
写在前面的话: 实习了半个多月,总结一下学到的内容,还有在做项目中遇到的问题及其解决方式。由于找的爬虫实习岗,所以大多都是数据采集,数据库,xpath等的使用,都是为了学习巩固,有什么不对的地方还希望各位大佬指正出来,不胜感激。

- 附上一个特别好用的链接,能直接获取页面,类似
postman。 Convert curl syntax to Python 使用方法也在页面下面
一、xpath的一些用法
1. 转换格式
- 将解析过的
xpath转换成HTML字符串 - 为什么会用到这个,是因为之前在爬取一些js包含的内容时用到了
js2xml,具体可参考连接 爬虫之 JS(返回非 json 数据)的爬取 ,得到的结果是xpath格式,但是又不知道内容是什么
……
html = etree.HTML(text) content = etree.tostring(html, encoding="utf-8").decode("utf-8") 讯享网
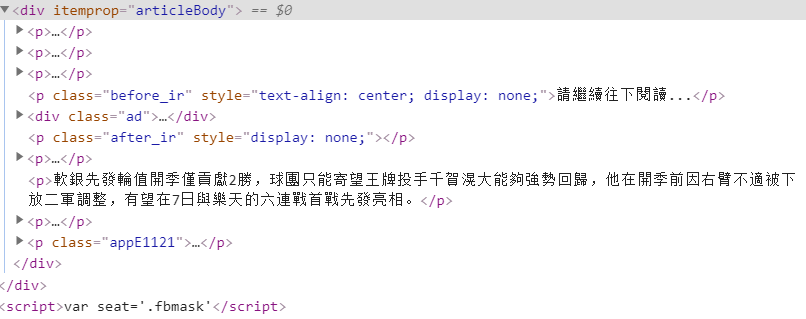
2. 去除不想要的标签
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/19857.html