
最近好火啊,体验了技术同事的小龙虾🦞,真是厉害,但是我是市场部门不会代码🥲有没有啥一键本地部署的方法啊?求大佬们指点
有,而且就是为你这种情况准备的。
先说结论:getaclaw.ai,下载安装包,双击,跟着中文引导走,15分钟装好,不需要懂任何代码。
以下是简单的安装过程∶
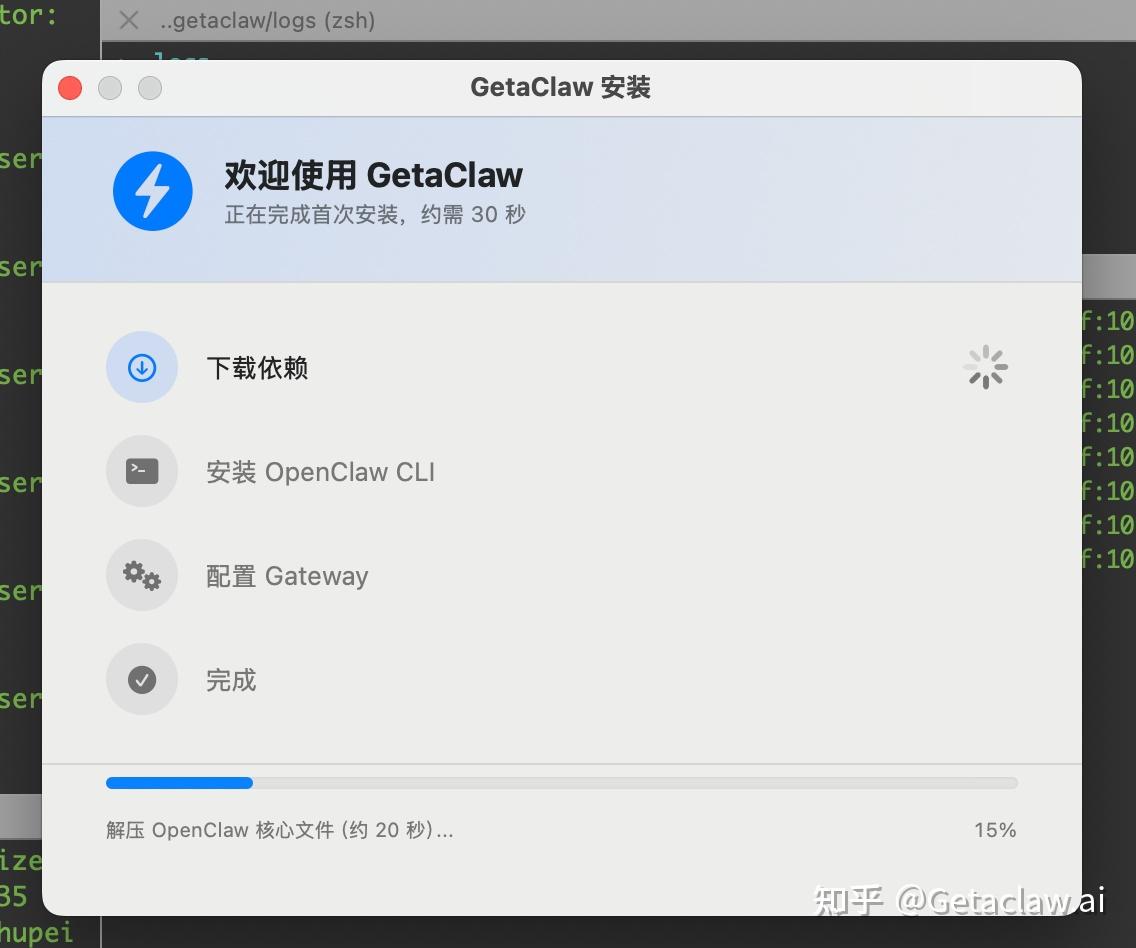
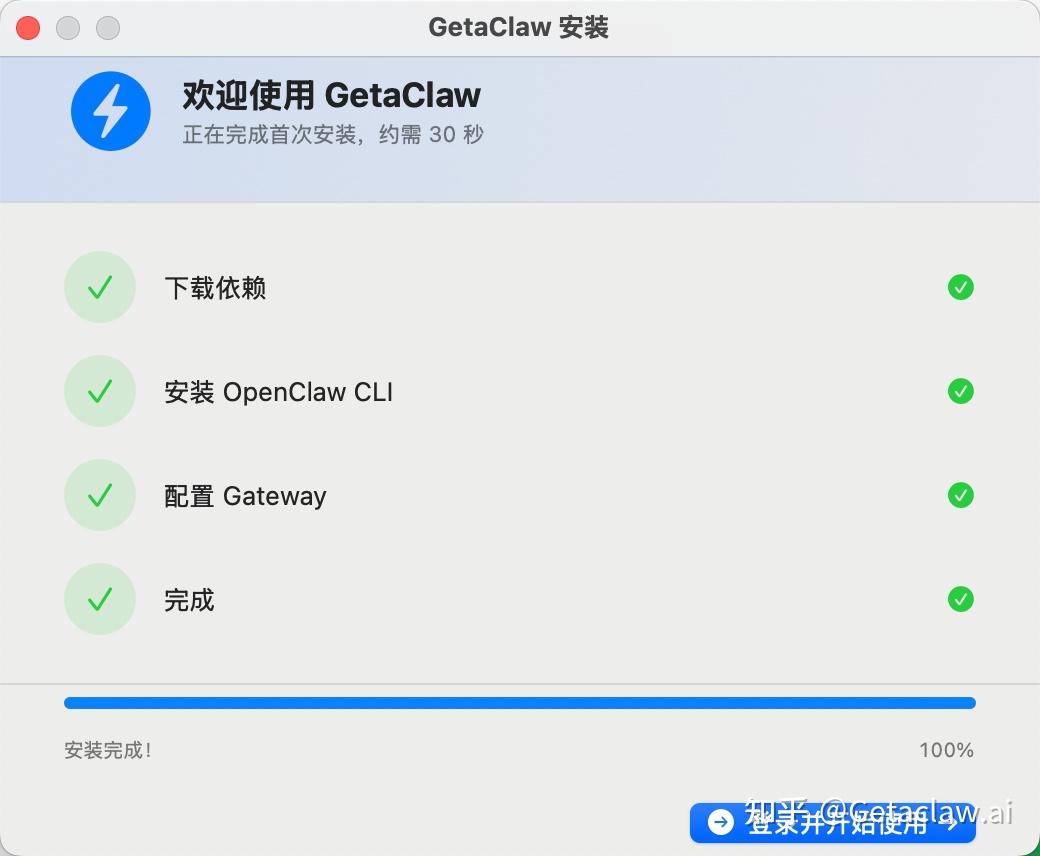
注册成功后就可以进入登录界面,开始使用∶
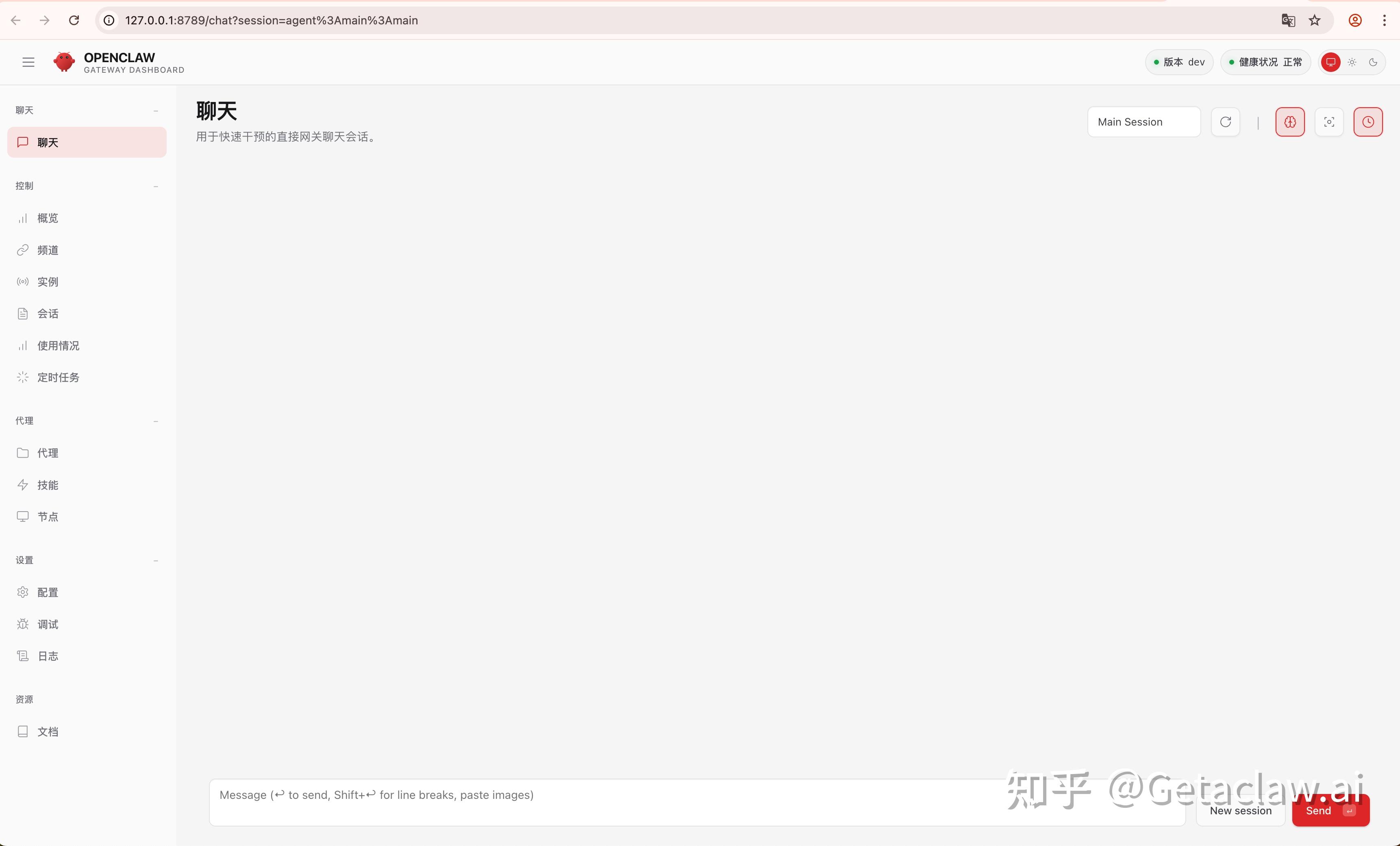
为什么大多数教程对你没用
搜“OpenClaw部署教程”,大概率看到的是:先安装 Node.js,然后 npm install -g openclaw,配置 Gateway,修改 JSON 文件……
