
比起之前的Claude 2.0和gpt4,性能如何?
昨天Claude2.1正式发布了,更新了一系列的新能力,不过只对API用户开放。

大概总结一下,200K Tokens的上下文窗口、模型幻觉率的显着降低、系统提示以及他们的新测试功能:工具使用。
其他的没啥可说的,重点聊聊这个200K Tokens的上下文。
记得几个月之前,Claude率先推出100K Token,引起了不小的风波,毕竟在那个上下文都还只有4K Tokens的年代,100K Token可是扎扎实实的降维打击。
而这次,Claude2.1号称全球第一,扔出了2倍容量的200K Token。大家可能对Token没啥概念。我换种描述来说。
200K Token等于470页的PDF材料。
按Claude自己的话说,你可以扔你整个代码库和技术文档、扔一整个财务报表,甚至把《奥德赛》或者《伊利亚特》扔进去。
这下是不是就大概有点数了?以前4K的小窗口,扔个几页PDF都费劲,现在,随便扔。
但是支持这么大的容量以后,使用起来到底怎么样?你不能光加容量,但是质量不加吧,就好比你喝瑞幸,以前是个普通中杯,给你放了半杯的冰,现在他说升级了,给你来了一口缸,但是缸里依然还特么的全是冰,咖啡就那么几口,那这升级有蛋用,对吧。
Token也是一样的道理,你说是升级了200K,但你实际到50K就全都忘干净了,那你100K和200K有啥区别?
所以X上一个大佬Greg Kamradt,为了弄明白Claude2.1的200K Token,究竟实测效果怎么样,就调用Claude 的API做了个压力测试。
