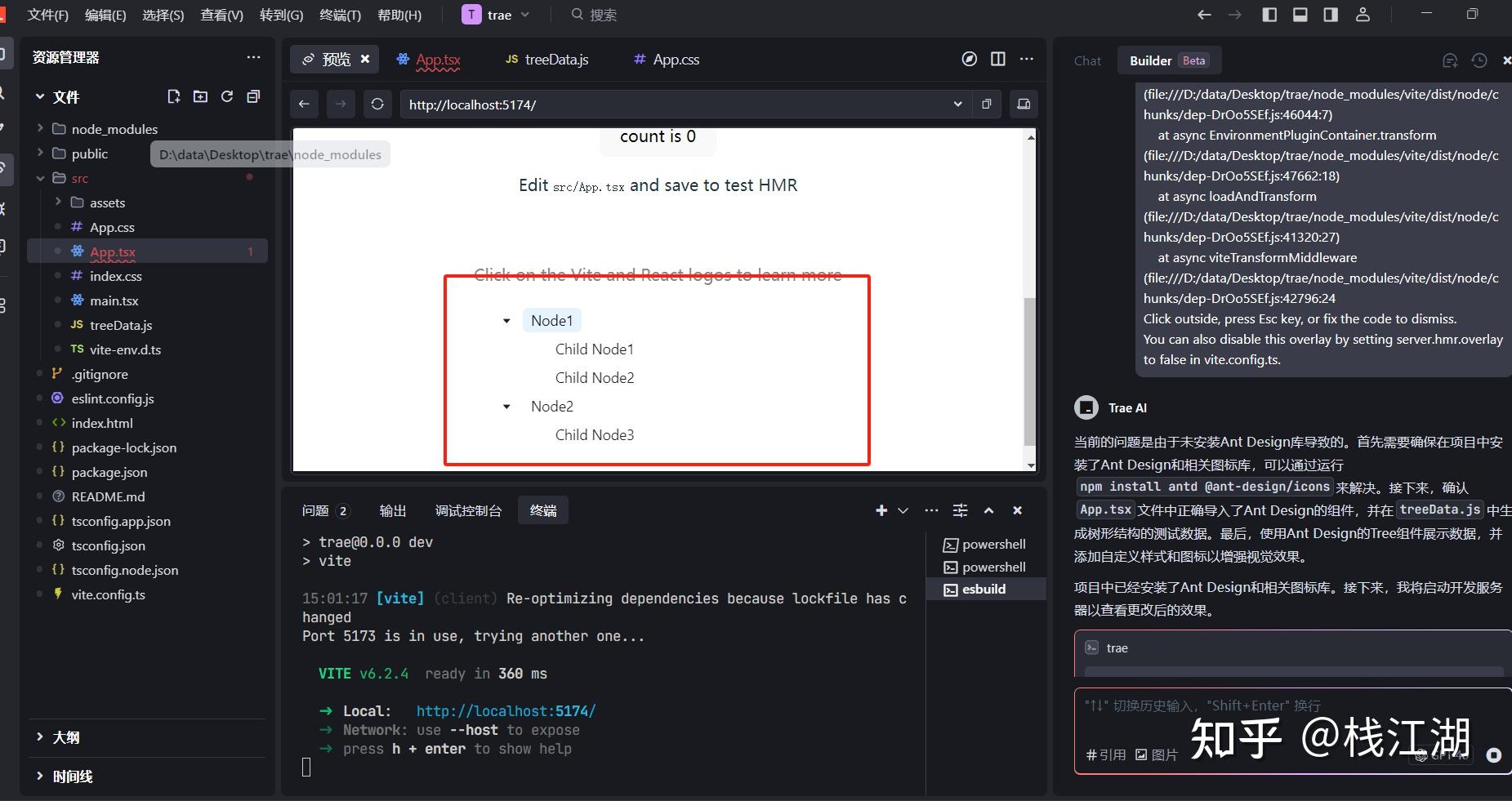
请生成一组树形结构的测试数据,然后再用react+antd把树展示出来,生成的效果要漂亮一点。另外要生成完整的项目可以直接运行。
- DeepSeek-V3-0324
2025年初最大的一个炸弹非deepseek莫属,deepseek-r1发布后风靡全球。而在3月24日deepseek又发布了deepseek-v3-0324版本,这个版本除了拥有deepseek-r1的部分深度思考能力又不需要深度思考的时间外,它还在前端的编码能力方面有增强。下面我们来具体试试:
deepseek是直接生成相应的代码
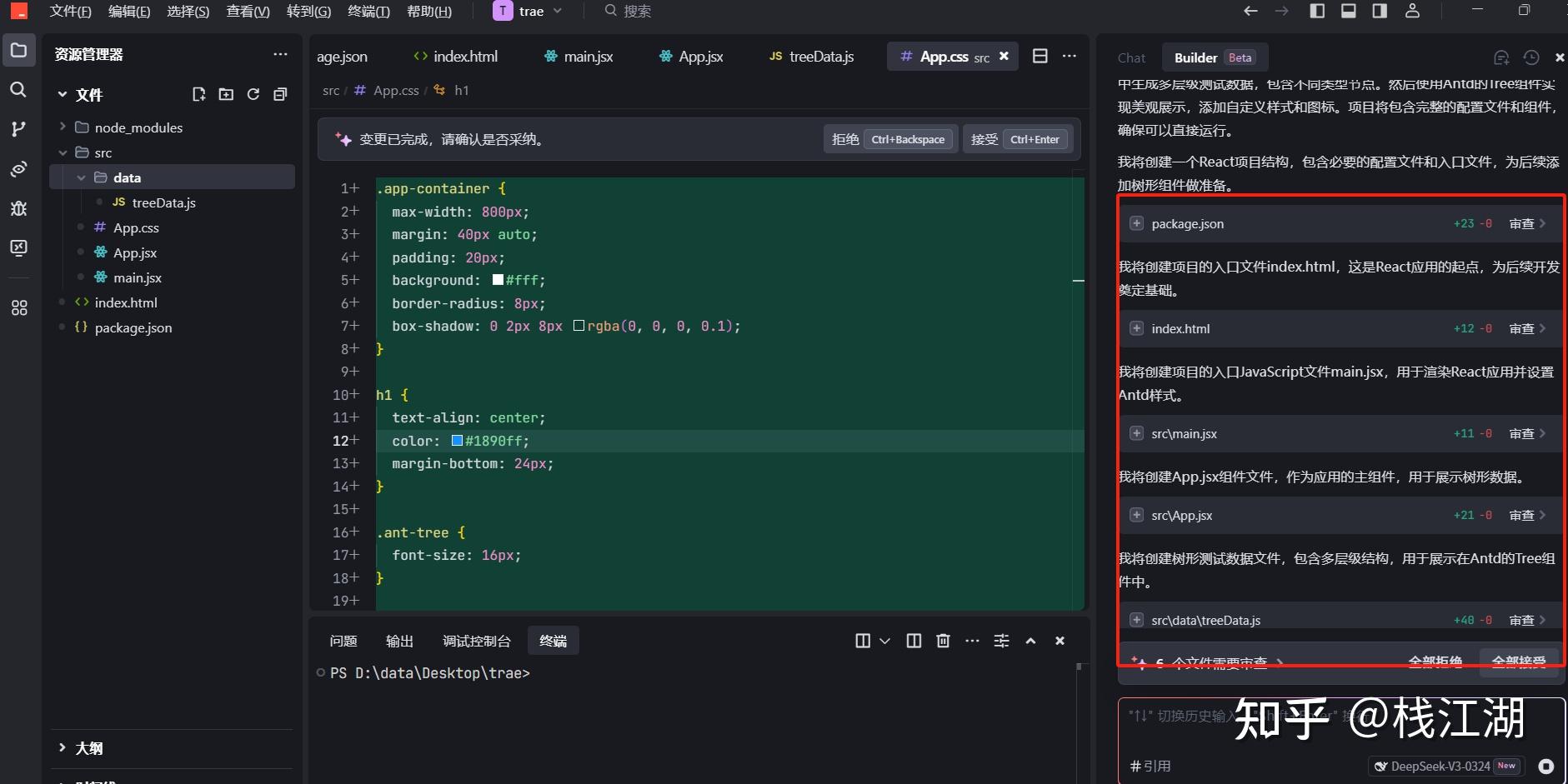
可能是deepseek没有先生成项目所以会缺少文件,然后运行后就会报错
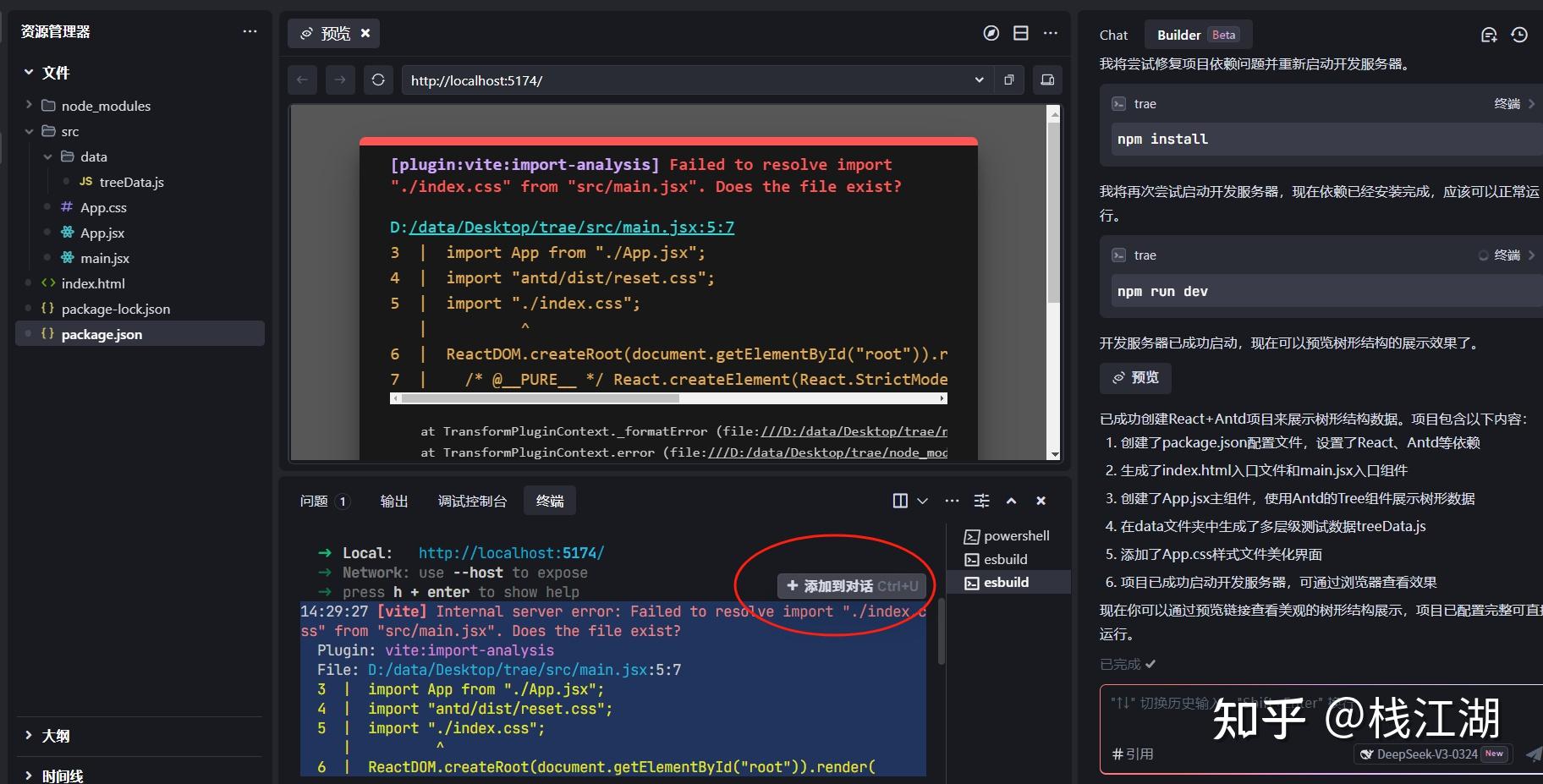
选中异常信息后,可以点击“添加到对话” 直接在对话中提交就会生成解决办法
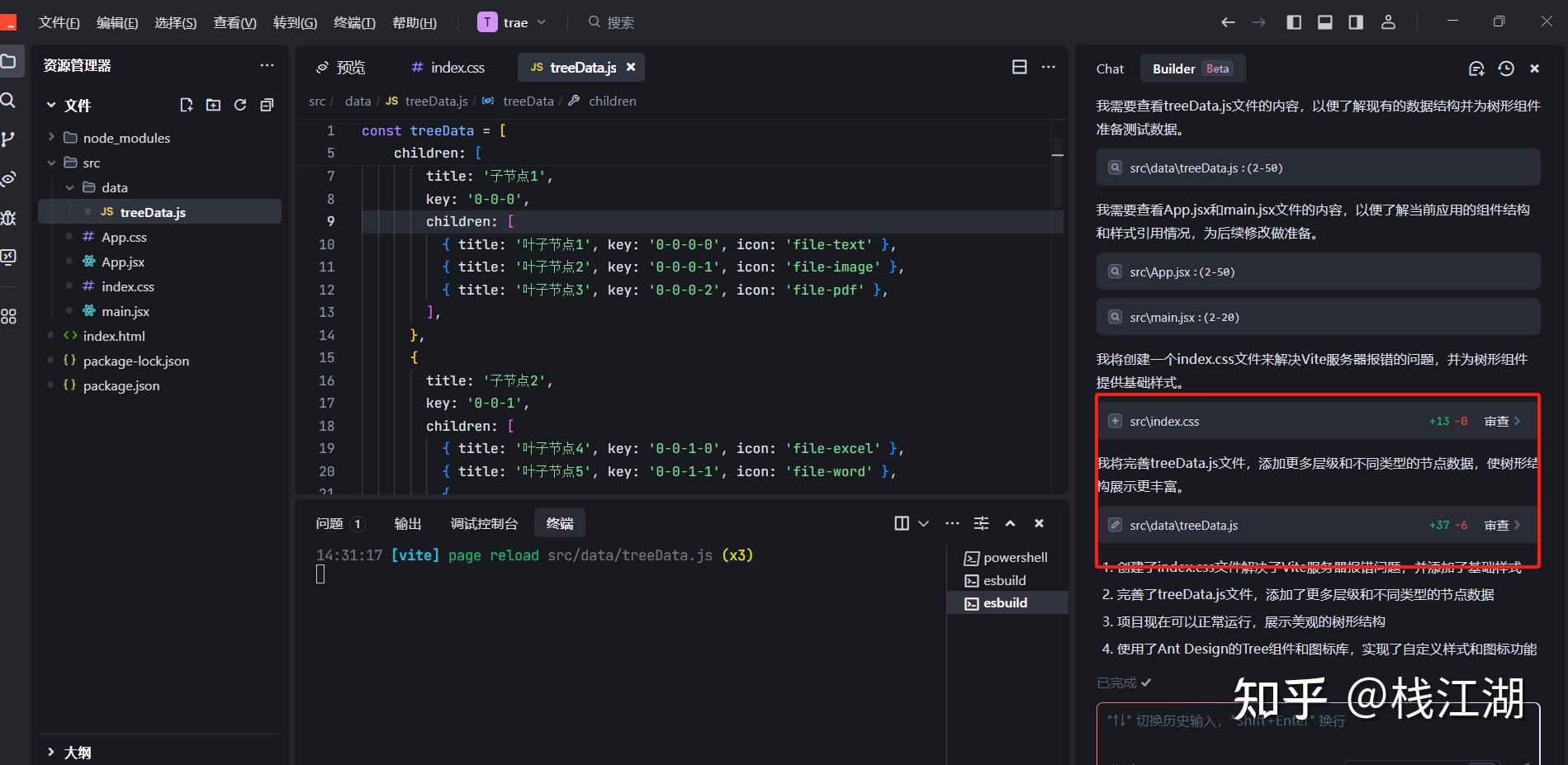
