
代码在 GitHub。如果你也想造一只属于自己的螃蟹钳子,欢迎 star/fork。我的 GitHub:jackwener,欢迎 follow。
2026 年 2 月,OpenClaw 火了。朋友圈里人人都在聊这只龙虾——一个能在 Telegram 里跟你对话、帮你干活的 AI 智能体。在我看到 Bub 之后,我也起了一个想自己写一个的心
我先简单看了 Nanobot(OpenClaw 的最小复现)了解核心架构,
深入研究了 Bub——PsiACE 的 Agent 项目。Bub 的架构非常优雅:AgentLoop 抽象、Tape 记忆系统、Skills 引擎,每个模块都恰到好处。后来在做 schedule 等功能时,也参考了 Zeroclaw 的实现思路。
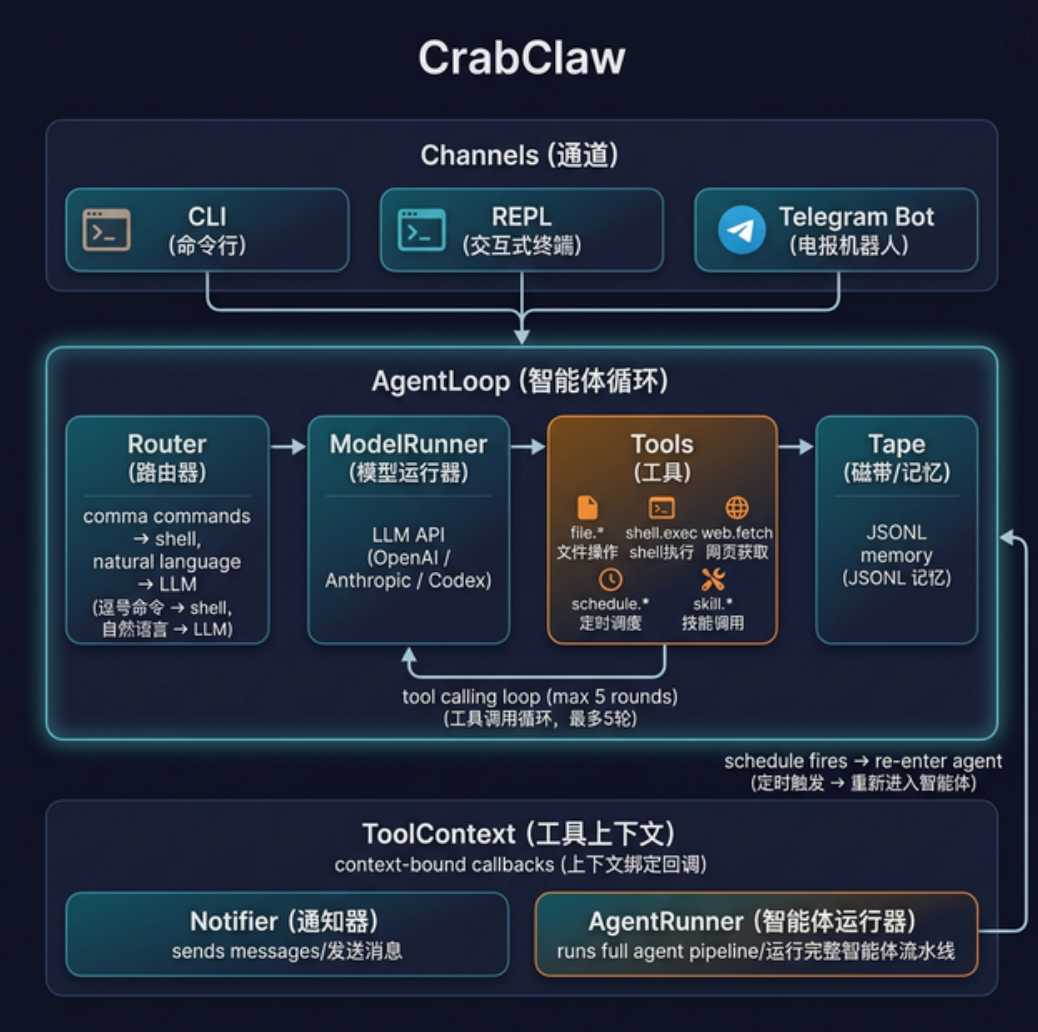
CrabClaw 的架构大量借鉴了 Bub,核心理念是 “路由 → 模型 → 工具 → 记忆” 的确定性单向数据流:
GPT plus 代充 只需 145
下面详细介绍图中每个组件。
CrabClaw 支持三种接入方式,它们的职责只有一个——收消息、发结果,不包含任何 agent 逻辑:
| Channel | 场景 | 特点 |
|---|---|---|
| CLI | cargo run – run –prompt “…” | 一次性执行,适合脚本集成 |
| REPL | cargo run – interactive | 交互式终端,支持流式输出 |
| Telegram Bot | cargo run – serve | 长轮询,带白名单 ACL、typing indicator |
所有 Channel 最终都通过 AgentLoop::handle_input(text) 进入同一条管线。
这是 CrabClaw 的心脏。最初我给 CLI、REPL、Telegram 各写了一套 agent 循环逻辑——消息解析、LLM 调用、工具执行、结果录制,每处都有微妙差异、重复代码。后来参考 Bub 的做法,抽出了统一的 AgentLoop:
讯享网config: &'a AppConfig, // 运行配置(模型、API key 等) workspace: &'a Path, // 工作区目录 tape: TapeStore, // 会话记忆 tool_view: ProgressiveToolView, // 渐进式工具视图 tool_ctx: ToolContext, // 工具执行上下文(notifier + agent_runner)
}
每次用户发消息,handle_input 跑一个完整的 6 步管线:
1. Route → 用户输入经过 Router 分流(命令 vs 自然语言)- Record → 用户消息写入 Tape(只追加)
- Tools → 从 ProgressiveToolView 获取当前可用工具定义
- Context → 从 Tape 构建上下文窗口(滑动窗口截断,默认 50 条)
- Model → ModelRunner 发起 LLM 推理 + Tool Calling Loop
- Process → 处理结果:录入 Tape、检测助手输出中的逗号命令
所有
,开头的输入直接走命令路由,绕过 LLM——零延迟、确定性结果:,help→ 内部命令,直接返回帮助文本,git status→ Shell 执行(/bin/sh -c),30 秒超时,tools→ 列出所有注册工具,tape.search <query>→ 搜索对话历史,handoff→ 创建上下文切换锚点(下面详解)