对技术同事来说这是家常便饭,但对市场、运营、HR来说,第一步就可能卡住。我见过不少人折腾了大半天,最后放弃。这不是你的问题,是工具门槛的问题。
一键方案怎么操作
- 打开 getaclaw.ai
- 下载对应系统的安装包(Windows / macOS 都有)
- 双击安装,全程中文提示
- 装好之后,可以直接接飞书、钉钉、企业微信——引导式配置,不用找文档
整个过程不需要打开终端,不需要输入任何命令,跟安装普通软件一样。
装好之后能做什么
你说体验了技术同事的龙虾,感觉厉害——但可能还没感受到它最厉害的地方:主动干活。
它不只是回答你问题的聊天窗口,它可以:
- 每天早上自动帮你整理信息摘要,发到飞书
- 盯着你的邮件,重要的立刻提醒
- 接入飞书之后,可以直接帮你回消息、整理内容
- 设好规则,它在后台帮你处理重复性的信息工作
市场部门用好了,竞品追踪、行业资讯整理、日报周报这些事可以省掉大量时间。
注册还有福利
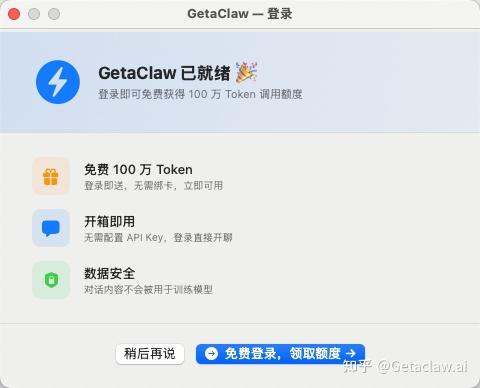
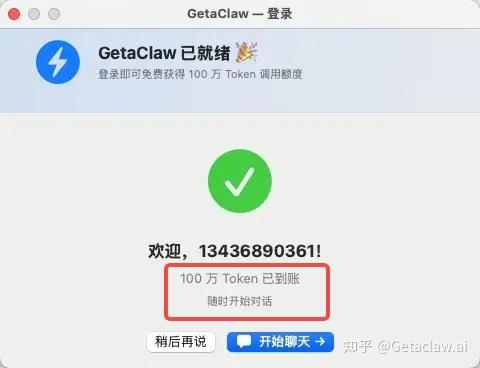
getaclaw.ai 注册之后会送百万免费 Token,够你把各种功能都摸一遍,不需要先掏钱就能正式体验完整能力。
试试吧,真的是给市场/运营/非技术同学专门准备的入口。装上之后有什么问题欢迎在评论区问。🦞
还有各位看官们提个小醒:我们这个送token的福利不定啥时候结束,早点注册可以早点享受福利哦

提到在 Mac 上跑本地大模型,很多人第一反应是 Ollama。但如果你追求极致的推理速度,并且想运行最新架构的模型(比如多模态小钢炮 Qwen3.5-4B),苹果官方主导的 MLX 框架才是终极答案!
