
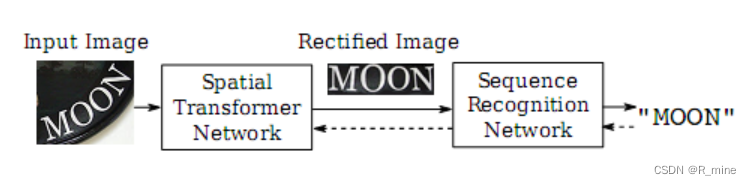
基于TPS(Thin Plate Spines)的STN网络是OCR领域CVPR论文《Robust Scene Text Recognition with Automatic Rectification》中提出的RARE网络的一部分,RARE网络的基本结构为空间变换网络(STN)+序列识别网络(SRN)。
讯享网

import torch import torch.nn as nn import torch.nn.functional as function import numpy as np class LocalizationNetwork(nn.Module): """ 空间变换网络 1.读入输入图片,并利用其卷积网络提取特征 2.使用特征计算基准点,基准点的个数由参数fiducial指定,参数channel指定输入图像的通道数 3.计算基准点的方法是使用两个全连接层将卷积网络输出的特征进行降维,从而得到基准点集合 """ def __init__(self, fiducial, channel): """ 初始化方法 :param fiducial: 基准点的数量 :param channel: 输入图像通道数 """ super(LocalizationNetwork, self).__init__() self.fiducial = fiducial # 指定基准点个数 self.channel = channel # 指定输入图像的通道数 # 提取特征使用的卷积网络 self.ConvNet = nn.Sequential( nn.Conv2d(self.channel, 64, 3, 1, padding=1, bias=False), nn.BatchNorm2d(64), nn.ReLU(True), # [N, 64, H, W] nn.MaxPool2d(2, 2), # [N, 64, H/2, W/2] nn.Conv2d(64, 128, 3, 1, padding=1, bias=False), nn.BatchNorm2d(128), nn.ReLU(True), # [N, 128, H/2, W/2] nn.MaxPool2d(2, 2), # [N, 128, H/4, W/4] nn.Conv2d(128, 256, 3, 1, padding=1, bias=False), nn.BatchNorm2d(256), nn.ReLU(True), # [N, 256, H/4, W/4] nn.MaxPool2d(2, 2), # [N, 256, H/8, W/8] nn.Conv2d(256, 512, 3, 1, padding=1, bias=False), nn.BatchNorm2d(512), nn.ReLU(True), # [N, 512, H/8, W/8] nn.AdaptiveAvgPool2d(1)) # [N, 512, 1, 1] # 计算基准点使用的两个全连接层 self.localization_fc1 = nn.Sequential(nn.Linear(512, 256), nn.ReLU(True)) self.localization_fc2 = nn.Linear(256, self.fiducial * 2) # 将全连接层2的参数初始化为0 self.localization_fc2.weight.data.fill_(0) """ 全连接层2的偏移量bias需要进行初始化,以便符合RARE Paper中所介绍的三种初始化形式,三种初始化方式详见 https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Shi_Robust_Scene_Text_CVPR_2016_paper.pdf,Fig. 6 (a) 下初始化方法为三种当中的第一种 """ ctrl_pts_x = np.linspace(-1.0, 1.0, fiducial // 2) ctrl_pts_y_top = np.linspace(0.0, -1.0, fiducial // 2) ctrl_pts_y_bottom = np.linspace(1.0, 0.0, fiducial // 2) ctrl_pts_top = np.stack([ctrl_pts_x, ctrl_pts_y_top], axis=1) ctrl_pts_bottom = np.stack([ctrl_pts_x, ctrl_pts_y_bottom], axis=1) initial_bias = np.concatenate([ctrl_pts_top, ctrl_pts_bottom], axis=0) # 修改全连接层2的偏移量 self.localization_fc2.bias.data = torch.from_numpy(initial_bias).float().view(-1) def forward(self, x): """ 前向传播方法 :param x: 输入图像,规模[batch_size, C, H, W] :return: 输出基准点集合C,用于图像校正,规模[batch_size, fiducial, 2] """ # 获取batch_size batch_size = x.size(0) # 提取特征 features = self.ConvNet(x).view(batch_size, -1) # 使用特征计算基准点集合C features = self.localization_fc1(features) C = self.localization_fc2(features).view(batch_size, self.fiducial, 2) return C class GridGenerator(nn.Module): """网格生成网络 Grid Generator of RARE, which produces P_prime by multipling T with P.""" def __init__(self, fiducial, output_size): """ 初始化方法 :param fiducial: 基准点与基本基准点的个数 :param output_size: 校正后图像的规模 基本基准点是被校正后的图片的基准点集合 """ super(GridGenerator, self).