非
,开头的输入才走 LLM 推理。这个设计确保了”确定性操作”的可靠性,同时把”需要智能”的部分交给模型。这是 Agent 区别于普通 Chatbot 的核心机制。当 LLM 的回复中包含
tool_calls(比如它想调用file.read读文件),ModelRunner会:讯享网
第 1 轮:LLM → “我想调用 file.read(path=’src/main.rs‘)” → 执行 file.read → 返回文件内容 → 把结果追加到上下文 → 再次调用 LLM
第 2 轮:LLM → “我看到了代码,现在调用 file.edit 修改第 42 行”
→ 执行 file.edit → 返回成功 → 再次调用 LLM 第 3 轮:LLM → “修改完毕,这是我的总结:…”
讯享网 → 没有 tool_calls → 循环结束,返回最终文本</code></pre></div><p data-pid="e0GYvEma">最多 <b>15 轮</b>,防止模型陷入无限循环。这个数字最初是 5——直到有人给 bot 发了”帮我从 HackerNews 采集 20 条新闻并总结”,5 轮根本不够完成 <code>web.fetch</code> → 解析 → 总结的完整链路。Zeroclaw 用的是 10,我们给了更多余量:</p><div class="highlight"><pre><code class="language-text">const DEFAULT_MAX_TOOL_ITERATIONS: usize = 15;</code></pre></div><p data-pid="TKMtazgA">此外,参考 Zeroclaw 的设计,CrabClaw 还有一个 <b>loop 检测</b> 机制:用 <code>HashSet<(tool_name, canonical_args)></code> 追踪每轮 tool call 的签名,如果 LLM 重复调用相同工具 + 相同参数,直接跳过并返回提示。这样就不会傻等 15 轮才超时——重复调用第 2 次就会被拦截。</p><p data-pid="WI2aOMvL">CrabClaw 内置的工具集:</p><table data-draft-node="block" data-draft-type="table" data-size="normal" data-row-style="normal"><tbody><tr><th>工具</th><th>功能</th></tr><tr><td>file.read/write/edit/list/search</td><td>工作区沙箱化的文件操作</td></tr><tr><td>shell.exec</td><td>Shell 命令执行(失败结果包装为 XML 供 LLM 自我纠正)</td></tr><tr><td>web.fetch / web.search</td><td>抓取网页 / DuckDuckGo 搜索</td></tr><tr><td>schedule.add/list/remove</td><td>定时任务(支持 reminder 和 agent 两种模式)</td></tr><tr><td>skill.*</td><td>从 .agent/skills/ 自动发现的 Markdown 技能插件</td></tr></tbody></table><p data-pid="3k0psE2M">如果每次 LLM 请求都带上所有工具的完整 JSON Schema(参数定义、类型约束、描述),那光工具定义就要吃掉约 <b>720 token</b>。