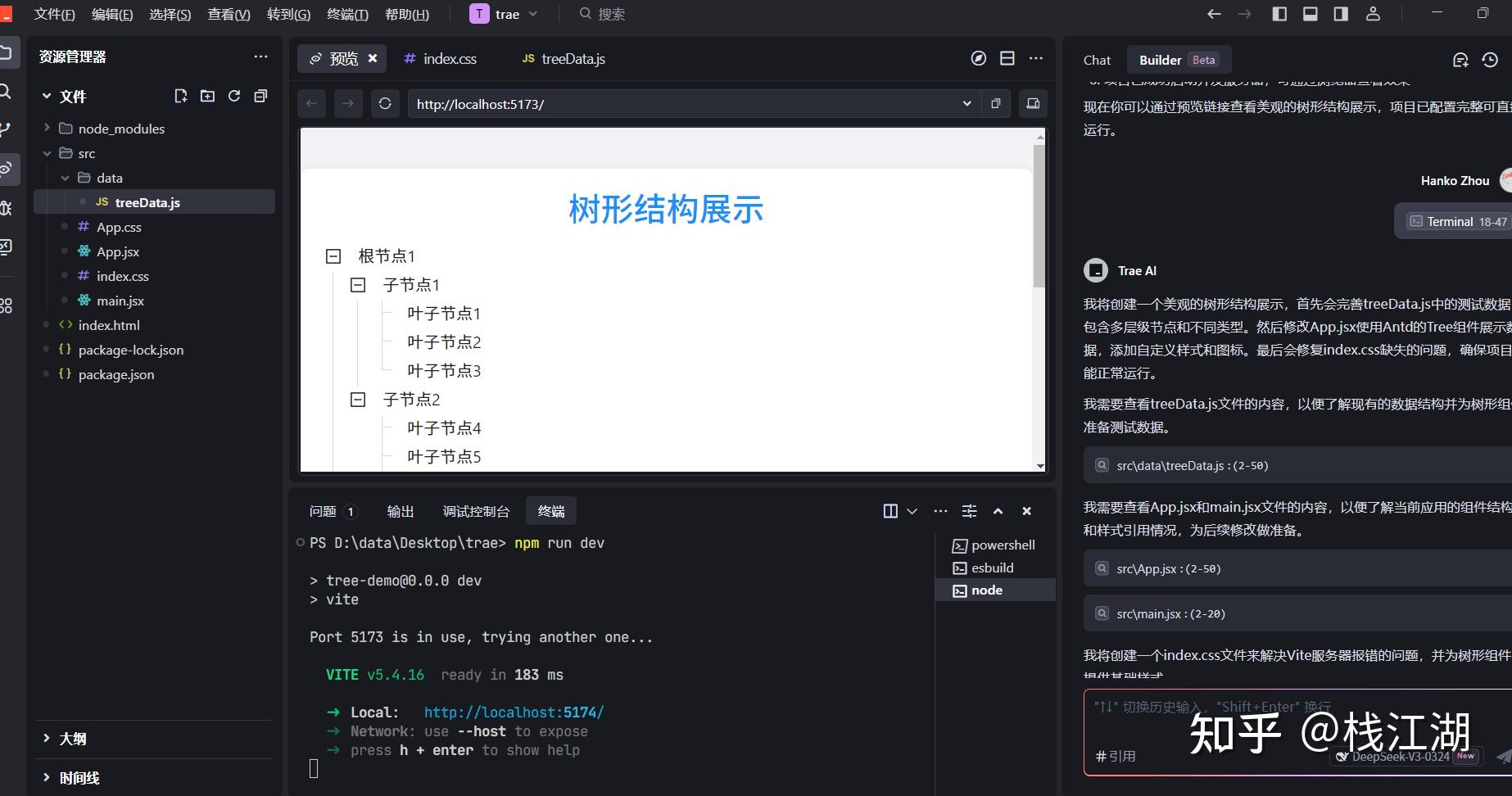
这里已经生成好了缺少的文件,直接再次运行,这就是生成的效果
2.Claude-3.7-sonnet
claude是由gpt离职员工出来后开发的,推出后一直和gpt是并肩的。到后来还有超出gpt的样子。现在claude的火热程度并不逊色于gpt。
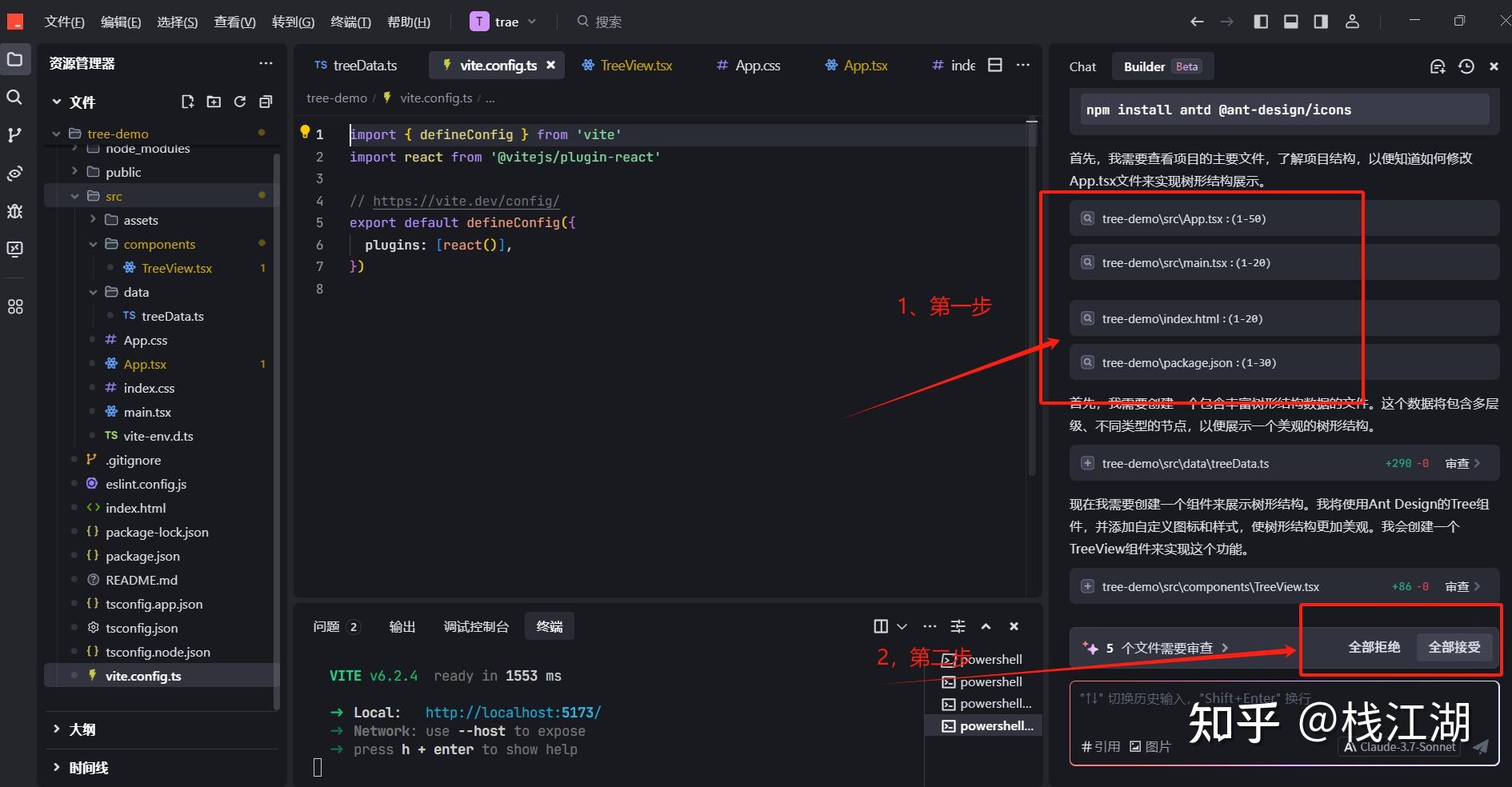
第一步会先生成react的模板项目
然后,生成相应的组件代码同时在右下角会出现“全部接受”的按钮,点击后代码就会自动生成到当前的文件夹里,并且文件是按react模板的目录存放。
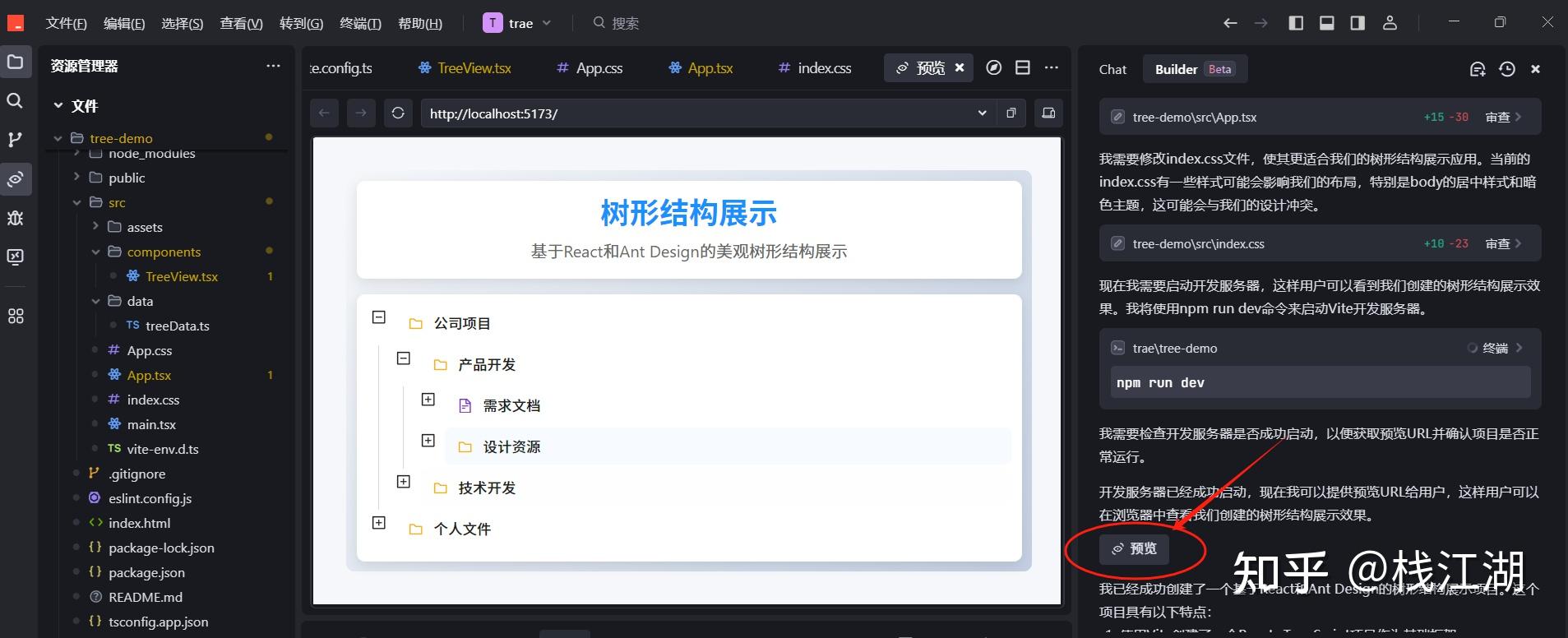
效果
点击预览,就会启动项目,并且trae内置了浏览器可以直接展示运行后的效果。代码完全没有报错,并且代码非常的工整。
3.GPT-4o
