
讯享网

国外大模型巨头Anthropic终于推出了可以推理的大模型Claude 3.7 Sonnet,最大的亮点是业界首个混合推理模型。
 https://www.zhihu.com/video/
https://www.zhihu.com/video/ 什么是混合推理模型?简单来说,就是模型即可以以常规方式快速回答,又可以深度思考后给出答案。Claude 3.7 Sonnet集普通大语言模型和推理模型于一体,可以这样说,Claude 3.7 Sonnet相当于DeepSeek V3和DeepSeek R1的混合体。这是一种全新的设计理念,也符合人类的大脑能力,因为我们可以使用同一个大脑进行快速反应和深度思考。(盲猜就是后训练的RL区分了两种模式)
具体来说,Claude 3.7 Sonnet通过‘thinking’参数来控制两种模式。在标准模式下,Claude 3.7 Sonnet 是 Claude 3.5 Sonnet 的升级版本。在扩展思考模式下,它会在回答前进行自我反思,从而在数学、物理、指令遵循、编码以及许多其他任务上表现更优。同时Anthropic发现,在这两种模式下,模型的提示方式基本相似。从API接口可以看到,这里会有一个thinking参数,当enabled后,模型就使用扩展思考模式(如果模型能自助判断是否开启就更完美了,可能避免简单问题的过度思考):
讯享网 <span class="o">--</span><span class="n">header</span> <span class="s2">"x-api-key: $ANTHROPIC_API_KEY"</span> \ <span