对于简单的对话来说,这是巨大的浪费。</p><p data-pid="KqA7A7DJ"><code>ProgressiveToolView</code> 的思路是 <b>“先给菜单,再给菜谱”</b>:</p><p data-pid="e6labFC_"><b>初始状态</b>(~50 token):系统提示词只包含工具名和一行描述:</p><div class="highlight"><pre><code class="language-text"><tool_view>
- shell.exec: Execute shell commands in the user’s workspace
- file.read: Read file contents (workspace-sandboxed)
- web.fetch: Fetch a URL and return content as Markdown … </tool_view>
按需展开:当 LLM 在回复中提到
\(file.read</code>(<code>\)前缀是 hint 语法),或者实际调用了某个工具,该工具的完整 Schema 才会在下一轮请求中发送给 API:// 检测 \(hint 模式并展开 view.activate_hints("I'll use \)file.read to check the config“); // → file.read 被展开,下次 API 调用会带上完整参数定义
// 工具被实际调用时也会展开 view.note_selected(”shell.exec“);
效果:从第一轮的 ~50 token 到按需展开的少量工具完整 Schema,节省了 90%+ 的 token 消耗。对于简单对话(不需要工具的),节省是 100%。
对话历史存储在 JSONL 格式的 TapeStore 中——只追加,不修改。每行是一个 TapeEntry:
讯享网{”id“: 1, ”type“: ”message“, ”payload“: {”role“: ”user“, ”content“: ”读一下 Cargo.toml“}} {”id“: 2, ”type“: ”message“, ”payload“: {”role“: ”assistant“, ”content“: ”…“}} {”id“: 3, ”type“: ”event“, ”payload“: {”event“: ”tool_call“, ”tool“: ”file.read“}} {”id“: 4, ”type“: ”anchor“, ”payload“: {”name“: ”handoff“, ”state“: {…}}}
Anchor 是 Tape 中的”书签”——标记一个有意义的时间点,比如”任务阶段完成”、”上下文切换”。
tape.anchor(”phase-1-done“, json!({ ”summary“: ”搭建完成“ }));Anchor 不影响对话流,但可以用于:
- 标记任务阶段边界
- 搜索时作为定位点
- Handoff 时记录切换信息
当对话变得很长,或者你要切换到完全不同的任务时,用 ,handoff 命令创建一个特殊的 Anchor 并重置上下文窗口:
讯享网> ,handoff phase-2 Handoff anchor ‘phase-2’ created. Context window reset (127 entries before).
