
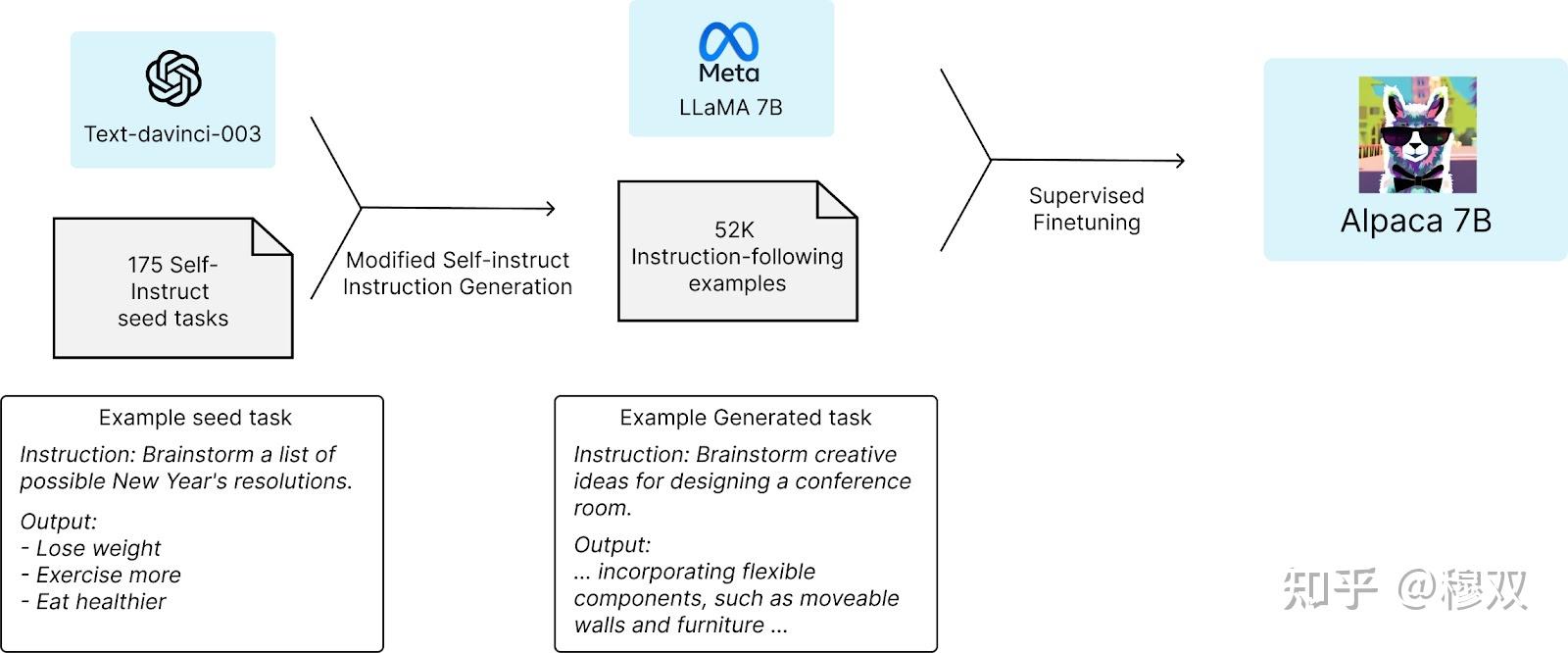
在本文中,我们将解释开源 ChatGPT 模型的工作原理以及如何运行它们。我们将涵盖十三种不同的开源模型,即 LLaMA、Alpaca、GPT4All、GPT4All-J、Dolly 2、Cerebras-GPT、GPT-J 6B、Vicuna、Alpaca GPT-4、OpenChatKit、ChatRWKV、Flan-T5 和 OPT。到本文结束时,您应该对这些模型有很好的理解,并且您应该能够在 Python 中运行它们。
ChatGPT 不是开源的。它有两个最近流行的版本 GPT-3.5 和 GPT-4。GPT-4 对 GPT-3.5 进行了重大改进,并且在生成响应方面更加准确。ChatGPT 不允许您查看或修改源代码,因为它不是公开的。因此,需要开源且免费提供的模型。通过使用这些开源模型,您无需为 OpenAI API 付费即可访问它们。
开源 ChatGPT 模型的好处
使用作为 ChatGPT 替代品的开源大型语言模型有很多好处。下面列出了其中一些。
- 数据隐私:许多公司希望控制数据。这对他们来说很重要,因为他们不希望任何第三方访问他们的数据。
- 定制化:它允许开发人员使用自己的数据训练大型语言模型,如果他们想应用,可以对某些主题进行一些过滤
- 负担能力:开源 GPT 模型让您可以训练复杂的大型语言模型,而无需担心昂贵的硬件。
- 人工智能民主化:它为进一步研究开辟了空间,可用于解决现实世界的问题。
您必须知道的开源聊天 GPT 模型
GPT plus 代充 只需 145
完整代码
简介:GPT4All