class="o">--</span><span class="n">header</span> <span class="s2">"anthropic-version: 2023-06-01"</span> \ <span class="o">--</span><span class="n">header</span> <span class="s2">"content-type: application/json"</span> \ <span class="o">--</span><span class="n">data</span> \ ‘{
<span class="s2">"model"</span><span class="p">:</span> <span class="s2">"claude-3-7-sonnet-"</span><span class="p">,</span> <span class="s2">"max_tokens"</span><span class="p">:</span> <span class="mi">20000</span><span class="p">,</span> <span class="s2">"thinking"</span><span class="p">:</span> <span class="p">{</span> <span class="s2">"type"</span><span class="p">:</span> <span class="s2">"enabled"</span><span class="p">,</span> <span class="s2">"budget_tokens"</span><span class="p">:</span> <span class="mi">16000</span> <span class="p">},</span> <span class="s2">"messages"</span><span class="p">:</span> <span class="p">[</span> <span class="p">{</span> <span class="s2">"role"</span><span class="p">:</span> <span class="s2">"user"</span><span class="p">,</span> <span class="s2">"content"</span><span class="p">:</span> <span class="s2">"Are there an infinite number of prime numbers such that n mod 4 == 3?"</span> <span class="p">}</span> <span class="p">]</span> }’
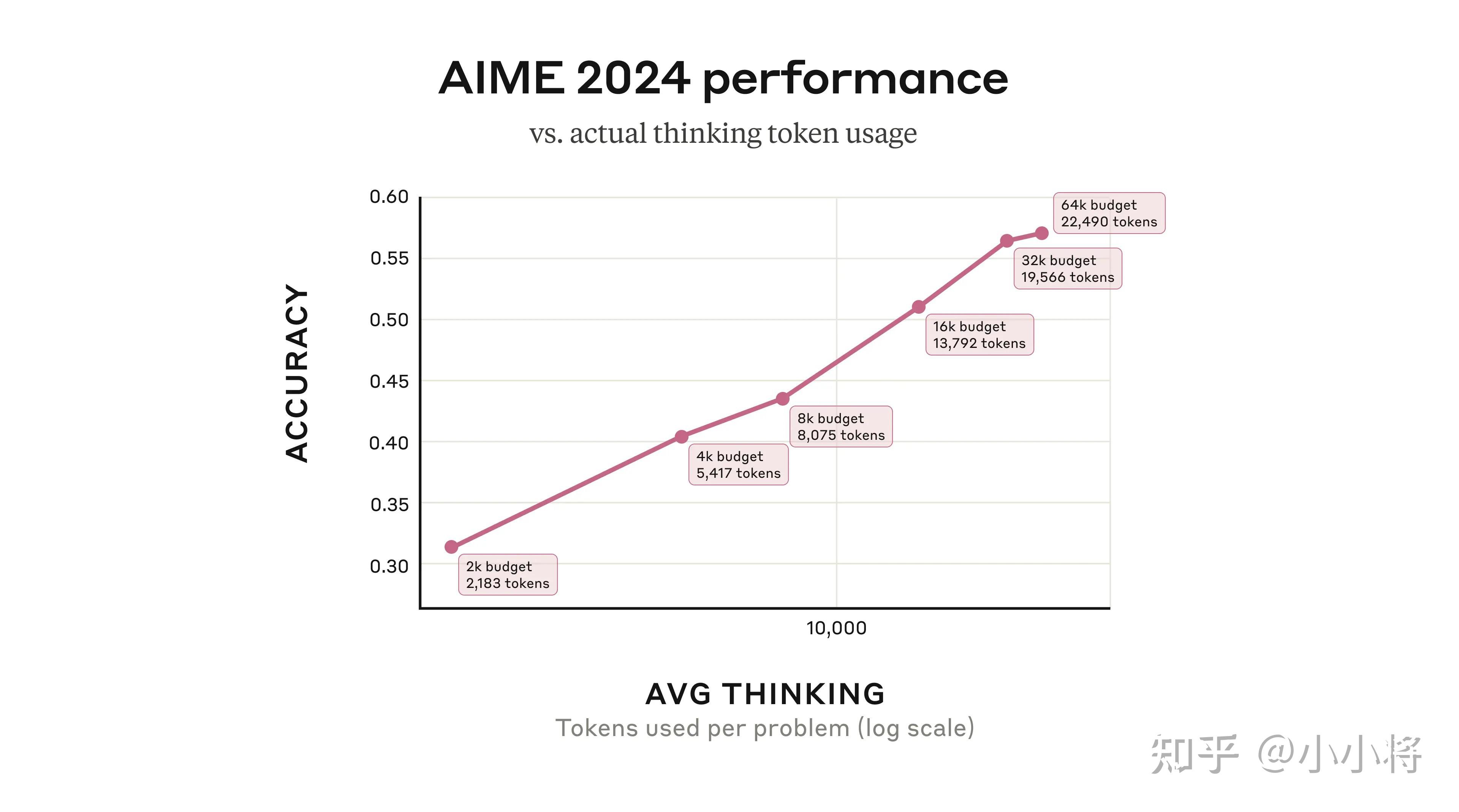
而且通过 API 用户还可以控制思考的预算(budget_tokens):这里可以设置 Claude 思考不超过 N 个 tokens,N 的值最高可达其输出限制的 128K token。
