
号称ChatGPT“最强竞争对手”的Claude,今天迎来史诗级更新——
模型记忆力原地起飞,现在1分钟看完一本数万字的小说,已经不在话下。
讯享网
消息一出,评论区直接炸了,网友们蜂拥而至,“woc连连”:
疯了疯了!
事情进展得太快了,又是为人类担心的一天!


原来,这次更新,将模型的上下文窗口token数提到了足足10万,相当于7.5万个单词!
这意味着,大模型“记性”不好的缺陷现在得到补强,我们可以直接丢给它上百页上万字的材料,比如财报、技术文档甚至是一本书。
而它都能在一分钟之内帮你分析总结完毕!
要知道,之前市面上几乎所有AI聊天机器一次都只能读取有限数量的文本,理解长资料里的上下文关系非常灾难。
而我们人类自己去处理大篇幅的文本又太慢了,比如光是要读完10万token的材料,就需要大约5个多小时,更别提还要花更多的时间去理解去消化才能进行总结。
现在,Claude直接一把搞定。
这波,简直是“五雷轰顶”、“反向开卷”GPT-4,因为,刚刚后者也不过才做到3.2万token。
一次10万token!GPT4最强对手史诗升级,百页资料一分钟总结完毕Claude已经能够支持100K的上下文token长度,也就是大约75,000个单词。
这是什么概念?
一般人用时大约5个小时读完等量内容后,还得用更多的时间去消化、记忆、分析。
对于Claude,不到1分钟就搞定。
把「了不起的盖茨比」整本书扔给它,大约有72k token,并将其中的一句话进行改动:
Mr. Carraway是一个在Anthropic从事机器学习工具的软件工程师。
你敢相信?Claude仅花了22秒,就把改动的这句话找出来了。
众路网友纷纷表示,有了Claude 100K,手里的GPT-4 32K已经不香了。

Claude 100k,倍儿香!
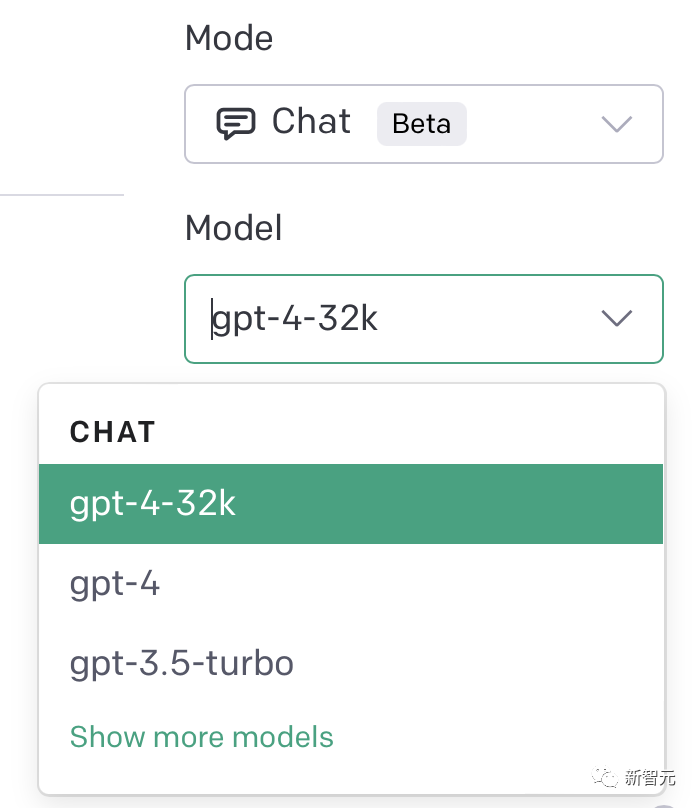
前段时间,在OpenAI的开发者社区中,许多人讨论GPT-4 32K正在推出。