Nomic AI Team 从 Alpaca 获得灵感,使用 GPT-3.5-Turbo OpenAI API 收集了大约 800,000 个提示-响应对,创建了 430,000 个助手式提示和生成训练对,包括代码、对话和叙述。80 万对大约是羊驼的 16 倍。该模型最好的部分是它可以在 CPU 上运行,不需要 GPU。与 Alpaca 一样,它也是一个开源软件,可以帮助个人进行进一步的研究,而无需花费在商业解决方案上。
GPT4All 是如何工作的
它的工作原理类似于,基于 LLaMA 7B 模型。LLaMA 7B 和最终模型的微调模型在 437,605 个后处理助手式提示上进行了训练。
性能:GPT4All
在自然语言处理中,困惑度用于评估语言模型的质量。它衡量语言模型根据其训练数据看到以前从未遇到过的新单词序列时会有多惊讶。较低的困惑值表示语言模型更擅长预测序列中的下一个单词,因此更准确。Nomic AI 团队声称他们的模型比 Alpaca 具有更低的困惑度。真正的准确性取决于您的提示类型。在某些情况下,Alpaca 可能具有更好的准确性。
内存要求:GPT4All
它可以在具有 8GB RAM 的 CPU 上运行。如果你有一台 4GB RAM 的笔记本电脑,可能是时候升级到至少 8G 了
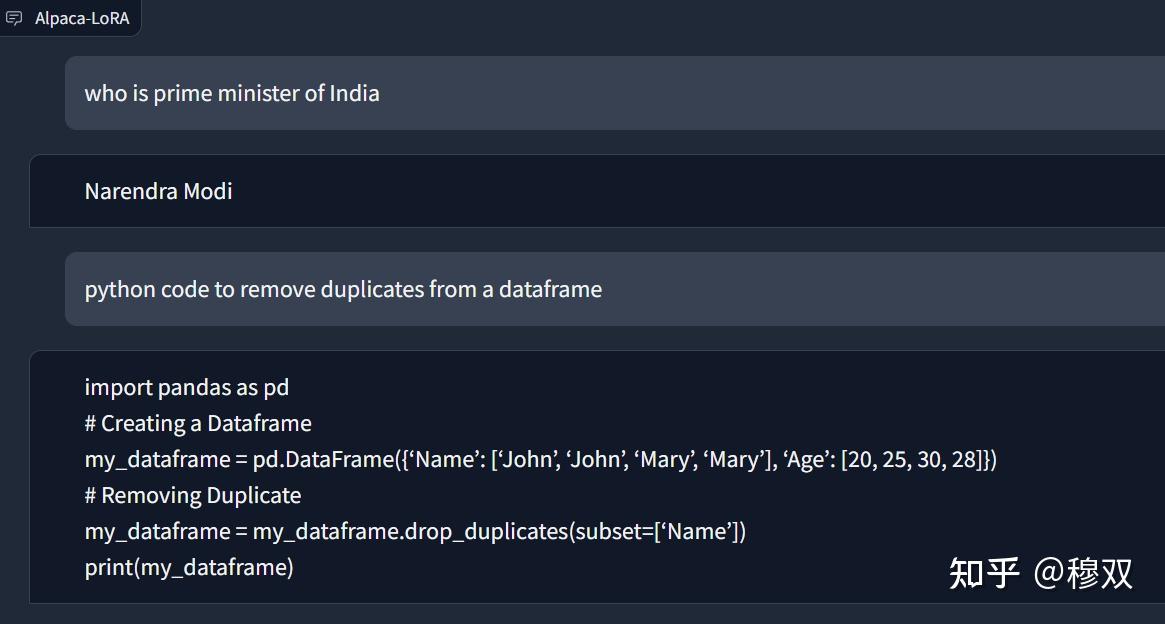
Python代码:GPT4All
可供您使用。您可以将其用作参考,根据需要进行修改,甚至按原样运行。完全由您决定如何使用代码来最好地满足您的要求。
克隆 Git 存储库
安装所需的包
训练
下载 CPU 量化的 gpt4all 模型检查点
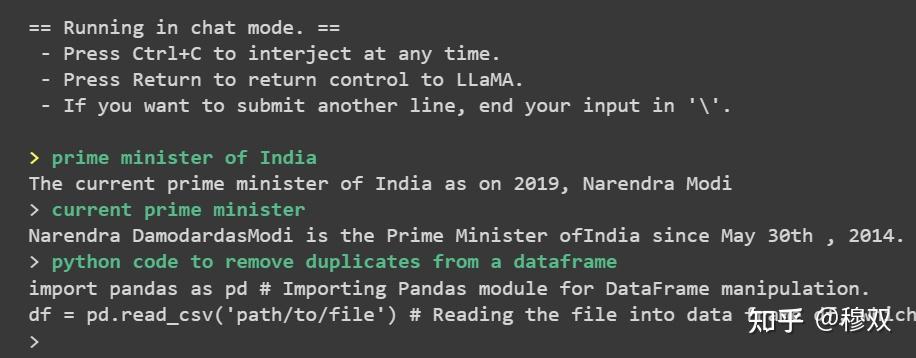
错误调试
Distributed package doesn’t have NCCL - 如果您在Mac操作系统上遇到此问题,那是因为您的计算机上未安装 CUDA。