他做个压力测试,花了1016 美金。。。。
你没看错,1016美金,折合人民币一共7255元。。。
只能说,太特么壕了,壕特么上天了。。。
直接放他的测试结果图,为了大家阅读体验良好,我给做成中文版的了
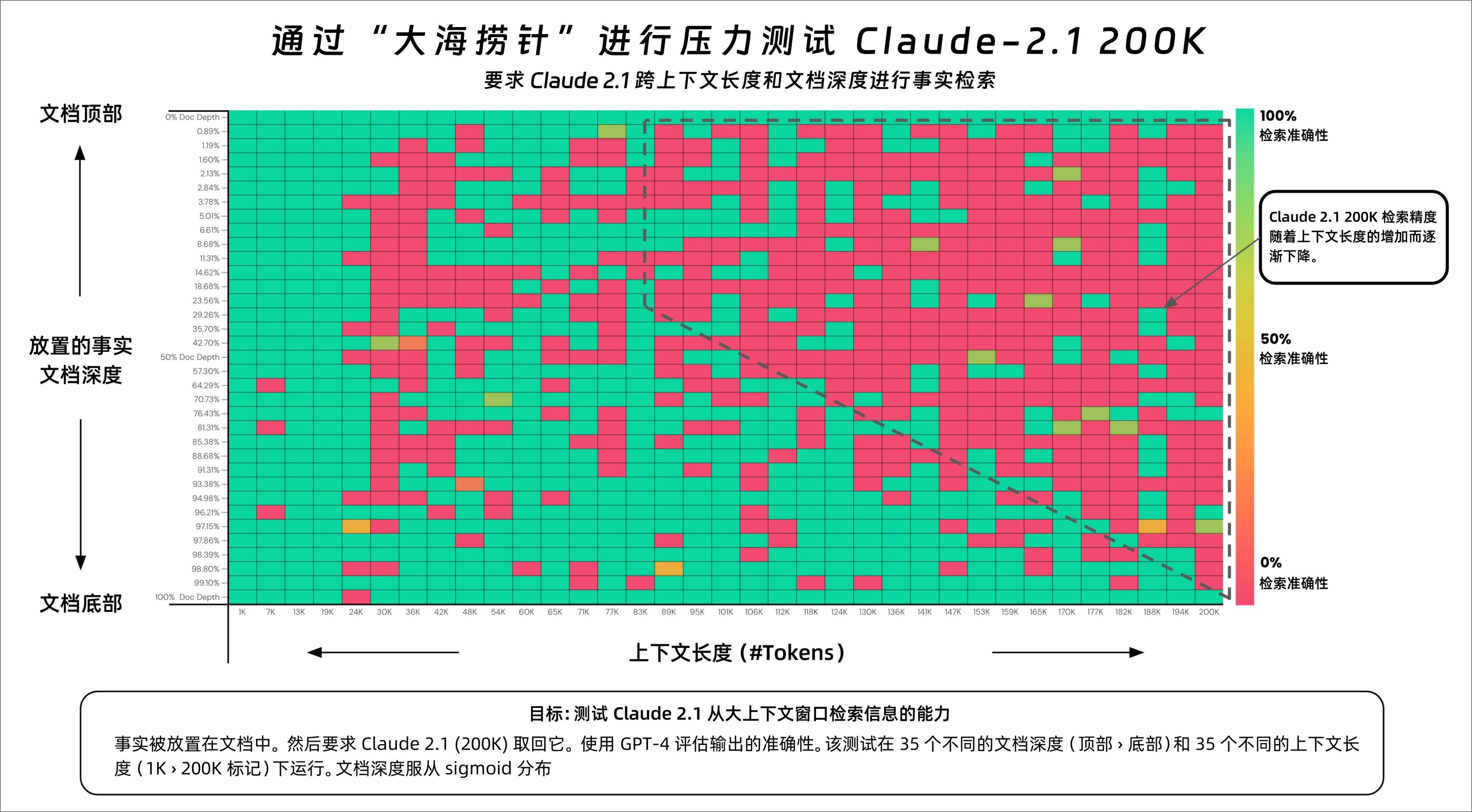
这个测试Greg Kamradt将其命名为“大海捞针”压力测试。
测试的目的是评估Claude从大量文本中检索信息的能力,特别是当信息被放置在文档的不同位置时的准确率。
横轴表示上下文长度(以Token表示),纵轴表示文档深度的百分比,这表示事实被放置在文档的位置。横轴应该比较好理解,就是给的信息总量Tokens数,从1K到200K不等。
纵轴我稍微解释一下,“文档深度百分比”实际上是表示要信息(事实)被放置在整个文档中的位置,就是你要从大海里捞的那根针所处的位置。
你可以想象一篇文章,它从头到尾都有文字。如果我们把这篇文章比作一堆纸叠在一起,那么“文档深度”的百分比就像是你从最顶部的纸张向下数,直到你找到那条信息所在的地方。
如果信息在文档的最开始部分,那么它的文档深度接近0%。
如果信息在文档的正中间,那么它的文档深度接近50%。
如果信息在文档的最末尾,那么它的文档深度接近100%。
如果一篇文章有100行,一个重要的事实被放在了第50行,我们可以说这个事实的文档深度是50%。如果这个事实在第25行,那么深度是25%;如果在第75行,深度就是75%。这个百分比告诉我们事实在文章中的位置,而不管文章有多长。
大概就是这个意思。
可以看到,整个测试,Claude红了半边天,一半都检索失败,根本找不到。