而且,不少GPT-4的用户已经可以在自己的PlayGround上看到GPT-4 32k的选项。
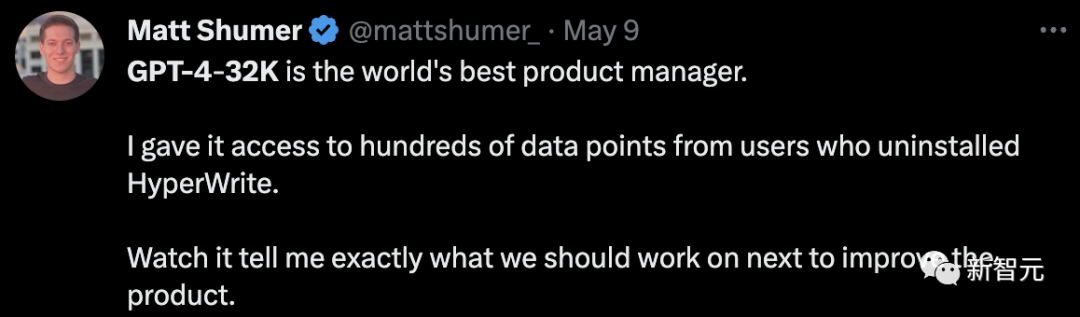
已经解锁这一版本的网友,让其访问了数百个来自卸载HyperWrite用户的数据点,GPT-4便准确地告诉他接下来该做怎样的改进。
他称赞道,GPT-4 32k是世界上最好的产品经理。
32k都这么厉害了,那么,有了100K岂不更强了。
显然,OpenAI的强大对手Anthropic最先占据了优势。
100K token的上下文长度,意味着,你可以在Claude上传数百页的文本分析。并且对话的持续时间也被大大拉长,延长到数小时,甚至数天。
当然,除了长文本阅读之外,Claude还可以从文档中快速检索出你所需的信息。
你可以把多个文档,甚至一本书的内容当作prompt,然后提问。
以后遇到论文,甚至巨长篇幅的直接让Claude总结吧,这简直就是啃论文后辈们的福音。
这种综合性的问题通常需要对文本中很多部分的内容有一个全面的认识,而在处理这种问题上,Claude可以说要比基于向量搜索的办法要强。