2022年11月GPT引发了AI变革,一场轰轰烈烈的AI革命就发生了。GPT的地位及在编程方面的能力也是非常突出的,当时GPT发布时通过手绘的草图然后发给AI,AI就能生成可以运行的网页。
来看看GPT也是通过模板先生成项目
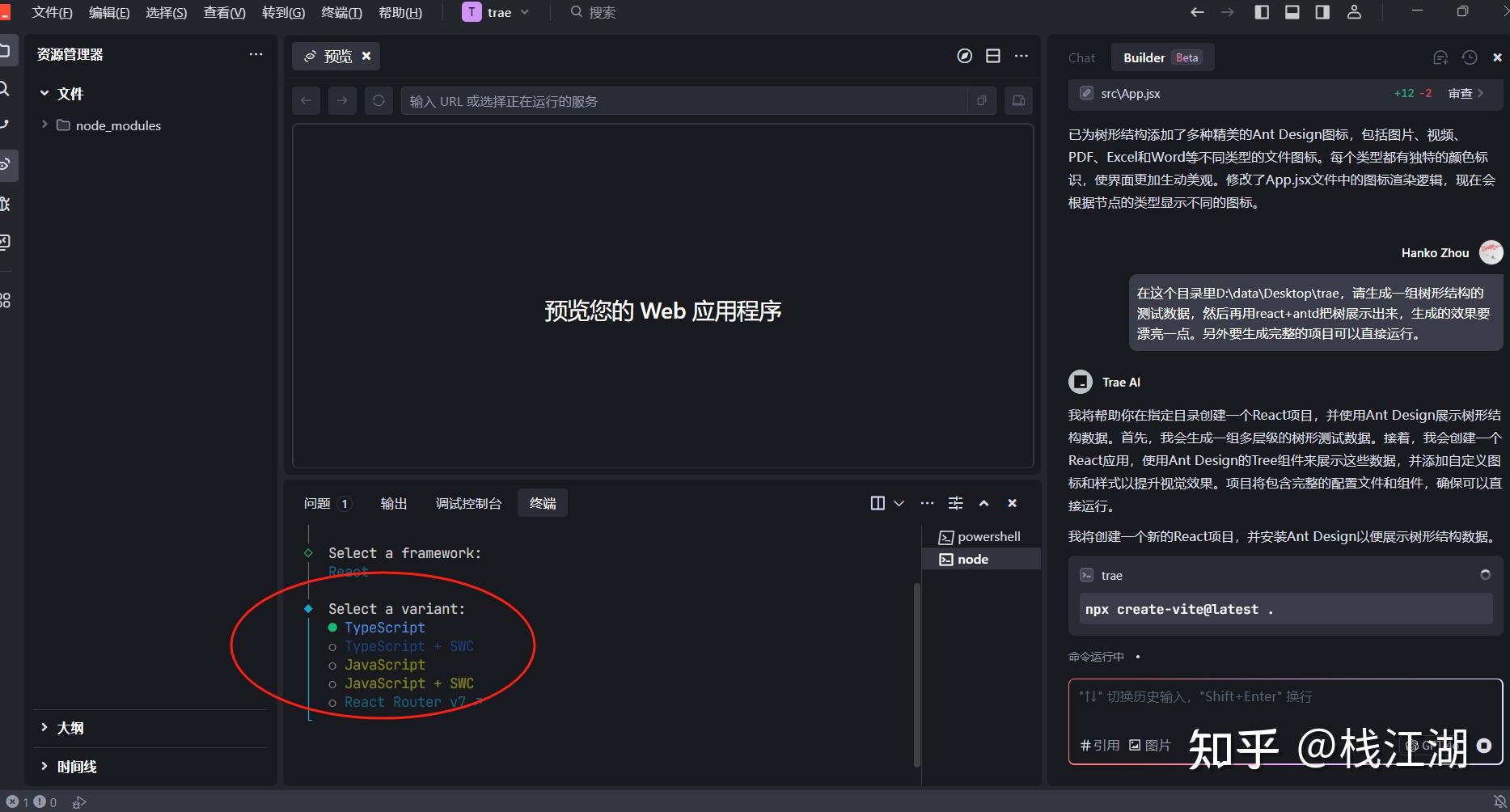
这里要人式选择一些参数
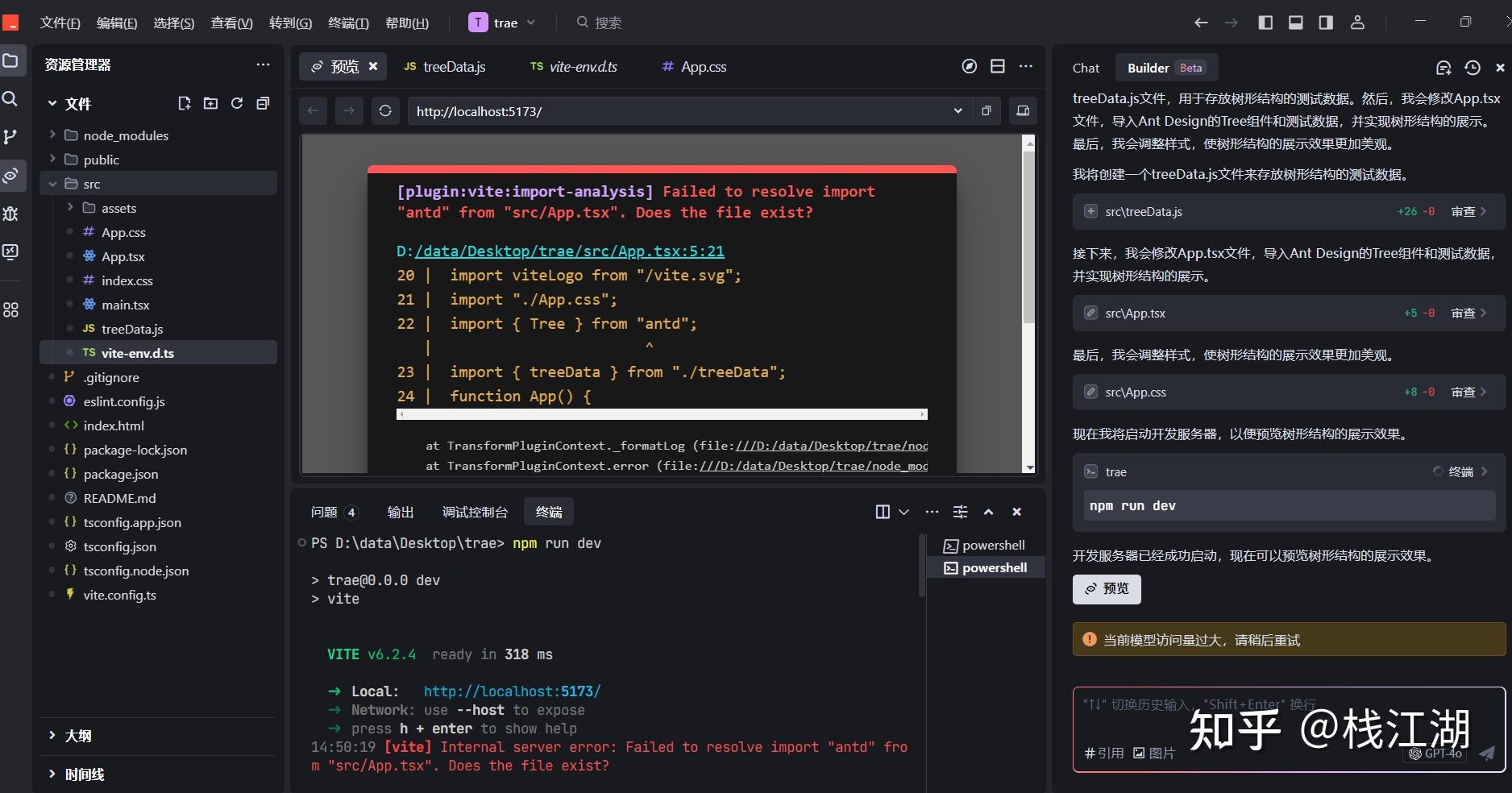
然后一下步,这里也报缺少文件的错,然后还缺少了让我执行
npm install antd @ant-design/icons
命令的错
最后出来了,可能它误解了漂亮两个字的定义
4.Gemini
gemini是谷歌的AI产品早期叫Bard后来统一成Gemini。我们知道生成式AI大模型基本上都有谷歌Transformer的影子,谷歌在AI领域也是居功至伟。
gemini也是先创建react项目
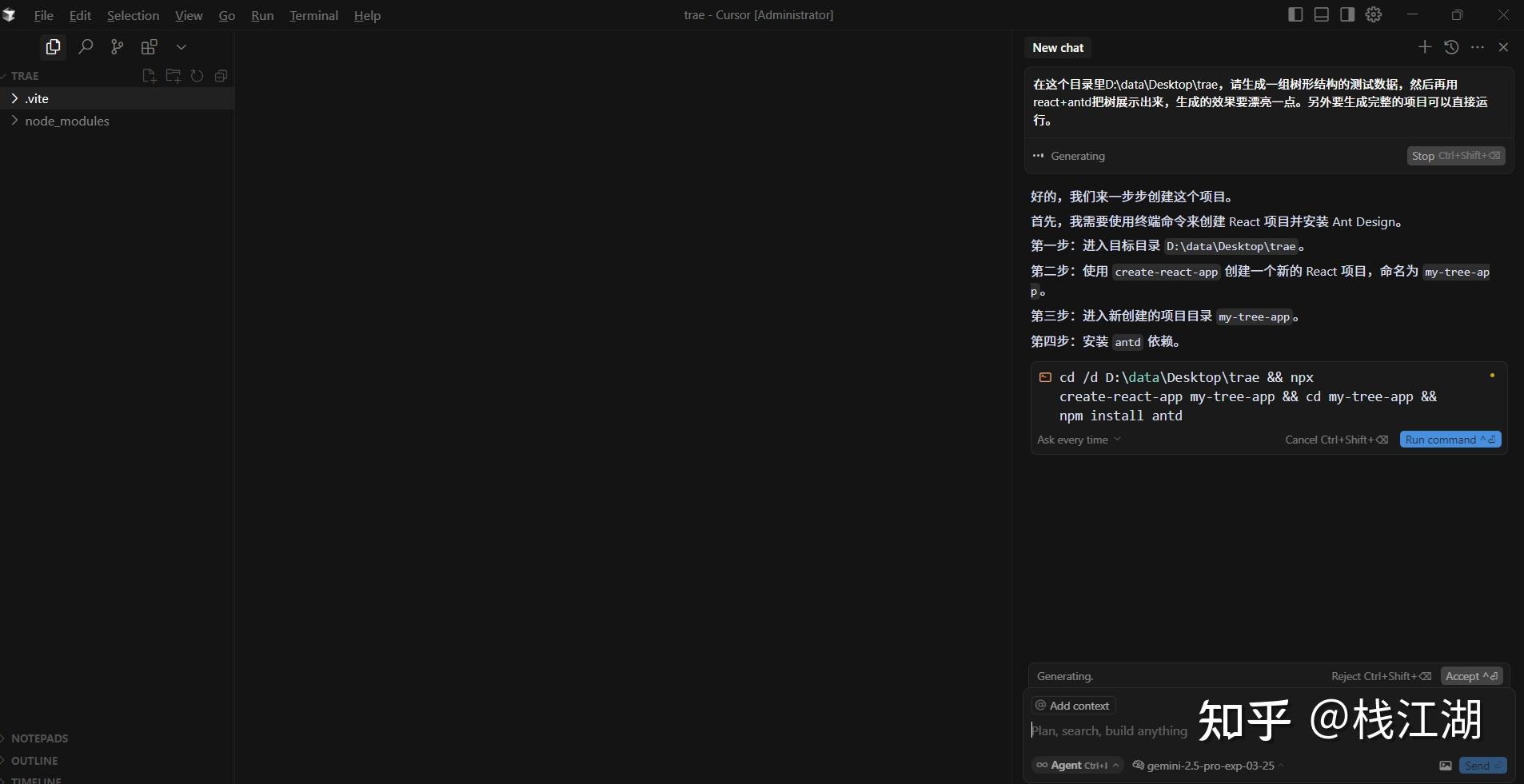
然后报了一些错,最后的效果
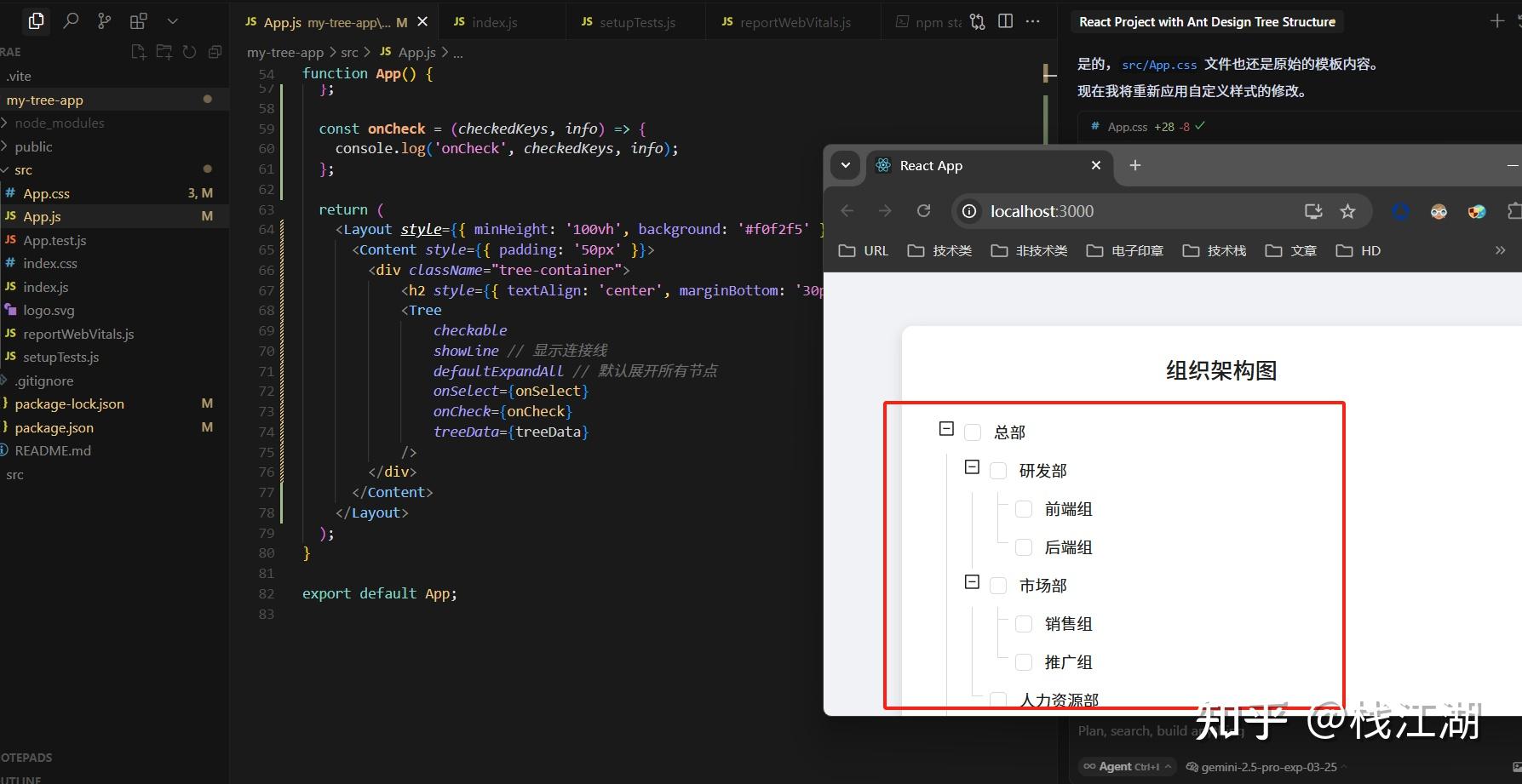
代码风格上gemini和claude还是很不错的。
