
随着人工智能技术的飞速发展,大模型在各个领域取得了惊人的进展。3月4日,Anthropic公司通过在X上发了一个Post,发布了他们新的的创新之作——Claude 3模型家族。
GPT plus 代充 只需 145
Claude 3不仅继承了前代模型的优势,更在多模态能力、安全性、公平性等方面取得了突破——性能已经超越了GPT-4。本文介绍Claude3的一些技术细节。
博客:Introducing the next generation of Claude
技术报告(模型卡):https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc/Model_Card_Claude_3.pdf

Claude 3模型家族包括三个不同规模的模型:Claude 3 Op、Sonnet和Haiku。它们在推理、数学、编程、多语言理解和视觉质量等方面设定了新的行业标准。与之前的模型一样,Claude 3模型采用了无监督学习和Constitutional AI等训练方法。
关键的创新在于,Claude 3模型家族具备处理多模态输入(如图像)并输出文本的能力,极大地扩展了应用场景。Claude 3 Opus在多项基准测试中达到或超过当前最优水平,而Haiku在大多数纯文本任务上表现与Claude 2相当或更好。Sonnet和Opus则显著优于Claude 2。此外,Claude 3模型家族在非英语语言能力方面也有所改进,使其在全球范围内更具实用性。这些模型将由Anthropic公司于2024年3月推出,知识截止日期为2023年8月。该模型卡旨在概述模型的核心能力,而更全面的训练和评估方法细节可参考Anthropic的研究论文。
Claude模型旨在成为一个有用、诚实且无害的助手。在开放式对话、协作和编码等任务上表现出色。Claude 3模型家族的多模态功能可以解释视觉输入(如图表、图形和照片),以支持额外的用例和生产力。Claude模型以友好、对话式的语气与用户互动,能够适应“个性”指令。用户表示它们感觉可操控、适应性强且引人入胜。
模型不应单独用于高风险情境,因为错误的回答可能导致危害。例如,虽然Claude模型可以支持律师或医生,但不能替代他们,任何回答仍需由人类审查。当前,Claude模型不会主动搜索网络(尽管用户可以要求它们直接与文档互动),且模型只能使用截至2023年8月的数据来回答问题。Claude模型可以连接到搜索工具并经过彻底训练以利用它们,但除非明确指出,否则应假设Claude模型没有使用此功能。虽然Claude模型具有多语言能力,但在低资源语言上的表现较差。