Claude还可以是你的「代码伴侣」,分分钟就能做个演示。
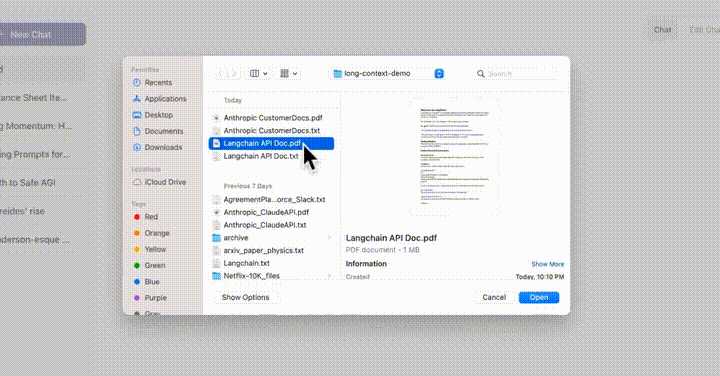
比如,上传一个240页的Langchain API文档,让它基于这个文档,用Anthropic的语言模型做一个Langchain的简单演示。
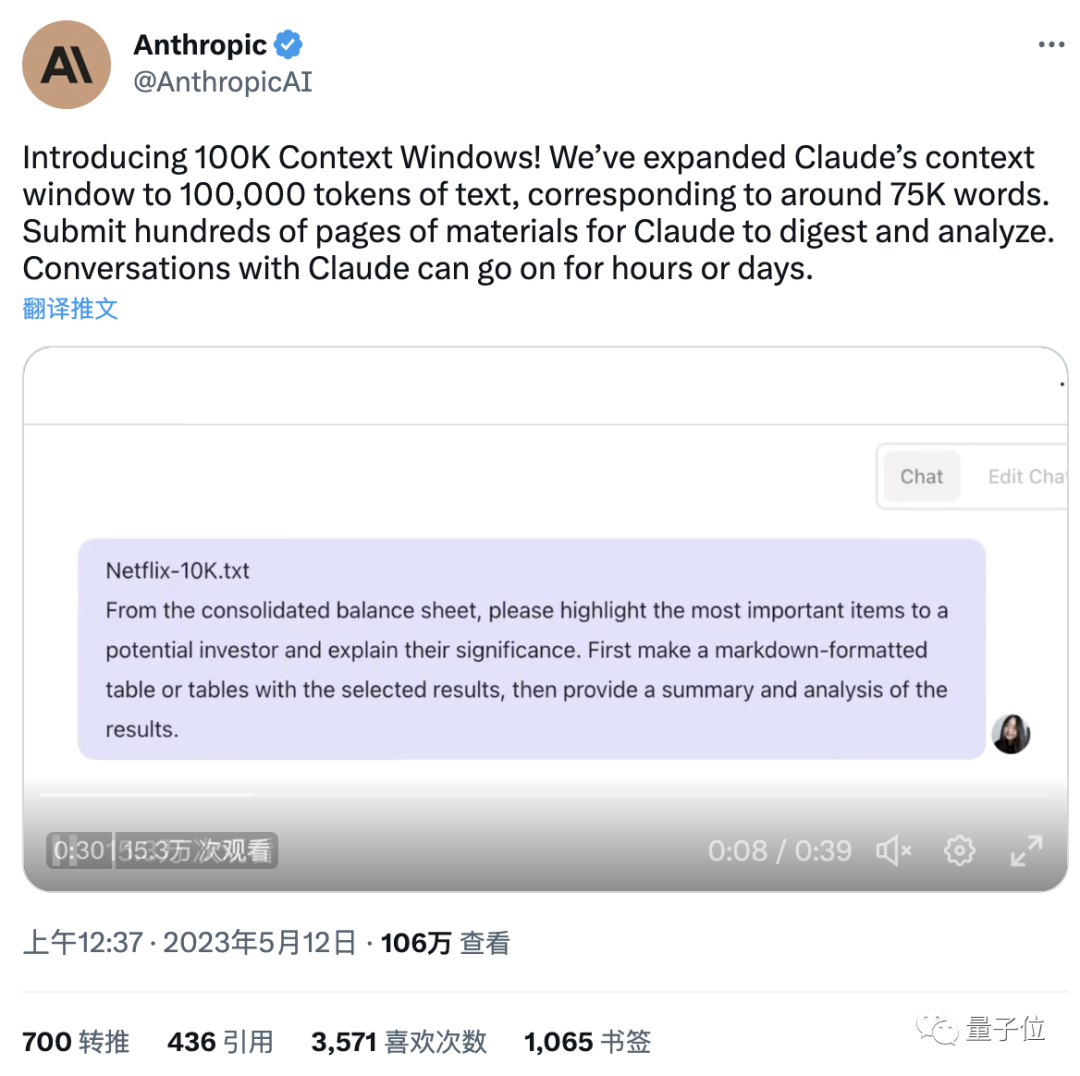
还可以把85页的公司年度报表(10k)喂给Claude。
然后,要求突出对潜在投资者最重要的项目,并解释其重要性。
此外,Claude 100k还能处理大约6小时的音频量。
比如说,AssemblyAI把一个卡马克的播客的内容转录成了58k个token量的文本,然后用Claude进行了总结和问答。
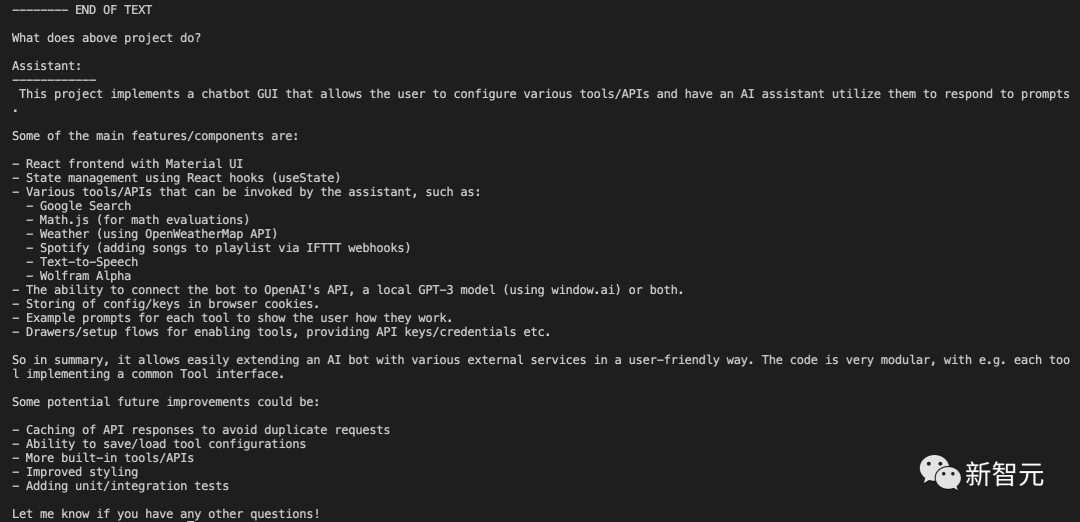
最后,Claude总结了一下自己能干的事,覆盖可以说是非常全面了。
- 理解、总结和解释密集的文件,如财务报表、研究论文等
- 根据年报分析公司的战略风险和机遇
- 评估一项立法的利弊
- 识别法律文件中的风险、主题和不同形式的争论
- 阅读数百页的开发文档,回答技术问题
- 通过将整个代码库放入上下文中,并智能地构建或修改它来快速制作原型
当然,现在,Anthropic表示100K上下文还是一个测试版功能,在此期间将按照标准API定价来收费。