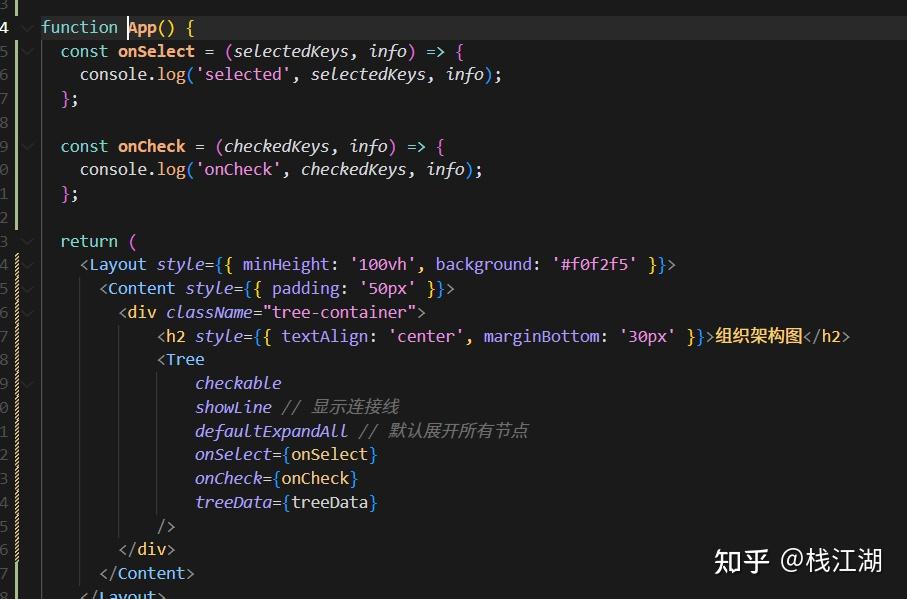
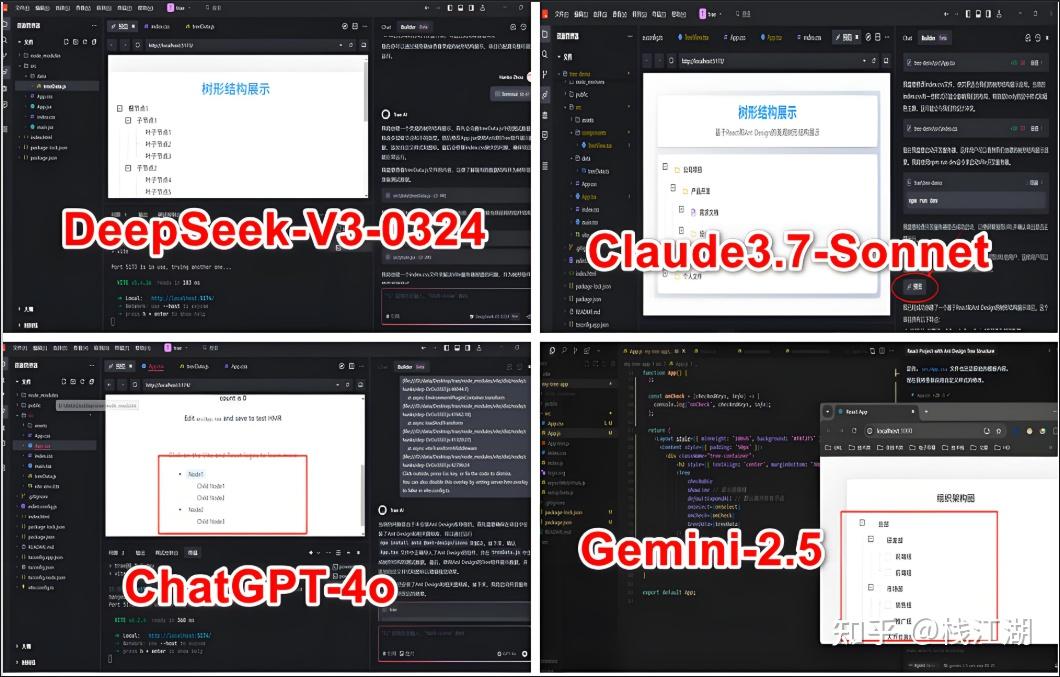
总的来说从代码生成、到代码风格、再到代码可执行方面这几款都还不错。至少现在AI生成的代码基本上是可以直接执行或使用的,更关键的是它可以关联文件夹里的所有文件,即使代码存在问题它可以进一步的完善。AI已经成为程序员一个非常大的助力,如果非要从这些里面选择最好的一个个人感觉是Claude,如果国内使用不佳的话那就是DeepSeek,当然随着时间的变化后面是哪个又是个未知的结果。
OpenRouter是一个卖API服务的中间商,每天卖出去的Token数量很客观,它自己做了一个排行榜,就是针对于不同用途的大模型使用量排序。
你看这周的排行,Claude 3.7 sonnet排名第一,2-4名是Google的Gemini模型。
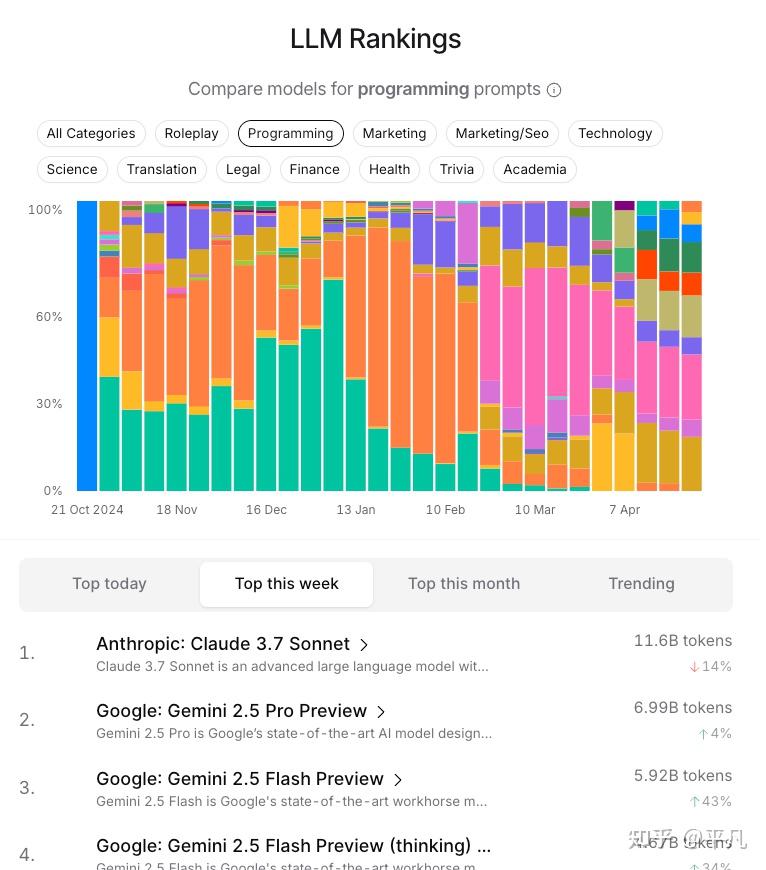