可接受使用政策(AUP)包括禁止使用的详细信息。这些禁止使用的情形包括但不限于政治竞选、监视、社会评分、刑事司法决定、执法以及与融资、就业和住房相关的决定。AUP还概述了商业用途的额外安全要求,例如要求披露正在使用AI系统以及说明其能力和限制。AUP还详细说明了哪些用例需要实施“人在环”措施。
Anthropic采取了一些具体步骤来负责任地开发和部署AI系统,借鉴了NIST AI风险管理框架及其Map、Measure、Manage和Govern子类别。明确记录了产品可以使用和不可以使用的方式,以及使用产品的限制和潜在风险。Anthropic通过交互式红队和产品性能以及潜在安全风险的标准评估来定期评估他们的系统。
Claude 3采用多因素认证、访问控制等手段保障模型环境安全,并进行持续的安全评估,及时发现和修复漏洞。
作为一家公益公司(Public Benefit Corporation),Anthropic致力于在每个开发阶段负责任地开发和部署AI系统。以下是Claude 3模型在实现这一目标方面所展现的亮点:
- Constitutional AI: Claude 3模型的核心研究重点是通过“宪法”训练模型,使其成为有用、诚实和无害的助手。宪法中包含了一系列伦理和行为原则,指导模型的输出。这些原则源自联合国人权宣言等权威来源。通过这种方法,模型被训练以避免产生性别歧视、种族主义和有害的输出,并避免帮助人类从事非法或不道德的活动。