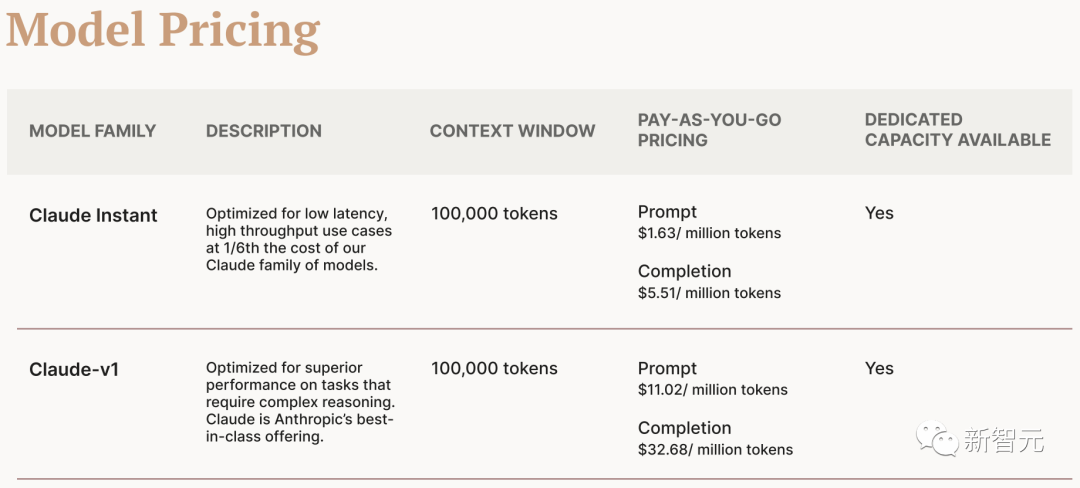
官网也给出了具体价格:
Claude Instant
Prompt:\(0.00163 / 1K tokens</p><p data-pid="C7CG7tHo">Completion:\)0.00551 / 1K tokens
Claude-v1
Prompt:\(0.01102 / 1K tokens</p><p data-pid="OrtCWl4i">Completion:\)0.03268 / 1K tokens
比起OpenAI,这价格已经非常亲民了。
据OpenAI官网,GPT-4 32k的Prompt需要\(0.06,Completion需要\)0.12。
相当于,你得花5-6倍的价格给模型prompt。