甚至可以看到文档到了200K的时候,除非你把那根“针”放在最顶部或者最底部,也就是文档深度0%的位置,才能成功。
甚至你放在1%的文档深度的位置都能失败,简直就离谱。
发现:
- 在20万个令牌(近470页)的文档深度下,Claude 2.1能够回忆起某些事实
- 位于文档最顶部和最底部的事实被几乎100%准确地回忆起来
- 位于文档顶部的事实的回忆表现不如底部(与GPT-4类似)
- 从大约90K个令牌开始,文档底部的回忆表现开始逐渐变差
- 在较低的上下文长度下,并不保证有良好的表现
结论以及如何做:
- 提示工程很重要。值得对您的提示进行调整,并进行A/B测试以测量检索的准确性
- 不能保证您的事实一定会被检索到。
- 更少的上下文 = 更高的准确性 - 这是众所周知的,但是如果可能的话,减少您发送给模型的上下文量可以增加它的回忆能力
- 位置很重要。但是放在文档最开始和文档深度50%到100%区间的事实似乎能被更好地回忆起来。
- 提示工程很重要 - 值得对您的提示进行调整,并进行A/B测试以测量检索的准确性
可以看到,Claude2.1的这个200K表现并不尽人意,更不能对它抱有过高的信任。总量达100K之后,检索成功率甚至只有50%不到。
前几天GPT4也发布了128K的版本,虽然它比Claude2.1少了近一半,但依然是个容量极大的超大杯了。我们再看看Greg Kamradt之前做的GPT4 128K的评测,来跟Claude2.1做一个横向的对比。
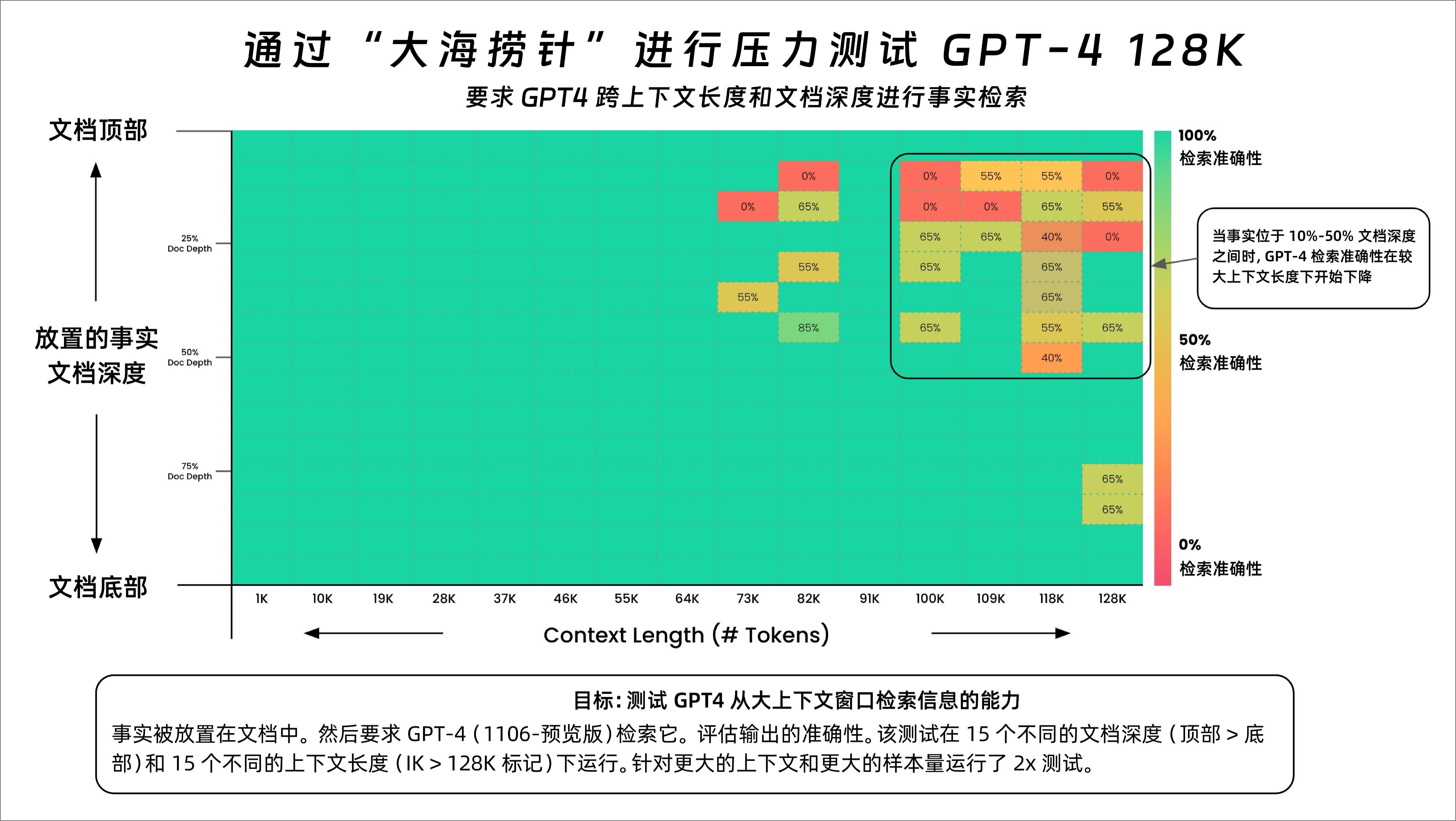