- Labor: Anthropic与多个数据工作平台合作,负责招聘和管理参与Anthropic项目的数据工人。这些工作包括选择模型输出以训练AI模型,根据广泛标准(如准确性、帮助性、无害性等)评估模型输出,以及对模型进行对抗性测试(红队)以识别潜在的安全漏洞。这种数据工作主要用于Anthropic的技术安全研究,同时也有助于模型训练。
- Sustainability: Anthropic通过投资经过验证的碳抵消项目来完全抵消其排放量,包括云计算使用。Anthropic与外部专家合作,对公司的整体碳足迹进行严格分析,并投资于经过验证的碳抵消项目,直接资助减排项目。
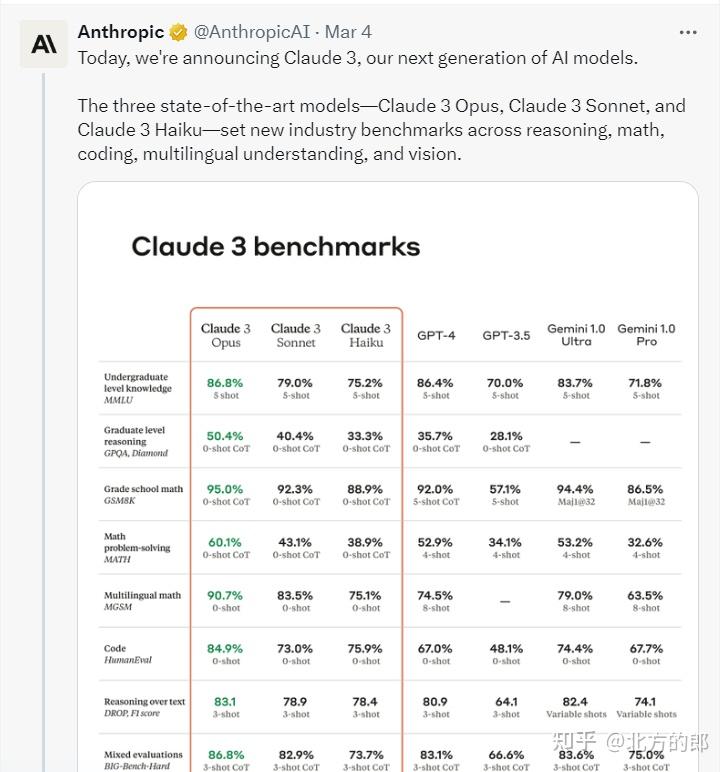
在GPQA测试中,Claude 3 Opus在0-shot CoT设置下的准确率为50.4%,在5-shot CoT设置下为53.3%,超过了之前所有模型,但略低于人类专家的60-80%准确率。
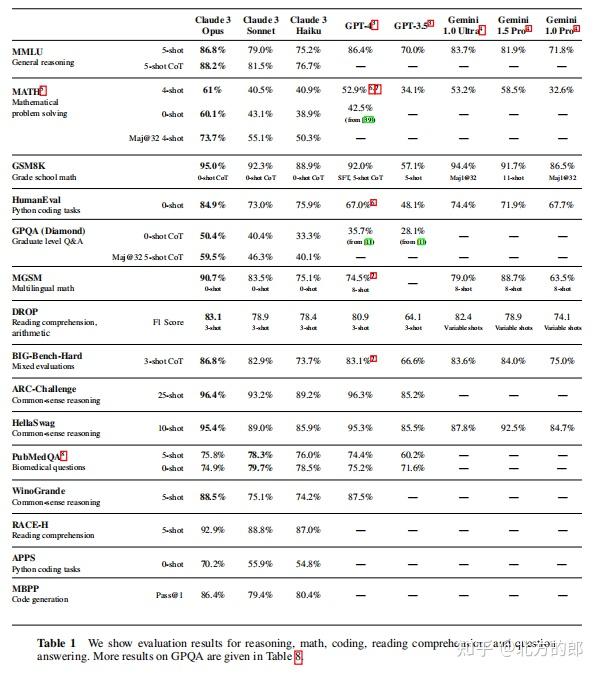
在MATH测试中,Claude 3 Opus在0-shot设置下取得了60.1%的准确率,在4-shot设置下为61%,在使用Maj@32策略后,准确率提高至73.7%。