网友称,Claude 100k比GPT-4 32k更快速、更便宜。

网友实测
这么重磅级的更新,一定少不了网友的体验。
有网友称100k简直难以置信,能够处理多篇完整的论文,部分完整的代码库,甚至一本250页的小说。

顺便提一句,许多网友最先用Claude测试了一番,发现效果还不错。
最初,100K仅限在API中,Claude应用的默认模型仍然是9K。但很快,Claude应用界面也支持100K了。
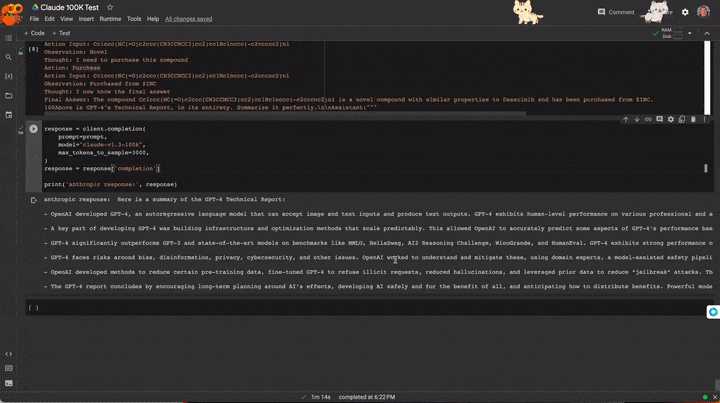
一位网友用100页的「GPT-4技术报告」测试,结果只能用amazing来形容。
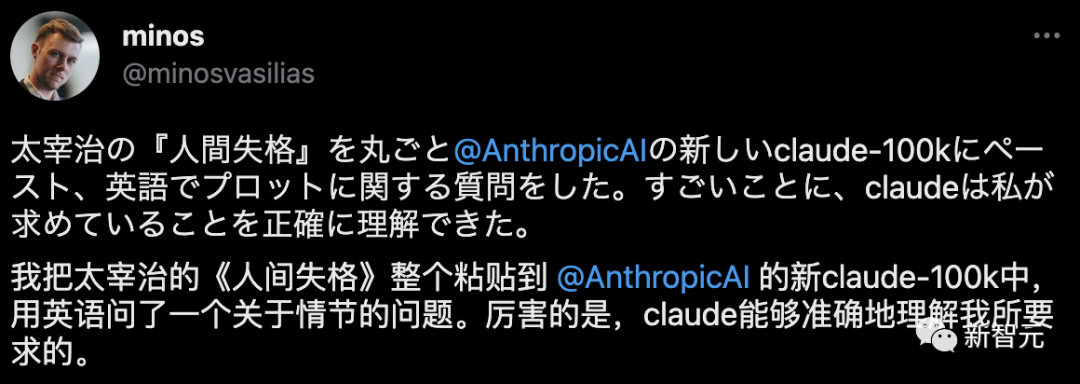
还有人直接把太宰治的「人间失格」喂给了Claude,并用英文问故事中情节,完全给出了准确的回答。