Claude 3.7 Sonnet的推理也符合test-time compute scaling law,这意味着增加思考的tokens可以提升性能,但也更慢。所以通过控制预算能够在速度(和成本)与回答质量之间进行权衡。
注意,Claude 3.7 Sonnet的思考过程也是用户可见的。
另外,Claude 3.7 Sonnet的推理模式开发中,减少了对数学和计算机科学竞赛问题的优化,而是将重点转向了更能反映企业实际使用大语言模型的现实任务,这点和OpenAI的o1有很大的区别。
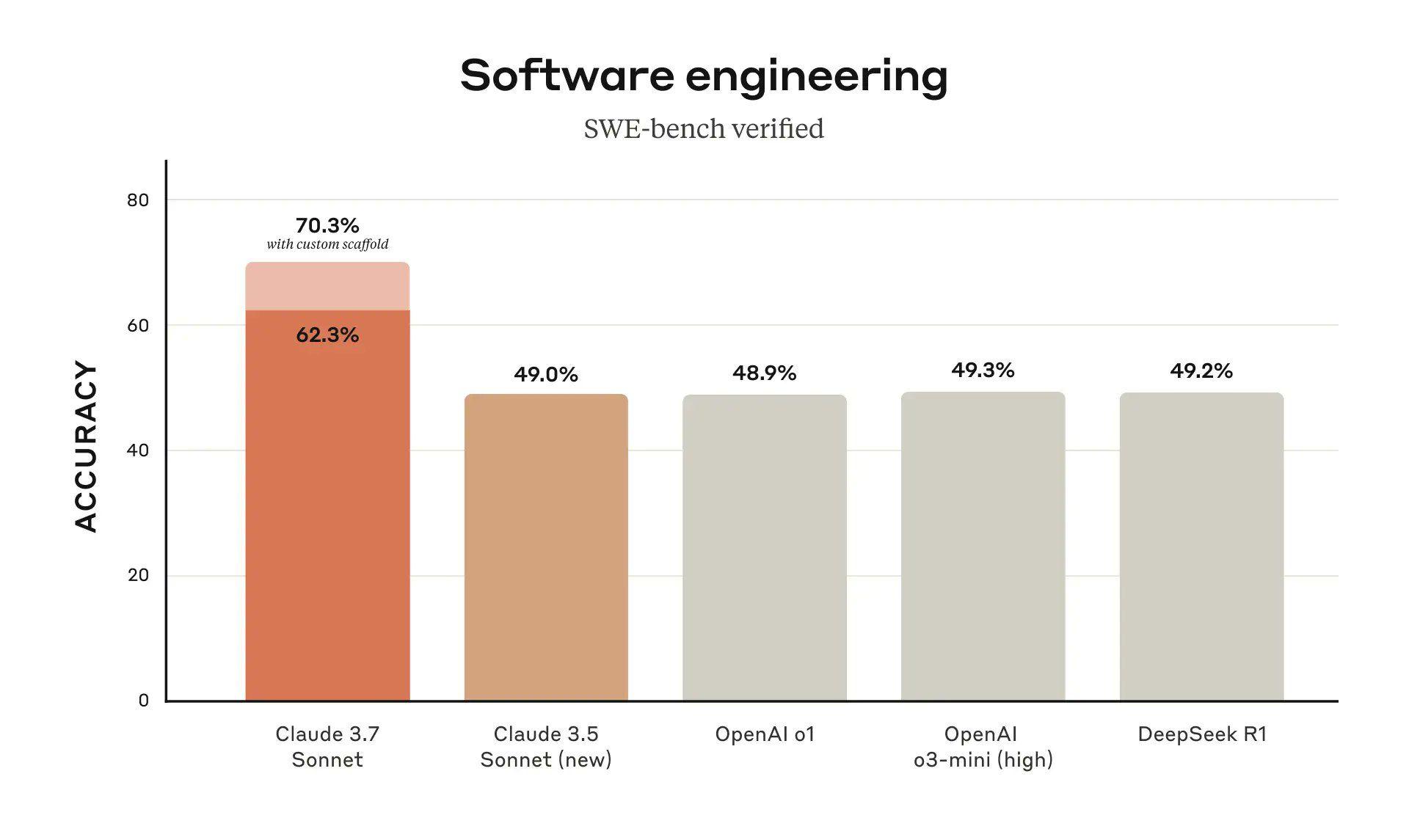
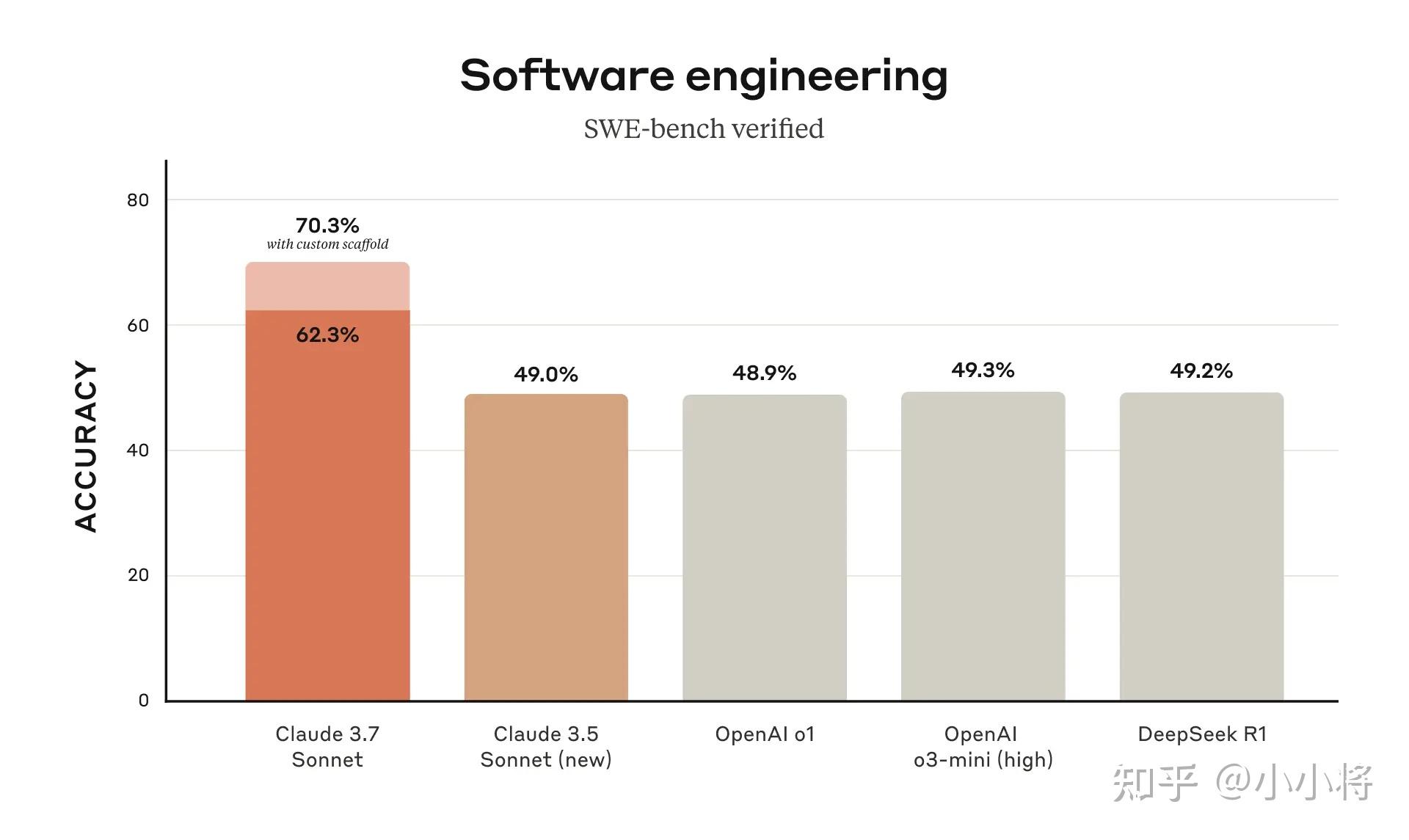
特别地,Claude 3.7 Sonnet 在 SWE-bench Verified 和TAU-bench 上均超过o3-mini和DeepSeek R1实现了最先进的性能,SWE-bench Verified基准评估了 AI 模型解决现实世界软件问题的能力(这个大幅度超过其他同类模型,真的太强了),而 TAU-bench 是一个测试 AI 代理在复杂现实任务中与用户和工具交互的框架。这说明Claude 3.7 Sonnet更擅长解决现实问题。
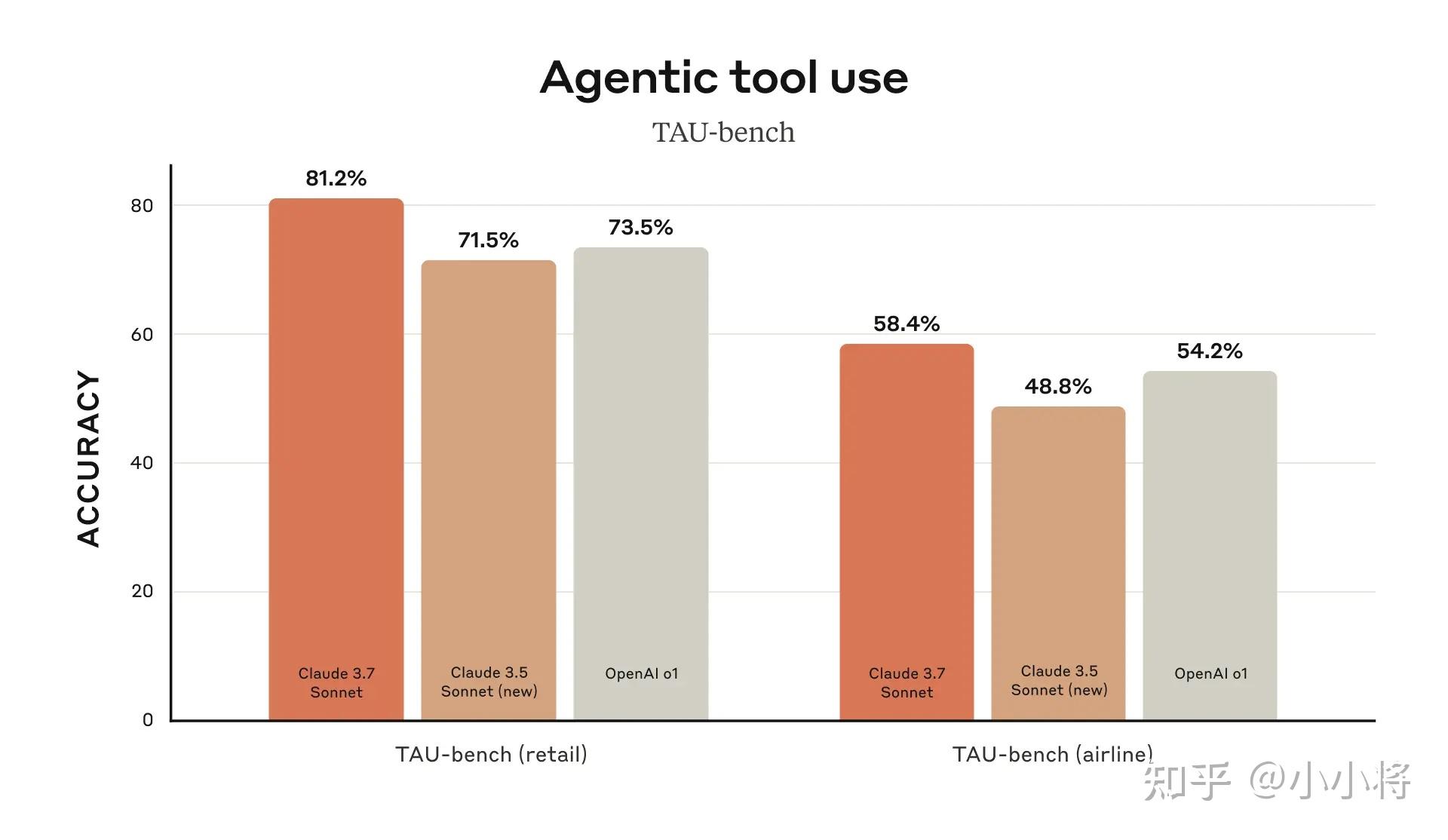
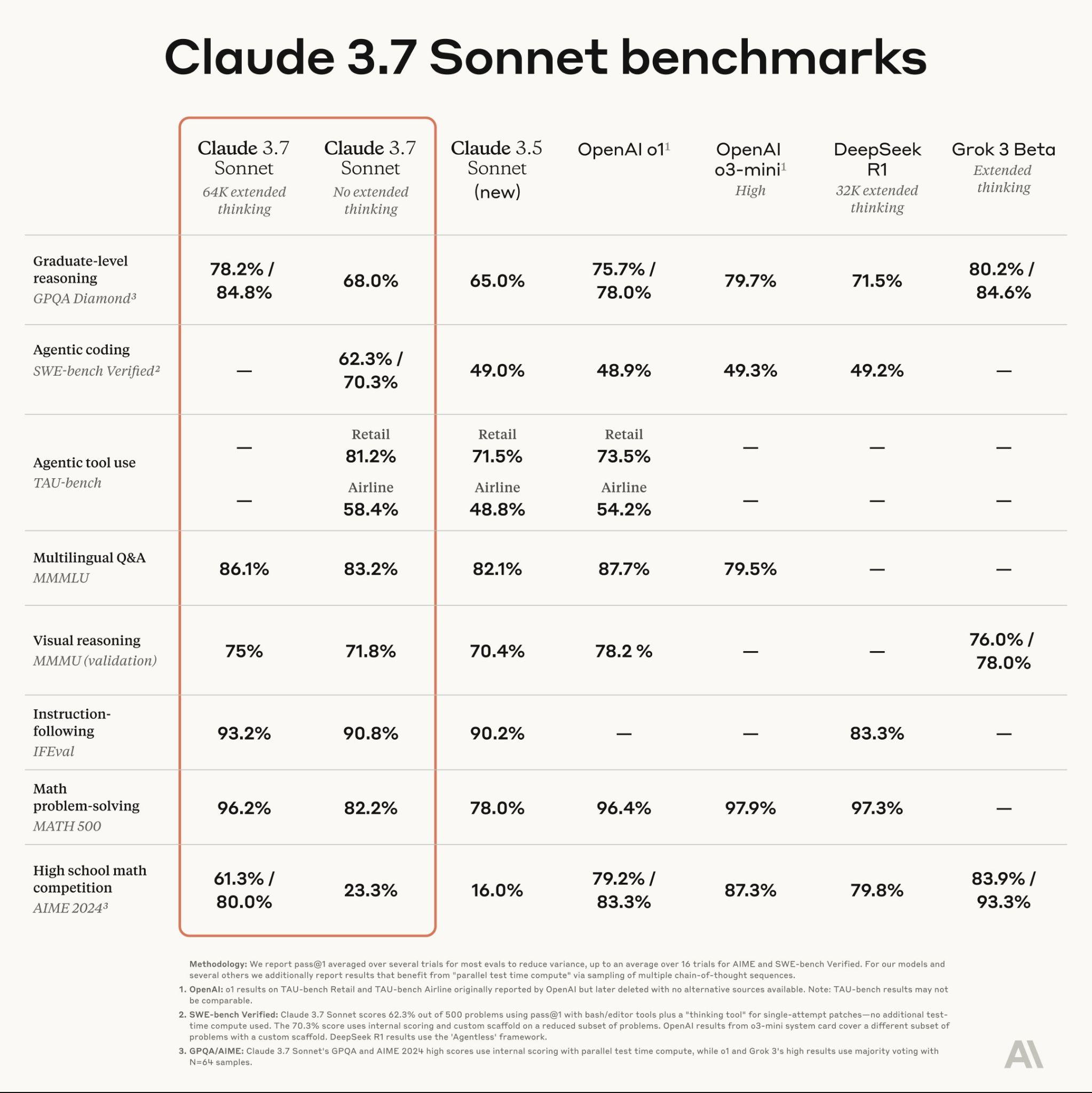
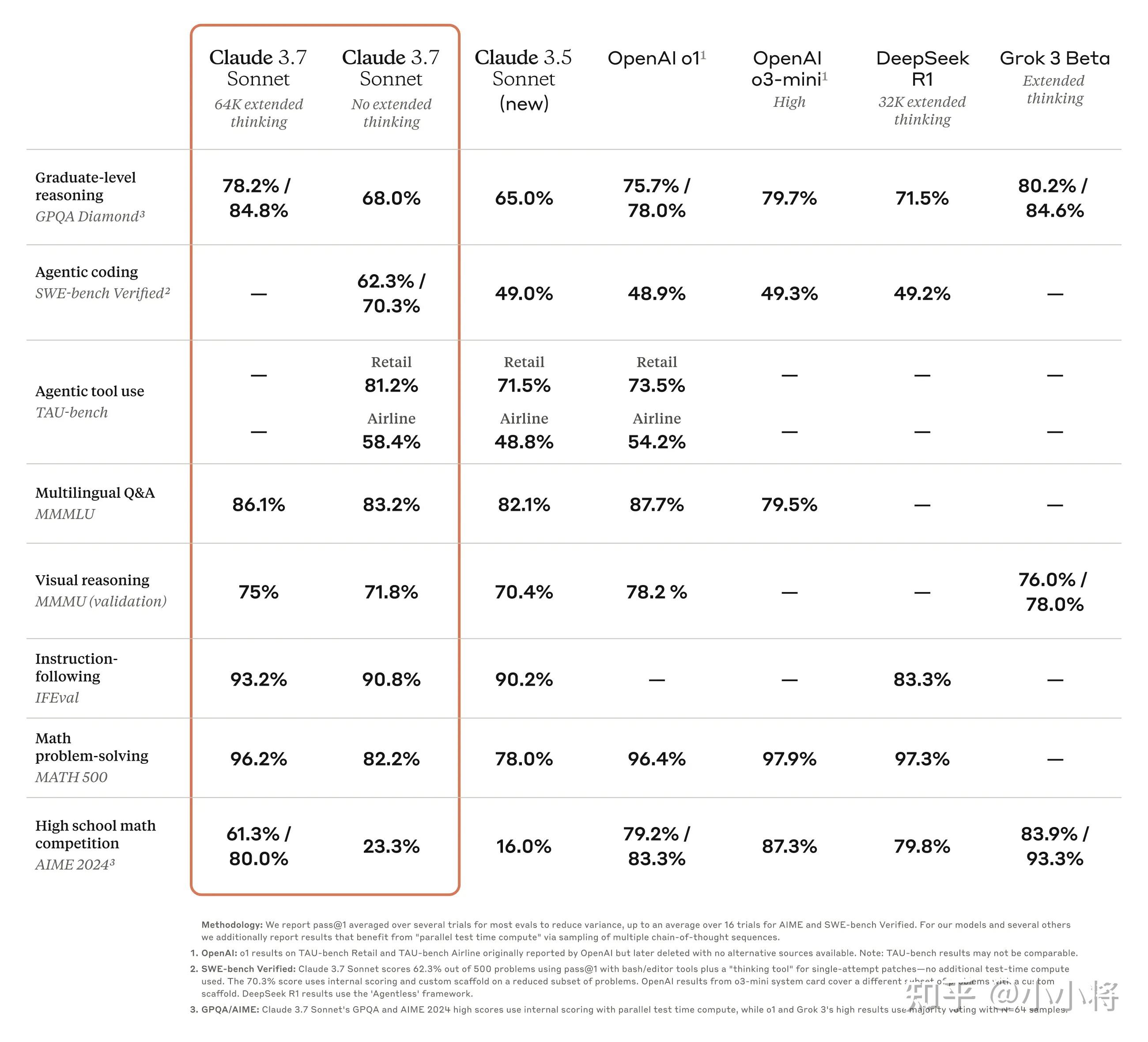
Claude 3.7 Sonnet的更多评测结果如下所示,可以看到在开启扩展思考模式下,部分指标已经超过o3-mini以及DeepSeek R1,但是不强于Grok 3。不过在数学竞赛评测集上,效果要比o3-mini和DeepSeek R1差一些,这可能是前面所提到的:Claude 3.7 Sonnet训练过程中刻意减少了对数学竞赛问题的优化。