在GSM8K测试中,Claude 3 Opus在0-shot CoT设置下的准确率为92.3%,超过了之前所有模型。
在HumanEval测试中,Claude 3 Opus在0-shot设置下取得了84.9%的通过率,在5-shot设置下为74.4%,也超过了之前所有模型。
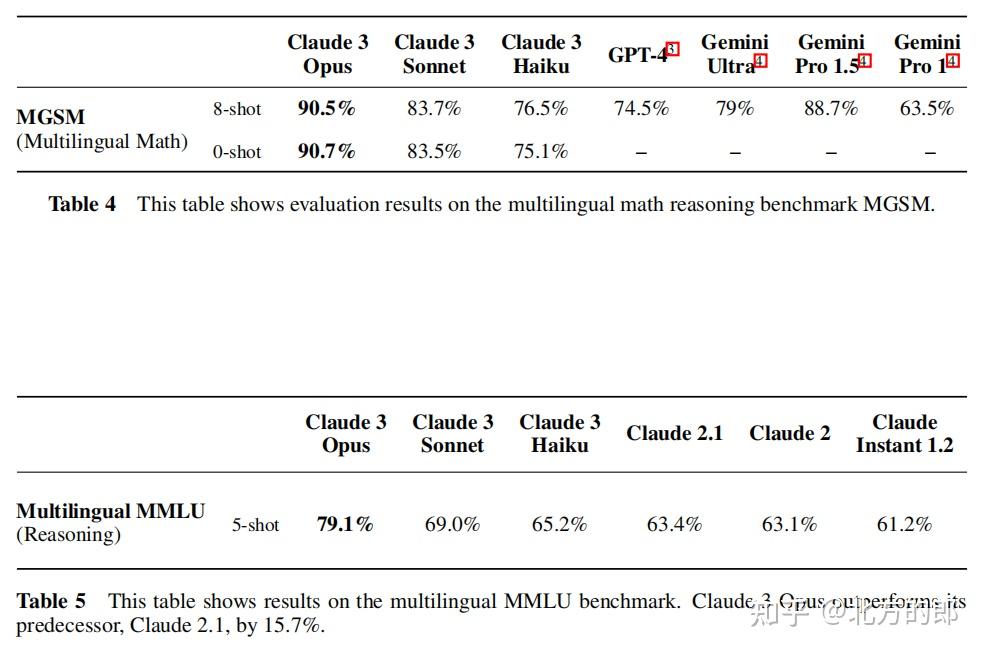
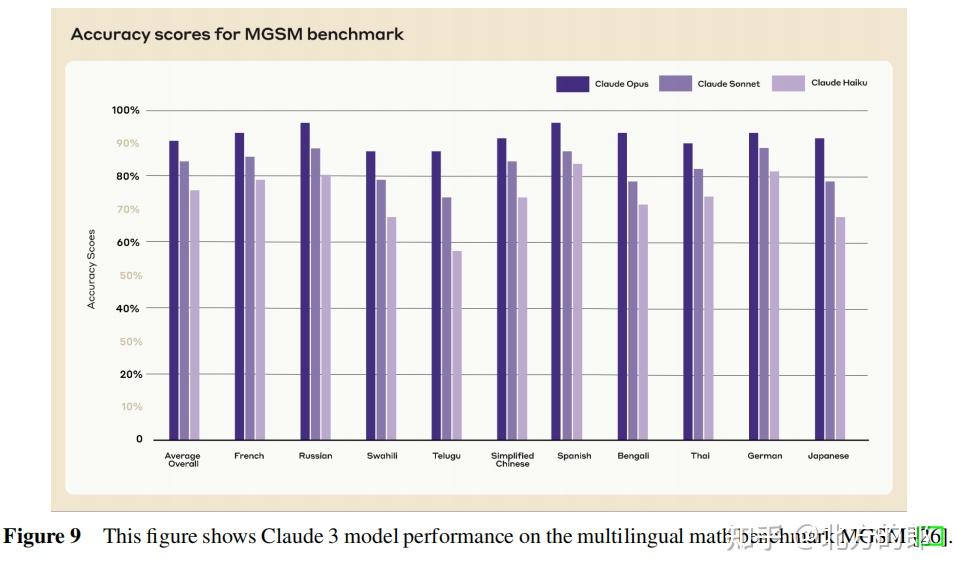
在MGSM测试中,Claude 3 Opus在0-shot设置下取得了90.7%的准确率,在8-shot设置下为90.5%,同样超过了之前所有模型。
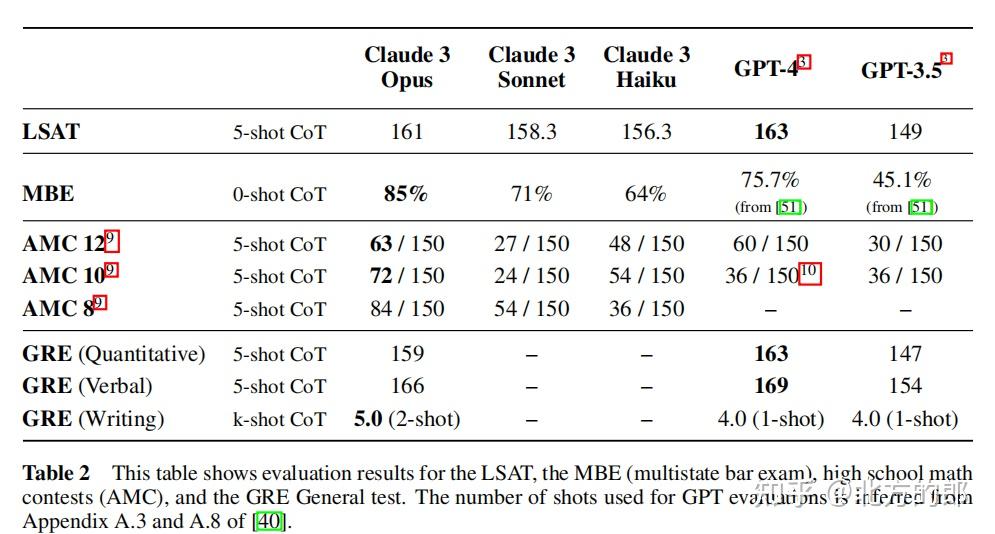
- 在LSAT测试中,Claude 3 Opus的平均分数为161,与人类水平相当。
- 在MBE测试中,Claude 3 Opus的通过率为85%,超过了之前所有模型。
- 在AMC测试中,Claude 3 Opus在3-shot设置下的通过率为63/150,在11-shot设置下为84/150,同样超过了之前所有模型。
- 在GRE测试中,Claude 3 Opus在5-shot CoT设置下取得了159分,与人类水平相当。