本文将手把手教你如何用 MLX 在 Mac 上部署最新的 Qwen3.5-4B-MLX-4bit 模型,并将其封装成完美兼容 OpenAI 格式的后台 API,最后丝滑接入 OpenClaw。
⚠️ 高能预警:部署最新模型往往伴随着无尽的环境报错。本文记录了我在配置过程中踩过的所有大坑,如果你遇到 command not found、model not supported 等玄学问题,看这一篇就够了!
很多小白上来就直接 pip install,结果遇到一堆类似 site-packages is not writeable 的权限报错,或者装完后终端提示 zsh: command not found。
原因:Mac 自带的 Python 版本太老(通常是 3.9),而最新的 AI 框架强制要求 Python 3.10 以上。
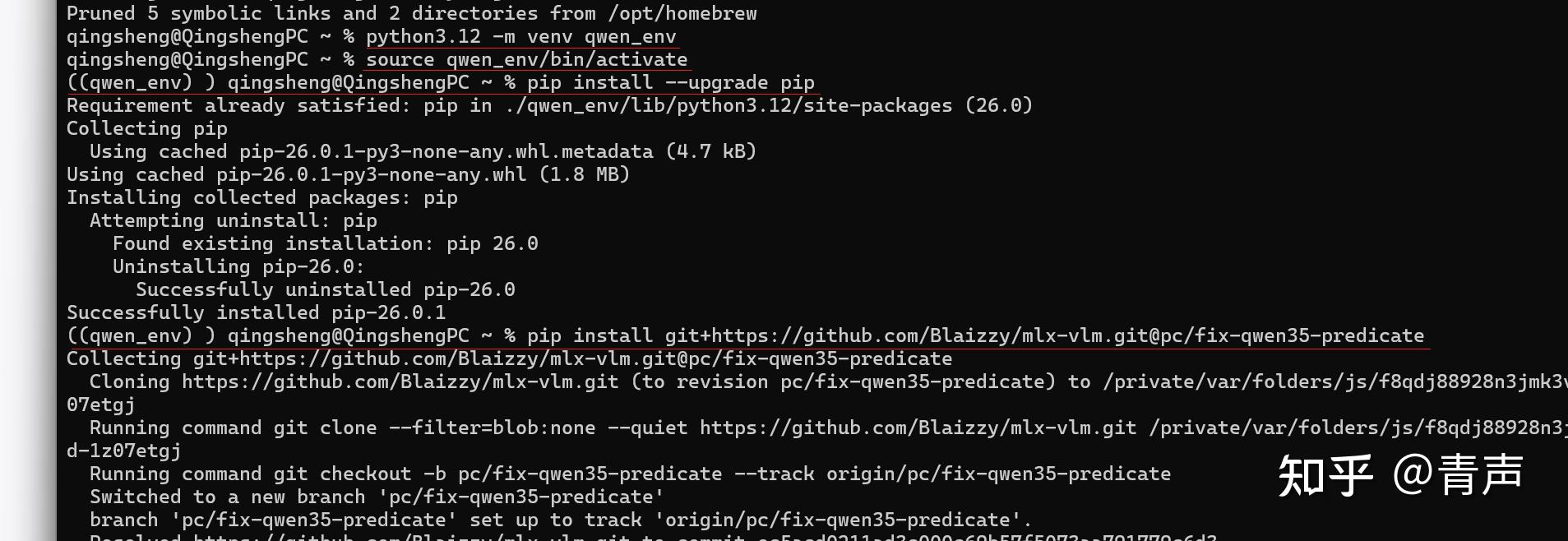
正确姿势:使用 Homebrew 安装 Python 3.12,并创建一个干净的虚拟环境!