Issues on Windows 10⁄11 - 一些用户报告说他们在 Windows 平台上遇到了一些奇怪的错误。作为最后的手段,您可以安装适用于 Linux 的 Windows 子系统,它允许您在 Windows 机器上安装 Linux 发行版,然后可以按照上面的代码进行操作。
您一定想知道这个模型如何与前一个名称相似,只是后缀为“J”。这是因为这两个模型都来自 Nomic AI 的同一个团队。唯一的区别是它现在是在上而不是在 LLaMa 上训练的。在 GPT-J 上训练它的好处是 GPT4All-J 现在是 Apache-2 许可的,这意味着您可以将它用于商业目的,也可以轻松地在您的机器上运行。
下载安装文件
内存要求:多莉 2
对于具有 8 位量化的 7B 模型,它需要一个具有大约 10GB RAM 的 GPU。对于 12B 型号,它至少需要 18GB GPU vRAM。
Python代码:多莉2
简介:骆马
来自加州大学伯克利分校、卡内基梅隆大学、斯坦福大学和加州大学圣地亚哥分校的研究人员团队开发了这个模型。它使用从 ShareGPT 网站提取的聊天数据集在 LLaMA 上进行了微调。研究人员声称该模型的质量得分超过 OpenAI ChatGPT-4 的 90%。值得注意的是,它的性能几乎与Bard持平。他们使用了羊驼的训练程序,并在多轮对话和长序列两个方面进行了进一步改进。
Python代码:Vicuna
您可以参考这篇文章——Vicuna来访问 python 代码和 Vicuna 模型的详细描述。
微调模型需要大量处理时间,因此必须非常耐心。微调完成后,您可以保存模型以备将来参考。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/210640.html