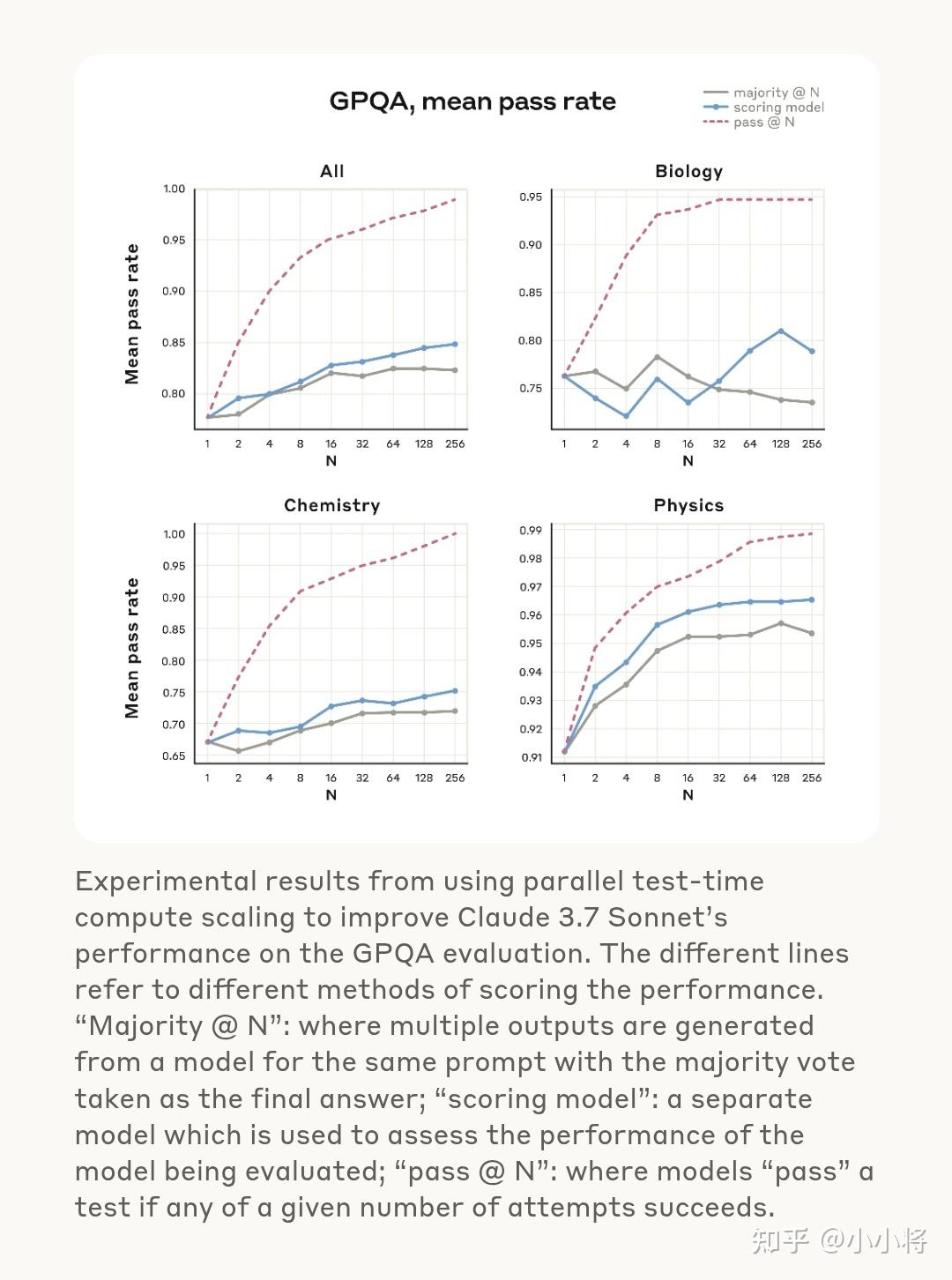
这里GPQA有两个结果,第二个结果是通过parallel test-time compute scaling来得到的,简单来说就是先同样的提示词采样多个回答,然后用一个打分模型选择最好的。和majority vote的区别是这里用一个学习过的打分模型来选择,而majority vote则选择出现次数最大的那个答案。实验看起来用打分模型比简单的majority vote要好。采样同算力的256个回答,限制最大64K的思考tokens,使用基于打分模型的parallel test-time compute scaling,Claude 3.7 Sonnet在GPQA上得分84.8%。
而且,Claude可以同时进行多种不同的扩展思维过程,这使得它能够考虑更多解决问题的方法,从而更频繁地得出正确答案。不过,在最新部署的模型中,尚不支持parallel test-time compute scaling功能。
除此之外,Anthropic还推出了首个代理编码工具Claude Code。Claude Code,能够搜索和阅读代码、编辑文件、编写和运行测试、提交代码并将其推送到 GitHub,以及使用命令行工具。在早期测试中,Claude Code 可以一次性完成了通常需要 45 分钟以上手动工作的任务,显著减少了开发时间和开销。感觉这个工具可能是Claude 3.7 Sonnet 最大的亮点。