Handoff 做了两件事:
- 在 Tape 中插入一个
type: ”handoff“的 Anchor,记录切换前的条目数 - 上下文构建器(
build_messages)从最后一个 handoff Anchor 之后开始构建上下文,相当于”忘记”之前的对话
为什么需要 Handoff? LLM 的上下文窗口有限。如果你跟 bot 聊了 200 轮关于前端的问题,突然要切到后端,之前的 200 轮上下文不仅浪费 token,还可能干扰模型对新任务的理解。Handoff 让你在同一个 session 内优雅地”翻篇”。
,tape.search <query> 可以在整个对话历史中做全文搜索(大小写不敏感),找到之前讨论过的内容。搜索范围包括消息内容、事件 payload、Anchor 名称。
ToolContext 是工具执行时的”环境对象”,携带了当前 session 的能力:
pub struct ToolContext {讯享网pub notifier: Option<Notifier>, // 发送通知消息 pub agent_runner: Option<AgentRunner>, // 运行完整 agent pipeline
}
- Notifier:Telegram 构建一个闭包,捕获
bot_token + chat_id。当 schedule reminder 触发时,通过这个闭包把消息发回给用户 - AgentRunner:Telegram 构建一个异步闭包,捕获
config + workspace + session_id。当 schedule agent job 触发时,调用process_message跑完整 agent pipeline,结果通过 Telegram API 发回
CLI 和 REPL 的 ToolContext 是空的(None, None)——它们没有通知能力。
整个开发过程几乎全部由 AI 辅助完成。我用 Gemini 做方案设计,用 Claude 写实现,用 Codex 做代码 review。
里面有意思的一段。用户在 Telegram 里给 bot 发了这么一条消息:
“帮我做个任务,每天十一点的时候从 HackerNews 上收集热点新闻,并且把摘要发给我。”
然后 bot 卡住了。
原因很简单:当时的 schedule 只能发静态文本。当 job 触发时,它只调用 notifier(”⏰ 提醒: xxx“)——发一条固定消息。它做不到调用 web.fetch 抓 HackerNews,更做不到调用 LLM 生成摘要。
于是我去研究了 Bub 和 Zeroclaw 怎么做的:
| 项目 | Schedule 触发行为 | 实现方式 |
|---|---|---|
| Bub | 启动子进程跑 agent | subprocess.run([”bub“, ”run“, prompt]) |
| Zeroclaw | 进程内调 agent::run() | 异步直接调用 |
| CrabClaw (重构前) | 发静态文本 ❌ | notifier(text) |
最终我选了 Zeroclaw 的路线,但做了更优雅的实现——用闭包捕获所有上下文:
pub type AgentRunner =讯享网Arc<dyn Fn(String) -> Pin<Box<dyn Future<Output = ()> + Send>> + Send + Sync>;</code></pre></div><p data-pid="tjH53UOE">Telegram 在收到消息时,构建一个 <code>AgentRunner</code> 闭包,捕获 <code>config</code>、<code>workspace</code>、<code>session_id</code>、<code>chat_id</code>。当 schedule 触发时,直接 <code>.await</code> 这个闭包,完整地跑一轮 agent pipeline——LLM 可以调 <code>web.fetch</code>、生成摘要,最后通过 Telegram API 把结果发回给用户。</p><p data-pid="ay0xXpHL">整个重构分了三步:</p><ol><li data-pid="VJ0269Od"><b>per-job notifier</b>:每个 job 捕获自己的通知回调,不再依赖全局 notifier</li><li data-pid="AIod8h_S"><b>ToolContext</b>:让 <code>execute_tool</code> 感知 session 上下文</li><li data-pid="xCM6sxxW"><b>AgentRunner</b>:<code>schedule.add</code> 支持 <code>mode: "agent"</code>,触发时运行完整 agent</li></ol><p data-pid="b8XHpvpv">这个设计比 Zeroclaw 更轻——不需要 SQLite 存储 job、不需要 cron 表达式解析、不需要复杂的 delivery config。一个闭包搞定一切。</p><p data-pid="KLmSKfKK">重构完,兴冲冲地部署,给 bot 发了”一分钟后帮我采集 HackerNews”。bot 说”好的,已创建任务”。然后……什么也没发生。</p><p data-pid="7HVs4fOM">排查了半天,发现问题:<code>agent_runner</code> 是一个 async 闭包,在 <code>tokio::spawn</code> 里执行。如果里面 panic 了——tokio task 静默死掉,没有任何日志,没有任何通知。用户看到的就是”bot 说做了,但什么也没发生”。