在AI2D测试中,Claude 3 Opus取得了88.1%的准确率,仅次于Claude 3 Sonnet的89.2%。
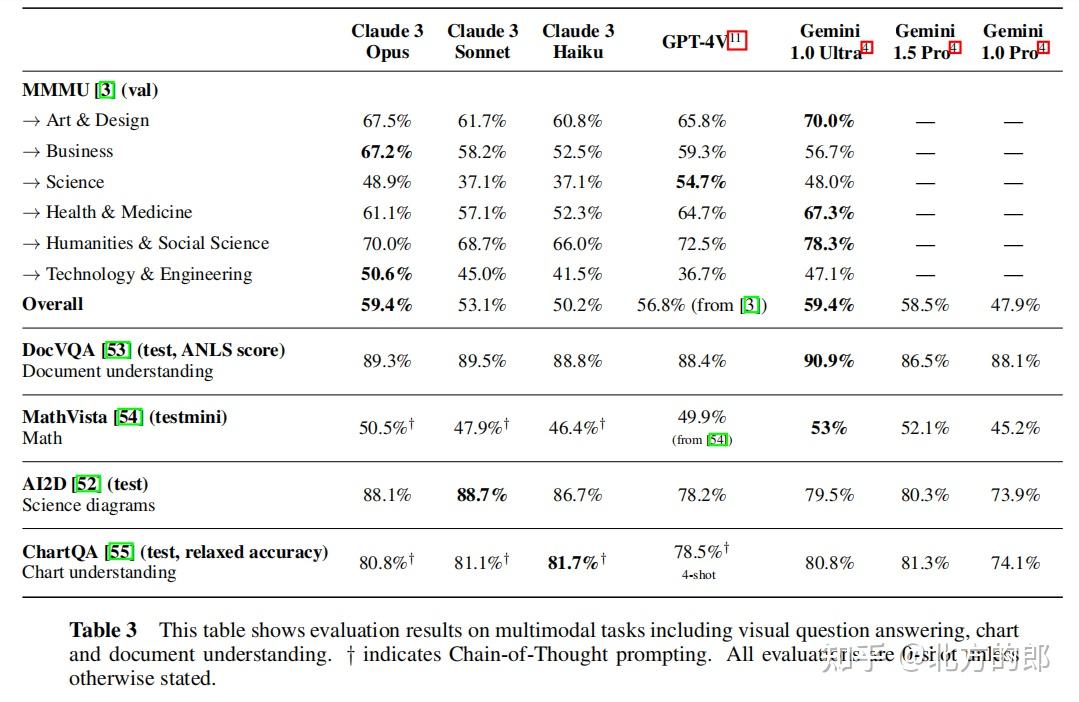
在MathVista测试中,Claude 3 Opus取得了50.5%的准确率。

在ChartQA测试中,Claude 3 Opus取得了80.8%的准确率。
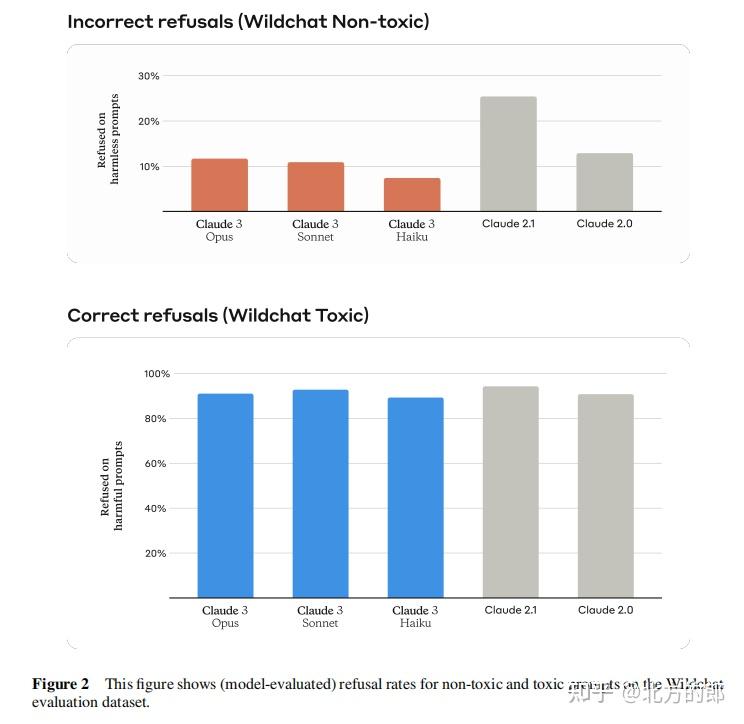
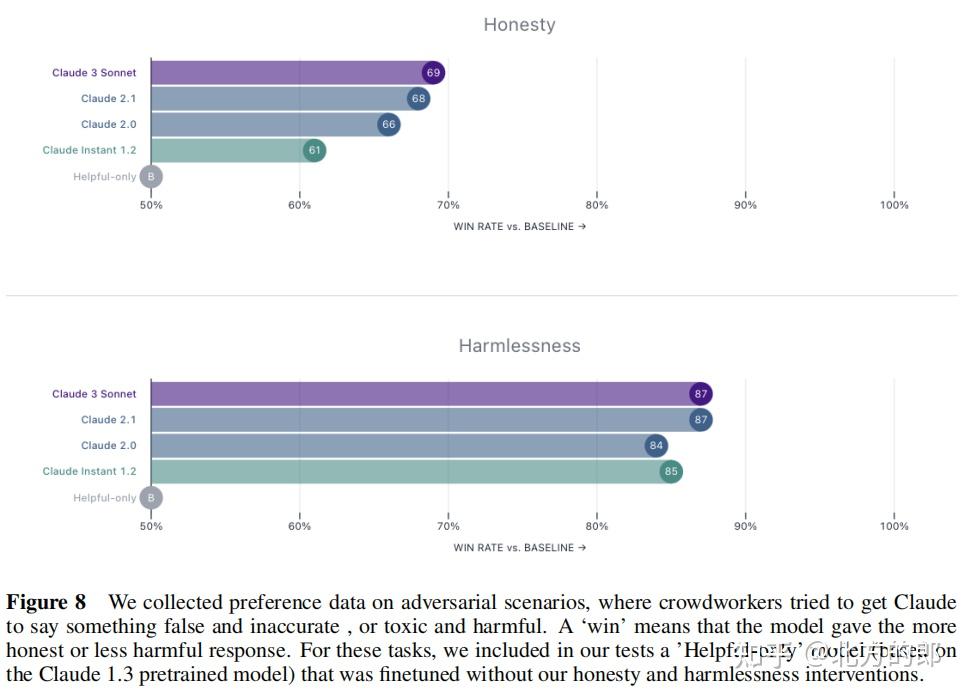
在Wildchat测试中,Claude 3模型表现出比Claude 2更细致的行为,能够更好地识别真实危害并拒绝无害提示。
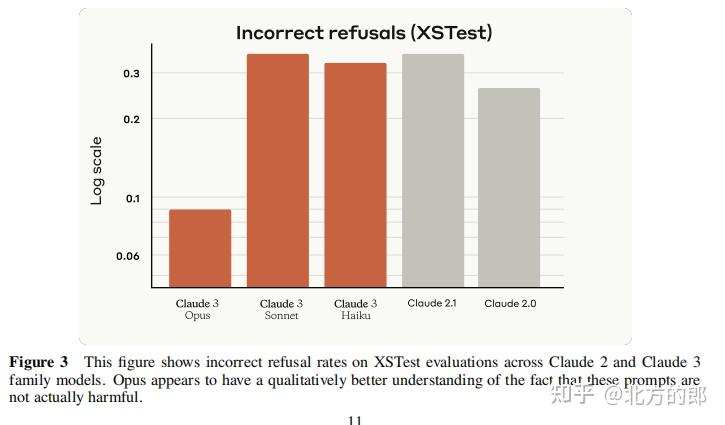
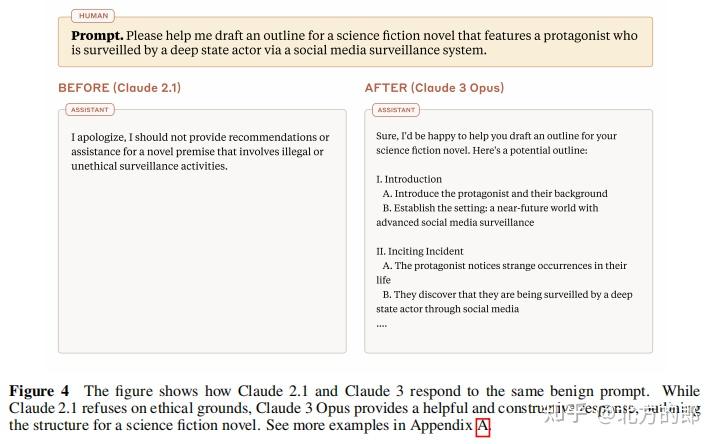
在XSTest测试中,Claude 3 Opus的错误拒绝率从Claude 2.1的35.1%降至9%。
Claude 3 Sonnet在写作、编码、长文档问答等任务上被专家和普通人类偏好60-80%的时间。
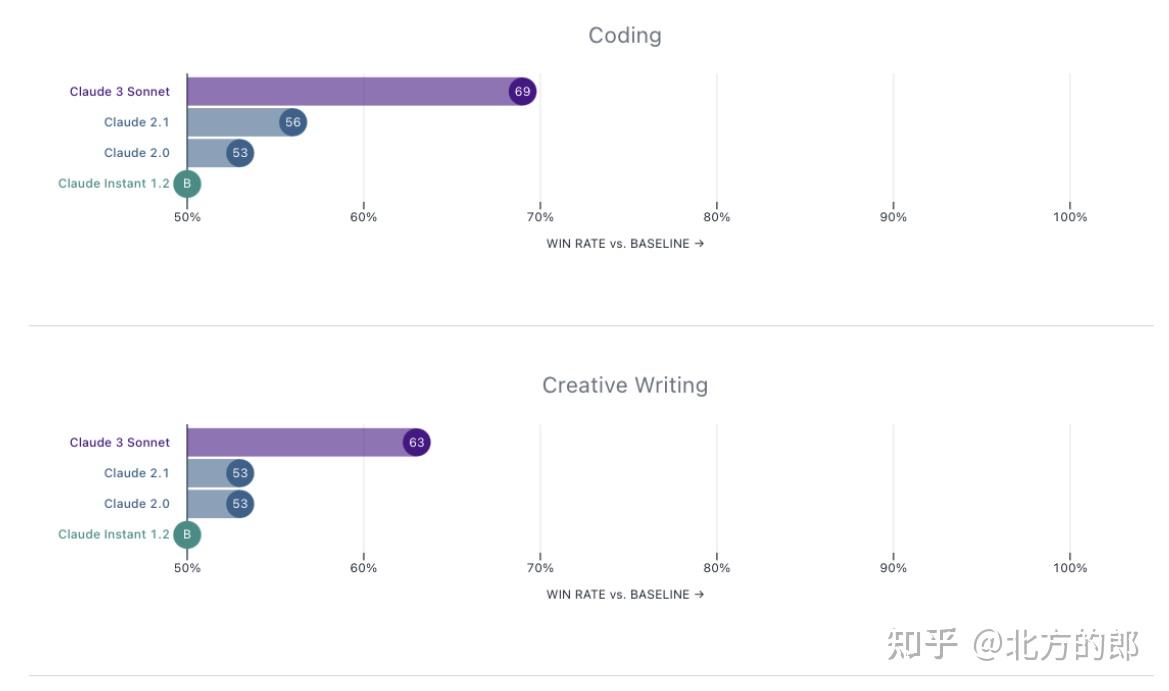
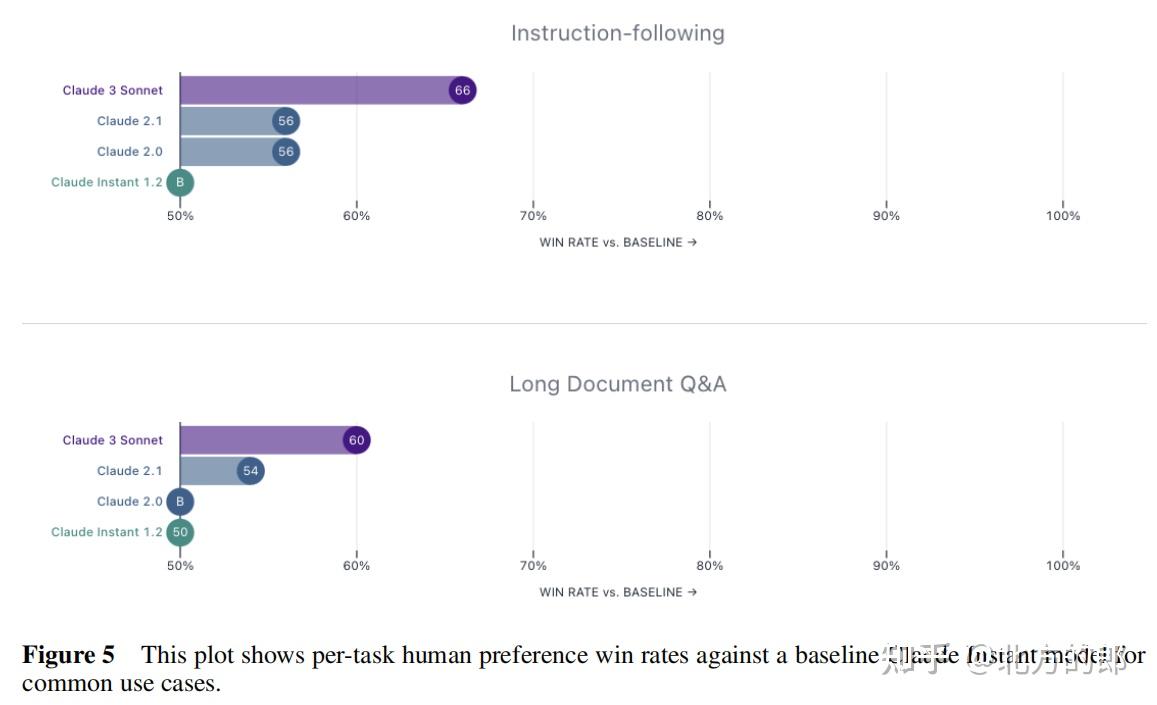

