
背景
笔者正在 Datawhale 举办的 AI 夏令营中参与 CV 方向的学习,研究课题为发布在讯飞 AI 开发者大赛上的脑PET图像分析和疾病预测挑战赛,需要对 nii 格式的医学影像文件进行学习,并进行疾病预测
第一轮学习中,Datawhale 团队给出了基于logistic回归进行预测的baseline,但其中并没有对 nii 文件进行详细介绍;且为了适配 logistic 回归模型,并缩小数据规模,其数据处理过程(个人认为)产生了不可忽视的信息丢失,直接导致预测的准确度仅略高于0.5——这跟瞎猜也没啥区别了吧……

鉴于此,笔者在探索中,总结出一篇对nii文件进行数据处理,并采用学习能力更强的简单CNN模型进行训练的教程
nii文件
数据格式
nii 文件是医学图像处理中经常使用的一种 NIFTI 格式图像,关于 nii 文件具体的底层原理,这里不做详细介绍,有兴趣的同学可以参见:Brainder.org的讲解。我们今天主要聚焦于,如何合理地处理 nii 文件中的数据,以便模型训练
数据集中的nii文件对一个人脑进行了三维建模。python 的 nibabel 库专门用于处理 nii 文件,我们可以通过 load() 函数读取 nii 文件,获取其信息:
#1.py import nibabel as nib import numpy as np im=nib.load('脑PET图像分析和疾病预测挑战赛数据集/Train/NC/1.nii') im_data=np.array(im.get_fdata()) #获取文件中的所有数值,并转换为numpy数组便于后续处理 print(im_data.shape) #查看数据的形状 #返回:(128, 128, 63, 1)可以看到,数据集中的 nii 文件包含四维数据:其中前三维确定某一个像素点的空间位置,其中左右和前后方向各分128层,上下方向分63层;第四维记录了该点的状态值(类似图片的灰度)
数据处理
在整份 nii 数据中,所有的数值均为正整数,随便挑出一个值看一看:
讯享网#1.py print(im_data[64,64,55,0]) #返回:10550.0
如此多这么大的数值,如果直接将其投入模型进行训练,效果会很差,必须对数据进行预处理,减小其规模。前面提到的 baseline 中的示例代码给出的方法是人工进行特征提取:
#1.py feat = [(im_data != 0).sum(), # 非零像素的数量 (im_data == 0).sum(), # 零像素的数量 im_data.mean(), # 平均值 im_data.std(), # 标准差 len(np.where(im_data.mean(0))[0]), # 在列方向上平均值不为零的数量 len(np.where(im_data.mean(1))[0]), # 在行方向上平均值不为零的数量 im_data.mean(0).max(), # 列方向上的最大平均值 im_data.mean(1).max() # 行方向上的最大平均值 ]这种人工特征提取的方法,优势在于极大地减小了数据规模:每份文件从128*128*63=个数值,减小到8个数值,大幅提升了训练速度。但或许其劣势也在于此:如此大规模的删减,势必造成严重的信息丢失
通常情况下,我们不对数据进行大量的丢弃与删除,而是对所有数据进行“归一化”,使得它们均值为0,标准差为1。具体操作为:求所有数据的平均值与标准差;随后对每个数据,减去平均值,再除以标准差:
讯享网#1.py def norm(image): m=image.mean() s=image.std() return (image-m)/s im_norm=norm(im_data) #看看刚才的10550变成了多少 print(im_norm[64,64,54,0]) #返回:3.955
理论上来说,似此般对所有的 nii 文件做读取和归一化操作,就可以喂给模型做训练了。但是在尝试中我发现,数据集中的文件并非全部是 (128, 128, 63, 1) 的形状!少部分数据的前三个值出现了变化,比如256, 256, 47!这些数据可能受到了损坏,或者它本来就那样……通过一段代码,我们可以看到数据集中的 nii 都有哪些尺寸:
#2.py import nibabel as nib import numpy as np import glob path=glob.glob('./脑PET图像分析和疾病预测挑战赛数据集/Train/*/*') path2=glob.glob('./脑PET图像分析和疾病预测挑战赛数据集/Test/*') sizeSet=set() for i in path: im=nib.load(i) im_data=np.array(im.get_fdata()) sizeSet.add(im_data.shape) for i in path2: im=nib.load(i) im_data=np.array(im.get_fdata()) sizeSet.add(im_data.shape) print(sizeSet) #返回:{ # (256, 256, 207, 1), (128, 128, 768, 1), (128, 128, 47, 1), # (256, 256, 47, 1), (168, 168, 82, 1), (168, 168, 81, 1), # (400, 400, 109, 1), (128, 128, 89, 1), (128, 128, 540, 1), # (128, 128, 63, 1), (256, 256, 81, 1), (128, 128, 88, 1) # }我初步的解决方法简单粗暴:在处理数据时,只要不是 (128, 128, 63, 1) 尺寸的数据,就直接丢弃它们!
#1.py def process(path): im=nib.load(path) im_data=norm(np.array(im.get_fdata())) if im_data.shape==(128, 128, 63, 1): #判断数据形状是否异常 if 'NC' in path: return True,im_data.reshape(-1),0 #表示正常(NC) else: return True,im_data.reshape(-1),1 #表示异常(MCI) else: return False,None,None #对于异常数据,直接不返回它们不幸的是,测试集中的数据也有类似的情况(100个数据里有31个尺寸不正确)。对于这些数据,我只能暂时给它们随机分配“NC”和“MCI”标签来完成预测。这样造成的损失完全不亚于我所吐槽的示例代码😅:

于是,我不得不妥协而进行数据修复。我对过小的数据采取补零,对过大的数据进行裁剪:
#1.py def process(path): im=nib.load(path) im_data=np.array(im.get_fdata()) if im_data.shape==(128, 128, 63, 1): #好的数据,直接保留 im_norm=norm(im_data) elif im_data.shape[2]>63: #规模过大的数据 if im_data.shape[0]>128: ex01=im_data.shape[0]-128 ex2=im_data.shape[2]-63 im_cut=im_data[ex01:,ex01:,ex2:,:] #裁剪 im_norm=norm(im_cut) else: ex2=im_data.shape[2]-63 im_cut=im_data[:,:,ex2:,:] #裁剪 im_norm=norm(im_cut) else: #规模过小的数据 if im_data.shape[0]>128: ex01=im_data.shape[0]-128 im_cut=im_data[ex01:,ex01:,:,:] else: im_cut=im_data lack=63-im_data.shape[2] im_norm=norm(np.pad(im_cut,((0,0),(0,0),(0,lack),(0,0)))) #补零 if 'NC' in path: return im_norm.reshape(-1),0 #表示正常(NC) else: return im_norm.reshape(-1),1 #表示异常(MCI)写这段花了我快两个小时,真是折磨……
将修复后的数据,放入 logistic 回归模型进行训练,准确率终于超过了0.6

有心的同学可能会注意到我进行尺寸统一的方式,并非那么合理:我没有考虑不同尺寸的图片之间,是否可以通过如此草率的操作——在首尾进行裁剪或补零——就可以完全统一。事实上,确实不行。如下三个方形切面,尺寸分别为128,168,和256:
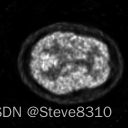
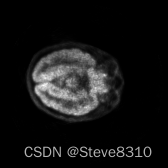
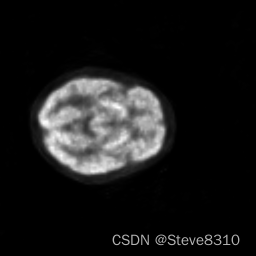
左图和中图,大脑的实际尺寸是一样的,可以通过裁剪或补零来统一,这通过 numpy 索引切片,和补零函数 pad() 就可以实现:
#1.py #将尺寸从128补零至168 im_data=np.pad(im_data,((20,20),(10,30),(0,0),(0,0)))但中图和右图,是等比例缩放的关系,必须用专门处理图像的工具来处理,在这里我使用了 skimage 库中的缩放功能:

#1.py from skimage import transform as skt #将256等其他尺寸,等比例缩放至168 im_data=skt.resize(im_data,(168,168,63,1))注意到,我更改了一下尺寸统一的标准,由128变成168。这没什么实际影响,只是方便缩放而已
数据预处理方向上,对示例代码的优化基本到此结束了。接下来,理所当然的优化方向是更换学习能力更强的模型(如 CNN)
CNN模型
优势:捕捉图像信息
即便是简单的 CNN 模型,其对于图片类型数据的学习能力也要远胜于普通全连接模型。这是因为,图片中存储的信息具有“位置敏感性”,每一个像素不是独立的,只有上下左右的几个像素拼在一起,才能共同传达信息
全连接层只接受线性的数据,它处理二维图片数据的方法是,将其第二行接在第一行末尾、第三行接在它们末尾……仅考虑了左右关系;但 CNN 中的卷积操作考虑了每个像素周围一圈的像素,这让模型极大增强了对图片信息的捕捉
我们使用 matplotlib 生成两个简单的图像来举例:
#3.py from matplotlib import pyplot as pt import numpy as np pic=np.array([[0,0,1,0,0], [0,1,1,1,0], [1,0,1,0,1], [0,0,1,0,0], [0,0,1,0,0]]) pt.imshow(pic,cmap='gray') pt.show()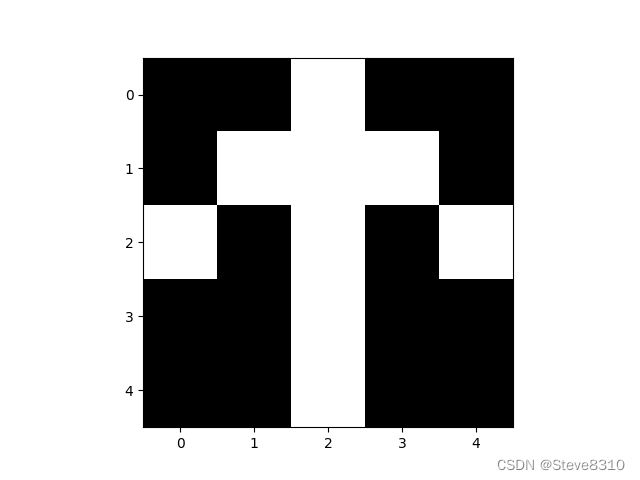
你大概可以看出这是一个向上的箭头,但如果我们按照全连接层的处理方法,对图像“扁平化”呢?
#3.py #将pic每一行首尾相接,合并成一行 pic_flat=pic.reshape(1,-1) pt.imshow(pic_flat,cmap='gray') pt.show() 
你还能看出这是一个向上的箭头吗?显然它丢失了像素在上下方向上的关联所蕴含的信息
构建模型并训练
我个人习惯于使用 pytorch 搭建深度学习模型,但百度的飞桨平台只允许使用百度自己的 paddlepaddle 库搭建模型。限于时间,我暂时放弃使用飞桨平台,在本地跑我的 pytorch🥺
基本流程仍然是数据处理,构建模型,训练模型,预测结果。这里面没有什么难点,需要使用的库也不多,贴一下就明白了:
import glob #获取文件位置 import nibabel #读取nii文件 import numpy #基本数据处理 from skimage import transform #数据处理中的图像缩放 from torch.utils.data import Dataset,DataLoader #构建数据集 import torch #构建模型 import pandas #打包输出结果 from matplotlib import pyplot #可视化训练过程本次搭建的简单 CNN 网络只有个位数层,仅包含卷积、池化、全连接这种基操。对于每张图百万级别的数据规模,泛化能力应该不咋地(事实证明确实如此):
class Net(torch.nn.Module): def __init__(self): super(Net,self).__init__() self.conv1=torch.nn.Conv2d(63,16,5) self.conv2=torch.nn.Conv2d(16,4,5) self.pool=torch.nn.MaxPool2d(2) self.fc1=torch.nn.Linear(6084,64) self.fc2=torch.nn.Linear(64,1) def forward(self,x): batch_size=x.size(0) x=x.to(torch.float32) x=torch.relu(self.pool(self.conv1(x))) x=torch.relu(self.pool(self.conv2(x))) x=x.view(batch_size,-1) x=self.fc1((x)) x=torch.sigmoid(self.fc2(x)) return x以前也做过各个流程的开发,但是这种全流程完整开发还没弄过几次,捯饬了一上午敲完了代码,调参又是一下午,最后分数只提升了一点

我的评价是总比没有好🤯
一些歪门邪道(划去)
在比赛提交结果页面中,官方给出了一个 csv 文件作为提交示例,其中所有的标签均为“NC”。而如果你将此文件提交上去,会得到0.74的超高评分(大嘘)

而本次竞赛的评价标准采用 F1 score,接受两个指标:精确率与召回率,公式如下:

简单来说,精确率是“我说是对的里,有多少真对”,召回率是“对的里面,有多少我说出来了”。对于全“NC”的标签,召回率显然为100%;又已知最终分数,可以解出精确率为0.59
也就是说,正确答案里面,100个标签中有59个“NC”!有心人可以将预测结果中的“NC”率=0.59,也作为一个学习目标来训练模型,来进一步逼近正确答案
预告
在第三次课堂上,如果有百度 paddlepaddle 的使用教学,我会保持更新;最后如果效果拿得出手,我计划把全部代码贴到gh上
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/20383.html