你再细看4月28号的用量,Claude3.7毫无疑问的最强者,但是Google的Gemini 2.5已经追上来了。
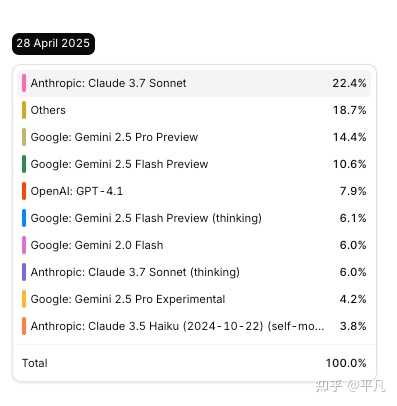
特别是今年年初的时候,Claude系列几乎能占到编程API使用量的85%,其他的所有模型都不够看。

最近的趋势就是Claude 3.7的确好用,但是Google的Gemini-2.5系列追赶势头很猛。
另一个维度就是你看AI编程软件最推荐你用什么模型,比如字节的Trae,你点卡它的海外版本,最前面的两个是Claude的模型,后面依此是Gemini,GPT以及DeepSeek,基本上也是性能排行榜。
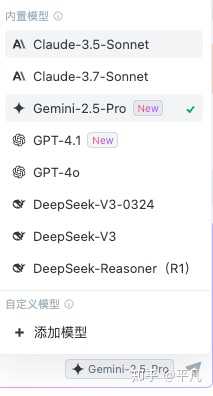
并且经过实测,Claude3.7的确好用,但是用的人比较多,容易卡,可以Claude3.5和3.7换着用。
不过这几个模型有个缺点,那就是很难再国内使用,因为各种访问限制,这种情况的话,Qwen3的235B模型,DeepSeek R1和升级版的V3,都是不错的选择。
建议你看看专栏第三节内容,写代码对于Prompt的精准度要求不低。