 https://www.zhihu.com/video/
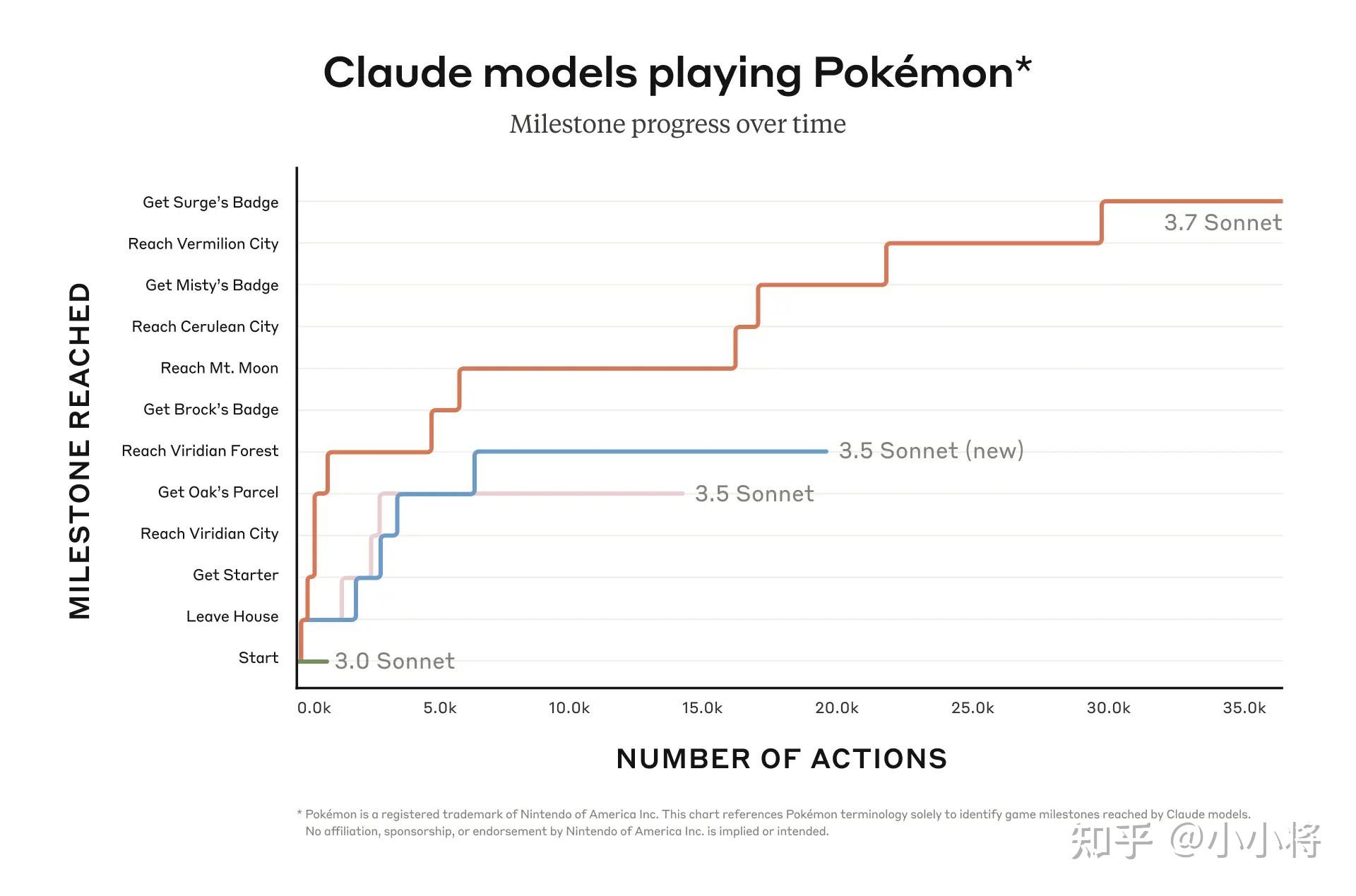
https://www.zhihu.com/video/ 补充一点,Claude 3.7 Sonnet的agent能力很强,它能够迭代调用函数、响应环境变化,并持续执行任务,直到完成开放式的任务。在《宝可梦》游戏中,Claude 3.7 Sonnet 提升很大,能成功击败三位宝可梦道馆馆主(游戏中的 Boss)并赢得了他们的徽章。
Claude在2027年的目标是成为pioneers:在解决具有挑战性的问题上取得了突破性进展,这些问题原本需要团队数年时间才能完成。虽然不是AGI,但是能实现这个目标也可能可怕。

神经一样的名字,神一样的表现。
(A社和DeepSeek是目前唯二专注于AGI核心智力的。)
Anthropic是十年老血栓,Claude 3.7是人能想出来名字么?我猜他们很后悔,没把Sonnet 3.5 New,叫做3.6,上次就“中风”过一次,现在又来一次。
应该是2025年春季模型的中流砥柱了。他们可以苟到6月份(目测是6月15左右)。
表现方面主要是两张图,一张是代码,一张是Agent (他们要抓超梦!) AIME和Math对A社没有什么意义。
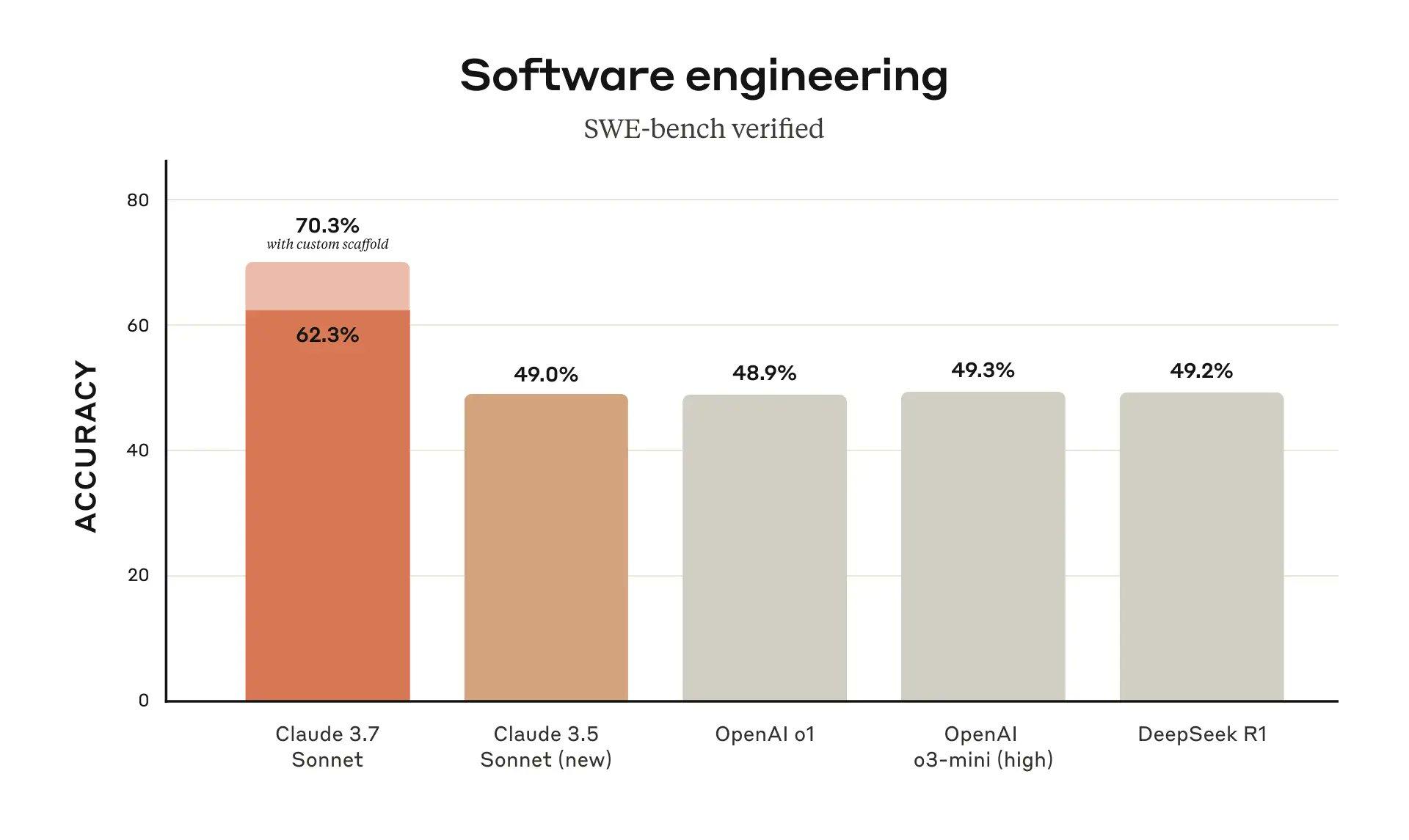
在这张代码性能相关图上,SWE-bench,几乎所有模型都碰到49%的智力空气墙,感觉被神秘力量挡住了。 Claude 3.7突破了这道空气墙,达到62.3 / 70.3%,如果实战与官报相符,那么这算引领了世界。 ——目前我观察到Claude 3.7在UI设计、物理模拟,自动跑角色的行为智力上都达到了很高的成就。