红彤彤一片。
整个检索成功率几乎都保持着成功,只有到了73K以后,在7%~50%的文档深度之间,成功率才有所降低。
可以从这个压力测试看出来,GPT4保持着遥遥领先的姿态,甩了Claude一大截。Token这个东西,容量越大当然越好,但是相应的,质量你得跟上吧。光大容量,结果掀开一看,全是冰块,那还玩个屁。
OpenAI的一出闹剧,依然改变不了GPT4在AI行业的王者地位。
希望后来者,能真正的给OpenAI一些压力。
高赞答主总结的很棒,我也看到了Greg Kamaradt这个人对Claude 2.1做的压力测试。
仅仅分享一些感想。
Claude 2.1相比于Claude2.0其实就是一个小的提升,不过从它的宣传来说,基本上是把200K Tokens当成了最大的卖点。
200k的上下文的确非常的厉害。
因为对于大模型来说,上下文长度也是一个非常重要的指标,因为这个涉及到了可以接收和处理的数据的大小。
如果上下文长度很短,只有1000个字的话,基本上稍微长一点儿的作文都处理不了,而分段多次输入的效果会大打折扣。
其次就算可以分段的多次输入,那碰到了几十万字的文章怎么办。
所以长上下文在大模型就是一个黄金指标,基本上就是越长越好。
200,000个Tokens,约等于150,000个单词或超过500页的材料。这能让你上传大型技术文档、财务报表甚至长篇文学作品,并利用Claude进行总结、问答、趋势预测、比较多个文档等任务。
基本上大多数的单个文档都能处理,特别长现阶段也不是很有必要。
但是,理想很丰满,但是很骨感。