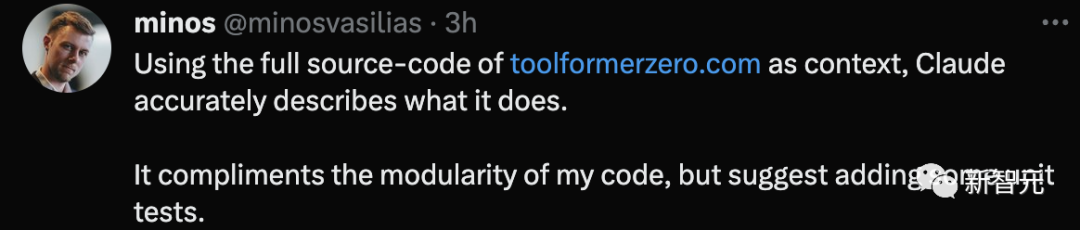
同时,这位网友把自己开发的Toolformer Zero完整源代码丢给它,Claude精准描述出这是用来做什么。
并且,Claude还称赞了代码的模块化,提供增加一些单元测试的建议。
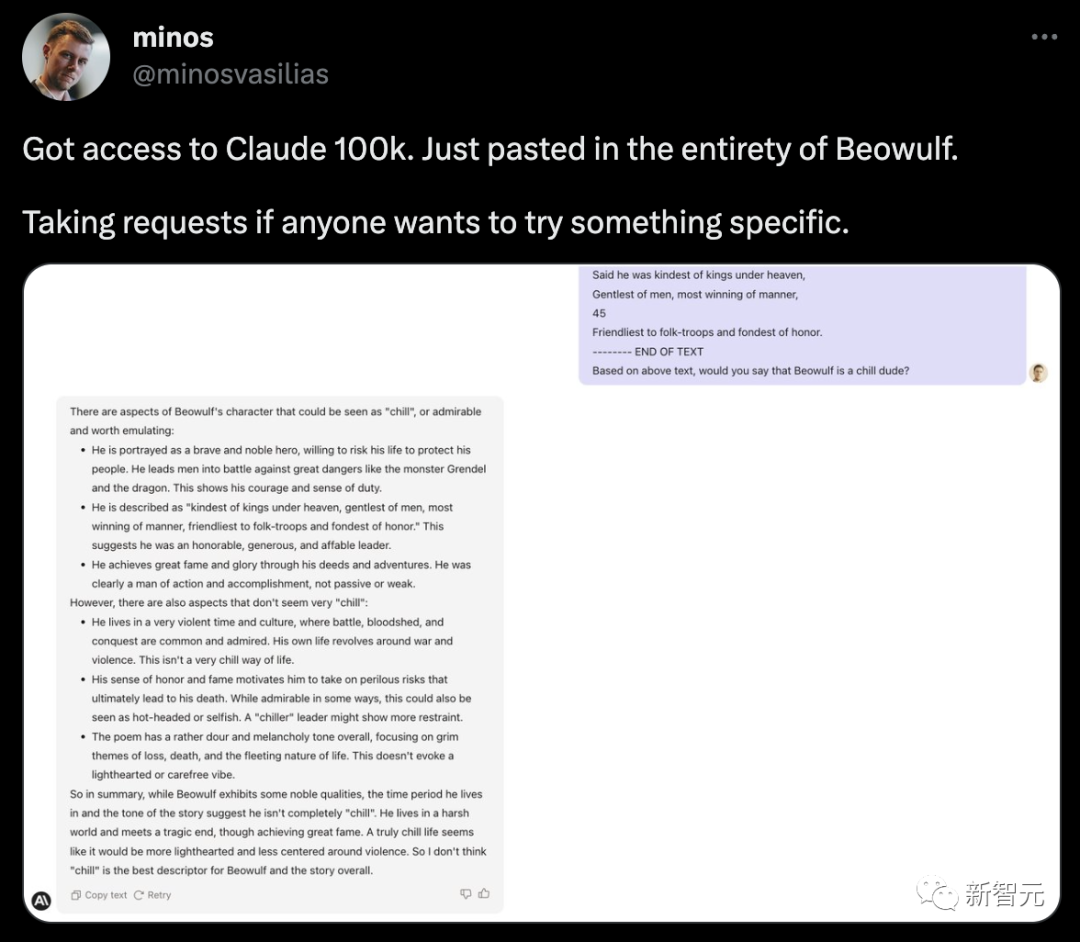
把「贝奥武夫」诗扔进去,分析下贝奥武夫这个人物性格,也是非常准确。
英伟达科学家Jim Fan表示,这是Anthropic抛出的杀手锏。未来在上下文长度的军备赛正快速升温。