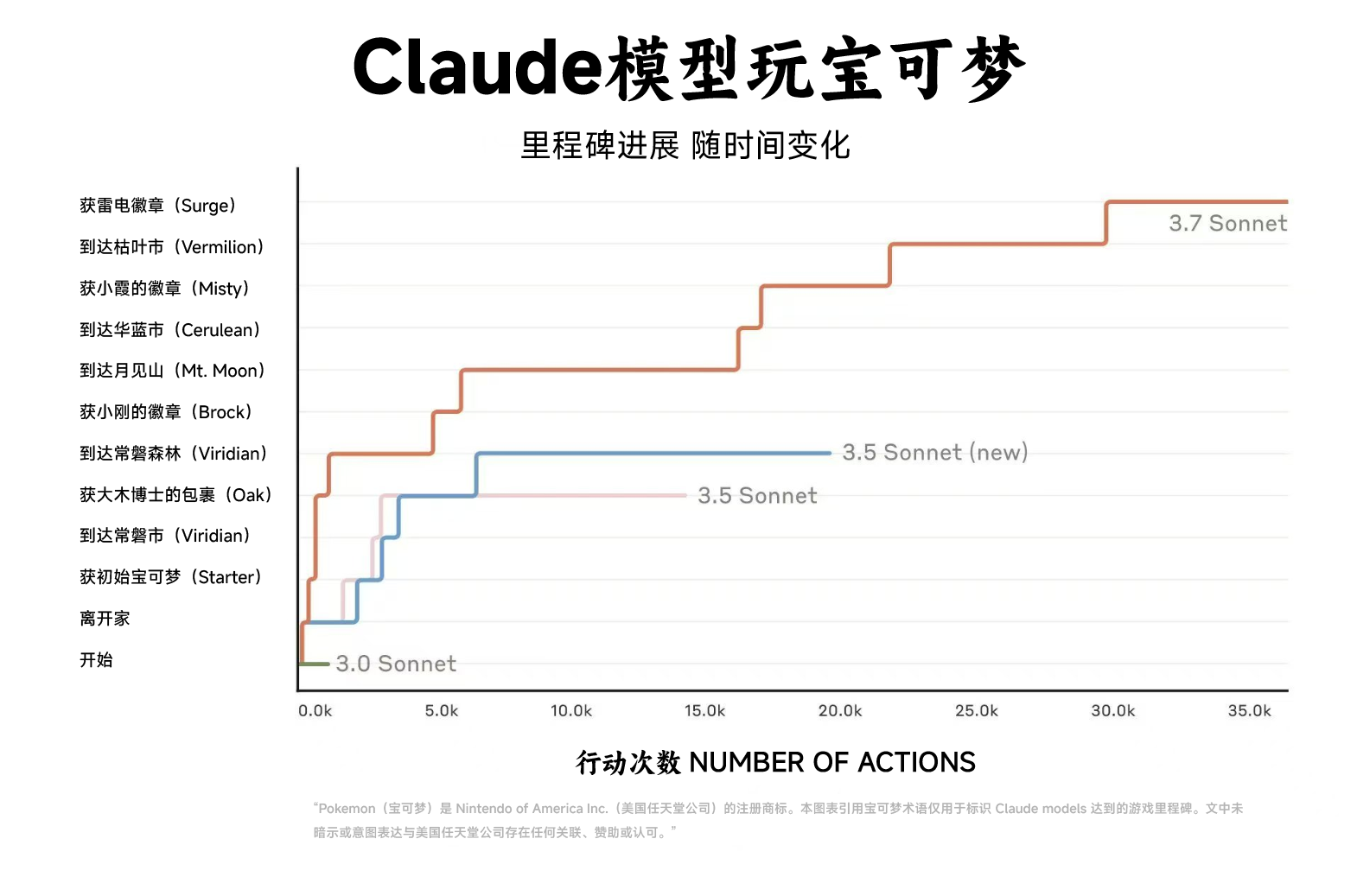
第二张图,是Claude玩Pokémon,我在“想法”里已经介绍过了。 这就是一套Agent测试系统。Amanda Askell (苏格兰女战神)说: 抓住超梦,就是达成了AGI!(火箭队行为)
他们这里没有使用Agent这个词,而是用了Model,我不知道他们是如何给Claude设定目标的。如果给Claude设定一个“抓住超梦”的最终目标,让它自由行动,它现在已经拿到了电系徽章,那这已经算ASI了。(当然,现在是不可能的)
可以看出Claude 3.7比3.6有了长足的进步,已经拿到了三个道馆徽章。 道馆里通常都是有迷宫的,脑子好的人都能掉坑里。
A社真不是嘴上说说要做Agent,实打实地在推进自主行动性实验。
实测了下,这里分享下结果。
虽然我不喜欢Dario Amodei这个人,讨厌他的傲慢和偏见,但不得不承认,日常工作还是离不开claude的,claude最强的地方在于它的代码能力。
说句实话,你看chatbot arena上,claude 3.5 sonnet仅排在19,似乎不太行的样子
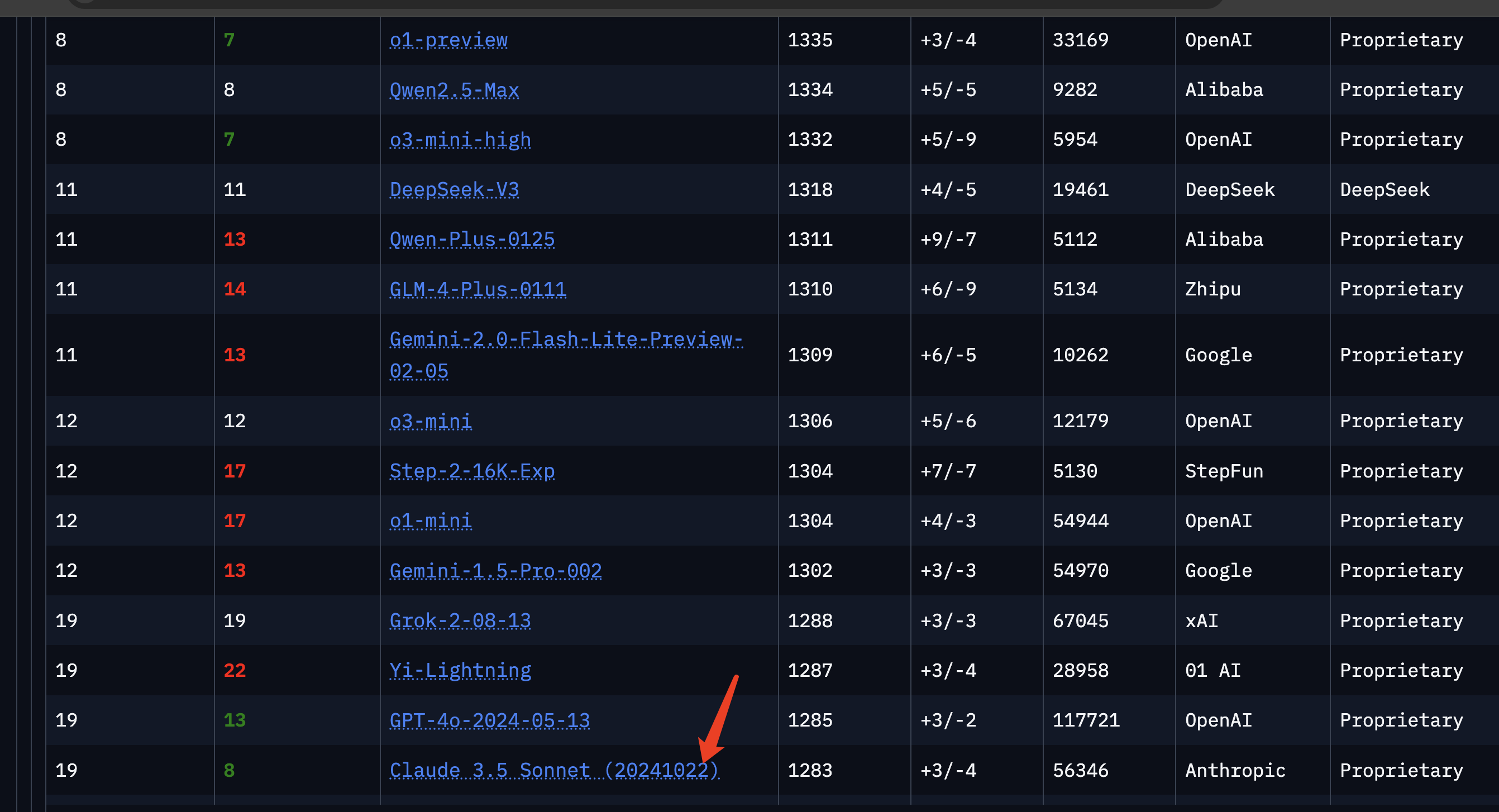
即使你把Category切换到coding,排名也不太靠前。
但经常用Cursor和copilot的朋友都知道,claude 3.5 sonnet实际上比o1-mini, gpt-4o都更加顺手,很难量化这种感觉,但总感觉claude 3.5 sonnet更懂你的需求。
而claude 3.7 sonnet更是锦上添花。