https://www. zhihu.com/column/c_1868 3872在代码编写方面,当前主流大模型各有特点,以下是综合对比及推荐建议:
- GPT-4⁄3.5(OpenAI)
- 优势:代码生成质量高、逻辑推理能力强,支持复杂算法实现和跨语言转换(如自然语言转代码)。擅长解决抽象问题,API生态完善。
- 不足:需付费使用,长上下文处理较弱(GPT-4 Turbo支持128k但价格较高),国内访问受限。
- 典型场景:算法设计、代码解释、全栈开发辅助。
- DeepSeek-Coder(深度求索)
- 亮点:
- 开源版本(33B/7B)支持16k-128k上下文,可处理完整项目代码
- 代码填充(Fill-in-the-middle)能力突出,适合IDE实时补全
- 中英双语优化,中文注释生成更准确
- 数学推理能力在代码模型中领先(HumanEval得分超GPT-3.5)
- 实测体验:项目级代码维护表现出色,函数级生成准确率约75%,支持130+语言,适合长期编程辅助。
- Claude 3(Anthropic)
- 优势:200k上下文窗口,适合分析大型代码库,文档生成质量高,复杂需求理解准确。
- 注意点:代码生成风格偏保守,创新性略逊于GPT-4。
- CodeLlama(Meta)
- 特点:完全开源(商用友好),支持34编程语言,Python专项版优化明显,适合本地部署。
- 局限:基础版70B参数以下模型逻辑推理能力较弱。
- 国内模型(通义灵码/文心一言)
- 优势:中文需求理解更精准,深度集成阿里云/百度生态,适合企业级开发。
- 现状:闭源模型能力接近GPT-3.5水平,开源生态待完善。
| 模型 | Pass@1得分 | 上下文长度 | 数学推理(MATH) |
|---|---|---|---|
| GPT-4 | 82.3% | 128k | 42.5% |
| DeepSeek-Coder-33B | 78.7% | 128k | 35.2% |
| Claude 3 Sonnet | 73.2% | 200k | 30.1% |
| CodeLlama-70B | 67.8% | 16k | 15.7% |
- 企业级开发:GPT-4(预算充足) + 通义灵码(中文场景)
- 个人开发者:
- 效率优先:DeepSeek-Coder(VSCode插件+API免费额度)
- 隐私敏感:CodeLlama-70B + 本地部署
- 学生/研究者:
- 算法题:GPT-4 > DeepSeek-Coder
- 项目开发:Claude 3(长上下文分析)
- 代码模型专用化:2024年新模型普遍采用扩展上下文(≥128k)+ 代码填充架构
- 多模态融合:GPT-4V等模型开始支持UI设计图转代码
- 本地化部署:Qwen-72B等国产模型显存优化显著(8卡可部署)
建议结合具体需求试用:DeepSeek-Coder适合长期编码伙伴,GPT-4应对复杂问题,Claude处理遗留系统改造,开源模型满足定制需求。实际开发中推荐组合使用,通过CI/CD流水线实现AI代码质量验证。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/215361.html