因为Claude2.1只是宣传,它可以处理20万Tokens长度的输入,但是它并没有非常明确的说处理的效果到底如何。

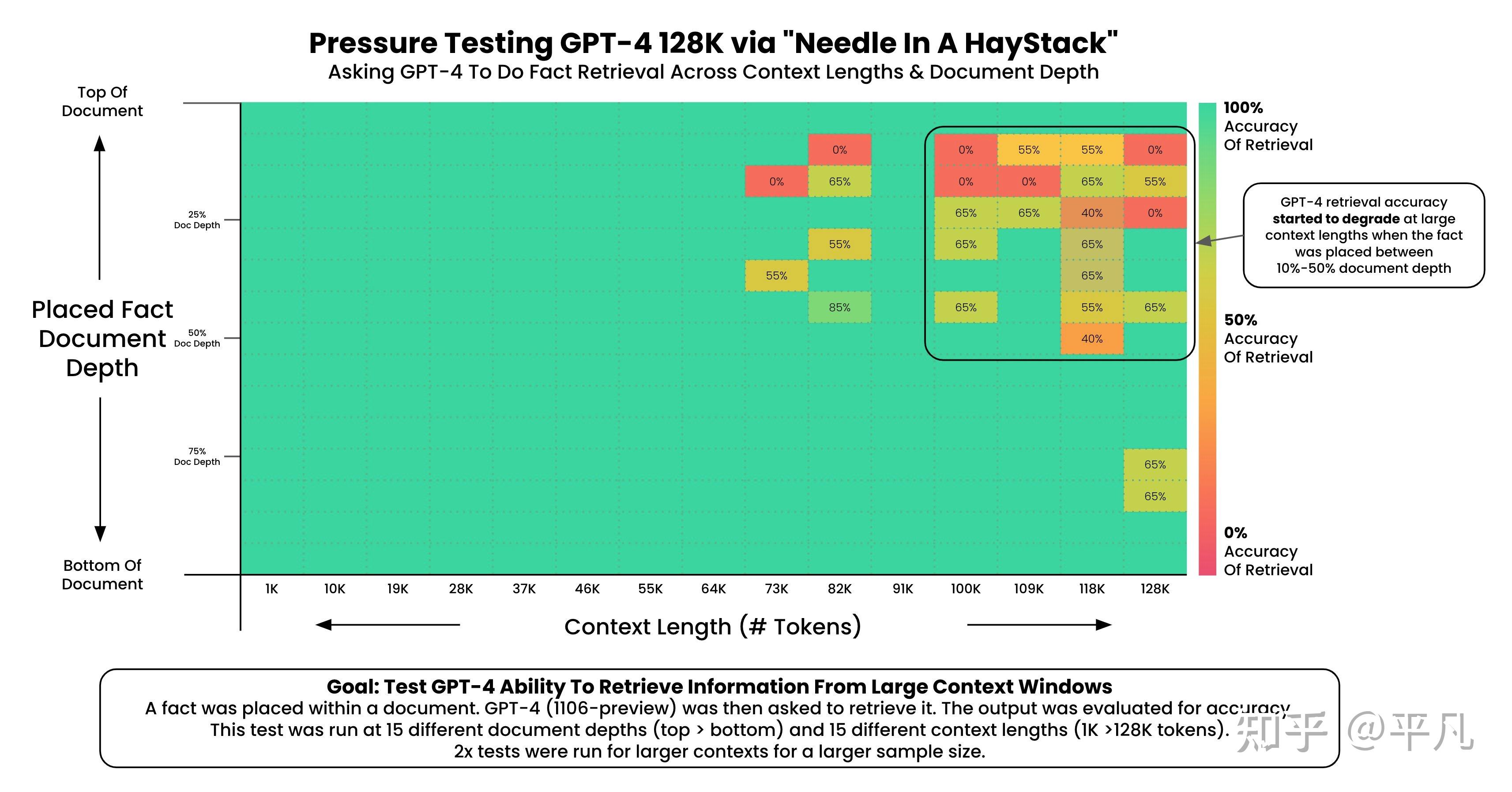
从图表的左侧可以看出,所谓的“Placed Fact Document Depth”即“放置事实的文档深度”,这表示测试中事实被放置的位置,从文档的顶部(0% Doc Depth)到底部(100% Doc Depth)。图表的底部表示上下文长度,即模型在执行任务时可以查看的信息量,从1K(1000个)Tokens到超过200K个Tokens。
颜色编码代表模型检索信息的准确率,从红色(0%准确率)到绿色(100%准确率)。可以看到,当上下文长度增加时,即横轴的令牌数量增多时,准确率普遍呈现出下降的趋势。这表明,对于Claude 2.1模型而言,在处理更长的上下文信息时,其检索特定事实的能力下降。
这就很明显的说明了一个事实,Claude2.1这个200K Tokens是一个假的特性,它根本就不成熟,完全达不到预期的效果。
不得不提一下GPT4,它的上下文长度只有128K,其实说起来要比Claude2.1小不少。但是同样的压力测试。GPT4基本上一片绿,特别是在73K以前,准确率非常非常的高。
意味着一个73K以内大小的文档,GPT4可以准确的从任意一处提取信息。
真的不比不知道,一比才发现GPT4真的很诚实,放出来的128K,那就是真的处理极限在这里。
因为如果按照Claude2.1的说法,我觉得GPT4完全可以宣传自己可以做400K的上下文处理,只不过准确率无限等于弱智一般。
Claude 2其实是很强的模型,但我不看好这次小升级。