对于支持100k的意义,网友称,泰裤辣!这很好地展示了为什么长文本对LLM很重要。

还有好多网友纷纷暗示GPT-4。
Claude-100K的诞生,让AnthropicAI正式成为OpenAI的真正竞争者。
「许多人还在排队等候32k的GPT-4。这次,Claude将上下文窗口扩展到10万token,直接大幅跃升。
这也意味着包括OpenAI、谷歌在内的公司都要在这一领域竞争,这对用户来说是一个巨大的胜利。」

还有网友感慨时代进步太快了。
谷歌宣布PaLM 2擅长高级推理任务不到一天,而Anthropic的Claude现在可以在不到一分钟的时间内消化10万个token。人工智能的进步确实令人瞩目。


不过,如果你输入的token少于9K,Antropic调用的似乎就是之前的模型了。

百万token,不是梦
过去几年,斯坦福大学Hazy Research实验室一直在从事一项重要的工作,就是增加模型的序列长度。
在他们看来,这将开启机器学习基础模型的新时代。
研究人员在22年提出的FlashAttention算法证明了32k可行性。
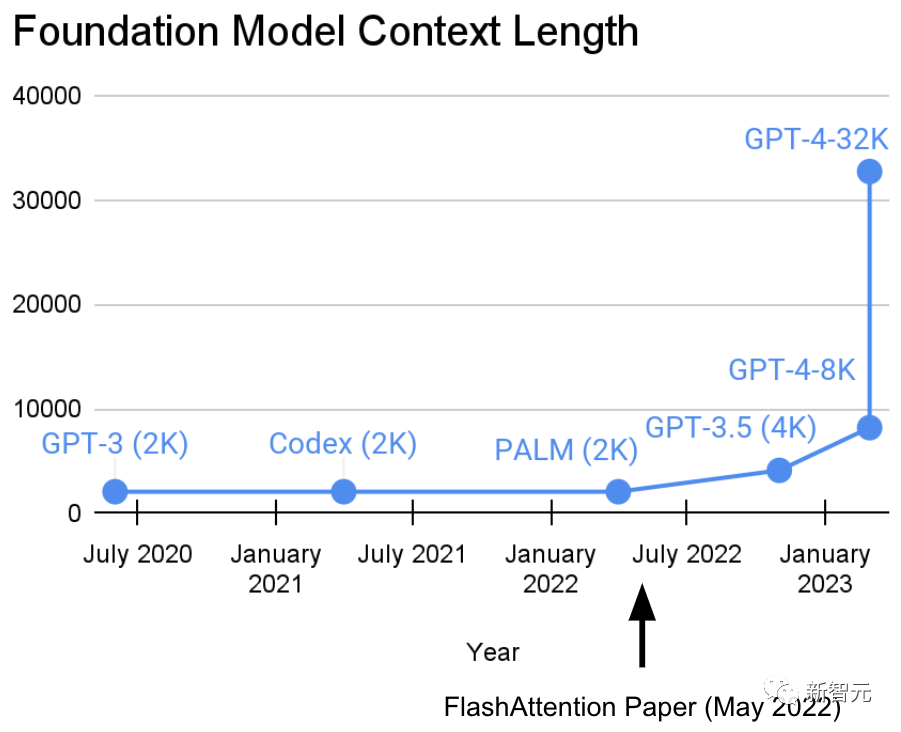
就连Sam Altman称我们要的是32k token。

其实,不仅是32k,现在100k都实现了,百万token也不远了。
「绝对太野了!几年后,支持100万的token上下文长度会不会成为可能?」

前段时间,来自DeepPavlov、AIRI、伦敦数学科学研究所的研究人员发布了一篇技术报告,使用循环记忆Transformer(RMT)将BERT的有效上下文长度提升到「前所未有的200万tokens」,同时保持了很高的记忆检索准确性。