__init__() self.eps = 1e-6 # 基准点与基本基准点的个数 self.fiducial = fiducial # 校正后图像的规模 self.output_size = output_size # 假设为[w, h] # 论文公式当中的C',C'是基本基准点,也就是被校正后的图片的基准点集合 self.C_primer = self._build_C_primer(self.fiducial) # 论文公式当中的P',P'是校正后的图片的像素坐标集合,规模为[h·w, 2],集合中有n个元素,每个元素对应校正图片的一个像素的坐标 self.P_primer = self._build_P_primer(self.output_size) # 如果使用多GPU,则需要寄存器缓存register buffer self.register_buffer("inv_delta_C_primer", torch.tensor(self._build_inv_delta_C_primer(self.fiducial, self.C_primer)).float()) self.register_buffer("P_primer_hat", torch.tensor( self._build_P_primer_hat(self.fiducial, self.C_primer, self.P_primer)).float()) def _build_C_primer(self, fiducial): """ 构建基本基准点集合C',即被校正后的图片的基准点,应该是一个矩形的fiducial个点集合 :param fiducial: 基本基准点的个数,跟基准点个数相同 该方法生成C'的方法与前面的空间变换网络相同 """ ctrl_pts_x = np.linspace(-1.0, 1.0, fiducial // 2) ctrl_pts_y_top = -1 * np.ones(fiducial // 2) ctrl_pts_y_bottom = np.ones(fiducial // 2) ctrl_pts_top = np.stack([ctrl_pts_x, ctrl_pts_y_top], axis=1) ctrl_pts_bottom = np.stack([ctrl_pts_x, ctrl_pts_y_bottom], axis=1) C_primer = np.concatenate([ctrl_pts_top, ctrl_pts_bottom], axis=0) return C_primer def _build_P_primer(self, output_size): """ 构建校正图像像素坐标集合P',构建的方法为按照像素靠近中心的程度形成等差数列作为像素横纵坐标值 :param output_size: 模型输出的规模 :return : 校正图像的像素坐标集合 """ w, h = output_size # 等差数列output_grid_x output_grid_x = (np.arange(-w, w, 2) + 1.0) / w # 等差数列output_grid_y output_grid_y = (np.arange(-h, h, 2) + 1.0) / h """ 使用np.meshgrid将output_grid_x中每个元素与output_grid_y中每个元素组合形成一个坐标 注意,若output_grid_x的规模为[w], output_grid_y为[h],则生成的元素矩阵规模为[h, w, 2] """ P_primer = np.stack(np.meshgrid(output_grid_x, output_grid_y), axis=2) # 在返回时将P'进行降维,将P'从[h, w, 2]降为[h·w, 2] return P_primer.reshape([-1, 2]) # [HW, 2] def _build_inv_delta_C_primer(self, fiducial, C_primer): """ 计算deltaC'的逆,该矩阵为常量矩阵,在确定了fiducial与C'之后deltaC'也同时被确定 :param fiducial: 基准点与基本基准点的个数 :param C_primer: 基本基准点集合C' :return: deltaC'的逆 """ # 计算C'梯度公式中的R,R中的元素rij等于dij的平方再乘dij的平方的自然对数,dij是C'中第i个元素与C'中第j个元素的欧式距离,R矩阵是个对称矩阵 R = np.zeros((fiducial, fiducial), dtype=float) # 对称矩阵可以简化for循环 for i in range(0, fiducial): for j in range(i, fiducial): R[i, j] = R[j, i] = np.linalg.norm(C_primer[i] - C_primer[j]) np.fill_diagonal(R, 1) # 填充对称矩阵对角线元素,都为1 R = (R 2) * np.log(R 2) # 或者R = 2 * (R 2) * np.log(R) # 使用不同矩阵进行拼接,组成deltaC' delta_C_primer = np.concatenate([ np.concatenate([np.ones((fiducial, 1)), C_primer, R], axis=1), # 规模[fiducial, 1+2+fiducial],deltaC'计算公式的第一行 np.concatenate([np.zeros((1, 3)), np.ones((1, fiducial))], axis=1), # 规模[1, 3+fiducial],deltaC'计算公式的第二行 np.concatenate([np.zeros((2, 3)), np.transpose(C_primer)], axis=1) # 规模[2, 3+fiducial],deltaC'计算公式的第三行 ], axis=0) # 规模[fiducial+3, fiducial+3] # 调用np.linalg.inv求deltaC'的逆 inv_delta_C_primer = np.linalg.inv(delta_C_primer) return inv_delta_C_primer def _build_P_primer_hat(self, fiducial, C_primer, P_primer): """ 求^P',即论文公式当中由校正后图片像素坐标经过变换矩阵T后反推得到的原图像素坐标P集合公式当中的P'帽,P = T^P' :param fiducial: 基准点与基本基准点的个数 :param C_primer: 基本基准点集合C',规模[fiducial, 2] :param P_primer: 校正图像的像素坐标集合,规模[h·w, 2] :return: ^P',规模[h·w, fiducial+3] """ n = P_primer.shape[0] # P_primer的规模为[h·w, 2],即n=h·w # PAPER: d_{i,k} is the euclidean distance between p'_i and c'_k P_primer_tile = np.tile(np.expand_dims(P_primer, axis=1), (1, fiducial, 1)) # 规模变化 [h·w, 2] -> [h·w, 1, 2] -> [h·w, fiducial, 2] C_primer = np.expand_dims(C_primer, axis=0) # 规模变化 [fiducial, 2] -> [1, fiducial, 2] # 此处相减是对于P_primer_tile的每一行都减去C_primer,因为这两个矩阵规模不一样 dist = P_primer_tile - C_primer # 计算求^P'公式中的dik,dik为P'中第i个点与C'中第k个点的欧氏距离 r_norm = np.linalg.norm(dist, ord=2, axis=2, keepdims=False) # 规模 [h·w, fiducial] # r'ik = d^2ik·lnd^2ik r = 2 * np.multiply(np.square(r_norm), np.log(r_norm + self.eps)) # ^P'i = [1, x'i, y'i, r'i1,......, r'ik]的转置,k=fiducial P_primer_hat = np.concatenate([np.ones((n, 1)), P_primer, r], axis=1) # 规模 经过垂直拼接[h·w, 1],[h·w, 2],[h·w, fiducial]形成[h·w, fiducial+3] return P_primer_hat def _build_batch_P(self, batch_C): """ 求本batch每一张图片的原图像素坐标集合P :param batch_C: 本batch原图的基准点集合C :return: 本batch的原图像素坐标集合P,规模[batch_size, h, w, 2] """ # 获取batch_size batch_size = batch_C.size(0) # 将本batch的基准点集合进行扩展,使其规模从[batch_size, fiducial, x] -> [batch_size, fiducial+3, 2] batch_C_padding = torch.cat((batch_C, torch.zeros(batch_size, 3, 2).float()), dim=1) # 按照论文求解T的公式求T,规模变化[fiducial+3, fiducial+3] × [batch_size, fiducial+3, 2] -> [batch_size, fiducial+3, 2] batch_T = torch.matmul(self.inv_delta_C_primer, batch_C_padding) # 按照论文公式求原图像素坐标的公式求解本batch的原图像素坐标集合P,P = T^P' # [h·w, fiducial+3] × [batch_size, fiducial+3, 2] -> [batch_size, h·w, 2] batch_P = torch.matmul(self.P_primer_hat, batch_T) # 将P从[batch_size, h·w, 2]转换到[batch_size, h, w, 2] return batch_P.reshape([batch_size, self.output_size[1], self.output_size[0], 2]) def forward(self, batch_C): return self._build_batch_P(batch_C) class TPSSpatialTransformerNetwork(nn.Module): """Rectification Network of RARE, namely TPS based STN""" def __init__(self, fiducial, input_size, output_size, channel): """Based on RARE TPS :param fiducial: number of fiducial points :param input_size: (w, h) of the input image :param output_size: (w, h) of the rectified image :param channel: input image channel """ super(TPSSpatialTransformerNetwork, self).__init__() self.fiducial = fiducial self.input_size = input_size self.output_size = output_size self.channel = channel self.LNet = LocalizationNetwork(self.fiducial, self.channel) self.GNet = GridGenerator(self.fiducial, self.output_size) def forward(self, x): """ :param x: batch input image [batch_size, c, w, h] :return: rectified image [batch_size, c, h, w] """ # 求原图的基准点集合C C = self.LNet(x) # [batch_size, fiducial, 2] # 求原图对应校正图像素的像素坐标集合P P = self.GNet(C) # [batch_size, h, w, 2] # 按照P对x进行采样,对于越界的位置在网格中采用边界的pixel value进行填充 rectified = function.grid_sample(x, P, padding_mode='border', align_corners=True) #规模[batch_size, c, h, w] print(np.shape(rectified)) return rectified if __name__ == '__main__': tps = TPSSpatialTransformerNetwork(6, (128, 64), (128, 64), 3) # input size: [batch_size, channel_num, w, h] input = torch.randn((1, 3, 128, 64)) tps(input) a = [1, 2, 3] b = [4, 5] P_primer = np.stack(np.meshgrid(a, b), axis=2) print(P_primer) 讯享网
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/20512.html