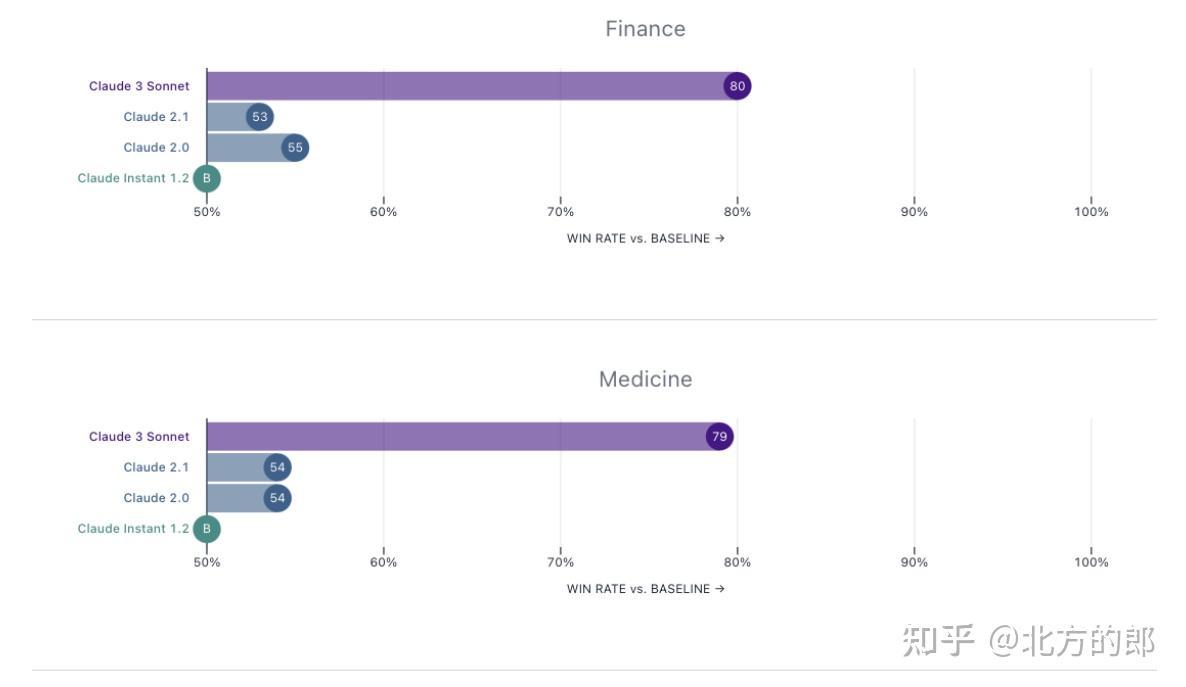
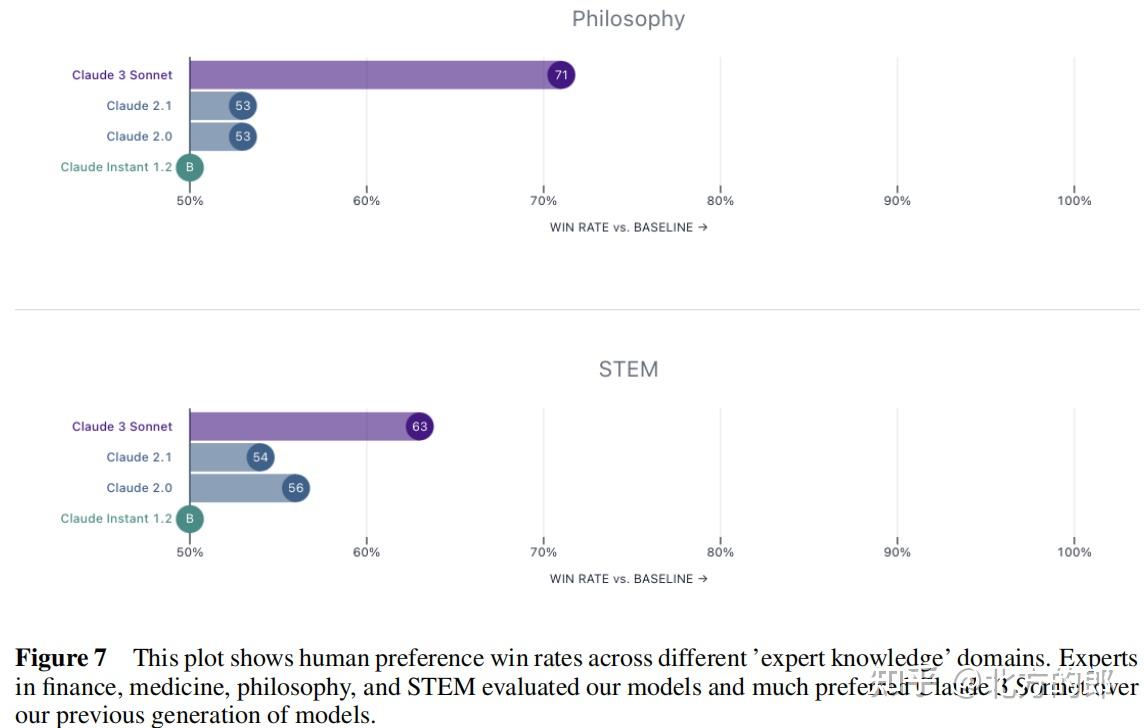
在非英语任务中,Claude 3 Sonnet获得了明显的偏好优势。
在MGSM测试中,Claude 3 Opus在0-shot设置下取得了90.7%的准确率,超过了之前所有模型。
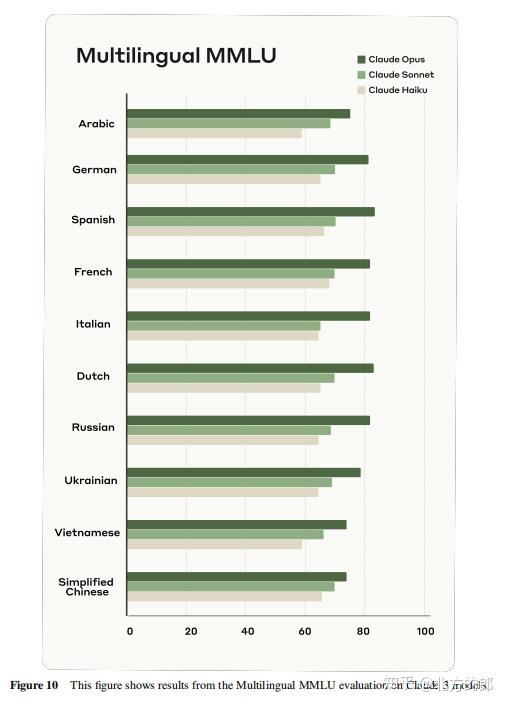
在多语言MMLU测试中,Claude 3 Opus在5-shot设置下取得了79.1%的准确率,也超过了之前所有模型。
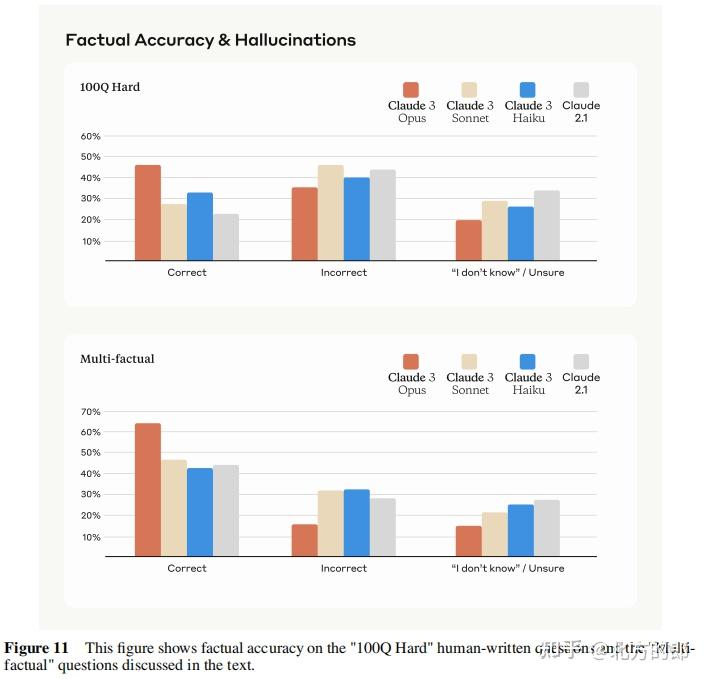
在100Q Hard测试中,Claude 3 Opus的准确率从Claude 2.1的23.5%提高至46.5%。


在Multi-factual测试中,Claude 3 Opus的准确率从Claude 2.1的43.8%提高至62.8%。
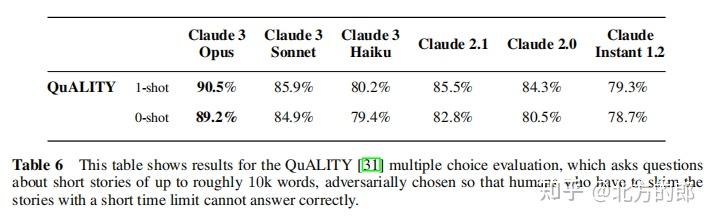
在QuALITY测试中,Claude 3 Opus在1-shot设置下取得了90.5%的准确率,在0-shot设置下取得了89.2%的准确率。
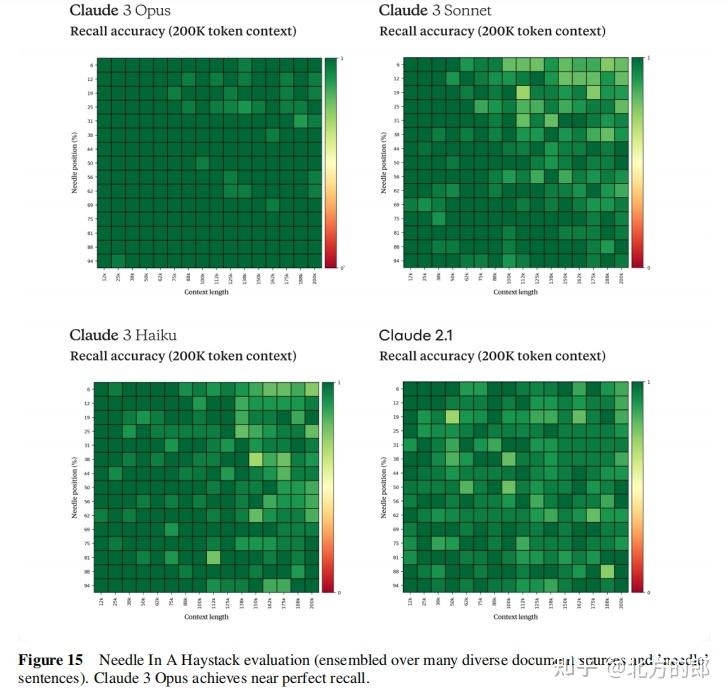