Claude 2.1这次以200k的上下文窗口为卖点。最近一个月,我发现大模型之间开始卷上下文窗口。
例如10月底,百川智能推出的Baichuan2-192K,把上下文窗口增大到192k,一度成为当时全球上下文窗口最大的模型。当时Baichuan2-192k还拿Claude2作为对比的。
不过这个记录没保持多久。11月6号,李开复带领的零一万物团队,发布开源大模型 Yi,支持200k的上下文窗口,马上刷新了Baichuan-192K的记录。
当然,Yi的记录也仅仅保持了不到两小时。当天下午又有团队把上下**到了256K

当然,大家其实也看出来了,把上下文窗口仅仅是一个输入的大小,能接受多大的输入,取决于开发者如何定义模型而已。难的是当输入大了,模型还能保持良好的性能。
事实上,在Baichuan2-192k的一份测试报告[1]里,就已经Claude-2的结果「剧透」过了。
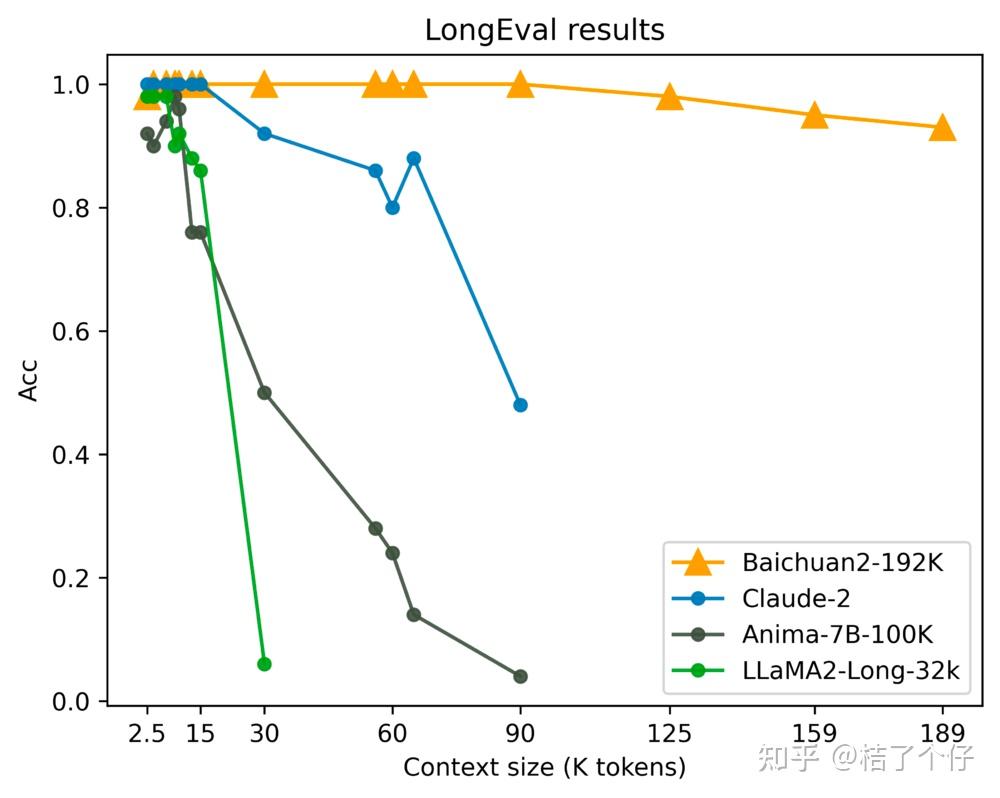
可以看到,Claude-2在上下文大小超过60k后,性能出现跳水。而Claude-2.1从版本号就能看出是一次小升级,并非全新的架构,因此直接把上下文窗口增大到200k,可能只会更暴露自己的缺点。事实上油管上也有老哥做了个测评,发现Claude2.1还不如2.0好。
虽然我也想亲自测试下Claude2.1,但想了下,只能通过API调用,还挺贵的,就作罢了。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/210566.html