brew install python@3.12打开终端,依次执行:
GPT plus 代充 只需 145# 1. 创建名为 qwen_env 的虚拟环境 python3.12 -m venv qwen_env
2. 激活虚拟环境
source qwen_env/bin/activate
3. 升级基础工具
pip install –upgrade pip
💡
提示:执行完后,你的终端提示符最左边会出现
(qwen_env) 字样,说明你已经进入了安全的“沙盒”。
我们要运行的模型是 mlx-community/Qwen3.5-4B-MLX-4bit。
Qwen 3.5 是一个支持视觉的多模态模型(VLM)。如果你习惯性地安装纯文本框架 mlx-lm,连模型都无法加载。必须使用 mlx-vlm。
如果你直接 pip install mlx-vlm,运行模型时大概率会遇到这个报错。
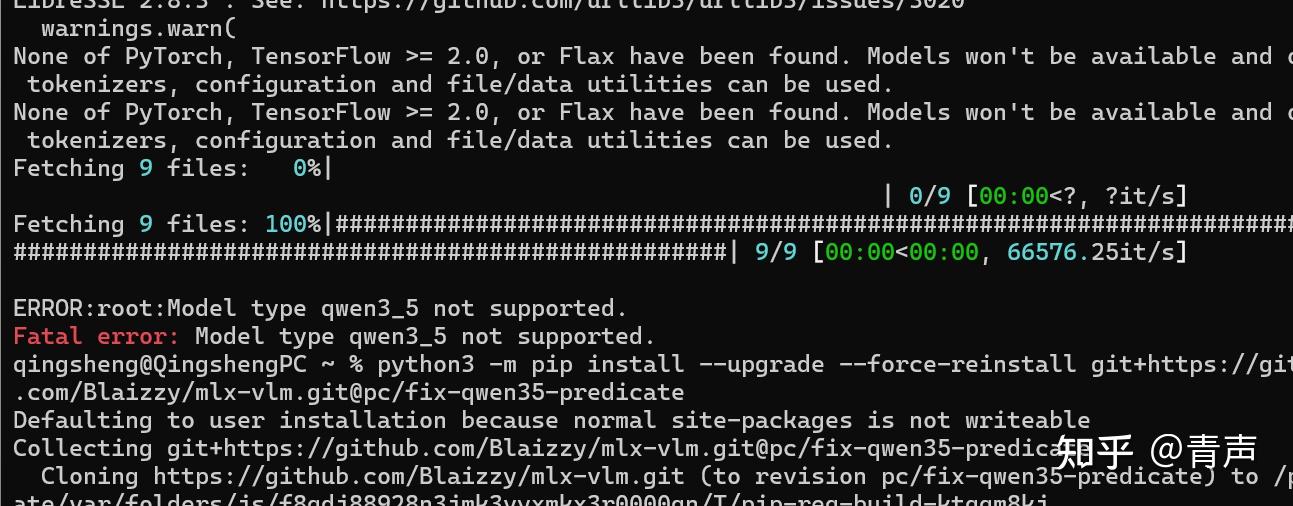
原因:Qwen 3.5 架构太新了,官方稳定版代码库还没来得及合并支持!