论文地址:https://arxiv.org/abs/2304.11062
该方法可以存储和处理局部和全局信息,并通过使用循环让信息在输入序列的各segment之间流动。
不过,虽然RMT可以不增加内存消耗,可以扩展到近乎无限的序列长度,但仍然存在RNN中的记忆衰减问题,并且需要更长的推理时间。
实际上,RMT背后是一个全新的记忆机制。
具体操作方法是,在不改变原始Transformer模型的前提下,通过在输入或输出序列中添加一个特殊的memory token,然后对模型进行训练以控制记忆操作和序列表征处理。
与Transformer-XL相比,RMT需要的内存更少,并可以处理更长序列的任务。
当然,在最终实现百万token之前,Claude 100k已经是相当大的起步了。
参考资料:
https://www.anthropic.com/index/100
我觉得现在这种宣传没什么意义,关键的都不说,例如机器总结与人类总结,以及特定某个人的总结,这些能一样吗?
别为了成功而成功,得脚踏实地做事,如果用户完全不懂原理,那就是肯定没法用,所以讲清楚原理是非常重要的。
首先,大家要搞明白总结不能代替阅读,就像“不懂原理就不会应用”这句高度浓缩的语句能被很多人看懂,但基本上没几个人能回答出来为什么一样,总结只有在读者充分了解原文内容的情况下才有效,否则肯定会产生误导或误解。
现在网上的一些思路是先浓缩了再说,等读者发现问题了,再由AI作出解答。这个思路是有漏洞的,因为前提是读者要有发现问题的能力,而浓缩总结本来就是有损加密过程,肯定会造成信息损失,而读者不可能对已经损失的信息有察觉问题的能力,AI在读者没察觉的情况下又不可能主动找补,所以误导在所难免。
因此,所谓让AI读完一本书,然后让它总结给你看来节省时间,这个说法是肯定有偏颇的。
然而,从日常生活当中,我们会发现很多文章写的内容都很类似,或者说直接就叫水文吧,实际阅读的时候并不需要针对全往篇文章内容进行详细阅读,可以只针对文章内的关键字进行快速阅读,所以总结在针对这些类似的内容上会显得非常有效。
由些可见,总结的有效范围关键还得看读者是否具有类似经历,不一定是看过类似的文章,可以是有过类似的经历。
举个例子,当读者明白1+1=2时,他能很容易理解2+2=4,但如果他本来就只懂1+1=3,那么你给他解释2+2=4就半天都解释不通。
让AI生成有针对性可读的总结内容,就必须对读者的过往经历有所了解,但从现在市场上任何的宣传都没有这部分内容,这说明现在的AI开发并没有在信息技术原理上论证过可靠性,只是希望以通识来蒙混过关。
可是我们也不能忽视用户的使用体验,毕竟大家只想要个总结,可不想AI给问这问那的,这个应用流程该怎么改还有待思考。
就目前这样的发展思路看,该“总结”功能的开发在短期内仍不可能具有可靠性(并不是说它写出来的东西完全不能读,但很难说到底漏了或多了什么,它针对的服务人群也很难给出明确定向),建议在使用的时候不要轻信,否则很容易被诱导进信息茧房。
我说几个实在点的影响吧。
1.淘宝资料商家的噩梦。
现在淘宝上(包括dd,JD等)都有一些商家收集一些电子资料,然后一块两块的卖出去,如果想要高精版本,就入个店铺会员或者加个扣费资料群。别小看这一块到十块的生意,我前端时间无聊用python做了个爬虫,然后开了一个这样的小店,一个月进账一千多(◦˙▽˙◦)。
现在如果人手一个claude,人还需要去你淘宝店进货?你来我这进货还差不多!
2.伪原创雇主的噩梦。
伪原创,国内加工价格极低,百字一元。现在人手一个claude,别说百字一元,你就百字一毛,我也能薅到你破产。
3.网文借鉴流写手的福音。
前段时间我用cpt写小说,成功从番茄网薅到两百块钱,用时两个月,每天连载6000字,其中5900字是机写,我就改了标题和部分生硬机翻。
如果有人可以使用脚本多开,em
4.标书行业的噩梦。
不夸张的说,现在的标书同质化非常严重,如果一个有经验的人,可以使用claude分分钟复制几千个用着还行的标书出来。
以前一个再不咋滴的标书500代工,现在人手一个claude,5毛,不能再多了
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/209870.html