</p><p data-pid="H0MwzpgE">修复方式是在 <code>fire_job</code> 里用 <code>tokio::task::spawn(fut).await</code> 加 <code>match</code>:</p><div class="highlight"><pre><code class="language-text">match tokio::task::spawn(fut).await { Ok(()) => info!("agent-mode job completed"), Err(e) => { error!("agent-mode job panicked: {e}"); // 回退到 notifier 通知用户 if let Some(notify_fn) = notifier { notify_fn(format!("⚠ Agent job failed: {e}")); } }
}
教训:在 Agent 系统里,任何 async 回调都必须有明确的错误传播路径。”fire and forget” 是 Agent 开发的大忌——用户永远不应该面对”机器人说做了但什么也没发生”的情况。
10 天 73 个 commit,13000+ 行 Rust。这不是吹嘘速度——如果只看代码量,这大概是纯手写一两个月的工作量。但这个过程中真正有意思的不是”快”,而是整个开发方式的变化。
CrabClaw 最初没有架构。我跟 AI 说”帮我写一个 Telegram bot,能调 LLM,能跑工具”,它就给我生成了一整坨——消息处理、LLM 调用、工具执行全在一个函数里。能跑,但每加一个功能,面条就长一截。
这是我第一个感悟:代码模式会以极快的速度扩散,无论好坏。AI 生成代码的速度太快了,一个面条式的起点,滚三天雪球就是万行单文件。错误会自我强化——AI 看到已有代码是面条式的,它生成的新代码也会是面条式的。
转折点是我去读了 Bub 的源码。看到 Bub 把 AgentLoop、ModelRunner、Router 拆得清清楚楚,我才意识到:AI 时代也需要软件工程,甚至更需要。架构不是给人看的文档,而是一种约束——控制复杂度、阻止不确定性扩散的约束。我回去花了一天把 CrabClaw 重构成现在的 AgentLoop → ModelRunner → ToolContext 三层结构,之后所有功能开发都顺畅了。
做 schedule 重构的时候,我试过先写一份详细的 spec,列清楚每个文件要改什么、接口长什么样、数据怎么流,然后把 spec 丢给 AI 执行。
效果不好。第二天我改了 ToolContext 的结构,spec 立刻过时了。但 AI 不知道,它还在按旧 spec 生成代码——忠实地执行一个已经不符合现实的计划,还不告诉你哪里不对。
Augment Code 说得好:设计文档、架构图、onboarding wiki,几乎一写出来就过时了。过时的文档误导人类顶多浪费点时间,因为人会自己判断;但过时的 spec 误导 Agent 是灾难性的,Agent 会一路错到底。
后来我换了方式:描述需求 → 让 AI 起草方案 → 我 review → 边做边调整。比如做 AgentRunner 的时候,我只说”schedule 触发时要能跑完整 agent pipeline”,AI 起草了实现方案,做的过程中发现需要闭包捕获上下文,方案就跟着改。人和 AI 共同维护计划,而不是人写完 spec 扔过墙。
这 10 天里,AI 最让我惊喜的是 bug 检查和代码 review。有一次 CI 挂了,我让 AI 分析 clippy 报错截图,它不仅修了报错,还顺手指出了两个我没注意到的逻辑问题。它在”已知 pattern 的代码生成”上也极其高效——给它 Bub 的架构,它能快速翻译成 Rust 实现。
但 AI 在 high-level 架构决策上几乎没给过有效建议。每次我让它”设计一个 schedule 系统”,出来的都是过度工程化的方案——SQLite 存储、cron 表达式解析、retry 策略、delivery config。实际上一个 Arc<dyn Fn> 闭包就够了。好的架构是做减法,而 AI 倾向于做加法。
开发后期我发现,工程师的核心工作不再是写代码,而是搭建一个让 AI 能自己跑通的环境。CrabClaw 里有几个具体的例子:
- pre-commit hook 是最有效的约束。
cargo fmt+cargo clippy强制格式和质量,AI 提交代码,hook 报错,AI 自己修——不需要我盯着。做 schedule 重构时改了 17 个文件,全靠 hook 和 CI 保证没引入回归 - 四层测试(单元 → AgentLoop 集成 → Channel 集成 → Live E2E)让每次重构都有安全网。测试不是负担,是让 AI 敢大胆改的前提
- 代码注释比独立文档靠谱。模块头部的 doc comment 跟代码在一起,不容易过时。它们构成了一个渐进式的知识系统——AI 读代码时自然就能理解模块职责,不需要额外去翻 wiki
AI 已经完全的改变了我们的 coding 方式,乃至于我们的生活方式。 我希望我自己变成一个 AI native 的人,适应这个新的 AI 世界。 就像这篇文章也是 AI 写的
- Bub(PsiACE)—— CrabClaw 最初的灵感来源,架构设计大量借鉴
- Zeroclaw —— agent-mode schedule 的参考实现
- Nanobot —— 最初帮我理解 OpenClaw 架构
- Frost Ming —— AI Native 理念的深刻阐述
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/214010.html