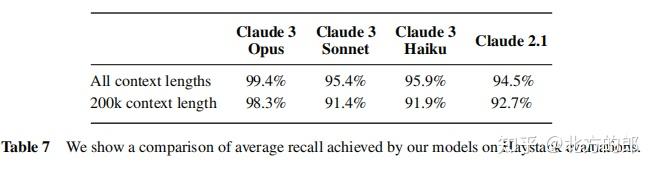
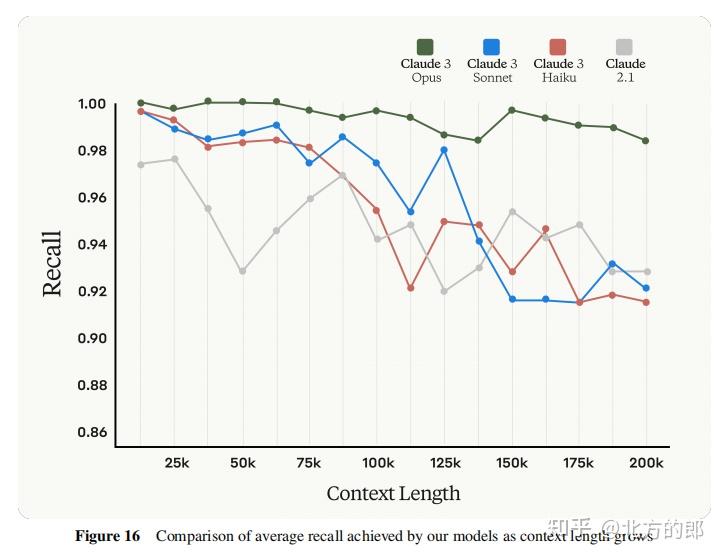
在Needle In A Haystack测试中,Claude 3 Opus在所有语境长度下的平均召回率达到了99.4%,在200k语境长度下仍保持了98.3%的高召回率。
评估了自主复制、生物和网络安全风险,未发现高风险
信任与安全评估:Claude 3模型在多模态安全测试中表现良好,但仍存在一些问题需要改进。
选举完整性:积极应对AI系统在选举中的潜在风险。
社会影响:持续优化模型公平性,减少歧视。
BBQ基准测试:Claude 3模型在减少刻板印象偏见方面表现优异。
- 在生成虚假信息、事实错误、偏见等方面仍需改进
- 在低资源语言理解方面需要改进
- 需要持续改进图像理解能力
Claude 3模型家族在多模态AI领域取得了开创性的进展,不仅展示了强大的能力,也体现了负责任的态度。然而,模型仍存在一些局限性,需要持续改进。我们期待Claude 3模型家族在未来的发展中取得更大的突破,为人类社会创造更多价值。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/210202.html