解法:我们需要直接从开发者的测试分支安装抢先版。
在虚拟环境中运行:
pip install git+https://github.com/Blaizzy/mlx-vlm.git@pc/fix-qwen35-predicate装完框架后运行,又弹出一堆:requires the Torchvision library…
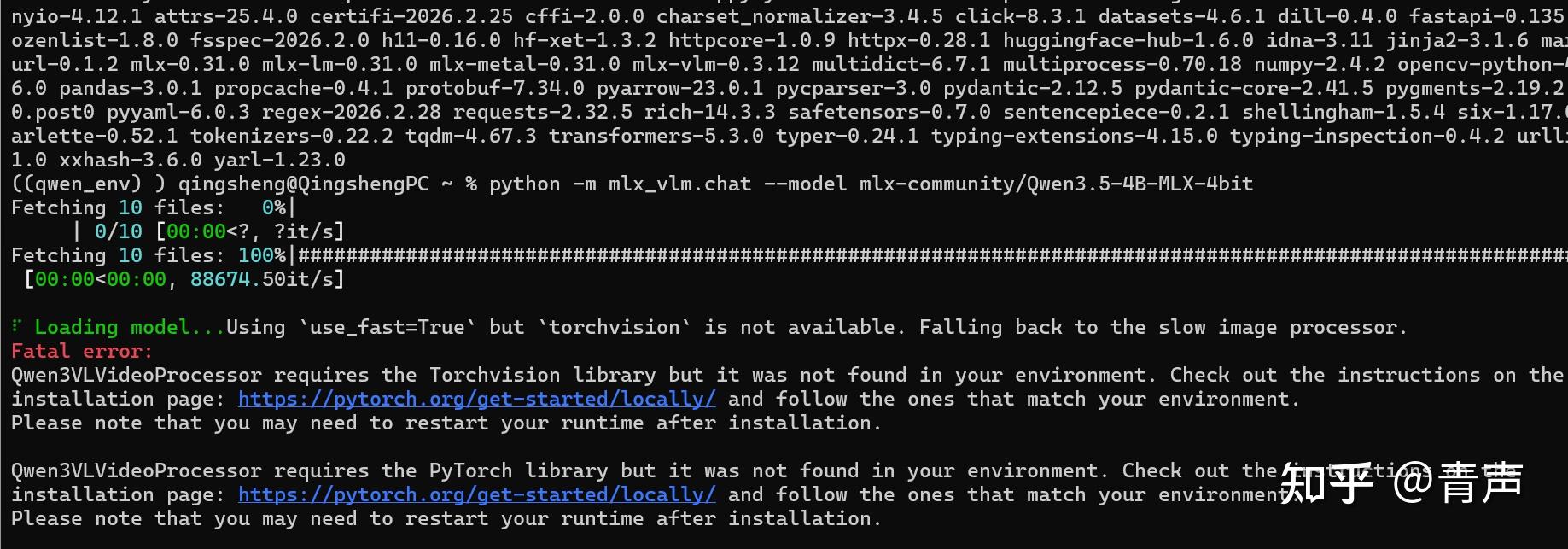
原因:既然是多模态模型,Hugging Face 的图片处理器底层强依赖 PyTorch,而我们的纯净环境里没有。
解法:顺手把图像处理的依赖补齐:
GPT plus 代充 只需 145pip install torch torchvision
环境终于配齐了,我们先用命令行测试一下模型能否正常对话。运行:
export HF_ENDPOINT=https://hf-mirror.com # 设置国内镜像站环境变量,如有梯子可忽略此步骤python -m mlx_vlm.chat –model mlx-community/Qwen3.5-4B-MLX-4bit
(首次运行会自动从 Hugging Face 下载约 3GB 的模型权重,速度极快,耐心等待进度条走完。)
⚠️小贴士1:如果遇到ConnectionError,不要慌!在命令前加上export HF_ENDPOINT=https://hf-mirror.com。这就像给你的下载器换了一条高速公路,实测下载速度能从几 KB 直接飙升到几十 MB。
⚠️ 小贴士2: 加载成功后,命令行可能会提示 Please load an image first。别慌!这是因为测试脚本默认你要测“看图说话”。我们直接无视,输入 /exit 退出即可。因为我们真正的目的是启动纯文本 API 服务。
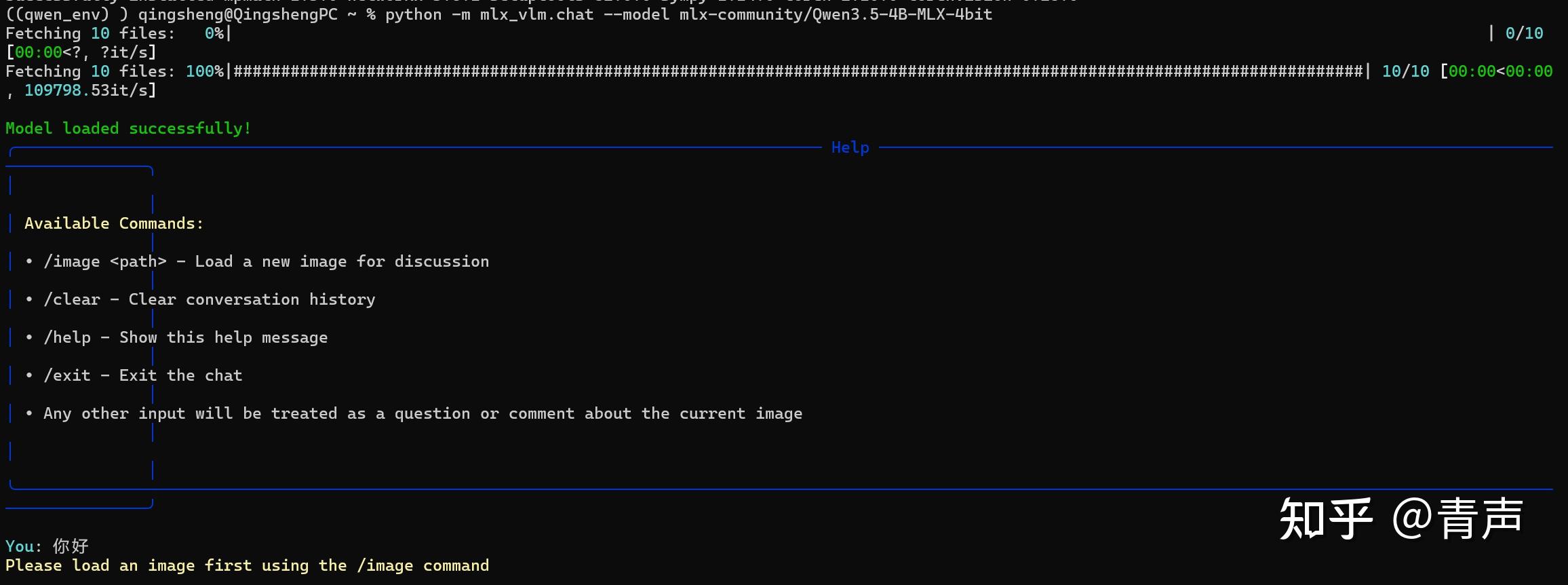
如果每次都要打开一个黑框框终端来启动 API,那也太不优雅了。关掉窗口还会导致服务断线。
Mac 系统自带了极其强大的进程管理工具 launchd,我们可以把模型做成一个原生的系统后台服务!
mlx_vlm 的 API Server 采用的是动态加载(Dynamic Loading)机制。它启动时只是个“空壳”,收到带模型名字的请求时才会去加载模型。如果启动命令里硬塞 –model 参数,会直接报错退出。
打开终端(不需要进虚拟环境),直接一次性复制粘贴下面这段代码并回车,这会在你的系统里生成一个服务配置文件:
⚠️ 注意:请把下方代码里的所有/Users/你的用户名替换成你 Mac 真正的电脑用户名路径(例如/Users/zhangsan)!
GPT plus 代充 只需 145cat << ‘EOF’ > ~/Library/LaunchAgents/com.local.qwen-server.plist <?xml version=“1.0” encoding=“UTF-8”?> <!DOCTYPE plist PUBLIC “-//Apple//DTD PLIST 1.0//EN” “http://www.apple.com/DTDs/PropertyList-1.0.dtd"> <plist version=”1.0“> <dict>
<key>Label</key> <string>com.local.qwen-server</string> <key>ProgramArguments</key> <array> <!-- 这里一定要写你虚拟环境中的 python 绝对路径 --> <string>/Users/你的用户名/qwen_env/bin/python</string> <string>-m</string> <string>mlx_vlm.server</string> <string>--port</string> <string>8080</string> <string>--trust-remote-code</string> </array> <key>RunAtLoad</key> <true/> <key>KeepAlive</key> <true/> <key>StandardOutPath</key> <string>/Users/你的用户名/qwen_server.log</string> <key>StandardErrorPath</key> <string>/Users/你的用户名/qwen_server_error.log</string> </dict> </plist> EOF
接着,激活这个服务:
GPT plus 代充 只需 145launchctl load ~/Library/LaunchAgents/com.local.qwen-server.plist
至此,你的 Qwen API 已经默默在后台 http://127.0.0.1:8080 运行了,开机自启,崩溃自动重启,且完全不占你的 Dock 栏!