据claude称,claude 3.7 sonnet是结合了快思考和慢思考的混合模型

目前claude 3.7 sonnet也在Cursor上架了。不过,在Cursor上看,这两个模型是分开的
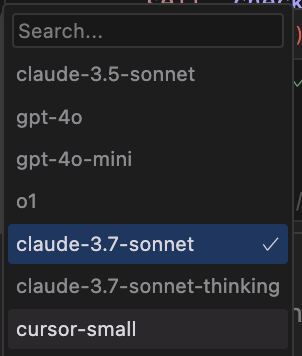
也就说,其实用户是可以指定Claude 3.7 Sonnet是使用快思考还是慢思考模式的。
到底Claude 3.7 Sonnet比3.5版本好多少呢?这里就拿我之前做过的一个demo试试吧。
claude 3.5 sonnet中我最喜欢的功能就是「抄一个app」,
虽然我的工作不涉及前端,但克隆app确实我最喜欢用来测试AI的案例之一。
这是我随手截图的Spotify页面
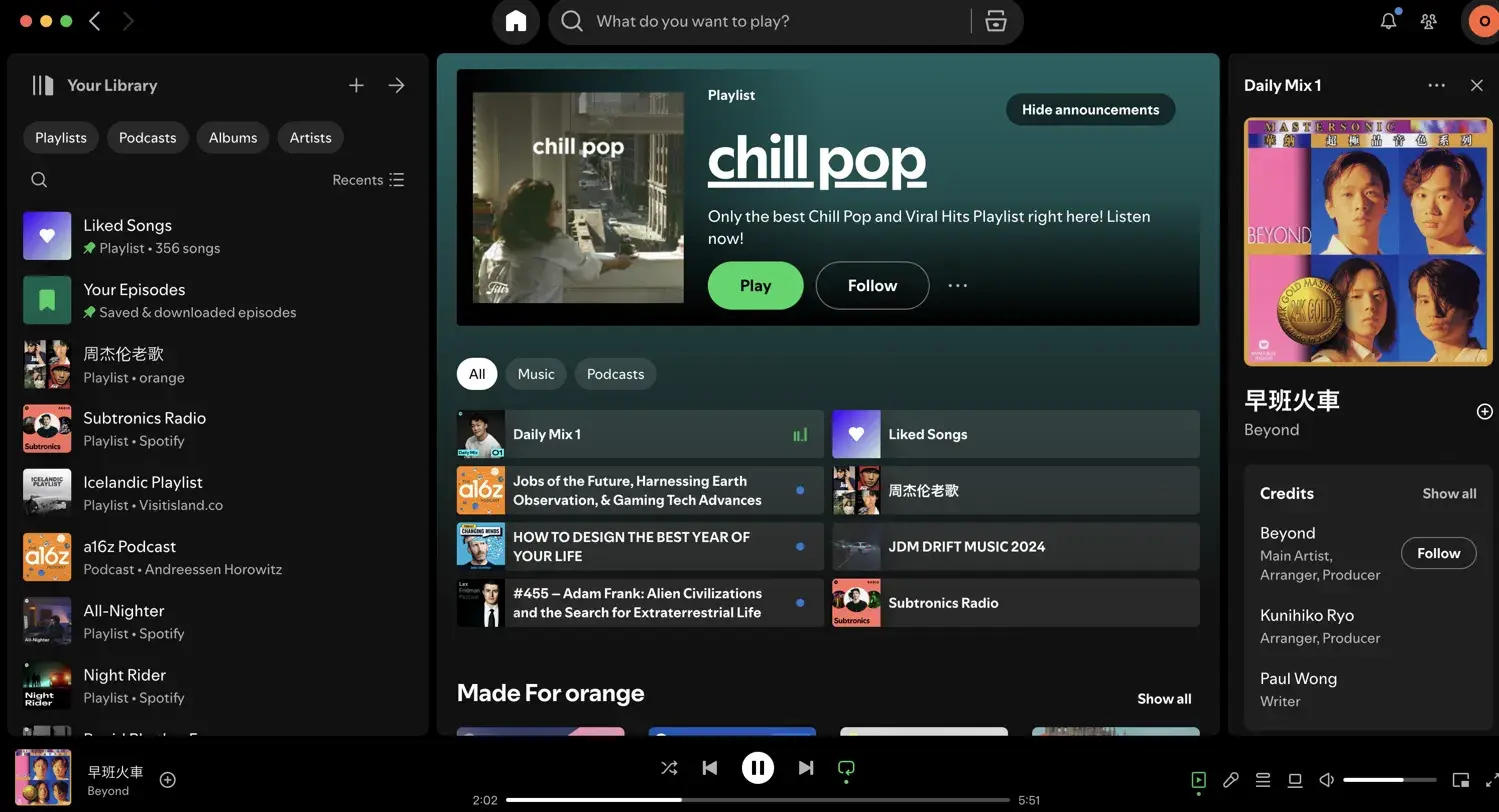
在用claude 3.5 Sonnet 时,我试过让claude克隆这个app,这是当时的结果,勉强完成任务吧。
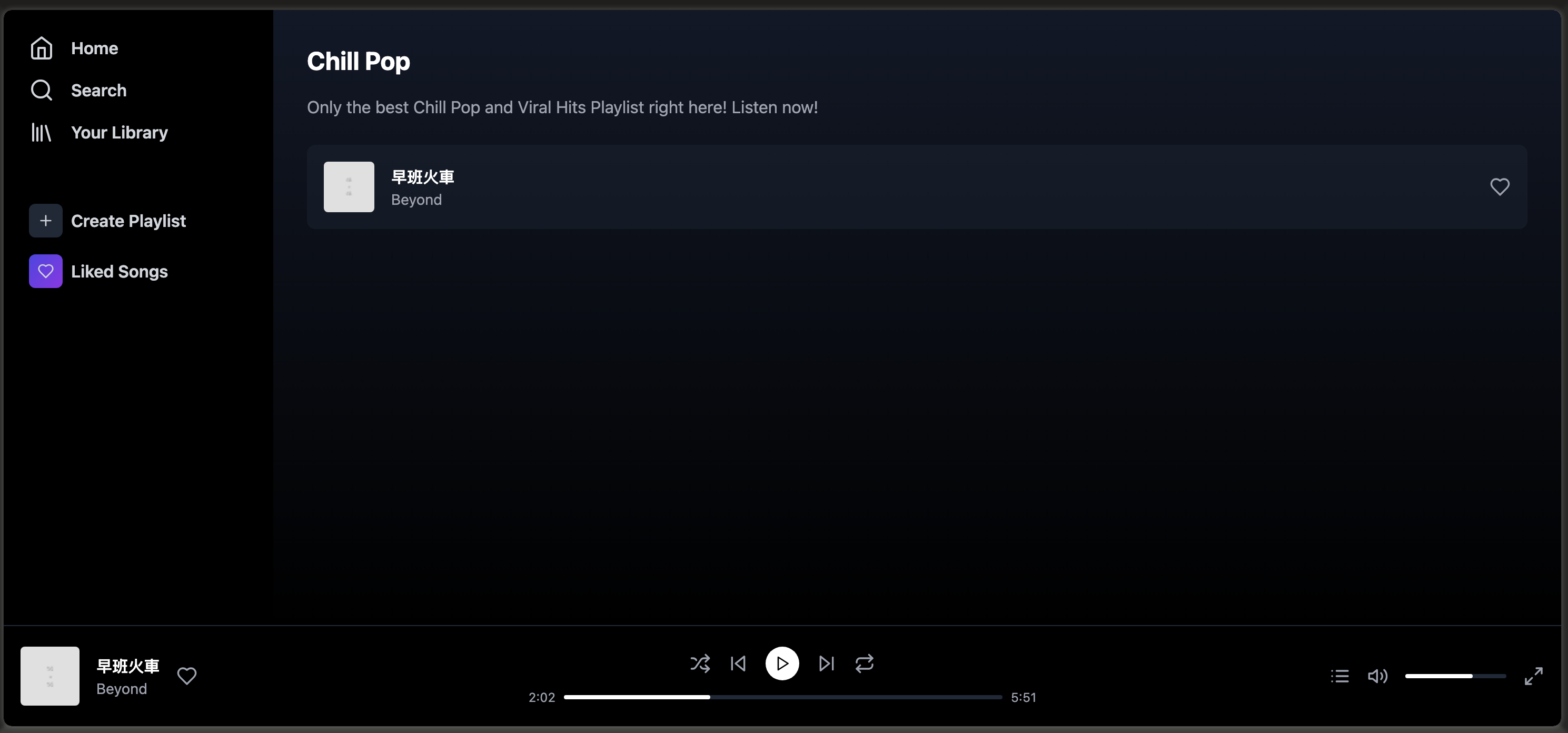
而用claude 3.7 sonnet再试,基本上克隆效果更好了,左边的菜单栏,中间的playlist,右边的详情页等等,都复制过来了。当然,专辑封面由于没有具体图片的地址,没法复制过来。
而且Claude 3.7 Sonnet 价格和Claude 3.5 Sonnet一样,输入每百万token 3美刀,输出每百万token 15美刀。
对AI编程爱好者而言,确实是好消息。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/209760.html