想要看运行日志?输入 tail -f ~/qwen_server.log 即可。
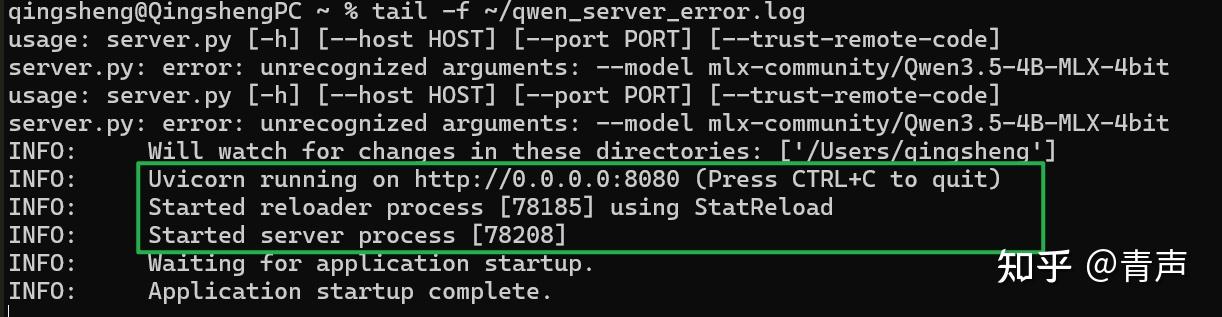
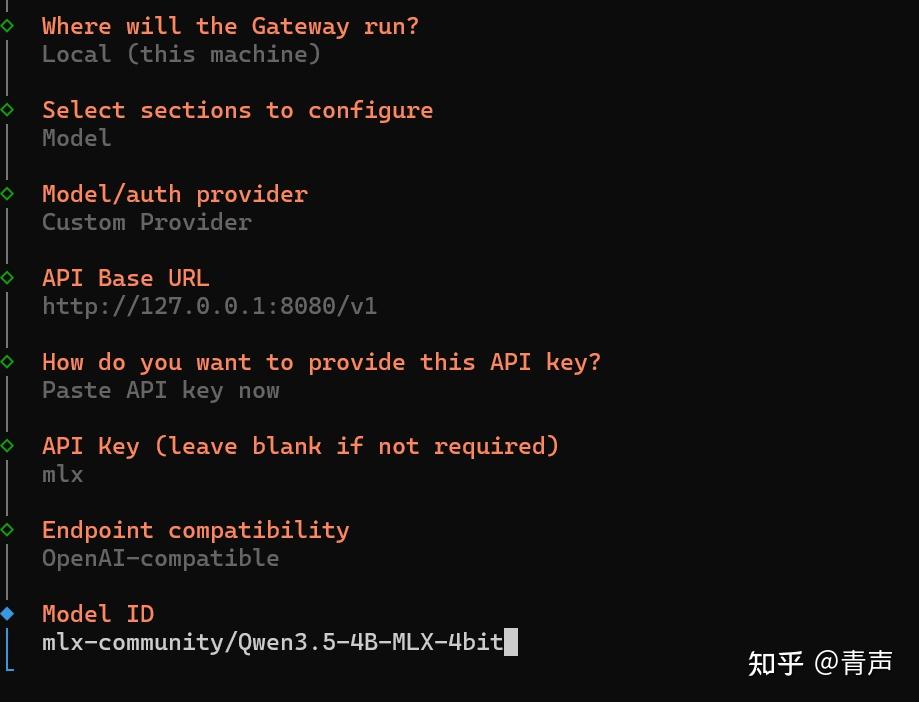
现在,万事俱备,打开 OpenClaw 的配置界面,填入你的本地最强辅助:
- API Provider (服务商):
OpenAI或Custom OpenAI - Base URL (接口地址):
常规填写:
http://127.0.0.1:8080/ 或 http://127.0.0.1:8080/v1 - ⚠️ 史诗级天坑:如果你的 OpenClaw 是用 Docker 容器运行的,千万别写
127.0.0.1,必须写http://host.docker.internal:8080/(这是 Docker 访问宿主机的专属通道)。 - API Key (密钥): 随便填(例如
mlx)。 - Model Name (模型名称): 必须一字不差地填写
mlx-community/Qwen3.5-4B-MLX-4bit。
💡 必看的“冷启动”科普
配置完成后,当你在 OpenClaw 发出第一句问候时,可能会卡住几秒甚至十几秒。别慌,没死机! 这是因为 API 服务平时处于“零显存占用”状态,收到请求时正在从硬盘把 3GB 的模型搬运到 Mac 的统一内存里。第一句回复出来后,模型就常驻内存了,接下来的对话则会正常!
https:// huggingface.co/mlx-comm unity/models知乎上面找,有很多。我用Windows11系统下的wsl部署的,system后台运行,Windows下tailscale远程连接(手机远程连接不上,去tailscale官网查看教程,用powershell输入指令生成个证书,通过https登录就行了)。要链接飞书,浏览器上手机扫码登录飞书开放平台,通过创建企业自建应用,启用一个机器人就行了。
剩下的就是添加大语言模型,和各种技能了。如果有opencode,就让西西弗斯安装。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/214578.html